深入 canvas/svg 的文本整形渲染

前言
在html/css中,我们已经习惯了其带来的便利,要展示一段文字,直接把内容写进一个节点(如)就行,设置好css的字体名、大小、行高、颜色。最多用到某种不常见的字体,稍微麻烦点通过font-face引入一下即可。
<style>
p {
width: 200px;
background: #F00;
font-family: 'PuHui';
font-size: 16px;
}
@font-face {
font-family: 'PuHui';
src: url(xxx.ttf);
}
</style>
<p>html的文字标签和css样式16px普惠体。</p>
声明式的标签结构,和面向切面的css排版样式使得web前端开发极为便利。
困难
然而在canvas中,一切都要从头开始。
字体加载可以用js中FontFace()和document.fonts.add()方法做,字体使用可以用ctx.font,渲染文本可以用ctx.fillText()。虽然麻烦了点但还是可以办到的。
排版换行怎么办?
最简单的,使用ctx.measureText()测量单字符宽度,然后一个个字符从左到右依次累加,超过则说明需要换行。这也是最常见的最基础的一种办法,很多方案都采用它。
如:https://www.zhangxinxu.com/wordpress/2018/02/canvas-text-break-line-letter-spacing-vertical/
看上去很美好,实际则暗藏玄机。另:svg类似,只是测量方式不一样,使用innerHTML+getComputedStyle()。
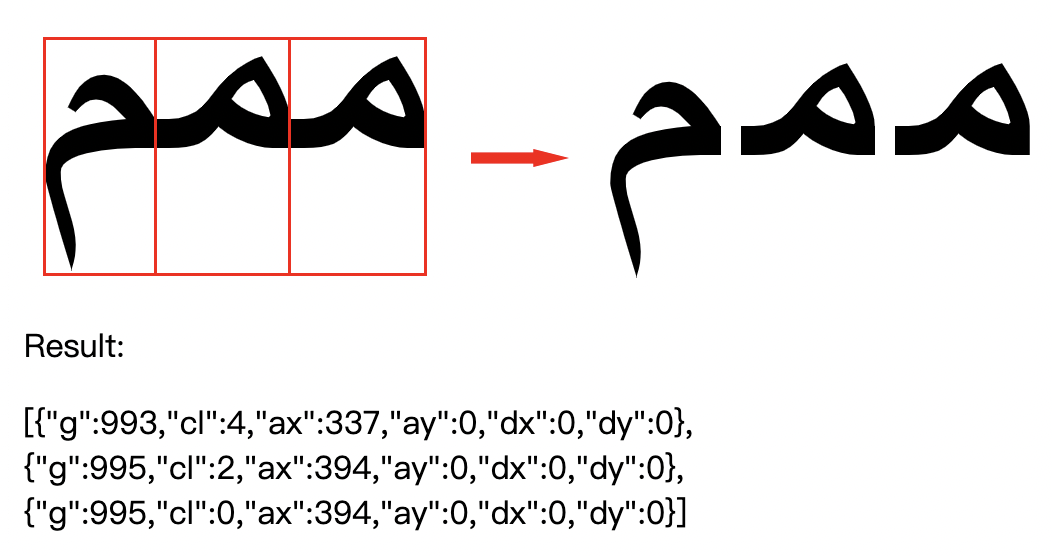
国人不常见的比如阿拉伯文字母 م,在单独书写时很正常,但在单词上下文中,就有不同的变体,连续多个时不是简单的拼接,而是 ممم。
这段红色标明的阿拉伯文,在浏览器上阅读时可以很明显地看到3个字母连续时的变化,常见的chrome/firefox浏览器用的是HarfBuzz。https://harfbuzz.github.io/why-do-i-need-a-shaping-engine.html
即便是常见的英文单词和数字,也普遍存在这种情况。
比如基础字形Arial、tahoma、苹方、宋体,它们的数字1字母f,都有类似情况出现。
karas.render(
<canvas width="360" height="360">
<span style={{
fontSize: 32,
fontFamily: 'Arial',
background: '#F00',
}}>1111111111</span>
</canvas>,
'#test'
);
可以看到,连续的字符1发生了书写变体,整体宽度比单个字符宽度之和要小,这反应在单行inline节点的尺寸(背景色)上。如果不用文本整形修正,尺寸和换行等计算全部会受影响,从而产生误差。
使用HarfBuzz,可以清楚地看到测量结果确实如此。
https://harfbuzz.github.io/harfbuzzjs/


解决既然单字符累加的方式有隐患,那么整体测量呢?
幸运的是,无论是canvas的ctx.measureText(),还是svg的getComputedStyle(),都可以将任意整段文字内容传入来测量,测量的结果浏览器底层已经包含了文本整形,因此它不会产生偏差!
ctx.measureText('1').width * 3; // 53.390625
ctx.measureText('111').width; // 48.640625这样的话,如果是测量宽度绘制单行inline背景色等场景,直接使用整体的结果即可。
那么多行换行呢?
简单办法依旧是累加,不过不再是单字符宽度累加,而是从第1个字符开始不断增加内容整体测量,直到>容器边界。
let str = '111111';
let widthLimit = 50;
for(let i = 1, length = str.length; i <= length; i++) {
let s = str.slice(0, i);
if(ctx.measureText(s).width > widthLimit) {
// 超过换行操作等
break;
}
}这里有个性能隐患,因为ctx.measureText()方法是和浏览器c/c++层交互,传递的是字符串内容,但js字符串截取再传递的性能消耗还是有的,如果容器尺寸比较大,文字又特别多,整个循环消耗就容易产生耗时。
karas目前使用了一种预测剩余宽度的算法。在给定fontSize的情况下,中文单字符一般宽度就是fontSize,英文一般在[0.5,1)的样子。其它语言都类似,因此假定一下一个字符占fontSize * 0.8,预估出容器边界widthLimit情况下,平均能容下多少字符进行测量。根据测量结果的误差,重复增减假定个数即可。
它能大大减少循环的次数,比普适的2分法表现还要好许多。 https://github.com/karasjs/karas/blob/8e35727421a59f2d4ab16b003ceb7200ab55b262/src/node/Text.js#L56-L163
场景
文字排版完善之后,常见的图文混排卡片渲染场景、个性化分享页等就不在话下。 即便是中文常见的标点悬挂,现代浏览器正则支持兼容性的也很好了。
除此之外,还有个大热门超难场景:web在线文档。
关于canvas实现doc的优劣细节不再多说,网络有很多讨论。这里选取比较常见canvas实现的代表测试下:google doc和腾讯文档。
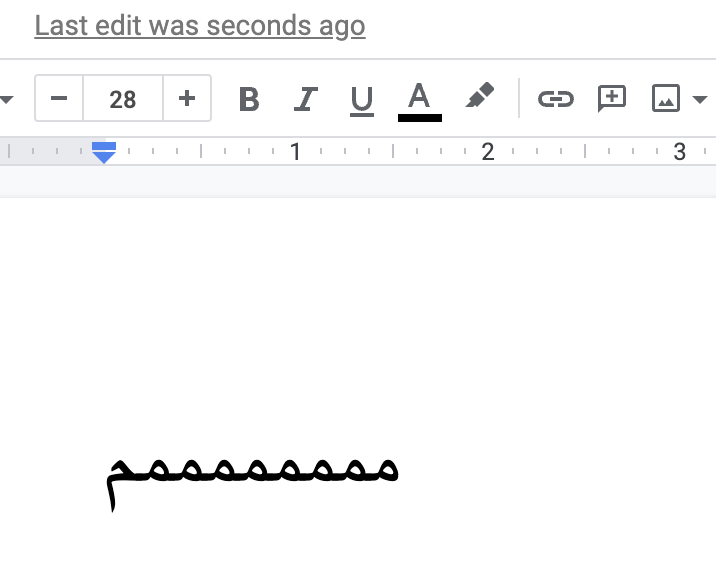
google doc不仅有基础的文本整形,还有双向文本BIDI支持,毕竟是偏国际化的,但是没有字间距,即css的letter-spacing。
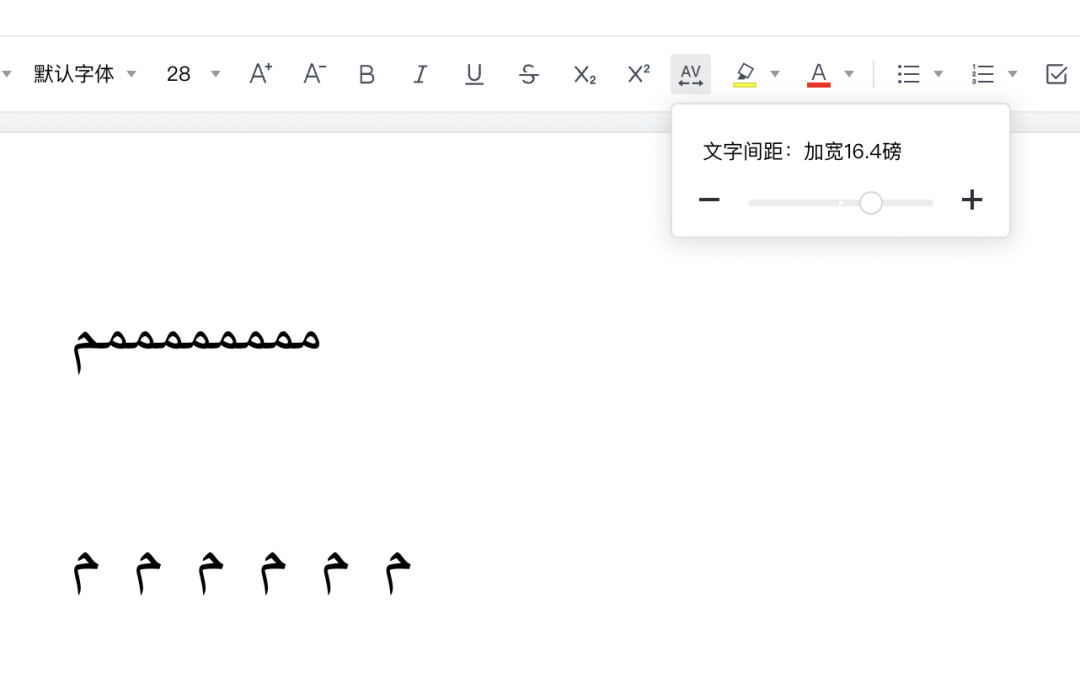
腾讯文档也有基础的文本整形,但没有双向文本,主打国内。有字间距,可惜的是,在文本整形的情况下失效了,本来应该变形的连续阿拉伯字母,变成了独立分开的形状。
这也情有可原,因为ctx.fillText()并不支持letter-spacing的设置,想要达到这一效果,只能回退到单个字符渲染的方案。这种情况没法使用整形,于是就降级为测量/渲染“错误”了。
那么有没有解决办法呢?
前面提到了Harfbuzz,官方提供的demo页面,仔细看发现是wasm,它可以使用js对已知字体文件(如ttf)的整段文本进行整形测量。
在线文档这个场景下面,由于可用字体是有限且已知的,因此当有letter-spacing时,宽度测量可以依旧使用ctx.measureText(),然后再加上字符个数 * letter-spacing,这样就能得出真正的尺寸。
渲染的时候呢,先按照无letter-spacing渲染到离屏画布上作为一张位图,再通过Harfbuzz的整形信息切割单个字符,重新ctx.drawImage()到主画布即可。只是性能没有实际测试过,这也是wasm存在的意义。
以上即是对文本整形的详解探索,如有错误请指正。
文字排版渲染只是普通渲染场景的冰山一角,随着功能的增多完善,像行级块级、图文混排、white-space、line-clamp、标点挤压,难度将呈几何级上升,不过这些是题外话超纲了,有机会另行叙说。