perf性能分析工具使用分享
前言
之前有分享过自己工作中自己搭建的CPU监控脚本等,但那个属于是自己手工写的一些脚本,比较粗浅的使用。后来就直接使用perf编译到驱动里面,在设备中直接使用perf了,比起自己写的脚本,效率直线提升。今天就来分享以下perf的功能使用,它可以将消耗 CPU 时间比较大的用户程序调用栈打印出来,并生成火焰图。
perf的介绍和安装
Perf 是Linux kernel自带的系统性能优化工具。Perf的优势在于与Linux Kernel的紧密结合,它可以最先应用到加入Kernel的new feature。pef可以用于查看热点函数,查看cashe miss的比率,从而帮助开发者来优化程序性能,也可以分析程序运行期间发生的硬件事件,比如 instructions retired ,processor clock cycles 等;您也可以分析 软件事件,比如 Page Fault 和进程切换,这使得 Perf 拥有了众多的性能分析能力,
通过它,应用程序可以利用 PMU,tracepoint 和内核中的特殊计数器来进行性能统计。它不但可以分析指定应用程序的性能问题 (per thread),也可以用来分析内核的性能问题,当然也可以同时分析应用代码和内核,从而全面理解应用程序中的性能瓶颈。
举例来说,使用 Perf 可以计算每个时钟周期内的指令数,称为 IPC,IPC 偏低表明代码没有很好地利用 CPU。Perf 还可以对程序进行函数级别的采样,从而了解程序的性能瓶颈究竟在哪里等等。Perf 还可以替代 strace,可以添加动态内核 probe 点,还可以做 benchmark 衡量调度器的好坏。。。
ubuntu安装:
sudo apt-get install linux-tools-common linux-tools-"$(uname -r)" linux-cloud-tools-"$(uname -r)" linux-tools-generic linux-cloud-tools-generic
安装好之后使用perf -v命令查看版本

在设备中安装 如果你使用yocto,那么可是用bitbake perf 直接编译perf工具出来,然后做成镜像烧录到设备中,如果你使用的是其他根文件系统制作工具,方法也是类似。
将编译好的的lib和bin目录拷贝到设备中使用。
perf基本使用
它和Oprofile性能调优工具等的基本原理都是对被监测对象进行采样,最简单的情形是根据 tick 中断进行采样,即在 tick 中断内触发采样点,在采样点里判断程序当时的上下文。假如一个程序 90% 的时间都花费在函数 foo() 上,那么 90% 的采样点都应该落在函数 foo() 的上下文中。运气不可捉摸,那么只要采样频率足够高,采样时间足够长,那么以上推论就比较可靠。因此,通过 tick 触发采样,我们便可以了解程序中哪些地方最耗时间,从而重点分析。
上面介绍了perf的原理,“根据 tick 中断进行采样,即在 tick 中断内触发采样点,在采样点里判断程序当时的上下文”,我们可以改变采样的触发条件使得我们可以获得不同的统计数据,例如 以时间点 ( 如 tick) 作为事件触发采样便可以获知程序运行时间的分布;以 cache miss 事件触发采样便可以知道 cache miss 的分布,即 cache 失效经常发生在哪些程序代码中。如此等等。
首先我们可以看一下 perf 中能够触发采样的事件有哪些。
perf list使用,可以列出所有的采样事件
sudo perf list
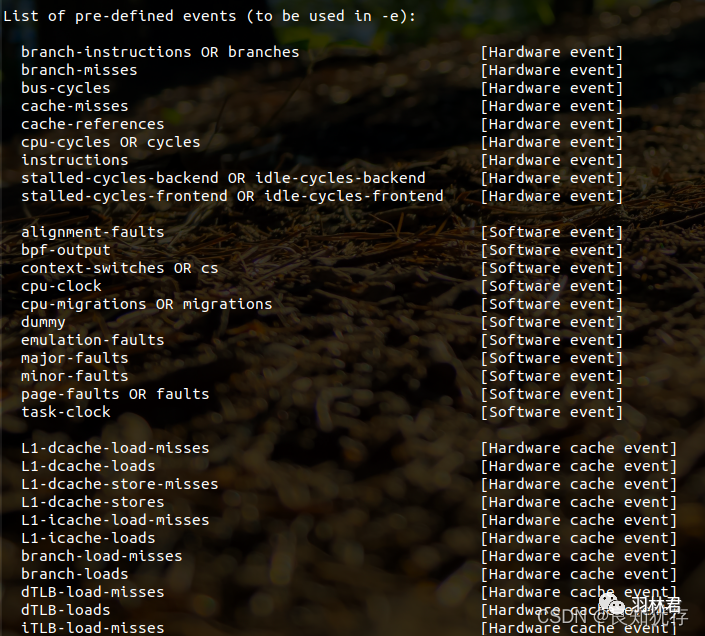
可以看到 Hadrware event Software event等
- Hardware Event 是由 PMU 硬件产生的事件,比如 cache 命中,当您需要了解程序对硬件特性的使用情况时,便需要对这些事件进行采样
- Software Event 是内核软件产生的事件,比如进程切换,tick 数等
- Tracepoint event 是内核中的静态 tracepoint 所触发的事件,这些 tracepoint 用来判断程序运行期间内核的行为细节,比如 slab 分配器的分配次数等
perf stat 概览程序的运行情况
perf stat选项,可以在终端上执行命令时收集性能统计信息
sudo perf stat -p 11664
指定进程查看,ctrl +c 杀死进程之后,就可以看到相应的数据了。
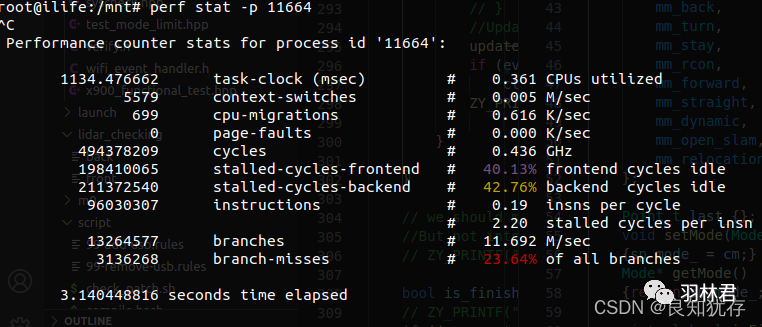
- task-clock(msec)是指程序运行期间占用了xx的任务时钟周期,该值高,说明程序的多数时间花费在 CPU 计算上而非 IO
- context-switches是指程序运行期间发生了xx次上下文切换,记录了程序运行过程中发生了多少次进程切换,频繁的进程切换是应该避免的。(有进程进程间频繁切换,或者内核态与用户态频繁切换)
- cpu-migrations 是指程序运行期间发生了xx次CPU迁移,即用户程序原本在一个CPU上运行,后来迁移到另一个CPU
- cycles:处理器时钟,一条机器指令可能需要多个 cycles
- Instructions: 机器指令数目。
- 其他可以监控的譬如分支预测、cache命中,page-faults 是指程序发生了xx次页错误等
sudo perf stat -p 13465
root@lyn:/mnt# ps -ux | grep target
root 13465 89.7 0.1 4588 1472 pts/1 R+ 17:30 0:07 ./target
root 13467 0.0 0.0 3164 744 pts/0 S+ 17:30 0:00 grep target
root@lyn:/mnt# perf stat -p 13465
^C
Performance counter stats for process id '13465':
13418.914783 task-clock (msec) # 1.000 CPUs utilized
13 context-switches # 0.001 K/sec
0 cpu-migrations # 0.000 K/sec
0 page-faults # 0.000 K/sec
25072130385 cycles # 1.868 GHz
20056061 stalled-cycles-frontend # 0.08% frontend cycles idle
8663621265 stalled-cycles-backend # 34.55% backend cycles idle
27108898221 instructions # 1.08 insns per cycle
# 0.32 stalled cycles per insn
3578980615 branches # 266.712 M/sec
841545 branch-misses # 0.02% of all branches
13.419173431 seconds time elapsed参考 链接
perf top实时显示当前系统的性能统计信息
sudo perf top -g
用于实时显示当前系统的性能统计信息。该命令主要用来观察整个系统当前的状态,比如可以通过查看该命令的输出来查看当前系统最耗时的内核函数或某个用户进程。
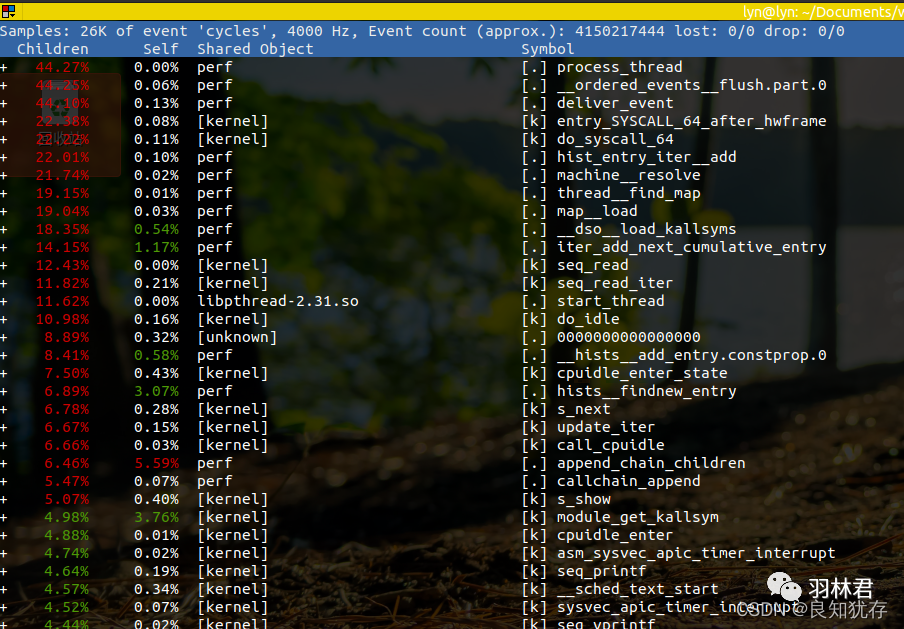
[.] : user level 用户态空间,若自己监控的进程为用户态进程,那么这些即主要为用户态的cpu-clock占用的数值 [k]: kernel level 内核态空间 [g]: guest kernel level (virtualization) 客户内核级别 [u]: guest os user space 操作系统用户空间 [H]: hypervisor 管理程序 The final column shows the symbol name.
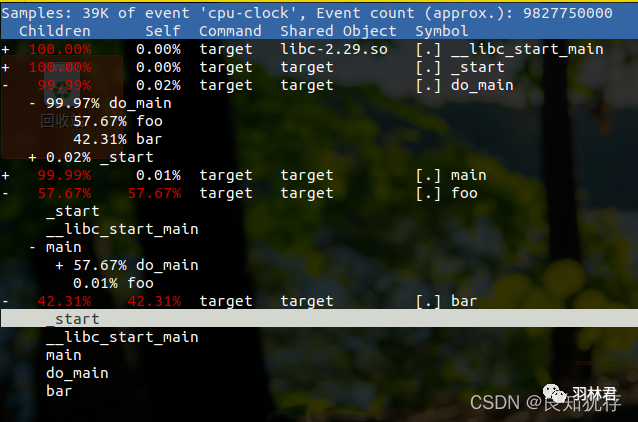
当 perf 收集调用链时,开销可以在两列中显示为Children和Self 。这里的Self列与没有“-g”的列类似:这是每个函数花费的 CPU 周期百分比。但是Children列在其下方添加了所有调用函数所花费的时间。不仅是直系子女,而且是所有后代。对于调用图的叶子,函数不调用其他任何东西,Self 和 Children 的值是相等的。但是对于 main(),它增加了在 f1()<-main() 和 f2()<-main() 中花费的时间。您将第一行读为:95.61% 的时间花在调用 main() 上,而只有 8.19% 的时间花在 main() 指令上,因为它大部分时间都在调用其他函数。请注意,您可以添加“Self”以覆盖 100%,但在“Children”中,儿童样本占多行。这个想法是在顶部查看占样本最多的调用堆栈片段。
有一个“+”,可以向下查看调用关系。
perf record 记录采集的数据
使用 top 和 stat 之后,perf可能已经大致有数了。要进一步分析,便需要一些粒度更细的信息。比如说我们已经断
使用 top 和 stat 之后,perf可能已经大致有数了。要进一步分析,便需要一些粒度更细的信息。比如说我们已经断定目标程序计算量较大,也许是因为有些代码写的不够精简。那么面对长长的代码文件,究竟哪几行代码需要进一步修改呢?这便需要使用 perf record 记录单个函数级别的统计信息,并使用 perf report 来显示统计结果(perf record表示记录到文件,perf top直接会显示到界面)。
perf record ,它可以对事件进行采样,将采样的数据收集在一个 perf.data 的文件中,这将会带来一定的性能开销,不过这个命令很有用,可以用来找出最占 CPU 的进程。
下面的命令对系统 CPU 事件做采样,采样时间为 60 秒,每秒采样 99 个事件,-g表示记录程序的调用栈。
sudoperf record -F 99 -a -g -- sleep 60
此外我们还可以使用PID监控程序perf record -e cpu-clock -g -p pid 监控 已启动的进程;也可以使用程序名监控程序perf record -e cpu-clock -g -p grep your_program
-e选项允许您在perf list命令中列出的多个类别中选择一个事件类别。例如,在这里,我们使用-e cpu-clock 是指perf record监控的指标为cpu周期程序运行完之后,perf record会生成一个名为perf.data的文件(缺省值),如果之前已有,那么之前的perf.data文件会变为perf.data.old文件
-g选项是告诉perf record额外记录函数的调用关系,因为原本perf record记录大都是库函数,直接看库函数,大多数情况下,你的代码肯定没有标准库的性能好对吧?除非是针对产品进行特定优化,所以就需要知道是哪些函数频繁调用这些库函数,通过减少不必要的调用次数来提升性能
perf record的其他参数:
- -f:强制覆盖产生的.data数据
- -c:事件每发生count次采样一次
- -p:指定进程
- -t:指定线程
可以使用ctrl+c中断perf进程,或者在命令最后加上参数 --sleep n (n秒后停止)
- sudo perf report -n可以生成报告的预览。
- sudo perf report -n --stdio可以生成一个详细的报告。
- sudo perf script可以 dump 出 perf.data 的内容。
获得这个perf.data文件之后,我们其实还不能直接查看,下面就需要perf report工具进行查看
perf report输出 record的结果
如果record之后想直接输出结果,使用perf report即可 perf report的相关参数: -i : 指定文件输出 -k:指定未经压缩的内核镜像文件,从而获得内核相关信息 --report:cpu按照cpu列出负载
sudo perf report
Samples: 123K of event 'cycles', Event count (approx.): 36930701307
Overhead Command Shared Object Symbol
18.91% swapper [kernel.kallsyms] [k] intel_idle
5.18% dev_ui libQt5lxxx [.] 0x00000000013044c7
3.20% dev_ui libc-2.19.so [.] _int_malloc
1.03% dev_ui libc-2.19.so [.] __clock_gettime
3.04% todesk libpixman-1.so.0.38.4 [.] 0x000000000008cac0
1.20% todesk [JIT] tid 126593 [.] 0x0000000001307c7a
0.84% todesk [JIT] tid 126593 [.] 0x000000000143c3f4
0.73% Xorg i965_dri.so [.] 0x00000000007cefe0
0.65% todesk libsciter-gtk.so [.] tool::tslice<gool::argb>::xcopy
0.58% Xorg i965_dri.so [.] 0x00000000007cf00e
0.53% Xorg i965_dri.so [.] 0x00000000007cf03c
0.49% todesk [JIT] tid 126593 [.] 0x0000000001307cb2
0.48% Xorg i965_dri.so [.] 0x00000000007cf06a
0.44% todesk [JIT] tid 126593 [.] 0x0000000001307cb6
0.41% todesk [JIT] tid 126593 [.] 0x0000000001307cc0
0.40% x-terminal-emul libz.so.1.2.11 [.] adler32_z
0.40% todesk [JIT] tid 126593 [.] 0x0000000001307c83
0.38% todesk [JIT] tid 126593 [.] 0x0000000001307cbb
0.33% swapper [kernel.kallsyms] [k] menu_select
0.32% gnome-shell libmutter-clutter-6.so.0.0.0 [.] clutter_actor_paint
0.31% gnome-shell libgobject-2.0.so.0.6400.6 [.] g_type_check_instance_is_a
0.31% swapper [kernel.kallsyms] [k] psi_group_change
0.24% SDK_Timer-8 [kernel.kallsyms] [k] psi_group_change
0.24% todesk libc-2.31.so [.] __memset_avx2_unaligned_erms
0.18% todesk [JIT] tid 126593 [.] 0x00000000013044c7
0.18% todesk [JIT] tid 126593 [.] 0x000000000143c3f0
0.17% gnome-shell libglib-2.0.so.0.6400.6 [.] g_hash_table_lookup
0.17% todesk [JIT] tid 126593 [.] 0x000000000143c426
0.17% todesk [JIT] tid 126593 [.] 0x000000000143c3dd
0.16% todesk [JIT] tid 126593 [.] 0x000000000143c3d9
0.16% swapper [kernel.kallsyms] [k] cpuidle_enter_state
0.16% SDK_Timer-8 [kernel.kallsyms] [k] syscall_exit_to_user_mode
0.16% swapper [kernel.kallsyms] [k] __sched_text_start
- 在第二行我们发现一个dev_ui ,占用了5.18%,使用了libQt5lxxx库, 它本身功能UI显示,,但是占用较高的CPU,说明调用该库存在问题(代码本身问题),需要对调用该库的代码进行检查。
- 第三行libc-2.19.so [.] _int_malloc 这是常用的malloc操作,由于对代码比较熟悉,在这个过程中不应该有这么多次申请内存,说明代码本身有问题,需要对申请动态内存的代码进行检查
- 第四行行 __clock_gettime 这个是由于计时需要,需要频繁获取时间,通常是指 gettimeofday()函数
- 整个统计显示有很多task-clock占用是由于kernel.kallsyms导致,同时也验证了对perf stat获得的数据的初步判断,即CPU飙升也与频繁的CPU迁移(内核态中断用户态操作)导致,解决办法是采用CPU绑核
也许有的人会奇怪为什么自己完全是一个用户态的程序为什么还会统计到内核态的指标?一是用户态程序运行时会受到内核态的影响,若内核态对用户态影响较大,统计内核态信息可以了解到是内核中的哪些行为导致对用户态产生影响;二则是有些用户态程序也需要依赖内核的某些操作,譬如I/O操作+ 4.93% dev_ui libcurl-gnutls.so.4.3.0 [.] 0x000000000001e1e0 ,左边的加号代表perf已经记录了该调用关系,按enter键可以查看调用关系,perf监控该进程结果记录到很多内核调用,说明该进程在运行过程中,有可能被内核态任务频繁中断,应尽量避免这种情况,对于这个问题我的解决办法是采用绑核,譬如机器有8个CPU,那么我就绑定内核操作、中断等主要在0-5CPU,GW由于有两个线程,分别绑定到6、7CPU上。
注意:调优应该将注意力集中到百分比高的热点代码片段上,假如一段代码只占用整个程序运行时间的 0.1%,即使您将其优化到仅剩一条机器指令,恐怕也只能将整体的程序性能提高 0.1%。俗话说,好钢用在刀刃上.
参考文章:链接
也可以用关键词筛选
使用了sudo perf report 可以查看当前perf.data的数据,但是当你代码调用很多时候不好进行分析查看,这个时候我们就可以选择我们需要关注的重点信息查看,提高效率。例如以下的futex_wait:

选中之后,使用 --call-graph ,,,,callee --symbol-filter = 后面增加你需要筛选监控的类型就可以单独显示了。
sudo perf report --call-graph ,callee –symbol-filter=futex_wait
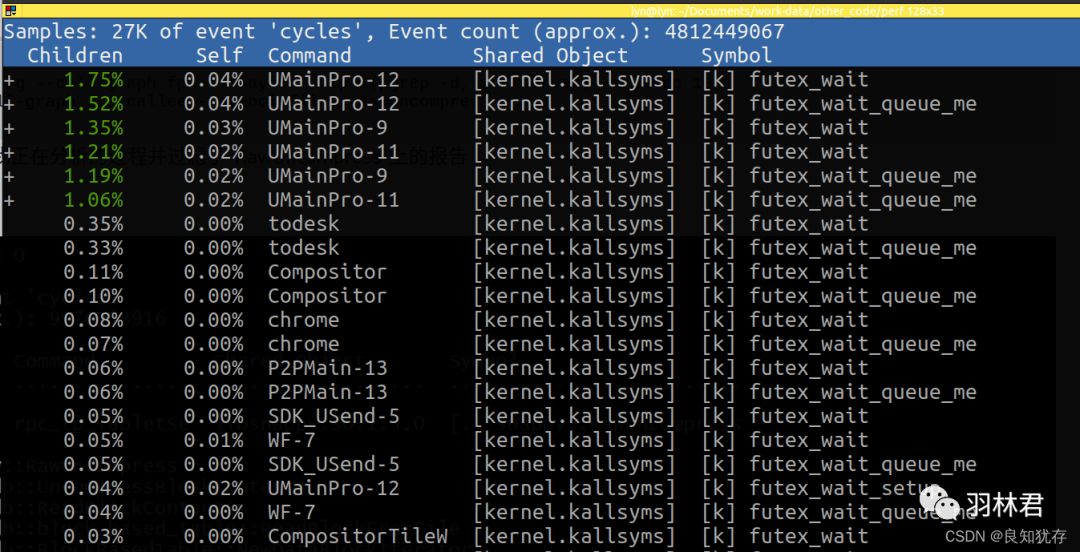
这篇文章可以更多的帮助你理解filter:链接
perf diff进行两次record对比
我们多次perf record之后,当前路径下会有两个perf.data 和perf.data.old文件,分别是本次和上次record的记录,这个时候我们可以通过perf diff进行对比优化的结果。

sudo perf diff perf.data perf.data.old
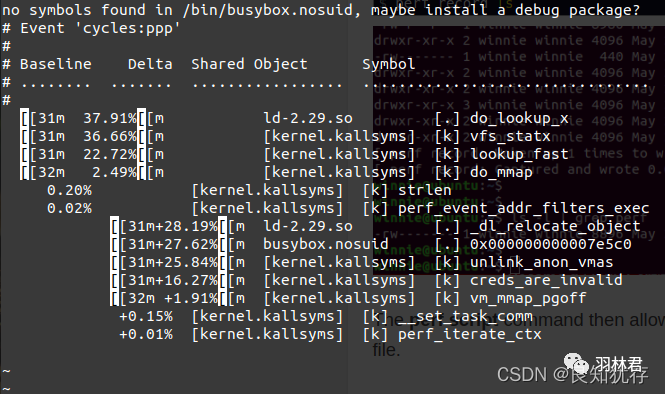
介绍一些了perf细节使用的描绘,再给大家分享一个perf详细使用介绍的网址,大家对于perf介绍中有需要继续深入探索的部分,可以点击以下链接进行学习。
perf Examples 详细的使用介绍
链接:https://www.brendangregg.com/perf.html
Linux Perf commands命令介绍使用
链接:https://linuxhint.com/linux-perf-commands/

火焰图的制作
CPU 的性能,它可以将消耗 CPU 时间比较大的用户程序调用栈打印出来,并生成火焰图。通过分析火焰图的顶层的显示,我们就可以很直观的查看我们函数的性能情况了。
这个是自己ubuntu20系统做捕获的火焰图显示
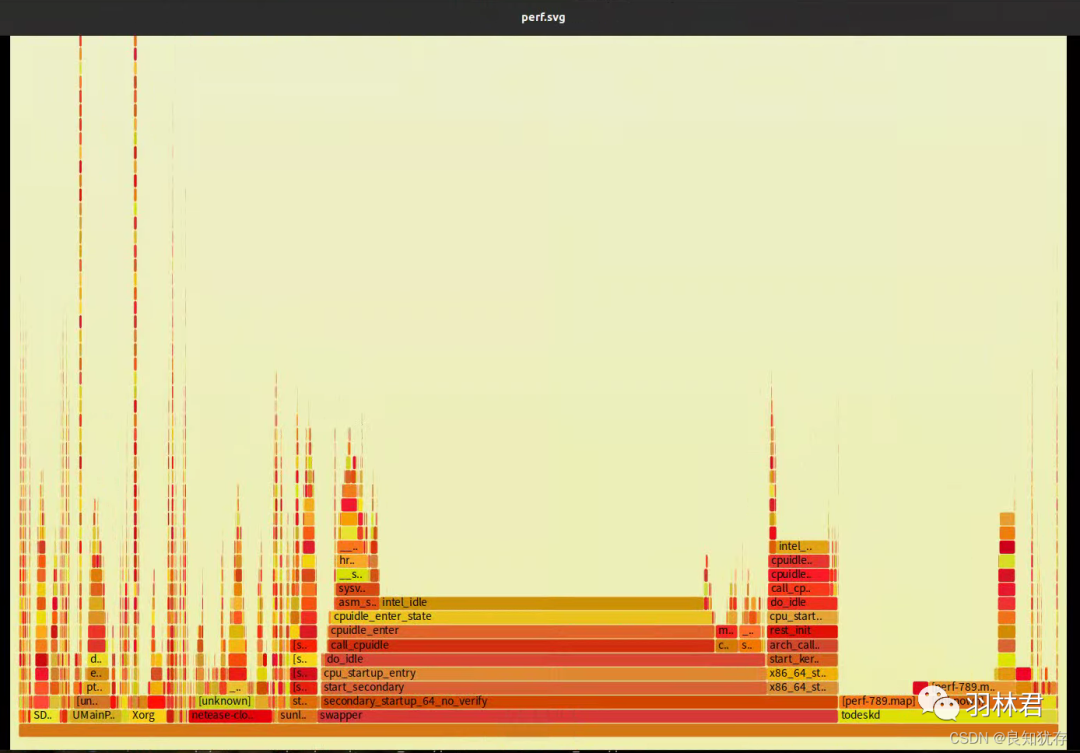
- x轴表示采样次数或者频率,如果一个函数在 x 轴占据的宽度越宽,就表示它被抽到的次数多,即执行的时间长。注意,x 轴不代表时间,而是所有的调用栈合并后,按字母顺序排列的。
- y 轴表示调用栈,每一层都是一个函数。调用栈越深,火焰就越高,顶部就是正在执行的函数,下方都是它的父函数。
火焰图就是看顶层的哪个函数占据的宽度最大。只要有"平顶"(plateaus),就表示该函数可能存在性能问题。
参考:链接1; 链接2
具体步骤:
- 1 首先,在 Ubuntu 安装 perf 工具:
- 2 再从github下载分析脚本 git clone https://github.com/brendangregg/FlameGraph.git
- 3 使用perf script工具对perf.data进行解析
perf script -i perf.data &> perf.unfold生成火焰图通常的做法是将 perf.unfold 拷贝到本地机器,在本地生成火焰图 - 4 将perf.unfold中的符号进行折叠
FlameGraph/stackcollapse-perf.pl perf.unfold &> perf.folded - 5 最后生成svg图
FlameGraph/flamegraph.pl perf.folded > perf.svg生成火焰图可以指定参数,–width 可以指定图片宽度,–height 指定每一个调用栈的高度,生成的火焰图,宽度越大就表示CPU耗时越多。

注 :如果svg图出现unknown函数,使用如下命令
sudo perf record -e cpu-clock --call-graph dwarf -p pid
范例:perf record -e cpu-clock -g -p 29713 --call-graph dwarf 使用–call-graph dwarf 之后record生成的perf.data很大,大家生成的时候要时刻注意设备剩余空间是否足够
实际测试范例
如图一段代码 main -> do_main -> foo -> bar 其中 foo 函数和 bar 各有一个for循环,用来表示代码时间运行消耗的cpu
#include <iostream>
#include <vector>
#include <string>
#include <unistd.h>
using namespace std;
void bar(){
// usleep(40*1000);
/* do something here */
for(int i=0;i< 4000;i++)
{
}
}
void foo(){
// usleep(60*1000);
for(int i=0;i< 5700;i++)
{
}
bar();
}
void do_main() {
foo();
}
int main(int argc,char** argv){
while(1)
{
do_main();
}
}运行代码之后进行 top实时查看(因为我的设备默认都是sudo权限,所以以下命令都不用前缀sudo)
ps -xu | grep target
perf top -e cpu-clock -p 29713
发现 foo 占用 60%cpu时间,而bar占用40%时间,和for循环展示的大致一样
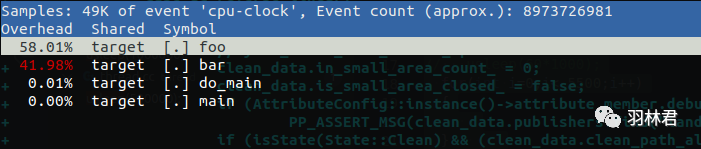
perf record -e cpu-clock -g -p 29713
ctrl + c停止记录,发现当前目录下保存了文件perf.data
使用report查看
perf report -i perf.data
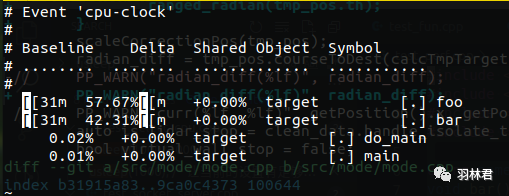
对比两者差异,因为只是单纯记录两次,代码没有修改,所以没有差异
perf diff perf.data perf.data
perf script -i perf.data &> perf.unfold
FlameGraph/stackcollapse-perf.pl test_data/perf.unfold &> test_data/perf.folded
拷贝到主机端进行转换成火焰图
FlameGraph/flamegraph.pl test_data/perf.folded > test_data/perf.svg
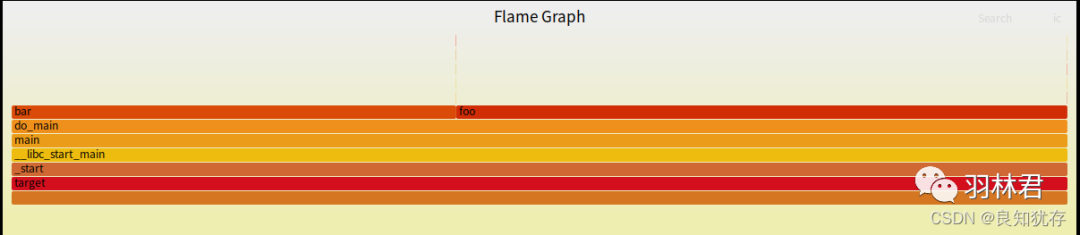
大家可以看到这个cpu占用关系,火焰图的顶层是个大平层,说明这段代码cpu单个函数foo和bar占用率太高,这段代码优化空间很大。
结语
这就是我自己的一些perf使用分享。如果大家有更好的想法和需求,也欢迎大家加我好友交流分享哈。