大文件怎样实现快速上传?
前言
大文件快速上传的方案,相信你也有过了解,其实无非就是将 文件变小,也就是通过 压缩文件资源 或者 文件资源分块 后再上传。
本文只介绍资源分块上传的方式,并且会通过 前端(vue3 + vite) 和 服务端(nodejs + koa2) 交互的方式,实现大文件分块上传的简单功能.
梳理思路
问题 1:谁负责资源分块?谁负责资源整合?
当然这个问题也很简单,肯定是前端负责分块,服务端负责整合.
问题 2:前端怎么对资源进行分块?
首先是选择上传的文件资源,接着就可以得到对应的文件对象 File,而 File.prototype.slice 方法可以实现资源的分块,当然也有人说是 Blob.prototype.slice 方法,因为 Blob.prototype.slice === File.prototype.slice.
问题 3:服务端怎么知道什么时候要整合资源?如何保证资源整合的有序性?
由于前端会将资源分块,然后单独发送请求,也就是说,原来 1 个文件对应 1 个上传请求,现在可能会变成 1 个文件对应 n 个上传请求,所以前端可以基于 Promise.all 将这多个接口整合,上传完成在发送一个合并的请求,通知服务端进行合并。
合并时可通过 nodejs 中的读写流(readStream/writeStream),将所有切片的流通过管道(pipe)输入最终文件的流中。
在发送请求资源时,前端会定好每个文件对应的序号,并将当前分块、序号以及文件 hash 等信息一起发送给服务端,服务端在进行合并时,通过序号进行依次合并即可。
问题 4:如果某个分块的上传请求失败了,怎么办?
一旦服务端某个上传请求失败,会返回当前分块失败的信息,其中会包含文件名称、文件 hash、分块大小以及分块序号等,前端拿到这些信息后可以进行重传,同时考虑此时是否需要将 Promise.all 替换为 Promise.allSettled 更方便.
前端部分
创建项目
通过 pnpm create vite 创建项目,对应文件目录如下.
请求模块
src/request.js
该文件就是针对 axios 进行简单的封装,如下:
import axios from "axios";
const baseURL = 'http://localhost:3001';
export const uploadFile = (url, formData, onUploadProgress = () => { }) => {
return axios({
method: 'post',
url,
baseURL,
headers: {
'Content-Type': 'multipart/form-data'
},
data: formData,
onUploadProgress
});
}
export const mergeChunks = (url, data) => {
return axios({
method: 'post',
url,
baseURL,
headers: {
'Content-Type': 'application/json'
},
data
});
}
复制代码文件资源分块
根据 DefualtChunkSize = 5 * 1024 * 1024 ,即 5 MB ,来对文件进行资源分块进行计算,通过 spark-md5[1] 根据文件内容计算出文件的 hash 值,方便做其他优化,比如:当 hash 值不变时,服务端没有必要重复读写文件等.
// 获取文件分块
const getFileChunk = (file, chunkSize = DefualtChunkSize) => {
return new Promise((resovle) => {
let blobSlice = File.prototype.slice || File.prototype.mozSlice || File.prototype.webkitSlice,
chunks = Math.ceil(file.size / chunkSize),
currentChunk = 0,
spark = new SparkMD5.ArrayBuffer(),
fileReader = new FileReader();
fileReader.onload = function (e) {
console.log('read chunk nr', currentChunk + 1, 'of');
const chunk = e.target.result;
spark.append(chunk);
currentChunk++;
if (currentChunk < chunks) {
loadNext();
} else {
let fileHash = spark.end();
console.info('finished computed hash', fileHash);
resovle({ fileHash });
}
};
fileReader.onerror = function () {
console.warn('oops, something went wrong.');
};
function loadNext() {
let start = currentChunk * chunkSize,
end = ((start + chunkSize) >= file.size) ? file.size : start + chunkSize;
let chunk = blobSlice.call(file, start, end);
fileChunkList.value.push({ chunk, size: chunk.size, name: currFile.value.name });
fileReader.readAsArrayBuffer(chunk);
}
loadNext();
});
}
复制代码发送上传请求和合并请求
通过 Promise.all 方法整合所以分块的上传请求,在所有分块资源上传完毕后,在 then 中发送合并请求.
// 上传请求
const uploadChunks = (fileHash) => {
const requests = fileChunkList.value.map((item, index) => {
const formData = new FormData();
formData.append(`${currFile.value.name}-${fileHash}-${index}`, item.chunk);
formData.append("filename", currFile.value.name);
formData.append("hash", `${fileHash}-${index}`);
formData.append("fileHash", fileHash);
return uploadFile('/upload', formData, onUploadProgress(item));
});
Promise.all(requests).then(() => {
mergeChunks('/mergeChunks', { size: DefualtChunkSize, filename: currFile.value.name });
});
}
复制代码进度条数据
分块进度数据利用 axios 中的 onUploadProgress 配置项获取数据,通过使用computed 根据分块进度数据的变化自动自动计算当前文件的总进度.
// 总进度条
const totalPercentage = computed(() => {
if (!fileChunkList.value.length) return 0;
const loaded = fileChunkList.value
.map(item => item.size * item.percentage)
.reduce((curr, next) => curr + next);
return parseInt((loaded / currFile.value.size).toFixed(2));
})
// 分块进度条
const onUploadProgress = (item) => (e) => {
item.percentage = parseInt(String((e.loaded / e.total) * 100));
}
复制代码服务端部分
搭建服务
- 使用 koa2 搭建简单的服务,端口为 3001
- 使用 koa-body 处理接收前端传递
'Content-Type': 'multipart/form-data'类型的数据 - 使用 koa-router 注册服务端路由
- 使用 koa2-cors 处理跨域问题
目录/文件划分
server/server.js
该文件是服务端具体的代码实现,用于处理接收和整合分块资源.
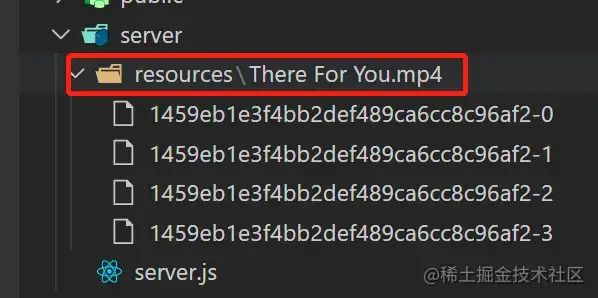
server/resources
该目录是用于存放单文件的多个分块,以及最后分块整合后的资源:
- 分块资源未合并时,会在该目录下以当前文件名创建一个目录,用于存放这个该文件相关的所有分块
- 分块资源需合并时,会读取这个文件对应的目录下的所有分块资源,然后将它们整合成原文件
- 分块资源合并完成,会删除这个对应的文件目录,只保留合并后的原文件,生成的文件名比真实文件名多一个
_前缀,如原文件名"测试文件.txt"对应合并后的文件名"_测试文件.txt"
接收分块
使用 koa-body 中的 formidable 配置中的 onFileBegin 函数处理前端传来的 FormData 中的文件资源,在前端处理对应分块名时的格式为:filename-fileHash-index,所以这里直接将分块名拆分即可获得对应的信息。
// 上传请求
router.post(
'/upload',
// 处理文件 form-data 数据
koaBody({
multipart: true,
formidable: {
uploadDir: outputPath,
onFileBegin: (name, file) => {
const [filename, fileHash, index] = name.split('-');
const dir = path.join(outputPath, filename);
// 保存当前 chunk 信息,发生错误时进行返回
currChunk = {
filename,
fileHash,
index
};
// 检查文件夹是否存在如果不存在则新建文件夹
if (!fs.existsSync(dir)) {
fs.mkdirSync(dir);
}
// 覆盖文件存放的完整路径
file.path = `${dir}/${fileHash}-${index}`;
},
onError: (error) => {
app.status = 400;
app.body = { code: 400, msg: "上传失败", data: currChunk };
return;
},
},
}),
// 处理响应
async (ctx) => {
ctx.set("Content-Type", "application/json");
ctx.body = JSON.stringify({
code: 2000,
message: 'upload successfully!'
});
});
复制代码整合分块
通过文件名找到对应文件分块目录,使用 fs.readdirSync(chunkDir) 方法获取对应目录下所以分块的命名,在通过 fs.createWriteStream/fs.createReadStream 创建可写/可读流,结合管道 pipe 将流整合在同一文件中,合并完成后通过 fs.rmdirSync(chunkDir) 删除对应分块目录.
// 合并请求
router.post('/mergeChunks', async (ctx) => {
const { filename, size } = ctx.request.body;
// 合并 chunks
await mergeFileChunk(path.join(outputPath, '_' + filename), filename, size);
// 处理响应
ctx.set("Content-Type", "application/json");
ctx.body = JSON.stringify({
data: {
code: 2000,
filename,
size
},
message: 'merge chunks successful!'
});
});
// 通过管道处理流
const pipeStream = (path, writeStream) => {
return new Promise(resolve => {
const readStream = fs.createReadStream(path);
readStream.pipe(writeStream);
readStream.on("end", () => {
fs.unlinkSync(path);
resolve();
});
});
}
// 合并切片
const mergeFileChunk = async (filePath, filename, size) => {
const chunkDir = path.join(outputPath, filename);
const chunkPaths = fs.readdirSync(chunkDir);
if (!chunkPaths.length) return;
// 根据切片下标进行排序,否则直接读取目录的获得的顺序可能会错乱
chunkPaths.sort((a, b) => a.split("-")[1] - b.split("-")[1]);
console.log("chunkPaths = ", chunkPaths);
await Promise.all(
chunkPaths.map((chunkPath, index) =>
pipeStream(
path.resolve(chunkDir, chunkPath),
// 指定位置创建可写流
fs.createWriteStream(filePath, {
start: index * size,
end: (index + 1) * size
})
)
)
);
// 合并后删除保存切片的目录
fs.rmdirSync(chunkDir);
};
复制代码前端 & 服务端 交互
前端分块上传
测试文件信息:

服务端分块接收
前端发送合并请求
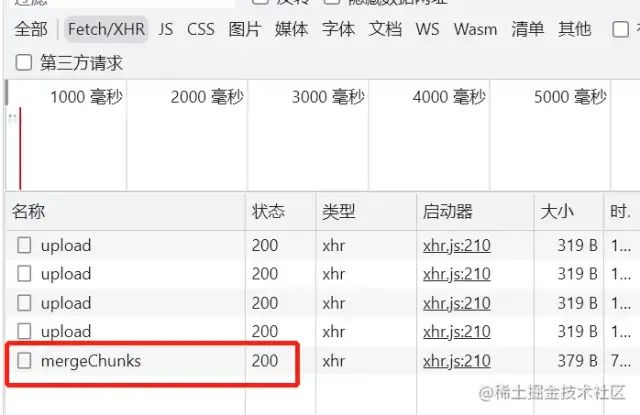
服务端合并分块

扩展 —— 断点续传 & 秒传
有了上面的核心逻辑之后,要实现断点续传和秒传的功能,只需要在取扩展即可,这里不再给出具体实现,只列出一些思路.
断点续传
断点续传其实就是让请求可中断,然后在接着上次中断的位置继续发送,此时要保存每个请求的实例对象,以便后期取消对应请求,并将取消的请求保存或者记录原始分块列表取消位置信息等,以便后期重新发起请求.
取消请求的几种方式
- 如果使用原生 XHR 可使用
(new XMLHttpRequest()).abort()取消请求 - 如果使用 axios 可使用
new CancelToken(function (cancel) {})取消请求 - 如果使用 fetch 可使用
(new AbortController()).abort()取消请求
秒传
不要被这个名字给误导了,其实所谓的秒传就是不用传,在正式发起上传请求时,先发起一个检查请求,这个请求会携带对应的文件 hash 给服务端,服务端负责查找是否存在一模一样的文件 hash,如果存在此时直接复用这个文件资源即可,不需要前端在发起额外的上传请求.
最后
前端分片上传的内容单纯从理论上来看其实还是容易理解的,但是实际自己去实现的时候还是会踩一些坑,比如服务端接收解析 formData 格式的数据时,没法获取文件的二进制数据等