Mutex内核同步机制详解
一、Mutex锁简介
在linux内核中,互斥量(mutex,即mutual exclusion)是一种保证串行化的睡眠锁机制。和spinlock的语义类似,都是允许一个执行线索进入临界区,不同的是当无法获得锁的时候,spinlock原地自旋,而mutex则是选择挂起当前线程,进入阻塞状态。正因为如此,mutex无法在中断上下文使用。和mutex更类似的机制(无法获得锁时都会阻塞)是binary semaphores,当然,mutex有更严格的使用规则:
1、只有mutex的owner可以才可以释放锁
2、不可以多次释放同一把锁
3、不允许重复获取同一把锁,否则会死锁
4、必须使用mutex初始化API来完成锁的初始化,不能使用类似memset或者memcp之类的函数进行mutex初始化
5、不可以多次重复对mutex锁进行初始化
6、线程退出后必须释放自己持有的所有mutex锁
当配置了DEBUG_MUTEXES的时候,内核会对上面的规则进行检查,防止用户误用mutex,产生各种问题。
下面是一个简单的mutex工作原理图:

传统的mutex只需要一个状态标记和一个等待队列就OK了,等待队列中是一个个阻塞的线程,thread owner当前持有mutex,当它离开临界区释放锁的时候,会唤醒等待队列中第一个线程(top waiter),这时候top waiter会去竞争持锁,如果成功,那么从等待队列中摘下,成为owner。如果失败,继续保持阻塞状态,等待owner释放锁的时候唤醒它。在owner task持锁过程中,如果有新的任务来竞争mutex,那么就会进入阻塞状态并插入等待队列的尾部。
相对于传统的mutex,linux内核进行了一些乐观自旋的优化,也就是说当线程持锁失败的时候,可以选择在mutex状态标记上自旋,等待owner释放锁,也可以选择进入阻塞状态并挂入等待队列。具体如何选择是在自旋等待的时间开销和进程上下文切换的开销之间进行平衡。此外为了防止多个线程自旋带来的性能问题,mutex的乐观自旋机制还引入了MCS锁,后面章节我们会详细描述。
二、数据结构
1、互斥量对象
互斥量对象用struct mutex来抽象,其成员描述如下:

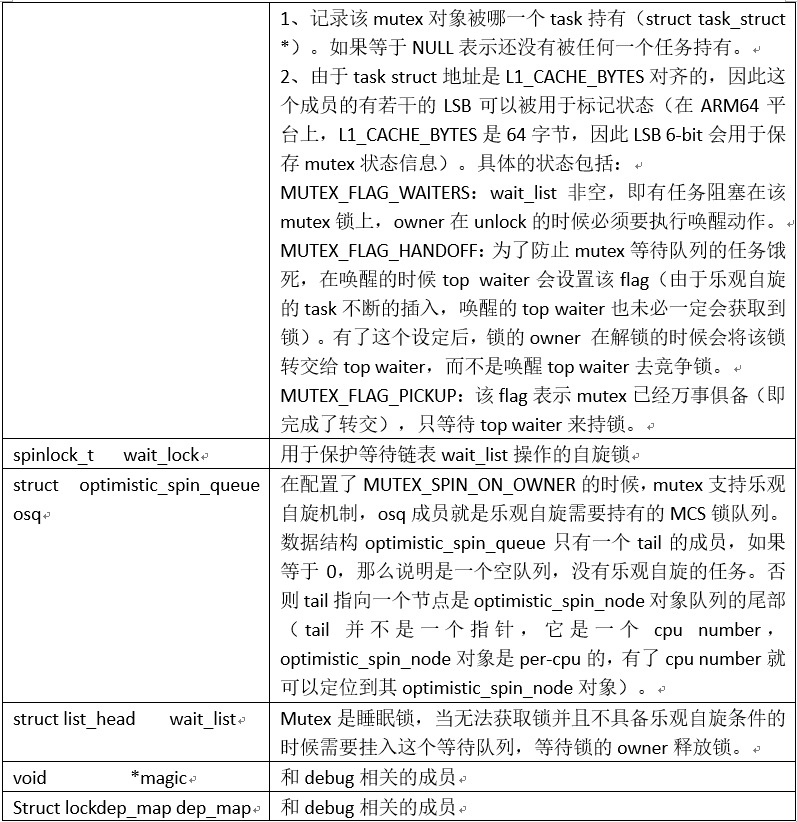
大部分的成员都非常好理解,除了osq这个成员,其工作原理示意图如下:
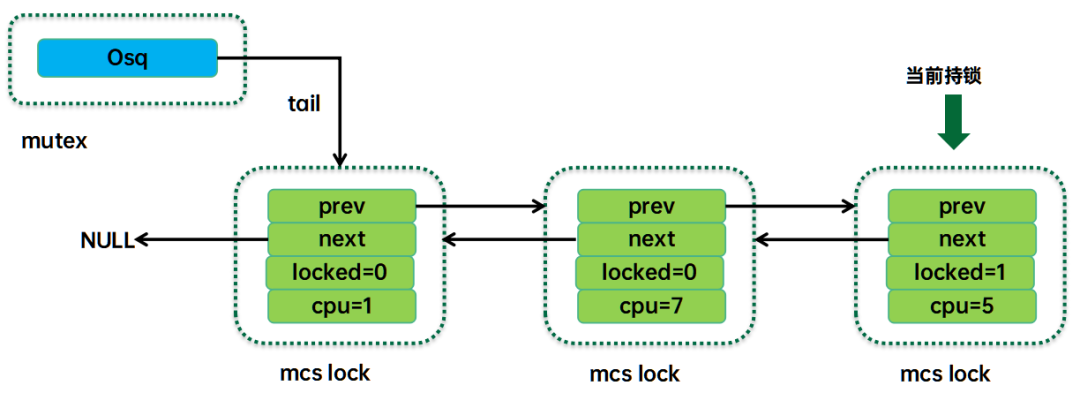
字如其名,Optimistic spin queue就是乐观自旋队列的意思,也就是形成一组处于自旋状态的任务队列。和等待队列不一样,这个队列中的任务都是当前正在执行的任务。Osq并没有直接将这些任务的task struct形成队列结构,而是把per-CPU的mcs lock对象串联形成队列。Mcs lock中有cpu number,通过这些cpu number可以定位到指定cpu上的current thread,也就定位到了自旋的任务。
虽然都是自旋,但是自旋方式并不一样。Osq队列中的头部节点是持有osq锁的,只有该任务处于对mutex的owner进行乐观自旋的状态(我们称之mutex乐观自旋)。Osq队列中的其他节点都是自旋在自己的mcs lock上(我们称之mcs乐观自旋)。当头部的mcs lock释放掉后(结束mutex乐观自旋,持有了mutex锁),它会将mcs lock传递给下一个节点,从而让spinner队列上的任务一个个的按顺序进入mutex的乐观自旋,从而避免了cache-line bouncing带来的性能开销。
2、等待任务对象
由于是sleep lock,我们需要把等待的任务挂入队列。在内核中,Struct mutex_waiter用来抽象等待mutex的任务,其成员描述如下:

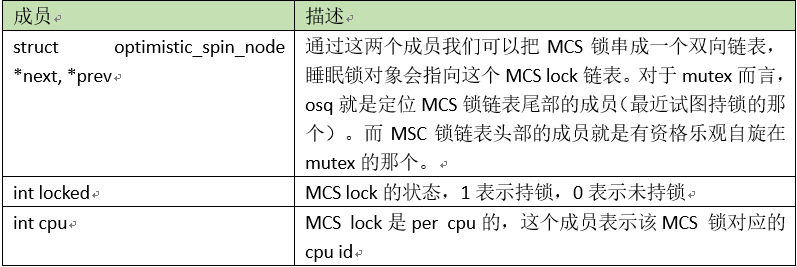
3、MCS锁对象
在linux内核中,我们对睡眠锁(例如mutex、rwsem)进行了乐观自旋的优化,这涉及到MCS lock,struct optimistic_spin_node用来抽象乐观自旋的MCS lock,其成员描述如下:
三、外部接口
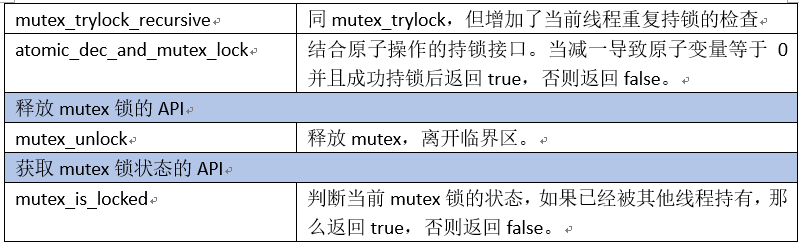
Mutex模块的外部接口API如下:

四、尝试获取锁
和mutex_lock不一样,mutex_trylock只是尝试获取锁,如果成功,那么自然是好的,直接返回true,如果失败,也不会阻塞,只是返回false就可以了。代码主逻辑在__mutex_trylock_or_owner函数中,如下:

A、对于mutex的owner成员,它是一个原子变量,我们采用了大量的原子操作来访问或者更新它。然而判断持锁需要一连串的操作,我们并没有采用同步机制(例如自旋锁)来保护这一段的对owner成员操作,因此,我们这些操作放到一个for循环中,在操作的结尾处会判断是否有其他线程插入修改了owner成员,如果中间有其他线程插入,那么就需要重新来过。
B、如果task非空(task变量保存了owner中去掉flag部分的任务指针),并且也不等于current thread,那么说明mutex锁被其他线程持有,还没有释放锁(也有可能在是否锁的时候,把锁直接转交给了其他线程),因此直接break跳出循环,持锁失败。
C、如果task等于current thread,而且设置了MUTEX_FLAG_PICKUP的标记,那么说明持锁线程已经把该mutex锁转交给了本线程,等待本线程来拾取。如果没有MUTEX_FLAG_PICKUP标记,那么也是直接break跳出循环,递归持锁失败。
D、有两种情况会走到这里的时候,一种情况是task为空,说明该mutex锁处于unlocked状态。另外一种情况是task非空,等于current thread,并且mutex发生了handoff,该锁被转交给当前试图持锁的线程。无论哪种情况,都可以去执行持锁操作了。
E、调用atomic_long_cmpxchg_acquire尝试获取锁,如果成功获取了锁(没有其他线程插入修改owner这个原子变量),返回NULL。如果owner发生了变化,说明中间有其他线程插入,那么重新来过。
五、获取mutex锁
mutex_lock代码如下:

这里的might_sleep说明调用mutex_lock函数有可能会因为未能获取到mutex锁而进入阻塞状态。在原子上下文中(中断上下文、软中断上下文、持有自旋锁、禁止抢占等),我们不能调用可以引起阻塞的函数,因此在might_sleep函数中嵌入了这个检查,当原子上下文中调用mutex_lock函数的时候,内核会打印出内核栈的信息,从而定位这个异常。
当然,这个功能是在设置CONFIG_DEBUG_ATOMIC_SLEEP选项的情况下才生效的,如果没有设置这个选项,might_sleep函数退化为might_resched函数。在配置了抢占式内核(CONFIG_PREEMPT)或者非抢占式内核(CONFIG_PREEMPT_NONE)的情况下,might_resched是空函数。
在配置了主动抢占式内核(CONFIG_PREEMPT_VOLUNTARY)的情况下,might_resched会调用_cond_resched函数来主动触发一次抢占。主动抢占式内核通过在might_sleep函数中增加了潜在的调度点实现了比非抢占式内核更好的延迟特性,同时确保抢占带来的进程切换开销低于抢占式内核。
Mutex是一种睡眠锁,如果未能获取锁,那么当前线程会阻塞。不过也许我们试图获取的mutex还处于空闲状态,因此通过__mutex_trylock_fast来尝试获取mutex(mutex_lock的快速路径):

atomic_long_try_cmpxchg_acquire函数有三个参数,从左到右分别是value指针,old指针和new。该函数会对比*value和*old指针中的数值,如果相等执行赋值*value=new同时返回true。如果不相等,不执行赋值操作,直接返回false。
如果lock->owner的值等于0(即不仅task struct地址等于0,所有的flag也要等于0),那么将当前线程的task struct的指针赋值给lock->owner,表示该mutex锁已经被当前线程持有。如果lock->owner的值不等于0,表示该mutex锁已经被其他线程持有或者锁正在传递给top waiter线程,当前线程需要阻塞等待。需要特别说明的是上面描述的操作(比较和赋值)都是原子操作,不能有任何指令插入其中。
在未能获取mutex锁的情况下,我们需要调用__mutex_lock_slowpath函数进入慢速路径。由于会进入睡眠,因此这里需要明确当前线程需要处于的阻塞状态,主要有三种状态:D状态、S状态和KILLABLE。
当调用不同的持锁API的时候,当前线程可以处于各种不同的状态。对于mutex_lock(大部分场景)当前线程会进入D状态。主要的代码逻辑在__mutex_lock_common函数中,我们分段解读(省略wait/wound和调试部分的代码):


__mutex_trylock用来再次尝试获取锁,mutex_optimistic_spin则是mutex乐观自旋(Optimistic spinning)部分的代码。这两个操作只要有其一能成功获取mutex锁,那么就直接返回了。由于没有进入阻塞状态,因此这个路径也叫做中速路径。
__mutex_trylock在上一节已经讲解了,不再赘述。乐观自旋的思路是因为mutex锁可能是被其他CPU上正在执行中的线程持有,如果临界区比较短,那么有可能该mutex锁很快就被释放。这时候,与其进行一次上下文切换,还不如自旋等待,毕竟上下文切换的开销也是不小的。乐观自旋机制底层使用的是MCS锁,具体的细节我们会在其他文档中描述。
慢速路径的代码如下(省略部分代码):

A、所谓慢速路径其实就是阻塞当前线程,这里将current task挂入mutex的等待队列的尾部。这样的操作让所有等待mutex的任务按照时间的先后顺序排列起来,当mutex被释放的时候,会首先唤醒队首的任务,即最先等待的任务最先被唤醒。此外,在向空队列插入第一个任务的时候,会给mutex flag设置上MUTEX_FLAG_WAITERS标记,表示已经有任务在等待这个mutex锁了。
B、进入阻塞状态,触发一次调度。由于目前执行上下文处于关闭抢占状态,因此这里的调度使用了关闭抢占版本的schedule函数。
C、该任务被唤醒之后,如果是等待队列中的第一个任务,即top waiter,那么需要给该mutex设置MUTEX_FLAG_HANDOFF,这样即便本次唤醒后无法获取到mutex(有些在该mutex上乐观自旋的任务可能会抢先获得锁),那么下一次owner释放锁的时候,看到这个handoff标记也会进行锁的交接,不再是大家抢来抢去。通过这个机制,我们可以防止spinner队列中的任务抢占CPU资源,饿死waiter队列中的任务。
D、如果获取到mutex,那么就退出循环,否则继续进入阻塞状态等待。如果是队列中的第一个waiter,那么如果__mutex_trylock失败,那么就进入乐观自旋过程,这样会有更大的机会成功获取mutex锁。
六、乐观自旋
Mutex乐观自旋的代码位于mutex_optimistic_spin函数中,进入乐观自旋函数的线程可能有下面几个结果:
1、成功获取osq锁,进入mutex乐观自旋状态,当owner释放mutex锁后,该线程结束乐观自旋,成功持有了mutex,返回true 2、未能获取osq锁,在自己的MCS锁上乐观自旋。一旦成功持锁,同步骤1 3、在MCS锁或者mcs锁乐观自旋的时候,由于各种原因(例如owner进入阻塞状态)而无法继续乐观自旋,那么mutex_optimistic_spin函数返回false,告知调用者乐观自旋失败,进入等待队列。
我们分两段来解析。首先来看第一段:

调用mutex_optimistic_spin函数的场景有两个,一个是waiter等于NULL,这是发生在mutex_lock的早期,这时候试图持锁的线程还没有挂入等待队列,因此waiter等于NULL。另外一个场景是持锁未果,挂入等待队列,然后被唤醒之后的乐观自旋。这时候试图持锁的线程已经挂入等待队列,因此waiter非空。在这种场景下,刚唤醒的top waiter线程会给与优待,因此不需要持有osq锁就可以长驱直入,进入乐观自旋。
A、当waiter为空时,因为是正常路径的持锁请求,所以在乐观自旋之前需要持有osq锁,只有获得了osq锁,当前线程才能进入mutex乐观自旋的过程。否则只能是在自己的MCS锁上自旋等待。
B、是否乐观自旋等待mutex可以从两个视角思考:一方面,如果本cpu已经设置了need resched标记,那说明有其他任务想要抢占当前试图持锁的任务。那么current task何必乐观自旋呢,赶紧的去sleep为其他任务让路吧。另外一方面需要从owner的行为来判断。如果owner正在其他cpu欢畅运行,那么可以考虑进入乐观自旋过程。
C、在基于共享内存的多核计算系统中,mutex的实现是通过一个共享变量(owner成员)和一个队列来完成复杂的控制的。如果有多个cpu上的线程同时乐观自旋在这个共享变量上,那么就会出现缓存踩踏现象。为了解决这个问题,我们控制不能让太多的线程进入mutex乐观自旋状态(轮询owner成员),只有那些获取了osq锁的线程才能进入。未能持osq锁的线程会进入mcs锁的乐观自旋过程,等待osq锁的owner(当前在mutex乐观自旋)释放osq锁。关于osq锁的细节我们在其他文章中描述。
完成了持osq锁之后(或者是被唤醒的top waiter线程,它会掠过osq持锁过程),我们就可以进入mutex乐观自旋了,代码如下:

A、首先还是调用__mutex_trylock_or_owner试图获取mutex锁,如果返回的owner非空(需要注意的是:这里的owner变量不包括mutex flag部分),那么说明mutex锁还在owner task手中。如果owner是空指针,说明原来持有锁的owner已经释放锁,同时这也就说明当前线程持锁成功,因此退出乐观自旋的循环。需要注意的是在退出mutex乐观自旋后会释放osq锁,从而会让spinner队列中的下一个mcs锁自旋的任务进入mutex乐观自旋状态。
B、如果__mutex_trylock_or_owner返回了非空owner,说明当前线程获取锁失败,那么可以进入mutex乐观自旋了。所谓自旋不是自旋在spinlock上,而是不断的循环检测锁的owner task是否发生变化以及owner task的运行状态。如果owner阻塞了或者当前cpu有resched的需求(可能唤醒更高级任务),那么就停止自旋,返回false,走入fail_unlock流程。
C、如果mutex锁的owner task发生变化(例如变成NULL)则mutex_spin_on_owner函数返回true,则说明可以跳转到for循环处再次尝试获取锁并进行乐观自旋。
七、释放mutex锁
mutex_unlock的代码如下:

如果一个线程获取了某个mutex锁之后,没有任何其他的线程试图进入临界区,那么这时候mutex的owner成员就是该线程的task struct地址,并且所有的mutex flag都是clear的。在这种情况下,将mutex的owner成员清零即可,不需要额外的操作,我们称之解锁快速路径(__mutex_unlock_fast)。
当然,如果有其他线程在竞争该mutex锁,那么情况会更复杂一些,这时候我们进入慢速路径(_mutex_unlock_slowpath),慢速路径的逻辑分成两段:一段是释放mutex锁,另外一段是唤醒top waiter线程。我们首先一起看第一段的代码,如下:

A、如果mutex flag中设定了handoff标记,那么说明owner在释放锁的时候要主动的把锁的owner传递给top waiter,不能让后来插入的乐观自旋的线程饿死top waiter。因此这时候我们还不能放锁,需要在__mutex_handoff函数中释放锁给top waiter。
B、将owner的task struct地址部分清掉,这也就是意味着owner task放弃了持锁。这时候,如果有乐观自旋的任务在轮询mutex owner,那么它会立刻感知到锁被释放,因此可以立刻获取mutex锁。在这样的情况下,即便后面唤醒了top waiter,但为时已晚。
C、如果等待队列中有任务阻塞在这个mutex中,那么退出循环,执行慢速路径中的第二段唤醒逻辑,否则直接返回,无需唤醒其他线程。
D、在操作owner的过程中,如果有其他线程对owner进行的修改(没有同步机制保证多线程对owner的并发操作),那么重新设定owner,再次进行检测。第二段唤醒top waiter的代码如下:

A、代码执行至此,需要唤醒top waiter,或者处理将锁转交top waiter的逻辑,无论哪种情况,都需要从等待队列中找到top waiter。找到后将其加入wake queue。
B、如果有任务(一般是top waiter,参考其唤醒后的代码逻辑)请求handoff mutex,那么调用__mutex_handoff函数可以直接将owner设置为top waiter任务,然后该任务在醒来之后直接pickup即可。这相当与给了top waiter一些特权,防止由于不断的插入乐观自旋的任务而导致无法获取CPU资源。
C、唤醒top waiter任务
八、结论
本文简单的介绍了linux内核中的mutex同步机制,在移动环境中,mutex锁的性能表现不尽如人意,无论是吞吐量还是延迟。在重载的场景下,我们经常会遇到Ux线程阻塞在mutex而引起的手机卡顿问题,如何在手机平台上优化mutex锁的性能是我们OPPO内核团队一直在做的事情,也欢迎热爱技术的你积极参与。
参考文献:
1、内核源代码
2、linux-5.10.61\Documentation\scheduler\*
3、https://zhuanlan.zhihu.com/p/364130923