go垃圾回收[5]—栈与栈对象
choose the tool for the problem and do not try to fit the problem for the tool
前情回顾
- [山雨欲来—Go垃圾回收连续剧预告]
- [激荡60年——垃圾回收与Go的选择]
- [go垃圾回收[2]—标记准备]
- [go垃圾回收[3]—并行标记执行模式]
- [go垃圾回收[4]—根对象与全局扫描]
栈扫描
在进行根对象扫描的过程中,栈扫描是其中最重要的部分。因为在一个程序中,可能会有成千上万的协程栈。栈扫描需要编译时与运行时的共同努力,运行时能够计算出当前协程栈的所有栈帧信息,而编译时能够得知栈上哪些地方有指针,以及对象中的哪一个部分包含了指针。
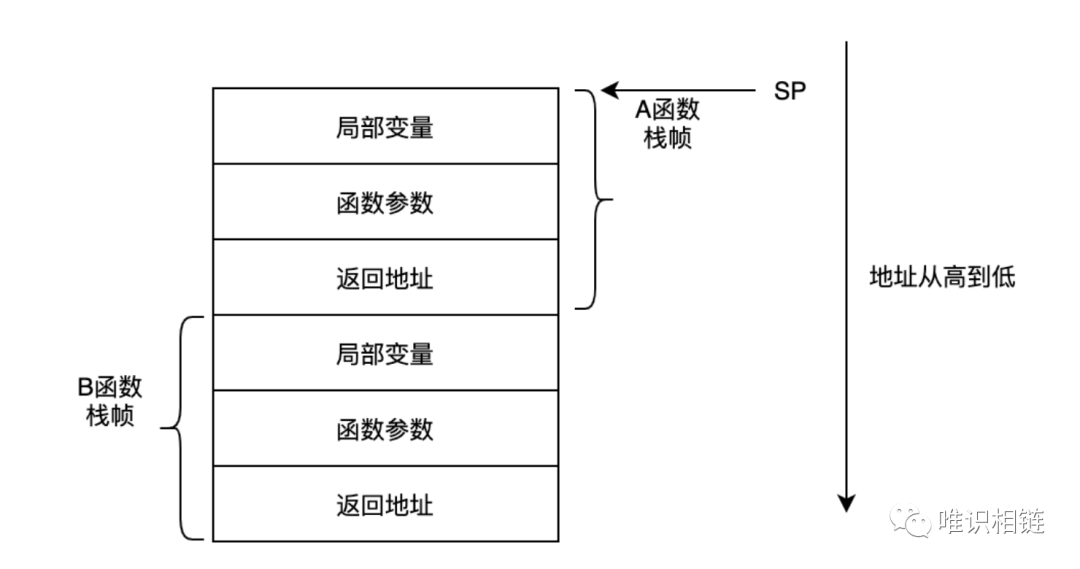
每一个函数在执行过程中都使用一块栈内存用来保存返回地址、局部变量、函数参数等,我们将这一块区域称为某函数的栈帧(stack frame)。
当发生函数调用时,因为调用者还没有执行完,其栈内存中保存的数据还有用,所以被调用函数不能覆盖调用者的栈帧,只能把被调用函数的栈帧压栈,等被调函数执行完成后再把其栈帧出栈。这样,栈的大小就会随函数调用层级的增加而生长,随函数的返回而缩小,也就是说函数调用层级越深,消耗的栈空间就越大。
因为数据是以先进先出的方式添加和删除的,所以基于堆栈的内存分配非常简单,并且通常比基于堆的动态内存分配内存快得多。另外,当函数退出时,堆栈上的内存会自动高效地回收,这是垃圾回收一种最初的形式。虽然维护和管理函数的栈帧非常重要,但是通常对于高级编程语言来说是隐藏的。例如Go语言中借助于编译器,在开发中不用关心局部变量在栈中的布局与释放。许多计算机指令集在硬件级别提供了用于管理栈的特殊指令,例如80x86指令集提供的SP寄存器用于管理栈,
以A函数调用B函数为例,抽象的函数栈的结构如下所示。
Go语言中实际的栈帧布局如下所示(源代码中的注释):
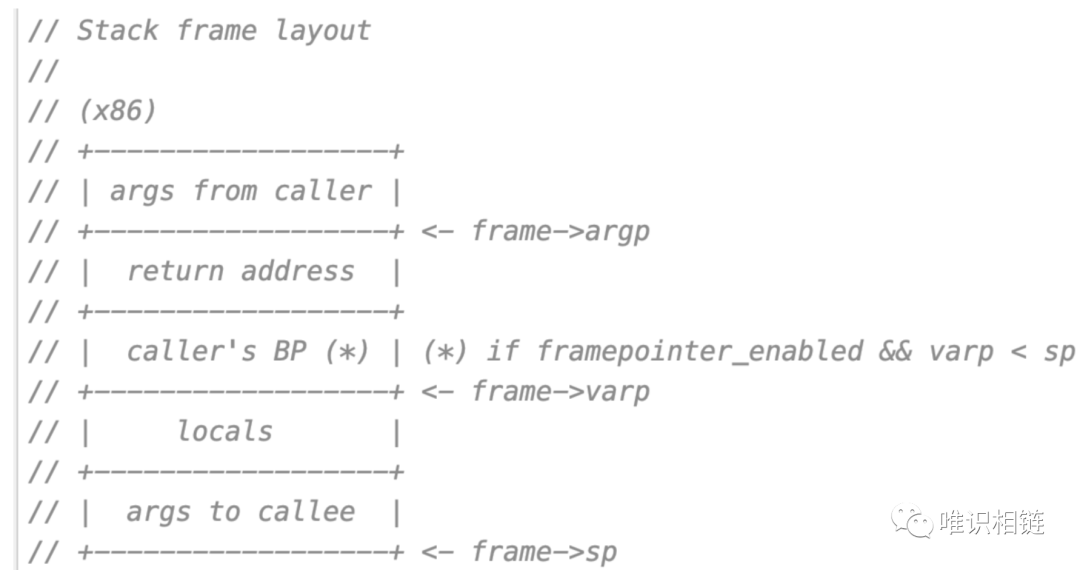
运行时可以计算出当前栈帧的函数参数、函数本地变量、寄存器信息SP、BP等一系列信息。
对每一个栈帧函数中的参数和局部变量,都需要对其进行扫描,扫描该对象是否仍然在使用。如果在使用,需要扫描bytedata位图判断对象中是否包含指针,如果包含指针则需要进行标记。其中函数执行到某一位置时,与某个参数和局部变量对应的位图bytedata是借助于编译时计算出来的。
func scanframeworker(frame *stkframe, state *stackScanState, gcw *gcWork) {
// 扫描局部变量
if locals.n > 0 {
size := uintptr(locals.n) * sys.PtrSize
scanblock(frame.varp-size, size, locals.bytedata, gcw, state)
}
// 扫描函数参数
if args.n > 0 {
scanblock(frame.argp, uintptr(args.n)*sys.PtrSize, args.bytedata, gcw, state)
}
}什么情况下对象可能没有在使用了呢?例如如下所示,当foo()函数执行到调用bar() 函数时,局部对象t就已经没有被使用了,所以即便对象t中有指针,位图bytedata中全为0,代表参数不再被使用。一个不再被使用的对象,可以被回收,不需要再进行扫描。
func foo(){
t := T{}
t.a = 2
bar()
}栈对象(stack object)
在Go语言早期就是通过上述方式对协程栈中的对象进行扫描的。但是这种方法在有些情况下会出现问题,例如在如下函数中, 对象t首先被p所引用,但是在之后的程序中,变量p的值发生了变化,这意味着,t其实并没有使用了。但是编译器由于难以知道P在何时会重新赋值导致t不再被引用,因此,编译器会采取保守的策略认为t对象仍然存在,从而,如果对象t中有指针指向了堆内存,就造成了内存泄露问题。因为这部分内存本应该被释放。
t := T{...}
p := &t
for {
if … {
p = …
}
}为了解决内存泄露的问题,Go语言引进了 栈对象(stack object) 的概念。栈对象是在栈上能够被寻址的对象。例如上例中的t,由于其能够被&t的形式寻址,其一定在栈上有地址。所以t就被叫做 栈对象。因为并不是所有的变量都会存储在栈上,例如存储在寄存器中的变量就是不能被寻址的。
首先,编译器会在编译时将所有的栈对象记录下来,在垃圾回收期间,所有的栈对象会存储到一颗二叉搜索树中。接着,第二步将栈中所有可能指向栈对象的指针都进行追踪。
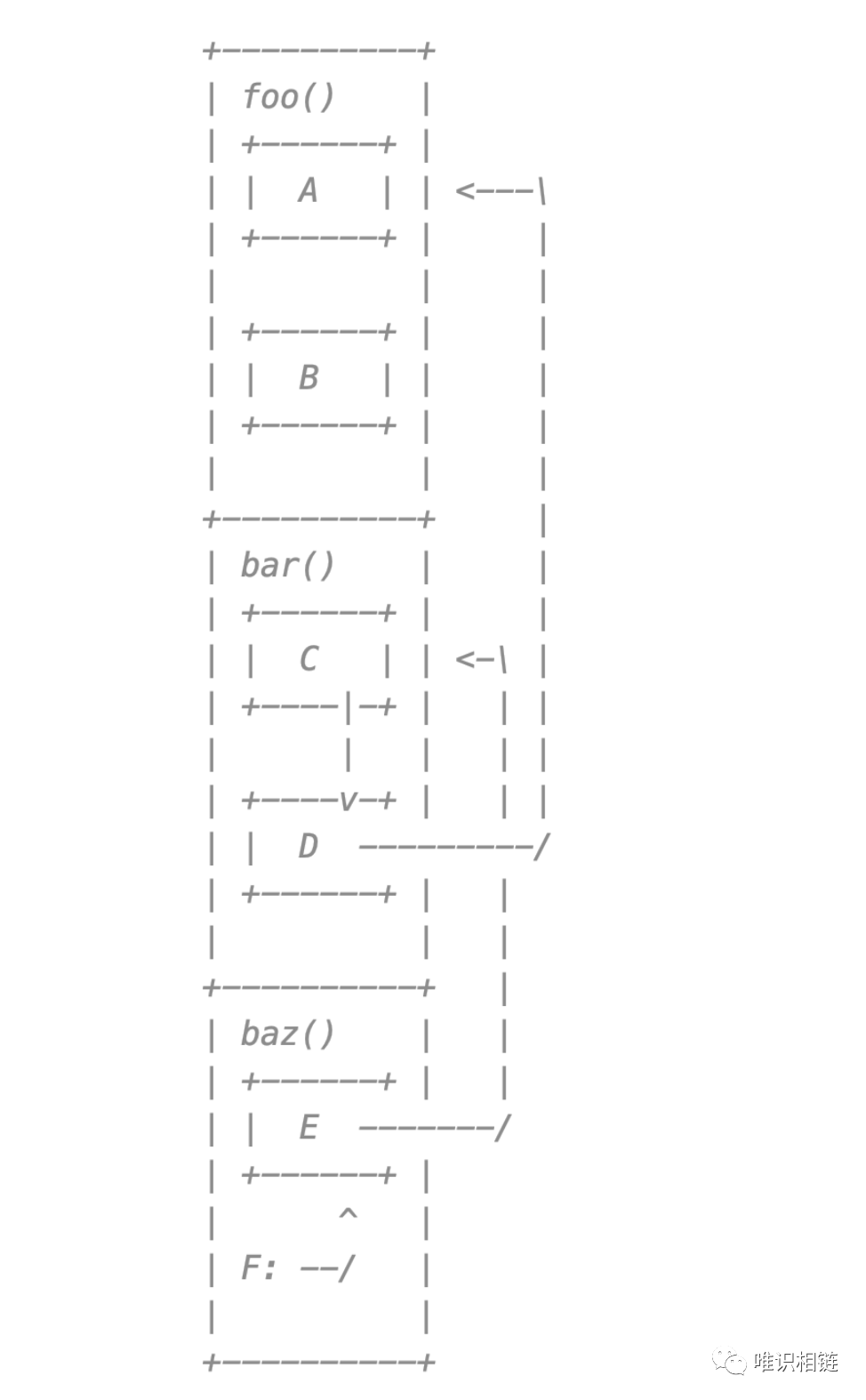
如下所示,假设F为一个局部变量指针,其引用了栈帧上的栈对象E→C→D→A, 因此说明栈对象E、C、D、A都是存活的,需要被扫描。 相反如果栈对象B没有被扫描,并且接下来在foo()函数中没有使用到B对象,那么B栈对象不会被扫描,从而解决了内存泄露问题。