Go内存管理三部曲[1]- 内存分配
点评
细微的对象切割
极致的多级缓存
精准的位图管理
这是Go内存分配
各位看官,你希望从这篇文章中得到什么?
阅读的前置知识
什么是内存、虚拟内存、常见的分配算法、内存分配的目标、TCmalloc
Go语言内存分配全局视野
span与元素
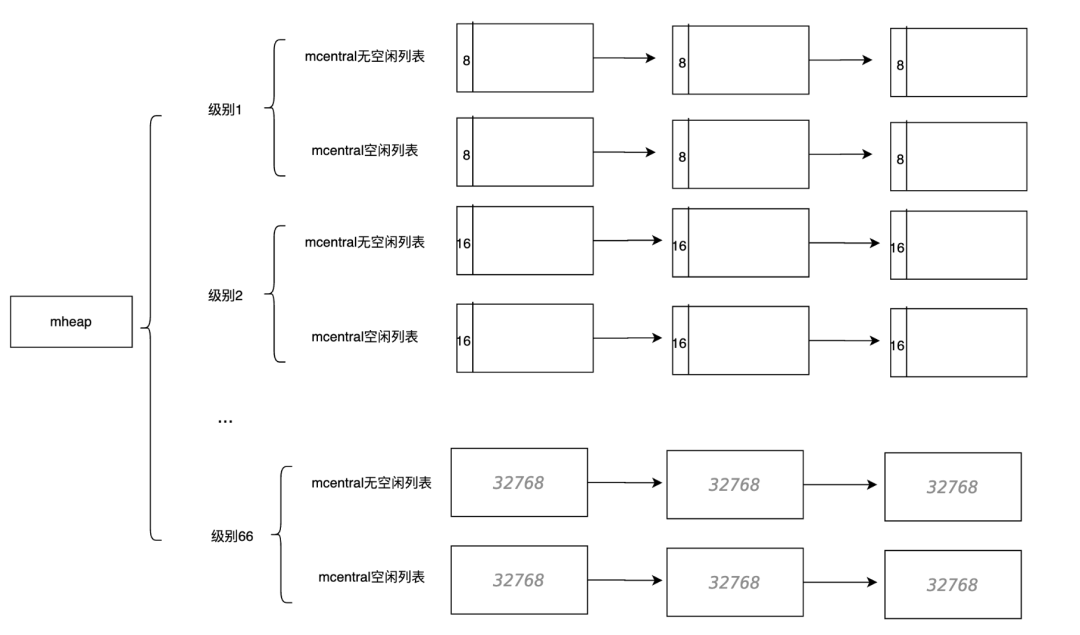
Go语言将内存分成了大大小小67个级别的span,其中0级代表特殊的大对象,其大小是不固定的。当具体的对象需要分配内存时,并不是直接分配span,而是分配不同级别的span中的元素。因此span的级别也不是以每个span大小为依据,而是以span中元素的大小为依据。
span等级 元素大小 span大小 对象个数
1 8 8192 1024
2 16 8192 512
3 32 8192 256
4 48 8192 170
5 64 8192 128
...
65 28672 57344 2
66 32768 32768 1如上所示,第一级元素大小为8字节,span的大小为8192字节,因此第一级中每一个span拥有8192/8 = 1024个。每一个span的大小和span中元素的个数都不是固定的,例如span 65 级别的span大小为57344字节,每一个对象为28672字节,元素个数为2个。Span大小虽然不固定,但其是8K或更大的连续内存区域。

运行时,每一个具体的对象在分配的时候,都需要对齐到指定的大小,例如分配17字节的对象,最终会对应到分配比17字节大并最接近它的元素级别,即等级为3的级别32字节。因此,这种分配方式不可避免的会带来内存的浪费。
三级对象管理
为了能够方便的对span进行管理、加速span对象的访问和分配。Go语言采取了三级管理结构,分别为:mcache、mcentral、mheap。
Go 像 TCMalloc 一样为每一个逻辑处理器P 提供一个本地span缓存称作 mcache。如果 协程 需要内存可以直接从 mcache 中获取,由于在同一时间只有一个 协程运行在 逻辑处理器P上,所以中间不需要任何锁的参与。mcache 包含所有大小规格的 mspan 作为缓存,但是每种规格大小只包含一个。除class0外,mcache的span都来自于mcentral中。
-
mcentral是被所有逻辑处理器P共享的
-
mcentral 对象收集所有给定规格大小的 span。每一个 mcentral 都包含两个 mspan 的链表:
做这种区主要是为了更快的分配span到mcache中。
除了级别0,每一个级别都会有一个mcentral,管理span列表。
-
nonempty mspanList -- 有空闲对象的 span链表
-
empty mspanList -- 没有空闲对象或 span 已经被 mcache 缓存的 span 链表
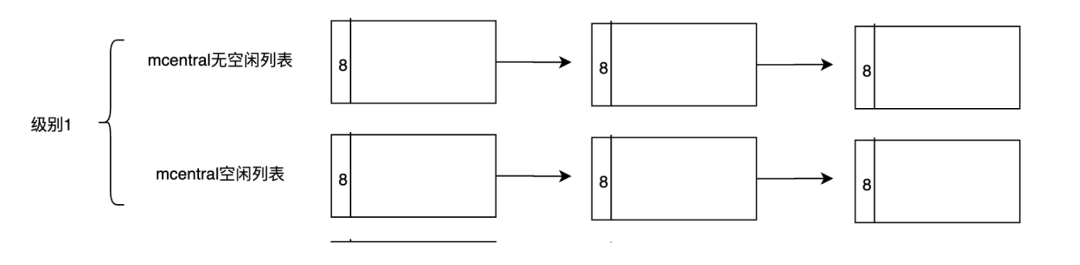
而所有级别的这些mcentral,其实是一个数组,由 mheap进行管理。
central [numSpanClasses]struct {
mcentral mcentral
pad [cpu.CacheLinePadSize - unsafe.Sizeof(mcentral{})%cpu.CacheLinePadSize]byte
}
mheap的作用不只是管理central,另外大对象也会直接通过mheap进行分配。mheap实现了对于虚拟内存线性地址空间的精准管理,建立了span与具体线性地址空间的联系,保存了分配的位图信息,是管理内存的最核心单元。后面我们还会看到,堆区的内存还被分成了HeapArea大小进行管理。对heap进行的操作必须得全局加锁,而不管是mcache、mcentral都只能看做是某种形式的缓存。
四级内存块管理
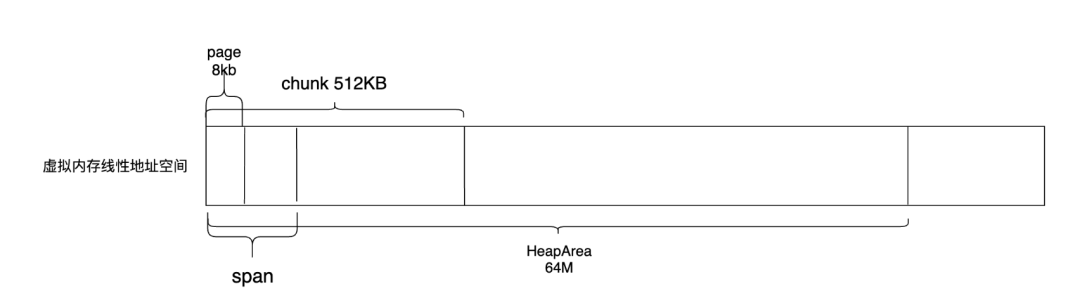
根据对象的大小,Go语言将堆内存中的块分成了HeapArea、chunk、span与page 4种进行管理。其中HeapArea最大,是平台相关的,在uinx 64位系统中占据64M,chunk占据了512KB,span根据级别大小的不同而不同,但是是page的倍数。而一个page占据了8KB。不同的内存块主要用于不同的场景当中,用于高效地对内存进行管理,后面还会详细介绍。
对象分配
正如前面介绍的,根据对象的不同大小会分配到不同的span中去,在这一小节中,将具体看一看其分配细节。在运行时分配对象的逻辑主要位于mallocgc函数中,这个名字很有意思,malloc代表了分配,gc代表了垃圾回收。意味着此函数还会为了gc做一些位图标记工作。在本小节中,主要关注于内存的分配。
func mallocgc(size uintptr, typ *_type, needzero bool) unsafe.Pointer {
// 判断是否小对象, maxSmallSize当前的值是32K
if size <= maxSmallSize {
if noscan && size < maxTinySize {
// 微对象分配
} else {
// 小对象分配
}else{
// 大对象分配
}}按照对象的大小划分,分为了tiny微小对象、小对象、以及大对象。tiny微小对象是可能的分配流程最长,逻辑链路最复杂的对象分配。并且在介绍tiny微小对象的分配时,其实就已经将小对象、大对象的分配流程介绍了,因此,下一小节,将重点介绍tiny微小对象,并对比介绍几种不同大小对象在分配上的不同。
tiny微小对象
对于小于16字节的对象,Go语言将其划分为了tiny对象。划分tiny对象的主要目的是为了处理极小的字符串和独立的转义变量。对json的基准测试表明,使用tiny对象减少了12%的分配次数和20%的堆大小[1]
tiny对象会被放入class为2的span中,由上例中知道,class为2的span元素大小为16字节。首先对tiny对象按照2、4、8进行字节对齐。例如字节为1的元素会分配2个字节,字节为7的元素会分配8个字节。
if size&7 == 0 {
off = alignUp(off, 8)
} else if size&3 == 0 {
off = alignUp(off, 4)
} else if size&1 == 0 {
off = alignUp(off, 2)
}首先查看之前分配的元素中是否有空余的空间。如下所示,如果当前对象要分配8个字节,并且当正在分配的元素可以容纳大小为8,则返回tiny+ooffset的地址,意味着当前的地址往后8个字节都是可以被分配的。
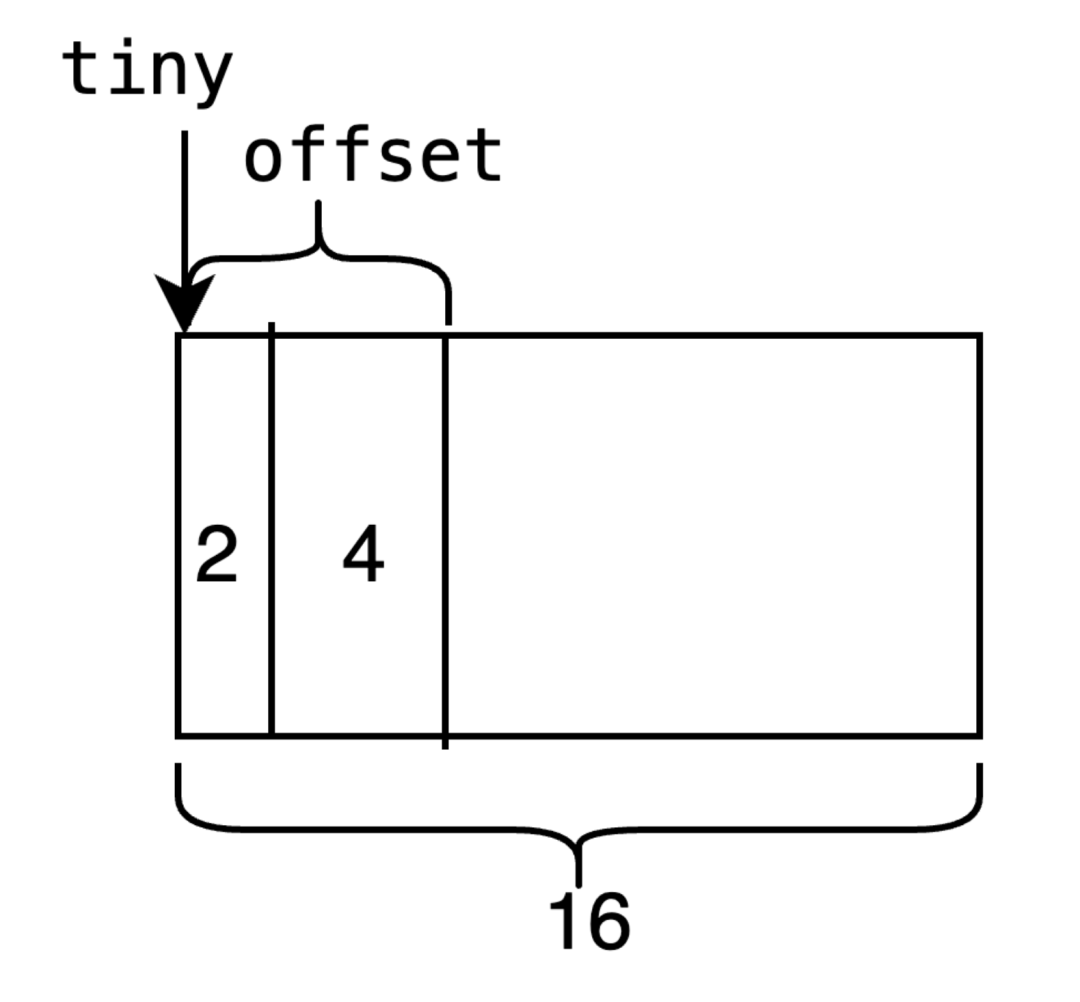
并且现在offset的位置也进行了偏移,为了下一次分配做准备。

如果当前要分配的大小不够,例如要分配16字节的大小,这时就需要找到下一个空闲的元素。因此,tiny分配的第一步是尝试利用分配过的前一个元素的空间,达到节约内存的目的。
off := c.tinyoffset
if off+size <= maxTinySize && c.tiny != 0 {
x = unsafe.Pointer(c.tiny + off)
c.tinyoffset = off + size
return x
}当前一个元素中没有空间时,第二步将尝试从mcache中查找元素。
mcache缓存位图
首先需要从mcache 中找到对应级别的mspan,mspan中拥有allocCache字段,其作为一个位图,用于标记span元素中的大小。由于allocCache元素为uint64大小,因此其最多一次缓存64位的大小。
func nextFreeFast(s *mspan) gclinkptr {
theBit := sys.Ctz64(s.allocCache)
if theBit < 64 {
result := s.freeindex + uintptr(theBit)
if result < s.nelems {
freeidx := result + 1
if freeidx%64 == 0 && freeidx != s.nelems {
return 0
}
s.allocCache >>= uint(theBit + 1)
s.freeindex = freeidx
s.allocCount++
return gclinkptr(result*s.elemsize + s.base())
}
}
return 0
}allocCache使用从后往前的方式与span中元素对应起来。例如allocCache中最后一个bit位对应的是span元素中最前的一个元素。
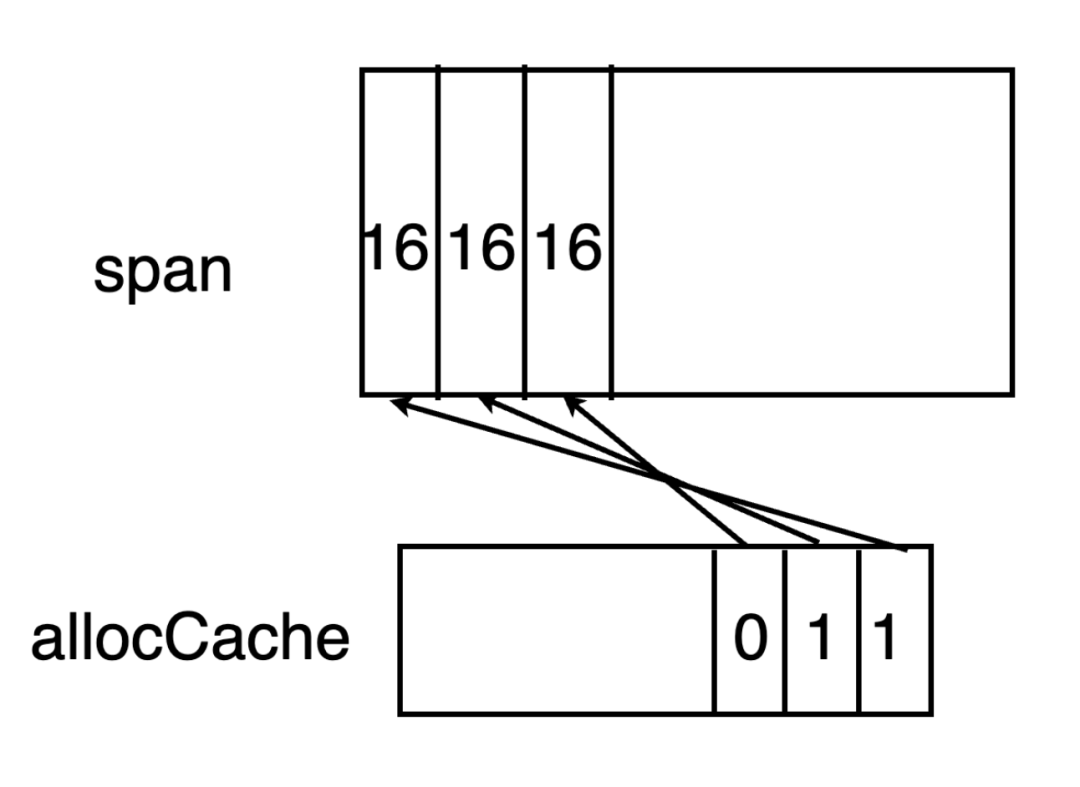
有时候,span中元素的个数大于64个,因此需要专门有一个字段freeindex来标识当前span中元素分配到了哪里。在span中小于freeindex序号的元素意味着都已经分配了,将从freeindex开始继续分配。
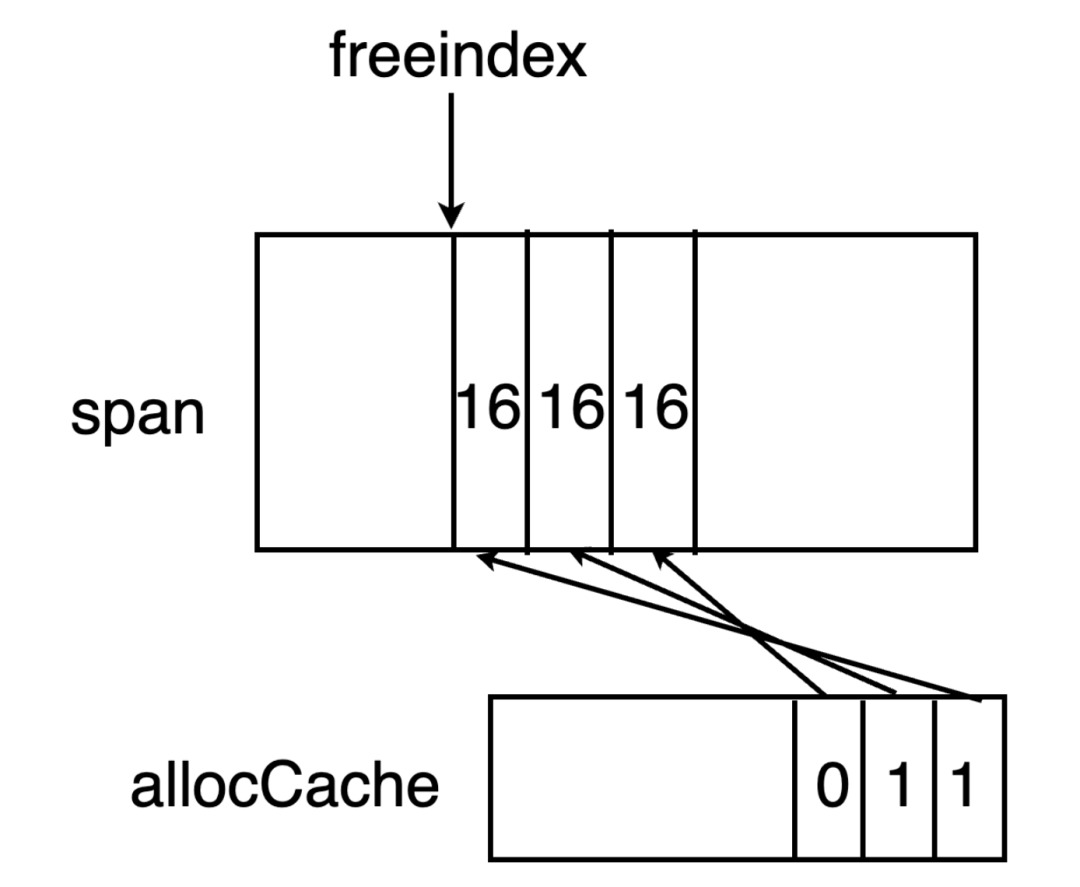
因此,只要从acclocCache开始找到哪一位为0即可。假如找到了X位为0,那么X + freeindex 为当前span中可用的元素序号。当allocCache中全部都已经标记为1后,就需要移动freeindex ,并更新allocCache。一直到达span元素末尾为止。
mcentral遍历可用span
如果当前的span中并没有可以使用的元素,这时就需要从mcentral中加锁查找。
之前介绍过,在mcentral中有两种类型的span链表,分别是有空闲元素的nonempty,以及没有空闲元素的empty链表。会分别遍历这两个列表,查找是否有可用的span。有些读者可能会有疑问,既然是没有空闲元素的empty列表,怎么还需要去遍历呢?这是由于有些span可能已经被垃圾回收器标记为空闲了,只是还没有来得及清理。这些Span在清扫后仍然是可以使用的,因此需要遍历。
func (c *mcentral) cacheSpan() *mspan {
var s *mspan
for s = c.nonempty.first; s != nil; s = s.next {
c.nonempty.remove(s)
c.empty.insertBack(s)
unlock(&c.lock)
goto havespan
}
//
for s = c.empty.first; s != nil; s = s.next {
...
}如果在mcentral元素中查找到有空闲元素的span,则将其赋值到mcache中,并更新allocCache,同时还需要将span添加到mcentral的empty链表中去。
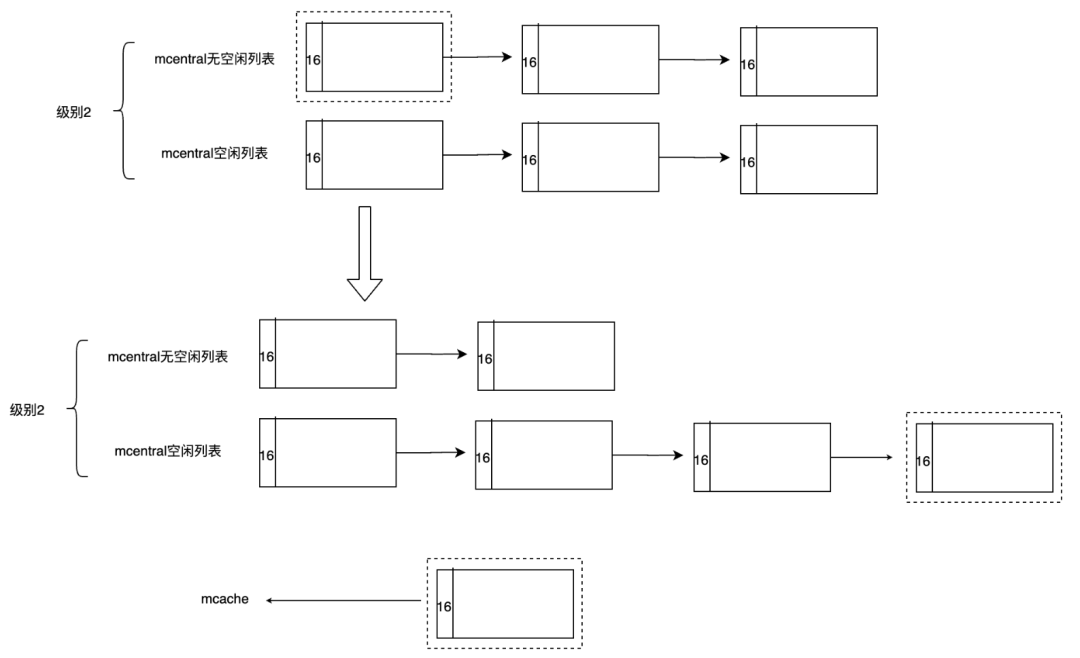
mheap缓存查找
当在mcentral中找不到可以使用的span后,就需要从mheap中查找。在Go1.12的时候,Go语言采用了Treap 进行内存的管理,Treap 是一种引入了随机数的二叉树搜索树,其实现简单,并且引入的随机数以及必要时的旋转保证了比较好的平衡特性。Michael Knyszek 提出[2]这种方式具有扩展性的问题,由于这棵树是mheap管理,当操作此二叉树的时候都需要维持一个lock。这在密集的对象分配以及逻辑处理器P过多的时候,会导致更长的等待时间。Michael Knyszek 提出用bitmap来管理内存页,并在每个P中维护一份page cache。这就是现在Go语言实现的方式。因此在go1.14之后,我们会看到在每个逻辑处理器P内部都有一个cache。
type pageCache struct {
base uintptr
cache uint64
scav uint64
}mheap会首先查找在每个逻辑处理器P中pageCache字段的cache。cache也是一个位图,其每一位都代表了一个page(8 KB) 因此,由于cache为uint64类型,其一共可以存储64*8=512KB的缓存。这512KB是连续的虚拟内存。在cache中,1代表未分配的内存,而0代表已分配的内存。base代表该虚拟内存的基地址。当需要分配的页数小于 512/4=128KB时,需要首先从cache中分配。
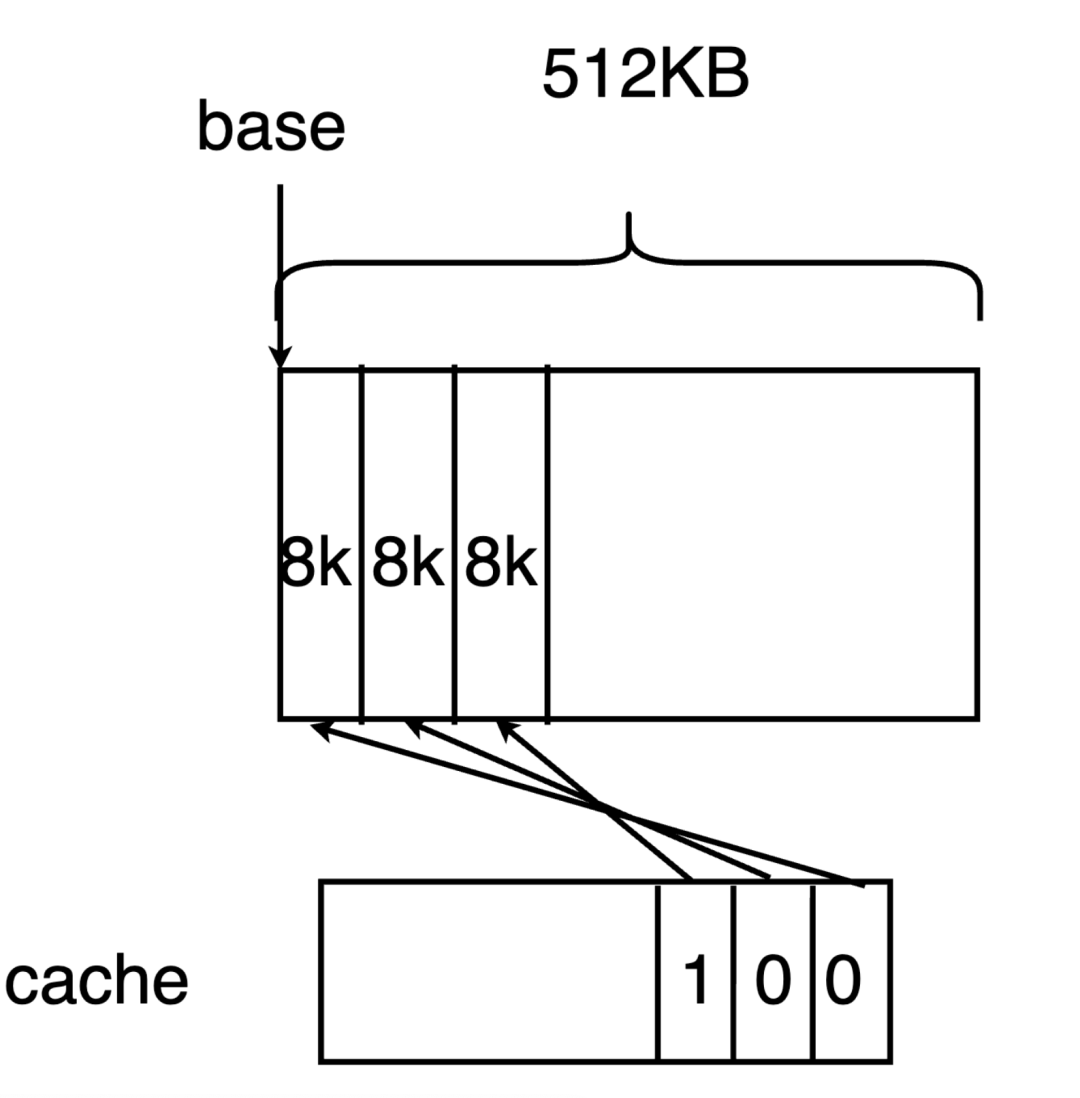
例如,假如要分配n pages,就需要查找cache中是否有连续n个1位。如果存在,则说明在缓存中查找到了合适的内存,用于初始化span。
mheap基数树查找
当要分配的page过大或者在逻辑处理器P的cache中没有找到可用的页数时,就需要对mheap加锁,并在整个mheap管理的虚拟地址空间的位图中查找是否有可用的pages。而且其在本质上涉及到Go语言是如何对线性的地址空间进行位图管理的。
管理线性的地址空间的位图结构叫做基数树(radix tree), 他和一般的基数树结构有点不太一样,这个名字很大一部分是由于父节点包含了子节点的若干信息。
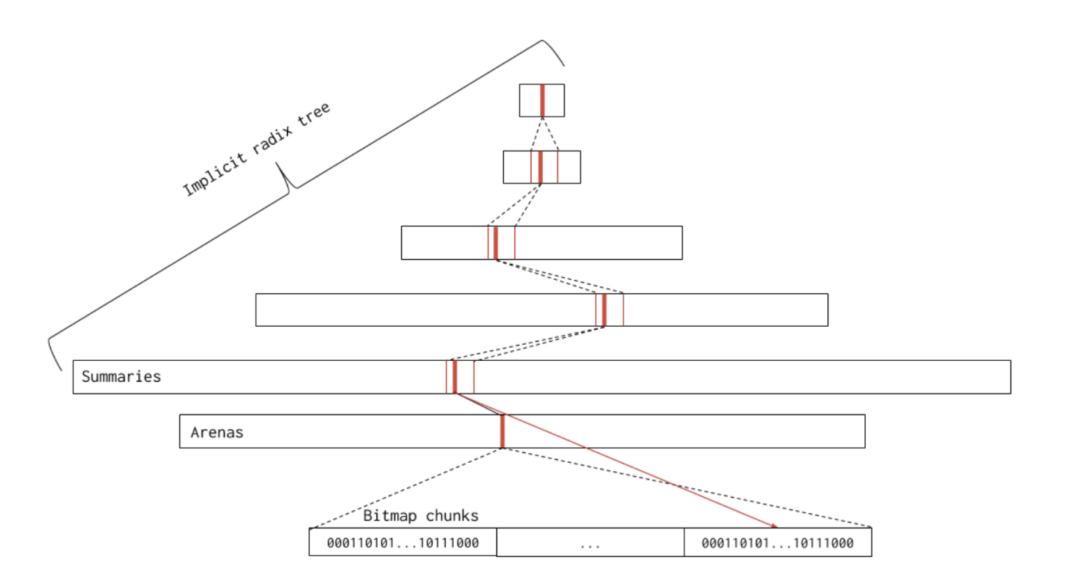
在该树中的每一个节点对应一个pallocSum结构。其中最底层的叶子节点对应的一个pallocSum结构包含了一个chunk的信息(512 * 8 KB),而除了叶子节点外的节点都包含了连续8个子节点的内存信息。例如,倒数第二层的节点包含了8个叶子节点(即8*chunk)的连续内存信息。因此,越上层的节点,其对应的内存就越多。
type pallocSum uint64
func (p pallocSum) start() uint {
return uint(uint64(p) & (maxPackedValue - 1))
}
// max extracts the max value from a packed sum.
func (p pallocSum) max() uint {
return uint((uint64(p) >> logMaxPackedValue) & (maxPackedValue - 1))
}
// end extracts the end value from a packed sum.
func (p pallocSum) end() uint {
return uint((uint64(p) >> (2 * logMaxPackedValue)) & (maxPackedValue - 1))
}pallocSum虽然是一个简单的uint64类型,但是分成了开头、中间、末尾3个部分,开头语末尾部分占据了21bit,中间部分占据了22bit。它们分别包含了在这个区域中连续空闲内存页的信息。包括了在开头有多少连续内存页,最大有多少连续内存页,在末尾有多少连续内存页。对于最顶层的节点,由于其中间的max位为22bit,因此一颗完整的基数树最多代表2^21 pages=16G内存。
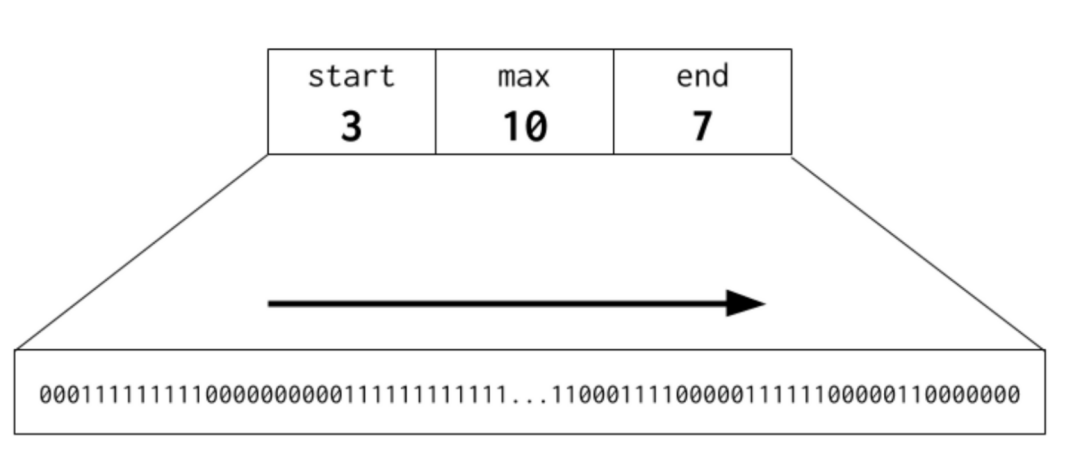
Go语言并不是一开始就直接从根节点往下查找的,而是首先做了一定的优化,类似于又一级别的缓存。在Go语言中,存储了一个特别的字段searchAddr,看名字就可以猜想到是用于搜索可用内存时使用的。searchAddr有一个重要的设定是在searchAddr地址之前一定是已经分配过的。因此在查找时,只需要往searchAddr地址的后方查找即可跳过查找的节点,减少查找的时间。
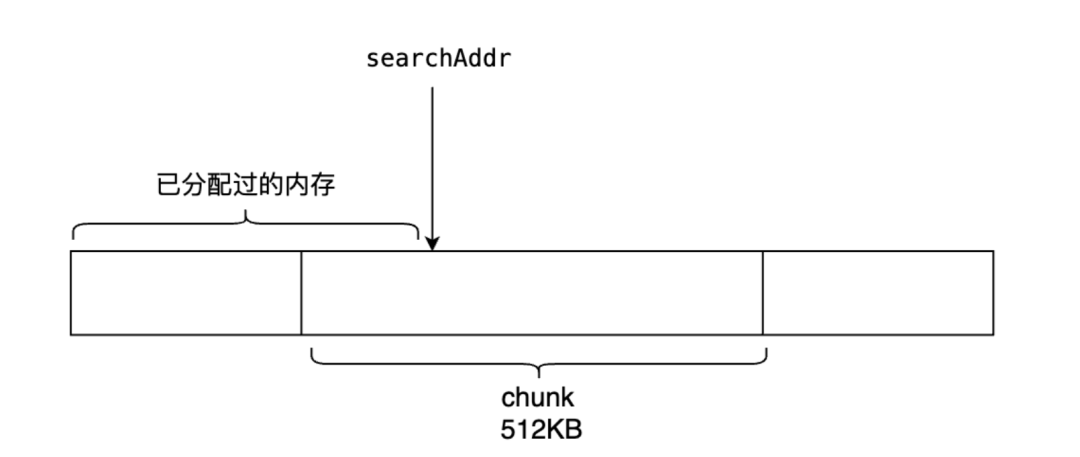
在第一次查找时,会首先从当前searchAddr的chunk块中查找是否有对应大小的连续空间。这种优化主要是针对比较小的内存分配(至少小于512KB)时使用的。Go语言对于内存有非常精细化的管理,chunk块的每一个page(8 KB)都有位图表明其是否已经被分配。
每一个chunk都有一个pallocData结构,其中pallocBits管理其分配的位图。pallocBits是一个uint64的大小为8的数组。由于每一位对应着一个page,因此pallocBits总共对应着64*8=512KB,恰好是一个chunk块的大小。位图的对应方式和之前是一样的。
type pallocData struct {
pallocBits
scavenged pageBits
}
type pallocBits [8]uint64而所有的chunk pallocData都在pageAlloc结构中进行管理。
type pageAlloc struct {
chunks [1 << pallocChunksL1Bits]*[1 << pallocChunksL2Bits]pallocData
}当所有的内存分配过大或者当前chunk块没有连续的npages空间时,就需要到基数树中从上到下进行查找。基数树有一个特性,即当要分配的内存越大时,它能够越快的查找到当前的基数树中是否有连续的空间能够满足。
在查找基数树的过程中,从上到下,从左到右的查找每一个节点是否符合要求。首先计算
pallocSum字段的开头start有多少连续的内存空间。如果start大于npages,说明我们已经查找到了可用的空间和地址。没有找到时,会计算pallocSum字段的max,即中间有多少连续的内存空间。如果max大于npages,我们需要继续往基数树当前节点对应的下一级继续查找。原因在于,max大于npages,表明当前一定有连续的空间满足npages,但是我们并不知道具体在哪一个位置,必须要继续往下一级查找时才能找到具体可用的地址。如果max也不满足,是不是就不满足了呢?不一定,因为有可能两个节点可以合并起来组成一个更大的连续空间。因此还需要将当前pallocSum计算的end与后一个节点的start加起来查看是否能够组合成大于npages的连续空间。

每一次从基数树中查找到内存,或者事后从操作系统分配内存的时候,都需要更新基数树中每一个节点的pallocSum。
操作系统分配
当在基数树都查找不到可用的连续内存时,就需要从操作系统中索取内存。
从操作系统获取内存的代码是平台独立的,例如在unix系统中,最终使用了mmap系统调用向操作系统申请内存。
func sysReserve(v unsafe.Pointer, n uintptr) unsafe.Pointer {
p, err := mmap(v, n, _PROT_NONE, _MAP_ANON|_MAP_PRIVATE, -1, 0)
if err != 0 {
return nil
}
return p
}每一次向操作系统申请内存时,Go语言规定必须为heapArena 大小的倍数。heapArena是和平台有关的内存大小,在unix 64位系统中,其大小为64M。这意味着即便需要的内存大小很少,最终也至少向操作系统申请64M。多申请的内存可以用于下次分配使用。
Go语言中对于heapArena有精准的管理,精准到每一个指针大小的内存信息,每一个page对应的mspan信息都有记录。
type heapArena struct {
// heapArena中bitmap用每2个bit记录一个指针大小(8byte)的内存信息,主要用于gc
bitmap [heapArenaBitmapBytes]byte
// spans 將 page ID 對應到 arena 裡的 mspan
spans [pagesPerArena]*mspan
...
}小对象的分配
当对象不属于tiny对象时,会判断对象是否为小对象。小对象是小于32KB的对象。Go语言会计算小对象对应于哪一个等级的span,并在指定等级的span的进行查找。
此后和tiny微小对象的分配一样,经历 mcache → mcentral → mheap位图查找 → mheap基数树查找→操作系统分配 的过程。(具体过程见上)
大对象分配
大对象是大小大于32KB的内存,不与 mcache 和 mcentral 沟通,并直接通过 mheap 进行分配。经历mheap基数树查找→操作系统分配 的过程。每一个大对象是一个特殊的span, 它的class是0。(具体过程见上)
各位看官,下一篇文章再见
see you~