节约千台容器,Go程序性能瓶颈实战分析
净是拿比自己弱的人当对手,不可能有意思。没有人能一看到谜题就瞬间解出答案。读到一半就知道犯人的推理小说真是无聊透顶。将自身能力发挥至极限去解开问题,这时才能把知识变成自己的东西。 —青木峰郎《Ruby 源代码完全解读》
当我们对Go程序进行性能分析时,一般想到的方式是Pprof提供的一系列工具分析CPU火焰图、内存占用。
诚然,通过分析cpu耗时最多的流程,并设法对cpu耗时最多的函数进行优化,毫无疑问能够改善程序整体的状况。然而,优化了这些步骤就一定能够大幅度降低容器配置和机器数量吗,一定能够大幅度提高性能吗?答案是不确定的。一个函数在pprof中耗时多可能是因为他本身耗时就多,他是现象却不一定是问题。同时,在高负载情况下可能会导致某一些请求,某一些函数耗时突然升高。但是这种升高不一定能够体现在pprof上。因为pprof能看到整体的耗时情况,却无法分析个例。因此我们需要跳出pprof cpu profiling,仔细审视程序遇到的最严重的性能瓶颈。
在本文中,将回顾笔者对于线上Go web程序面临的性能瓶颈进行分析的过程,这一瓶颈分析的结果最终将导致线上节约上千台容器。本文中使用的工具和方法可以对排查其他瓶颈问题起到启发的作用。
愿望
程序的核心目标是能够在更短的时间并行处理更多的请求,需要保证正常情况下在500ms以下的耗时保证
压测手段
调整机器权重,对于单台容器进行压测
现状?
通过压测分析,得到的现状是:
-
正常情况下服务 ~3qps 。压测时候(通过调整权重)到达 ~16qps 以上时,可见耗时p99(百分之1的请求高于该阈值)抖动, 而p95保持稳定。正常p99 300ms+,压测时 部分容器p99 可见700ms+
-
cpu idle 80%以上
-
内存容量充足。
-
相同的请求再次调用时,走相同的代码路径,但是耗时能够恢复正常。这种耗时差距可达300ms以上。
-
下游调用的耗时p99可见保持稳定,可以一定程度排除是网络耗时导致的
-
当容器飘逸到性能更强的宿主机之后,耗时能够得到显著缓解
因此我们主要面对的问题是耗时p99抖动的问题。接下来笔者从多个成面对此问题进行了分析。
请求
耗时上涨可能是因为http请求排队导致的吗?http keep-alive 时第二个请求会等待第一个请求的情况,但是这种假设不成立
连接总是在不断变化,没有复用长连接:
netstat -antp |grep xxx | grep ES
并且打印请求耗时的时间是从接收到请求的时间开始计时的。
时间
新部署的容器,问题仍然复现。
程序处理模型
Go语言在处理网络方面拥有优良的特性,当前程序的时间消耗可分为磁盘io与程序自身的cpu消耗。
对于网络io、go语言拥有足够优秀的网络模型处理大量的网络请求,通过封装epoll,轻量且快速。异步,不会导致因为网络堵塞而导致排队的问题。同时通过对p99请求打印的耗时来看,网络耗时很正常,并没有堵塞。
对于磁盘io 和系统调用,确实有可能发生堵塞导致的排队问题,但是go语言sysmon 会在10ms监控这种情况并适时的创建新的线程。
再加上go调度器的均衡工作,从理论上来讲,程序的理想运行状态应该是随着负载的增加,耗时稳定的上升,而不是突然出现的毛刺。
Go运行时
qps很低,本身来讲由于任务数增加,导致Go运行时调度器某一个协程长期得不到执行的问题,这种可能性很低。8个P(GoMaxProcs)足够承载当前低程度的qps。
进一步,分析调度器细节:
GOMAXPROCS=8 GODEBUG=schedtrace=1000,scheddetail=1 nohup ./main -config conf/conf.test.toml > runoob.log 2>&1 &瞬时1秒打印,发现基本没有在运行的协程队列,从这个程度上侧面反应了,这表明程序有极大提升qps的空间。这个现象也反应了为什么负载下cpu idle很高,因为程序没有满负载运行。
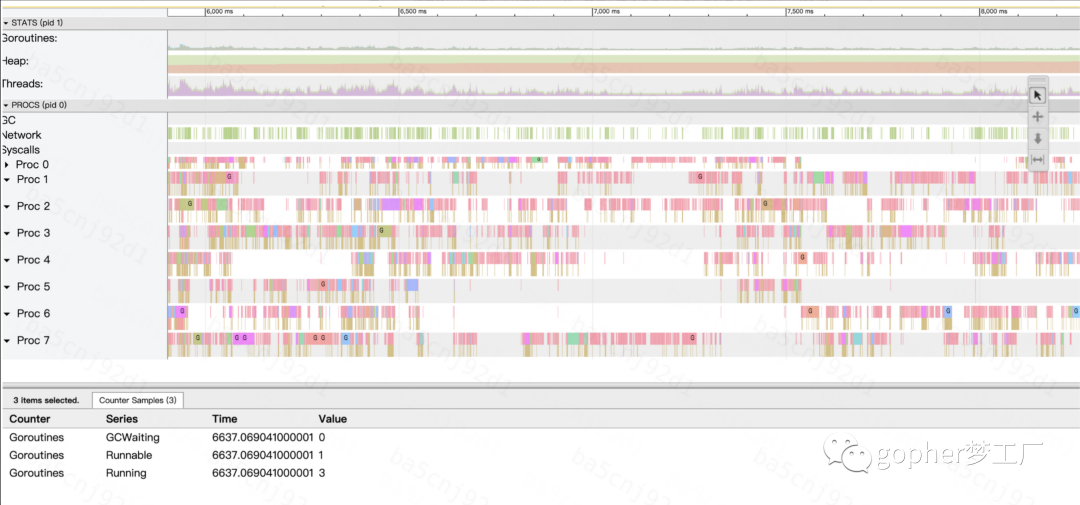
通过在后面的trace工具分析,更能够直观的分析出正常情况下程序明显负载不足的情况。可运行协程数量小于GOMAXPROCS并且P运行协程有大量的间隙。
内存分配
程序占用的内存约4G,随着时间稳定,cgroup可使用的容量大小有16G。 分析程序暴露的运行时内存分配metric,没有发现明显的异常。
垃圾回收
gc频率相对较高,几秒一次,但是初步分析不足以导致瓶颈。从程序暴露的运行时指标,GC程序生命周期内平均花费的CPU时间千分之2左右,以及最近一次STW时间(即不可用时间)小于1ms都表明了GC不是瓶颈
协程与线程数量
程序本身协程数量高120左右,但是大部分都是休眠状态。在负载情况下协程数量与请求数量大致相同,增加10多个,但不是瓶颈。
从线程数量上来看,线程数量大约14个左右。
cat /proc/`ps -ef | grep xxx | awk 'NR==1 {print $2}'`/status | grep Threads
在负载时并没有增加线程数量,由于go语言有系统监控10ms堵塞会新建线程去处理的机制,降低了系统调用堵塞的可能性。
pprof查看程序整体运行情况
压测时,查看pprof火焰图,和正常负载下的火焰图无明显变化。
并发导致的锁问题
从代码上来看,几乎未使用锁等同步机制。另一方面,即便是使用锁,在如此低的负载情况下到达几百毫秒的延迟不太可能,更不提标准库中的锁耗时,都是上万qps才可能导致的瓶颈。通过查看pprof block 未发现有瓶颈问题。
go tool pprof http://localhost:9981/debug/pprof/block
go tool pprof http://localhost:9981/debug/pprof/mutex同步写日志的磁盘问题
-
磁盘容量正常
-
磁盘利用率正常
-
inode利用率正常
-
iops正常
-
磁盘输入/输出操作时间占比
宿主机排查
不是并发的锁问题,也不是任务队列太多的调度器问题,不是gc问题,也不是操作系统调用导致的堵塞的问题,那么到底是什么原因呢?结合着之前飘逸到宿主机情况会好转的规律,我将目光转到了宿主机的体质上。分析了如下几个方面的问题:
-
宿主机cpu idle正常
-
cpu外部争抢cpu.exter_wait_rate正常,这个指标主要用来衡量任务在线程队列中是否等待处理其他容器的任务的时间过长。
-
cgroup cpu与内存设置正常
-
查看容器cpu.throttled 次数和throttled_time, 在正常情况下和压测时都会存在, 本身这个指标可以衡量容器的资源由于利用太狠到达了分配的资源限制被抢占,从而导致的耗时增加。 压测时这个次数没有明显的飙升,不足以支持耗时能够增加到300毫秒。
-
查看一段时间内操作系统线程堆栈,程序并没有耗在操作系统调用上,而是用户态上。同时查看操作系统线程的等待队列,外部程序的抢占看起来也不明显。
总之,从现象上看和宿主机有关系,从当前信息的分析上无法得出明显的结论。
以退为进
由于Go程序协程的存在,并不太好直接查看耗时长的时刻在哪一个协程id和线程id上。
以退为进,从问题出发,直接在代码中关键位置打印出耗时,分析到底耗时高的程序到底是消耗在哪里。通过对日志的分析,发现,大部分时间都消耗在了XXX函数上,该函数由于本身耗时就很高,所以在pprof火焰图上看不出变化。XXX函数的特点是频繁的内存分配,比如1000次内存分配。但是打印每一次内存分配的时间,都不足1ms,累积起来仍然恐怖。也就是说,内存分配没有明显的突然的恶化导致的卡点,而是均匀的上涨了,这确实比较奇怪,因为从Go运行时内存分配的模型来看,速度应该是是比较快的。
在深入到分析运行时内存分配的bug之前,我选择了使用更强大的工具trace分析程序在生命周期内的运行状态,并最终让我找到了答案。这种强大的分析借助于Go运行时在关键时刻进行的埋点。例如当进行协程切换时,记录下来一个事件,即可知道某一时刻线程对应的M从协程A切换到了协程B。

首先抓取压测情况下的trace,然后分析Goroutine analysis。Goroutine analysis是一个非常有用的工具,可以用来分析某一个协程的情况。
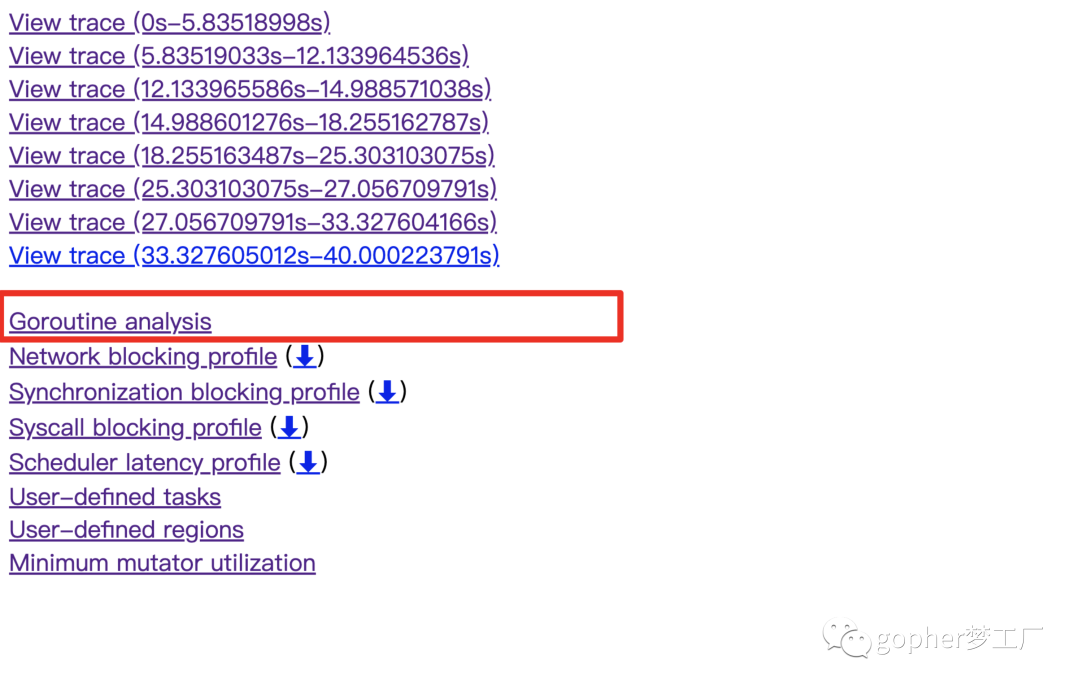
我们要做的是找到我们想要分析的那一个函数所对应的协程,如下所示,func6是xx函数的第6个协程,样本数有500多个。

接下来分析一下这些样本协程的耗时情况:
从图中可以看出,最大的一些协程函数耗时到达了300ms以上,这些协程会导致p99的飙升,和现象是对应的。同时这个工具可以为我们打印出协程的耗时花在了哪一个地方,从图中可以看出,协程的耗时主要花费在了EXecution执行阶段,比较奇怪的是,这些阶段大部分时间都处于GC中。

点击某一个协程的详细信息,可以看到协程在当前一段时间内的运行状态。
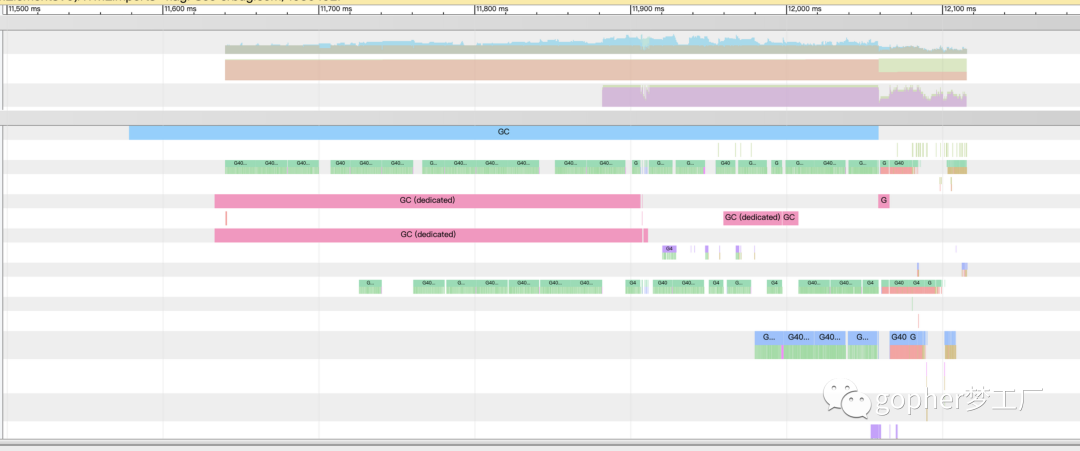
等等,这密密麻麻的绿色线条是怎么回事,放大以后特别吓人,大部分时间都在MARK ASSIST。

即在已经GC情况下,由于疯狂的内存分配导致的MARK ASSIST问题严重,这也解释了为什么负载上来了才会导致P99问题。
GC阶段下大量的内存分配导致大量的MARK ASSIST,在这一段时间内,加上25%的专有GC处理暂用了2个线程,程序运行状态恶化。

MARK ASSIST辅助标记解释
“Go 1.5 引入了并发标记后,带来了许多新的问题。例如,在并发标记阶段,扫描内存的同时用户协程也不断被分配内存,当用户协程的内存分配速度快到后台标记协程来不及扫描时,GC 标记阶段将永远不会结束,从而无法完成完整的GC 周期,造成内存泄漏。为了解决这样的问题,引入辅助标记算法。辅助标记必须在垃圾回收的标记阶段进行,由于用户协程被分配了超过限度的内存而不得不将其暂停并切换到辅助标记工作。” ———《Go语言底层原理剖析》
结论
这一线上瓶颈问题的本质是内存使用的不合理,当触发GC之后,在负载高的情况下,内存分配的速度超过了GC扫描的速度,从而一直在执行辅助标记,大大减慢了程序运行的速度。这会导致调度延迟等各方面情况发生恶化。通过优化代码逻辑和复用内存分配,消除瓶颈,节约线上千台容器。
反思
程序的运行状态就像是一个黑盒,不同的指标可以在侧面反应程序的运行状态,不同的工具可以反应相同的问题,在合适的时间使用合适的工具,将起到事半功倍的效果。
一个运行中的程序似乎总是缺乏“内省”的能力,这种能力借助于关键埋点和时间流的跟踪。本案例证明了trace工具在分析程序整体运行状态甚至是P99瓶颈问题时的强大,是性能分析甚至启发式探索问题的利器。
容器化之下,复杂问题的排查其实变得更加更困难了,很多时候我们面临的问题不只是语言成面的,而是所有程序都需要面对的问题。需要有体系化的思考和强大的学习能力