Go垃圾回收[10]-实战一例频繁GC的性能问题
横表示知识的宽度,竖是技术的深度,你可以自己选择发展宽度还是深度的。假如是宽度,你懂很多皮毛的东西,但不深,那么这颗钉子打在墙上,随便就可以拔下来被替换掉。但是假如你专业很深、技术上很扎实,就会越来越不可撼动。
弱小,就是我们最大的罪过。在本文中,笔者将实战分析一个由于垃圾回收造成程序效率损失的例子。在排查内存泄露的过程中,使用了trace工具(trace集成在了pprof http中,本文中不会介绍trace工具的使用方法)
在pprof的分析中,能够知道一段时间内的CPU占用、内存分配、协程堆栈信息。这些信息都是一段时间内数据的汇总,但是其并没有提供整个周期内发生的事件,例如指定的goroutines何时执行,执行了多长时间,什么时候陷入了堵塞,什么时候解除了堵塞,GC如何影响单个goroutine的执行,STW中断花费的时间是否太长等。这就是在Go1.5之后推出的trace工具的强大之处,其提供了指定时间内程序发生的事件的完整信息,这些事件信息包括:
-
协程的创建、开始和结束;
-
协程的堵塞——系统调用、通道、锁;
-
网络I / O相关事件;
-
系统调用事件;
-
垃圾回收相关事件。
分析开始,查看程序在某段时间内内存的增长情况。
curl -o trace.out http://ip:6060/debug/pprof/trace?seconds=30
go tool trace trace.out通过查看trace可视化结果,发现GC在30秒的时间内执行了43次,每次GC时间大约在1ms,这种频繁的垃圾回收会带来一定的性能损失。同时,查看堆内存的变化情况发现内存呈现锯齿状,表明在垃圾回收时释放了大量临时垃圾内存。
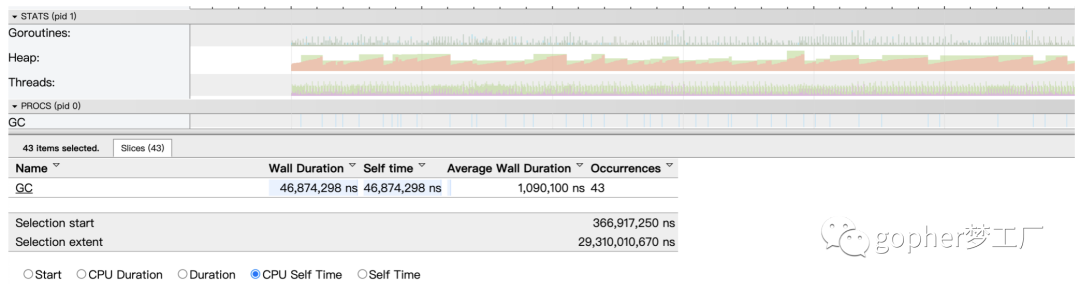
图1 trace工具发现GC频繁触发
为了探究为什么发生了如此频繁的垃圾回收,可以查看每一次GC发生时的堆栈信息,这仍然是依靠trace工具的强大功能。从概率的角度来讲,当我们在堆栈信息中查看到多次在相同的函数处触发了垃圾回收,那么该函数大概率是有问题的。如下所示,在堆栈信息中查看到saveFaceToRedis函数出现多次,其调用了makeslice函数分配内存。可以通过显示的函数所在的位置,在对应的代码中查看是否出现问题。

图20-29 查看触发GC的函数的堆栈信息
一般来讲,这样的问题是由于临时分配的内存过多,没有合理复用内存导致的。这种问题在短时间需要分配大量内存的场景(例如为处理的图片分配内存、序列化与反序列化)比较常见。在本案例中,查看代码发现,由于多次分配了过大的内存导致垃圾回收频繁发生。通过修改代码,借助标准库中sync.pool复用产生的内存,轻松解决了出现的问题。再次通过trace工具查看程序的变化,发现30秒只执行了2次GC。
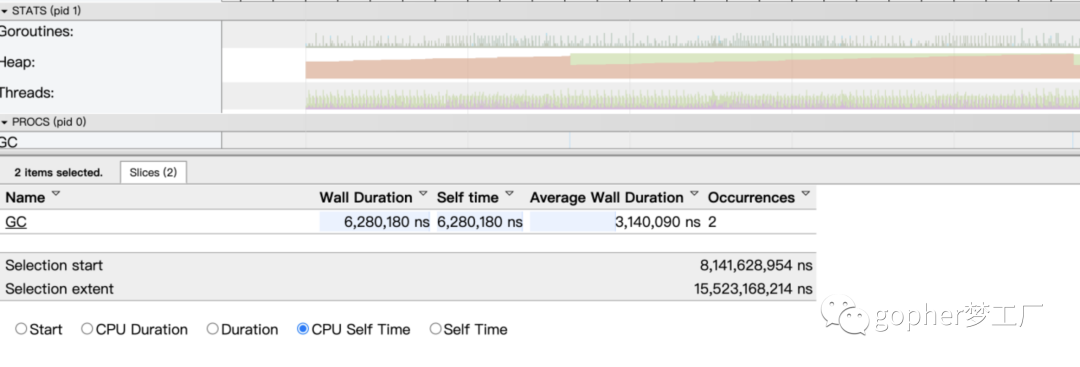
图20-30 修复问题后内存与GC状况恢复正常