从业务视角来聊一聊为什么我们需要 RxJS?
本文目标
本文尝试从在线教室的现状出发,聊一聊引入 RxJS 的原因,并从 RxJS 最具高频的使用场景切入,尝试将 RxJS 的最为核心的概念弄清楚的同时,帮助读者、听众能够实际将 RxJS 应用在业务中,学以致用。
本文只是笔者作为一个初学者,在接手业务代码与看了诸多业界的优秀实践文章之后的思考与沉淀,写的匆忙,许多地方没有经过细细钻研,所以行文难免有所疏漏、错误,如果你在看或听的过程中觉得有些不妥的地方,可以随时在本文进行评论或打断我,一起探讨学习。

业务背景
最近团队接手了在线教室,从前辈们的思考中得知一个完善的在线教室符合如下特点:
1 . 一个在线教室是有状态的,例如:一个教室可能处于课前、课中,可能正在进行随堂测验、抢答;
2 . 在线教室内的各个功能,可以触发教室状态的流转,即事件驱动;
3 . 教室状态的流转存在一定的规则,例如,正在进行随堂测验,不能直接进入下课状态,必须先结束随堂测,然后下课;不同的业务形态,状态的流转规则可能不同,规则可配置;
4 . 在线教室通过状态的定时广播,达到广播老师端指令的目的;
从上面我们可以认识到,在线教室抽象出来就是一个状态机,状态包含各种状态,如聊天、轮播、签到、课件与激励等数十个状态,每个状态可能是在时间维度上有先后关系,每个状态也会有推 / 拉的操作,从而驱动状态的流转,状态的推 / 拉操作又是异步为主。
针对这种复杂的、多状态、异步、注重时序控制的场景,天然有一种技术,或者说是一种编程思想是为此而生的,那就是 FRP(Functional Reactive Programming),而在 FRP 领域,ReactivX,简称 Rx,是由微软推出的通过可观察的流来进行异步编程的 API 则是 FRP 最经典的实现范本之一。
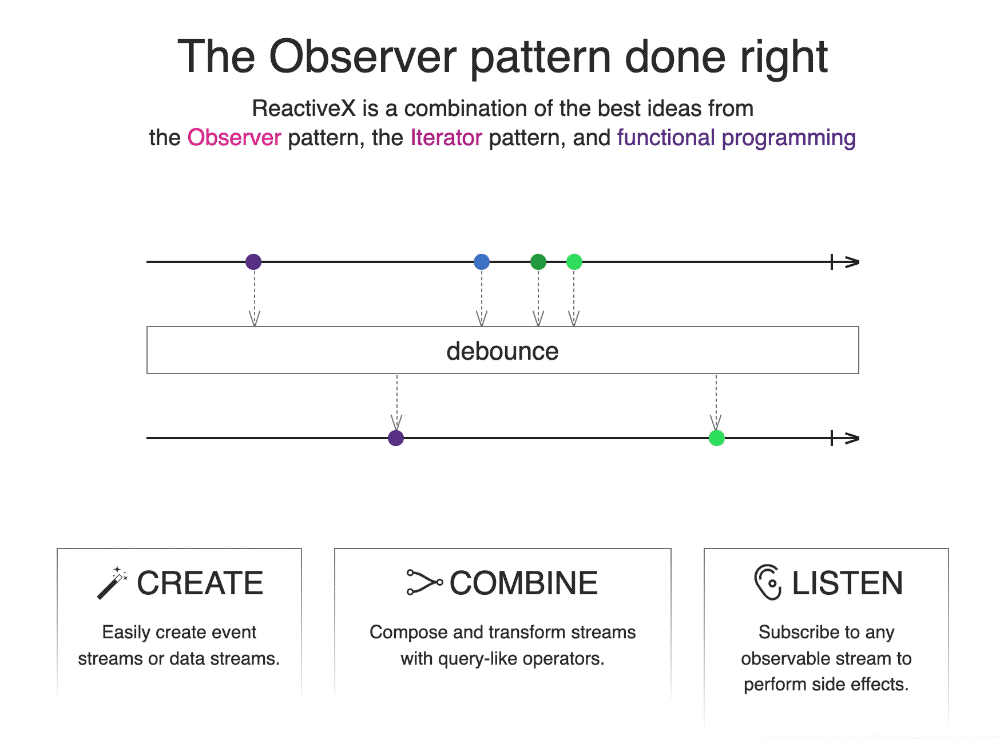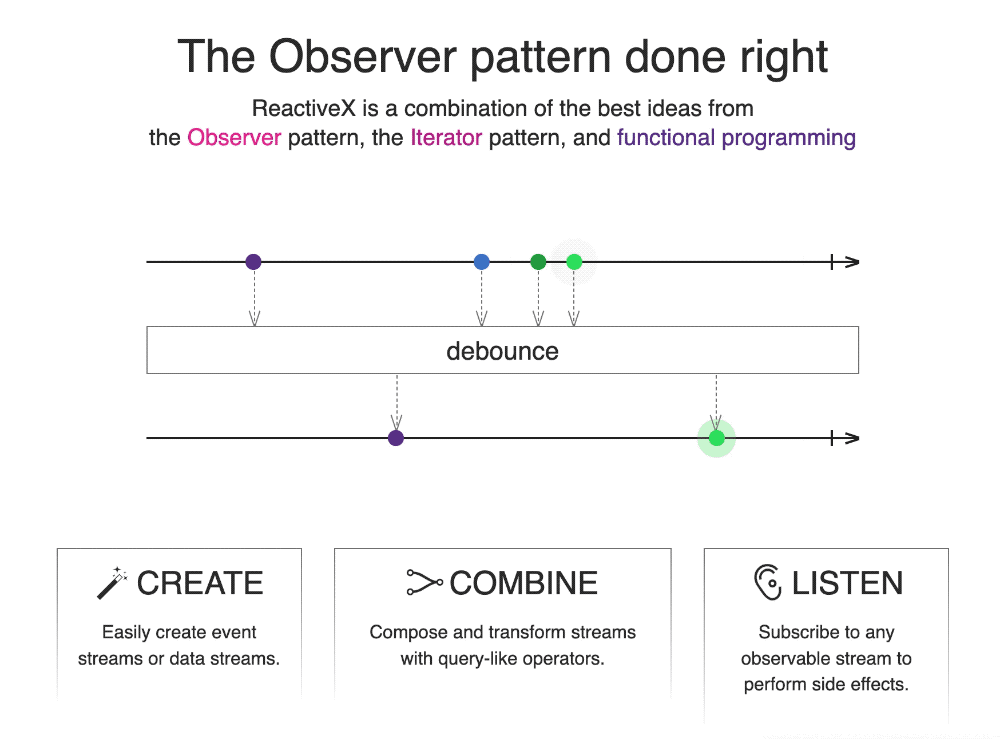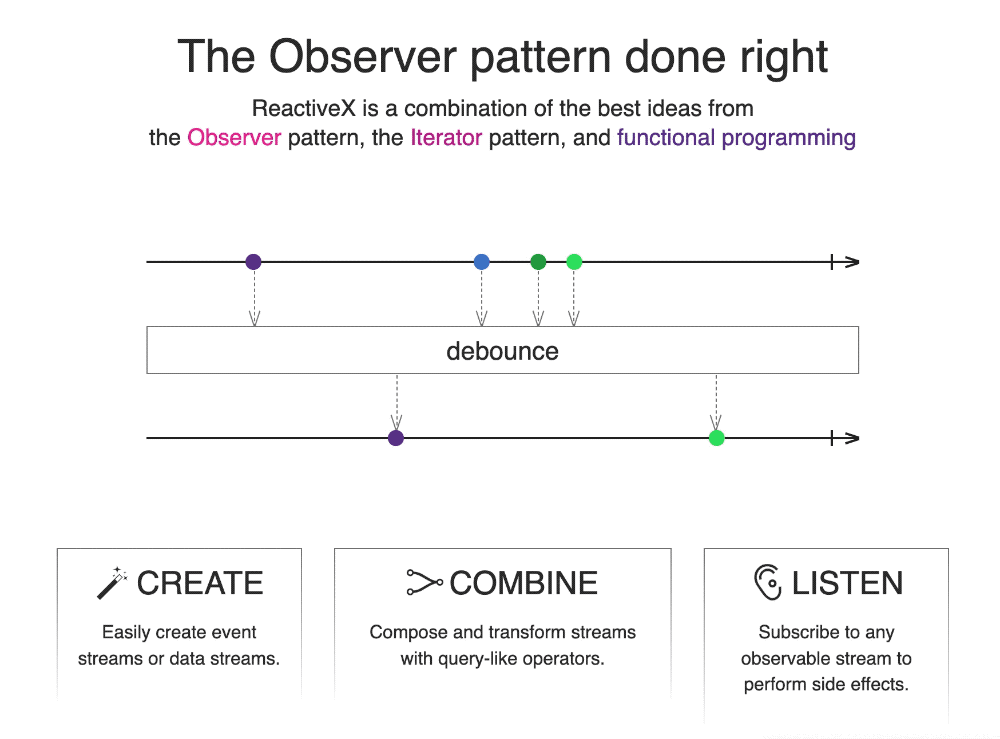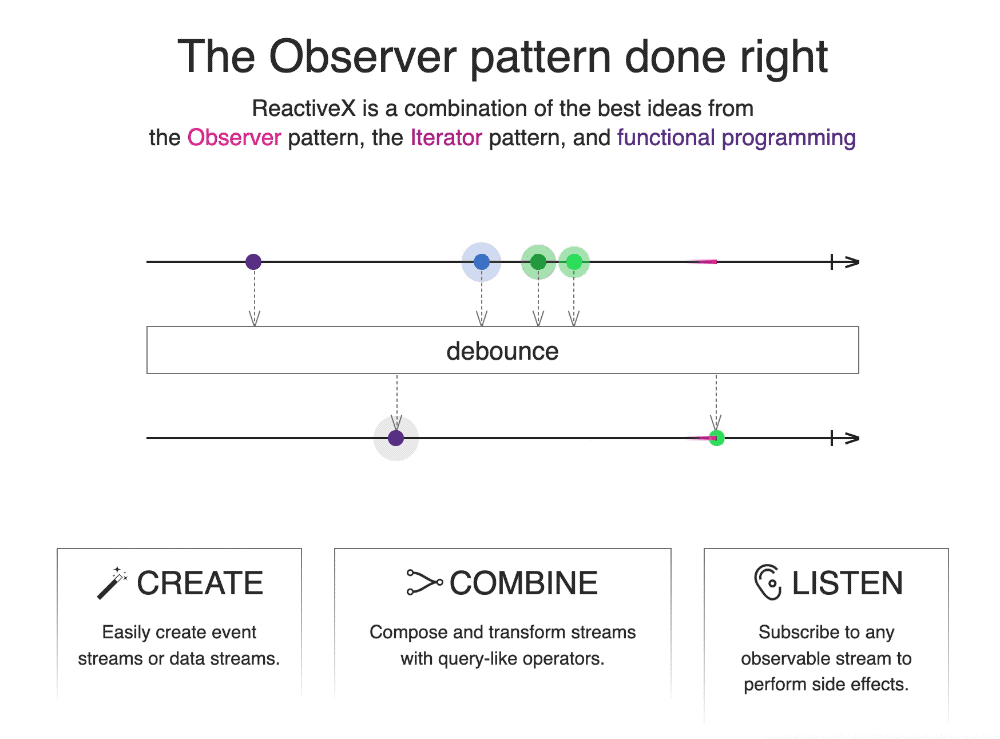
上述为 ReactiveX 的官方:https://reactivex.io/ 例子,主要通过最简洁的语言与动画描述什么是 ReactiveX。
而原教室中台的前端同学也是选择了 RxJS(Reactive Extension for JavaScript),通过 RxJS 整合了异步编程、时序控制以及各种遵循函数式编程思想的 Operators 的特性,优雅的实现了这种复杂的状态机。
如学生列表服务:
// packages/room/src/service/signalling/msg/fsm.ts
const fsmSubject = new Subject<classroom_common.IFsm | null>();
const behaviorFsmSubject = new BehaviorSubject<classroom_common.IFsm | null>(
null
);
fsmSubject.subscribe(behaviorFsmSubject);
// packages/room/src/service/tools/stduent-list/index.ts
behaviorFsmSubject.subscribe((fsm) => {
if (fsm) {
const equipment = fsm.equipment;
if (equipment) {
const data = equipment.data;
if (data) {
const draftEquipment = EquipmentFsmField.decode(
data
) as classroom_media_equipment.IEquipmentFsmField;
this.subscribeEquipmentStateCb.forEach((cb) => cb(draftEquipment));
}
}
}
});
export function pipeFsmMessage() {
// ...
const observable$$ = Emitter.on(MessageType.fsm);
// ...
observable$$.subscribe((payload) => {
if (payload) {
const currSeqId = Number(payload.seq_id);
const biggerSeqIdComing = currSeqId > setId;
if (biggerSeqIdComing) {
fsmSubject.next(payload);
setId = currSeqId;
}
}
});
}
// packages/room/src/base.ts
export class RoomEngine {
// ...
async enterRoom() {
// ...
pipeFsmMessage(isBoe(), resp.fsm);
// ...
}
}当状态机状态变化,即 MessageType.fsm 对应的状态变化,且现在服务端的 seq_id 大于前端保存的 seq_id 时,就会前端状态机对应的 fsmSubject 就会广播事件给到所有的订阅者,而 behaviorFsmSubject 订阅了 fsmSubject,之后在学生列表等其他状态中,又订阅了 behaviorFsmSubject,所以此时学生列表的相关状态就会变化,处理学生列表中设备信息的变化,如麦克风、摄像头、网络状况等,然后更新前端的 UI 显示。
当然上述逻辑只是在线教室庞大且复杂状态逻辑中的一小部分,像下面这样的代码随处可见:
startFollowWidthRetry = (
retryCount: number,
delayTime: number,
errorCb?: (err: Partial<RecorderStartResponse>) => void
) => {
const sub$ = new Observable((observer) => {
this.startFollowAudioRecord()
.then((res) => {
if (res.err_no) {
return observer.error(res);
}
observer.next(res);
observer.complete();
})
.catch((e) => {
return observer.error(wrapNetworkError(e));
});
});
return sub$
.pipe(
retryWhen((err$) => {
return err$.pipe(
scan((errCount, err) => {
if (errCount >= retryCount) {
throw new Error(err);
}
console.log("follow::retry", errCount);
errorCb && errorCb(err);
return errCount + 1;
}, 0),
delay(delayTime)
);
})
)
.toPromise();
};上述代码是实现学生跟读时音频录音的上报的逻辑,在这段代码中进行了学生跟读音频的录制上报、处理了错误,并提供了错误重试的机制等等,这段复杂的代码其实包含了一个典型的 RxJS 流的处理过程,并使用了大量的函数式 Operators(操作符),如 retryWhen 、scan 、delay 等
上述代码乍一看其实是反直觉的,执行逻辑尚不明晰,再加上一大堆新名词,如 Observable 、observer 以及 pipe 还有上面提到的各种名为 Operators 的东西,更是让人头脑昏厥,拒绝食用。
最绝望的是,上述这种加了很多语法糖的代码,调试体验爆炸,出错了无从调起。


走入 RxJS
牛刀小试
1 . 在正式讲解 RxJS 之前,让我们先来体会一下 RxJS 的魔法 。首先抛出一个需求:
让我们实现一个带 AutoComplete 的搜索框,输入内容时,自动向服务器发请求搜索对应的内容,然后将内容处理之后以列表的形式展示在输入框下面。
实现效果大致如下:
1 . 首先最 naive 的,监听搜索框的 input 事件,每次有变化就发起一个请求,请求搜索服务器,拿到结果,然后丢给 UI 层去渲染
2 . 接着我们需要过滤空输入、重复请求
3 . 可能从性能方面考虑,我们需要加入防抖
4 . 从容错性方面考虑,我们需要处理竟态
5 . 更严谨一点,我们还需要处理失败重试
6 . ....
一个实现上述 4 点功能的原生 JS 代码大概如下:
const debounce = (fn, delay) => {
let timer;
return function (...args) {
if (timer) clearTimeout(timer);
timer = setTimeout(() => fn.apply(this, args), delay);
};
};
const takeLatestRequest = (promiseCreator) => {
let index = 0;
return function () {
index++;
const promise = promiseCreator.apply(this, arguments);
function guardLatest(func, reqIndex) {
return function () {
if (reqIndex === index) {
func.apply(this, arguments);
}
};
}
return new Promise(function (resolve, reject) {
promise.then(guardLatest(resolve, index), guardLatest(reject, index));
});
};
};
useEffect(() => {
const inputSearch = document.querySelector(".search");
const latestRequest = takeLatestRequest(searchWikiPedia);
let lastInputValue = "";
inputSearch.addEventListener(
"input",
debounce((e) => {
if (!e.target.value) return;
if (lastInputValue === e.target.value) return;
else lastInputValue = e.target.value;
latestRequest(e.target.value)
.then((data) => setItems(data[1] || []))
.catch((err) => console.log(err));
}, 250)
);
}, []);近 50 行代码,还过得去。

useEffect(() => {
const inputSearch = document.querySelector(".search");
fromEvent(inputSearch, "input")
.pipe(
map((e) => e.target.value),
filter((val) => val),
debounceTime(250),
distinctUntilChanged(),
switchMap((val) => searchWikiPedia(val))
)
.subscribe((data) => {
setItems(data[1] || []);
});
}, []);我们将在下面的 “体验 Operators 带来的魔法” 这一小节详细讲解这段实现过程,迫不及待想要了解的同学可以猛戳这个链接抢先体验。
短短 14 行搞定,不仅简洁,还清晰,就和搭积木似的,需要什么加个 Operators,不需要的时候把这行删掉,搞定!

从数组聊起
其实 RxJS 和数组有解不开的因缘,为什么这么说呢?这就和 RxJS 的核心概念有关系,也和 FRP 编程思想有关系:
let arr = ['a', 'b', 'c'];
let iterator = arr[Symbol.iterator]( "Symbol.iterator")
iterator.next(); // {value: 'a', done: false }
iterator.next(); // {value: 'b', done: false }
iterator.next(); // {value: 'c', done: false }
iterator.next(); //{value: undefined, done: true }首先迭代器模式大家很清楚了,针对可迭代对象部署了统一的接口,使得这些对象能够按照统一的方式进行遍历,而无需关心内部的实现。
同时数组还具有二维数组、可组合等特性:
let arr = ['a', ['b', 'c'], 'd'];
let arr2 = ['e', 'f', 'g'];
arr.concat(arr2); // ['a', ['b', 'c'], 'd', 'e', 'f', 'g']除此之外,数组还可以很好的结合函数式编程使用:
arr.flat().map(item => item.toUpperCase()).reduce((total, item) => total += item)
上述操作将二维数组拍平,然后将每个字母转换为大写字母,接着进行聚合操作,拿到最后的结果:ABCD 。
对数组有一个体感之后,我们再去看 RxJS 会感觉熟悉很多,虽然 RxJS 最核心的概念:Stream,相比数组多了一个时间维度的概念,可以理解为带上时间属性的 “数组”,后续我们也将在讲解 RxJS 时拿数组进行举例对照说明讲解。
好的,我们正式开始 RxJS 的讲解。
RxJS 是什么?
Reactive Extension for JavaScript
有各种语言的实现,如 RxJava,RxPy,RxGo 等等...,其中的 Rx 是指 Reactive Extension,指响应式编程(Reactive Programming)这种编程范式在 JavaScript 的一种实现。
什么是 Reactive Programming?
响应式编程(Reactive Programming)是融合了观察者模式、迭代器模式与函数式编程三者最优秀的观点,从而诞生的一种新的编程范式,是一种以异步数据流(Async Data Stream)为中心的编程范式。
关于流 Stream 我们会在后续进行讲解。
这里可能会引出如下几个疑问?
- 什么是观察者模式、迭代器模式?
- 什么是主动式(Proactive),什么是响应式(Reactive)?
- 什么是命令式(Imperactive)、什么是函数式(Functional/Declaractive)、什么是响应式(Reactive)?
观察者模式与迭代器模式
观察者模式定了一个对象之间的一对多的依赖关系,当目标对象 Subject 更新时,所有依赖此 Subject 的 Observer 都会收到更新。
举个例子
import { fromEvent } from "rxjs";
// 创建一个监听 document click 事件的 Observable
let Observable = fromEvent(document, "click");
// 通过 Observable.subscribe 时,接收一个 Observer 回调,当有点击事件(click)发生时
// 则调用传入的回调函数,即 Observer 会收到更新
let subscription = Observable.subscribe((e) => {
console.log("dom clicked");
});
let subscription2 = Observable.subscribe((e) => {
console.log("dom clicked");
});
let subscription3 = Observable.subscribe((e) => {
console.log("dom clicked");
});上述代码,当点击 DOM 时,三个 observer (回调函数)都会收到通知,然后打印 dom clicked 语句。
迭代器模式是指提供一种方法顺序访问一个聚合对象中各个元素,而不需要暴露该对象的具体表示,常见的为部署 Symbol.iterator 属性,调用对应 Symbol.iterator 的方法返回一个迭代器对象,然后就可以以统一的方式进行遍历:
let arr = ['a', 'b', 'c'];
let iterator = arr[Symbol.iterator]( "Symbol.iterator")
iterator.next(); // { value: 'a', done: false }
iterator.next(); // { value: 'b', done: false }
iterator.next(); // { value: 'c', done: false }
iterator.next(); // { value: undefined, done: true }对应的 RxJS 里面就是 Observable 可观察对象,也就是我们后续将引出的 Stream 流的概念,每个 Stream/Observable 其实可以看作是一个数组,然后支持数组相关的各种操作、变换等,变成另外一个 Stream/Observable,拿 RxJS 举例:
import { fromEvent, map } from "rxjs";
// 创建一个监听 document click 事件的 Observable
let subscription = fromEvent(document, "click")
.pipe(map(e => e.target)
.subscribe(value => {
console.log('click: ', value);
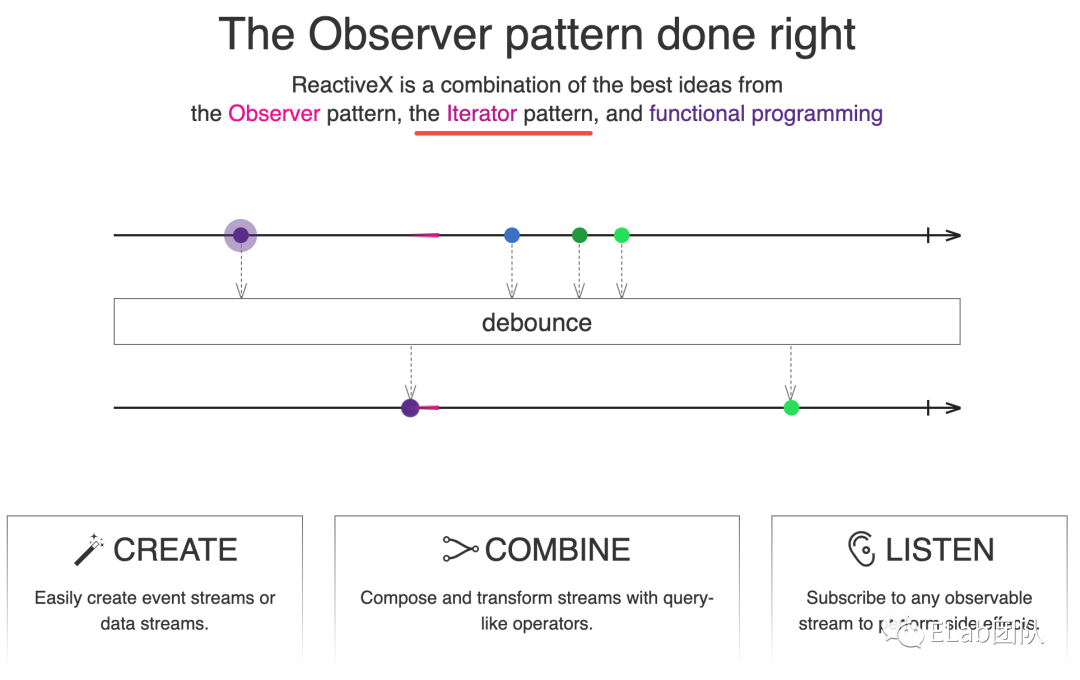
});fromEvent(document, "click") 会声明一个 Observable 对象,同时也创建了一个 Stream,类似下面的图片:

fromEvent(document, "click") 创建的 Observable 对应着上面的带有箭头的线,这条线就是一个 Stream 流,上面的一个个 ev 就是每次点击之后产生的事件,随着时间推移,不断的产生事件,在这个线上不断的流动下去 -- 之所以为 Stream,而这个 Stream 其实也可以看作是一个 “数组”,上面的一个个事件即为 “数组” 的元素,我们可以对这个 “数组”进行遍历,以统一的方式如 map/filter 等进行遍历,所以也叫融合了迭代器模式,而在 RxJS 中,通过这种 “迭代器” 模式,我们可以方便的对一个 Stream 进行变换,如 map 操作效果如下图所示:
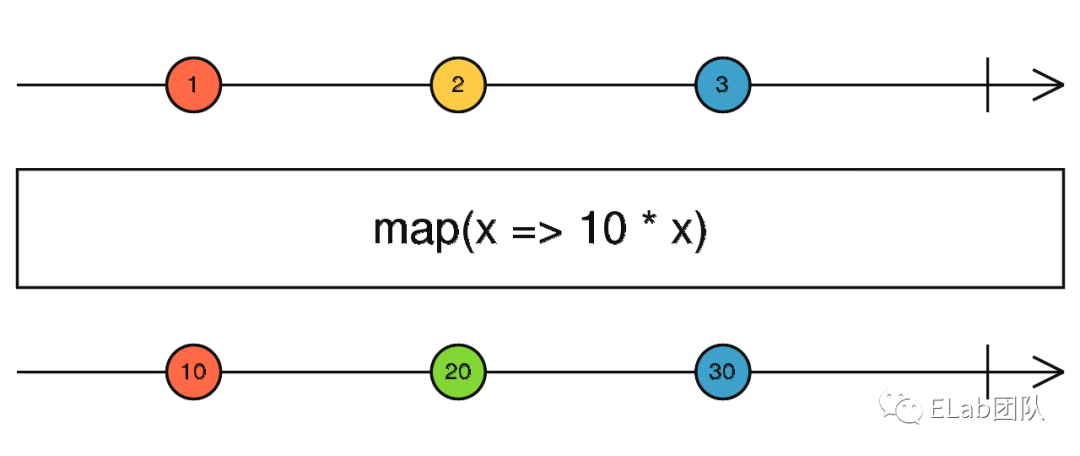
map 将一个 Stream 变换为另外一个 Stream
而最后通过 subscribe 生成了 observer 观察者,当有事件发生时,observer 的回调函数会调用,打印 Log,即融合了观察者模式。
那么函数式是如何应用在 RxJS 里面的呢?细心地同学可能发现了,RxJS 其实提供了大量的 Operators,如 map、filter、scan 等,以 函数式/声明式 的方式来操作 Stream,且操作之后生成一个新 Stream,不会突变原 Stream,此为融合了函数式编程思想。
主动式与响应式
Proactive(主动式):即主动轮询,不停的去问需求方以期完成任务,常见的有设置一个定时器,不断的去给服务器发请求询问是否有新的内容产生。
Reactive(响应式):即有事件发生时,通知我完成任务,常见的有 DOM 事件的监听与触发、WebSocket 等
举个例子
完成目标:如平台中的上课通知,如果服务端收到新的课程开始通知,对应的客户端需要展示这些上课通知。
通过主动式的方式我们会写出如下代码:
setInterval(async function () {
try {
const classroomNotification = await fetch('https://xxx');
// 后续操作
} catch(err) {}
, 3000)上述代码每隔 3S 去发一次请求,问一下服务端,现在数据有没有更新,有就把数据给我。
通过响应式的方式去实现上述逻辑可能是如下:
const socket = new WebSocket("ws://xxx");
socket.addEventListener('open', function() { // 连接成功,可以开始通讯 });
socket.addEventListener('message', function () {
// 收到服务端传来的数据,修改前端数据,展示在前端
})命令式与函数式
命令式:你命令机器去做事情(how),得到你想要的(what)
声明式:你告诉机器你需要什么(what),让机器想出如何去做(how)
举个例子
完成目标:拿到一个数组中的每项数字或包含数字的字符串,获得这些数字乘以 2 之后相加的结果。
如果完成上述目标,我们用命令式的方式会写出如下代码:
const source = [1, 5, 9, 3, 'hi', 'tb', 456, '11', 'yoyoyo'];
let total = 0;
for (let i = 0; i < source.length; i++) {
let num = parseInt(source[i], 10);
if (!isNaN(num)) {
total += num * 2;
}
}即一步步的告知计算机要做什么(how),如遍历数组,对每一项进行 parseInt 操作,判断如果不是 NaN 时就相加,最后得到相加的结果(what)。
通过函数式或者声明式的方式,我们会写出如下代码:
const source = [1, 5, 9, 3, 'hi', 'tb', 456, '11', 'yoyoyo'];
let total = source
.map(x => parseInt(x, 10))
.filter(x => !isNaN(x))
.map(x => x * 2)
.reduce((total, value) => total + value )上面的代码则是告知机器我想要什么(what),如我想要对数据进行映射(map)、过滤(filter)、再映射(map)、最后进行聚合(reduce)得到结果,由计算机自己想出如何进行 map、filter、reduce 等操作,我不需要关心 map、filter、reduce 底层的实现细节。
再看什么是 Stream?
Stream 是指时间序列上的一连串数据事件,而常见的数据事件(Data Event)包括 Variables、User Inputs、Properties、Caches、Data Structures 等各种同步或异步的操作,通过 Observe(观察)这些 Data Event,并依据其 Side Effects 进行对应的操作。
一个标准的流有开始态(黄色),有中间态(绿色、蓝色),有错误态(叉),有完成态(竖)。
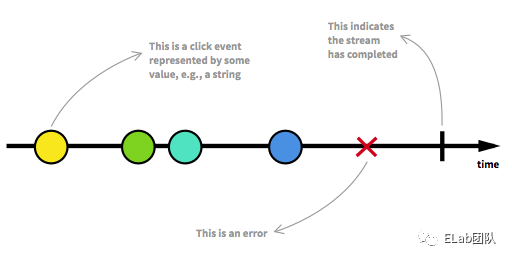
http://rxmarbles.com/ 这个网站可视化了各种 RxJS 的 Stream,也叫 Marbles (弹珠)图,所有的 RxJS 相关内容及 Operators 都可以通过 Marbles 图来表示出来
- 黄色:对于一个点击事件,如 Click Event,当用户点击一个 DOM 元素时,触发了点击事件,这是一个数据事件。这是一个流的开始态。
- 绿色、蓝色:点击事件之后可能对数据进行了取值、缓存、或者声明新的数据结构进行存储等,这些也是数据事件。这是一个流的中间态。
- 叉:遇到 let 暂时性死区,未声明就使用,会抛出一个错误,这也是数据事件。这是一个 Stream 的错误态,错误态是一种完成态。
- 竖:点击以及点击之后的一系列操作执行完成,会到达一个 Stream 的完成态。
通过一段 RxJS 的代码来展现上述的 Stream:
import { range, map } from "rxjs";
let source = range(1, 5);
let subscription = source
.pipe(map(val => val * 2))
.subscribe(
(x) => console.log("onNext: " + x),
(e) => console.log("onError: " + e.message),
() => console.log("onCompleted")
);
// Logs:
// onNext: 1
// onNext: 2
// onNext: 3
// onNext: 4
// onNext: 5
// onCompleted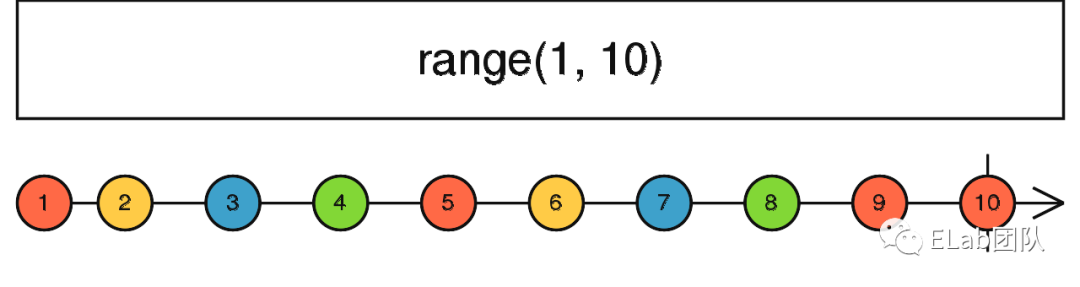
上述为 range 的 Marbles 图示
上述为 map 的 Marbles 图示
上述通过 RxJS 提供的 range operators 快速的创建了一个以 1 为起始值,长度为 5 的递增序列的 Stream:
- 流的创建为起始态
- 对起始态的数据 1-5 进行后续的操作,为中间态,即将 1-5 映射为 2/4/6/8/10
- 如果在 Stream 的中间态遇到错误,进入到错误态,则会执行 subscribe 的第二个参数,,打印
onError: e.message - 如果中间态执行完毕没有遇到错误,则会进入到完成态,执行 subscribe 的第三个参数,打印
onCompleted - 同时,通过 subscribe 此 Stream,我们可以声明一个观察者(observer),当流中的数据事件发生副作用(Side Effects)时,做出对应的反应,对应到上述例子,此流后续会依次发出 1/2/3/4/5 等 5 个数据事件,这样 susbcribe 的第一个参数即会打印出
onNext: x这样的 Log
Operators 的概念后续会讲解 = =!
再看什么是 RxJS?
RxJS 最核心的概念就是 Observable(可观察对象)、Observer(观察者),当然还有一些 Subject、Scheduler 与 Operators 我们后续讲解。
Observable 就是我们上节提到的 Stream,RxJS 通过 Observable 这样一个可观察对象来具象化 Stream 的概念,我们通过一个例子来体会一下:
import { fromEvent } from "rxjs";
// 创建一个监听 document click 事件的 Observable
let Observable = fromEvent(document, "click");
// 通过 Observable.subscribe 方法来声明一个观察者 observer,当有点击事件(click)发生时
// 则调用传入的回调函数
let subscription = Observable.subscribe((e) => {
console.log("dom clicked");
});上述为 fromEvent 的 Stream 图示
我们知道,Variables、User Inputs、Properties、Caches、Data Structures 等在 Stream 的概念中都是一个个数据事件,而 RxJS 可以将这些数据事件转换为 Observable,从而变成可观察对象,即创建为一个 Stream,然后此 Stream 则可以进行一系列 “中间态”,如进行 map 操作,最后到达“错误态”或“完成态”,同时在整个 Stream 的生命周期,我们可以 Subscribe(订阅)此流,声明一个 Observer(观察者),当 Stream 中的数据事件有 Side Effects 时,观察者就可以执行对应的操作。
RxJS 能做什么?
从 Stream 的视角来操作程序
从 RxJS 的视角来看,我们程序就是一个个 Stream 组成,无论是同步还是异步,无论是变量、事件等,都是一个个的 Stream,通过 RxJS,我们将这些数据事件转换为 Observable,然后进行 “流式” 操作。
我们通过一个 RxJS 的例子来重新理解 Stream 这个概念,也就是 Observable 这个概念,来看下面这段代码:
import { fromEvent, map, scan } from "rxjs";
// 创建一个监听 document click 事件的 Observable
fromEvent(window, "click")
.pipe(
map((val) => 1),
scan((total, curr) => total + curr)
)
.subscribe((val) => console.log(val));先提一个问题:
我如果点击 4 次,打印的结果是什么?
答案是:1,2,3,4
首先说明一下 scan 类似我们平时的 reduce,即对一组数据进行聚合,而 map 就和我们平时使用的 map 的作用一致,这两个都是对 Stream 进行了转换,而 subscribe 则是声明了一个观察者,一旦有数据过来,即打印这个数据。
如果要理解上述结果,我们首先需要从 Stream 这个概念出来,去描绘整个处理过程,而首先需要关注的是 Stream 是一个具有 “时间” 这个维度的一个概念,即类似下面图:
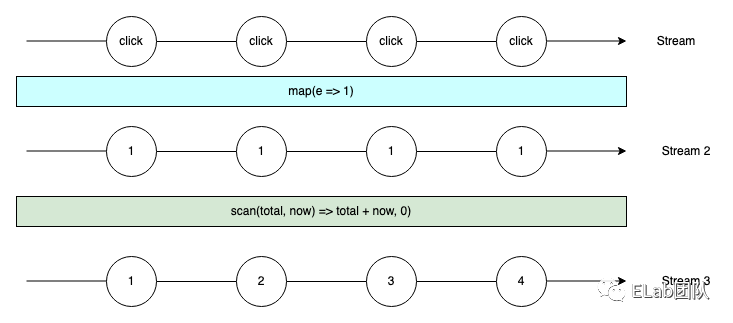
fromEvent 创建了一个 Stream,也就是一个 Observable,然后随着时间推移,后续会触发多次 click 事件,即会在 Stream 这条线上,按时间维度触发这些 click 事件,每个事件即为上图中的一个圆,这一系列的事件实际上组成了一个数组。
而我们通过 map 操作符,将数组中每个事件都映射成 1 这个数字,这里注意映射之后成为了一个新 Stream,我这里称它为 stream 2,stream 2 中每个数据事件都是 1。
接着我们继续调用 scan 操作符,scan 操作符类似 reduce,对传过来的数据进行聚合操作,但是这里为什么结果是 1, 2, 3, 4 呢?这里的核心就是需要理解我们 Stream 的核心,即从第一次点击开始,到后续的点击,这条流上共发生了 4 个数据事件,而每一次 scan 则会扫描从 stream 上面开始的第一个事件到当前发生的事件,并对这些数据进行聚合操作,所以结果计算如下:
1 . total 为 0,now 为 1,结果为 1
2 . total 为 0,对 [1, 1] 进行聚合,结果为 2
3 . total 为 0,对 [1, 1, 1] 进行聚合,结果为 3
4 . total 为 0,对 [1, 1, 1, 1] 进行聚合,结果为 4
对 Stream 进行组合
我们了解了 Stream 其实也是一个数组,但是 Stream 还拥有一个 “时间” 维度的概念,即随着时间的增长,Stream 上会不断的增加元素,这么说你可能还没有什么体感,可能还会反问:“我数组不也可以随着时间增加元素吗?”

merge ,我们来看它的 Stream 图示:
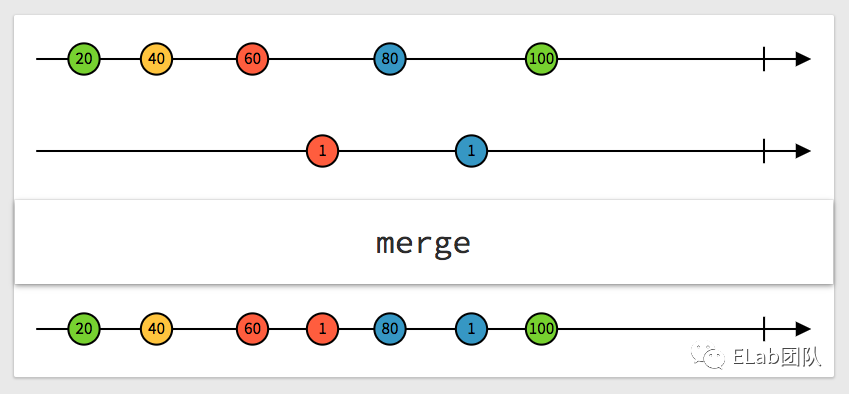
let arr1 = [20, 40, 60, 80, 100]
let arr2 = [1, 1]
let arr3 = arr1.concat(arr2) // [20, 40, 60, 80, 100, 1, 1]
let arr4 = arr2.concat(arr1) // [1, 1, 20, 40, 60, 80, 100]这就是时间属性在 Stream 上最明显的体现。
我们通过一个实际的例子来了解组合的强大力量:
给定一个需求,实现一个计数器,当点击 +/- 时能够正确的显示对应的数字
实现效果如下:
import React, { useState } from "react";
export default function Merge() {
const [count, setCount] = useState(0);
const handlePlus = () => {
setCount(count + 1);
};
const handleMinus = () => {
setCount(count - 1);
};
return (
<div>
<div className="count">{count}</div>
<button className="plus-button" onClick={handlePlus}>
+
</button>
<button className="minus-button" onClick={handleMinus}>
-
</button>
</div>
);
}上述代码很好懂,是完全的命令式的实现,即我加 1 的时候就手动加 1,减 1 的时候就手动减 1,我告诉计算机如何做(how),然后得到我要的结果 (what)
然后我们切换成 RxJS 的形式:
import React, { useState, useEffect } from "react";
import { fromEvent, merge, mapTo, scan } from "rxjs";
export default function Merge() {
const [count, setCount] = useState(0);
useEffect(() => {
merge(
fromEvent(document.querySelector(".plus-button"), "click").pipe(mapTo(1)),
fromEvent(document.querySelector(".minus-button"), "click").pipe(
mapTo(-1)
)
)
.pipe(scan((total, curr) => total + curr, 0))
.subscribe((val) => {
setCount(val);
});
}, []);
return (
<div>
<div className="count">{count}</div>
<button className="plus-button">+</button>
<button className="minus-button">-</button>
</div>
);
}实现的效果类似:

- 将
plus-button的点击事件转换成 Observable 可观察对象,每次点击就mapTo(1),转为 1 - 将
minus-button的点击事件转换成 Observable 可观察对象,每次点击就mapTo(-1),转为 -1 - 将这两个 Stream 在时间维度上进行 merge,得到如下效果
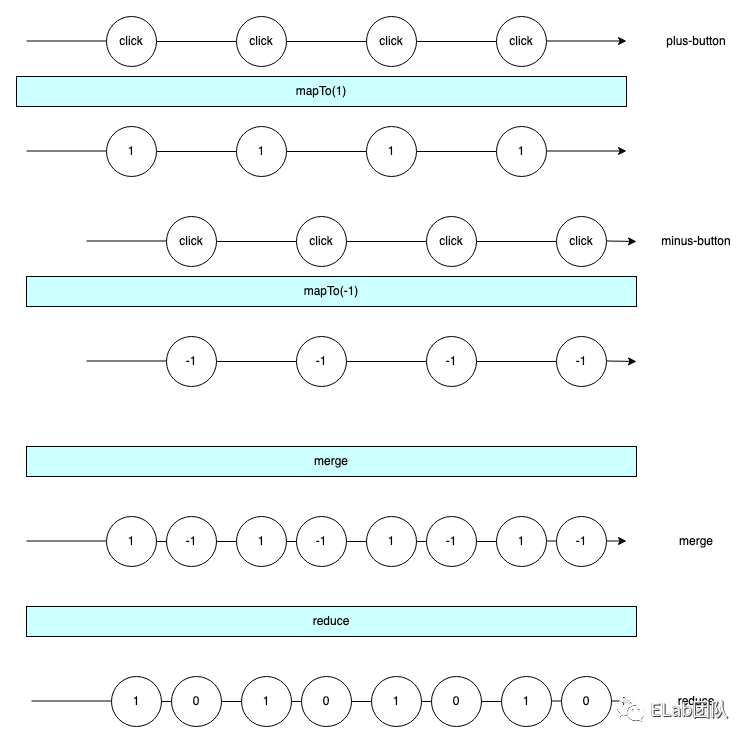
可以看到我们通过 RxJS Stream 的思想,通过在时间维度上 merge 两个流,来实现计数器的效果,而我们在实现的过程中完全遵循声明式的写法,即你告诉计算机你要什么(what),然后计算机会自己推导出如何做(how),比如 mapTo 就是你告诉计算机每当一个点击事件发生时,我需要拿到数据 1,而 scan 则是告诉计算机我需要对数据进行聚合操作,然后计算机就会自动完成 merge 之后 Stream 的聚合操作。
对多重嵌套 Stream 进行处理
在上面我们理解了 RxJS 将程序抽象为一个个 Stream 的概念,并且学习了从 Stream 的视角来操作程序,以及对多个 Stream 进行组合操作,接下来我们将探索如何在 Stream 中嵌套 Stream,然后又如何去处理这些多重嵌套的 Stream。
那么什么是多重嵌套的 Stream 呢?我们在平时的业务开发中会碰到的典型的多重嵌套的 Stream 是什么呢?让我们来带着问题继续往下看
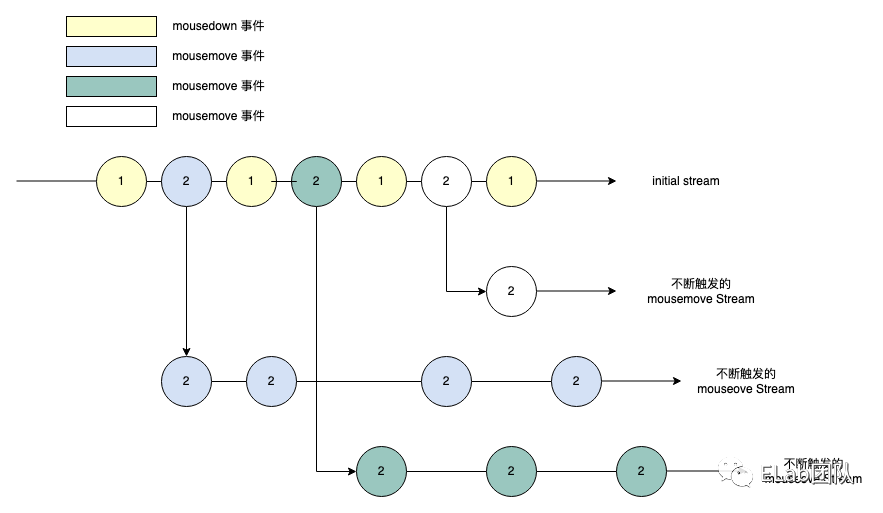
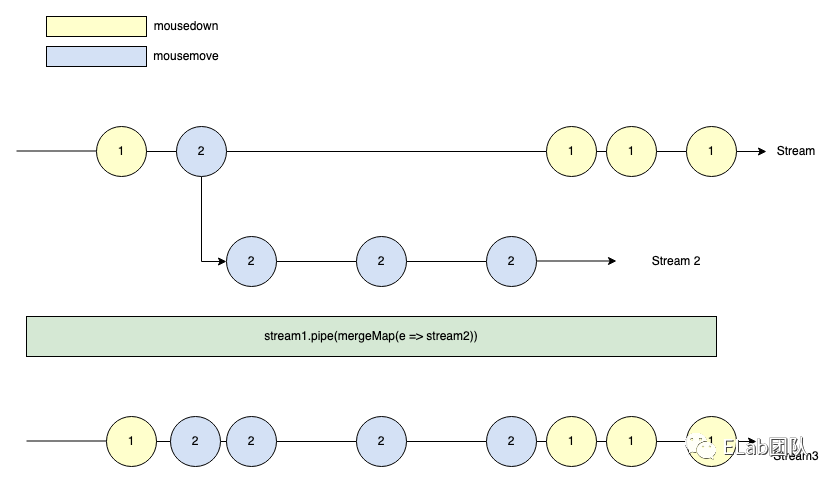
- 当我们多次 mousedown ,在时间维度上组合成 initial Stream,为黄色的圆圈那条线
- 每次 mousedown 之后开始 mousemove 时,当鼠标不停的移动,就会持续的触发 mousemove,也就是第一个淡蓝色的 mousemove(2)事件发生之后,以此淡蓝色 mousemove 事件为起点,会引发一条新的 Stream,我们称之为 “不断触发的 mousemove Stream”,从这里开始 Stream 里面嵌套了一条 Stream,类似二维数组
- 同样的在第二次 mousedown 之后开始 mousemove,之后以第一个墨绿色的 mousemove(2)为事件起点,会引发一条新的 Stream,我们称之为 “不断触发的 mousemove Stream”
上述的多重嵌套流从数组的视角来看就是如下内容:
[1, [2, 2, 2, 2], 1, [2, 2, 2, 2], 1, [2, 2], 1]
// => 格式化之后
[
1, // mousedown
[2, 2, 2, 2], // mousemove
1, // mousedown
[2, 2, 2, 2], // mousemove
1, // mousedown
[2, 2], // mousemove
1 // mousedown
]这里能够很清晰的看出 Stream 和数组有着脱不开的关系,所以数组相关的操作、函数,Stream 都有对应的操作与函数
了解了多重嵌套 Stream,以及其对应的场景之后,我们就来实战演练一下如何将这种多重 Stream 以 RxJS 的角度进行实现,并能够完成较为复杂的业务逻辑。
给定一个目标:实现通过 Canvas 能够进行自由画图
如果我们通过传统的命令式的实现大概长这样:
import React, { useState, useEffect } from "react";
export default function NestedNormal() {
useEffect(() => {
let canvas = document.querySelector(".canvas");
let ctx = canvas.getContext("2d");
const draw = (e) => {
ctx.lineTo(e.clientX, e.clientY - canvas.offsetTop);
ctx.stroke();
};
ctx.beginPath();
canvas.addEventListener("mousedown", (e) => {
ctx.moveTo(e.clientX, e.clientY - canvas.offsetTop);
canvas.addEventListener("mousemove", draw);
});
canvas.addEventListener("mouseup", (e) => {
canvas.removeEventListener("mousemove", draw);
});
});
return (
<div>
<canvas
className="canvas"
style={{ border: "1px solid black" }}
width={400}
height={400}
></canvas>
</div>
);
}它可以实现这样的效果:

1 . 等 DOM loaded 之后,对 canvas 添加 mousedown 事件监听,然后移动 canvas 画笔
ctx.lineTo(e.clientX, e.clientY - canvas.offsetTop);
2 . 接着监听 mousemove 事件,等到鼠标移动时,就进行绘图:
ctx.lineTo(e.clientX, e.clientY - canvas.offsetTop);
ctx.stroke();3 . 接着监听 mouseup 事件,等到鼠标抬起时,清除 mousemove 的监听事件,宣告此次画图的结束
canvas.addEventListener("mouseup", (e) => {
canvas.removeEventListener("mousemove", draw);
});那么我们将上述的处理方式换成 RxJS 的形式,让我们来从 Stream 的角度来思考问题。
首先进行问题分析,画出 Stream 图示:
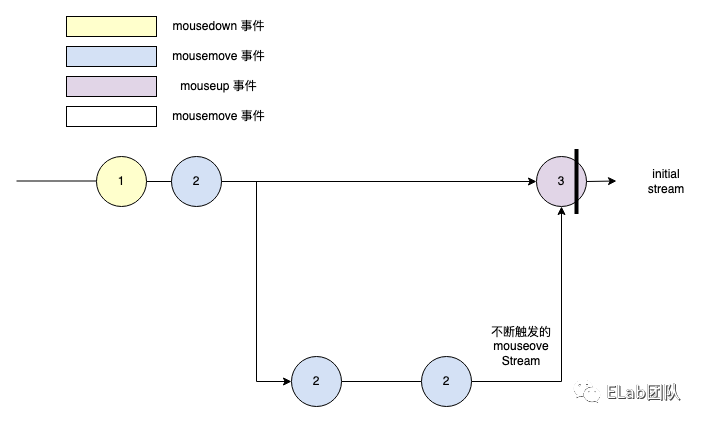
- 从时间维度上来看,先触发 mousedown
- 然后触发 mousemove,mousemove 实际上会产生一个新的 Stream,即嵌套的 Stream
- 然后触发 mouseup 事件,回到 initial stream,宣告从 1 引出的 Stream,然后经过嵌套的 2 之后,在 3 进入完成态,此 Stream 及其过程中的子 Stream 进入完成态。
上述代码用 RxJS 实现就是如下这样:
import React, { useEffect } from "react";
import { fromEvent, tap, takeUntil, mergeMap } from "rxjs";
export default function NestedRxJS() {
useEffect(() => {
let canvas = document.querySelector(".canvas");
let ctx = canvas.getContext("2d");
const draw = (e) => {
ctx.lineTo(e.clientX, e.clientY - canvas.offsetTop);
ctx.stroke();
};
ctx.beginPath();
fromEvent(canvas, "mousedown")
.pipe(tap((e) => ctx.moveTo(e.clientX, e.clientY - canvas.offsetTop)))
.pipe(
mergeMap((source) =>
fromEvent(canvas, "mousemove").pipe(
takeUntil(fromEvent(canvas, "mouseup"))
)
)
)
.subscribe((e) => {
draw(e);
});
});
return (
<div>
<canvas
className="canvas"
style={{ border: "1px solid black" }}
width={400}
height={400}
></canvas>
</div>
);
}上面的代码初看上去可能有点费解,但是不要方,我们一步一步来拆解它,并结合上述讲到的 Stream 的知识,看看是如何对应起来的。
fromEvent(canvas, "mousedown")
基于 canvas 的 mousedown 事件来生成一个 Stream,每次有 mousedown 事件就执行一次移动画笔的操作:
tap((e) => ctx.moveTo(e.clientX, e.clientY - canvas.offsetTop))
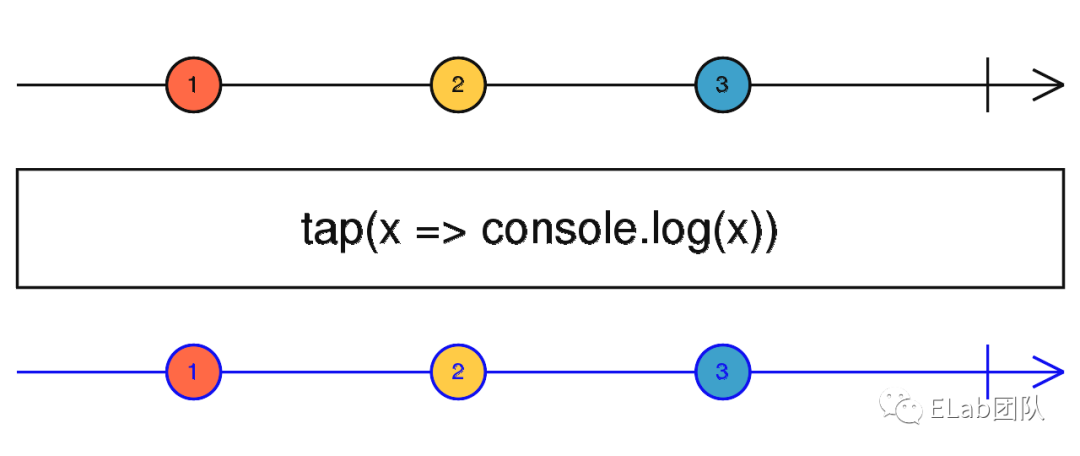
上述 tap 是一个 RxJS 操作符(operators),类似 subscribe 的效果,但是只会拿传过的来值进行一次不影响后续 Stream 的 “纯操作”,常用来在 Stream 的中间态拿到当前的数据事件来修改外部的状态或做一些通知,它的 Stream 图如下:
这里
tap所充当的作用较为关键,因为它可以拿到上一步的值,但是又不影响后续的操作,所以我们可以通过tap操作符进行 RxJS 的 Debug 操作,我们在后续的 如何 Debug RxJS 应用中讲解?
接着我们进行了一个较为复杂的操作:
mergeMap((source) =>
fromEvent(canvas, "mousemove").pipe(
takeUntil(fromEvent(canvas, "mouseup"))
)
)我们先看里面的内容:
fromEvent(canvas, "mousemove").pipe(
takeUntil(fromEvent(canvas, "mouseup"))
)fromEvent 很好理解,将 canvas 的 mousemove 事件转为一个 Observable 对象,也就是转为一个 Stream,然后这个 Stream 进行 pipe,即桥接到如下代码:
takeUntil(fromEvent(canvas, "mouseup"))
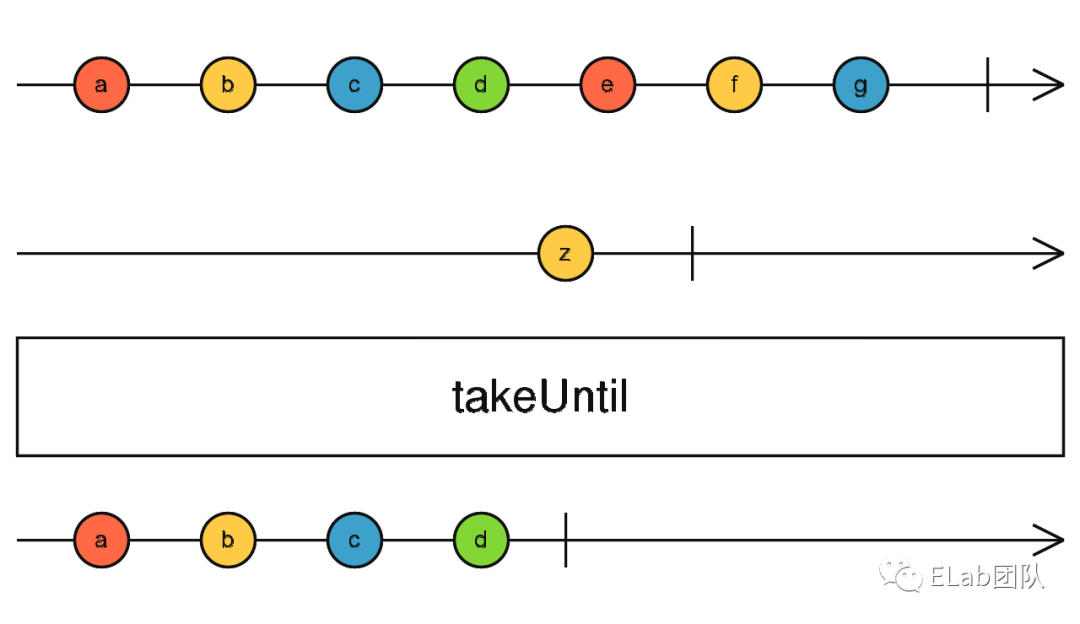
首先来看一下 takeUntil 的 Stream 图示:
对应到我们上述的需求里:
fromEvent(canvas, "mousemove").pipe(
takeUntil(fromEvent(canvas, "mouseup"))
)即在 canvas 的 mouseup 事件发生时,mousemove 这个 Stream 就进入完成态,也比较符合我们的之前的例子,即在鼠标抬起时,就清除 mousemove 事件,只不过我们这里没有命令计算机去清除这个事件,而是告诉计算机我们需要在某个事件发生时,对应的事件要结束,然后计算机就会自己去处理这个过程。
然后我们再回过头来看 mergeMap ,它是干什么的呢?我们自己画个图来演示一下,官方的图比较模糊:
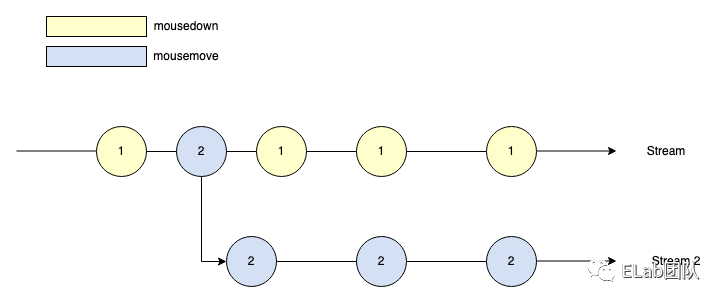
mousedown 之后,我们移动鼠标产生多个 mousemove 事件,对应到数组的表示就是:
[
1,
[2, 2, 2, ...]
1,
[2, 2, 2, ...]
...
]我们的 Stream 为多重嵌套状态,类似上述的二维数组,但是我们按照时间的维度来看,其实只有 1,然后 2,等 2 结束之后才能 1,所以如果我们想把上述二维数组压平,变成如下形状:
[ 1, 2, 2, 2, ..., 1, 2, 2, 2, ..., 1 ... ]
变成一维的数组,也就是一维的 Stream,上述场景就需要用到 mergeMap 这个操作符,也就是我们通过 mergeMap 之后的 Stream 图示如下:
答案是我们期望创建一个 mousedown 事件的 Stream,当 mousedown 事件触发时,都能创建一个 mousemove 事件的 Stream,按理来说应该用我们之前提到的 mapTo 方法:
fromEvent(canvas, "mousedown")
.pipe(tap((e) => ctx.moveTo(e.clientX, e.clientY - canvas.offsetTop)))
.pipe(
mapTo(fromEvent(canvas, "mousemove").pipe(
takeUntil(fromEvent(canvas, "mouseup"))
)
)
)
.subscribe((e) => {
draw(e);
});但是这样有个问题就是,如果直接 mapTo 其实相当于我们从一个 mousedown 数据事件,转成了一个 mousemove 的 Stream,如果直接 subscribe 的话,拿到的 e 其实是 mousemove 这个 Stream,而并非是我们期望的 event ,所以这里我们将 mousedown 与嵌套的 mousemove Stream 压平,然后再 subscribe 就会拿到单个 mousedown 事件触发时的 event 对象了,然后执行 draw 操作。
通过上述 RxJS 的操作逻辑,我们实现了同样的画图效果:

不得不说,Canvas 性能无解!♂️
我们再回过头来看我们的整体代码:
fromEvent(canvas, "mousedown")
.pipe(tap((e) => ctx.moveTo(e.clientX, e.clientY - canvas.offsetTop)))
.pipe(
mergeMap((source) =>
fromEvent(canvas, "mousemove").pipe(
takeUntil(fromEvent(canvas, "mouseup"))
)
)
)
.subscribe((e) => {
draw(e);
});整体解释如下:
1 . 监听 mousedown 事件,生成一个 Stream
2 . 每触发一次 mousedown 事件,就执行一次移动鼠标的操作 ctx.moveTo
3 . 每触发一次 mousedown 事件,就创建一个监听 mousemove 事件的 Stream
4 . 对于 mousemove Stream,通过施加 takeUntil 方法,当 mouseup 事件发生时,就将此 Stream 的状态修改为完成态
5 . 为了能够在每次 mousedown 事件时,既满足创建一个 监听 mousemove 事件的 Stream,又能在每次 mousemove 时,能够触发 subscribe 拿到实际 event 对象,我们通过 mergeMap 将两个 Stream 按照时间维度进行映射合并来达到这个效果
体验 Operators 带来的魔法
RxJS 的 Operators 比较多,只需了解核心原理,然后剩下的查阅文档,或参考这个网站 https://reactive.how/ 进行具体的学习即可。
先看一个兄弟团队那边的同学实现的一个搜索框的例子:
我们就可以认识到,认识与理解 Observable 与 Stream 的概念是第一步,当你能够做到心中有 Stream,那么再操起“ Operators 魔法,你就可以杀心自起!”
直接上一个类似搜索框的实际例子。
给定如下需求:让我们实现一个带 AutoComplete 的搜索框,类似上面的那个例子,每当用户输入一段内容,就展示对应内容的搜索结果。
我们先尝试用传统的 JS 过程式实现方式:
import React, { useState, useEffect } from "react";
import jsonp from "jsonp";
export default function OperatorsNormal() {
const [items, setItems] = useState([]);
const searchWikiPedia = (search) => {
return new Promise((resolve, reject) => {
return jsonp(
`http://en.wikipedia.org/w/api.php?format=json&action=opensearch&search=${search}&callback=JSON_CALLBACK`,
null,
(err, data) => {
if (err) {
console.log("err", err);
reject(err);
} else resolve(data);
}
);
});
};
const debounce = (fn, delay) => {
let timer;
return function (...args) {
if (timer) clearTimeout(timer);
timer = setTimeout(() => fn.apply(this, args), delay);
};
};
const takeLatestRequest = (promiseCreator) => {
let index = 0;
return function () {
index++;
const promise = promiseCreator.apply(this, arguments);
function guardLatest(func, reqIndex) {
return function () {
if (reqIndex === index) {
func.apply(this, arguments);
}
};
}
return new Promise(function (resolve, reject) {
promise.then(guardLatest(resolve, index), guardLatest(reject, index));
});
};
};
useEffect(() => {
const inputSearch = document.querySelector(".search");
const latestRequest = takeLatestRequest(searchWikiPedia);
let lastInputValue = "";
inputSearch.addEventListener(
"input",
debounce((e) => {
if (!e.target.value) return;
if (lastInputValue === e.target.value) return;
else lastInputValue = e.target.value;
latestRequest(e.target.value)
.then((data) => setItems(data[1] || []))
.catch((err) => console.log(err));
}, 250)
);
}, []);
return (
<div>
<input type="text" className="search" />
<ul>
{items.map((item) => (
<li key={item}>{item}</li>
))}
</ul>
</div>
);
}上述代码还有几个小的优化点:
1 . 输入置空时,不应该发起请求
2 . 过滤同样的请求
3 . 不应该频繁发起请求,不能每输入一个字符就发起请求,一般中间的单个字符都没有搜索意义,也就是我们常说的防抖
4 . 请求存在竞态
a . 先输入 a,然后发起请求 a
b . 在输入 b,发起请求 b
c . b 比 a 的响应先回来,则先展示 b 的结果再展示 a 的结果,逻辑不符合
下面我们来分别实现它们。
首先实现置空时不要发起请求:
// ...
inputSearch.addEventListener("input", (e) => {
if (!e.target.value) setItems([])
else {
searchWikiPedia(e.target.value)
.then((data) => setItems(data[1] || []))
.catch((err) => console.log(err))
}
});
// ...接着我们来实现过滤同样的请求:
// 记录上次input value;
let lastInputValue = '';
const value = e.target.value;
if (lastInputValue === value) {
return;
} else {
lastInputValue = value;
}然后实现防抖,我们在 250MS 之后才能执行一次,如果 250MS 之内有新输入,我们就重新计时(面试都背的滚瓜乱熟了对吧):
let timer = null;
const debounce = (fn, delay) => {
let timer;
return function (...args) {
if (timer) clearTimeout(timer);
timer = setTimeout(() => fn.apply(this, args), delay);
};
};
inputSearch.addEventListener("input", debounce((e) => {
searchWikiPedia(e.target.value)
.then((data) => setItems(data[1] || []))
.catch((err) => console.log(err))
}));最后我们还要实现竞态处理,即判断当前反馈的响应是否与发出的请求时一一对应,如果不是则不处理该响应:
let timer = null;
const takeLatestRequest = (promiseCreator) => {
let index = 0;
return function () {
index++;
const promise = promiseCreator.apply(this, arguments);
function guardLatest(func, reqIndex) {
return function () {
if (reqIndex === index) {
func.apply(this, arguments);
}
};
}
return new Promise(function (resolve, reject) {
promise.then(guardLatest(resolve, index), guardLatest(reject, index));
});
};
};
const latestRequest = takeLatestRequest(searchWikiPedia);
inputSearch.addEventListener("input", debounce((e) => {
latestRequest(e.target.value)
.then((data) => setItems(data[1] || []))
.catch((err) => console.log(err))
}));基本上搞定,我们来看一下实际的效果与对应的完整代码。
实际效果如下:

import React, { useState, useEffect } from "react";
import jsonp from "jsonp";
export default function OperatorsNormal() {
const [items, setItems] = useState([]);
const searchWikiPedia = (search) => {
return new Promise((resolve, reject) => {
return jsonp(
`http://en.wikipedia.org/w/api.php?format=json&action=opensearch&search=${search}&callback=JSON_CALLBACK`,
null,
(err, data) => {
if (err) {
console.log("err", err);
reject(err);
} else resolve(data);
}
);
});
};
const debounce = (fn, delay) => {
let timer;
return function (...args) {
if (timer) clearTimeout(timer);
timer = setTimeout(() => fn.apply(this, args), delay);
};
};
const takeLatestRequest = (promiseCreator) => {
let index = 0;
return function () {
index++;
const promise = promiseCreator.apply(this, arguments);
function guardLatest(func, reqIndex) {
return function () {
if (reqIndex === index) {
func.apply(this, arguments);
}
};
}
return new Promise(function (resolve, reject) {
promise.then(guardLatest(resolve, index), guardLatest(reject, index));
});
};
};
useEffect(() => {
const inputSearch = document.querySelector(".search");
const latestRequest = takeLatestRequest(searchWikiPedia);
let lastInputValue = "";
inputSearch.addEventListener(
"input",
debounce((e) => {
if (!e.target.value) return;
if (lastInputValue === e.target.value) return;
else lastInputValue = e.target.value;
latestRequest(e.target.value)
.then((data) => setItems(data[1] || []))
.catch((err) => console.log(err));
}, 250)
);
}, []);
return (
<div>
<input type="text" className="search" />
<ul>
{items.map((item) => (
<li key={item}>{item}</li>
))}
</ul>
</div>
);
}可以看到,在我们需要实现一个类似上述这种较为复杂、边界条件、异步的业务场景时,需要很多的样板代码,光是边界判断,防抖处理、竞态处理就差不多要 50 行,当然我们还没有考虑失败重试、数据兜底等因素,如果将这些因素考虑进去的话,那么代码可能要突破 100 行。

import React, { useState, useEffect } from "react";
import jsonp from "jsonp";
import { fromEvent, switchMap, debounceTime, filter, map, distinctUntilChanged } from "rxjs";
export default function OperatorsRxJS() {
const [items, setItems] = useState([]);
const searchWikiPedia = (search) => {
return new Promise((resolve, reject) => {
return jsonp(
`http://en.wikipedia.org/w/api.php?format=json&action=opensearch&search=${search}&callback=JSON_CALLBACK`,
null,
(err, data) => {
if (err) {
console.log("err", err);
reject(err);
} else {
resolve(data);
}
}
);
});
};
useEffect(() => {
const inputSearch = document.querySelector(".search");
fromEvent(inputSearch, "input")
.pipe(
map((e) => e.target.value),
filter((val) => val),
debounceTime(250),
distinctUntilChanged(),
switchMap((val) => searchWikiPedia(val))
)
.subscribe((data) => {
setItems(data[1] || []);
});
}, []);
return (
<div>
<input type="text" className="search" />
<ul>
{items.map((item) => (
<li key={item}>{item}</li>
))}
</ul>
</div>
);
}上述代码实现的效果如下:
可以看到上述代码主要有如下几点优化:
- 我们的代码从 50 行缩短到 13 行,代码量减少将近 4 倍
- 同时我们不仅实现了同样的功能,如过滤空输入、防抖、处理重复输入请求、以及竟态处理(通过
switchMap) - 而且当我们需要删除某项功能时,我们可以直接删除对应的函数,不会对上下文产生任何影响
- 同时我们需要加功能时,再加个函数加到我们 pipe 处理链中即可,比如我们需要事先超时重试(
retryWhen)等逻辑
distinctUntilChanged,比如 switchMap 等,接下来我们就通过弹珠图来可视化上述过程。
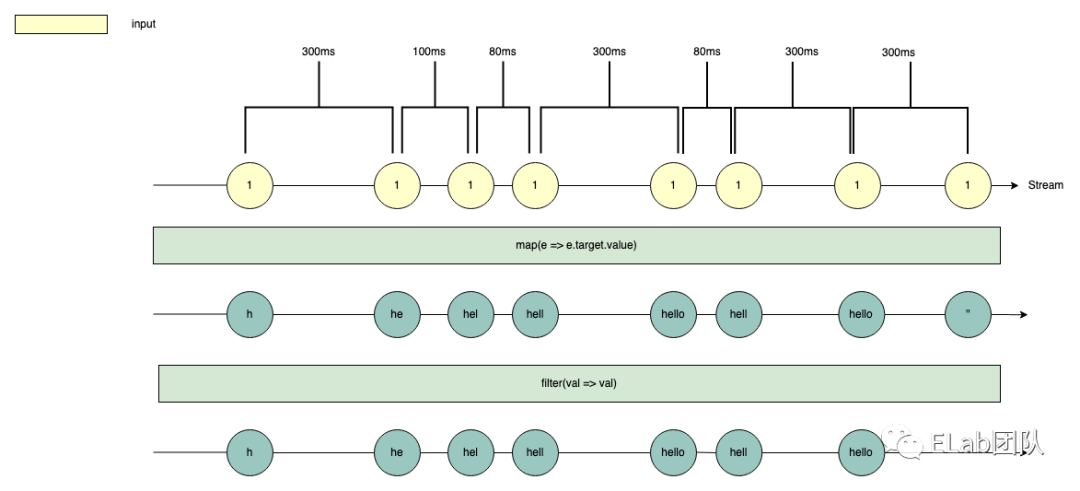
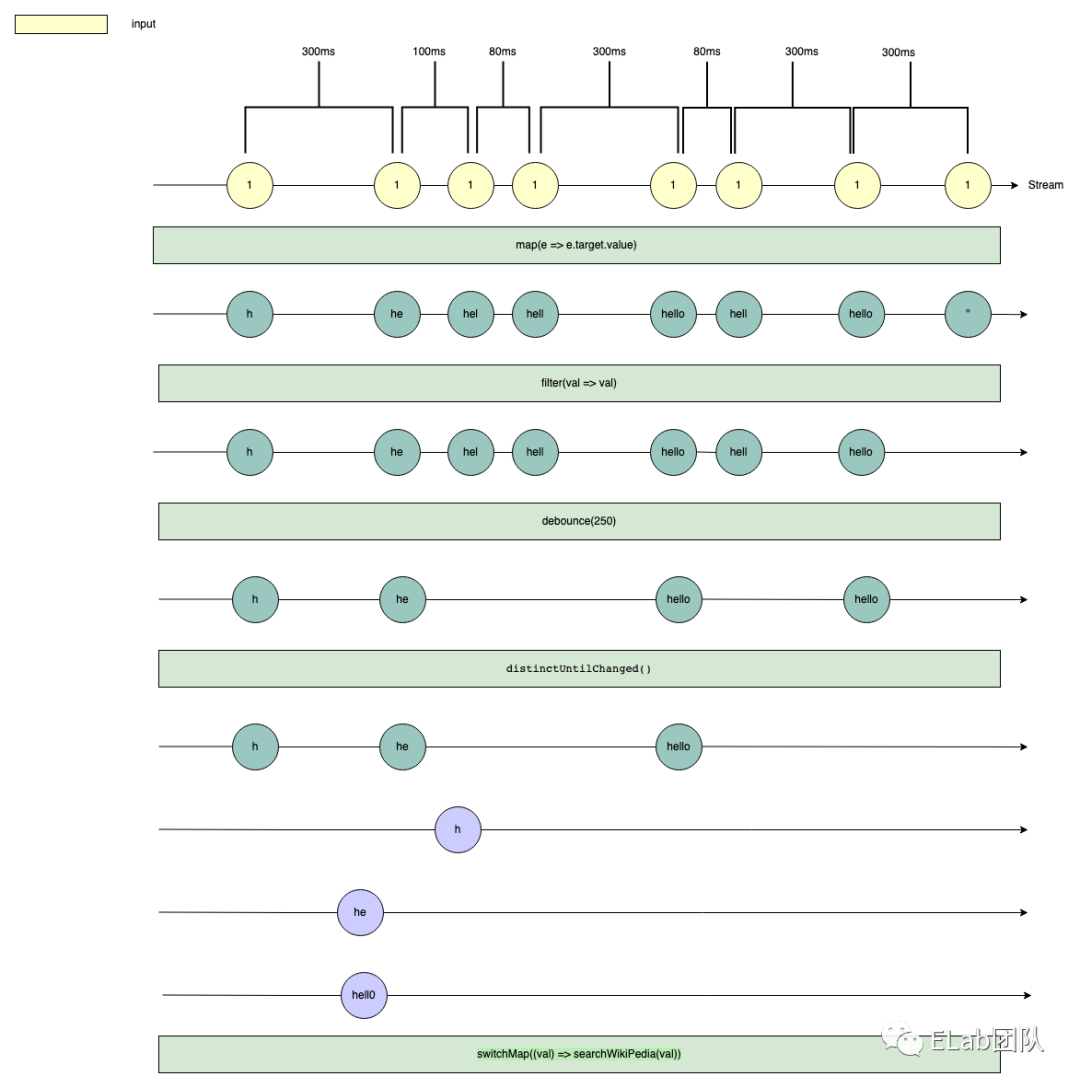
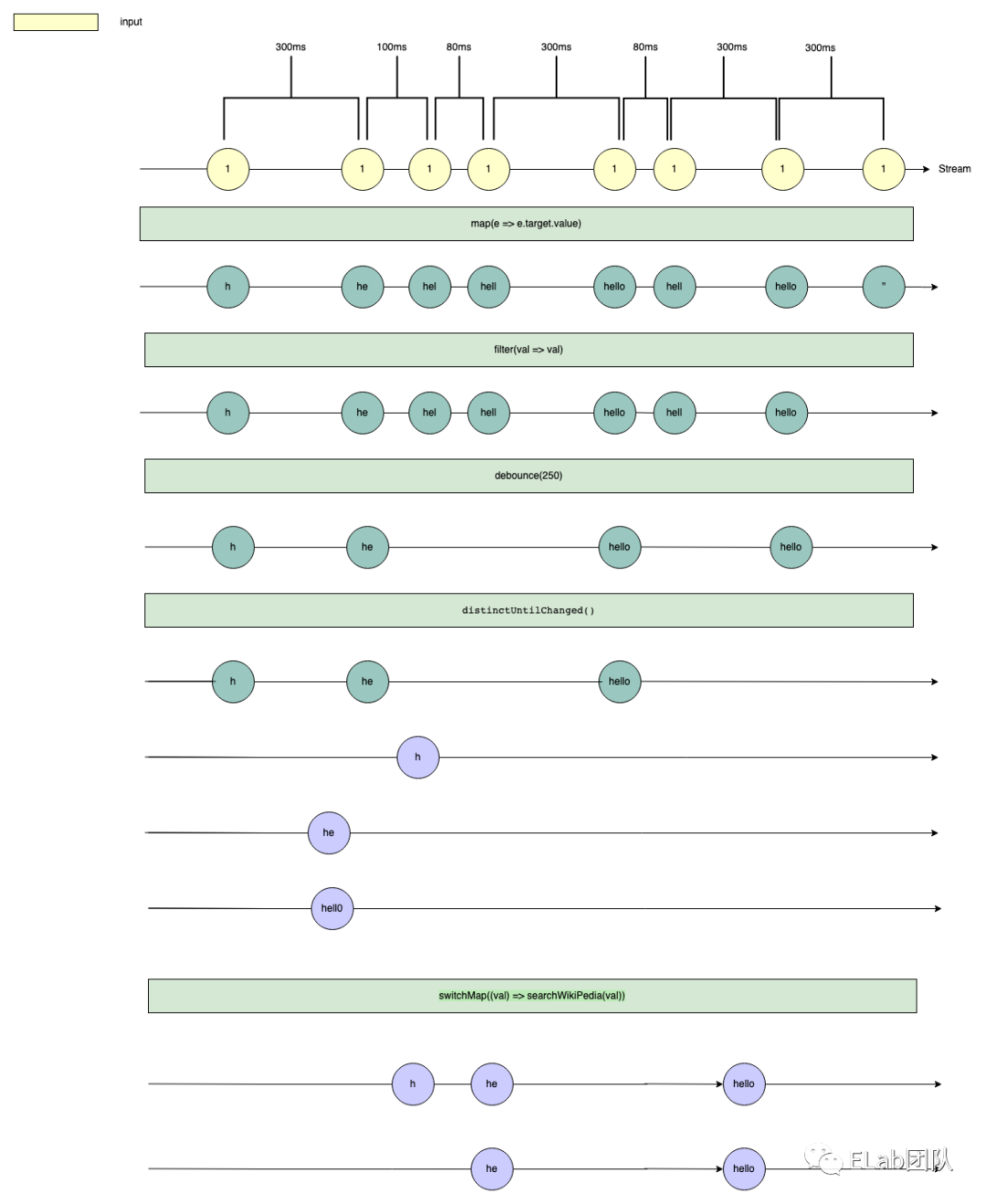
首先我们将 input.search 的 input 事件变为 Observable,然后也随之开始了 Stream 图,也就是弹珠图:

hello,然后最后进行了删除置空操作,将输入框清空:
- 即触发了第一次 input 事件,输入
h - 然后 300ms 内没有触发第二次 input 事件
- 接着 300ms 时触发了第二次 input 事件,输入
e - 然后紧接着 +100ms 触发了第三次 input 事件,输入
l - 然后紧接着 +80ms 触发了第四次 input 事件,输入
l - 然后接着 +300ms 触发了第五次 input 事件,输入
o - 然后接着 +80ms 触发了第六次 input 事件,删除
o - 然后借助 +300ms 触发了第七次 input 事件,添加
o - 然后接着 +300ms 触发了第八次 input 事件,将输入框清空,变为了空字符串
上述 8 个事件在时间维度上组成了一个 Stream,接下来我们要做的第一个操作就是,拿到这些输入事件对应的输入框的值,即 map(e => e.target.value) :

filter(val => val) :
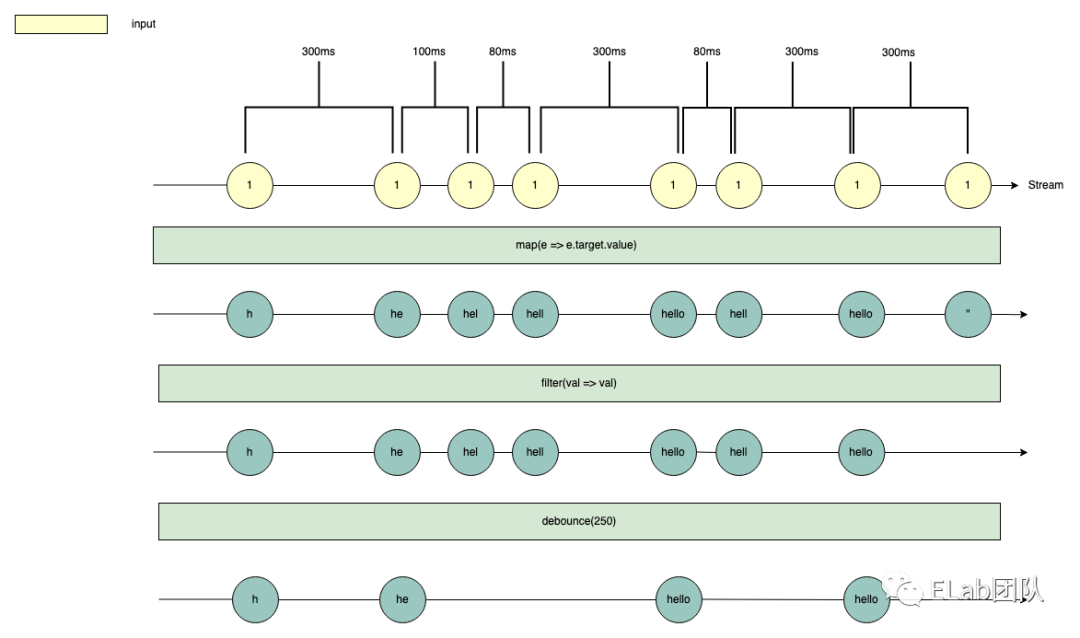
接着我们尝试加入防抖,即 debounceTime(250) 加入了一个 250ms 的防抖,这会对应到如下图:
紧接着我们尝试去除重复的请求,即在经过防抖之后,和上次请求一样的请求数据其实是不必要的请求,所以我们使用 distinctUntilChanged ,此是如何运作的呢?直接上图!
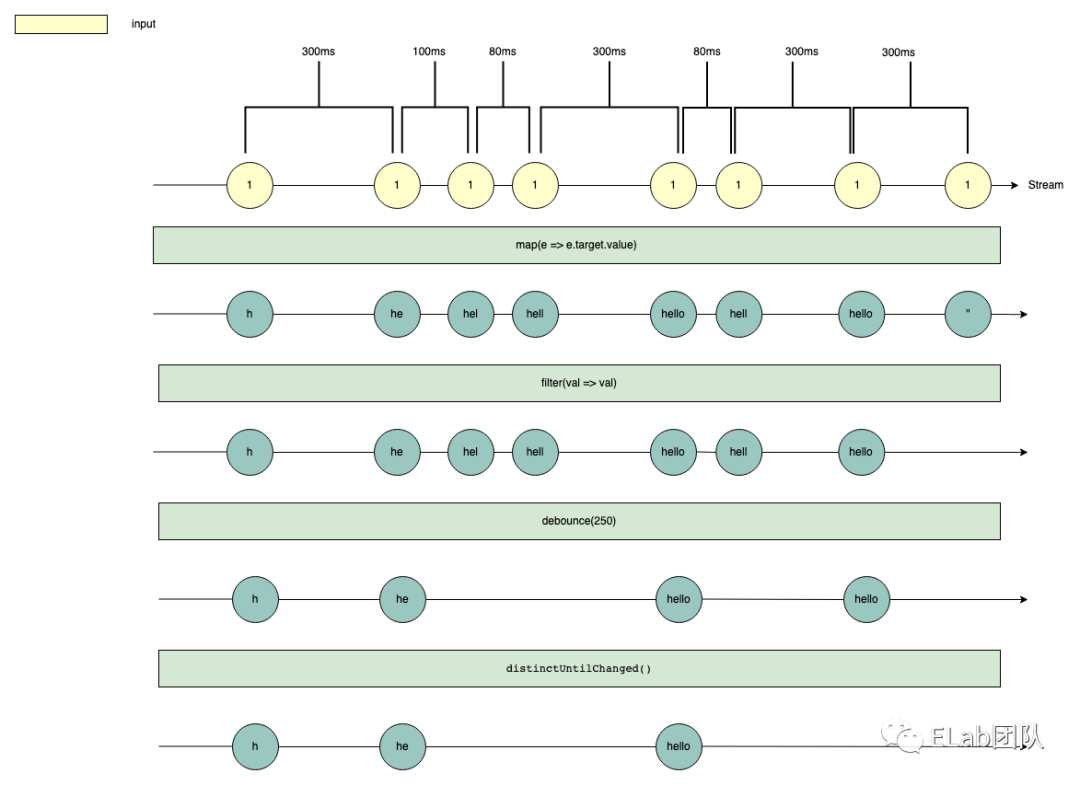
distinctUntilChanged 处理之后就不会派发新的事件,最后只剩下三个事件。
最后我们需要处理竟态,因为这里我们在例子中并没有出现竟态的情况,所以这里仅仅是说明,具体的竟态读者可以自行实现,有问题可以找我探讨
我们直接使用 RxJS 文档里关于 switchMap 的弹珠图来说明什么是竟态,以及如何处理竟态:
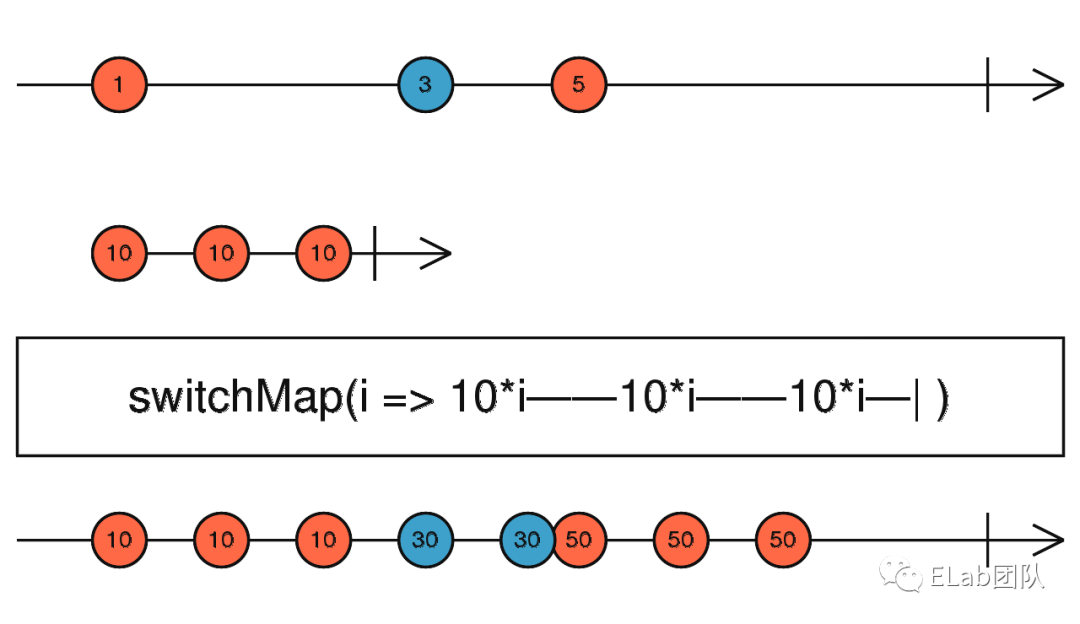
switchMap 主要做的事情有两件:
- 对 source Observable 进行 map 操作,map 操作时的每一项都会被压平之后以 Observable 的形式返回
- 按照原 source Observable 的时序,map 操作之后,前一个事件被压平的 Observable 如果有超过后一个事件的,那么选择后一个事件,而丢弃前一个事件
这两句话有点绕,我们画个弹珠图来解释一下:
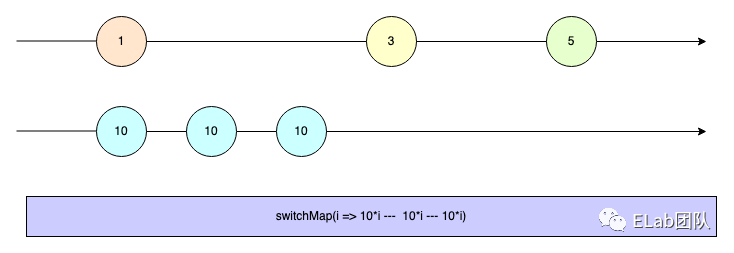
switchMap 的作用,接下来我们来画图解释一下我们之前业务需求里面使用 switchMap 的效果:
useEffect(() => {
const inputSearch = document.querySelector(".search");
fromEvent(inputSearch, "input")
.pipe(
map((e) => e.target.value),
filter((val) => val),
debounceTime(250),
distinctUntilChanged(),
switchMap((val) => searchWikiPedia(val))
)
.subscribe((data) => {
setItems(data[1] || []);
});
}, []);
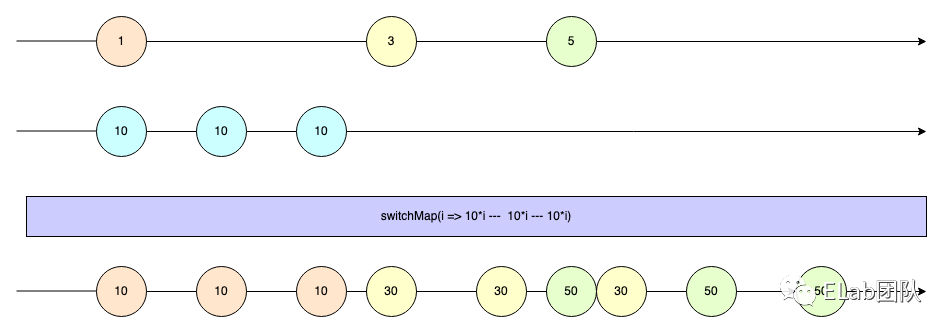
searchWikiPedia 请求为例,经过 switchMap 之后,会映射成下面两个紫色的 Stream:
1 . 第一个紫色的 Stream 中代表 searchWikiPedia(value) 生成的 Promise,这个 Promise 被转为了 Observable 对象,然后隔了 400ms 时间 Promise resolved 之后会派发一个事件
2 . 第二个紫色的 Stream 中代表 searchWikiPedia(value) 生成的 Promise,这个 Promise 被转为了 Observable 对象,然后隔了 200ms 时间 Promise resolved 之后会派发一个事件
3 . 第三个紫色的 Stream 中代表 searchWikiPedia(value) 生成的 Promise,这个 Promise 被转为了 Observable 对象,然后隔了 200ms 时间 Promise resolved 之后会派发一个事件
最后映射压平之后的中间态如下:
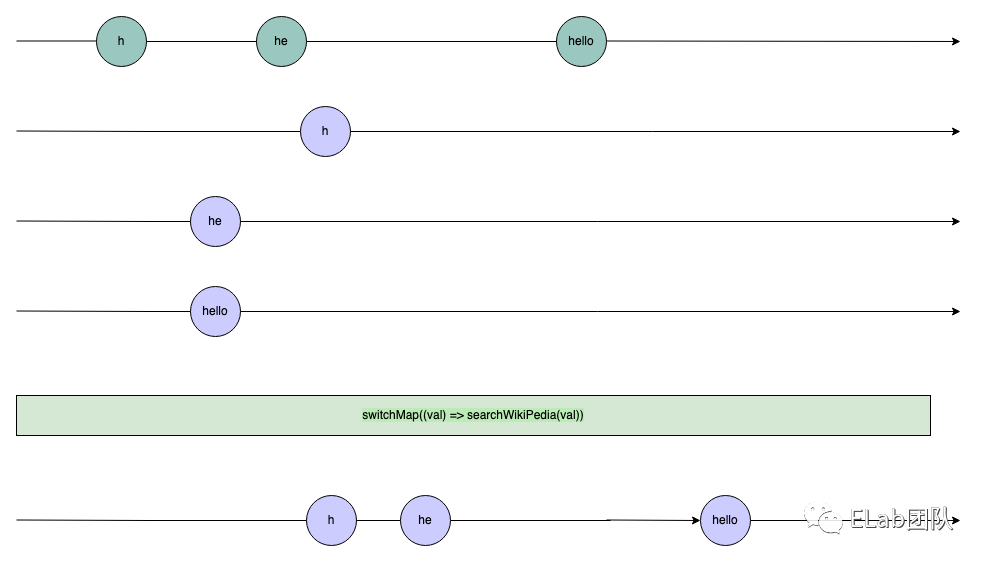
- 我输入了 he,但是显示的是 h 的结果,会让用户觉得很奇怪
而我们使用了 switchMap 之后,最后要做的操作就是按照原 source Observable 的顺序,丢掉那些时间不对的 observable,即中间的那个 h 响应会被丢弃,变成如下结果:
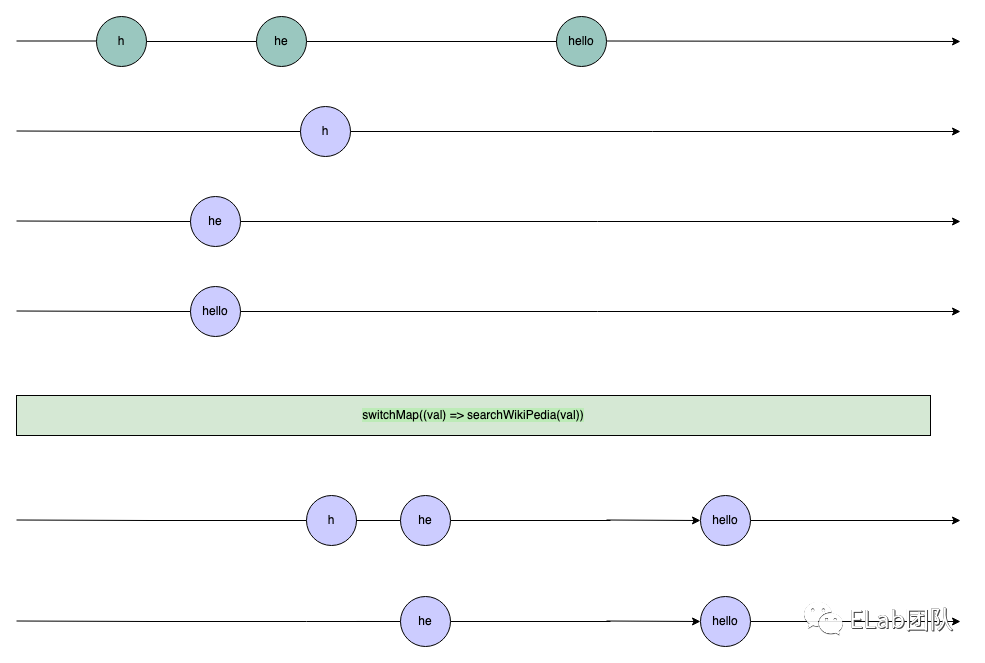
懂了吗?是不是很绕。。。

可能是 RxJS 最适合前端的角色:接口防腐层
其实到目前为止,我们都是通过例子强加 RxJS 的实现,虽然看起来很牛逼,加了函数式编程,让过程变得更加声明式,写起来看起来更加高级,但是 Stream 的概念或许没有想象的那么易懂,这就导致 RxJS 在平时的业务开发中很难实际应用进去,就像单纯的函数式编程也很难应用一样,或许针对上面提到的 AutoComplete 搜索框的实现场景,我们使用 RxJS 就如鱼得水,但是在平时的业务开发场景里,上述业务需求只是众多业务需求中的一个,一旦过了这种业务需求,我们再想拾起 RxJS 就会变得很困难。
让我们再来梳理一下在线教室使用到 RxJS 的场景,大致有如下几种:
- 通过
Emiiter.on(type)将多种事件、信令类型注册在一个全局的状态 Store,包括播放器的EventType、信令的ValidChannelMessageTypes等,然后在需要的地方按需引用使用 - 状态机信令以及相关依赖模块信令,通过 RxJS Subject(一种多播的 Observable)实现相互订阅,即状态机信令状态变化,通知到依赖模块,如学生列表,学生列表状态变化,通知到状态机信令,同时信令又包含长链,高低有短链,混杂 WebSocket 与轮询,与普通的一次性的 HTTP 请求模型不太一样
- 长链,高低优短链的状态归并处理,竟态处理...
- 某个模块依赖另外一个模块,通过 IoC 注入进来,然后订阅对应模块的状态,如注入
room模块,然后订阅this.room.destory$的销毁状态,执行后续的操作 - 模块自身内部处理一些内部异步状态,如
webview模块,监听页面内容的 JavaScript是否正常运行 - .....
可以看到在线教室除了核心的状态机信令及其对应模块的信令等包含 WebSocket、轮询的模块使用了 RxJS 来建模外,针对各种异步处理的情况也是遵循能使用则使用的原则,这个其实也是充分发挥了 RxJS 的潜力,但是这种多元的使用方式不免混淆了我们的视听,即 RxJS 最适合前端的使用的场景到底在哪里,我们能够高频使用 RxJS 的场景又在哪里?
回看前端架构
无论是 MVC 还是 MVVM,其实我们作为前端主要的期待是 View 层的稳定,即用户能够顺畅的跑通整套业务流程,那针对这样一个目标进行合理的取舍,我们就会得到如下结论:
“写厚 Service 层,写薄 View 层,然后对 Service 层进行高覆盖、大规模单测”
纵观整个前端开发工程体系,最复杂多变不稳定的模块就是来自于与外部应用的交互,无论是 HTTP、WeboSocket 等接口调用方面,需要处理超时重试、去重、防抖、竟态等等,还是接口的更迭导致的不兼容,或者需要兼容多套接口等。这些与外部应用的交互状态如果处理的不好,则会影响我们前端的根基:View 层面的内容。

图片来自 2021 DevFest 杭州:如何使用 RxJS 构建稳健的前端应用https://www.zhihu.com/zvideo/1458183228482318336,侵权删。
我们来看一下接口影响到前端业务层面的几种典型情况:
1 . 如接口从 V1 变更到 V2,返回的数据结构变了,那么组件层面拿到的数据也就变了,而我们也需要随之修改组件层面的使用方式
// v1 response
{ usage: 1.3 }
// v2 response
{ data: { usage: 1.3 }, errMsg: null }// MemoryUsage.tsx
import React, { useEffect, useState } from "react";
function MemoryUsage() {
const [usage, setUsage] = useState<number>(0);
useEffect(() => {
(async () => {
// v1
const result = await fetch("/api/v1/memory/usage");
const data = await result.json();
// v2
const result = await fetch("/api/v2/memory/usage");
const { data } = await result.json();
setUsage(data);
})();
}, []);
return <div>Usage: {usage} GB</div>;
}
export default MemoryUsage;以上和以下的 Client 与 Server 端的代码参考自:https://github.dev/vthinkxie/rxjs-acl/blob/master/src/server/index.ts
2 . 随着版本迭代,我们的调用方式可能也需要发生改变,之前需要调用两个接口的,但是服务端优化之后变成了调用一个接口就可以解决问题
// V1
app.get("/api/v1/memory/free", function (req, res) {
return res.json(free);
});
app.get("/api/v1/memory/usage", function (req, res) {
return res.json(usage);
});
// V2
app.get("/api/v3/memory", function (req, res) {
return res.json({ requestId: randomUUID(), data: { free, usage } });
});3 . 有时候需要维护旧版本的接口,如 V1 和 V2 需要同时保证可用
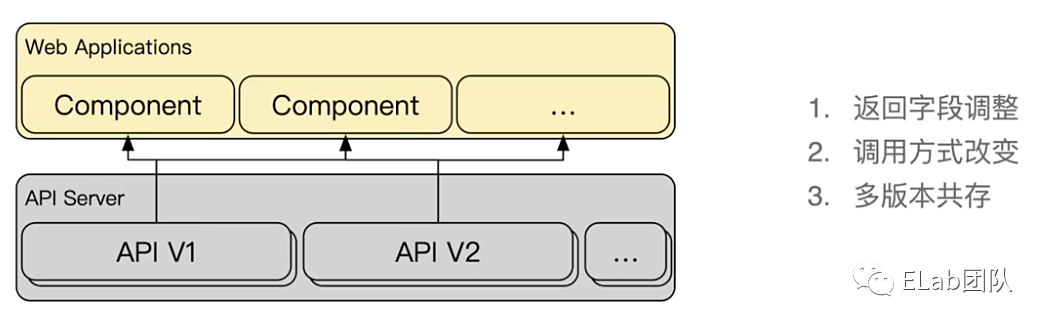
图片来自 2021 DevFest 杭州:如何使用 RxJS 构建稳健的前端应用https://www.zhihu.com/zvideo/1458183228482318336,侵权删。
4 . 当我们维护一个平台型 toB 应用时,除了服务端的 API,可能还需要对接各种平台的 API,比如平台的 CEF 的 API,或者使用的 监控 API,使用的 RTC 的 API 等,然后这些 API 也可能存在字段更高、调用方式的改变,多版本共存的情况,这就会让我们前端维护的外部状态变得非常复杂

图片来自 2021 DevFest 杭州:如何使用 RxJS 构建稳健的前端应用https://www.zhihu.com/zvideo/1458183228482318336,侵权删。


回归本质
得益于 RxJS 可以很好的统一同步、异步数据,统一 Promise、回调函数、WebSocket 与 Http 调用等,使得这些内容都能够按照统一的操作符、流程进行处理,正如如下图所示:
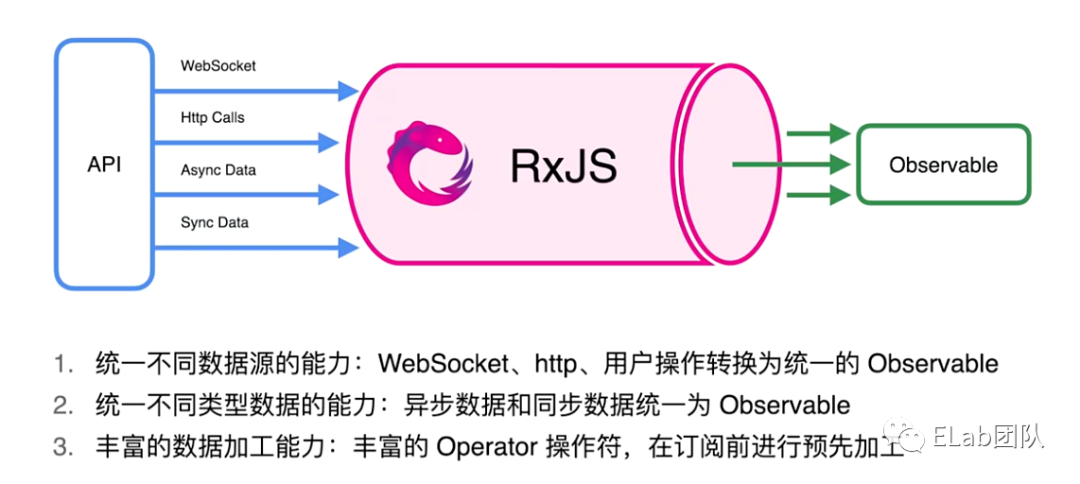
图片来自 2021 DevFest 杭州:如何使用 RxJS 构建稳健的前端应用https://www.zhihu.com/zvideo/1458183228482318336,侵权删。
那我们是不是可以很自然的想到,如果使用 RxJS 接管前端与外部应用状态交互这部分角色,或者说 Service 层,然后组件层面(View)只需要与 Service 层进行交互:
1 . 确保自己需要对数据进行改变时,通知 Service 层进行处理
2 . 当需要对数据进行渲染时,确保 Service 层给到合适的数据
a . 无论外部应用状态如何获取、处理、合并、加工等,都由 Service 层去处理
b . 无论外应用状态如何变化,接口字段改变、调用方式改变、多版本共存等,都由 Service 层去处理
让我们拿上面提到的那些问题现状来提个需求:
现在接口可能存在多个版本,然后在 V2/V3 时调用方式也发生了变化,之前 V2 调用需要两个接口,但是 V3 进行了重构,只需要一个接口即可以获取之前两个接口获取的内容。
如果是之前的形式,将接口内联到组件内部:
import React, { useEffect, useState } from "react";
function MemoryUsagePercent() {
const [percent, setPercent] = useState<number>(0);
useEffect(() => {
(async () => {
const free = await fetch("/api/v2/memory/free");
const freeData = await free.json();
const usage = await fetch("/api/v2/memory/usage");
const usageData = await usage.json();
setPercent(+((usageData / (usageData + freeData)) * 100).toFixed(2));
})();
}, []);
return <div>Usage Percent: {percent} %</div>;
}
export default MemoryUsagePercent;如果调用方式改变之后,变成了如下这样:
import React, { useEffect, useState } from "react";
function MemoryUsagePercent() {
const [percent, setPercent] = useState<number>(0);
useEffect(() => {
(async () => {
const memory = await fetch("/api/v3/memory");
const memoryData = await memory.json()
const { usage, free } = memoryData;
setPercent(+((usage / (usage + free)) * 100).toFixed(2));
})();
}, []);
return <div>Usage Percent: {percent} %</div>;
}
export default MemoryUsagePercent;可以看到如果调用方式改变之后,我们需要对代码进行大量的修改,而且原计算内存占用率的公式也需要随之调整,当然我们上述的逻辑还没有实现一些必要的逻辑:
1 . 多版本共存,如果 V3 的接口不可用,我们需要 backup 到 V2 的接口
2 . 如果 V2/V3 都不可用时,我们可能需要数据兜底,才能保证应用不会崩溃
我们现在来实现一下上述逻辑:
import React, { useEffect, useState } from "react";
function MemoryUsagePercent() {
const [percent, setPercent] = useState<number>(0);
useEffect(() => {
(async () => {
try {
// 首先使用 V3 接口
const memory = await fetch("/api/v3/memory");
const memoryData = await memory.json()
const { usage, free } = memoryData;
setPercent(+((usage / (usage + free)) * 100).toFixed(2));
} catch (err) {
try {
// 如果不可用,就使用 V2
const free = await fetch("/api/v2/memory/free");
const freeData = await free.json();
const usage = await fetch("/api/v2/memory/usage");
const usageData = await usage.json();
setPercent(+((usageData / (usageData + freeData)) * 100).toFixed(2));
} catch (err) {
// 如果 V2/V3 都不可用,直接 backup 一个兜底数据
setPercent(0.00)
}
}
})();
}, []);
return <div>Usage Percent: {percent} %</div>;
}
export default MemoryUsagePercent;可以看到上述逻辑再引入了多版本共存、数据兜底之后,组件层变得异常复杂,而且各种中间字段的含义实际上这个组件本来是无需去感知的,但是为了进行对应的数据处理以得到最后的效果,我们需要编写大量的 try/catch 、中间变量等,如果此组件自身的 UI/逻辑还比较复杂,那么接口逻辑与组件自身逻辑混杂在一起就会变得特别混乱,而且后续一旦有新的变化,那么这个组件可能会轻易就崩溃了。当然有的同学会说,我们可以通过自动化测试来保障质量,但是将组件与外部状态混杂在一起的自动化测试实施会比较困难。
如果引入 Service 层的概念之后,通过 RxJS 来作为实现,我们上述的例子可以修改成如下这样:
import React, { useEffect, useState } from "react";
import { lastValueFrom } from "rxjs";
import { getMemoryUsagePercent } from "./service";
function MemoryUsagePercent() {
const [percent, setPercent] = useState<number>(0);
useEffect(() => {
(async () => {
const result = await lastValueFrom(getMemoryUsagePercent());
setPercent(result);
})();
}, []);
return <div>Usage Percent: {percent} %</div>;
}
export default MemoryUsagePercent;// service.ts
import {
catchError,
forkJoin,
map,
mergeMap,
Observable,
of,
race,
} from "rxjs";
import { fromFetch } from "rxjs/fetch";
export function getMemoryLegacy(): Observable<{ free: number; usage: number }> {
const legacyUsage = fromFetch("/api/v2/memory/usage").pipe(
mergeMap((res) => res.json())
);
const legacyFree = fromFetch("/api/v2/memory/free").pipe(
mergeMap((res) => res.json())
);
return forkJoin([legacyUsage, legacyFree], (usage, free) => ({
free: free.data.free,
usage: usage.data.usage,
}));
}
export function getMemory(): Observable<{ free: number; usage: number }> {
const current = fromFetch("/api/v3/memory").pipe(
mergeMap((res) => res.json()),
map((data) => data.data)
);
return current.pipe(
catchError(() => getMemoryLegacy()),
catchError(() => of({ usage: 0.0, free: 10.0 }))
);
}
export function getMemoryUsagePercent(): Observable<number> {
return getMemory().pipe(
map(({ usage, free }) => +((usage / (usage + free)) * 100).toFixed(2) || 0)
);
}可以看到我们的 View 层和接口有关的逻辑变成了短短的一行具有语义化的函数调用,主要是通过 RxJS 的 lastValueFrom Operators 来获取最近的一次结果(注意这里需要最近的一次结果,原因是 getMemoryUsagePercent 是一个 Stream,所以直接 subscribe 的话会依次从 Stream 的起点开始逐步返回数据),这样 View 层就只无需关注所需的数据是怎么来的,只需要关心拿到自己需要的数据进行渲染即可。
而对应的我们抽出了对应的 Service 层代码,在 Service 层里面我们使用 RxJS 来进行逻辑实现,可以看到我们做了如下几件事:
1 . 声明了 getMemoryLegacy 与 getMemory 两个方法,一个是 V2 版本的获取方式,一个是 V3 版本的获取方式,V3 将之前需要两个接口合并成了一个接口
2 . 在 getMemoryLegacy 中我们使用 forkJoin 将两个接口的返回结果合并并返回,getMemory 则是首先声明一个获取 V3 接口的 Stream,然后通过 race 让 V3 与 V2 的结果进行 “赛跑”,那个先成功返回则使用哪个,如果两个都失败了,那么提供一个兜底数据 { usage: 0, free: 0 }
3 . 最后 getMemoryUsagePercent 则是拿最后的结果进行计算,然后给到 View 层去使用
可以看到我们在 Service 层做了大量的合并、静态、兜底,并且处理了多版本共存等问题,其中数据兜底其实相当于我们前端直接实现了数据的 Mock,而无需一些 Mock 服务器的搭建,后面无论接口如何变化,无论是返回字段、调用方式、多版本共存,还是各种处理网络状况等情况,我们都可以在 Service 层(防腐层)去进行修改、适应,通过 RxJS 将这些内容简洁、有机的串联在一起的同时,保证了 View 层干净漂亮!
较为理想的情况下,如果前端应用极其复杂,可以派出一人专注于维护 Service 层,以及与服务端、各种 Platform API 打交道,专注于对这些接口进行合理的设计、转换、合并、Mock 等(前端层面的 BFF),然后让这个人充当其他前端同学与接口之间的中间人,减少多人参与带来的重复性劳动与规范不一致性。

为什么选 RxJS?
说到这里,可能有一些小伙伴有疑问了,为什么一定是 RxJS?
其实选择 RxJS 来实现前端防腐层还有一层理解,即虽然在前端的发展历史中,为了保证接口的架构稳定,我们发展了一代又一代方法:从 GraphQL,到 BFF,再到 RxJS
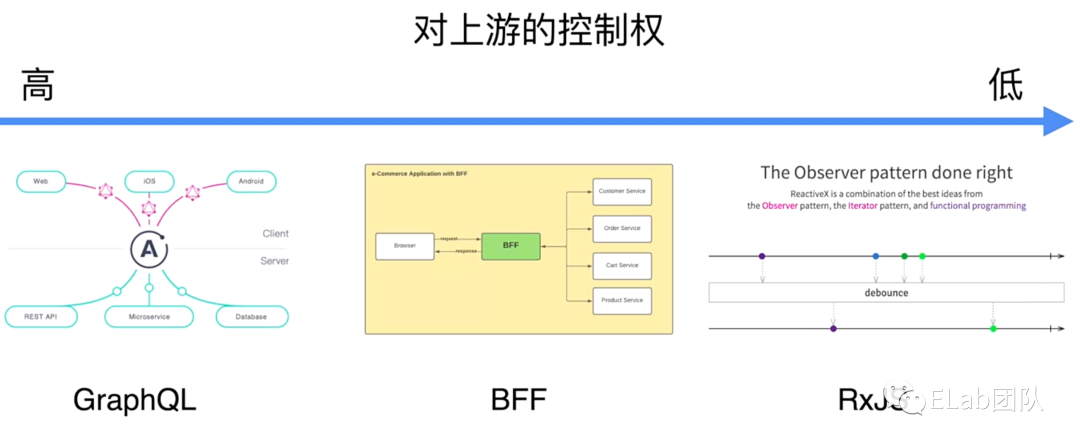
图片来自 2021 DevFest 杭州:如何使用 RxJS 构建稳健的前端应用https://www.zhihu.com/zvideo/1458183228482318336,侵权删。
那么为什么我们需要选择 RxJS 作为前端接口防腐层呢?其实取决于对上游的控制权:
- GraphQL 需要服务端配合改造
- BFF 同样需要部署服务器资源
- 而 RxJS 可以直接跑在浏览器上,受前端直接控制,并且可以完成前两者同样的事情
更近一步,实现前端状态管理
随着 React Hooks 的发布,RxJS 从作为 Service 层充当前端防腐层的角色,可以扩充到承担起整个前端状态管理的职责,在状态管理中对外接口设计,可以使用 RxJS 进行合理的封装,而针对应用的其他状态,通用可以通过 RxJS 来进行管理、分发。
前端状态管理最重要的里程碑之一是基于 Flux 架构实现的 Redux,它的单向数据流的思想很好的支撑起构建大型应用的使命,但是 Redux 有种种问题,让我们来细数一下:
1 . 实现一个状态的处理,需要先在 Store定义,然后定义 Action ,通过 Dispatch Action 来修改 State,然后经过 Reducer 的 switch case 进行过滤处理,更新状态,接着通过 mapStateToProps 将修改的状态丢入组件内进行渲染,完成一次状态的全流程,整个流程复杂、样本代码繁多
2 . 因为状态更新的流程比较复杂,随着而来的是 Debug 比较困难,基本上只能通过 Redux Devtools 去查看,当状态比较复杂时,很难去剥离出当前 Action 待修改的状态
3 . 当需要处理异步情况时,事情会变得更加复杂,我们需要添加 Middleware,如 redux-thunk、redux-saga 等,这会使得原本就很复杂的情况变得更加难懂
4 . 因为 Redux 天生是单向数据流,如果遇到一些事件、WebSocket 等异步处理时,很难去将这些异步状态与 Redux 的单向数据流整合起来
5 . Redux 的单向数据流是具有传染性的,如果某个子包使用了 Redux,要接入这个子包,也得去使用 Redux
6 . 结合 TypeScript 的使用体验糟糕
7 . ....
上述问题可以具体观看 Redux 的官方文档了解,Redux 官方文档通过一个经典的 TodoList 来介绍如何使用 Redux[2]。

话不多说,先看个用 RxJS 实现 Redux TodoList 的例子:
// service/todo.ts
import { BehaviorSubject } from 'rxjs';
export interface ITodo {
text: string;
completed: boolean;
}
export enum VisibilityFilter {
SHOW_ALL,
SHOW_COMPLETED,
SHOW_ACTIVE,
}
export default class TodoService {
todos = new BehaviorSubject([
{
text: 'hello rxjs state management',
completed: false,
}
]);
visibilityFilter = new BehaviorSubject(VisibilityFilter.SHOW_ALL);
addTodo(text: string) {
let todos = this.todos.value;
todos = todos.concat({
text,
completed: false,
});
this.todos.next(todos);
}
toggleTodo(index: number) {
let todos = this.todos.value;
todos = todos.map((todo, i) => (i === index ? { text: todo.text, completed: !todo.completed } : todo));
this.todos.next(todos);
}
setVisibilityFilter(filter: VisibilityFilter) {
this.visibilityFilter.next(filter);
}
}// service/index.ts
import TodoService from "./todo";
export const todoService = new TodoService();// hooks.ts
import { useState, useEffect, EffectCallback } from 'react';
import { BehaviorSubject } from 'rxjs';
export function useObservable<T>(observable: BehaviorSubject<T>) {
const [val, setVal] = useState(observable.value);
useEffect(() => {
const subscription = observable.subscribe(setVal)
return () => subscription.unsubscribe();
}, [observable])
return val;
}// index.tsx
import React from 'react';
import { useObservable } from './hooks';
import { todoService } from './services';
import { ITodo, VisibilityFilter } from './services/todo';
export default function() {
const todos = useObservable(todoService.todos);
const filter = useObservable(todoService.visibilityFilter)
const visibleTodos = getVisibleTodos(todos, filter);
return (
<div>
<ul>
{visibleTodos.map((todo, index) => (
<TodoItem key={index} todo={todo} index={index} />
))}
</ul>
<p>
Show: <FilterLink filter={VisibilityFilter.SHOW_ALL}>All</FilterLink>,
<FilterLink filter={VisibilityFilter.SHOW_ACTIVE}>Active</FilterLink>,
<FilterLink filter={VisibilityFilter.SHOW_ALL}>Completed</FilterLink>
</p>
</div>
);
}
const FilterLink = ({ filter, children }: { filter: VisibilityFilter; children: React.ReactNode }) => {
const activeFilter = useObservable(todoService.visibilityFilter);
const active = filter === activeFilter;
return active ? (
<span>{children}</span>
) : (
<a href="" onClick={() => todoService.setVisibilityFilter(filter)}>
{children}
</a>
);
};
const TodoItem = ({ todo: { text, completed }, index }: { todo: ITodo; index: number }) => {
return (
<li
style={{
textDecoration: completed ? "line-through" : "none",
}}
onClick={() => todoService.toggleTodo(index)}
>
{text}
</li>
);
};
function getVisibleTodos(todos: ITodo[], filter: VisibilityFilter): ITodo[] {
switch (filter) {
case VisibilityFilter.SHOW_ALL:
return todos;
case VisibilityFilter.SHOW_COMPLETED:
return todos.filter(t => t.completed);
case VisibilityFilter.SHOW_ACTIVE:
return todos.filter(t => !t.completed);
}
}上述例子实现效果如下:
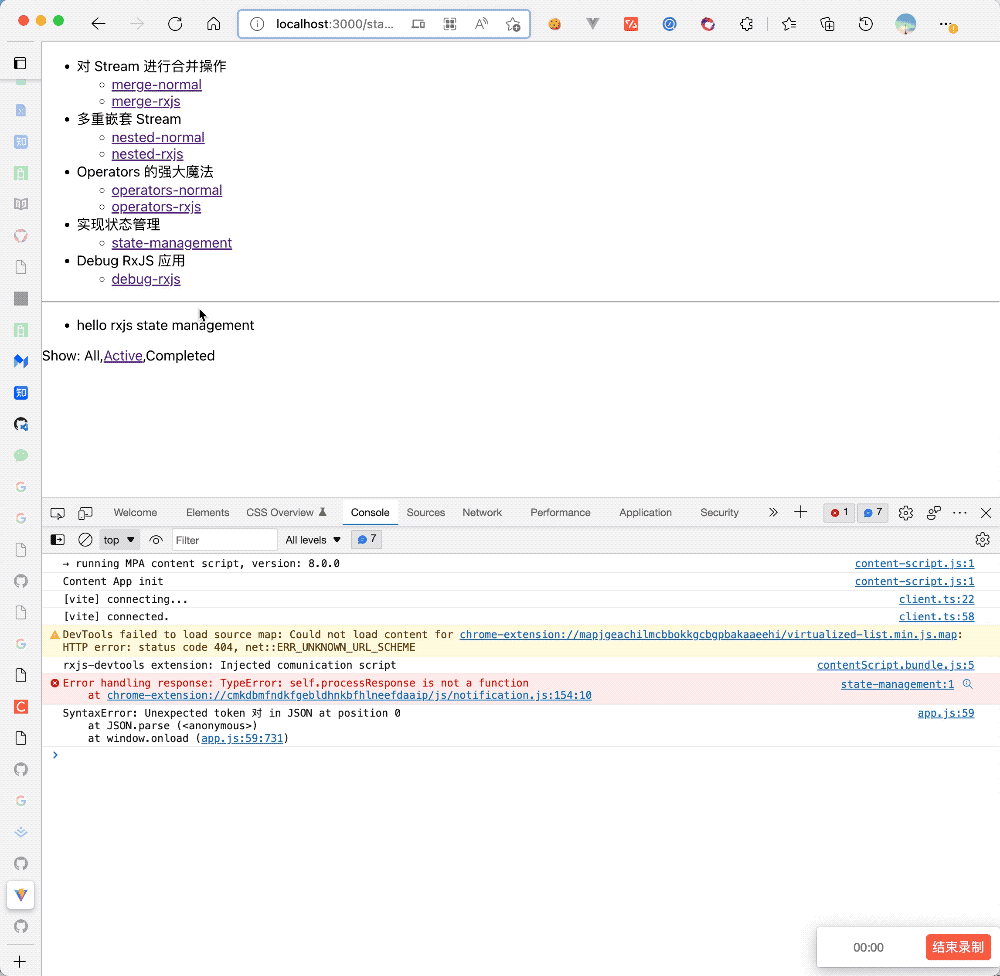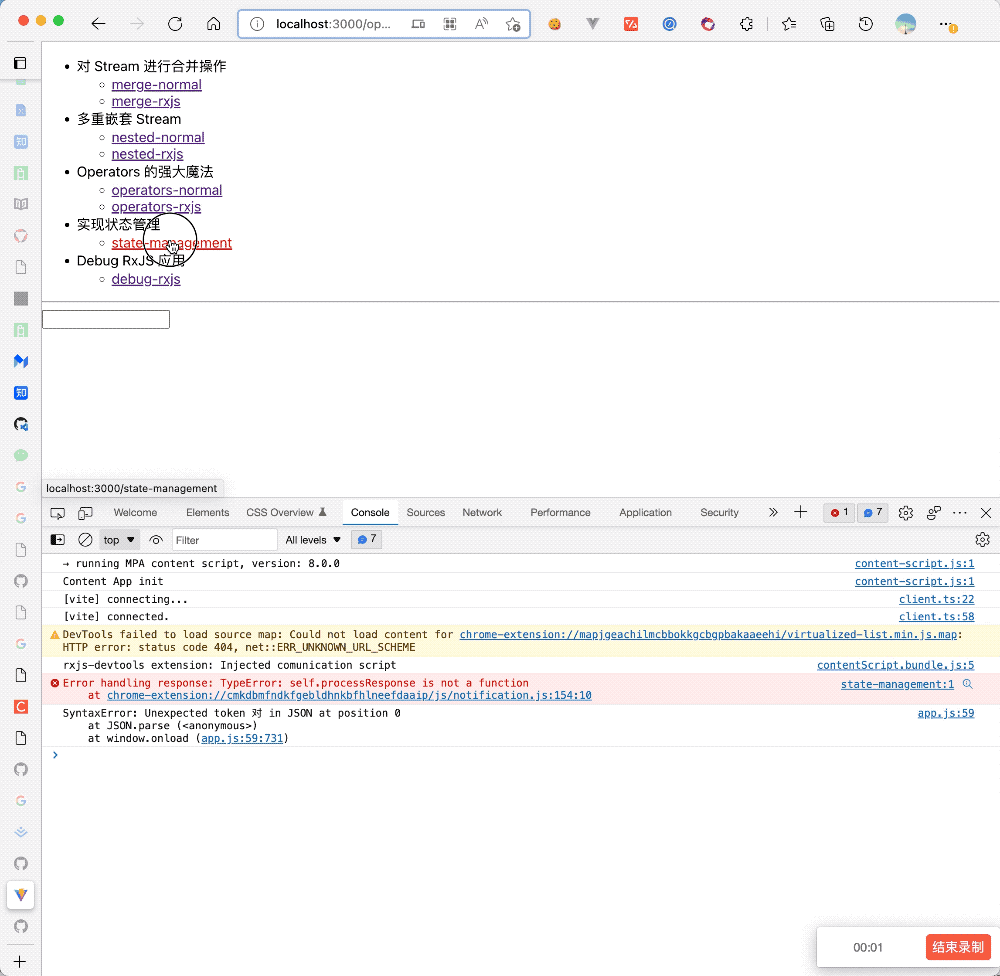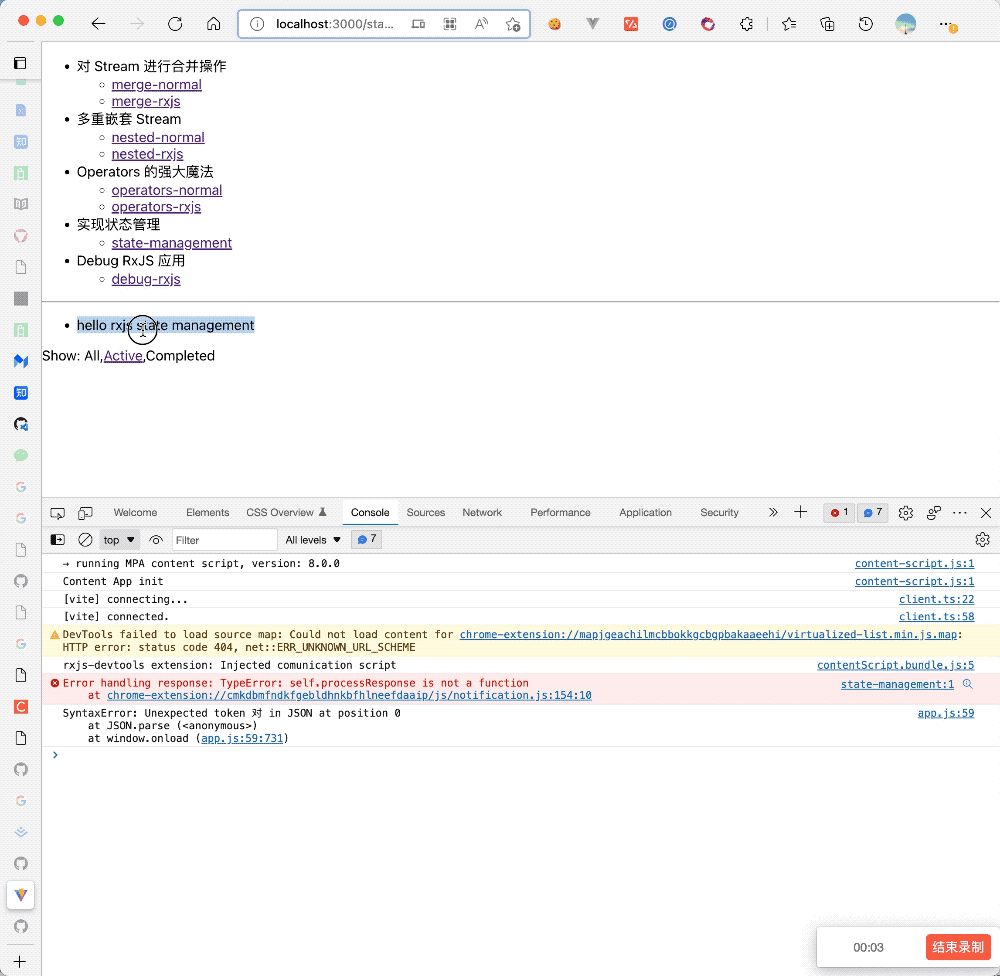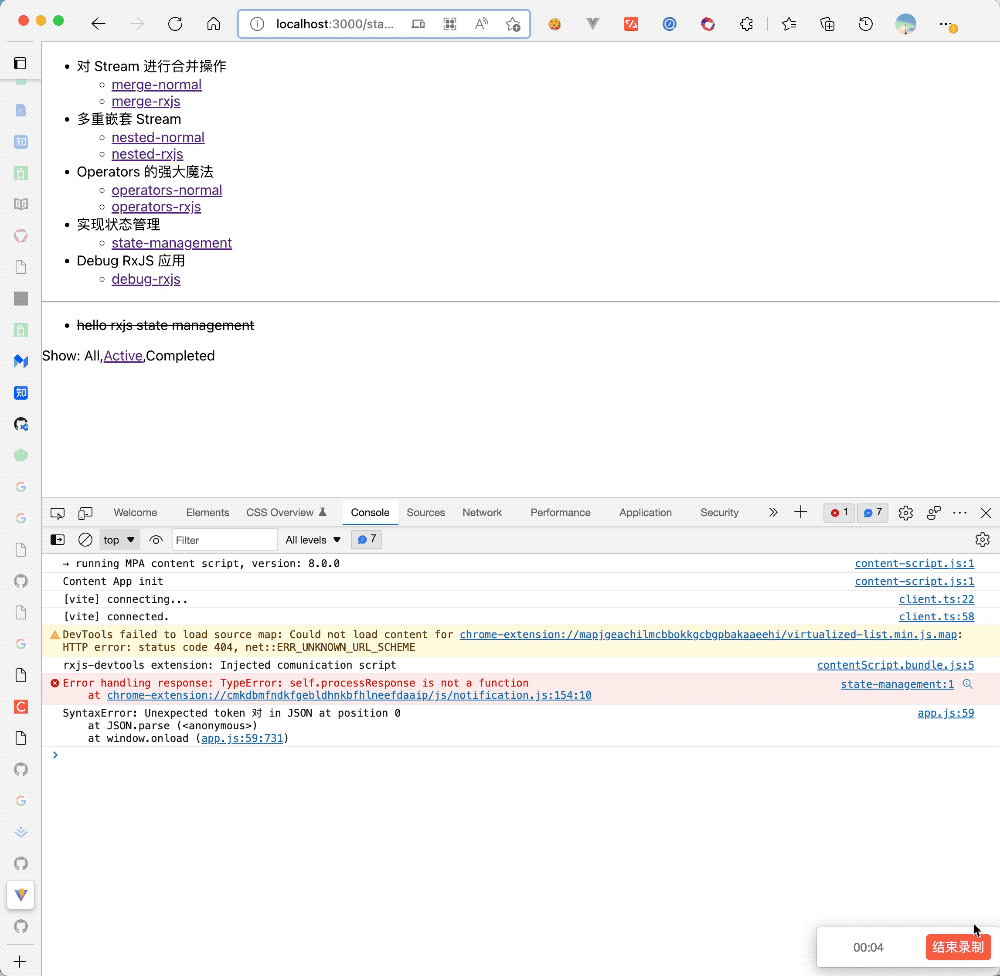
- 状态的 Model 与组件一一对应,状态清晰、Debug 清晰,没有样板代码,非常简介,调用
todoService.toggleTodo等方法时,更新 Service 状态,然后通过useObservable钩子自动触发视图更新 - 当其他组件需要使用到这个状态时,直接通过
useObservable导入使用 - 使用非常简单,没有中间层,如果组件部分出错了,那么问题基本上就可以通过断点调试在 Service 层发现
- 开箱即用的 TypeScript 支持,无需一些 Trick
- RxJS Observable 或者说 Stream 天然就是 Immutable 的,所以也无需 immer 之类的库来保证数据的不可突变性
- 借助 RxJS,可以在处理接口设计时起到非常强大效用,可以直接使用 Async/Await 来处理异步逻辑
- 等等...
当然我们这里实现的 useObservable 钩子还非常 Naive,更加生产化的实现可以参考以下这两个库:
- https://github.com/LeetCode-OpenSource/rxjs-hooks(目前已经不维护,推荐后者)
- https://observable-hooks.js.org/guide/
这种使用 RxJS 实现状态管理的方式也比较 Naive,更成熟的方案可以参考 CycleJS[3]。
Redux 与 RxJS 状态管理的区别?
Redux 是基于 Flux 架构的实现,是典型的单向数据流体现:
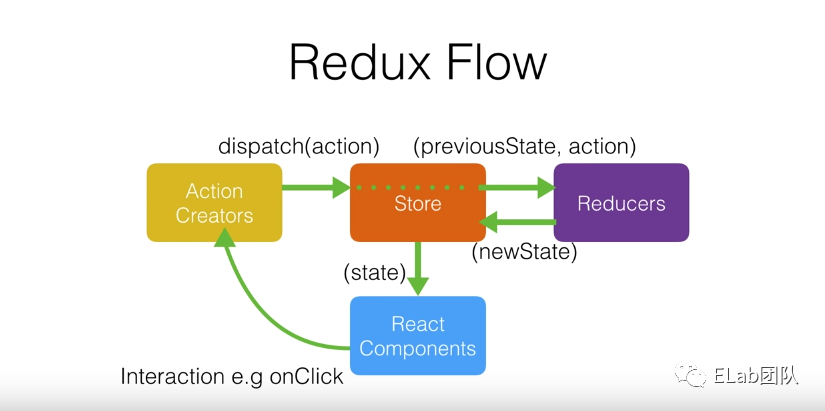
1 . Single Source of Truth:单一 Store,类似前端数据库
2 . Every state change must dispatch action:每次 State 更改一定有对应的 Action
3 . Reducer must be pure function:Reducer 操作数据时必须返回新的数据,而不能对元数据进行突变
4 . Every component state is a slice of Store:即某个组件的状态是 Store 这个全局状态的一个切片
而 RxJS 则是 for Component 的,一份 UI 对应一份 Service 的分形架构:
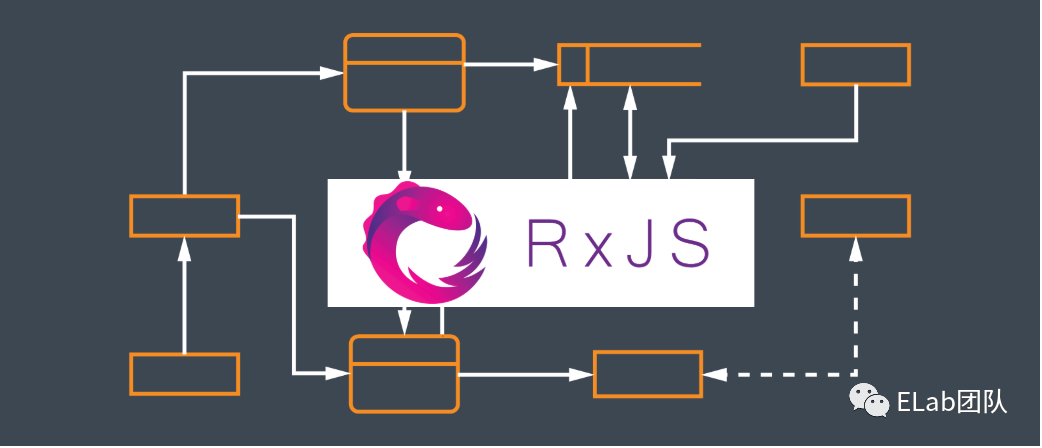
1 . 组件与数据流融为整体,与外部数据流隔离,甚至将数据处理也融合在了数据流管道中,便于调试
2 . 便于组件复用,因为数据流是组件的一部分,不具有传染性
3 . 可以挂载在全局 Store 中,这样可以在全局可以在局部进行调试,较为灵活
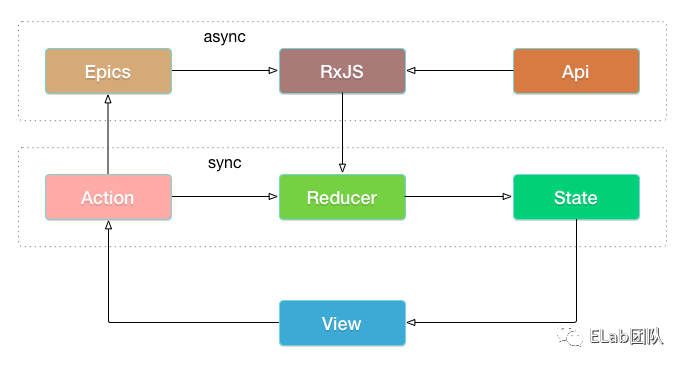
当然也有将 RxJS 整合进 Redux 去使用:redux-observable[4],它的数据流架构图如下:

如何 Debug RxJS 应用?
到这里我们基本上介绍了 RxJS 在前端的主要应用场景,包括实现较为复杂、异步的搜索框组件;承接前端接口防腐层;参与前端状态管理等,讲了那么多 RxJS 的优点,那么也要正视它的一些缺点,其中最主要的痛点之一就是 Debug RxJS 应用,那么何来之痛呢?
看一段上面提到的代码:
const inputSearch = document.querySelector(".search");
fromEvent(inputSearch, "input")
.pipe(
map((e) => e.target.value),
filter((val) => val),
debounceTime(250),
distinctUntilChanged(),
switchMap((val) => searchWikiPedia(val))
)
.subscribe((data) => {
setItems(data[1] || []);
});凭你十几年的编程经验,能想到如何调试这段程序?

使用 Tap 操作符
主要是因为这个是某个领域特定的写法,所以需要遵循这个领域特定的调试方法,在 RxJS 这个领域下,有一个名为 tap 的操作符,它的引入不会对后续的 Stream 产生影响,所以用它来进行 Debug 操作已经成为 RxJS 届的共识,看一个例子:
import { interval, tap } from 'rxjs';
const example = interval(1000)
.tap(x => console.log(`tap log: ${x}`)
.map(x => x + 1)
.subscribe(x => {
console.log(`subscription log: ${x}`);
});
// tap log: 0
// subscription log: 1
// tap log: 1
// subscription log: 2画出 Marble 图
当我们遇到复杂的 RxJS 代码时,如果通过 Tap 无法轻易的看出程序是如何执行的,因为 Tap 只能拿到某个中间的执行结果,但是无法可视化中间的执行过程,那么我们就可以通过之前介绍的,从 Stream 的起始态、中间态、错误态、完成态触发,通过 Marble 图体现 Stream 的变换,然后通过 Tap 验证变换的结果。
然后继续回顾上面的例子:
const inputSearch = document.querySelector(".search");
fromEvent(inputSearch, "input")
.pipe(
map((e) => e.target.value),
filter((val) => val),
debounceTime(250),
distinctUntilChanged(),
switchMap((val) => searchWikiPedia(val))
)
.subscribe((data) => {
setItems(data[1] || []);
});
借助专业的调试库和可视化工具
如果对 RxJS 熟悉的小伙伴应该能发现,我们要面对的实际上不是一次性的程序执行,而是面对一个个的 Stream,按照时间的维度,会不断的产生事件,保不准那次会出现错误,如果我们光通过 tap 来进行一股脑的打印,那么我们的 Console 将满屏的输出,很难抓住调试的重点,当然还有种种具体场景具体分析的问题。
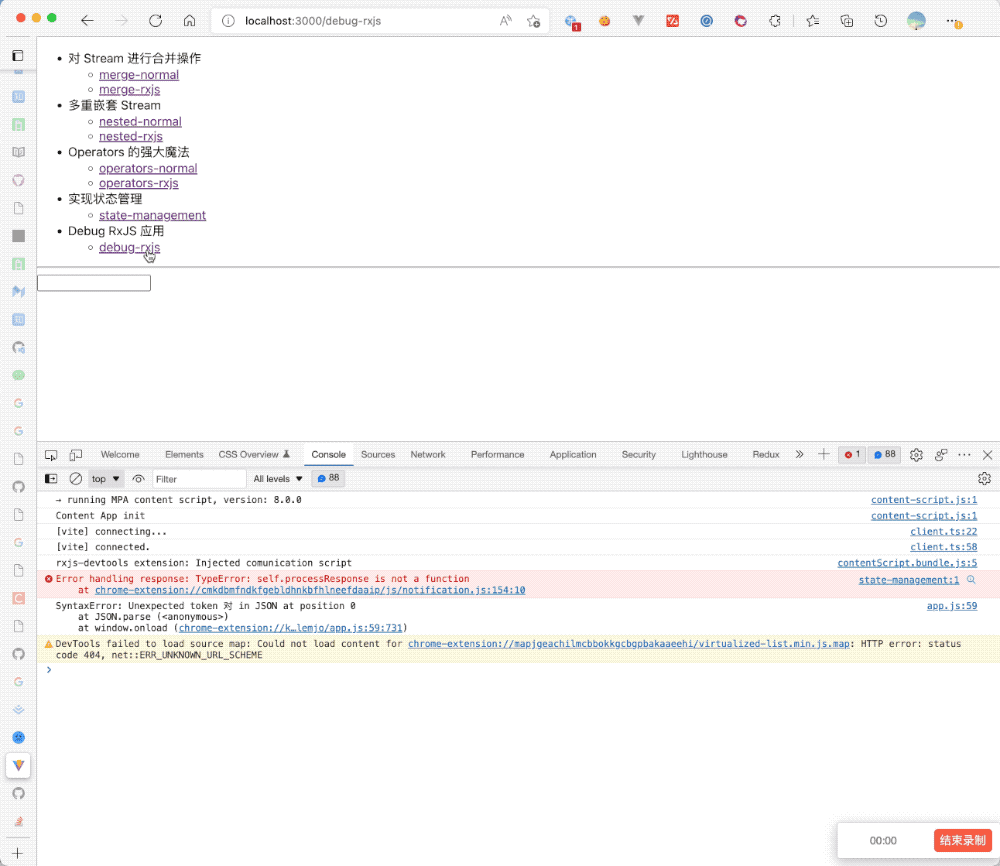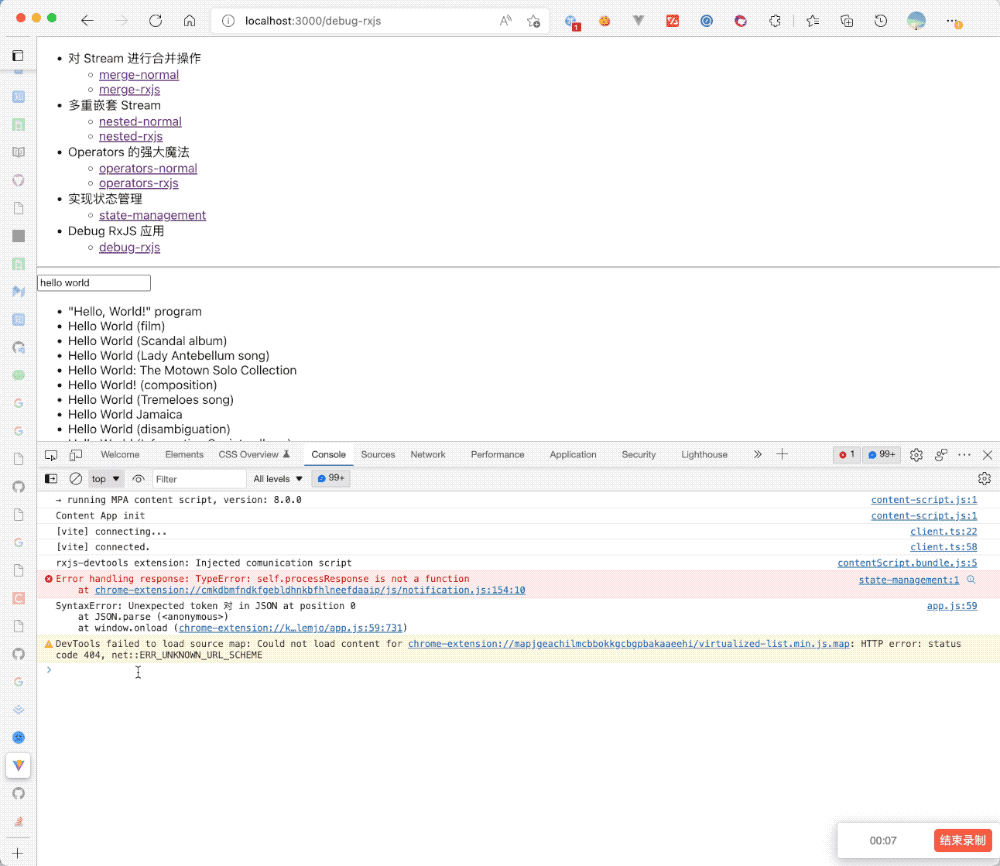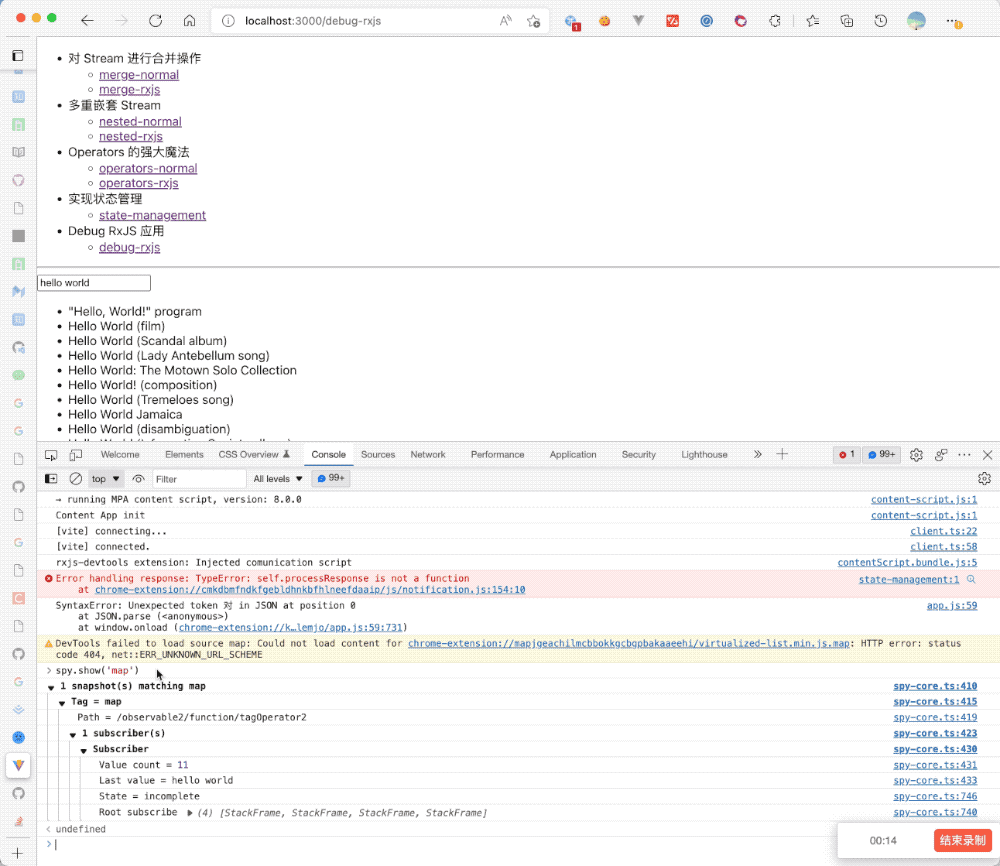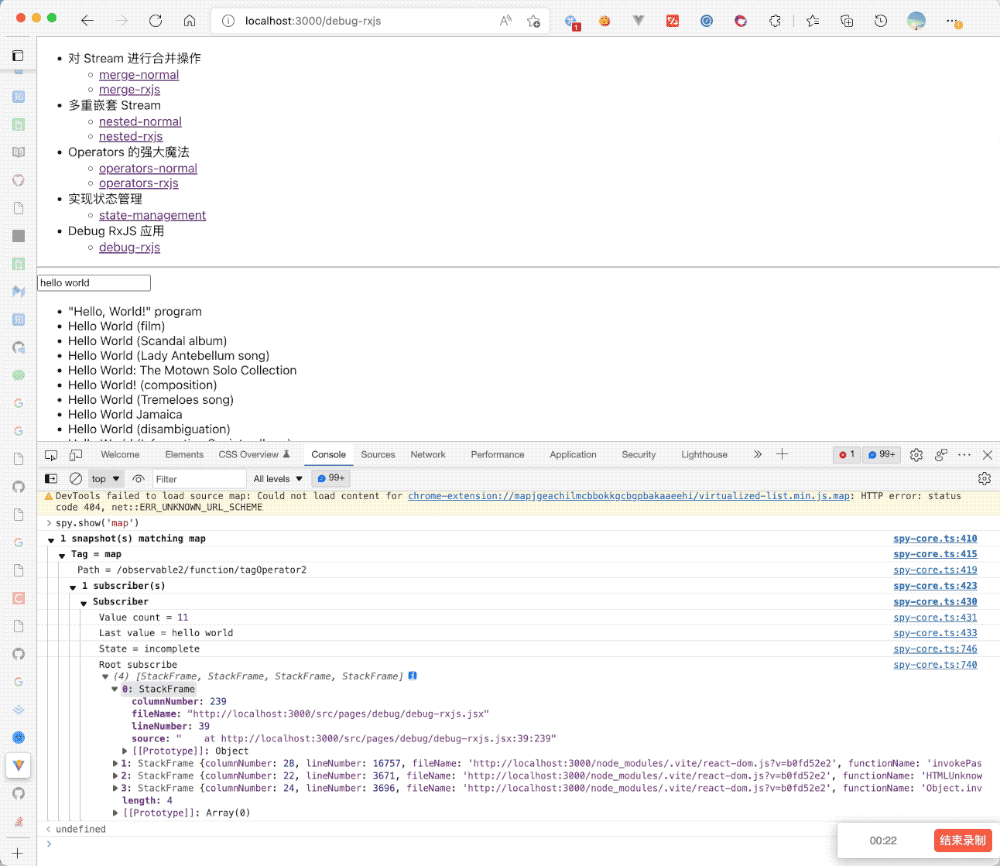
所以 RxJS 的核心成员 cartant 基于上述痛点开发了一个专为 RxJS 而生的调试库:rxjs-spy[5],它主要有如下几个特点:
1 . 如无手动触发,不会打印 log
2 . 可以录制整个 Stream 的过程,打印一个集合的结果,便于调试
3 . 每个结果有对应的执行时间,方便精准定位
4 . 可以暂停、修改、回滚 Stream
5 . 等等
我们拿之前的 AutoComplete 的搜索例子看了解一下 rxjs-spy 如何运作:
首先导出并声明执行:
import { create } from "rxjs-spy";
export const spy = create();然后在想要调试的 Stream 上打 tag:
import { tag } from "rxjs-spy/operators/tag";
const inputSearch = document.querySelector(".search");
fromEvent(inputSearch, "input")
.pipe(
map((e) => e.target.value),
tag("map"),
filter((val) => val),
debounceTime(250),
tag("debounceTime"),
distinctUntilChanged(),
tag("distinctUntilChanged"),
switchMap((val) => searchWikiPedia(val))
)
.subscribe((data) => {
setItems(data[1] || []);
});上述我们在三个部分打了 tag,然后给了对应的标识符,接着我们运行程序,打开控制台就可以查看对应的 Stream 执行的过程:
1 . https://ncjamieson.com/debugging-rxjs-part-1-tooling/
2 . https://ncjamieson.com/debugging-rxjs-part-2-logging/
提供了这种底层操作、打印 Stream 的 API,自然就会有人基于它实现可视化工具,就像 Redux Devtools 一样,同样有人做了 rxjs-devtools[6],通过如下配置:
import DevToolsPlugin from "rxjs-spy-devtools-plugin";
import { create } from "rxjs-spy";
export const spy = create();
const devtoolsPlugin = new DevToolsPlugin(spy, {
verbose: false,
});
spy.plug(devtoolsPlugin);然后下载对应的 Chrome 扩展[7],就可以收获如下的效果:
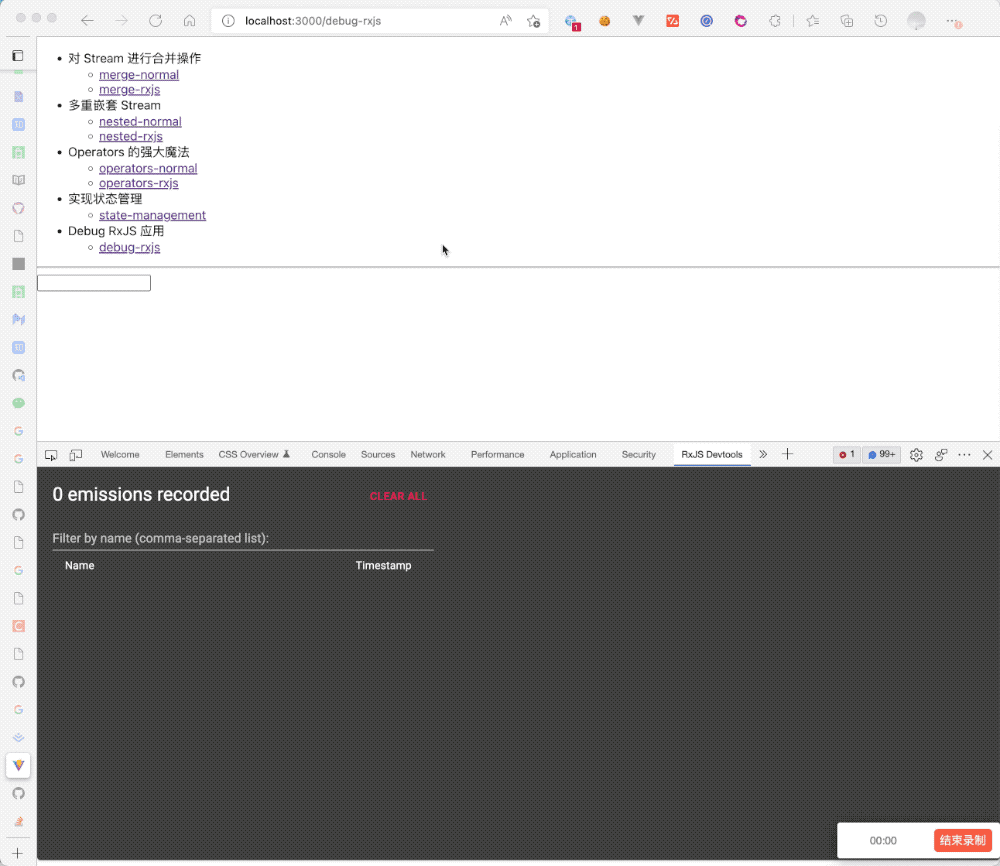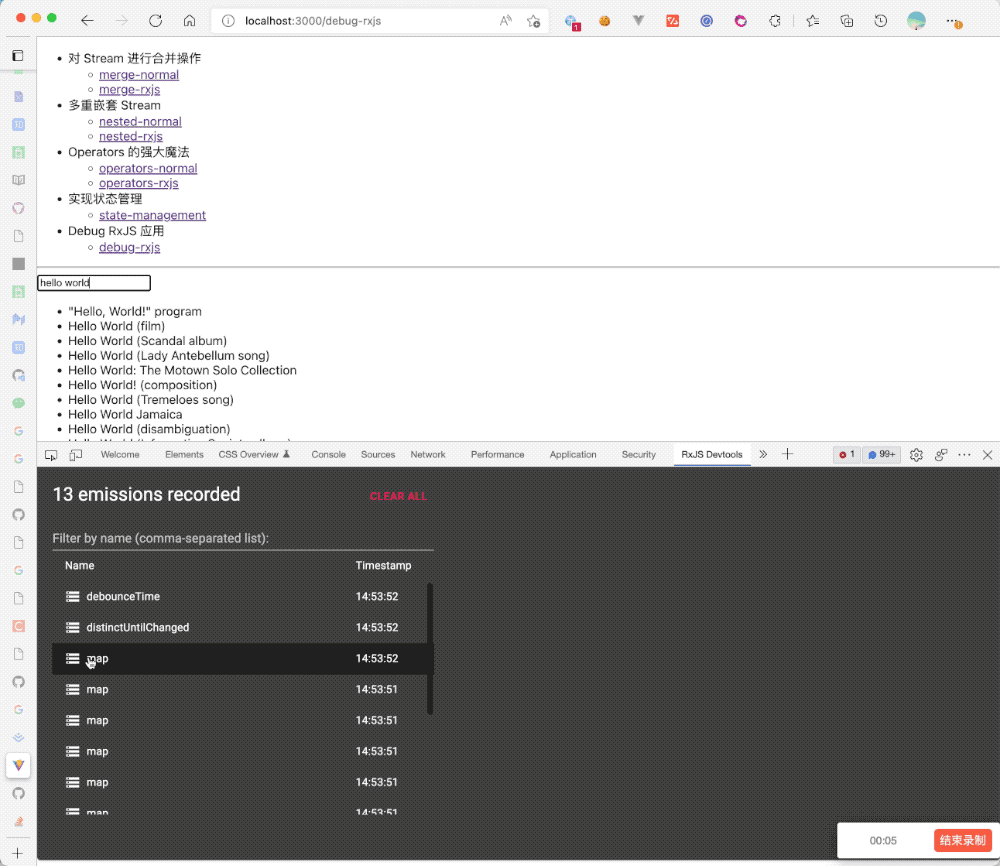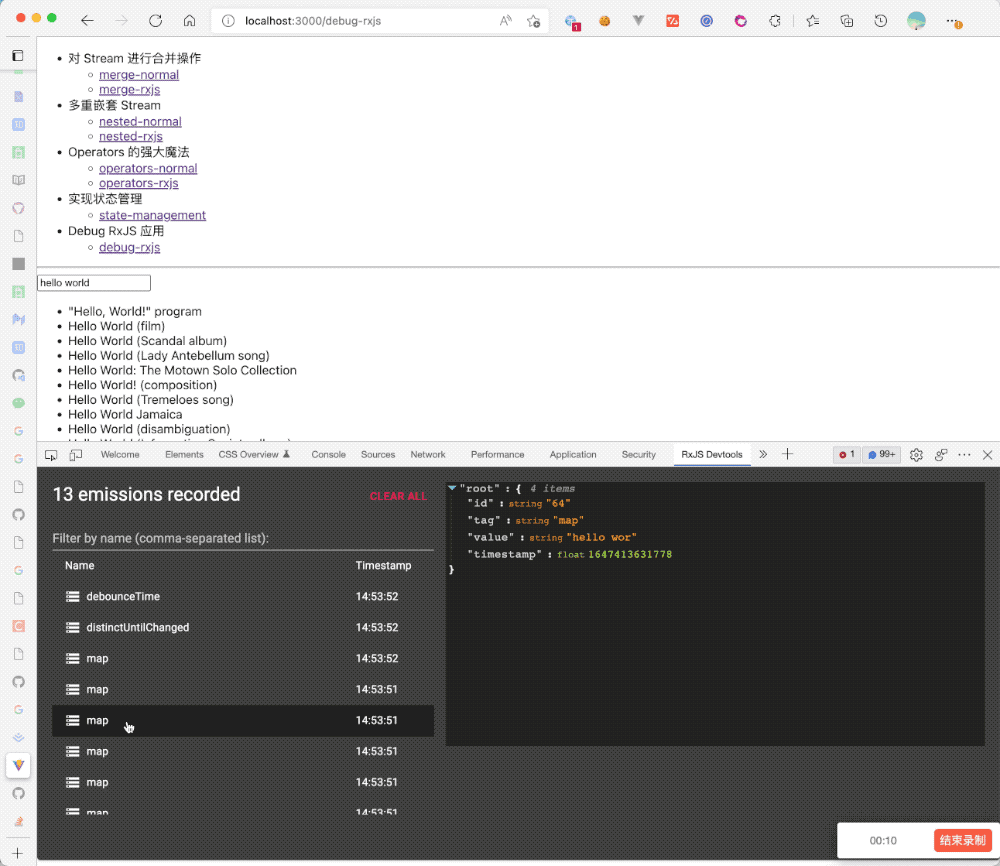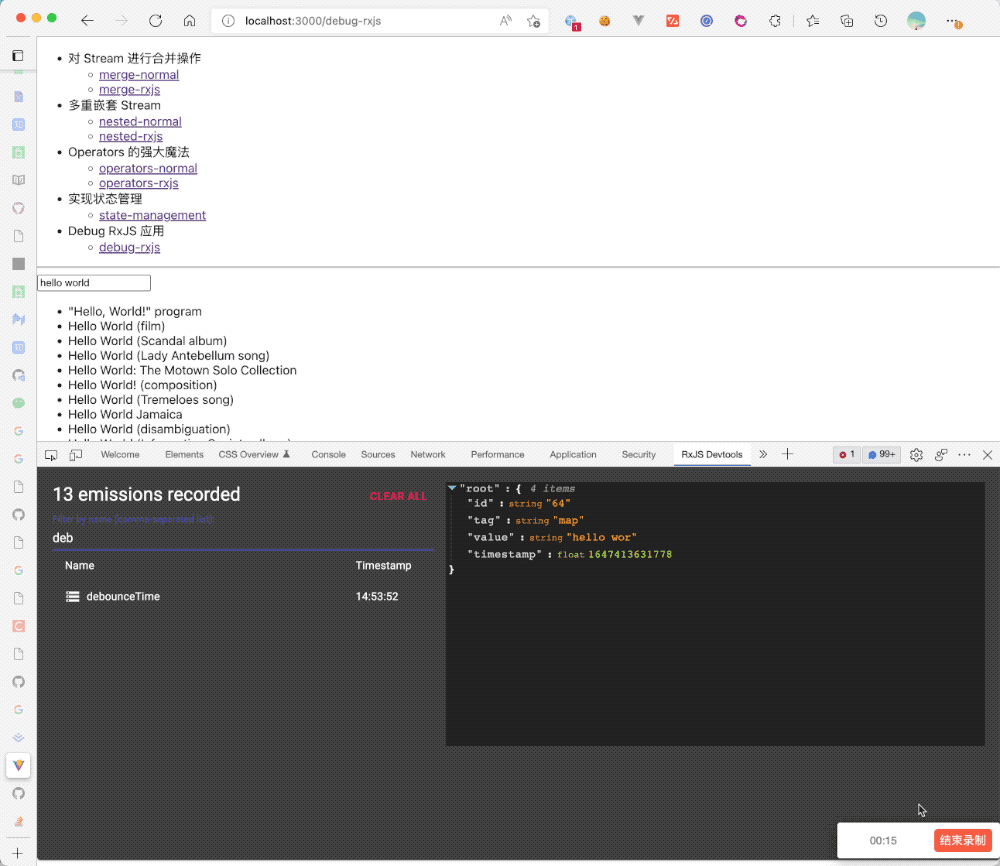
RxJS 社区的维护还可以做哪些工作?
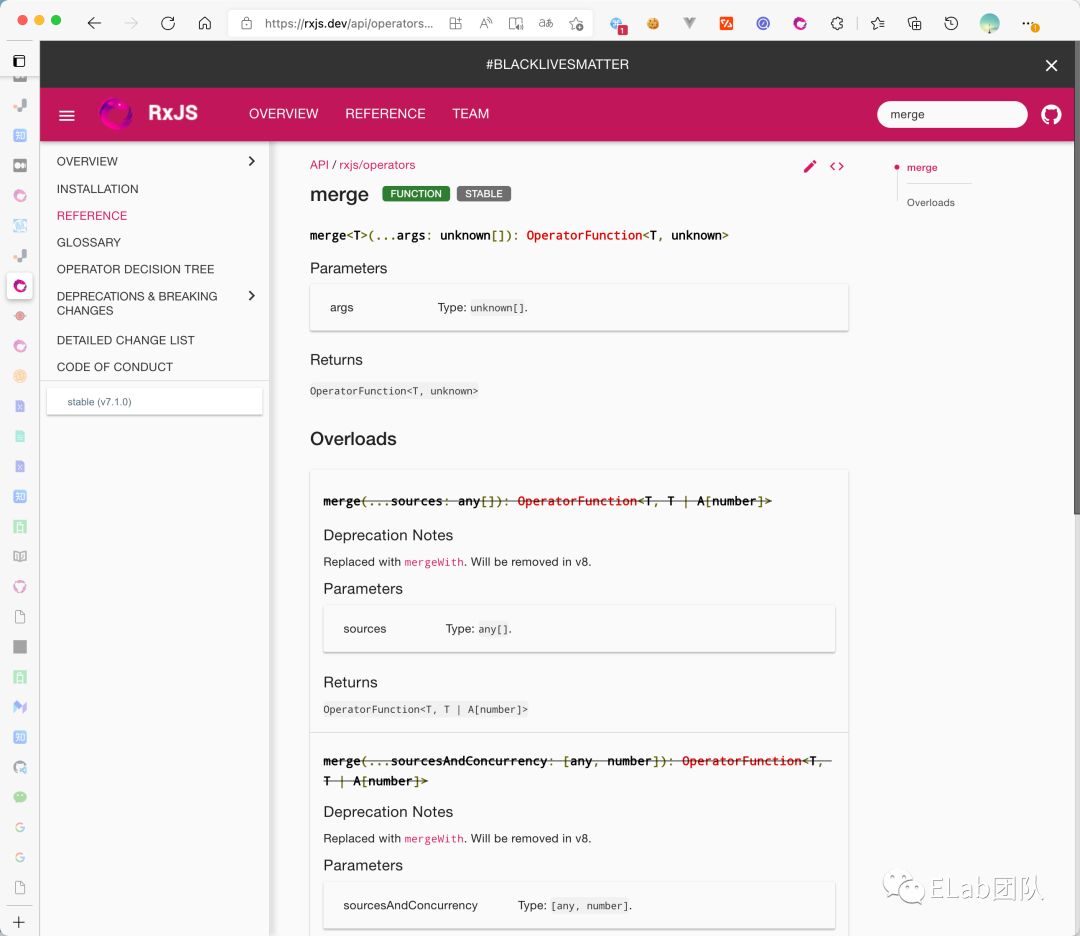
- 将一些缺乏的弹珠图补齐,比如如下这种
- 开发一种方便展示 marbles 图示的 debug tools,类似如下这种:
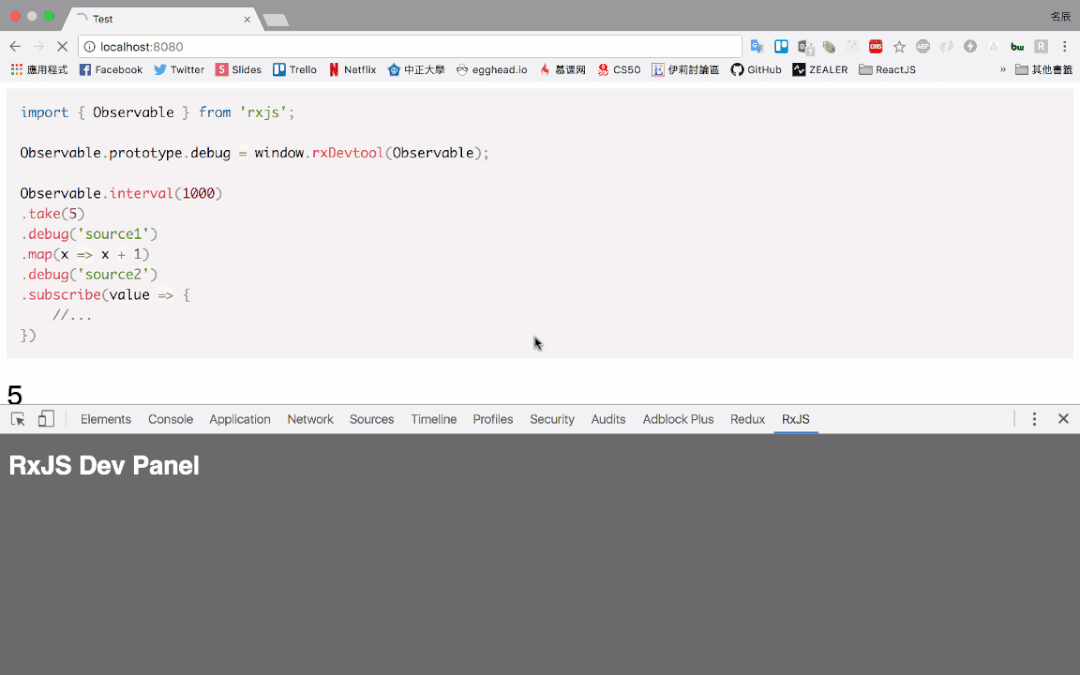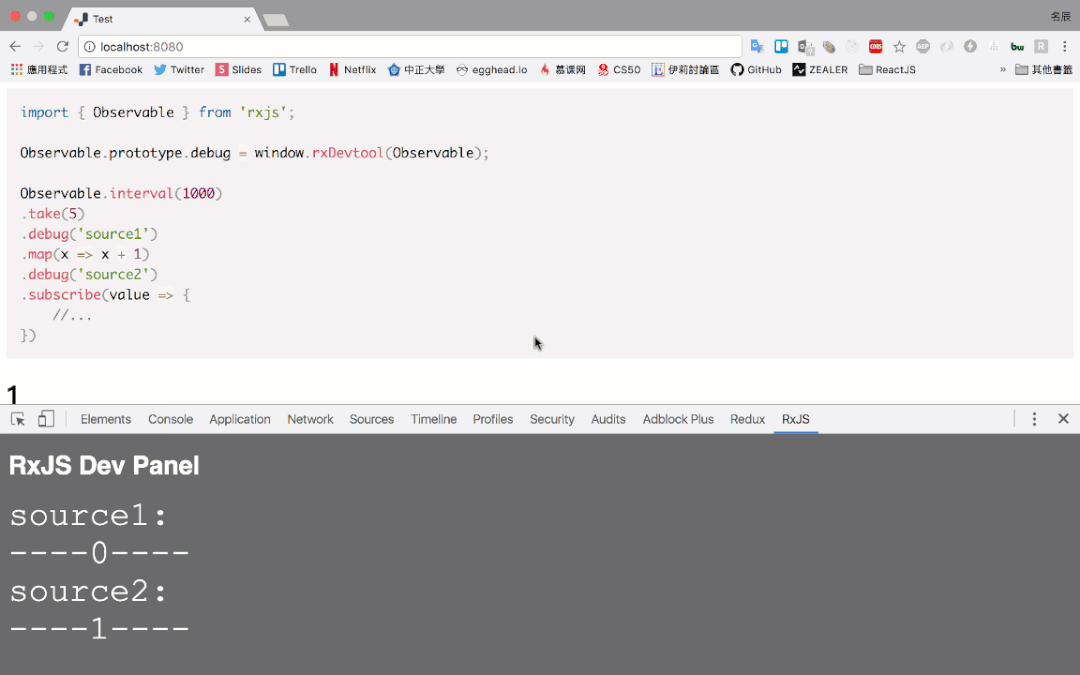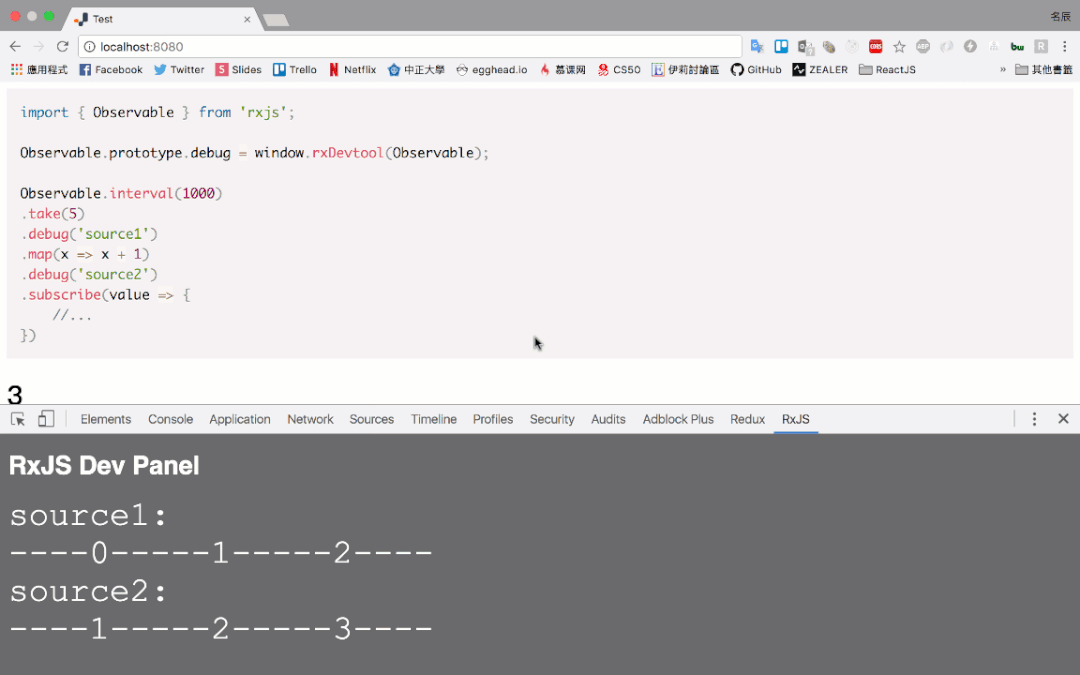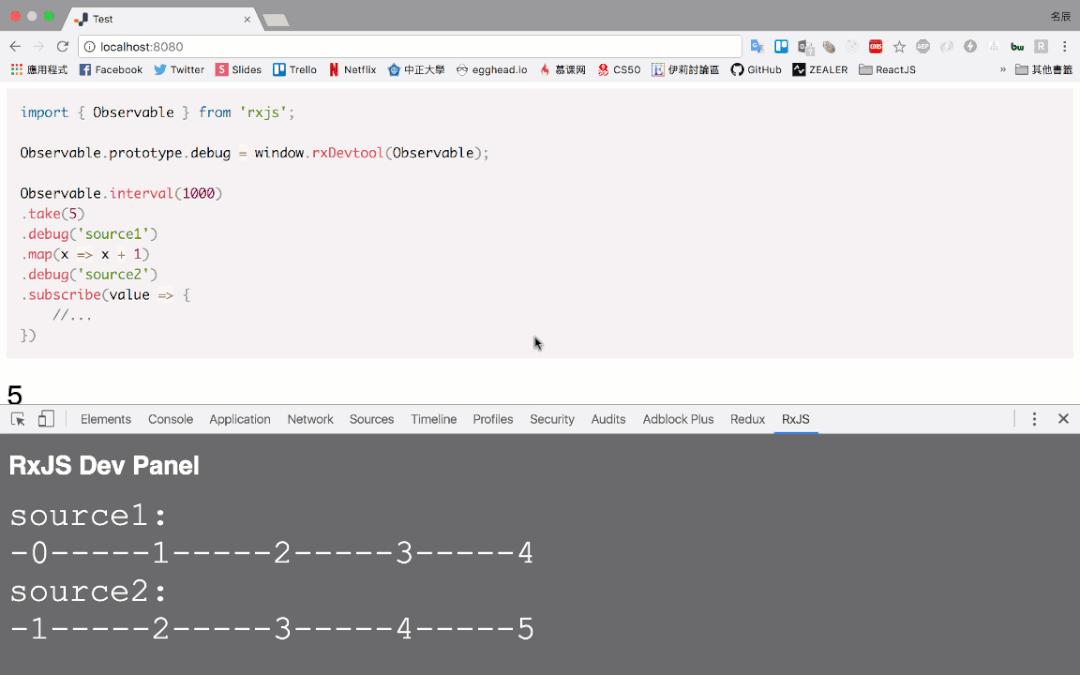
- https://blog.jerry-hong.com/series/rxjs/thirty-days-RxJS-31/
- https://github.com/Jerry-Hong/rx-devtools
RxJS 还有哪些需要了解的?
还有很多东西需要了解,但是受限于篇幅我们无法在本次分享中全部囊括到,剩下的内容我列了一个大纲,留待大家自己去探索,当然大家也可以根据我在文末列出的参考文章进行学习,里面收录了大量的我在撰写这篇分享时的参考。
本文没有包括的内容如下:
-
Subject:
-
BehaviorSubject
-
ReplaySubject
-
AsyncSubject
-
Cold/Hot Observable
-
Scheduler 调度器
-
queue
-
asap
-
async
-
animationFrame
-
各种额外的操作符,具体包含如下几类
-
创建型
-
转换
-
过滤
-
组合
-
多播
-
错误处理
-
工具
-
条件与布尔
-
数学与聚合
或许我们有机会在后续的分享中再来聊一聊这些内容,但是 RxJS 的核心理念与业务落地场景我们已经聊得差不多了。

参考文章
- https://zhuanlan.zhihu.com/p/360033854
- https://www.zhihu.com/question/40035517/answer/84372581
- https://www.zhihu.com/zvideo/1458183228482318336
- https://blog.csdn.net/lunahaijiao/article/details/112792013
- https://blog.techbridge.cc/2017/12/08/rxjs/
- https://blog.jerry-hong.com/series/rxjs/thirty-days-RxJS-00
- https://blog.techbridge.cc/2016/05/28/reactive-programming-intro-by-rxjs/
- http://rxmarbles.com/
- https://github.com/cyclejs/cyclejs
- https://juejin.cn/post/6844903871710494733
- https://segmentfault.com/a/1190000019722065
- https://segmentfault.com/a/1190000019635210
- https://github.com/xufei/blog/issues/38
- https://www.zhihu.com/question/40035517/answer/84372581
- https://github.com/redux-observable/redux-observable
- https://github.com/RxJS-CN/learn-rxjs-operators
- https://www.learnrxjs.io/learn-rxjs/operators/utility/do
- https://www.youtube.com/watch?v=f1KjK8irCbY
- https://blog.jerry-hong.com/series/rxjs/thirty-days-RxJS-31/
- https://github.com/cartant
- https://github.com/ardoq/rxjs-devtools
- https://github.com/cartant/rxjs-spy
- https://ncjamieson.com/
- https://ncjamieson.com/debugging-rxjs-part-1-tooling/
- https://ncjamieson.com/debugging-rxjs-part-2-logging/
- https://github.com/Jerry-Hong/rx-devtools
- https://observable-hooks.js.org/guide/
- https://github.com/LeetCode-OpenSource/rxjs-hooks
- https://github.com/vthinkxie/rxjs-acl
- redux-observable:https://itnext.io/simplifying-websockets-in-rxjs-a177b887f3b8
- https://blog.betomorrow.com/replacing-redux-with-observables-and-react-hooks-acdbbaf5ba80?gi=d08195ad71c4
- https://github.com/BeTomorrow/micro-observables
- https://github.com/pmndrs
- https://zhuanlan.zhihu.com/p/26743163
- http://www.noobyard.com/article/p-znrdioau-r.html
参考资料
[1]https://github.com/pftom/rxjs-demoes: https://github.com/pftom/rxjs-demoes
[2]一个经典的 TodoList 来介绍如何使用 Redux: https://redux.js.org/basics/reducers#reducersjs
[3]CycleJS: https://github.com/cyclejs/cyclejs
[4]redux-observable: https://github.com/redux-observable/redux-observable
[5]rxjs-spy: https://github.com/cartant/rxjs-spy
[6]rxjs-devtools: https://github.com/ardoq/rxjs-devtools
[7]Chrome 扩展: https://chrome.google.com/webstore/detail/rxjs-devtools/abgkgpfkdkafjidfgcjddeffnfnkoeil?hl=en