go语言-深入defer演进与堆分配[3]

defer演进
Go语言中defer的实现经历了复杂的演进过程, Go 1.13、Go 1.14都经历了比较大的更新。在Go 1.13之前,defer是被分配在堆区的,尽管有全局的缓存池分配,还是有比较大的性能问题,原因在于使用defer涉及堆内存的分配,在一开始还需要存储defer函数中的参数,最后还需要将堆区数据转移到栈中执行,涉及内存的复制。因此,defer比普通函数的直接调用要慢很多。
为了将调用defer函数的成本降到与调用普通函数相同。Go 1.13在大部分情况下将defer语句放置在了栈中,避免在堆区分配、复制对象。但是其仍然和Go1.12一样,需要将整个defer语句放置到一条链表中,从而能够在函数退出时,以LIFO的顺序执行。
将defer添加到链表中被认为是必不可少的,原因在于defer的数量可能是无限的,也可能是动态调用的,例如通过for或者if块包裹的defer语句,只有在运行时才能决定执行的个数。在Go1.13中包括2种策略,对于最多调用一个(at most once)语义的defer语句使用了栈分配的策略,而对于其他的方式,例如for循环体内部的defer语句,仍然采用了之前的堆分配策略。在大部分情况下,程序中的defer使用的都是比较简单的场景,这一改变也大幅度提高了defer的效率。defer的操作时间从Go 1.12时的50ns降到Go 1.13时35ns(直接调用大约花费6ns)[2]。Go 1.13虽然进行了一定程度的优化,但仍然比直接调用慢了5、6倍左右。Go 1.14进一步对最多调用一次的defer语义进行了优化,通过编译时实现内联优化[2]。因此,在Go 1.14之后,根据不同的场景,实际存在了3种实现defer的方式。
// cmd/compile/internal/gc/ssa.go
case ODEFER:
if Debug_defer > 0 {
var defertype string
if s.hasOpenDefers {
defertype = "open-coded"
} else if n.Esc == EscNever {
defertype = "stack-allocated"
} else {
defertype = "heap-allocated"
}
}堆分配
在Go 1.13前,defer全部使用在堆区分配的内存存储,由于本文基于Go 1.14进行讲解,因此本节主要关注Go 1.14后出现堆分配的情况。目前在大部分情况下,堆分配只会在循环结构中出现,例如在for循环结构中。
func main(){
for i:=0;i<3;i++{
defer fmt.Println("defer func",i)
}
}在上面的循环defer中,当执行汇编代码时,会发现每一条defer语句都调用了运行时的runtime.deferproc函数。在函数退出前,调用了运行时runtime.deferreturn函数,其抽象代码如下所示:
for i:=0;i<3;i++{
CALL runtime.deferproc(SB)
}
CALL runtime.deferreturn(SB)
RETdeferproc函数的流程比较简单,主要分为3个步骤,如下所示:
-
计算deferproc调用者的器值及参数存放在栈中的位置。
-
在堆内存中分配新的_defer结构体,并将其插入当前协程记录_defer的链表头部。
-
将SP、PC寄存器值记录到新的defer结构体中,并将栈上的参数复制到堆区。
func deferproc(siz int32, fn *funcval) {
// 计算调用者SP、PC、参数位置
sp := getcallersp()
argp := uintptr(unsafe.Pointer(&fn)) + unsafe.Sizeof(fn)
callerpc := getcallerpc()
// 在堆内存中分配新的defer结构体
d := newdefer(siz)
// 插入当前协程记录defer的链表头部
d.link = gp._defer
gp._defer = d
d.fn = fn
d.pc = callerpc
d.sp = sp
switch siz {
case 0:
case sys.PtrSize:
// 如果defered函数的参数和指针大小一样,则直接通过赋值来复制参数
*(*uintptr)(deferArgs(d)) = *(*uintptr)(unsafe.Pointer(argp))
default:
// 通过memmove复制defered函数的参数
memmove(deferArgs(d), unsafe.Pointer(argp), uintptr(siz))
}
// 通过汇编指令设置rax = 0
return0()
}以下面的代码为例,defer add需要传递两个参数。
func add(a, b int) {
fmt.Println("add:" , a + b)
}
func f() {
for i:=0;i<2;i++{
defer add(3, 4)
}
}
func main() {
f()
}当执行到defer语句时,调用运行时deferproc函数,其在栈中的结构如图10-1所示。
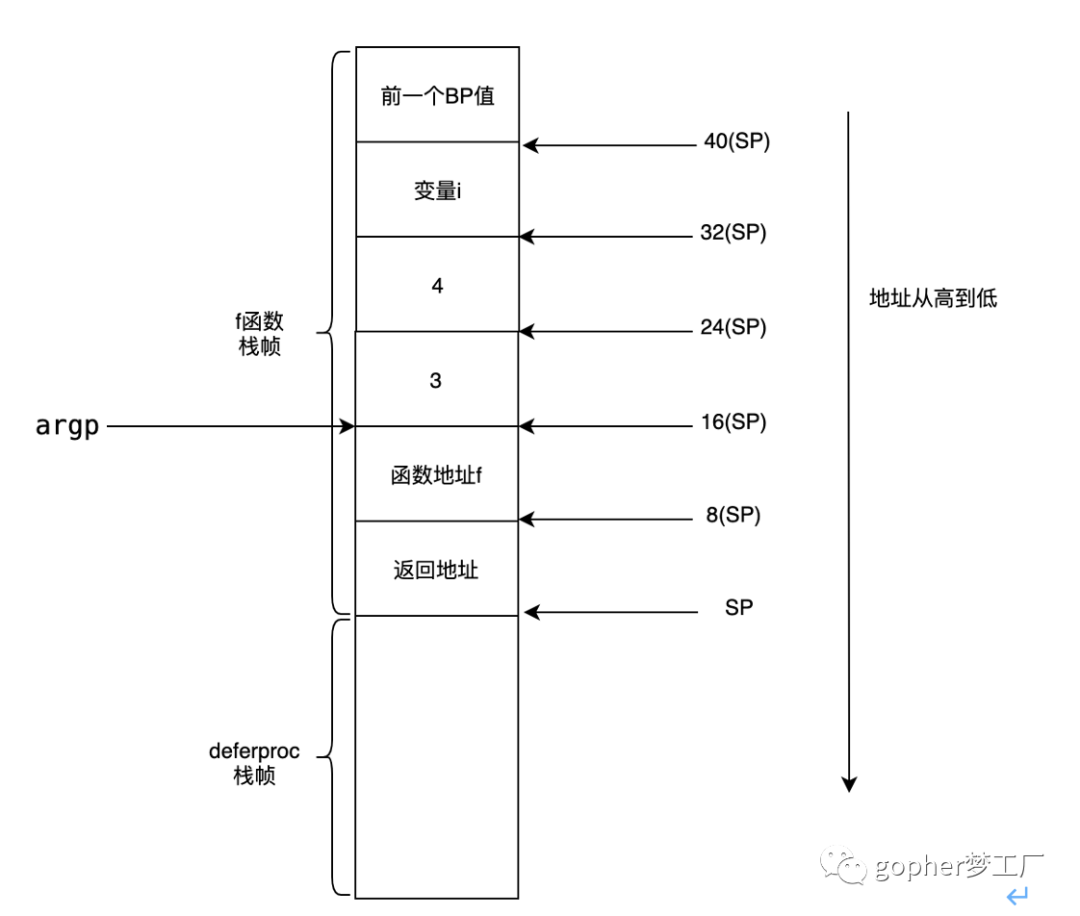
deferproc函数在栈中的结构
每个协程都对应着一个结构体g,deferproc函数新建的_defer结构最终会放置到当前协程存储_defer结构的链表中。
type g struct {
...
_defer *_defer
}新加入的_defer结构会放置到当前链表的头部中,从而保证在后续执行defer函数时能以先入后出的顺序执行,如图所示。
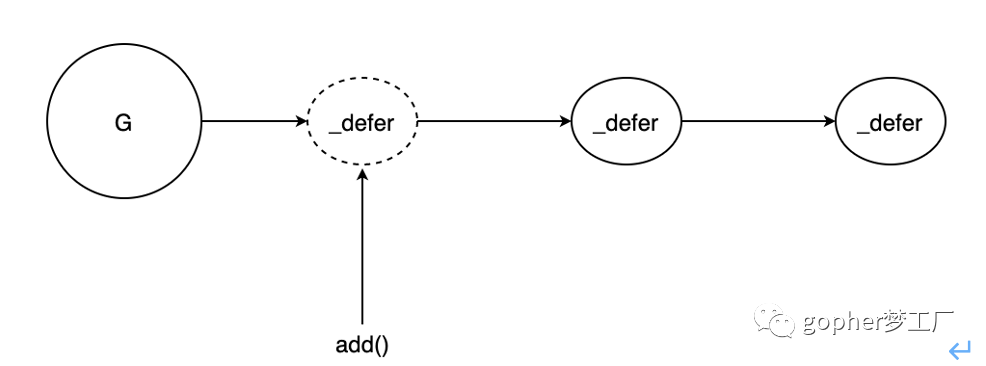
defer链先入后出的添加顺序
runtime.newdefer在堆中申请具体的_defer结构体,每个逻辑处理器P中都有局部缓存(deferpool),在全局中也有一个缓存池(schedt.deferpool),图显示了defer全局与局部缓存池的交互。defer根据结构的大小分为5个等级,以方便快速地找到最适合当前分配的_结构体。这种分级策略在Go语言内存管理中的使用非常普遍。
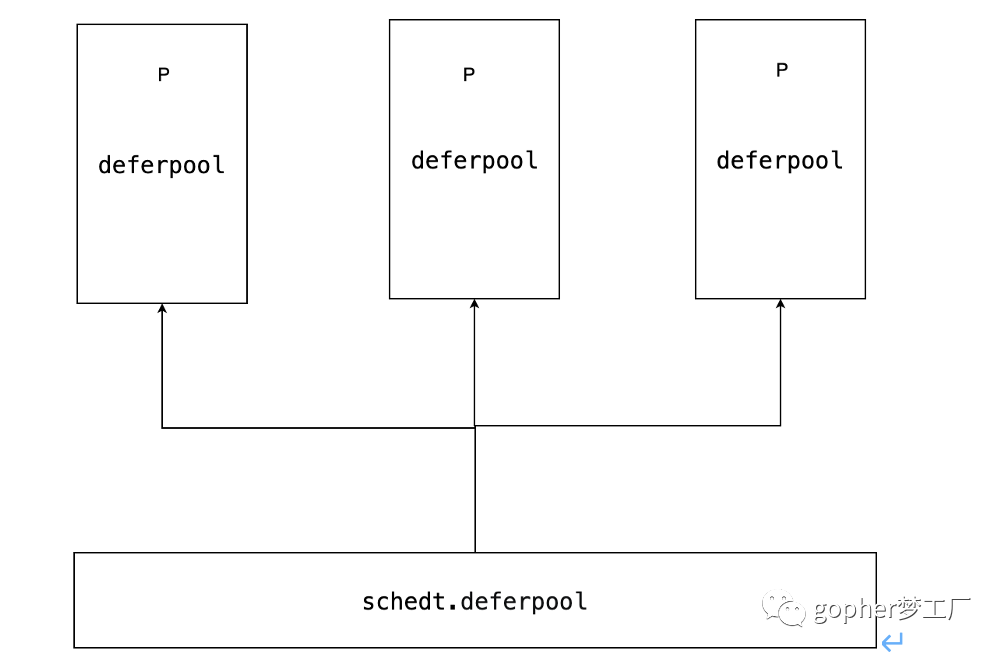
defer全局与局部缓存池交互
当在全局和局部缓存池中都搜索不到对象时,需要在堆区分配指定大小的defer。
func newdefer(siz int32) *_defer {
var d *_defer
// defer等级
sc := deferclass(uintptr(siz))
// 等级在范围内
if sc < uintptr(len(p{}.deferpool)) {
if len(pp.deferpool[sc]) == 0 && sched.deferpool[sc] != nil {
systemstack(func() {
lock(&sched.deferlock)
// 从全局_defer缓存池拿一些_defer结构体到局部_defer缓存池
for len(pp.deferpool[sc]) < cap(pp.deferpool[sc])/2 && sched.deferpool[sc] != nil {
...
}
unlock(&sched.deferlock)
})
}
// 从局部缓存池分配
if n := len(pp.deferpool[sc]); n > 0 {
d = pp.deferpool[sc][n-1]
pp.deferpool[sc][n-1] = nil
pp.deferpool[sc] = pp.deferpool[sc][:n-1]
}
}
// 如果P的缓存中没有可用的_defer结构体则从堆上分配
if d == nil {
systemstack(func() {
total := roundupsize(totaldefersize(uintptr(siz)))
d = (*_defer)(mallocgc(total, deferType, true))
})
}
d.siz = siz
}当defer执行完毕被销毁后,会重新回到局部缓存池中,当局部缓存池容纳了足够的对象时,会将_结构体放入全局缓存池中。存储在全局和局部缓存池中的对象如果没有被使用,则最终在垃圾回收阶段被销毁。