实战kafka—生产消费全局视野
生产者在消息体ProducerRecord中,需要明确topic、value。另外分区与key是可选的。
- 如果指定了分区,则放入特定分区
- 如果只指定了key,那么相同的key会放入相同的分区
- 如果分区与key都未指定,则认为是随机的
由于网络中通过二进制方式进行传输,因此需要进行序列化。
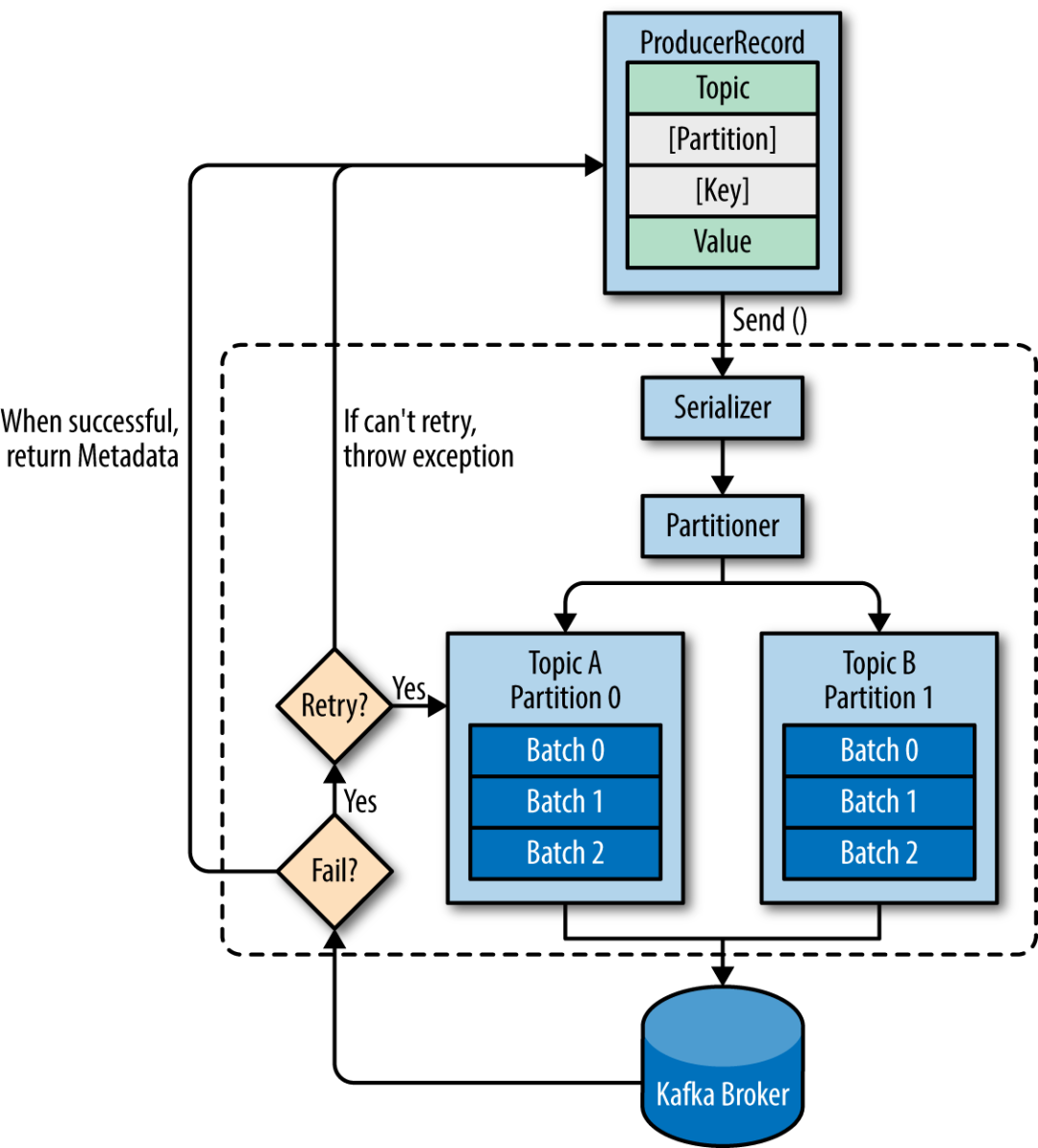
如下是一个抽象的生产者模型,总结起来很简单:
构建消息体——序列化——确定分区规则——发消息到kafka broker——如果失败请求重试,成功返回meta元数据。
消费者
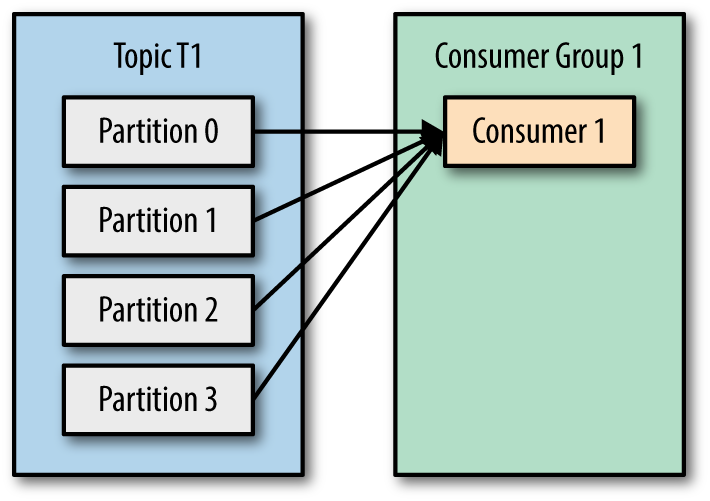
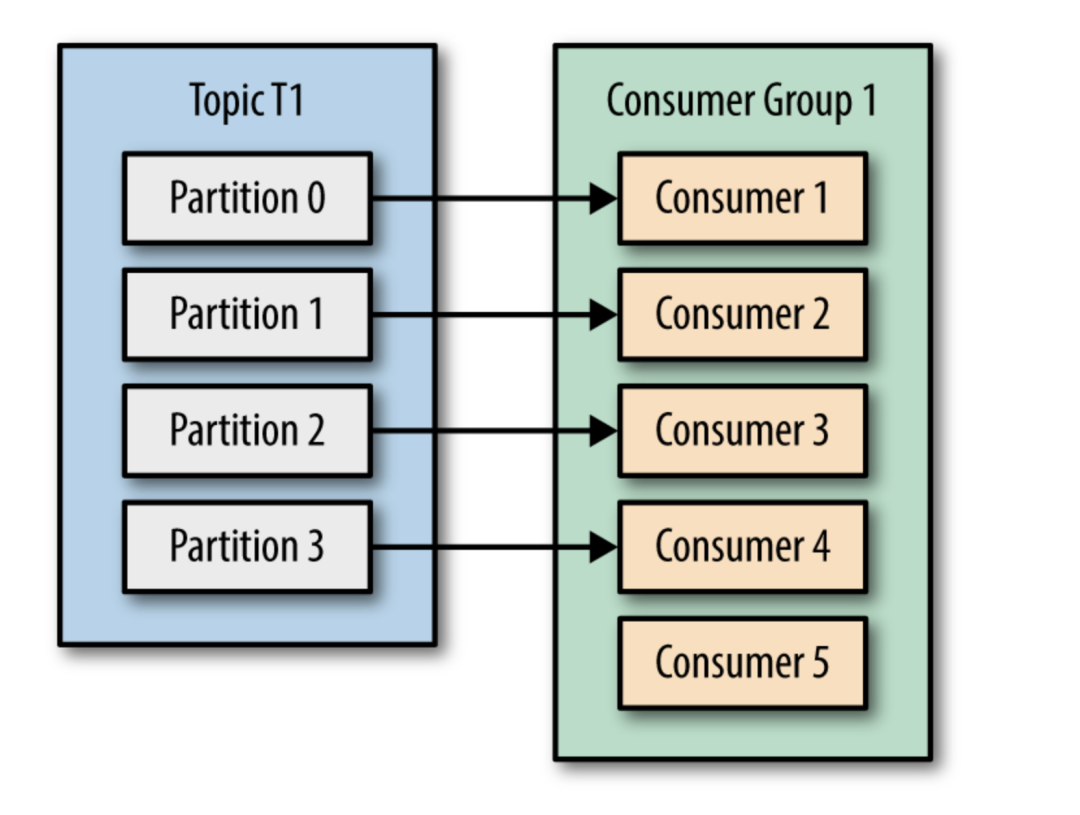
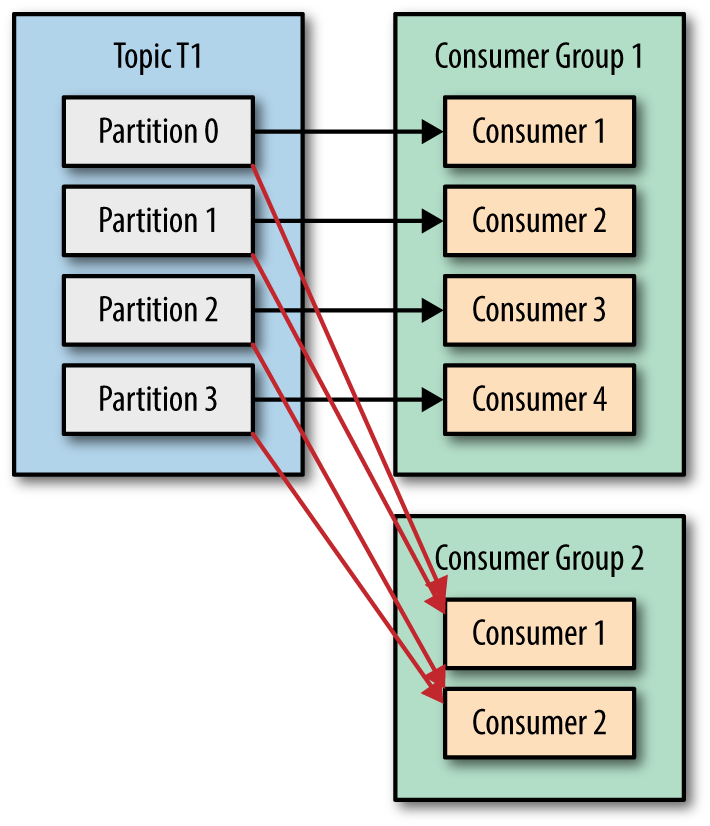
在实战中,用一个消费者去消费message常常跟不生产者推送message的数量,这时使用消费组去消费用显得尤为重要。
当只有一个消费者,所有分区数量都分配给同一个消费者。
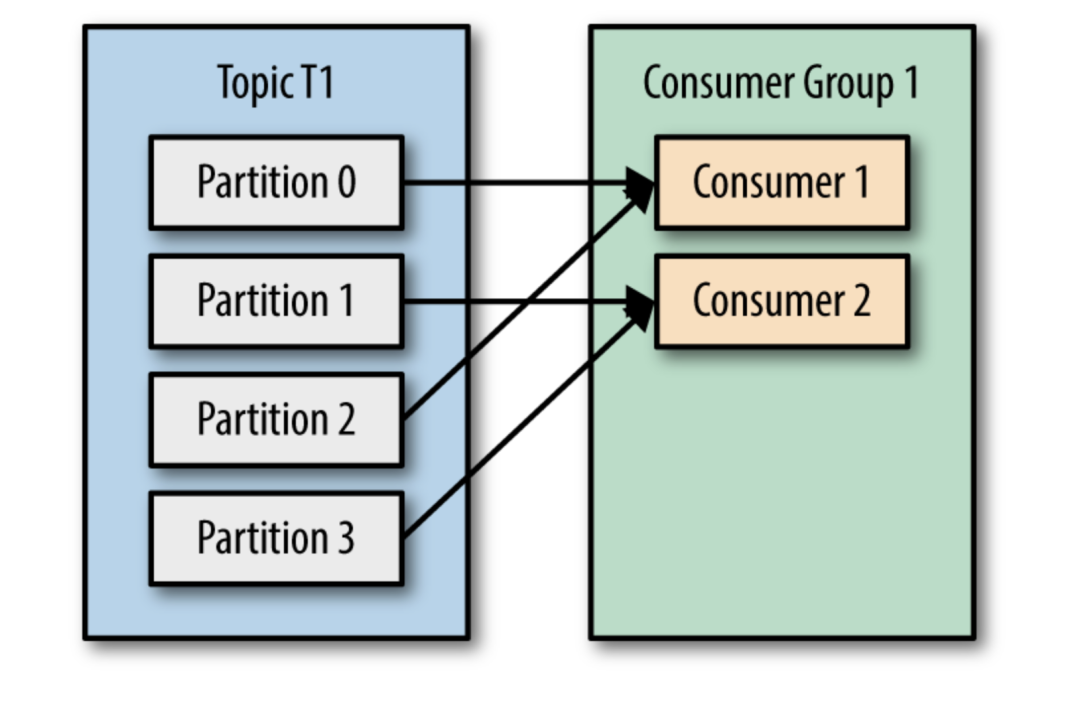
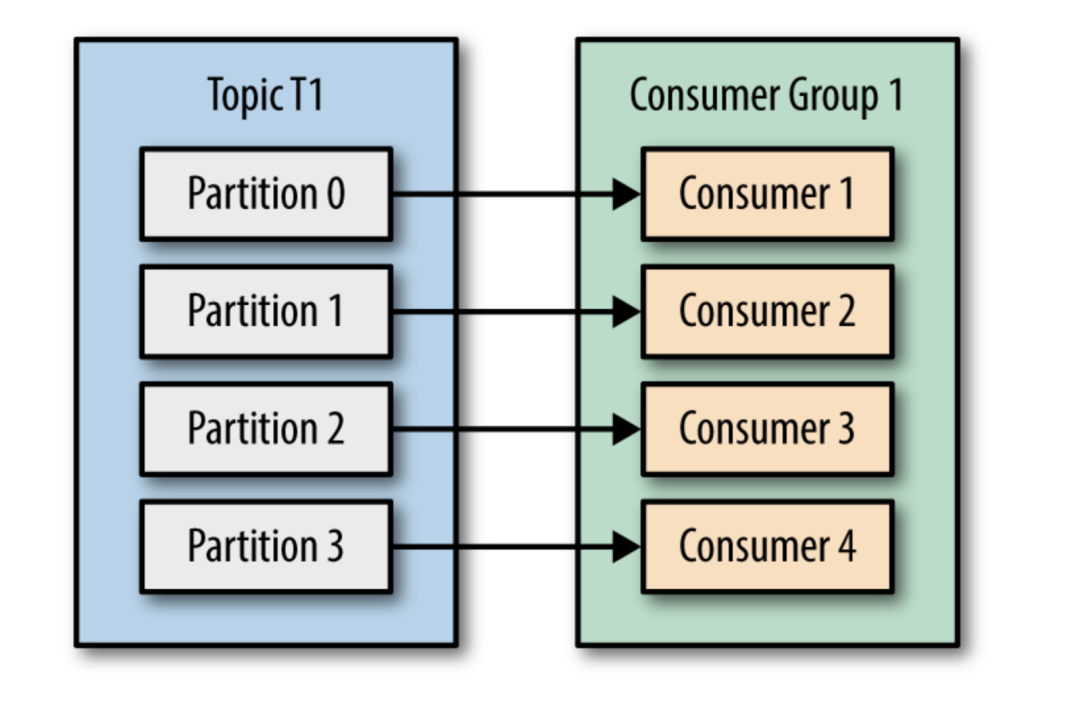
这就是为什么调大分区数量是一个好的理由,可以在负载增大时,水平增加消费者。
commit
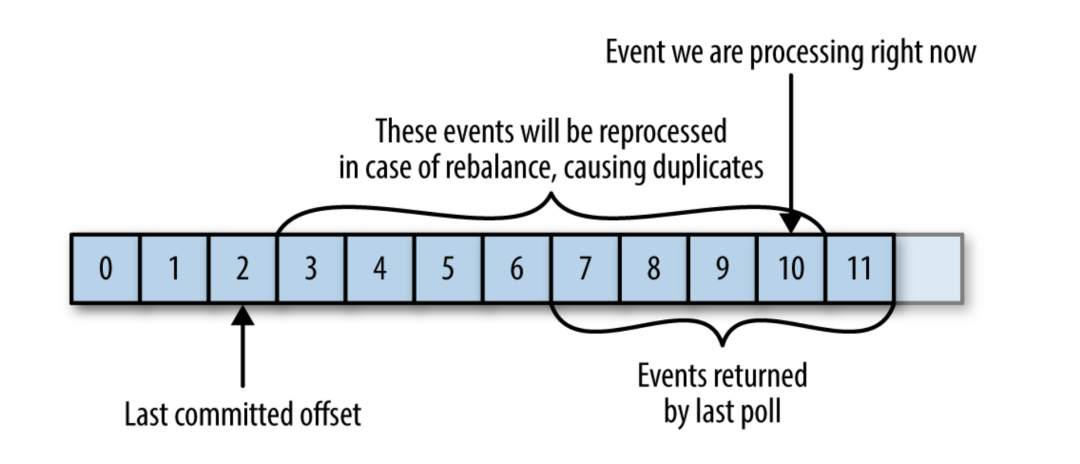
偏移量非常重要,topic在每个分区中的每个message都有唯一的偏移量。消费者可以通过偏移量追踪到哪些数据是已经消费过了,这样即便程序中断和重启后可以继续消费。借助于offset的偏移还可以重复消费数据,甚至丢弃数据。
offset的偏移是应用程序在消费数据(一条或者是一批数据)之后通知kafka的。由于这种ack的机制,这导致了可能会消费重复的数据。另外,在新建消费者导致分区重新的分配时,也可能会导致消费重复的数据。这是消息队列时常会遇到的问题。
高可用
在集群环境下,多个broker会利用Zookeeper进行简单选主操作,选出的leader叫做Controller。
在集群环境下,topic在一个分区中的内容可能会有多个副本,但是只有一个分区所在的broker作为这些副本的leader.这一个分区叫做Leader replica,其余的副本叫做Leader replica。Leader replica的任务是要明确副本的meaage是否与自己一致。
Controller在broker加入或退出时,协调分区副本的leader。
kafka客户端只有将请求发送到某一个Leader replica 才被允许,因此,可以首先通过Meatadata 请求到任意broker查找到当前分区leader是哪一个。
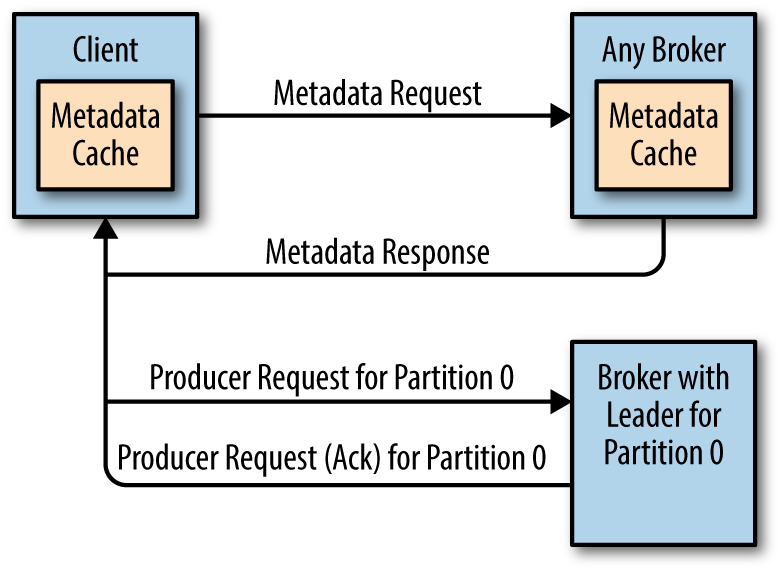
通过生产者参数ack来指定。
acks=0 数据可能还没写入就认为成功了
acks=1 数据写入leader replica 成功
acks=all 数据写入所有副本成功