前端浪漫中的浪漫:文档协同办公的原理
本文针对生活中常见的协同编辑场景,介绍了几种业内常见的解决方案及其原理,适合对协同编辑算法零基础的同学进行科普性的学习。通过阅读本文,你可以了解到:
- 协同编辑的场景定义及分类
- 协同编辑的数据模型
- 协同编辑的解决方案和实践
引言
现代办公场景中,人与人之间的协作变得越来越频繁而重要,我们经常碰到多个人需要对同一份文档作出修改,使之融合多人工作成果的场景,这种行为称之为协同编辑(collaborative editing)[1]。
狭义的协同编辑指的是对纯文本(plain text)的编辑,此时我们的编辑对象是一个纯文本。随着数据结构变得复杂,也可延伸到富文本(rich text)和代码(code)。更广义的,协同编辑的概念可应用于任何结构化数据,例如图形(graph)和表格(sheet)。
场景分类
根据实时性要求的不同,可以把生活中的协同场景分为离线协同编辑和实时协同编辑。
离线协同
离线协同编辑(offline collaborative editing)针对多个副本在不同时间对同一原本进行修改的场景。这意味着,副本产生的更改并不会马上应用到原本上,并且同一时刻只会有一个副本的更改会被应用到原本上。例如大部分在线配置文件、代码的版本管理、传统的网页博客编辑等。通常来说这种场景下默认大家都是有序进行编辑的,且最后完成编辑提交的副本决定文档原本的最终内容。根据合并策略的选择,还可以继续细分为覆盖式和非覆盖式。
-
覆盖式:始终用最后提交的副本内容覆盖远程原本内容,也就是说最后提交的副本唯一决定着最终的原本内容。这种方式在实现上很简单,但是在实际使用中存在着多种问题,比如多个副本内容来回覆盖等。因此在某些场景下,还会引入编辑锁(edit lock),用以确保编辑行为的有序性。
-
非覆盖式:也称增量式,本地副本在提交时,总是会比较当前副本和远程原本的差异,只更新差异部分。相对于直接覆盖的方案,这种方案只应用变更部分,保证了多人合作的秩序。常见于代码版本管理中的差异补丁(diff-patch)。
实时协同
实时协同编辑(real-time collaborative editing)指的是多个副本同时并行的对同一原本进行修改,满足物理意义上的实时性。在这个过程中更改的发生是频繁的,副本更改发生的顺序是不确定的,同时其它副本的更改也会及时的更新到本地。与离线编辑相比,实时编辑带来了许多新的挑战:
- 写冲突。多个副本可能会在同一时间对同一位置(比如文档末尾)产生插入字符操作,此时最终的文档内容该如何决定?
- 删除冲突。如果多个副本同时删除了同一位置的字符,是否会产生重复删除问题,导致被删除的字符比预期的要多?
- 通信成本。实时场景下的编辑行为很频繁,需要不断的同步更改内容,随着文档规模的不断扩大,需要传输的字符串是不是越来越多?通信的成本是否会越来越高?
- 延迟问题。真实世界的网络通信存在延时,副本更改产生的时间顺序可能与到达服务器的时间顺序可能不一致,是否会导致因果关系的错乱?
- 断线重连。实际场景中,由于网络情况等诸多原因,如果某个副本在编辑时失去网络连接,在本地继续编辑一段时间后,重新连上服务器,此时服务器上的数据已经不再是断线前一瞬间的版本,该如何处理同步冲突?
协同模型
通常我们以 CCI 模型为例来介绍协同编辑中最终一致性模型的三个要求
因果关系保护(Causality preservation):确保因果相关操作在协作过程中的执行顺序与其自然因果顺序一致。两个操作之间的因果关系由 “happened-before”关系正式定义。当两个操作没有因果关系时,它们是并发的。可以在两个不同的文档副本上以不同的顺序执行两个并发操作。
- 收敛(Convergence):确保共享文档的复制副本在静止时在所有站点都相同
- 意图保护(Intention preservation):确保对任何文档状态执行操作的效果与操作的意图相同。操作O的意图被定义为可以通过将O应用于生成O的文档状态来实现的执行效果。
CCI 模型以新的标准扩展了 CC 模型:意图保护。收敛和意图保护的本质区别在于前者总是可以通过序列化协议来实现,但如果操作总是以其原始形式执行,则后者可能无法通过任何序列化协议来实现。实现不可序列化的意图保存特性一直是一项重大的技术挑战。已发现 OT 特别适合在协作编辑系统中实现收敛和意图保存。
此外还有CC模型、CSM 模型和CA 模型,这里不一一做介绍了。
方案介绍
Edit Lock
编辑锁(edit lock)是最简单的协同解决方案,其具体描述为:当某个用户编辑文档时,自动获得该文档的所有权,此时其他人均无法编辑该文档,直到当前用户完成编辑,释放所有权,其他用户才可以继续参与编辑。此方案保证了在同一时刻只存在一个用户进行编辑,且每个用户都是基于最新(上一个用户释放所有权时保存)的文档版本进行编辑,从而避免了编辑冲突。
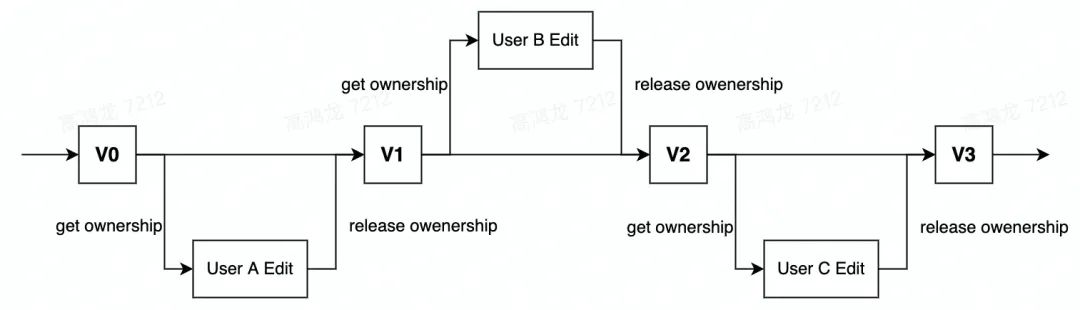
遗憾的是,在文档编辑场景下,编辑权限的切换并不能做到像操作系统的线程切换那样高效无感,所以事实上编辑锁方案并不适用于实时编辑场景。
Diff-Patch/Merge
diff 是在 1970 年代初期在 Unix 操作系统上开发的, 1974 年第 5 版 Unix 发布了第一个版本,由 Douglas McIlroy 和 James Hunt 编写,diff 算法是代码版本管理的基石。
diff 算法的原理和最长公共子序列问题[2]的解法非常相似。
以下面的字符串为例
// S1
a b c d f g h j q z// S2
a b c d e f g i j k r x y z我们想找到一个最长的项目序列,它以相同的顺序出现在两个原始序列中。也就是说,我们要找到一个新的序列,可以从第一个原始序列中删除一些项,从第二个原始序列中删除其他项。我们还希望这个序列尽可能长。在这种情况下我们可以得到
a b c d f g j z
然后我们把 S2 剩下的部分与 S1 进行对比,即可得到
a b c d e f g h i j q k r x y z
+ - + - + + + +也就是说,为了把第一个字符串转成第二个字符串,我们需要在对应的位置添加字符 eikrxy,删除字符 hq。使用 jsdiff[3],我们可以得到以下变换过程:
[
{ count: 4, value: 'abcd' },
{ count: 1, added: true, removed: undefined, value: 'e' },
{ count: 2, value: 'fg' },
{ count: 1, added: undefined, removed: true, value: 'h' },
{ count: 1, added: true, removed: undefined, value: 'i' },
{ count: 1, value: 'j' },
{ count: 1, added: undefined, removed: true, value: 'q' },
{ count: 4, added: true, removed: undefined, value: 'krxy' },
{ count: 1, value: 'z' }
]把这个过程 patch 到 S1 上,我们可以得到 S2。
git 的版本管理也是基于这个原理实现的,但是出于性能考虑,git 的diff不是基于字符比较做的,而是基于行比较,这样大大减少了 diff 时产生的开销,与此同时也牺牲了比较的精度(改动行内任意字符,均会被视作改变了整行文本)。
this is line 1
- this is line 2
this is line 3this is line 1
this is line 2'
this is line 3基于 diff 和 patch,我们可以对基于同一个原本的两个副本进行合并,称之为 merge
| 原本 | 副本一 | 副本二 | 合并版本 |
|---|---|---|---|
| this is line 1 this is line 2 this is line 3 | this is line 1 - this is line 2 + this is line 2' this is line 3 | this is line 1 this is line 2 - this is line 3 + this is line 3' | this is line 1 this is line 2' this is line 3' |
想象我们共同维护同一个代码仓库的场景,大家依次往主分支合并代码,如果这个过程足够快,是不是也接近于实时编辑了?理论上说,不考虑冲突的话,diff-path 也可以达到近似实时的效果。
事实上,这个方案是不可行的。前面说过 diff 算法是基于行比较的,如果多个副本对同一行文本进行了编辑,那么就会产生编辑冲突,从而使得文档无法合并。这对于实时协同编辑是无法接受也是很难避免的。除此之外,还有更关键的一点,即便不考虑性能问题,采用逐文字 diff 方案,也无法满足CCI模型中的意图保存原则,例如对于 aaa 到 aa 的文本变更,我们无法确定是哪个 a 被删除了,这会对协同编辑时的光标位置造成歧义。
因此,作为代码版本管理中优秀的 diff 算法,在实时场景下的发挥并不好,很难满足实时协同编辑的需求,它本质上还是一种离线方案。
OT(Operational Transformation)
Operational Transformation 最早由 C. Ellis and S. Gibbs 在 1989 年提出。此后不断的有人去扩充和维护 OT。在 1998 年,人们还成立了 Special Interest Group on Collaborative Editing(SIGCE)以便于更好的去交流和研究协同编辑算法,并每年举办相关的研讨会。时至今日,OT 已经成为协同编辑领域最成熟的解决方案。我们所熟知的 Google Doc/Jupiter 等文档编辑器的实时协作功能,都采用了 OT。
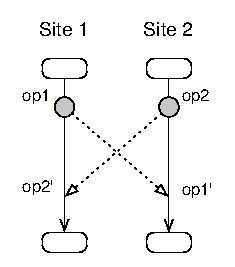
顾名思义,OT 的核心思想是操作转换,其基本原理是对文本的编辑抽象成操作(operation),并根据固定规则,对不同副本的操作进行转换,从而使各个副本的文档保持一致。在这个过程中,各个副本的操作到达服务器的时间都是随机的,不会因为到达的前后顺序产生问题。
-
retain(n: number),代表将光标从当前位置向后移动 n 个距离,此操作不会对文档产生任何修改。 -
insert(str: string),代表在当前位置插入str,同时光标向后自动移动str.length个距离。 -
delete(n: number),代表从当前位置往后删除 n 个字符。
在这里我们规定,一次完整的操作必须保证光标从字符串的头部遍历到字符串的尾部,否则该操作就是非法的。
对于原始字符串 abcde,我们假设有两个副本(site1, site2)同时对其进行编辑。
// Site1:
op1 = [retain(1), insert('x'), retain(4)] // ins(1, 'x')
abcde --op1--> axbcde
// Site2
op2 = [retain(3), delete(1), retain(1)] // del(3, 1)
abcde --op2--> abce如果两个副本均是先在本地应用了自己的操作,然后再去应用对方的操作,那么我们可以得到
// Site1:
op1 = [retain(1), insert('x'), retain(4)] // ins(1, 'x')
op2 = [retain(3), delete(1), retain(2)] // del(3, 1)
abcde --op1--> axbcde --op2--> axbde
// Site2
op2 = [retain(3), delete(1), retain(1)] // del(3, 1)
op1 = [retain(1), insert('x'), retain(3)] // ins(1, 'x')
abcde --op2--> abce --op1--> axbce可以看到,仅仅是交换了操作顺序,两个副本的应用结果就不再一样,这显然无法满足要求。这是因为两步操作之间是存在因果关系的,交换了顺序,因果关系也就变了,所以最终的结果也就发生了变化。为了保证操作结果的收敛,我们需要对操作进行转换,例如下面这样:
// Site1:
op1 = [retain(1), insert('x'), retain(4)] // ins(1, 'x')
op2' = [retain(4), delete(1), retain(1)] // del(4, 1)
abcde --op1--> axbcde --op2'--> axbce
// Site2
op2 = [retain(3), delete(1), retain(1)] // del(3, 1)
op1' = [retain(1), insert('x'), retain(4)] // ins(1, 'x')
abcde --op2--> abce --op1'--> axbce// Transform takes two operations A and B that happened concurrently and
// produces two operations A' and B' (in an array) such that
// `apply(apply(S, A), B') = apply(apply(S, B), A')`. This function is the
// heart of OT.
TextOperation.transform = function (operation1, operation2) {
if (operation1.baseLength !== operation2.baseLength) {
throw new Error("Both operations have to have the same base length");
}
var operation1prime = new TextOperation();
var operation2prime = new TextOperation();
var ops1 = operation1.ops, ops2 = operation2.ops;
var i1 = 0, i2 = 0;
var op1 = ops1[i1++], op2 = ops2[i2++];
while (true) {
// At every iteration of the loop, the imaginary cursor that both
// operation1 and operation2 have that operates on the input string must
// have the same position in the input string.
if (typeof op1 === 'undefined' && typeof op2 === 'undefined') {
// end condition: both ops1 and ops2 have been processed
break;
}
// next two cases: one or both ops are insert ops
// => insert the string in the corresponding prime operation, skip it in
// the other one. If both op1 and op2 are insert ops, prefer op1.
if (isInsert(op1)) {
operation1prime.insert(op1);
operation2prime.retain(op1.length);
op1 = ops1[i1++];
continue;
}
if (isInsert(op2)) {
operation1prime.retain(op2.length);
operation2prime.insert(op2);
op2 = ops2[i2++];
continue;
}
if (typeof op1 === 'undefined') {
throw new Error("Cannot compose operations: first operation is too short.");
}
if (typeof op2 === 'undefined') {
throw new Error("Cannot compose operations: first operation is too long.");
}
var minl;
if (isRetain(op1) && isRetain(op2)) {
// Simple case: retain/retain
if (op1 > op2) {
minl = op2;
op1 = op1 - op2;
op2 = ops2[i2++];
} else if (op1 === op2) {
minl = op2;
op1 = ops1[i1++];
op2 = ops2[i2++];
} else {
minl = op1;
op2 = op2 - op1;
op1 = ops1[i1++];
}
operation1prime.retain(minl);
operation2prime.retain(minl);
} else if (isDelete(op1) && isDelete(op2)) {
// Both operations delete the same string at the same position. We don't
// need to produce any operations, we just skip over the delete ops and
// handle the case that one operation deletes more than the other.
if (-op1 > -op2) {
op1 = op1 - op2;
op2 = ops2[i2++];
} else if (op1 === op2) {
op1 = ops1[i1++];
op2 = ops2[i2++];
} else {
op2 = op2 - op1;
op1 = ops1[i1++];
}
// next two cases: delete/retain and retain/delete
} else if (isDelete(op1) && isRetain(op2)) {
if (-op1 > op2) {
minl = op2;
op1 = op1 + op2;
op2 = ops2[i2++];
} else if (-op1 === op2) {
minl = op2;
op1 = ops1[i1++];
op2 = ops2[i2++];
} else {
minl = -op1;
op2 = op2 + op1;
op1 = ops1[i1++];
}
operation1prime['delete'](minl "'delete'");
} else if (isRetain(op1) && isDelete(op2)) {
if (op1 > -op2) {
minl = -op2;
op1 = op1 + op2;
op2 = ops2[i2++];
} else if (op1 === -op2) {
minl = op1;
op1 = ops1[i1++];
op2 = ops2[i2++];
} else {
minl = op1;
op2 = op2 + op1;
op1 = ops1[i1++];
}
operation2prime['delete'](minl "'delete'");
} else {
throw new Error("The two operations aren't compatible");
}
}
return [operation1prime, operation2prime];
};我们可以看到,对于 site1 来说,先执行了本地的 op1,然后对于 site2 产生的 op2,在 op1 的基础上进行了一次转换,得到 op2',对于 site2 也是如此,二者均将对方的操作进行了一次转换,从而使得最终的效果保持一致。这就是 OT 的核心思路。
在这里,我们以ot.js[4]为例,探索它的实现方式。
// Transform takes two operations A and B that happened concurrently and
// produces two operations A' and B' (in an array) such that
// `apply(apply(S, A), B') = apply(apply(S, B), A')`. This function is the
// heart of OT.
TextOperation.transform = function (operation1, operation2) {
if (operation1.baseLength !== operation2.baseLength) {
throw new Error("Both operations have to have the same base length");
}
var operation1prime = new TextOperation();
var operation2prime = new TextOperation();
var ops1 = operation1.ops, ops2 = operation2.ops;
var i1 = 0, i2 = 0;
var op1 = ops1[i1++], op2 = ops2[i2++];
while (true) {
// At every iteration of the loop, the imaginary cursor that both
// operation1 and operation2 have that operates on the input string must
// have the same position in the input string.
if (typeof op1 === 'undefined' && typeof op2 === 'undefined') {
// end condition: both ops1 and ops2 have been processed
break;
}
// next two cases: one or both ops are insert ops
// => insert the string in the corresponding prime operation, skip it in
// the other one. If both op1 and op2 are insert ops, prefer op1.
if (isInsert(op1)) {
operation1prime.insert(op1);
operation2prime.retain(op1.length);
op1 = ops1[i1++];
continue;
}
if (isInsert(op2)) {
operation1prime.retain(op2.length);
operation2prime.insert(op2);
op2 = ops2[i2++];
continue;
}
if (typeof op1 === 'undefined') {
throw new Error("Cannot compose operations: first operation is too short.");
}
if (typeof op2 === 'undefined') {
throw new Error("Cannot compose operations: first operation is too long.");
}
var minl;
if (isRetain(op1) && isRetain(op2)) {
// Simple case: retain/retain
if (op1 > op2) {
minl = op2;
op1 = op1 - op2;
op2 = ops2[i2++];
} else if (op1 === op2) {
minl = op2;
op1 = ops1[i1++];
op2 = ops2[i2++];
} else {
minl = op1;
op2 = op2 - op1;
op1 = ops1[i1++];
}
operation1prime.retain(minl);
operation2prime.retain(minl);
} else if (isDelete(op1) && isDelete(op2)) {
// Both operations delete the same string at the same position. We don't
// need to produce any operations, we just skip over the delete ops and
// handle the case that one operation deletes more than the other.
if (-op1 > -op2) {
op1 = op1 - op2;
op2 = ops2[i2++];
} else if (op1 === op2) {
op1 = ops1[i1++];
op2 = ops2[i2++];
} else {
op2 = op2 - op1;
op1 = ops1[i1++];
}
// next two cases: delete/retain and retain/delete
} else if (isDelete(op1) && isRetain(op2)) {
if (-op1 > op2) {
minl = op2;
op1 = op1 + op2;
op2 = ops2[i2++];
} else if (-op1 === op2) {
minl = op2;
op1 = ops1[i1++];
op2 = ops2[i2++];
} else {
minl = -op1;
op2 = op2 + op1;
op1 = ops1[i1++];
}
operation1prime['delete'](minl "'delete'");
} else if (isRetain(op1) && isDelete(op2)) {
if (op1 > -op2) {
minl = -op2;
op1 = op1 + op2;
op2 = ops2[i2++];
} else if (op1 === -op2) {
minl = op1;
op1 = ops1[i1++];
op2 = ops2[i2++];
} else {
minl = op1;
op2 = op2 + op1;
op1 = ops1[i1++];
}
operation2prime['delete'](minl "'delete'");
} else {
throw new Error("The two operations aren't compatible");
}
}
return [operation1prime, operation2prime];
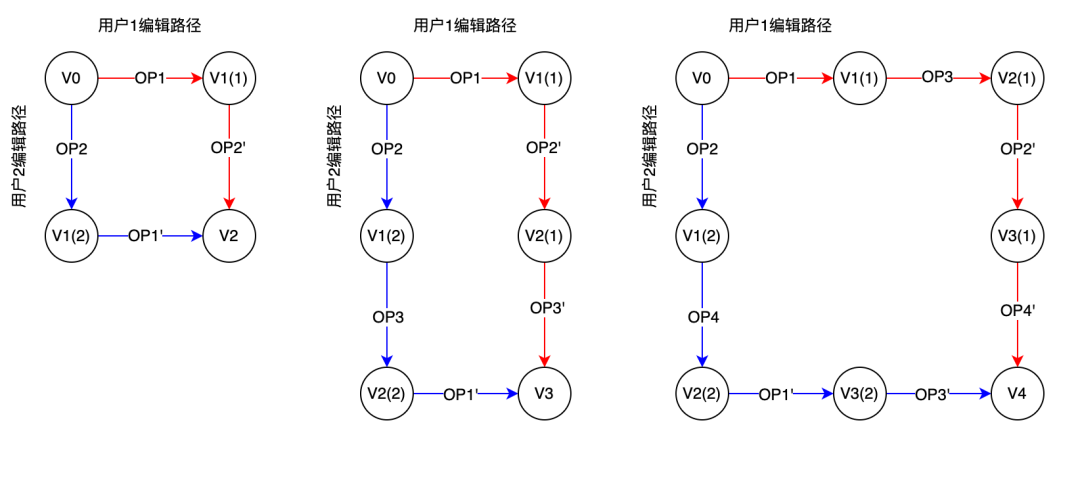
};基于以上转换思路,我们考虑实际的场景。通常可能会有超过两个用户同时编辑文档,这时该如何处理多个用户之间的转换关系呢?倘若存在 n 个用户,是否需要维护 n(n-1)/2 套转换关系?这样心智负担是否太重了?因此为了简洁,ot.js 采用了主从架构,即每个副本只与服务器进行交互,服务器作为唯一原本。对于某个副本来说,任何其他副本产生的操作,在服务端进行转换以后,均可以视为从服务端产生的操作。

每个本地副本也会维持一个 revision,他也是严格递增的,但是服务端的 rivison 可以覆盖本地。
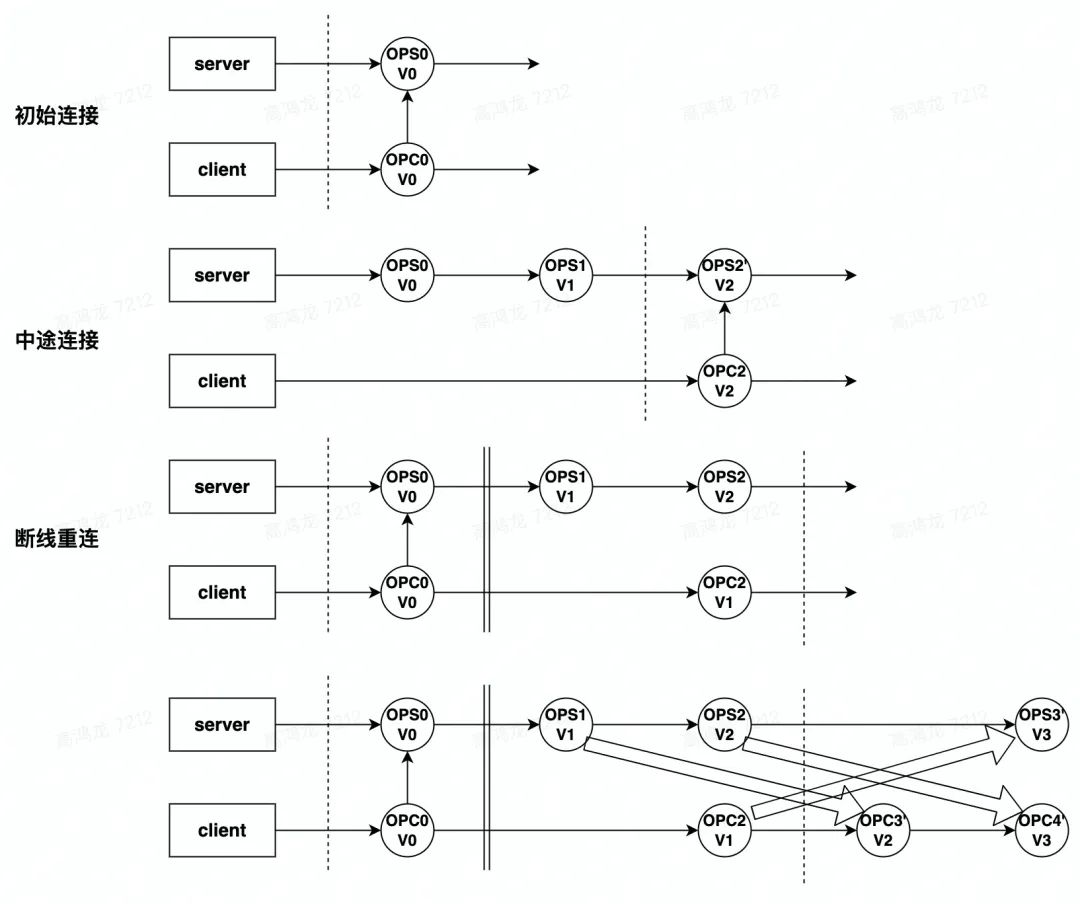
对于 OT 来说,由于所有的变更都是基于操作来做的,因此随着文档规模和并发数的上升,对于单个副本(upstream)来说,开销增长并不大(单个副本的开销主要来源于通过文本 diff 产生对应操作),但是对于服务端(downstream)来说,由于所有的转换操作都需要服务端完成,因此服务端的计算压力是巨大的。通常来说,采用 OT 方案的协同编辑,并发数上升以后,服务端可以感觉到明显的延迟。
CRDT(Conflict-free Replicated Data Type)
Conflict-free replicated data type(CRDT),中文解释为无冲突复制数据类型。在分布式计算中,CRDT)是一种可以在网络中的多台计算机之间复制的数据结构,其中副本可以独立和同时更新,而无需副本之间的协调,并且始终在数学上可以解决可能出现的不一致。
CRDT 概念于 2011 年由 Marc Shapiro、Nuno Preguiça、Carlos Baquero 和 Marek Zawirski 正式定义。最初是由协作文本编辑和移动计算推动的。CRDT 还被用于在线聊天系统、在线赌博和 SoundCloud 音频分发平台。NoSQL 分布式数据库 Redis、Riak 和 Cosmos DB 具有 CRDT 数据类型。除此之外,大家熟悉的 atom 编辑器的插件@atom/teletype,以及知名设计软件 figma 也都是基于 CRDT 实现的。
如说 OT 的核心是操作的话,那么 CRDT 的核心就是数据结构。通常来说,CRDT 也分为Operation-based和State-based。
在介绍文本编辑相关的 CRDT 之前,我们先来看一个最简单的基于状态的 CRDT:G-Counter (Grow-only Counter)
payload integer[n] P
initial [0,0,...,0]
update increment()
let g = myId()
P[g] := P[g] + 1
query value() : integer v
let v = Σ(i) P[i]
compare (X, Y) : boolean b
let b = (∀i ∈ [0, n - 1] : X.P[i] ≤ Y.P[i])
merge (X, Y) : payload Z
let ∀i ∈ [0, n - 1] : Z.P[i] = max(X.P[i], Y.P[i])此 CRDT 为具有 n 个节点的集群实现了一个计数器。集群中的每个节点都分配有一个从 0 到 n - 1 的 ID,通过调用 myId() 来检索该 ID。因此,每个节点都在数组 P 中分配了自己的槽,它在本地递增。更新在后台传播,并通过获取 P 中每个元素的 max() 进行合并。包含比较函数以说明状态的偏序。合并函数是可交换的、关联的和幂等的。更新函数根据比较函数单调增加内部状态。因此,这是一个正确定义的 CRDT,并将提供强大的最终一致性。等价的 CmRDT 在收到增量操作时广播它们。
文本编辑的 CRDT 则属于另一种类型:Sequence CRDT。顾名思义,这种 CRDT 适用于序列化的字符串。一些知名的序列 CRDT 是 Treedoc、RGA、 Woot、 Logoot、 LSEQ 和 YJS。为了方便理解,我们选择相对简单的 Treedoc 进行介绍。
Treedoc,从名字上可以看出,它是一个以树表达文档的数据结构,接下来需要明确一些定义:
文档树(Treedoc)。我们用一个二叉树来表示文档,二叉树的中序遍历结果就是文档本身。例如对于文档内容 abcdef,我们有这样一棵二叉树:
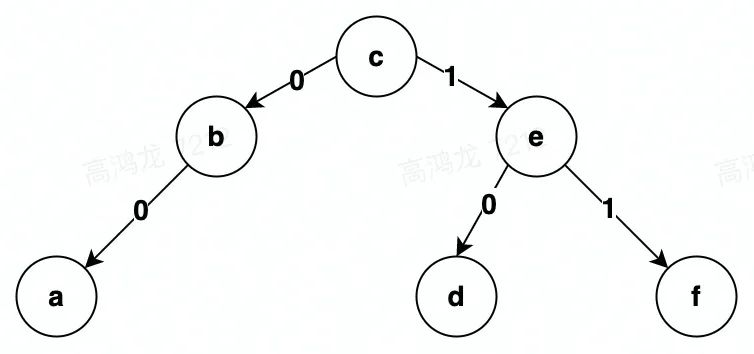
-
文档 中的每个原子缓冲区有一个标识符。
-
没有两个不同的原子有相等的标识符。
-
给定原子的标识符在文档的整个生命周期中保持不变。
-
有标识符的总顺序与缓冲区中的原子顺序一致
-
标识符空间总是稠密的:给定任何标识符 P 和 F,P 和 F 之间的标识符都可以被访问。形式上:
∀P, F: P < F ⇒ ∃N : P < N < F。
节点(Node)。我们将一个(atom, PosID)记为一个节点。
路径(path)。从根结点出发,到达目标节点的路径。例如 c 的路径是 root, d 的路径是 root->1->0,通常我们会省略 root。在 treedoc 中,path 就是我们需要的 PosID。
操作(operation)。每个用户都可以在本地维护一个副本,每个副本都具备两个基本操作:
-
insert(PosIDn, newatom)。在指定 PosIDn 的位置插入新的原子 newatom。
-
delete(PosIDn)。删除指定 PosIDn 上的原子。
基于以上操作定义:
// 在c和d之间插入字符w
PosID(c) = ''
Atom(c) = 'c'
Node(c) = ('c', '')
PosID(d) = '10'
Atom(d) = 'd'
Node(d) = ('d', '10')
// 执行插入操作
Insert('100', 'w')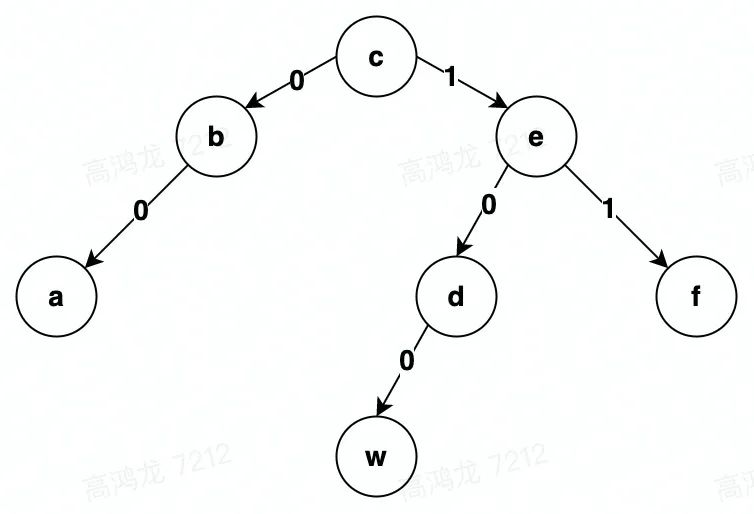
// 删除节点e
PosID(e) = '1'
Atom(e) = 'e'
Node(e) = ('e', '1')
// 执行删除操作
Delete('1')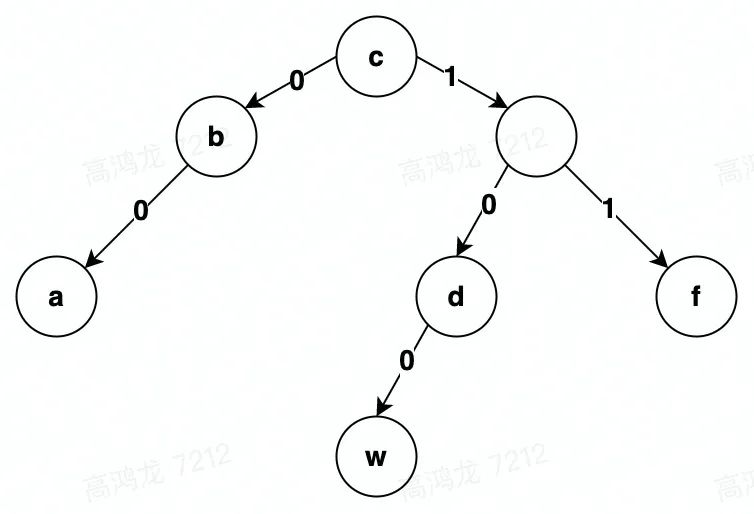

但是,如果同时写入同一个节点呢?此时便会产生冲突。因此在多人编辑场景下,我们需要对当前数据结构进行扩充。
消歧符(Disambiguator)。用于区分不同用户产生的操作,通常来说可以用户 ID 来表示。
迷你节点(MiniNode)。对现有 node 的扩充,一个 node 内部有多个 mini node,其排列顺序按照 Disambiguator 的值来决定。
暂时无法在飞书文档外展示此内容
这样一来,节点 w 的路径可以表示为10(0: dA) 通过这种方式,我们可以保证多个用户同时参与编辑时,所有的操作都可以被正确合并。
相比于 OT,CRDT 的服务端开销是极低的,服务器只负责转发操作即可。甚至在某些场景下,借助于 webRTC 等 p2p 技术,多人协同的过程可完全不需要服务端参与,每个 peer 只需要将本人操作广播给其他 peer 即可。
一些优化手段:
- 垃圾回收:通常来说 CRDT 删除内容时并不会直接删除对应的节点。对于不再具备子节点,同时自身也为空的节点,我们可以直接回收该节点
- 降低原子粒度:以字符为单位的 treedoc 是极为庞大的,可以将其适当或者局部调整为以单词或者以行为单位的 treedoc,可以大大降低数的复杂度。
- 批量插入新节点:通常来说,编辑操作总是发生在同一个位置,比如文章尾部。逐个添加可能会导致数在不满秩的同时到达极大的深度。于是我们可以直接插入一棵平衡二叉树,从而减少搜索深度。
暂时无法在飞书文档外展示此内容
小结
通过以上探索,我们了解了实时协同场景面临的问题,并且掌握了 OT 和 CRDT 两种方案的基本原理,总结来说,
-
OT 作为一种基于操作的方案,历史更悠久,方案更成熟,目前也是业界最主流的协同方案,久经考验,值得信赖。
-
CRDT 作为基于数据结构的方案,相对年轻,但是更加优雅,且更适合分布式场景,目前也有越来越多的产品在尝试使用 CRDT。
开源库
-
OT based
-
ot.js[5]
-
sharedb[6]
-
CRDT based
-
@atom/teletype-crdt[7]
-
yjs[8]
参考资料
[1]协同编辑(collaborative editing): https://en.wikipedia.org/wiki/Collaborative_editing
[2]最长公共子序列问题: https://en.wikipedia.org/wiki/Longest_common_subsequence_problem
[3]jsdiff: https://github.com/kpdecker/jsdiff
[4]ot.js: https://github.com/Operational-Transformation/ot.js
[5]ot.js: https://github.com/Operational-Transformation/ot.js/
[6]sharedb: https://github.com/share/sharedb
[7]@atom/teletype-crdt: https://github.com/atom/teletype-crdt
[8]yjs: https://github.com/yjs/yjs