进程切换的本质是什么?
我们都知道操作系统最重要的功能之一是多任务能力,也就是可以运行超过CPU数量的程序——即进程,要想实现这一功能就必须具备将有限的CPU资源在多个进程之间分配的能力,在程序员看来,我们的程序在一直运行,而在CPU看来程序其实在“走走停停”,程序的一走一停就涉及到进程切换,那么进程切换的本质是什么呢?
从本质上讲,函数调用和进程切换是非常类似的,有的同学可能会有疑问,这怎么可能呢?别着急,看完这篇你就明白啦。
函数调用
我们先来看一下函数调用,函数调用是这样的,A函数调用B函数,当B函数执行完成时会跳转回A函数(此时A函数和B函数位于同一个进程):
void B() {
...
}
void A() {
...
}这个过程是这样的:
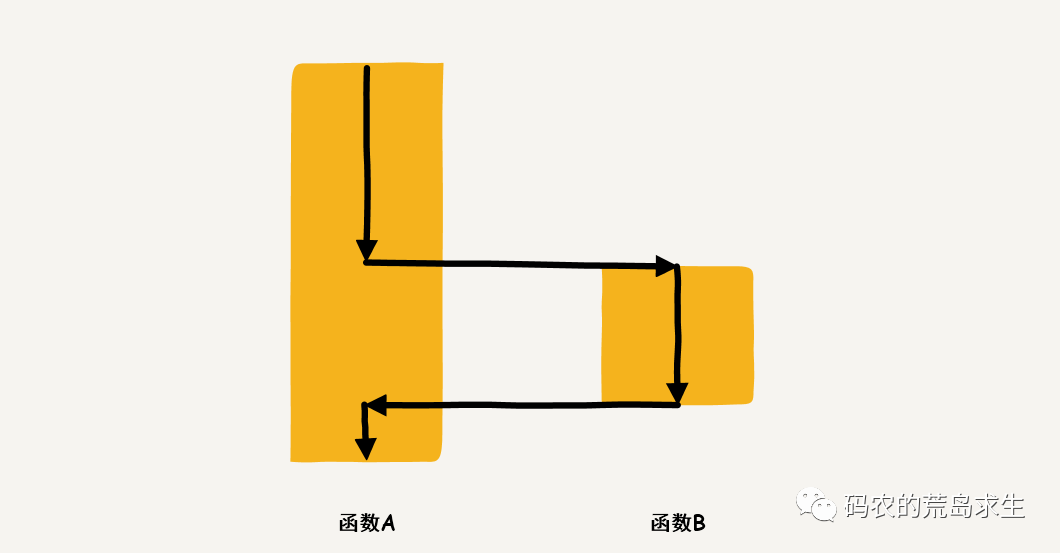
B函数执行完成后会将控制权转给A,所谓控制权是指告诉CPU继续执行函数A。
but,你有没有想过,A函数调用B函数,B函数执行完成时一定要跳转回A函数吗?不一定的,既然B函数可以将控制权转给A那么就能将控制权转给函数C。
听上去很神奇有没有,A函数调用B函数,当B函数执行完成时竟然可以跳转到C函数,可这该怎样做到呢?让我们来看一段神奇的代码。
一段神奇的代码
有这样一段代码:
#include <stdio.h>
#include <stdlib.h>
void funcC() {
printf("jump to funcC !!!\n") ;
exit(-1) ;
}
void funcB() {
long *p = NULL ;
p = (long*)&p ;
*(p+2) = (long)funcC ;
}
void funcA() {
funcB();
}
int main() {
funcA() ;
return 0 ;
}想一想这段代码运行后会输出什么?
有的同学可能会说main函数调用了funcA,funcA函数调用了funcB,funcB函数看上就是一堆赋值,执行完成后返回了funcA,funcA又返回main函数,因此执行完毕后什么都不会输出。
真的是这样的吗?让我们编译运行一下(小风哥使用的是5.2.0版gcc,64位机器,未开启编译优化,不同编译器版本运行效果可能不同)。
$ ./a.out
jump to funcC !!!有的同学也许会大吃一惊,这怎么可能!!!
这段明明没有调用funcC,可为什么funcC函数却运行了?
程序员经常说“代码之中没有秘密”,这句话不全对,应该是“机器指令中没有秘密”,后来我想了想,这句话也不全对,因为对我们来说CPU是如何执行机器指令这回事其实对我们来说是黑盒的,我们只能从大体的原理来说CPU是怎样执行一条机器指令的,但这里真正的细节只有处理器生产商比如intel/AMD等知道,而一些魔鬼恰恰就在这些细节中。
魔鬼在细节
扯远了,让我们回到这篇文章的主题,先来看看生成的机器指令是什么样的:
0000000000400586 <funcC>:
400586: 55 push %rbp
400587: 48 89 e5 mov %rsp,%rbp
40058a: bf 74 06 40 00 mov $0x400674,%edi
40058f: e8 bc fe ff ff callq 400450 <puts@plt>
400594: bf ff ff ff ff mov $0xffffffff,%edi
400599: e8 e2 fe ff ff callq 400480 <exit@plt>
000000000040059e <funcB>:
40059e: 55 push %rbp
40059f: 48 89 e5 mov %rsp,%rbp
4005a2: 48 c7 45 f8 00 00 00 movq $0x0,-0x8(%rbp)
4005a9: 00
4005aa: 48 8d 45 f8 lea -0x8(%rbp),%rax
4005ae: 48 89 45 f8 mov %rax,-0x8(%rbp)
4005b2: 48 8b 45 f8 mov -0x8(%rbp),%rax
4005b6: 48 83 c0 10 add $0x10,%rax
4005ba: ba 86 05 40 00 mov $0x400586,%edx
4005bf: 48 89 10 mov %rdx,(%rax)
4005c2: 90 nop
4005c3: 5d pop %rbp
4005c4: c3 retq这些指令在说什么呢?
我们先来看普通的函数调用:
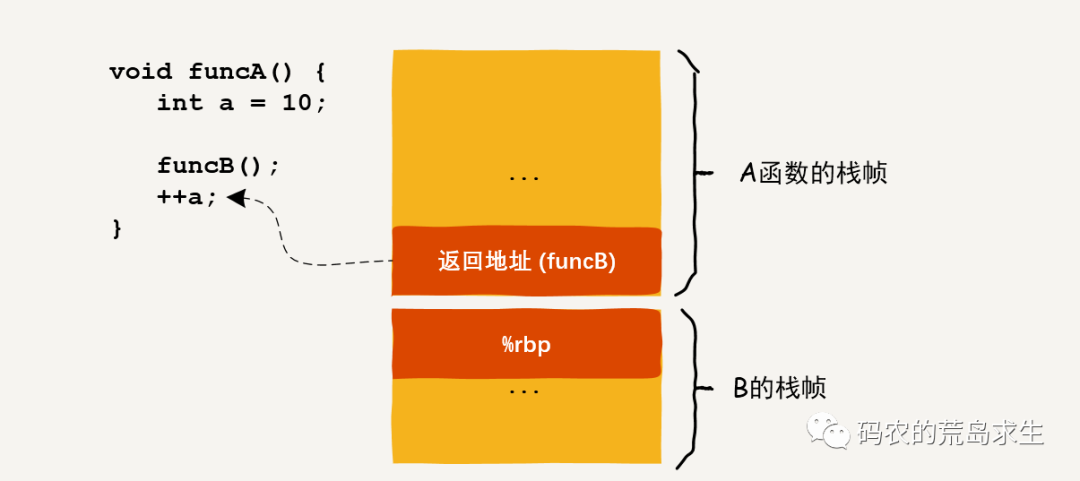
函数B的最后一条机器指令通常为:ret,这条指令的目的是将当前栈顶的内容弹出到%rip寄存器中,CPU会根据rip中的值从内存中取出指令并执行,显然ret指令会将之前保存的返回地址放入rip寄存器中,这样CPU就可以继续执行A函数中的后续代码了,也就是++a这行代码。
有的同学可能已经看出来,如果我们有办法修改A栈帧上的返回地址不就能实现“指哪打哪”了吗?
实际上代码中“*(p+2) = (long)funcC ;”这行会将本来指向funcB的返回地址修改为指向funcC,即:
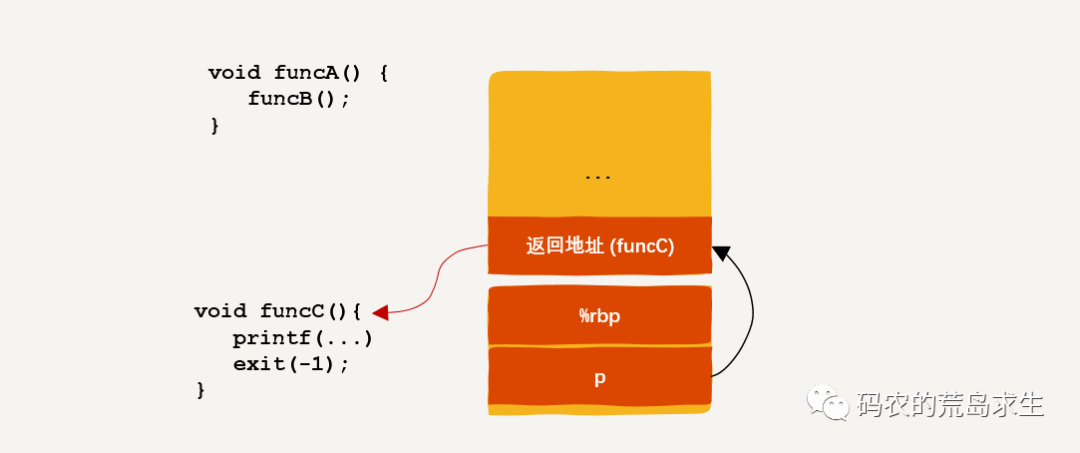
这样当funcB函数运行完成后会直接跳转到funcC函数,从而实现可控的执行流切换,进程切换的本质与此别无二致,只不过进程切换需要连带着把栈也切换过去(以及地址空间),同时还会保存被切换进程的上下文。
有的同学可能已经看出来了,上述过程叫做缓冲区溢出攻击,要实现的目的和进程切换一样:实现控制权的转移,只不过缓冲区溢出攻击是非法的,不符合预期的(符合黑客的预期,但不符合操作系统设计者制定的游戏规则),而进程切换是合法的,符合预期的(符合操作系统设计者的预期)。
而有时,(真正意义上的)黑客与操作系统设计者其实是一伙人 。
怎么样,现在你应该对进程切换有较为直观的认知了吧,当然真实的进程切换绝不像这里讲解的这样简单。