Jenkins Pipeline 复用groovy文件

前言
Jenkins作为我们目前普遍使用的CI/CD工具,有很多特性。我目前使用最多的是用Jenkins来做一些部署打包、发布前检查、自动化测试、单元测试、Lint检查等等这些工作。这些场景在一条完整的 "生产线" 上是很常见的。
例如开发aar库的时候,当每次有改动合入aar库的主分支时,我们需要将aar发布到maven仓库(此时可能是SNAPSHOT的),而这一个流程显然是可以实现自动化的,我们就完全可以借助Jenkins,来hook git 仓库的主分支merge行为,来自动打包、发布并通知到具体的开发人员。
上述的只是实际开发中的一个场景,而依据我们所在公司的组织架构,我们可能分为很多个团队,每个团队又分为很多个组(组下可能还有小组),这时可能会有很多个Jenkins的Job,随着Job的增多,Jenkins Job的配置肯定会出现很多可复用的模式。本篇文章不会过多的讲Jenkins以及pipeline的一些概念,目的是讲一下如何在pipeline中引用groovy文件,来达到pipeline一些公共函数的复用
Pipeline
pipeline是Jenkins 中最常用的一种模式,顾名思义,pipeline可以让我们像产品流水线一样来定义我们的Job,例如我们可以将一个发布的流程看作是一个流水线,我根据自己的理解简单画了一张图:
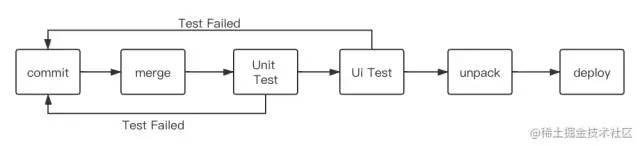
这张图大致表示了从开发阶段(commit)到最后的发布阶段需要做哪些事,这一整个流程可以看作是一个pipeline,其中每一步就是一个stage。而对应的Jenkins Job会在执行的过程中按照stage来执行,还可以结合 Blue Ocean 插件清晰的看出每一个stage的日志以及执行是否成功。
JenkinsFile
Pipeline 有两种形式,都是使用groovy来实现的,分别为:Declarative Pipeline、Scripted Pipeline。具体的写法有什么不同可以去 官网 查看,本篇文章将会以Scripted Pipeline作为例子来说明。
另外,Pipeline可以以两种方式来配置**:第一种是直接在Jenkins 新建一个 Pieline Job,然后在配置页面直接写pipeline脚本**,如下图:
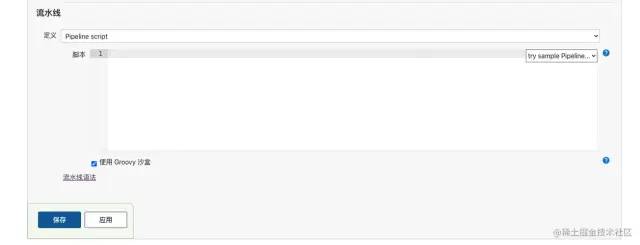
除了这种方式之外,我们可以将pipeline脚本定义在项目里,然后通过配置git仓库的方式来获取到pipeline脚本。
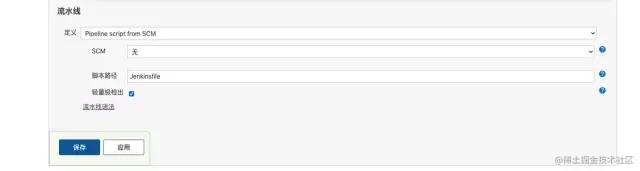
比较推荐第二种方法,因为这样很灵活,在修改了项目代码之后就可以直接改了JenkinsFile,否则还需要每次都去Jenkins配置页面再修改一下,除此之外还需要给每个人都Job的配置权限。
导入Groovy
上面对Pipeline做了一个大致的介绍。正如前文所说,当项目越来越多,pipeline就会出现很多需要复用的场景,例如如下这段pipeline:
node {
// 运行单元测试
stage('Unit Test') {
sh './run_unitTest'
}
// 导出报告、最后删除报告文件夹
stage('Test Result Reporter') {
sh './export_reporter'
archiveArtifacts './reporter'
sh 'rm -rf reporter'
}
stage('...') {
}
}
复制代码显然,在实际使用中,我们很多项目都需要单元测试以及导出报告的stage,这时这两个stage我们应该能够服用量,否则的话每个Job的pipeline都需要写一遍。有几种方式可以实现复用:
- 将公共的pipeline步骤导入到 Global Pipeline LIbraries,这个不是我们要讲的,感兴趣的话可以去官网看看:Jenkins Pipeline 扩展共享库
- 由于pipeline是用groovy脚本编写的,那么我们可以将公共的步骤抽出来,形成一个公共代码库,当需要引用公共库中的stage时,只需要将对应的groovy脚本load进来即可,这样做的好处是可以随时的修改,并且省去了上传到Jenkins 共享库的步骤,这种方式也是我们今天要讲的。
根据上面描述第二种方式,我们就可以定义一个公共脚本 unit_test.groovy:
def runUnitTest() {
sh './run_unitTest'
}
def exportReporter() {
sh './export_reporter'
archiveArtifacts './reporter'
sh 'rm -rf reporter'
}
复制代码而我们的pipeline就可以改为:
node {
def unitTestModule = load('unit_test.groovy')
// 运行单元测试
stage('Unit Test') {
unitTestModule.runUnitTest()
}
// 导出报告、最后删除报告文件夹
stage('Test Result Reporter') {
unitTestModule.exportReporter()
}
stage('...') {
}
}
复制代码可以看到,变得简洁了许多。
需要注意的是,上面的 load() 参数是需要输入对应的groovy的路径的,假设公共库与pipeline位于同一个仓库下,我们就可以直接向上面那种方式引入groovy文件。但是实际上我们可能不希望在项目里嵌入一个pipeline的公共库,理想状态是公共库是一个独立的仓库,我们同样可以去加载对应的groovy,这是我们就需要做一些额外的工作:
- 首先需要在Jenkins安装插件:Pipeline Remote Loader plugin
- 借助该插件,就可以实现直接引入其他仓库的groovy文件,如下代码:
node {
def unitTestModule = fileLoader.fromGit('your_groovy_path', 'git_repository_url', 'branch', 'credentialsId', 'node_label')
// 运行单元测试
stage('Unit Test') {
unitTestModule.runUnitTest()
}
// 导出报告、最后删除报告文件夹
stage('Test Result Reporter') {
unitTestModule.exportReporter()
}
stage('...') {
}
}
复制代码当安装了 Pipeline Remote Loader plugin 插件后,就可以使用 fileLoader.fromGit() 来load对应仓库下的groovy了。那么当需要引入多个groovy文件应该怎么办呢?可以使用如下方法:
fileLoader.withGit('git_repository_url', 'branch', 'credentialsId', 'node_label') {
def unitTestModule = load('your_unit_test_groovy_path')
def otherModule = load('your_other_groovy_path')
...
}
复制代码可以看到,如果要导入多个脚本,则使用withGit就可以了。
fileLoader 有五个API:
-
fromGIt(String libPath, String repository, String branch, String credentialsId, String labelExpression )从指定的git 仓库加载单个groovy文件
-
withGit(String repository, String branch, String credentialsId, String labelExpression)从指定的git 仓库加载一组groovy文件
-
fromSVN(String libPath, String repository, String credentialsId, String labelExpression)从指定的SVN 仓库加载单个 groovy文件
-
withSVN(String repository, String credentialsId, String labelExpression)从指定的SVN 仓库加载一组groovy文件
-
load(String libPath)根据路径加载groovy文件
参数释义:
- libPath: groovy 文件的相对路径
- repository: Git或者SVN的地址
- branch: 对应的分支
- credentialsId: 已经添加进Jenkins的去Git或者SVN拉代码的凭据,一般是用户名+密码或者是私钥。具体怎么配可以搜一下,网上有很多。
- labelExpression: 是否指定node运行该操作。
总结
可以看到,通过Pipeline Remote Loader plugin 插件就可以随意的引用groovy文件了,可以帮助我们实现pipeline脚本的复用,大家可以根据自己的项目来选择使用哪种复用方式。