Go语言核心手册-6.GMP原理
6.1 协程和线程
协程跟线程是有区别的,线程由CPU调度是抢占式的,协程由用户态调度是协作式的,一个协程让出CPU后,才执行下一个协程。
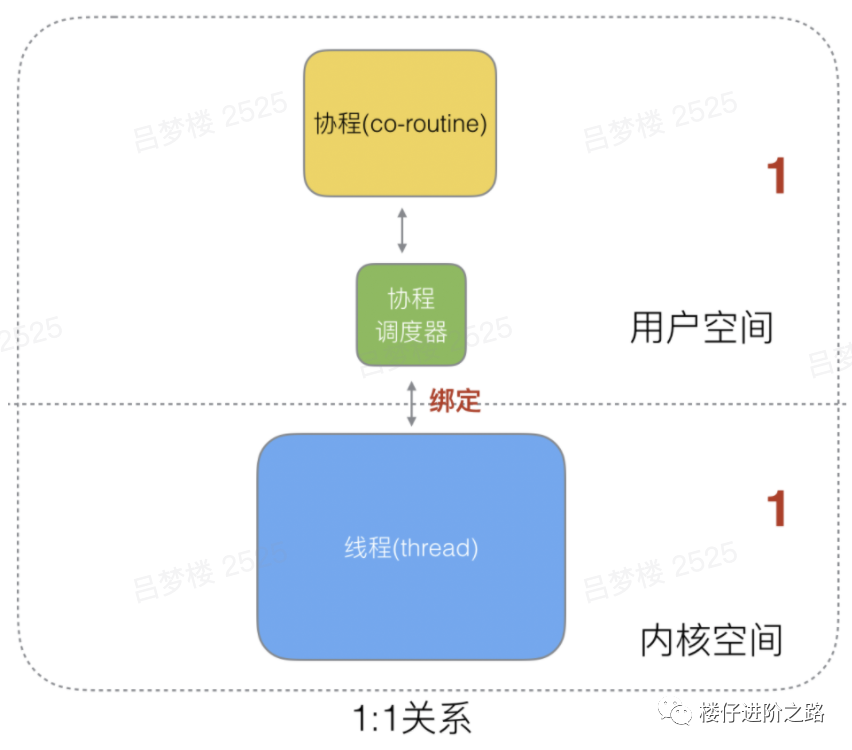
6.1.1 1:1关系
- 优点:1个协程绑定1个线程,这种最容易实现,协程的调度都由CPU完成了。
- 缺点:协程的创建、删除和切换的代价都由CPU完成,有点略显昂贵了。
6.1.2 N:1关系
- 优点:N个协程绑定1个线程,协程在用户态线程即完成切换,不会陷入到内核态,这种切换非常的轻量快速。
- 缺点:1个进程的所有协程都绑定在1个线程上,某个程序用不了硬件的多核加速能力,一旦某协程阻塞,造成线程阻塞,本进程的其他协程都无法执行了,根本就没有并发的能力了。

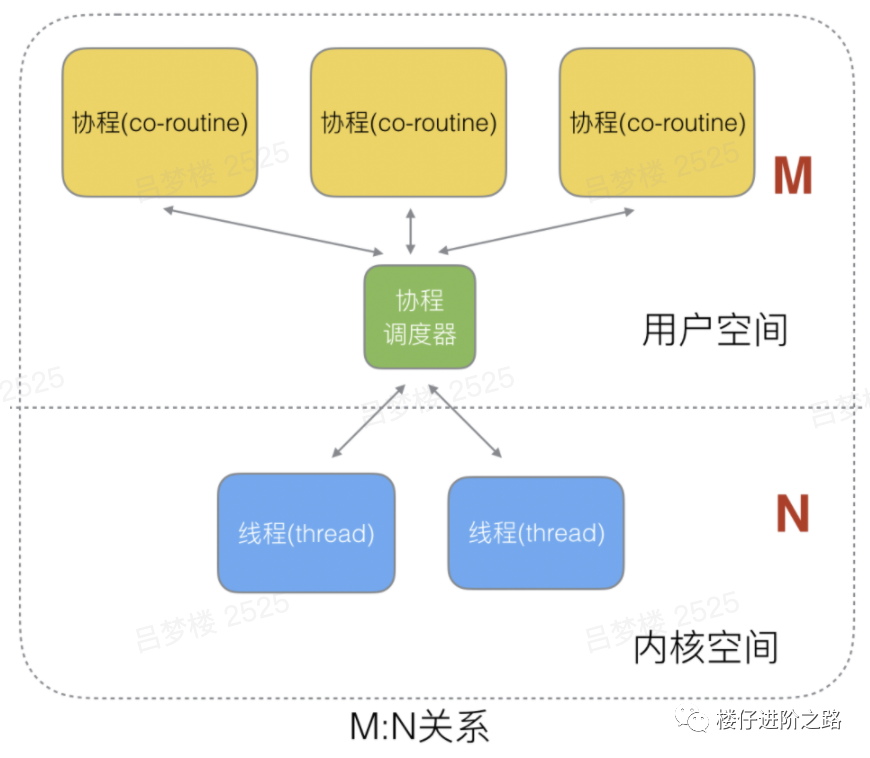
6.1.3 M:N关系
- 优点:M个协程绑定1个线程,是N:1和1:1类型的结合,克服了以上2种模型的缺点。
- 缺点:实现起来最为复杂。
6.2 GMP模型
Go为了提供更容易使用的并发方法,使用了goroutine和channel。goroutine来自协程的概念,让一组可复用的函数运行在一组线程之上,即使有协程阻塞,该线程的其他协程也可以被runtime调度,转移到其他可运行的线程上。最关键的是,程序员看不到这些底层的细节,这就降低了编程的难度,提供了更容易的并发。
goroutine非常轻量,一个goroutine只占几KB,并且这几KB就足够goroutine运行完,这就能在有限的内存空间内支持大量goroutine,支持了更多的并发。虽然一个goroutine的栈只占几KB,但实际是可伸缩的,如果需要更多内容,runtime会自动为goroutine分配。
6.2.1 模型说明
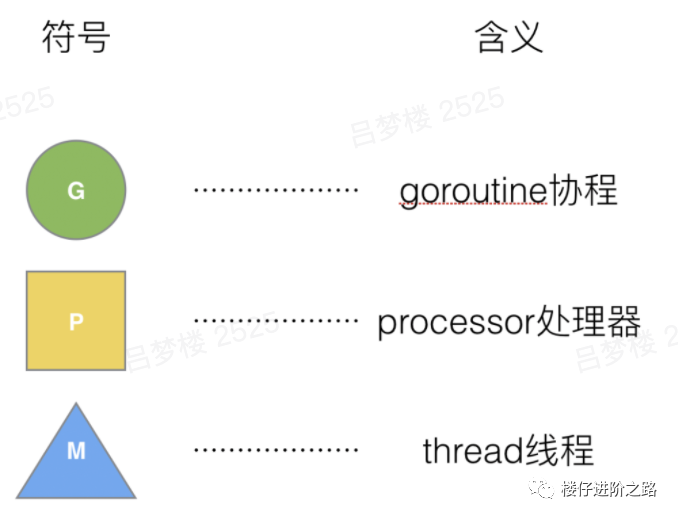
G来表示Goroutine,M来表示线程,P来表示Processor:
线程是运行goroutine的实体,调度器的功能是把可运行的goroutine分配到工作线程上:
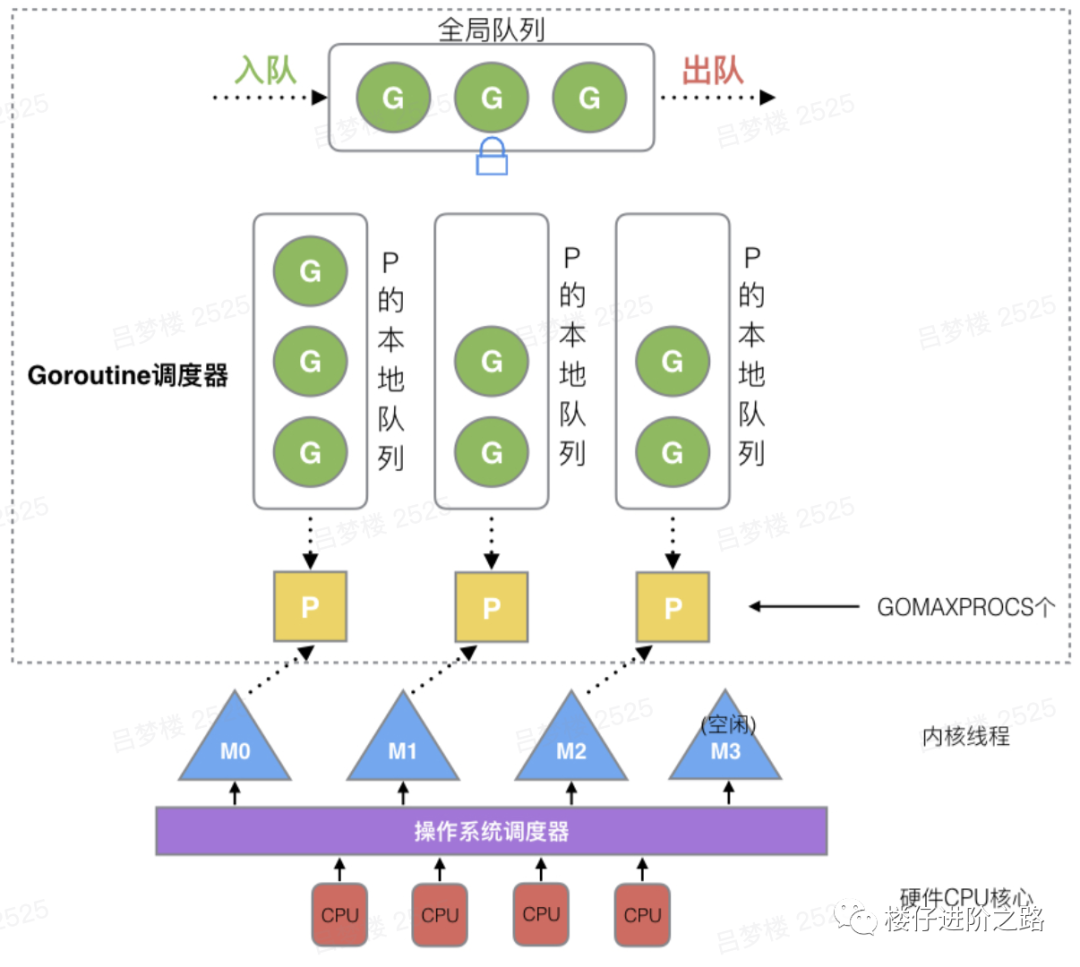
Goroutine调度器和OS调度器是通过M结合起来的,每个M都代表了1个内核线程,OS调度器负责把内核线程分配到CPU的核上执行,对上图的解读如下:
- 全局队列(Global Queue):存放等待运行的G。
- P的本地队列:同全局队列类似,存放的也是等待运行的G,存的数量有限,不超过256个。新建G'时,G'优先加入到P的本地队列,如果队列满了,则会把本地队列中一半的G移动到全局队列。
- P列表:所有的P都在程序启动时创建,并保存在数组中,最多有GOMAXPROCS(可配置)个。
- M:线程想运行任务就得获取P,从P的本地队列获取G,P队列为空时,M也会尝试从全局队列拿一批G放到P的本地队列,或从其他P的本地队列偷一半放到自己P的本地队列。M运行G,G执行之后,M会从P获取下一个G,不断重复下去。
6.2.2 调度流程
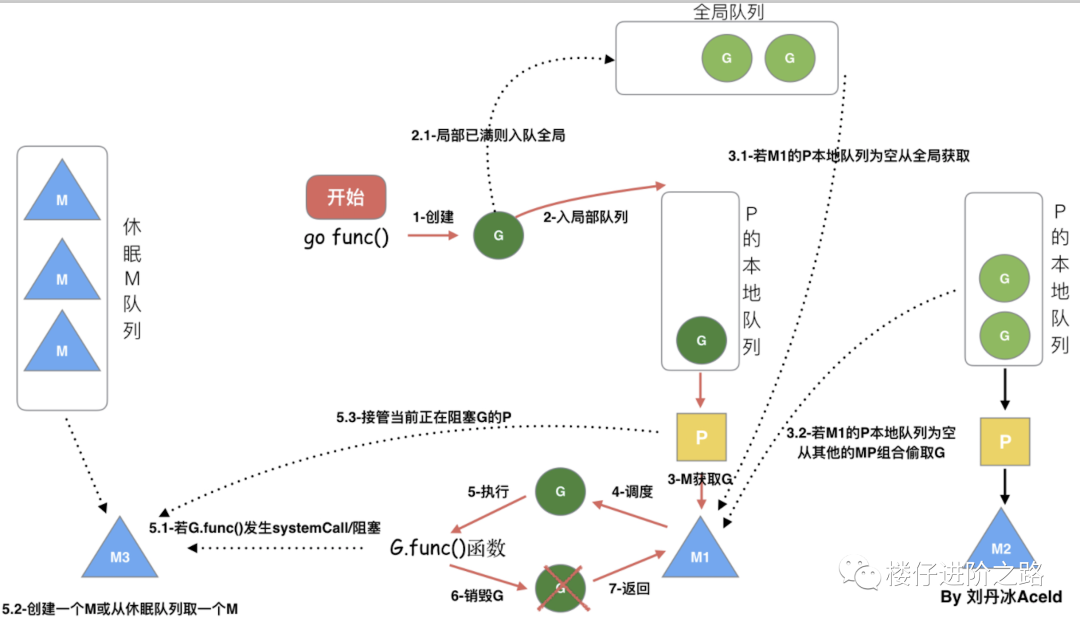
从上图我们可以分析出几个结论:
- 我们通过 go func()来创建一个goroutine;
- 有两个存储G的队列,一个是局部调度器P的本地队列、一个是全局G队列。新创建的G会先保存在P的本地队列中,如果P的本地队列已经满了就会保存在全局的队列中;
- G只能运行在M中,一个M必须持有一个P,M与P是1:1的关系。M会从P的本地队列弹出一个可执行状态的G来执行,如果P的本地队列为空,就会想其他的MP组合偷取一个可执行的G来执行;
- 一个M调度G执行的过程是一个循环机制;
- 当M执行某一个G时候如果发生了syscall或则其余阻塞操作,M会阻塞,如果当前有一些G在执行,runtime会把这个线程M从P中摘除(detach),然后再创建一个新的操作系统的线程(如果有空闲的线程可用就复用空闲线程)来服务于这个P;
- 当M系统调用结束时候,这个G会尝试获取一个空闲的P执行,并放入到这个P的本地队列。如果获取不到P,那么这个线程M变成休眠状态, 加入到空闲线程中,然后这个G会被放入全局队列中。
6.3 调度场景
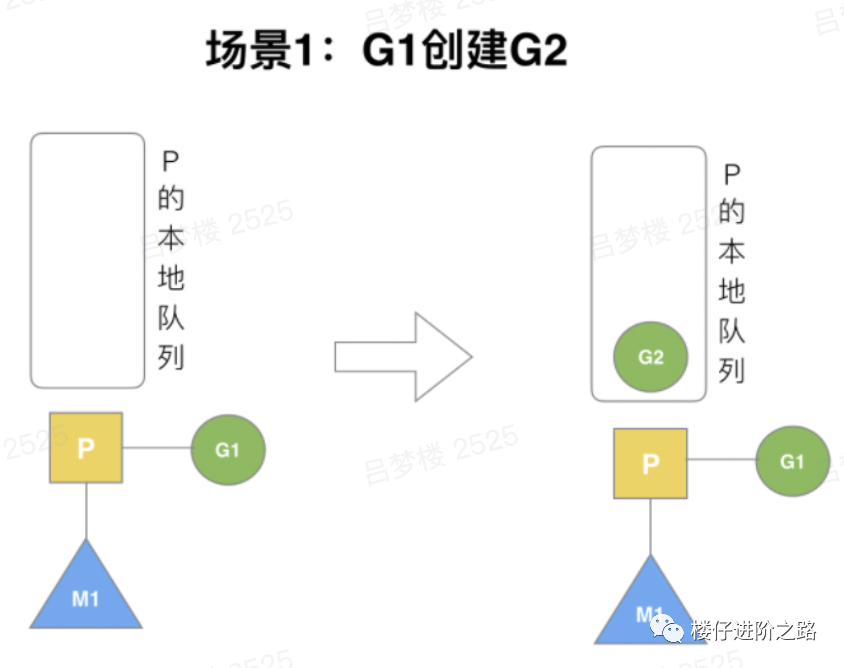
6.3.1 G1创建G2
场景:P拥有G1,M1获取P后开始运行G1,G1使用go func()创建了G2,为了局部性G2优先加入到P1的本地队列。
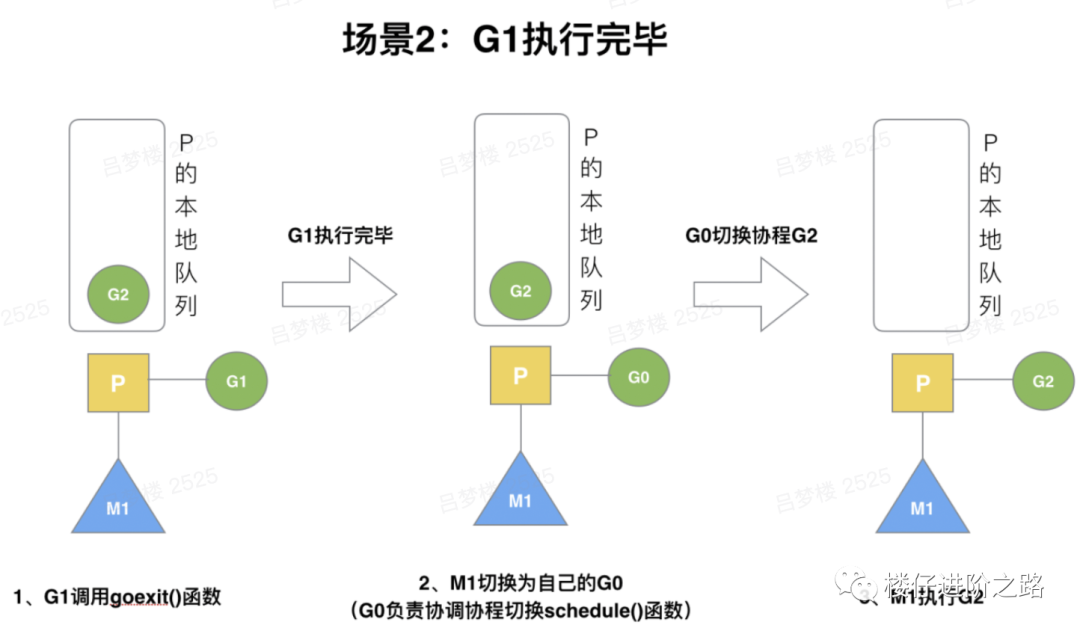
6.3.2 G1执行完毕
场景:G1运行完成后,M上运行的goroutine切换为G0,G0负责调度时协程的切换。从P的本地队列取G2,从G0切换到G2,并开始运行G2,实现了线程M1的复用。
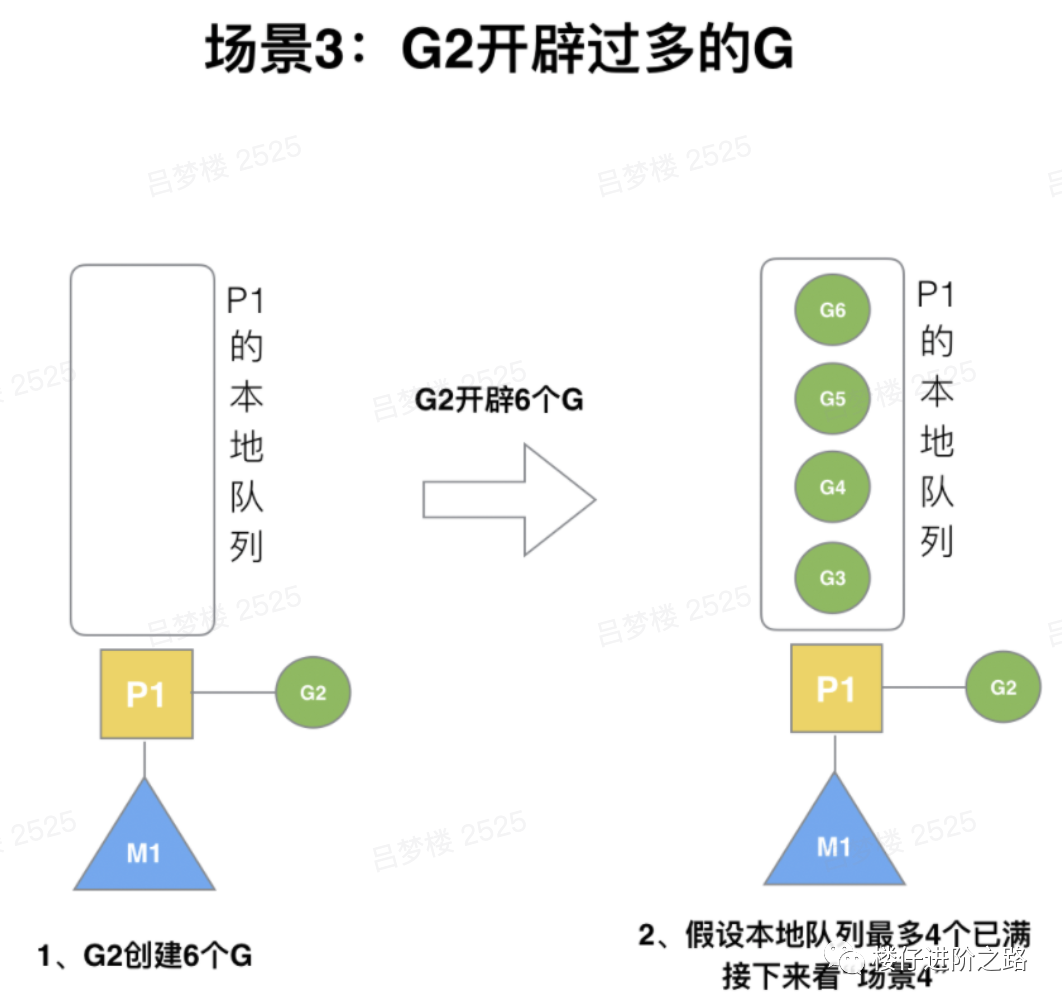
6.3.3 G2开辟过多的G
场景:假设每个P的本地队列只能存3个G。G2要创建了6个G,前3个G(G3, G4, G5)已经加入p1的本地队列,p1本地队列满了。
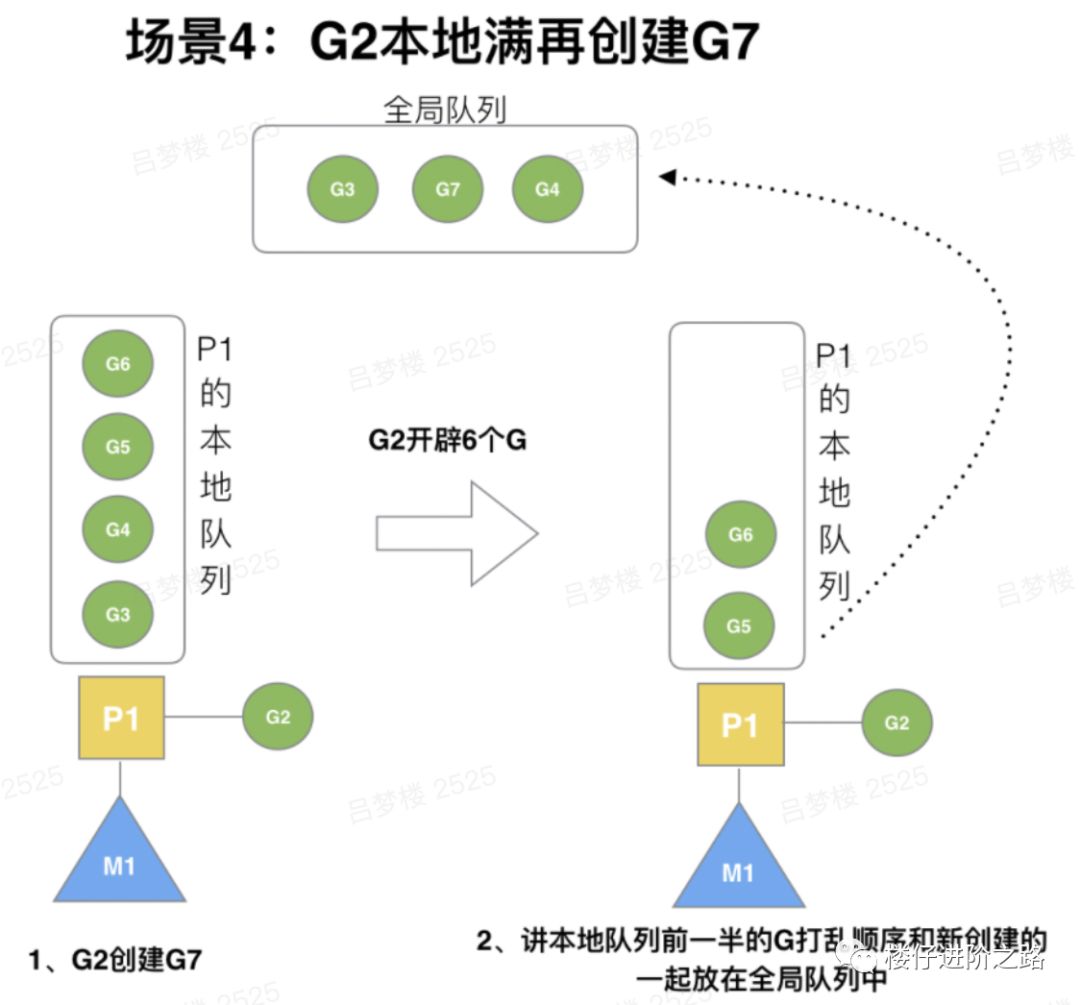
6.3.4 G2本地满再创建G7
场景:G2在创建G7的时候,发现P1的本地队列已满,需要执行负载均衡(把P1中本地队列中前一半的G,还有新创建G转移到全局队列)(实现中并不一定是新的G,如果G是G2之后就执行的,会被保存在本地队列,利用某个老的G替换新G加入全局队列)说明:这些G被转移到全局队列时,会被打乱顺序。所以G3,G4,G7被转移到全局队列。
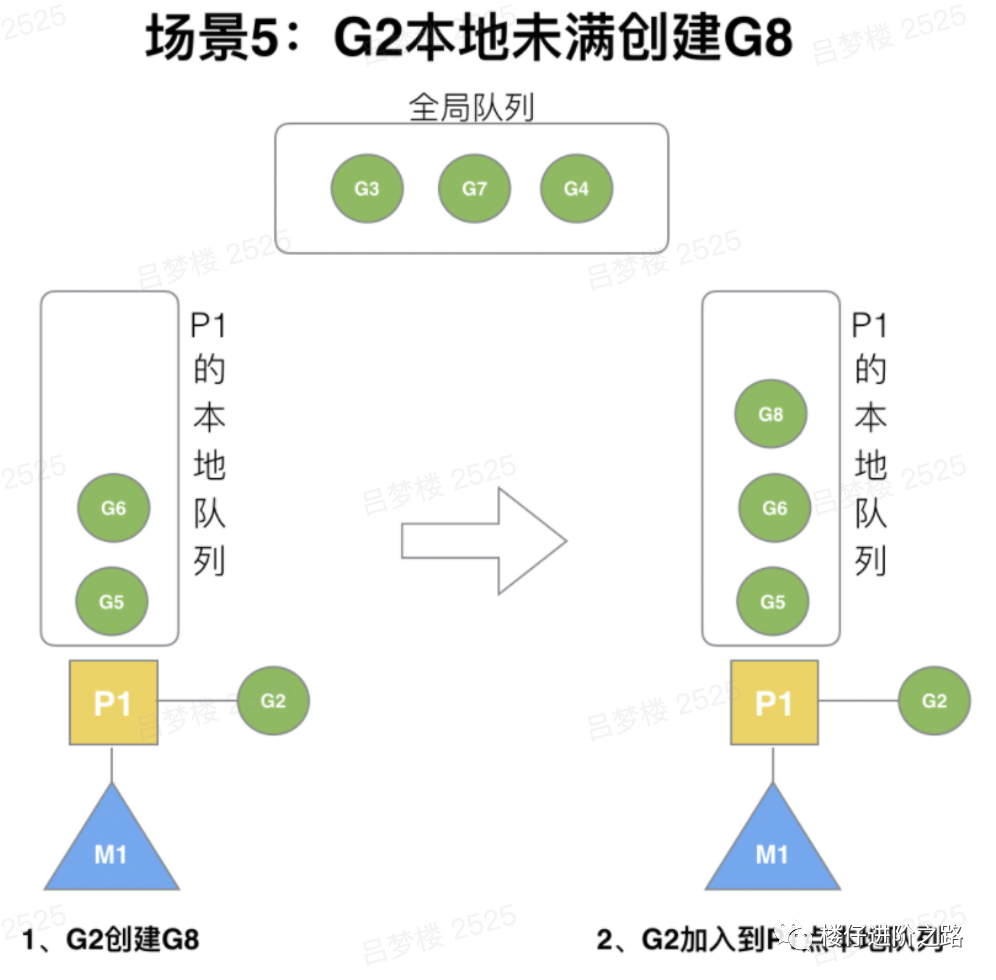
6.3.5 G2本地未满再创建G8
场景:G2创建G8时,P1的本地队列未满,所以G8会被加入到P1的本地队列。
说明:G8加入到P1点本地队列的原因还是因为P1此时在与M1绑定,而G2此时是M1在执行。所以G2创建的新的G会优先放置到自己的M绑定的P上。
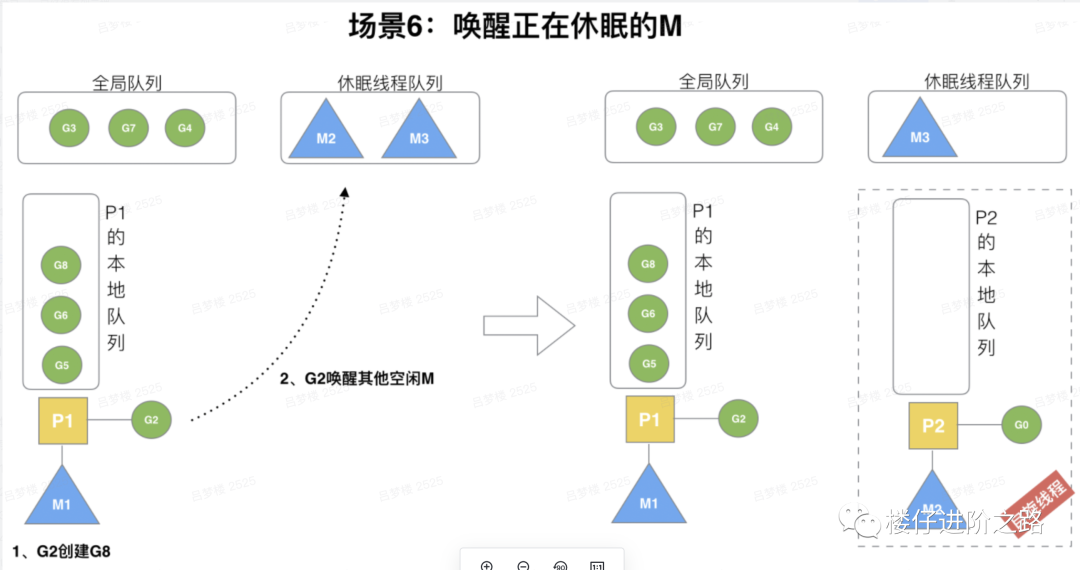
6.3.6 G2本地未满再创建G8
场景:在创建G时,运行的G会尝试唤醒其他空闲的P和M组合去执行。
说明:假定G2唤醒了M2,M2绑定了P2,并运行G0,但P2本地队列没有G,M2此时为自旋线程(没有G但为运行状态的线程,不断寻找G)。
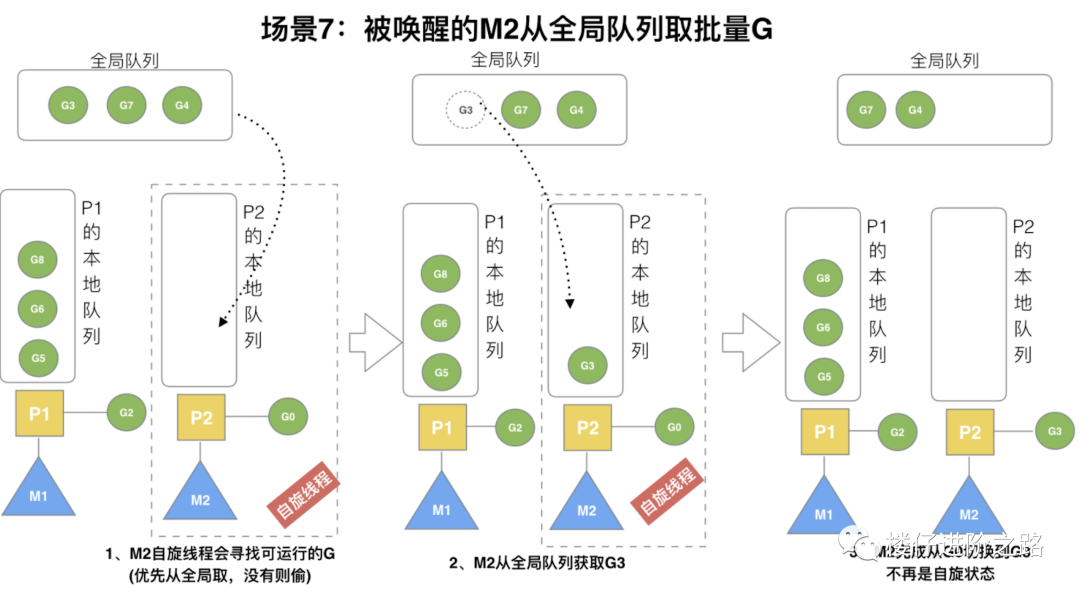
6.3.7 被唤醒的M2从全局队列取批量G
场景:M2尝试从全局队列(简称“GQ”)取一批G放到P2的本地队列。至少从全局队列取1个g,但每次不要从全局队列移动太多的g到p本地队列,给其他p留点。这是从全局队列到P本地队列的负载均衡。
说明:假定我们场景中一共有4个P(GOMAXPROCS设置为4,那么我们允许最多就能用4个P来供M使用)。所以M2只从能从全局队列取1个G(即G3)移动P2本地队列,然后完成从G0到G3的切换,运行G3。
6.3.8 M2从M1中偷取G
场景:假设G2一直在M1上运行,经过2轮后,M2已经把G7、G4从全局队列获取到了P2的本地队列并完成运行,全局队列和P2的本地队列都空了,如场景8图的左半部分。
说明:全局队列已经没有G,那m就要执行work stealing(偷取):从其他有G的P哪里偷取一半G过来,放到自己的P本地队列。P2从P1的本地队列尾部取一半的G,本例中一半则只有1个G8,放到P2的本地队列并执行。

6.3.9 自旋线程的最大限制
场景:G1本地队列G5、G6已经被其他M偷走并运行完成,当前M1和M2分别在运行G2和G8,M3和M4没有goroutine可以运行,M3和M4处于自旋状态,它们不断寻找goroutine。
说明:为什么要让m3和m4自旋,自旋本质是在运行,线程在运行却没有执行G,就变成了浪费CPU. 为什么不销毁现场,来节约CPU资源。因为创建和销毁CPU也会浪费时间,我们希望当有新goroutine创建时,立刻能有M运行它,如果销毁再新建就增加了时延,降低了效率。当然也考虑了过多的自旋线程是浪费CPU,所以系统中最多有GOMAXPROCS个自旋的线程(当前例子中的GOMAXPROCS=4,所以一共4个P),多余的没事做线程会让他们休眠。

6.3.10 自旋线程的最大限制
场景:假定当前除了M3和M4为自旋线程,还有M5和M6为空闲的线程(没有得到P的绑定,注意我们这里最多就只能够存在4个P,所以P的数量应该永远是M>=P, 大部分都是M在抢占需要运行的P),G8创建了G9,G8进行了阻塞的系统调用,M2和P2立即解绑,P2会执行以下判断:如果P2本地队列有G、全局队列有G或有空闲的M,P2都会立马唤醒1个M和它绑定,否则P2则会加入到空闲P列表,等待M来获取可用的p。本场景中,P2本地队列有G9,可以和其他空闲的线程M5绑定。

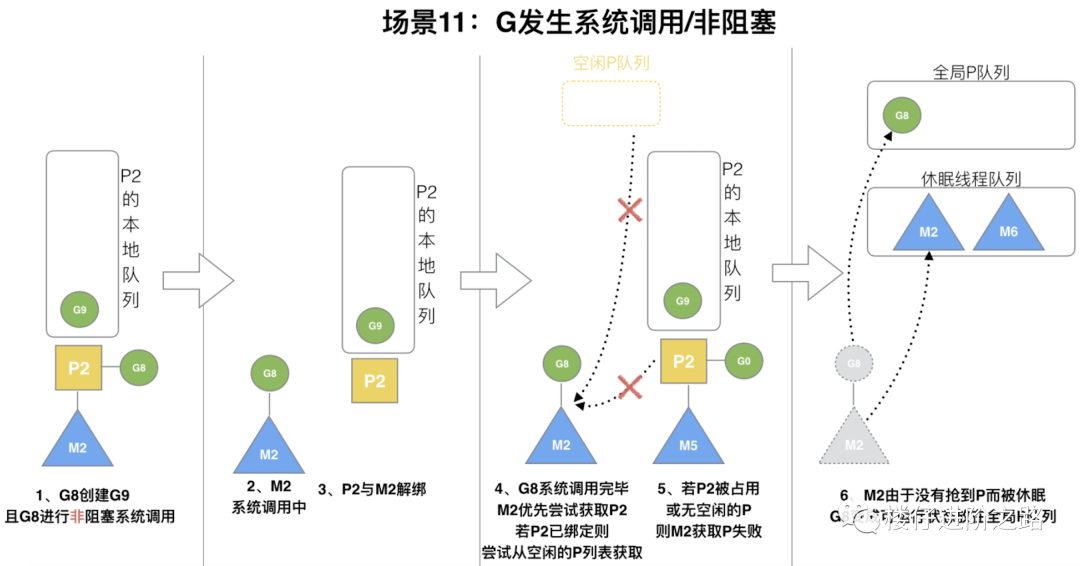
6.3.11 G发生系统调用/非阻塞
场景:G8创建了G9,假如G8进行了非阻塞系统调用。
说明:M2和P2会解绑,但M2会记住P2,然后G8和M2进入系统调用状态。当G8和M2退出系统调用时,会尝试获取P2,如果无法获取,则获取空闲的P,如果依然没有,G8会被记为可运行状态,并加入到全局队列,M2因为没有P的绑定而变成休眠状态(长时间休眠等待GC回收销毁)。