Go单例实现—双重检测是否安全
起因
今天看到项目中的kafka客户端包装结构体的获取是单例模式 单例的实现是老生常谈的问题了,懒汉饿汉线程安全,因为看到项目中写的还是有些问题,网上go单例实现的搜索结果比较少经测试也并不靠谱,所以在这记录下
现状
当前有的项目直接使用Mutex锁,有的就直接判断nil则创建,对于前者,每次都加锁性能差,对于后者则会出现多个实例,也就不是单例了
改进
进而想要改进一下,在这不讨论饿汉和线程非安全的实现,对于go中线程安全的懒汉实现,常见两种:
- 双重检验
- sync.Once
双重检验示例:
package main
import (
"sync"
"testing"
)
var (
instance *int
lock sync.Mutex
)
func getInstance() *int {
if instance == nil {
lock.Lock()
defer lock.Unlock()
if instance == nil {
i := 1
instance = &i
}
}
return instance
}
// 用于下边基准测试
func BenchmarkSprintf(b *testing.B){
for i:=0;i<b.N;i++{
go getInstance()
}
}是否线程安全
基于java中双重检验锁的经验,因为jvm的内存模型,双重检验锁会出现可见性问题,可以通过 volatile解决 那么在go里会有类似问题吗?关键点在于instance变量的读和写是否是原子操作 这里做了个race竞态检测:
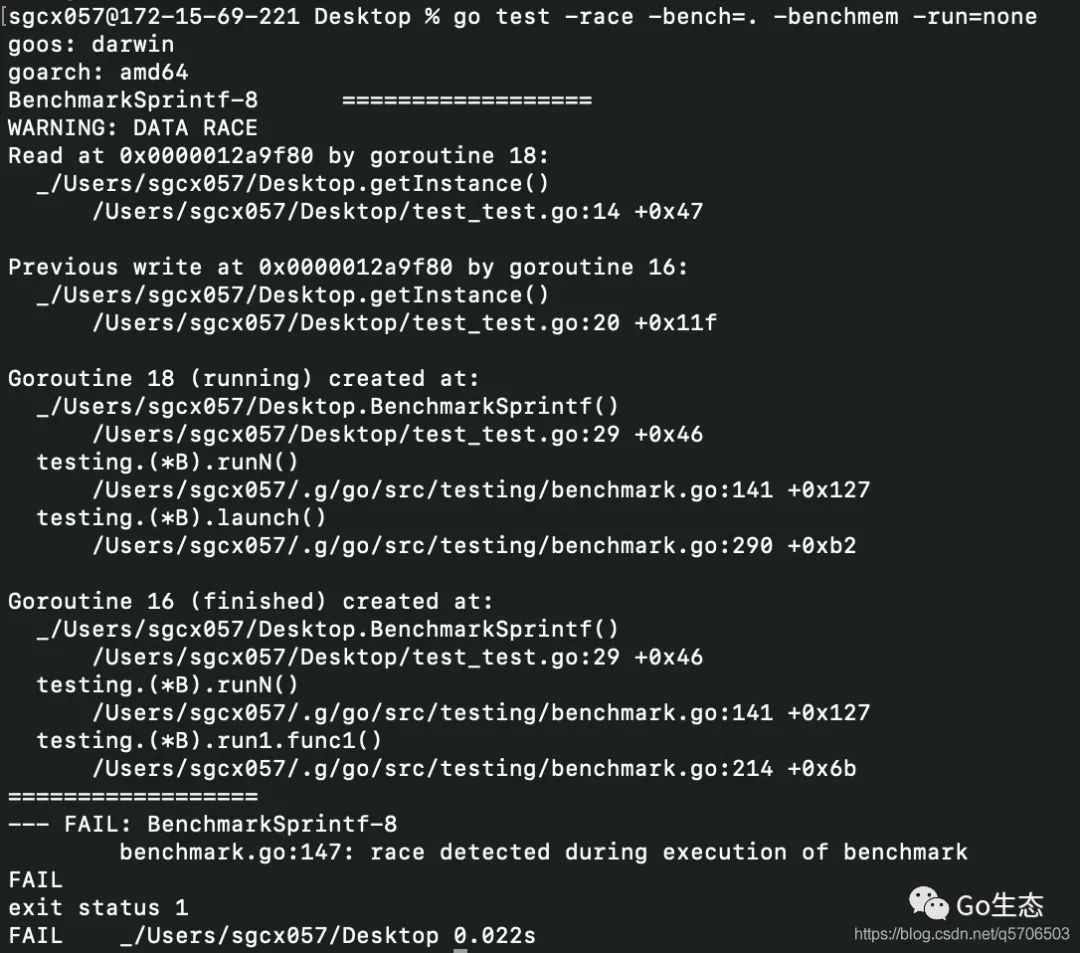
可以看到 20行的写入和14行的读取发生了竞态 上例中用64位(系统是64位)的int指针表示一个实例,也说明了对于64位数据的写入和读取是非原子操作
我们看另一种实现:sync.Once方法
package main
import (
"sync"
"testing"
)
var (
instance *int
once sync.Once
)
func getInstance() *int {
once.Do(func(){
if instance == nil {
i := 1
instance = &i
}
})
return instance
}
func BenchmarkSprintf(b *testing.B){
for i:=0;i<b.N;i++{
go getInstance()
}
}实现比双重检验看起来要整洁许多
race检测结果:

没有发生竞态
关于sync.Once
那么sync.Once是怎么实现的呢
看下源码:
package sync
import (
"sync/atomic"
)
type Once struct {
done uint32
m Mutex
}
func (o *Once) Do(f func()) {
if atomic.LoadUint32(&o.done) == 0 {
o.doSlow(f)
}
}
func (o *Once) doSlow(f func()) {
o.m.Lock()
defer o.m.Unlock()
if o.done == 0 {
defer atomic.StoreUint32(&o.done, 1)
f()
}
}可以看到sync.Once内部其实也是一个双重检验锁,但是对于共享变量(done字段)的读和写使用了atomic包的StoreUint32和LoadUint32方法
sync.Once使用一个32位无符号整数表示共享变量,即使是32位变量的读写操作都需要atomic包方法来实现原子性,更说明了go里边指针的读写不能保证原子性
关于atomic和metex
引用一段话:https://ms2008.github.io/2019/05/12/golang-data-race/
解决 race 的问题时,无非就是上锁。可能很多人都听说过一个高逼格的词叫「无锁队列」。都一听到加锁就觉得很 low,那无锁又是怎么一回事?其实就是利用 atomic 特性,那 atomic 会比 mutex 有什么好处呢?go race detector 的作者总结了这两者的一个区别:Mutexes do no scale. Atomic loads do. mutex 由操作系统实现,而 atomic 包中的原子操作则由底层硬件直接提供支持。在 CPU 实现的指令集里,有一些指令被封装进了 atomic 包,这些指令在执行的过程中是不允许中断(interrupt)的,因此原子操作可以在 lock-free 的情况下保证并发安全,并且它的性能也能做到随 CPU 个数的增多而线性扩展。若实现相同的功能,后者通常会更有效率,并且更能利用计算机多核的优势。所以,以后当我们想并发安全的更新一些变量的时候,我们应该优先选择用 atomic 来实现。
结论
- go单例实现—双重检测法对共享变量直接读取和赋值是不安全的,需要atomic包实现原子操作的读写
- 对于懒汉模式单例的实现,sync.Once是更好的办法,简洁安全,sync.Once已经帮我们实现了安全的双重检验,能做到加载完成后不再加锁
- 这里也提醒我们,只要是对于共享变量的并发访问,一定要注意安全性,go更推崇避免共享变量,使用chan来交流信息,如果无法避免共享内存,优先使用atomic实现,其次sync,安全第一!