搜狐智能媒体基于Zipkin和Starrocks的微服务链路追踪实践
搜狐智能媒体基于Zipkin和Starrocks的微服务链路追踪分析实践
目录
-
微服务架构中的链路追踪
-
Logging、Metrics、Tracing
-
从Monitoring到Observability
-
Tracing
-
基于zipkin和starrocks构建链路追踪分析系统
-
数据采集
-
数据存储
-
分析计算
-
实践效果
-
总结与展望
-
参考文档
前言
❝本文主要介绍搜狐智能媒体,在微服务体系架构下,使用
zipkin进行服务链路追踪(Tracing)的埋点采集,将采集的Trace信息存储到starrocks中,通过starrocks强大的SQL计算能力,对Tracing信息进行多维度的统计、分析等操作,提升微服务监控能力,从简单统计的Monitoring上升到更多维度探索分析的Observability。
本文主要分为三个部分,第一节主要介绍微服务下的常用监控方式,其中链路追踪技术,可以串联整个服务调用链路,获得整体服务的关键信息,对微服务的监控有非常重要的意义;第二节主要介绍搜狐智能媒体是如何构建链路追踪分析体系的,主要包括Zipkin的数据采集,starrocks的数据存储,以及根据应用场景对starrocks进行分析计算等三个部分;第三节主要介绍搜狐智能媒体通过引入zipkin和starrocks进行链路追踪分析取得的一些实践效果。
微服务架构中的链路追踪
近年来,企业IT应用架构逐步向微服务、云原生等分布式应用架构演进,在搜狐智能媒体内部,应用服务按照微服务、Docker、Kubernetes、Spring Cloud等架构思想和技术方案进行研发运维,提升部门整体工程效率。
微服务架构提升工程效率的同时,也带来了一些新的问题。微服务是一个分布式架构,它按业务划分服务单元,用户的每次请求不再是由某一个服务独立完成了,而是变成了多个服务一起配合完成。这些服务可能是由不同的团队、使用不同的编程语言实现,可能布在了不同的服务器、甚至不同的数据中心。如果用户请求出现了错误和异常,微服务分布式调用的特性决定了这些故障难以定位,相对于传统的单体架构,微服务监控面临着新的难题。
Logging、Metrics、Tracing
微服务监控可以包含很多方式,按照监测的数据类型主要划分为Logging、Metrics和Tracing三大领域:
Logging
❝用户主动记录的离散事件,记录的信息一般是非结构化的文本内容,在用户进行问题分析判断时可以提供更为详尽的线索。
Metrics
❝具有聚合属性的采集数据,旨在为用户展示某个指标在某个时段的运行状态,用于查看一些指标和趋势。
Tracing
❝记录一次请求调用的生命周期全过程,其中包括服务调用和处理时长等信息,含有请求上下文环境,由一个全局唯一的
Trace ID来进行标识和串联整个调用链路,非常适合微服务架构的监控场景。
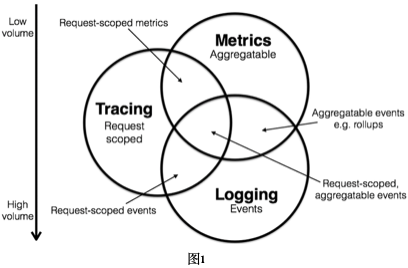
Logging可以聚合相关字段生成Metrics信息,关联相关字段生成Tracing信息;Tracing可以聚合查询次数生成Metrics信息,可以记录业务日志生成Logging信息。一般情况下要在Metrics和Logging中增加字段串联微服务请求调用生命周期比较困难,通过Tracing获取Metrics和Logging则相对容易很多。
另外,这三者对存储资源有着不同的需求,Metrics是天然的压缩数据,最节省资源;Logging倾向于无限增加的,甚至会超出预期的容量;Tracing的存储容量,一般介于Metrics和Logging两者之间,另外还可通过采样率进一步控制容量需求。
从Monitoring到Observability
❝Monitoring tells you whether the system works. Observability lets you ask why it's not working.
– Baron Schwarz
微服务监控从数据分析层次,可以简单分为Monitoring和Observability。

Monitoring
❝告诉你系统是否在工作,对已知场景的预定义计算,对各种监控问题的事前假设,对应上图
Known Knowns和Known Unknowns,都是事先假设可能会发生的事件,包括已经明白和不明白的事件。
Observability
❝可以让你询问系统为什么不工作,对未知场景的探索式分析,对任意监控问题的事后分析,对应上图
Unknown Knowns和Unknown Unknowns,都是事未察觉可能会发生的事件,包括已经明白和不明白的事件。
很显然,通过预先假设所有可能发生事件进行Monitoring的方式,已经不能满足微服务复杂的监控场景,我们需要能够提供探索式分析的Observability监控方式。在Logging、Metrics和Tracing,Tracing是目前能提供多维度监控分析能力的最有效方式。
Tracing
链路追踪Tracing Analysis为分布式应用的开发者提供了完整的调用链路还原、调用请求量统计、链路拓扑、应用依赖分析等工具,可以帮助开发者快速分析和诊断分布式应用架构下的性能瓶颈,提高微服务时代下的开发诊断效率。
Tracing可以串联微服务中分布式请求的调用链路,在微服务监控体系中有着重要的作用。另外,Tracing介于Metrics和Logging之间,既可以完成Monitoring的工作,也可以进行Observability的分析,提升监控体系建设效率。
系统模型
链路追踪(Tracing)系统,需要记录一次特定请求经过的上下游服务调用链路,以及各服务所完成的相关工作信息。如下图所示的微服务系统,用户向服务A发起一个请求,服务A会生成一个全局唯一的Trace ID,服务A内部Messaging方式调用相关处理模块(比如跨线程异步调用等),服务A模块再通过RPC方式并行调用服务B和服务C,服务B会即刻返回响应,但服务C会采用串行方式,先用RPC调用服务D,再用RPC调用服务E,然后再响应服务A的调用请求,服务A在内部两个模块调用处理完后,会响应最初的用户请求。最开始生成的Trace ID会在这一系列的服务内部或服务之间的请求调用中传递,从而将这些请求调用连接起来。另外,Tracing系统还会记录每一个请求调用处理的timestamp、服务名等等相关信息。
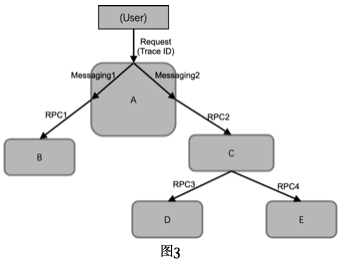
在Tracing系统中,主要包含Trace和Span两个基础概念,下图展示了一个由Span构成的Trace。

- Trace指一个外部请求经过的所有服务的调用链路,可以理解为一个有服务调用组成的树状结构,每条链路都有一个全局唯一的ID来标识。
- Span指服务内部或服务之间的一次调用,即
Trace树中的节点,如下图所示的由Span构成的Trace树,树中的Span节点之间存在父子关系。Span主要包含Span名称、Span ID、父ID,以及timestamp、dration(包含子节点调用处理的duration)、业务数据等其他log信息。
Span根据调用方式可以分为RPC Span和Messaging Span:
RPC Span
❝由
RPC Tracing生成,分为Client和Server两类Span,分别由RPC服务调用的Client节点和Server节点记录生成,两者共享Span ID、Parent Span ID等信息,但要注意,这两个Span记录的时间是有偏差,这个偏差是服务间的调用开销,一般是由网络传输开销、代理服务或服务接口消息排队等情况引起的。
Messaging Span
❝由
Messaging Tracing生成,一般用于Tracing服务内部调用,不同于RPC Span,Messaging Span之间不会共享Span ID等信息。
应用场景
根据Tracing的系统模型,可获得服务响应等各类Metric信息,用于Alerting、DashBoard查询等;也可根据Span组成的链路,分析单个或整体服务情况,发现服务性能瓶颈、网络传输开销、服务内异步调用设计等各种问题。如下图所示,相比于Metrics和Logging,Tracing可以同时涵盖监控的Monitoring和Observability场景,在监控体系中占据重要位置,Opentracing、Opencensus、Opentelemetry等协会和组织都包含对Tracing的支持。

Tracing记录的Span信息可以进行各种维度的统计和分析。下图基于HTTP API设计的微服务系统为例,用户查询Service1的 /1/api 接口,Service1再请求Service2的 /2/api,Service2内部异步并发调用msg2.1和msg2.2,msg2.1请求Service3的 /3/api接口,msg2.2请求Service4的 /4/api接口,Service3内部调用msg3,Service4再请求Service5的 /5/api,其中Service5没有进行Tracing埋点,无法采集Service5的信息。
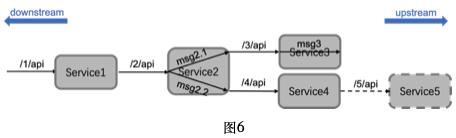
服务内分析
关注单个服务运行情况,比如对外服务接口和上游接口查询的性能指标等,分析场景主要有:
- 1、上游服务请求
❝如Service1提供的 /1/api ,Service4提供的 /4/api等,统计获得次数、QPS、耗时百分位数、出错率、超时率等等
metric信息。
- 2 下游服务响应
❝如Service1请求的 /2/api ,Service4请求的 /5/api等,统计查询次数、QPS、耗时百分位数、出错率、超时率等等
metric信息。
- 3 服务内部处理
❝服务对外接口在内部可能会被分拆为多个
span,可以按照span name进行分组聚合统计,发现耗时最长的span等,如Service2接口 /2/api ,接口服务内部Span包括 /2/api 的Server Span,call2.1对应的Span和call2.2对应的Span,通过Span之间的依赖关系可以算出这些Span自身的耗时duraion,进行各类统计分析。
服务间分析
在进行微服务整体分析时,我们将单个服务看作黑盒,关注服务间的依赖、调用链路上的服务热点等,分析场景主要有:
- 1、服务拓扑统计
❝可以根据服务间调用的
Client Span和Server Span,获得整个服务系统的拓扑结构,以及服务之间调用请求次数、duration等统计信息。
- 2、调用链路性能瓶颈分析
❝分析某个对外请求接口的调用链路上的性能瓶颈,这个瓶颈可能是某个服务内部处理开销造成的,也可能是某两个服务间的网络调用开销等等原因造成的。
❝对于一次调用涉及到数十个以上微服务的复杂调用请求,每次出现的性能瓶颈很可能都会不一样,此时就需要进行聚合统计,算出性能瓶颈出现频次的排名,分析出针对性能瓶颈热点的服务或服务间调用。
以上仅仅是列举的部分分析场景,Tracing提供的信息其实可以支持更多的metric统计和探索式分析场景,本文不再一一例举。
基于zipkin和starrocks构建链路追踪分析系统
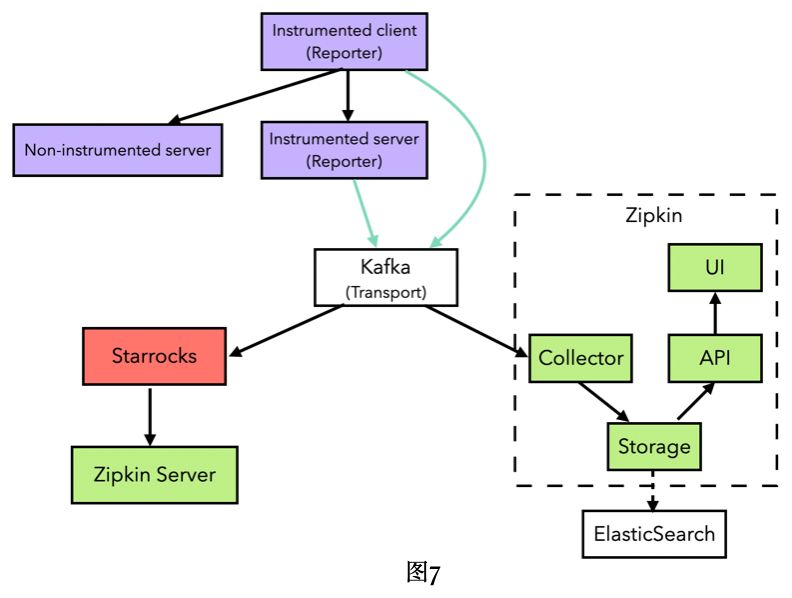
链路追踪系统主要分为数据采集、数据存储和分析计算三大部分,目前使用最广泛的开源链路追踪系统是Zipkin,它主要包括数据采集和分析计算两大部分,底层的存储依赖其他存储系统。搜狐智能媒体在构建链路追踪系统时,最初采用Zipkin+ElasticSearch得方式进行构建,后增加starrocks作为底层存储系统,并基于starrocks进行分析统计,系统总体架构如下图。
数据采集
Zipkin支持客户端全自动埋点,只需将相关库引入应用程序中并简单配置,就可以实现Span信息自动生成,Span信息通过HTTP或Kafka等方式自动进行上传。Zipkin目前提供了绝大部分语言的埋点采集库,如Java语言的Spring Cloud提供了Sleuth与Zipkin进行深度绑定,对开发人员基本做到透明使用。为了解决存储空间,在使用时一般要设置1/100左右的采样率,Dapper的论文中提到即便是1/1000的采样率,对于跟踪数据的通用使用层面上,也可以提供足够多的信息。
数据模型
对应图6,下面给出了Zipkin Span埋点采集示意图(图8),具体流程如下:
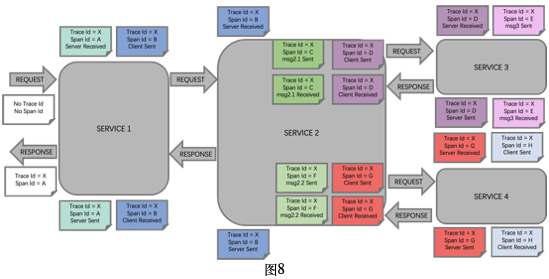
- 用户发送给Service1的
Request中,不含有Trace和Span信息,Service1会创建一个Server Span,随机生成全局唯一的TraceID(如图中的X)和SpanId(如图中的A,此处的X和A会使用相同的值),记录Timestamp等信息;Service1在给用户返回Response时,Service1会统计Server Span的处理耗时duration,会将包含TraceID、SpanID、Timestamp、duration等信息的Server Span完整信息进行上报。 - Service1向Service2发送的请求,会创建一个
Client Span,使用X作为Trace ID,随机生成全局唯一的SpanID(如图中的B),记录Timestamp等信息,同时Service1会将Trace ID(X)和SpanID(B)传递给Service2(如在HTTP协议的HEADER中添加TraceID和SpanID等相关字段);Service1在收到Service2的响应后,Service1会处理Client Span相关信息,并将Client Span进行上报 - Service2收到Service1的
Request中,包含Trace(X)和Span(B)等信息,Service2会创建一个Server Span,使用X作为Trace ID,B作为SpanID,内部调用msg2.1和msg2.2同时,将Trace ID(X)和SpanID(B)传递给它们;Service2在收到msg2.1和msg2.2的返回后,Service1会处理Server Span相关信息,并将此Server Span进行上报 - Service2的msg2.1和msg2.2会分别创建一个
Messaging Span,使用X作为Trace ID,随机生成全局唯一的SpanID(如图中的C和F),记录Timestamp等信息,分别向Service3和Service4发送请求;msg2.1和msg2.2收到响应后,会分别处理Messaging Span相关信息,并将两个Messaging Span进行上报 - Service2向Service3和Service4发送的请求,会各创建一个
Client Span,使用X作为Trace ID,随机生成全局唯一的SpanID(如图中的D和G),记录Timestamp等信息,同时Service2会将Trace ID(X)和SpanID(D或G)传递给Service3和Service4;Service12在收到Service3和Service3的响应后,Service2会分别处理Client Span相关信息,并将两个Client Span进行上报 - Service3收到Service2的
Request中,包含Trace(X)和Span(D)等信息,Service3会创建一个Server Span,使用X作为Trace ID,D作为SpanID,内部调用msg3;Service3在收到msg3的返回后,Service3会处理此Server Span相关信息,并将此Server Span进行上报 - Service3的msg3会分别创建一个
Messaging Span,使用X作为Trace ID,随机生成全局唯一的SpanID(如图中的E),记录Timestamp等信息,msg3处理完成后,处理此Messaging Span相关信息,并将此Messaging Span进行上报 - Service4收到Service2的
Request中,包含Trace(X)和Span(G)等信息,Service4会创建一个Server Span,使用X作为Trace ID,G作为SpanID,再向Service5发送请求;Service4在收到Service5的响应后,Service4会处理此Server Span相关信息,并将此Server Span进行上报 - Service4向Service5发送的请求,会创建一个
Client Span,使用X作为Trace ID,随机生成全局唯一的SpanID(如图中的H),记录Timestamp等信息,同时Service4会将Trace ID(X)和SpanID(H)传递给Service5;Service4在收到Service5的响应后,Service4会处理Client Span相关信息,并将此Client Span进行上报
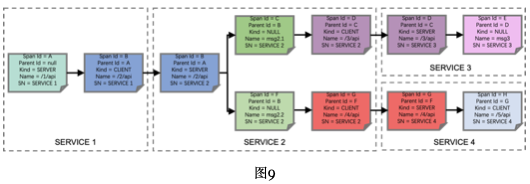
上面整个Trace X调用链路会生成的Span记录如下图,每个Span主要会记录Span Id、Parent Id、Kind(CLIENT表示RPC CLIENT端Span,SERVER表示RPC SERVER端SPAN,NULL表示Messaging SPAN),SN(Service Name),还会包含Trace ID,时间戳、duration等信息。Service5没有进行Zipkin埋点采集,因此不会有Service5的Span记录。
数据格式
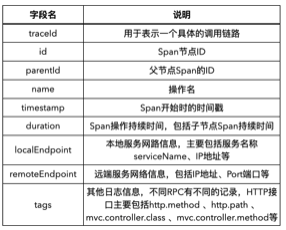
设置了Zipkin埋点的应用服务,默认会使用Json格式向Kafka上报Span信息,上报的信息主要有如下几个注意点:
- 每个应用服务每次会上报一组
Span,组成一个Json数组上报 Json数组里包含不同Trace的Span,即不是所有的Trace ID都相同- 不同形式的接口(如
Http、Grpc、Dubbo等),除了主要字段相同外,在tags中会各自记录一些不同的字段
[
{
"traceId": "3112dd04c3112036",
"id": "3112dd04c3112036",
"kind": "SERVER",
"name": "get /2/api",
"timestamp": 1618480662355011,
"duration": 12769,
"localEndpoint": {
"serviceName": "SERVICE2",
"ipv4": "172.24.132.32"
},
"remoteEndpoint": {
"ipv4": "111.25.140.166",
"port": 50214
},
"tags": {
"http.method": "GET",
"http.path": "/2/api",
"mvc.controller.class": "Controller",
"mvc.controller.method": "get2Api"
}
},
{
"traceId": "3112dd04c3112036",
"parentId": "3112dd04c3112036",
"id": "b4bd9859c690160a",
"name": "msg2.1",
"timestamp": 1618480662357211,
"duration": 11069,
"localEndpoint": {
"serviceName": "SERVICE2"
},
"tags": {
"class": "MSG",
"method": "msg2.1"
}
},
{
"traceId": "3112dd04c3112036",
"parentId": "3112dd04c3112036",
"id": "c31d9859c69a2b21",
"name": "msg2.2",
"timestamp": 1618480662357201,
"duration": 10768,
"localEndpoint": {
"serviceName": "SERVICE2"
},
"tags": {
"class": "MSG",
"method": "msg2.2"
}
},
{
"traceId": "3112dd04c3112036",
"parentId": "b4bd9859c690160a",
"id": "f1659c981c0f4744",
"kind": "CLIENT",
"name": "get /3/api",
"timestamp": 1618480662358201,
"duration": 9206,
"localEndpoint": {
"serviceName": "SERVICE2",
"ipv4": "172.24.132.32"
},
"tags": {
"http.method": "GET",
"http.path": "/3/api"
}
},
{
"traceId": "3112dd04c3112036",
"parentId": "c31d9859c69a2b21",
"id": "73cd1cab1d72a971",
"kind": "CLIENT",
"name": "get /4/api",
"timestamp": 1618480662358211,
"duration": 9349,
"localEndpoint": {
"serviceName": "SERVICE2",
"ipv4": "172.24.132.32"
},
"tags": {
"http.method": "GET",
"http.path": "/4/api"
}
}
]
数据存储
zipkin支持MySQL、Cassandra和ElasticSearch三种数据存储,这三者都存在各自的缺点:
- MySQL:采集的
Tracing信息基本都在每天上亿行甚至百亿行以上,MySQL无法支撑这么大数据量。 - Cassandra:能支持对单个
Trace的Span信息分析,但对聚合查询等数据统计分析场景支持不好 - ElasticSearch:能支持单个
Trace的分析和简单的聚合查询分析,但对于一些较复杂的数据分析计算不能很好的支持,比如涉及到join、窗口函数等等的计算需求,尤其是任务间依赖计算,zipkin目前还不能实时计算,需要通过离线跑spark任务计算任务间依赖信息。
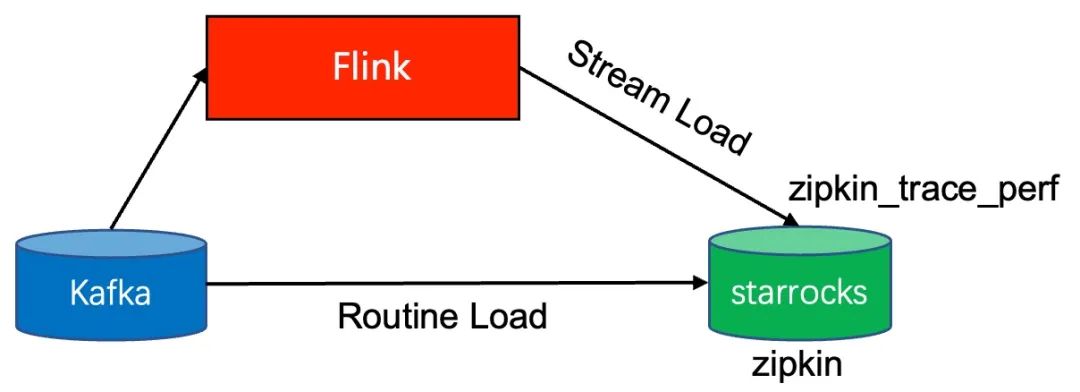
我们在实践中也是首先使用ElasticSearch,发现了上面提到的问题,比如zipkin的服务依赖拓扑必须使用离线方式计算,便新增了starrocks作为底层数据存储。将zipkin的trace数据导入到starrocks很方便,基本步骤只需要两步,CREATE TABLE+CREATE ROUTINE LOAD。另外,在调用链路性能瓶颈分析场景中,要将单个服务看作黑盒,只关注RPC SPAN,屏蔽掉服务内部的Messaging Span,使用了Flink对服务内部span进行ParentID溯源,即从RPC Client SPAN,一直追溯到同一服务同一Trace ID的RPC Server SPAN,用RPC Server SPAN的ID替换RPC Client SPAN的parentId,最后通过flink-connector-starrocks将转换后的数据实时写入starrocks。
基于starrocks的数据存储架构流程如下图所示。
CREATE TABLE
建表语句示例参考如下,有如下几点注意点:
- 包括
zipkin和zipkin_trace_perf两张表,zipkin_trace_perf表只用于调用链路性能瓶颈分析场景,其他统计分析都适用zipkin表 - 通过采集信息中的
timestamp字段,生成dt、hr、min时间字段,便于后续统计分析 - 采用
DUPLICATE模型、bitmap索引等设置,加快查询速度 zipkin表使用id作为分桶字段,在查询服务拓扑时,查询计划会优化为colocate join,提升查询性能。
zipkin
CREATE TABLE `zipkin` (
`traceId` varchar(24) NULL COMMENT "",
`id` varchar(24) NULL COMMENT "Span ID",
`localEndpoint_serviceName` varchar(512) NULL COMMENT "",
`dt` int(11) NULL COMMENT "",
`parentId` varchar(24) NULL COMMENT "",
`timestamp` bigint(20) NULL COMMENT "",
`hr` int(11) NULL COMMENT "",
`min` bigint(20) NULL COMMENT "",
`kind` varchar(16) NULL COMMENT "",
`duration` int(11) NULL COMMENT "",
`name` varchar(300) NULL COMMENT "",
`localEndpoint_ipv4` varchar(16) NULL COMMENT "",
`remoteEndpoint_ipv4` varchar(16) NULL COMMENT "",
`remoteEndpoint_port` varchar(16) NULL COMMENT "",
`shared` int(11) NULL COMMENT "",
`tag_error` int(11) NULL DEFAULT "0" COMMENT "",
`error_msg` varchar(1024) NULL COMMENT "",
`tags_http_path` varchar(2048) NULL COMMENT "",
`tags_http_method` varchar(1024) NULL COMMENT "",
`tags_controller_class` varchar(100) NULL COMMENT "",
`tags_controller_method` varchar(1024) NULL COMMENT "",
INDEX service_name_idx (`localEndpoint_serviceName`) USING BITMAP COMMENT ''
) ENGINE=OLAP
DUPLICATE KEY(`traceId`, `parentId`, `id`, `timestamp`, `localEndpoint_serviceName`, `dt`)
COMMENT "OLAP"
PARTITION BY RANGE(`dt`)
(PARTITION p20220104 VALUES [("20220104"), ("20220105")),
PARTITION p20220105 VALUES [("20220105"), ("20220106")))
DISTRIBUTED BY HASH(`id`) BUCKETS 100
PROPERTIES (
"replication_num" = "3",
"dynamic_partition.enable" = "true",
"dynamic_partition.time_unit" = "DAY",
"dynamic_partition.time_zone" = "Asia/Shanghai",
"dynamic_partition.start" = "-30",
"dynamic_partition.end" = "2",
"dynamic_partition.prefix" = "p",
"dynamic_partition.buckets" = "100",
"in_memory" = "false",
"storage_format" = "DEFAULT"
);zipkin_trace_perf
CREATE TABLE `zipkin_trace_perf` (
`traceId` varchar(24) NULL COMMENT "",
`id` varchar(24) NULL COMMENT "",
`dt` int(11) NULL COMMENT "",
`parentId` varchar(24) NULL COMMENT "",
`localEndpoint_serviceName` varchar(512) NULL COMMENT "",
`timestamp` bigint(20) NULL COMMENT "",
`hr` int(11) NULL COMMENT "",
`min` bigint(20) NULL COMMENT "",
`kind` varchar(16) NULL COMMENT "",
`duration` int(11) NULL COMMENT "",
`name` varchar(300) NULL COMMENT "",
`tag_error` int(11) NULL DEFAULT "0" COMMENT ""
) ENGINE=OLAP
DUPLICATE KEY(`traceId`, `id`, `dt`, `parentId`, `localEndpoint_serviceName`)
COMMENT "OLAP"
PARTITION BY RANGE(`dt`)
(PARTITION p20220104 VALUES [("20220104"), ("20220105")),
PARTITION p20220105 VALUES [("20220105"), ("20220106")))
DISTRIBUTED BY HASH(`traceId`) BUCKETS 32
PROPERTIES (
"replication_num" = "3",
"dynamic_partition.enable" = "true",
"dynamic_partition.time_unit" = "DAY",
"dynamic_partition.time_zone" = "Asia/Shanghai",
"dynamic_partition.start" = "-60",
"dynamic_partition.end" = "2",
"dynamic_partition.prefix" = "p",
"dynamic_partition.buckets" = "12",
"in_memory" = "false",
"storage_format" = "DEFAULT"
);ROUTINE LOAD
ROUTINE LOAD创建语句示例如下:
CREATE ROUTINE LOAD zipkin_routine_load ON zipkin COLUMNS(
id,
kind,
localEndpoint_serviceName,
traceId,
`name`,
`timestamp`,
`duration`,
`localEndpoint_ipv4`,
`remoteEndpoint_ipv4`,
`remoteEndpoint_port`,
`shared`,
`parentId`,
`tags_http_path`,
`tags_http_method`,
`tags_controller_class`,
`tags_controller_method`,
tmp_tag_error,
tag_error = if(`tmp_tag_error` IS NULL, 0, 1),
error_msg = tmp_tag_error,
dt = from_unixtime(`timestamp` / 1000000, '%Y%m%d'),
hr = from_unixtime(`timestamp` / 1000000, '%H'),
`min` = from_unixtime(`timestamp` / 1000000, '%i')
) PROPERTIES (
"desired_concurrent_number" = "3",
"max_batch_interval" = "50",
"max_batch_rows" = "300000",
"max_batch_size" = "209715200",
"max_error_number" = "1000000",
"strict_mode" = "false",
"format" = "json",
"strip_outer_array" = "true",
"jsonpaths" = "[\"$.id\",\"$.kind\",\"$.localEndpoint.serviceName\",\"$.traceId\",\"$.name\",\"$.timestamp\",\"$.duration\",\"$.localEndpoint.ipv4\",\"$.remoteEndpoint.ipv4\",\"$.remoteEndpoint.port\",\"$.shared\",\"$.parentId\",\"$.tags.\\\"http.path\\\"\",\"$.tags.\\\"http.method\\\"\",\"$.tags.\\\"mvc.controller.class\\\"\",\"$.tags.\\\"mvc.controller.method\\\"\",\"$.tags.error\"]"
)
FROM
KAFKA (
"kafka_broker_list" = "IP1:PORT1,IP2:PORT2,IP3:PORT3",
"kafka_topic" = "XXXXXXXXX"
);Flink溯源ParentID
针对调用链路性能瓶颈分析场景中,使用Flink进行ParentID溯源,代码示例如下:
env
// 添加kafka数据源
.addSource(getKafkaSource())
// 将采集到的Json字符串转换为JSONArray,
// 这个JSONArray是从单个服务采集的信息,里面会包含多个Trace的Span信息
.map(JSON.parseArray(_))
// 将JSONArray转换为JSONObject,每个JSONObejct就是一个Span
.flatMap(_.asScala.map(_.asInstanceOf[JSONObject]))
// 将Span的JSONObject对象转换为Bean对象
.map(jsonToBean(_))
// 以traceID+localEndpoint_serviceName作为key对span进行分区生成keyed stream
.keyBy(span => keyOfTrace(span))
// 使用会话窗口,将同一个Trace的不同服务上的所有Span,分发到同一个固定间隔的processing-time窗口
// 这里为了实现简单,使用了processing-time session窗口,后续我们会使用starrocks的UDAF函数进行优化,去掉对Flink的依赖
.window(ProcessingTimeSessionWindows.withGap(Time.seconds(10)))
// 使用Aggregate窗口函数
.aggregate(new TraceAggregateFunction)
// 将经过溯源的span集合展开,便于调用flink-connector-starrocks
.flatMap(spans => spans)
// 使用flink-connector-starrocks sink,将数据写入starrocks中
.addSink(
StarRocksSink.sink(
StarRocksSinkOptions.builder().withProperty("XXX", "XXX").build()))分析计算
以图6作为一个微服务系统用例,给出各个统计分析场景对应的Starrocks SQL语句。
服务内分析
上游服务请求指标统计
下面的sql使用zipkin表数据,计算服务Service2请求上游服务Service3和上游服务Service4的查询统计信息,按小时和接口分组统计查询指标
select
hr,
name,
req_count,
timeout / req_count * 100 as timeout_rate,
error_count / req_count * 100 as error_rate,
avg_duration,
tp95,
tp99
from
(
select
hr,
name,
count(1) as req_count,
AVG(duration) / 1000 as avg_duration,
sum(if(duration > 200000, 1, 0)) as timeout,
sum(tag_error) as error_count,
percentile_approx(duration, 0.95) / 1000 AS tp95,
percentile_approx(duration, 0.99) / 1000 AS tp99
from
zipkin
where
localEndpoint_serviceName = 'Service2'
and kind = 'CLIENT'
and dt = 20220105
group by
hr,
name
) tmp
order by
hr下游服务响应指标统计
下面的sql使用zipkin表数据,计算服务Service2响应下游服务Service1的查询统计信息,按小时和接口分组统计查询指标
select
hr,
name,
req_count,
timeout / req_count * 100 as timeout_rate,
error_count / req_count * 100 as error_rate,
avg_duration,
tp95,
tp99
from
(
select
hr,
name,
count(1) as req_count,
AVG(duration) / 1000 as avg_duration,
sum(if(duration > 200000, 1, 0)) as timeout,
sum(tag_error) as error_count,
percentile_approx(duration, 0.95) / 1000 AS tp95,
percentile_approx(duration, 0.99) / 1000 AS tp99
from
zipkin
where
localEndpoint_serviceName = 'Service2'
and kind = 'SERVER'
and dt = 20220105
group by
hr,
name
) tmp
order by
hr服务内部处理分析
下面的sql使用zipkin表数据,查询服务Service2的接口 /2/api,按span name分组统计duration等信息
with
spans as (
select * from zipkin where dt = 20220105 and localEndpoint_serviceName = "Service2"
),
api_spans as (
select
spans.id as id,
spans.parentId as parentId,
spans.name as name,
spans.duration as duration
from
spans
inner JOIN
(select * from spans where kind = "SERVER" and name = "/2/api") tmp
on spans.traceId = tmp.traceId
)
SELECT
name,
AVG(inner_duration) / 1000 as avg_duration,
percentile_approx(inner_duration, 0.95) / 1000 AS tp95,
percentile_approx(inner_duration, 0.99) / 1000 AS tp99
from
(
select
l.name as name,
(l.duration - ifnull(r.duration, 0)) as inner_duration
from
api_spans l
left JOIN
api_spans r
on l.parentId = r.id
) tmp
GROUP BY
name服务间分析
服务拓扑统计
下面的sql使用zipkin表数据,计算服务间的拓扑关系,以及服务间接口duration的统计信息
with tbl as (select * from zipkin where dt = 20220105)
select
client,
server,
name,
AVG(duration) / 1000 as avg_duration,
percentile_approx(duration, 0.95) / 1000 AS tp95,
percentile_approx(duration, 0.99) / 1000 AS tp99
from
(
select
c.localEndpoint_serviceName as client,
s.localEndpoint_serviceName as server,
c.name as name,
c.duration as duration
from
(select * from tbl where kind = "CLIENT") c
left JOIN
(select * from tbl where kind = "SERVER") s
on c.id = s.id and c.traceId = s.traceId
) as tmp
group by
client,
server,
name调用链路性能瓶颈分析
下面的sql使用zipkin_trace_perf表数据,针对某个服务接口响应超时的查询请求,统计出每次请求的调用链路中处理耗时最长的服务或服务间调用,进而分析出性能热点是在某个服务或服务间调用。
select
service,
ROUND(count(1) * 100 / sum(count(1)) over(), 2) as percent
from
(
select
traceId,
service,
duration,
ROW_NUMBER() over(partition by traceId order by duration desc) as rank4
from
(
with tbl as (
SELECT
l.traceId as traceId,
l.id as id,
l.parentId as parentId,
l.kind as kind,
l.duration as duration,
l.localEndpoint_serviceName as localEndpoint_serviceName
FROM
zipkin_trace_perf l
INNER JOIN
zipkin_trace_perf r
on l.traceId = r.traceId
and l.dt = 20220105
and r.dt = 20220105
and r.tag_error = 0 -- 过滤掉出错的trace
and r.localEndpoint_serviceName = "Service1"
and r.name = "/1/api"
and r.kind = "SERVER"
and r.duration > 200000 -- 过滤掉未超时的trace
)
select
traceId,
id,
service,
duration
from
(
select
traceId,
id,
service,
(c_duration - s_duration) as duration,
ROW_NUMBER() over(partition by traceId order by (c_duration - s_duration) desc) as rank2
from
(
select
c.traceId as traceId,
c.id as id,
concat(c.localEndpoint_serviceName, "=>", ifnull(s.localEndpoint_serviceName, "?")) as service,
c.duration as c_duration,
ifnull(s.duration, 0) as s_duration
from
(select * from tbl where kind = "CLIENT") c
left JOIN
(select * from tbl where kind = "SERVER") s
on c.id = s.id and c.traceId = s.traceId
) tmp1
) tmp2
where
rank2 = 1
union ALL
select
traceId,
id,
service,
duration
from
(
select
traceId,
id,
service,
(s_duration - c_duration) as duration,
ROW_NUMBER() over(partition by traceId order by (s_duration - c_duration) desc) as rank2
from
(
select
s.traceId as traceId,
s.id as id,
s.localEndpoint_serviceName as service,
s.duration as s_duration,
ifnull(c.duration, 0) as c_duration,
ROW_NUMBER() over(partition by s.traceId, s.id order by ifnull(c.duration, 0) desc) as rank
from
(select * from tbl where kind = "SERVER") s
left JOIN
(select * from tbl where kind = "CLIENT") c
on s.id = c.parentId and s.traceId = c.traceId
) tmp1
where
rank = 1
) tmp2
where
rank2 = 1
) tmp3
) tmp4
where
rank4 = 1
GROUP BY
service
order by
percent descsql查询的结果如下图所示,在超时的Trace请求中,性能瓶颈服务或服务间调用的比例分布。

实践效果
目前搜狐智能媒体已在30+ 个服务中接入Zipkin,涵盖上百个线上服务实例,1% 的采样率每天产生近10亿多行的日志。
通过zipkin server查询starrocks,获取的Trace信息如下图所示:
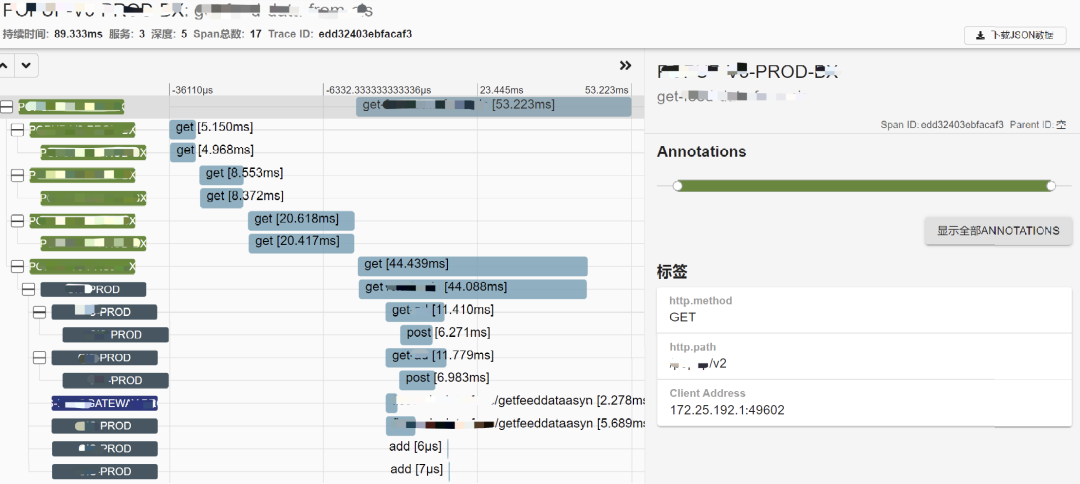
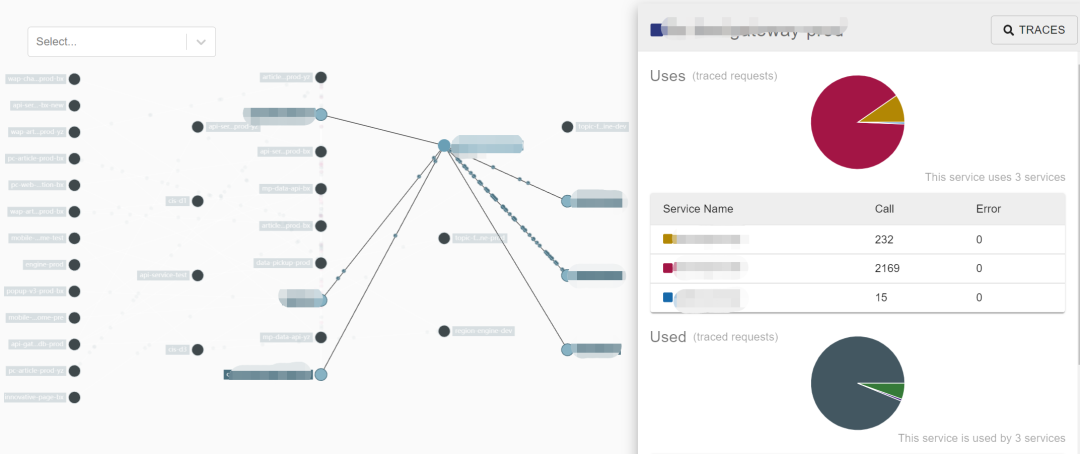
zipkin server查询starrocks,获取的服务拓扑信息如下图所示:
Zipkin+starrocks的链路追踪体系实践过程中,明显提升了微服务监控分析能力和工程效率:
提升微服务监控分析能力
- 在监控报警方面,可以基于
starrocks查询统计线上服务当前时刻的响应延迟百分位数、错误率等指标,根据这些指标及时产生各类告警; - 在指标统计方面,可以基于
starrocks按天、小时、分钟等粒度统计服务响应延迟的各项指标,更好的了解服务运行状况; - 在故障分析方面,基于
starrocks强大的SQL计算能力,可以进行服务、时间、接口等多个维度的探索式分析查询,定位故障原因。
提升微服务监控工程效率
Metric和Logging数据采集,很多需要用户手动埋点和安装各种采集器Agent,数据采集后存储到ElasticSearch等存储系统,每上一个业务,这些流程都要操作一遍,非常繁琐,且资源分散不易管理。
而使用zipkin+starrocks的方式,只需在代码中引入对应库SDK,设置上报的Kafka地址和采样率等少量配置信息,Tracing便可自动埋点采集,通过zikpin server界面进行查询分析,非常简便。
总结与展望
基于zipkin+starrocks构建链路追踪系统,能够提供微服务监控的Monitoring和Observability能力,提升微服务监控的分析能力和工程效率。
后续有几个优化点,可以进一步提升链路追踪系统的分析能力和易用性:
- 使用
starrocks的UDAF、窗口函数等功能,将parentID溯源下沉到starrocks计算,通过计算后置的方式,取消对Flink的依赖,进一步简化整个系统架构。 - 目前对原始日志中的
tags等字段,并没有完全采集,starrocks正在实现json数据类型,能够更好的支持tags等嵌套数据类型。 Zipkin Server目前的界面还稍显简陋,我们已经打通了Zipkin Server查询starrokcs,后续会对Zipkin Server进行UI等优化,通过starrocks强大的计算能力实现更多的指标查询,进一步提升用户体验。
参考文档
- 《云原生计算重塑企业IT架构 - 分布式应用架构》: https://developer.aliyun.com/article/717072
- What is Upstream and Downstream in Software Development? https://reflectoring.io/upstream-downstream/
- Metrics, tracing, and logging: https://peter.bourgon.org/blog/2017/02/21/metrics-tracing-and-logging.html
- The 3 pillars of system observability:logs, metrics and tracing: https://iamondemand.com/blog/the-3-pillars-of-system-observability-logs-metrics-and-tracing/
- observability 3 ways: logging, metrics and tracing: https://speakerdeck.com/adriancole/observability-3-ways-logging-metrics-and-tracing
- Dapper, a Large-Scale Distributed Systems Tracing Infrastructure: https://static.googleusercontent.com/media/research.google.com/en//archive/papers/dapper-2010-1.pdf
- Jaeger:www.jaegertracing.io
- Zipkin:https://zipkin.io/
- opentracing.io: https://opentracing.io/docs/
- opencensus.io: https://opencensus.io/
- opentelemetry.io: https://opentelemetry.io/docs/
- Microservice Observability, Part 1: Disambiguating Observability and Monitoring: https://bravenewgeek.com/microservice-observability-part-1-disambiguating-observability-and-monitoring/
- How to Build Observable Distributed Systems: https://www.infoq.com/presentations/observable-distributed-ststems/
- Monitoring and Observability: https://copyconstruct.medium.com/monitoring-and-observability-8417d1952e1c
- Monitoring Isn't Observability: https://orangematter.solarwinds.com/2017/09/14/monitoring-isnt-observability/
- Spring Cloud Sleuth Documentation: https://docs.spring.io/spring-cloud-sleuth/docs/current-SNAPSHOT/reference/html/getting-started.html#getting-started