硬核,图解bufio包系列之读取原理
今天跟大家分享一篇 bufio 的读取原理。
01 Go中普通的文件读写
首先我们来看看在Go中对文件的普通读取方式是怎么样的。下面是普通的读取文件内容的示例代码:
package main
import (
"fmt"
"io/ioutil"
"os"
"sync/atomic"
)
func main() {
filename := "./test.txt"
//以读写模式打开文件
fd, _ := os.OpenFile(filename, os.O_RDWR, 0666)
b := make([]byte, 2)
// 从文件中读取最多len(b)个字节的内容到b中
n, err := fd.Read(b)
fmt.Printf("n:=%d, b:=%s, err=%+v\n", n, b, err)
}上面的读取方式是通过文件系统的IO进行读取的,每次都需要一次底层的系统调用,若需要连续多次读取,那么这种方式的效率就会大大降低。如下图:
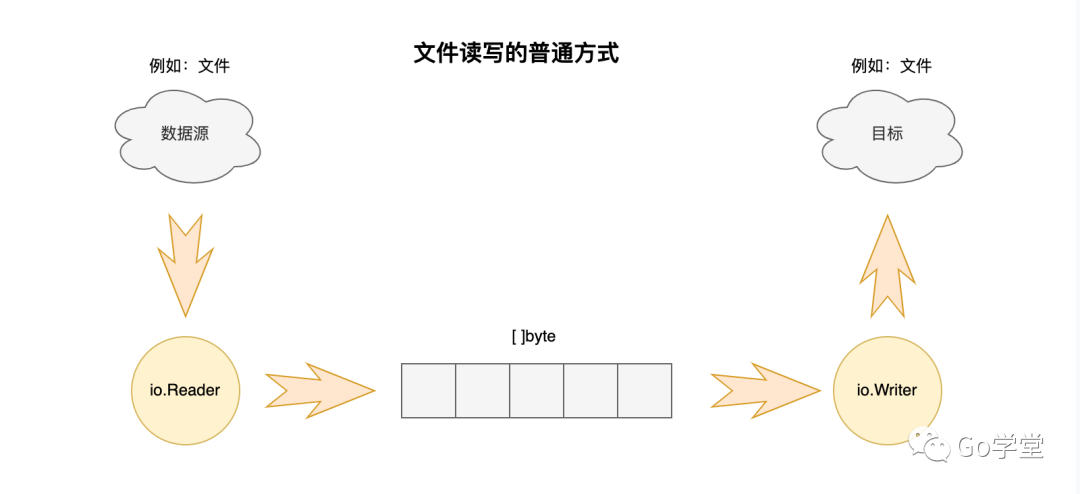
在Go中,将读写文件的操作抽象成了接口io.Reader和io.Writer,只要实现对应接口的方法即可。如示例中os.OpenFile函数返回的File对象即实现了这两个接口。那有没有什么办法提高读写效率呢?那就是编程中常用的技术--缓存。
02 将文件内容预读取到缓存--bufio
这里的思想很简单,当用户从文件中读取数据的时候,先从文件中读取一大块内容到内存缓冲区,以供后面的读取操作直接从内存缓冲区进行读取,以降低从文件中读取的系统调用次数。如下图所示:
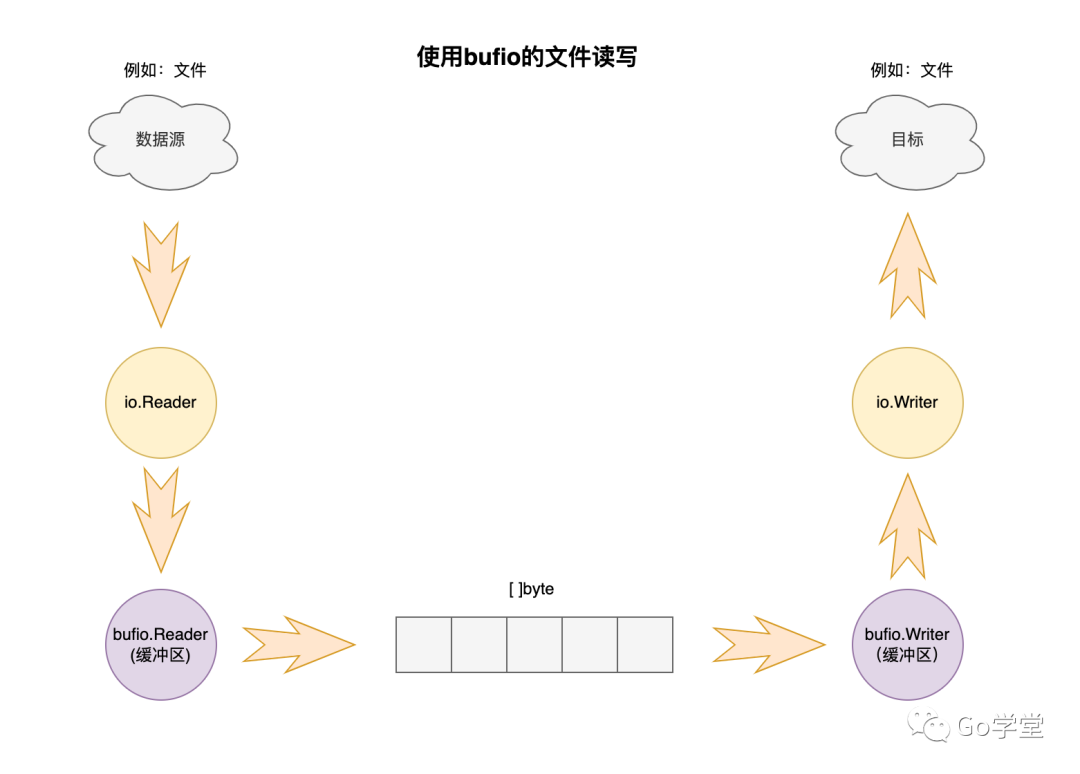
整体思想比较简单。但在bufio中的具体实现中针对不同的场景使用了不同的策略机制。下面我们先看下缓冲区的几种状态,然后再针对缓冲区的每一类读取操作来深入分析其具体的实现策略。
03 缓冲区的状态
缓冲区有三种状态,分别是缓冲区为空、缓冲区未满但有可读取的数据以及缓冲区满的状态。在bufio中,缓冲区本质上是一个字节切片,并通过两个整型变量r和w分别表示可读取以及可写入的索引位置。从文件中每加载一个字节的内容到缓冲区则w+1,从缓冲区每读走一个字节的内容,则r+1。下面我们分别看下三种状态。
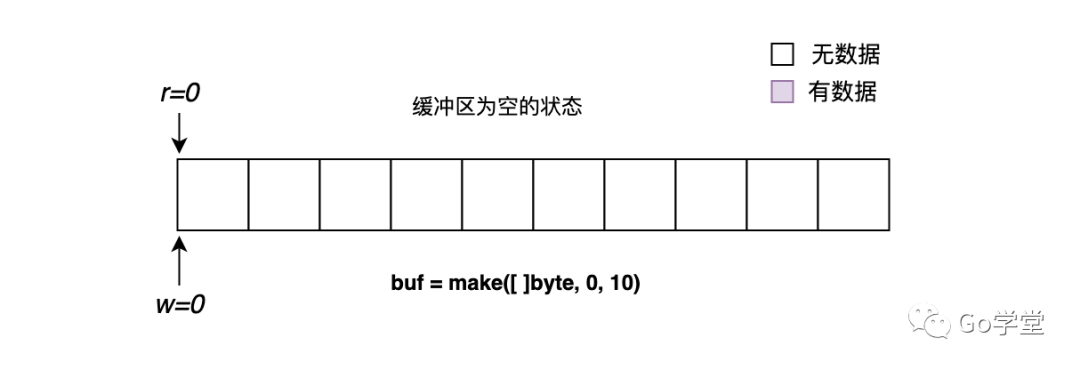
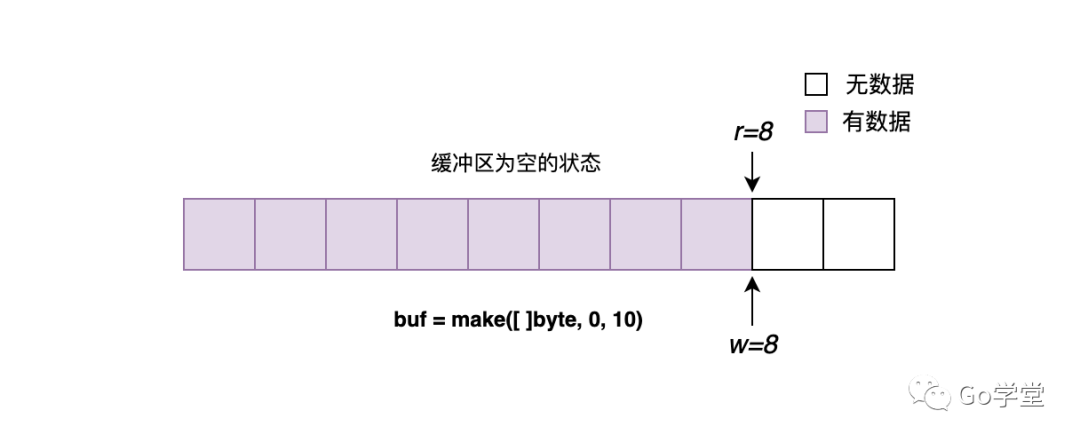
1)缓冲区为空的状态
缓冲区为空的状态本质上是指没有内容可读。其判断标准如下:
r == w
r和w相等,意味着已经将写入到缓冲区的内容都读完了。其中最简单的就是r和w都等于0,缓冲区中没有任何内容,如下图所示:
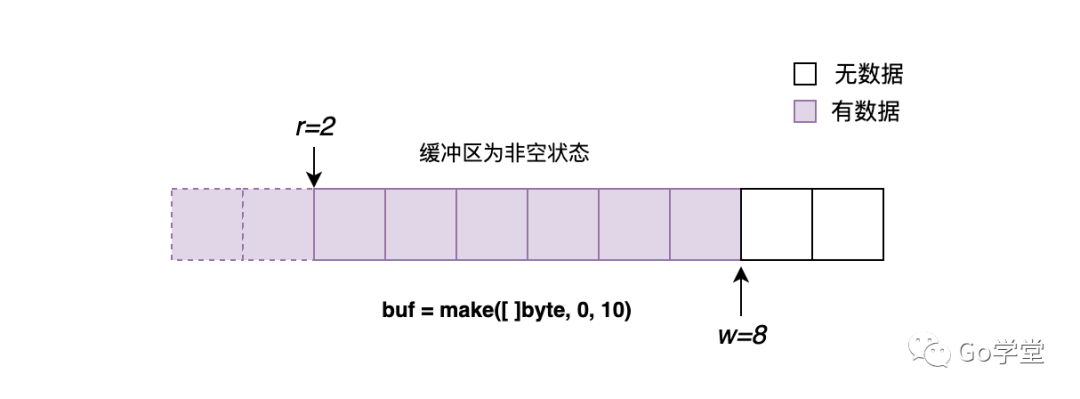
2)缓冲区为非空的状态
这种状态是指在缓冲区中有可读的内容,其判断标准如下:
r != w && (w-r) < len(buf)
r != w 说明buf[r:w]这段内容还没被调用方读取。(w-r) < len(buf) 说明buf不是满的状态,还有空间可以继续填充内容。在这种状态下,当程序执行读操作时,会直接从缓冲区中读取。如下图:
3)缓冲区满状态
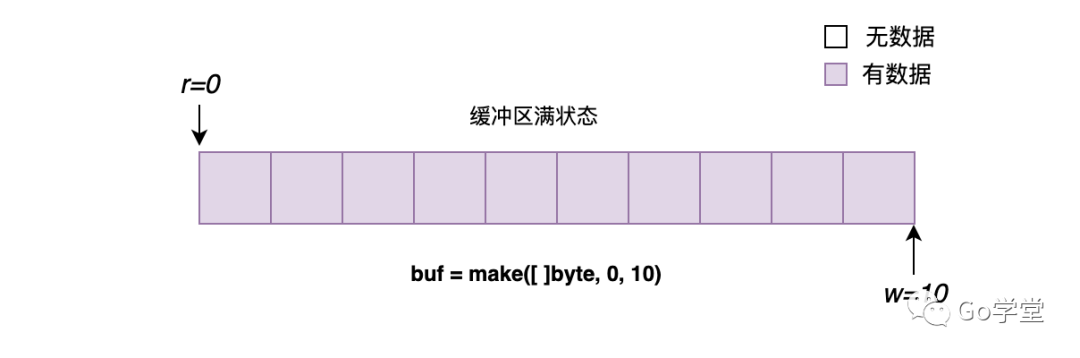
还有最后一种缓冲区状态,即缓冲区满。其通用的判断标准如下:
(w-r) >= len(buf)
如果要满足上述公式,只有一种情况,即 r=0,表示还没有从缓冲区读走任何内容。w=len(buf),表示从文件中读取的内容已经填满了整个缓冲区。该示例中为w=10,即表示没有任何空闲的空间。如下图所示:
以上就是缓冲区的三种状态,下面我们来开始看看bufio的具体是如何从缓冲区读取数据的。
04 读取特定字节数的操作-- Read([]byte)
我们还是从最简单的读取操作开始。还是上面的例子,我们将其改写成使用bufio的读取操作:
package main
import (
"bufio"
"fmt"
"os"
)
func main() {
filename := "./test.txt"
//以读写模式打开文件
fd, _ := os.OpenFile(filename, os.O_RDWR, 0666)
//将fd包装到buffer Reader中
bufioReader := bufio.NewReader(fd)
p := make([]byte, 2)
n, _ := bufioReader.Read(p)
fmt.Printf("n=%d,p=%s", n, p)
}基本用法看起来和直接从文件中读取差不多,只不过是多包装了一层buffer Reader。下面我们看看其内部的具体实现。
上面提到bufio的基本思想是有一个缓冲区,调用方直接从缓冲区中读取。下图是其初始的状态:
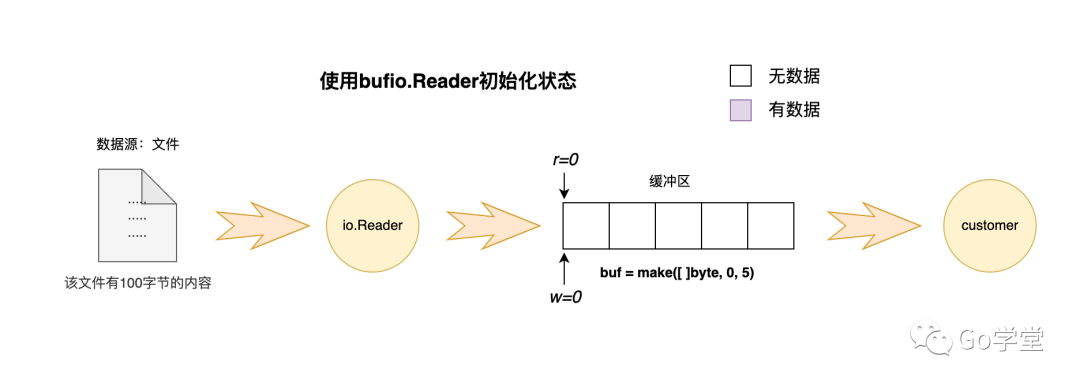
场景一:当缓冲区为空状态时的读取逻辑(即r等于w)
在缓冲区为空时,进行读取也有两种情况:
- 若调用方要读取的字节数 小于 缓冲区的长度,则先填充缓冲区,再从缓冲区中读取。
- 若调用方要读取的字节数 ≥ 缓冲区的长度,则直接从文件中读取,不填充缓冲区。
下面我们先来看第一种情况:要读取的字节数小于缓冲区的长度。这种情况的读取逻辑是从文件中将内容读取到缓冲区中,将缓冲区填满。然后再从缓冲区读取想要的字节内容。
我们看下下面语句的具体执行过程:
p := make([]byte, 2)
n, _ := bufioReader.Read(p)这里是要从文件中读取2个字节。即要读取的字节数少于缓冲区的内容字节数。我们看下下图:
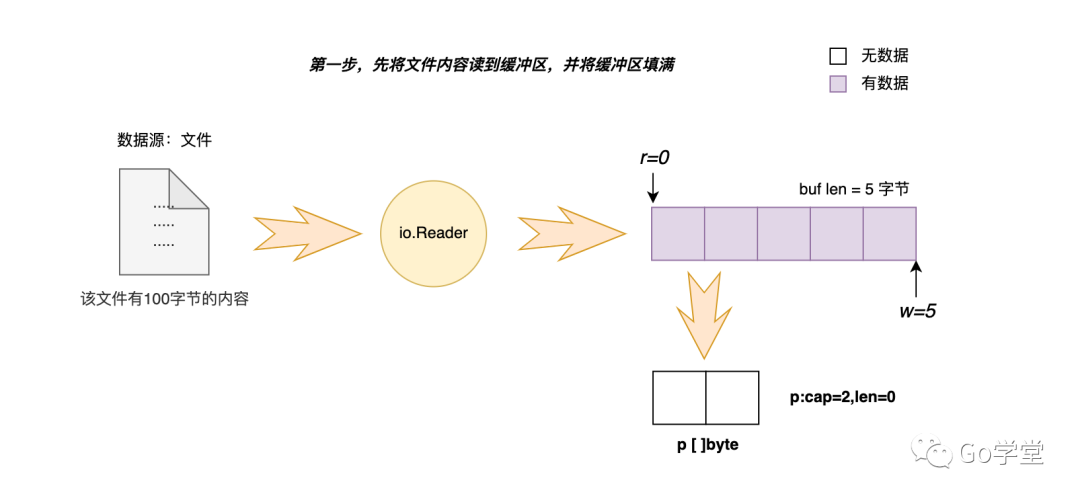
- 若文件的可读取的内容字节数大于等于缓冲区容量,那就先将缓冲区填满。
- 若文件的可读取的内容字节数小于缓冲区容量,则将可读取内容全部读取到缓冲区即可。
第二步,从缓冲区中读取数据。示例中,需要拷贝2个字节到调用者的变量 p 中。如下图:
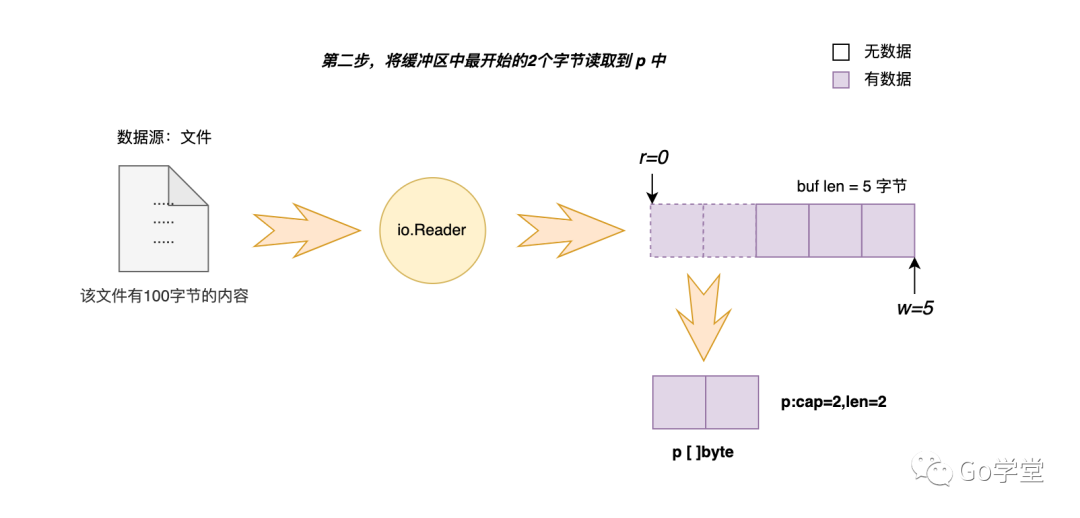
第三步,移动 r 的位置,以便标记下次从缓存区读取时的开始位置。这次是从缓冲区索引0的位置开始读取的,并且只读取了2个字节,所以下次读取应该是从缓冲区的索引位置2处开始读取。
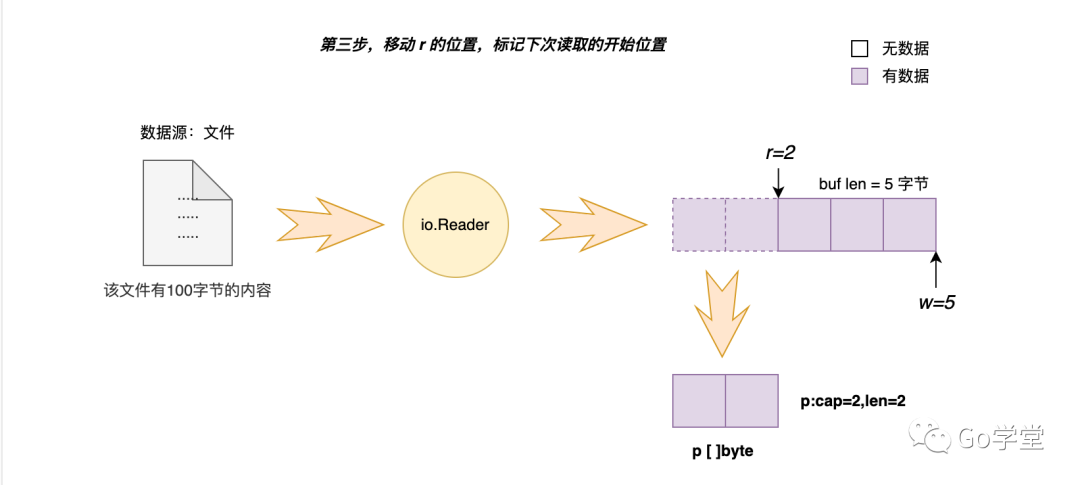
以上就是要读取的字节数比缓冲区的缓存内容字节数少时的实现逻辑。
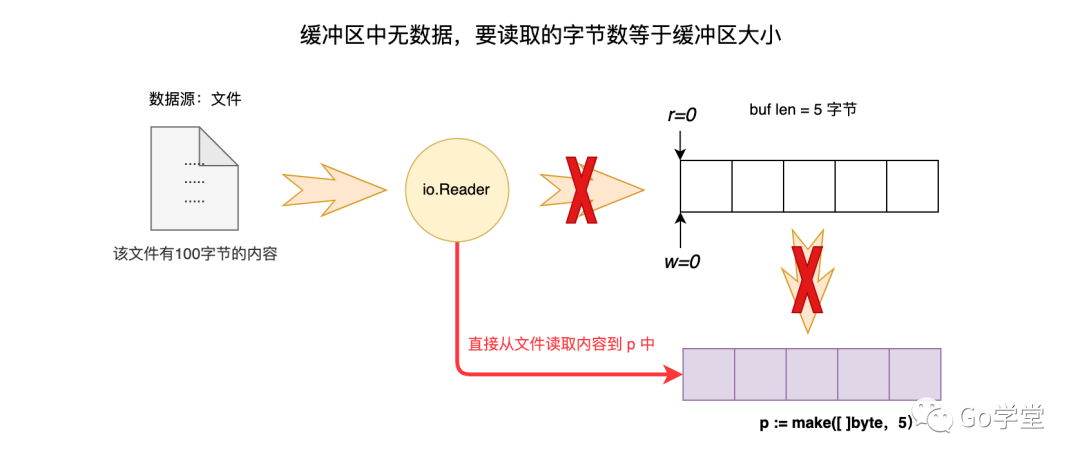
现在,我们来看这样一种场景,如果调用者要读取的字节数和缓冲区的字节数相等,按照上面的逻辑,其读取过程如下:
- 先从文件读取5个字节到缓冲区,这时 w=5,代表下次再写入缓冲区的位置。缓冲区从空的状态转换到满的状态。
- 然后再将缓冲区的5个字节全部拷贝到 p 中,这时r = 5,代表下次再从缓冲区读取数据的位置。这时缓冲区中的内容都已经被读走了, r 和 w相等。这时缓冲区从满的状态又变成了空的状态。
场景二:当缓冲区为非空状态的读取逻辑
如果在缓冲区非空状态下进行读取操作时,唯一需要注意的点就是当缓冲区中可读取的内容字节数小于调用者要读取的字节数时,则只能读取缓冲区中的内容。如下是bufio中缓冲区的初始状态,目前只有1字节的内容可读,如下图:
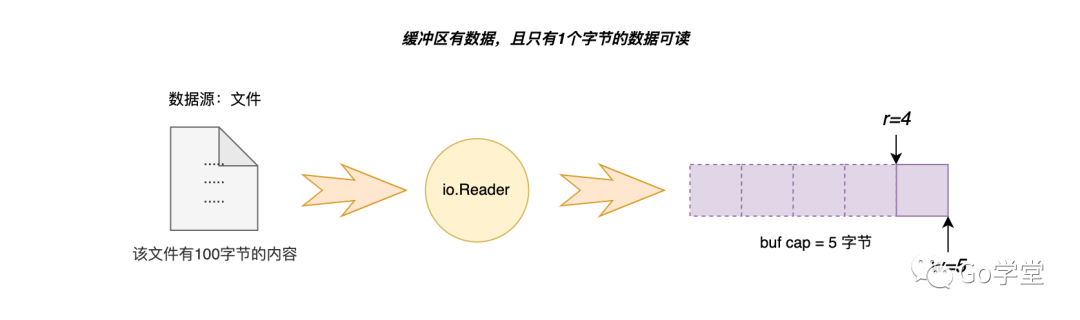
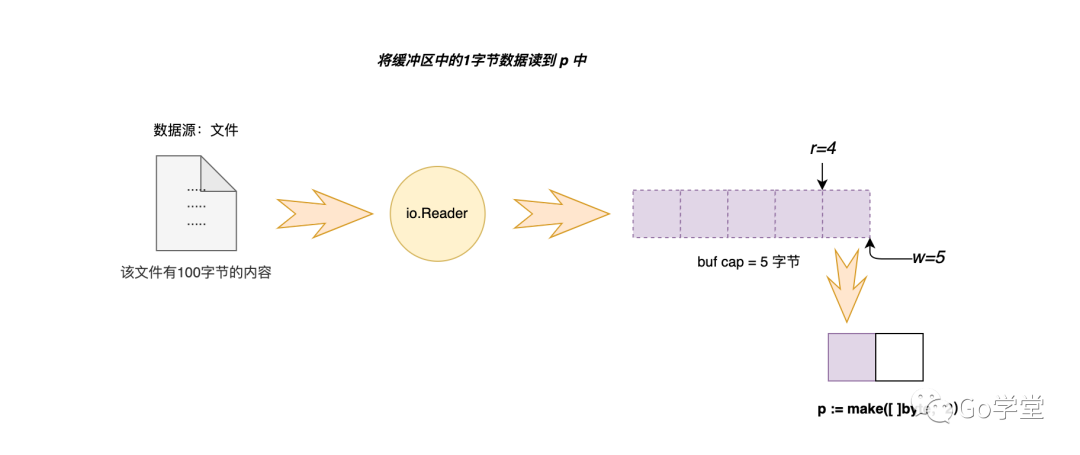
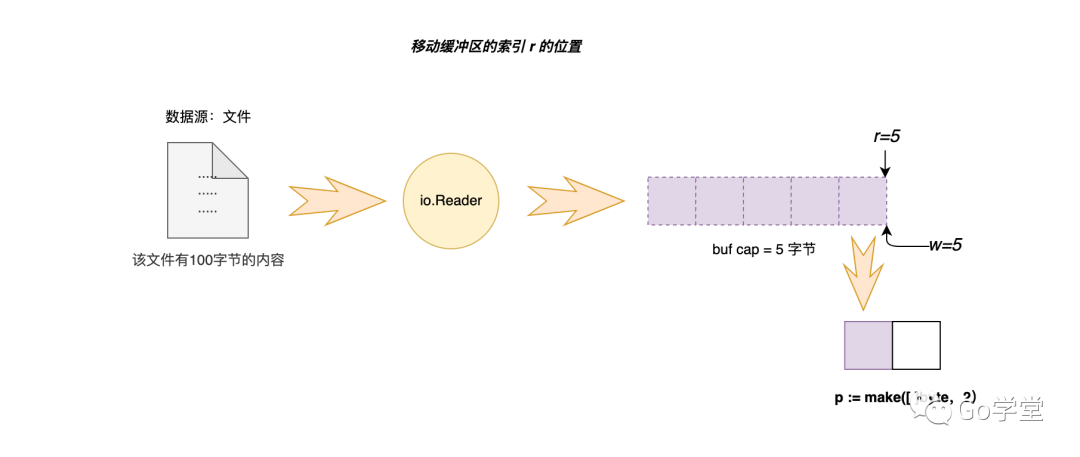
另外还有一种就是缓冲区满的状态下的读取逻辑,这种场景下就结合场景二进行读取即可。以上实际上就是bufio包中的Read([]byte)函数的逻辑,按字节读取。其实在实际编程中,我们经常会遇到的是按行读取,更通用一点就是一直读取到指定的字符为止。下面我们来看看这种读取操作的实现。
05 从缓冲区中读取到指定位置
这种读取方式是从缓冲区中读取数据,直到遇到指定的字符为止(实际上是指定字符所在的切片索引位置)。按行读取是最常见的场景之一,即一直读取到换行符为止。这种读取方式中也分两种情况:
- 情况1:当缓冲区中包含指定的字符,则从缓冲区中直接返回包含该字符及之前的有效内容。
- 情况2:当缓冲区中没有指定的字符,又分两种情况:
- 2.1 若缓冲区是满的状态,则返回整个缓冲的内容
- 2.2 若缓冲区处于非空状态(也非满的状态),则将缓冲区填满内容,再从该缓冲区中查找是否存在指定的字符。若在缓冲区中能够查找到指定的字符,则返回该指定字符及以前的内容,否则,返回整个缓冲区的内容,即2.1的情况。
情况1比较简单,假设我们在缓冲区中读取内容,直到遇到指定字符 E为止。缓冲区中的状态如下:
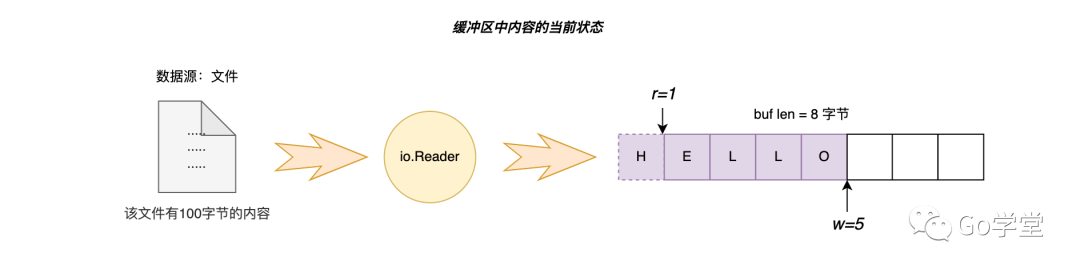
情况2稍微复杂下。下面我们稍微拆解下在缓冲区各种状态下第一次未找到对应的字符的情况。
首先我们看当缓冲区处于满的状态下,第一次未找到对应字符的逻辑。如下:
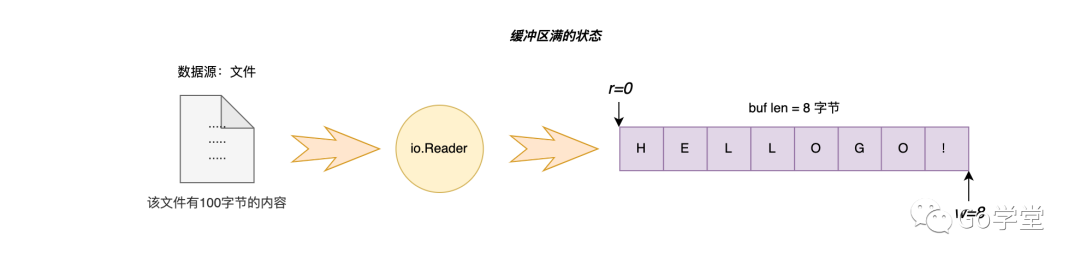
若在缓冲区中查找字符B,发现没有对应的字符,同时又发现缓冲区状态是满的状态,所以就直接将缓冲区中的所有内容都返回,同时将缓冲区满的错误返回给调用者。如下图,则返回给调用者 HELLOGO!,同时返回errors.New("buffer is full"):
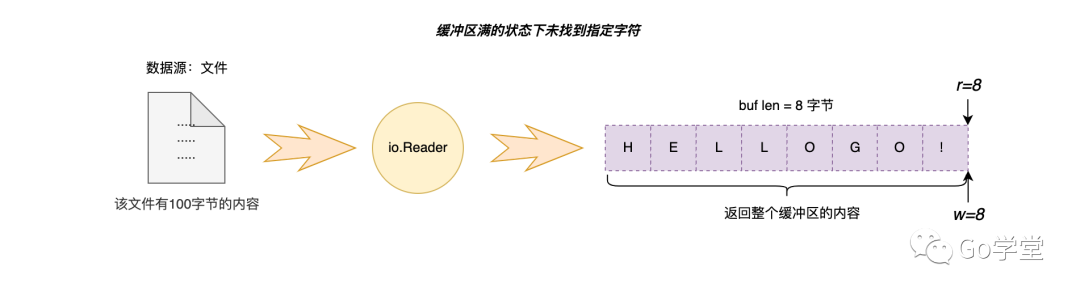
其次,我们看下如果缓冲区里有内容,但未满的状态的查找逻辑。假设缓冲区中下次可读的位置在第5个,如下图:
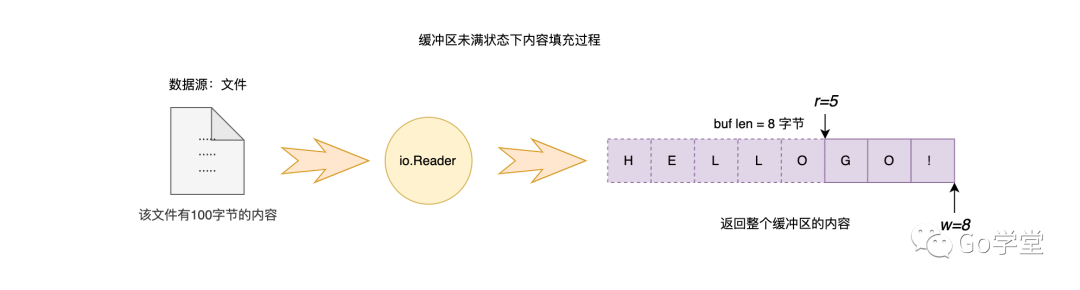
我们从缓冲区的索引5的位置开始查找字符B,发现没有找到。但同时也发现缓冲区处于非满的状态,因为从索引0到索引5之间的内容已经被读取走了,所以这段内存相当于处于空闲的状态。因此,这里会先将缓冲区中5到8之间的内容移动到0到3之间,然后再从文件中读取一段内容填充到缓冲3到8的位置上,最后继续查找。如下图:
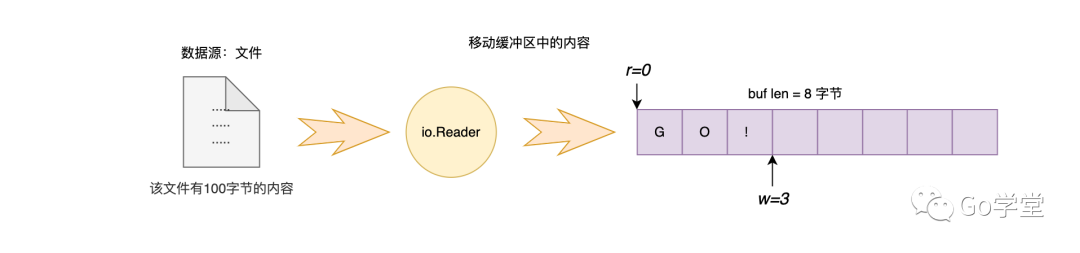
上图是移动完内容之后的结果。然后从文件中读取内容填充剩余的缓冲区,如下图:
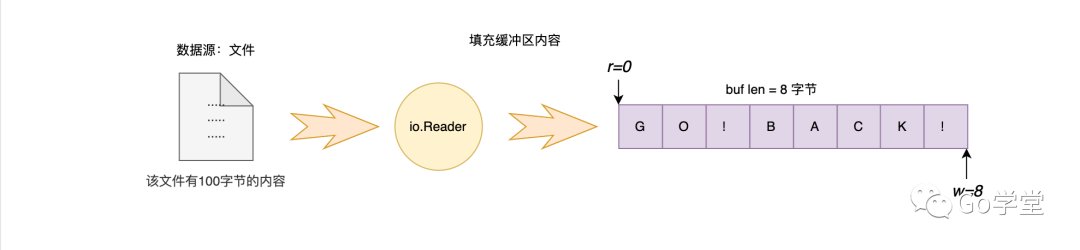
这样,缓冲区中又有了新的内容,则会从新的内容中继续查找指定的字符B,如下图: 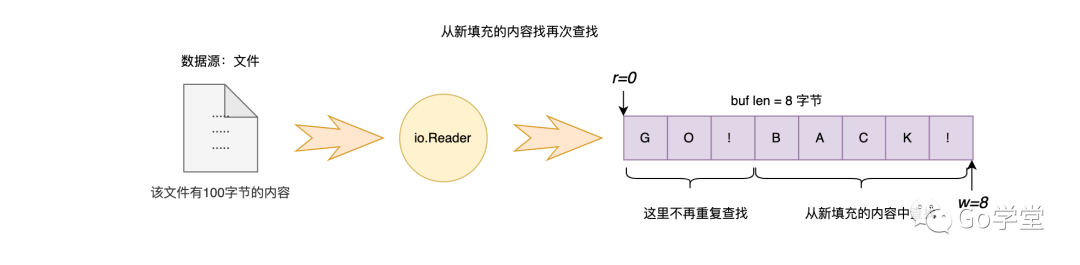
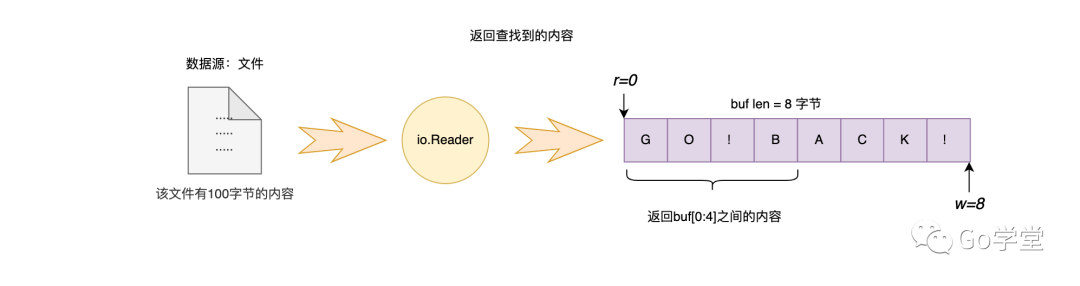
以上在缓冲区中移动内容到开始位置,并重新填充内容到缓冲区的过程实际上就是bufio包中的fill方法。而整个按指定字符读取的过程是bufio包中的ReadLine和ReadSlice函数的对应实现(ReadLine函数调用了ReadSlice函数)。ReadLine函数默认是读取内容,直到遇到第一个换行符\n为止。
我们注意到以上的ReadLine和ReadSlice函数都是在缓冲区中的内容中搜索。只要在缓冲区满的状态下,无论是能否搜索到对应的字符,都会返回。我们知道,文件内容的大小一般都会远远大于缓冲区的大小,那如果在缓冲区满的状态下没有找到对应的字符,如何继续往下查找呢?
06 从全文件中读取到指定位置
这种读取方式是从缓冲区中读取,如果该缓冲区中没有读到指定的字符,那么就将该缓冲区的内容暂存到一个临时区,然后再读取文件将缓冲区填满,再次查找,依次循环,直到读到指定的字符为止或读到文件的末尾,将所有的结果返回给调用者。
假设缓冲区处于满的状态,我们要查找指定的字符 r
第一步先从缓冲区中查找,如下:
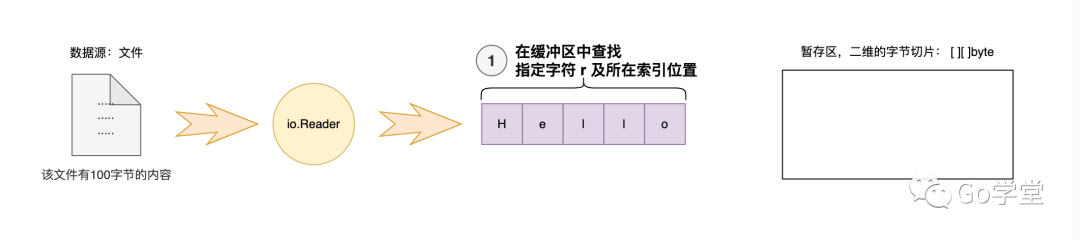
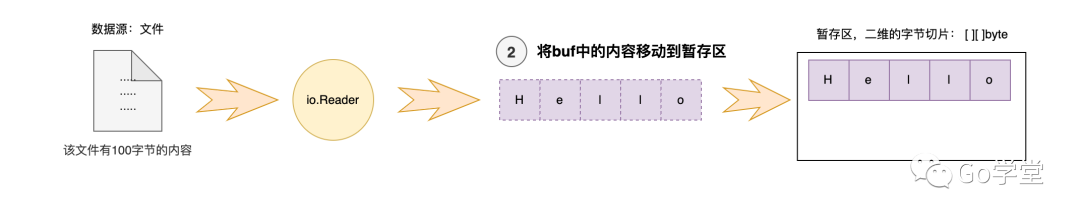
第三步,这时缓冲区实际处于空的状态,然后需要从文件中读取内容再次填充缓冲区,继续查找 是否有 r字符。如下图:

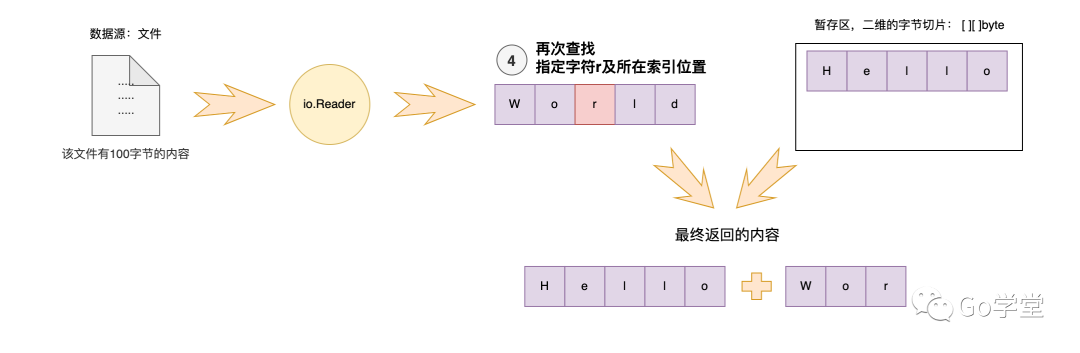
此过程就是bufio中的ReadString函数即对应的collectFragments函数的实现。有兴趣的同学可以查看对应的源码。
说在最后
由以上可知,bufio是利用局部性原理,通过将文件的内容预先加载到缓存中,以减少IO的系统调用来提高读取性能的。也就是说当读取数据时,只有在缓冲区中能够命中才能提高读取的性能。好了,以上就是我们分享的读取逻辑。下一篇文章我们继续解析bufio中的写入逻辑的实现。