C++服务性能优化的道与术-道篇:google benchmark的安装与使用
如果你实现一个公共的工具函数,有多种实现方式,你怎么测试性能呢?是循环多少次,然后打印一下起止时间,计算耗时吗?这样当然没问题。但是每次都类似的需求,都会写很多冗余的代码来进行耗时统计,另外也缺乏灵活性。有没有方便的方式来测试呢?有,Google家的benchmark性能测试框架。
编译安装google benchmark
github地址如下:
https://github.com/google/benchmark
下载benchmark的最新release代码。
wget https://github.com/google/benchmark/archive/refs/tags/v1.6.0.tar.gz
tar xvf v1.6.0.tar.gz我这里直接wget下载它最小的release包,当然你也可以用git clone它的源码。解压之后出现一个源码目录benchmark-1.6.0,接着我们使用cmake编译它。
不指定cmake参数的话,cmake执行完会提升缺少依赖库:googletest(即gtest)。如果你没有安装gtest的话,也没关系。可以用cmake参数移除该依赖。
cd benchmark-1.6.0/
cmake -DBENCHMARK_ENABLE_GTEST_TESTS=OFF .
make -j $(nproc)上面的-j $(nproc)会自动获取你的CPU核数,然后开始多核并行编译。cmake 执行后会生成Makefile文件,然后就能make了。
实战演练,split的性能对比
我们以字符串切分为例,实战演练一把benchmark的基本使用方法。由于C++没有官方提供字符串的split函数,所以我们可能见到过各种各样的实现方式。比如:
void split0(std::vector<std::string>& vec, std::string str, char delim) {
std::stringstream ss(str);
std::string word;
while (std::getline(ss, word, delim)) {
vec.push_back(word);
}
}
void split1(std::vector<std::string>& vec, std::string str, char delim) {
size_t pos = str.find(delim);
while (pos != std::string::npos) {
vec.emplace_back(str, 0, pos);
std::string new_s = str.substr(pos+1);
str.swap(new_s);
pos = str.find(delim);
}
if (str.size() > 0) {
vec.push_back(str);
}
}
void split2(std::vector<std::string> &vec, std::string str, char delim) {
size_t start = str.find_first_not_of(delim);
size_t end;
while (start != std::string::npos) {
end = str.find_first_of(delim, start + 1);
if (end == std::string::npos) {
//vec.push_back(str.substr(start));
vec.emplace_back(str, start);
break;
} else {
//vec.push_back(str.substr(start, end - start));
vec.emplace_back(str, start, end - start);
}
start = str.find_first_not_of(delim, end + 1);
}
}
void split3(std::vector<std::string> &vec, std::string str, char delim) {
int start = 0;
while (start < str.size()) {
size_t end = str.find(delim, start);
if (end == std::string::npos) {
vec.emplace_back(str, start);
break;
}
vec.emplace_back(str, start, end-start);
start = end + 1;
}
}这里我们简化问题,只考虑分隔符是单个字符的情况,不考虑字符串作为分隔符的情况,也不考虑连续空格是否要压缩成一个空格。另外还有大家常用的boost::split()。以及C语言中的strtok_r()。
void strtok_split(std::vector<std::string> &vec, std::string str, char delim) {
const int MAX_BUF_SIZE = 1024;
char* save = NULL;
char buf[MAX_BUF_SIZE];
char del[2] = "";
del[0] = delim;
int ret = snprintf(buf, sizeof(buf), "%s", str.c_str());
if (ret < 0) {
return;
}
char* token = strtok_r(buf, del, &save);
while (token != NULL) {
vec.emplace_back(token);
token = strtok_r(NULL, del, &save);
}
}使用benchmark做测试的时候要新增一个static函数,在其中调用你要测试的函数。
用法如下:
// 测试字符串
const std::string global_str = "1234_56_890_abcd_efg_hijk_lmn_opq_rst_uvw_xyz_1111_222_444";
static void BM_split0(benchmark::State& state) {
for (auto _ : state) {
std::vector<std::string> vec;
split0(vec, global_str, '_');
}
}
static void BM_split1(benchmark::State& state) {
for (auto _ : state) {
std::vector<std::string> vec;
split1(vec, global_str, '_');
}
}... 类似的我们把split2、split3、strtok_split也定义一下测试函数 每个static函数定义完成之后,都要调用一次宏函数BENCHMARK才能纳入测试用例中。
BENCHMARK(BM_split0);
BENCHMARK(BM_split1);
BENCHMARK(BM_split2);
BENCHMARK(BM_split3);
BENCHMARK(strtok_split);当然如果你觉得上面代码太冗余的话,其实可以抽成一个宏函数,因为他们的基本套路是一样的:
#define BM(func) static void BM_##func(benchmark::State& state) { \
for (auto _ : state) { \
std::vector<std::string> vec; \
func(vec, global_str, '_'); \
} \
} \
BENCHMARK(BM_##func);
BM(split0)
BM(split1)
BM(split2)
BM(split3)
BM(strtok_split)我们也测试一下boost::split()的性能,它一般有两种用法,搭配boost::is_any_of()或者自己手写lambda:
boost::split(vec, global_str, boost::is_any_of("_"));
// 或
boost::split(vec, global_str, [](char c) {return c == '_';});测一下它们:
static void BM_boost_split0(benchmark::State& state) {
for (auto _ : state) {
std::vector<std::string> vec;
boost::split(vec, global_str, boost::is_any_of("_"));
}
}
BENCHMARK(BM_boost_split0);
static void BM_boost_split1(benchmark::State& state) {
for (auto _ : state) {
std::vector<std::string> vec;
boost::split(vec, global_str, [](char c) {return c == '_';});
}
}
BENCHMARK(BM_boost_split1);最后在定义完之后,最后再调用一个宏函数。实现原理暂且不表,其中封装了main()函数。
BENCHMARK_MAIN();
编译这个代码:
g++ $^ -o $@ -I ~/local/include -std=c++11 -L ~/local/lib -lbenchmark -pthread
注意指定一下benchmark和boost的头文件路径以及libenchmark.a的库路径。
编译完成,然后运行:

Time就是运行的平均耗时,Iterations是运行的迭代次数。因为每个测试用例都是跑(基本)相同时间的,所以Time和Iterations是基本成反比的,因为毕竟运行一次的时间越短,同样时间内能执行的次数就越多嘛!
Time表示的是真实时间,CPU表示的是CPU时间,一般CPU时间会小于Time的时间。我这个在我的WSL上测试的,二者是一样的。
好了,这就是benchmark的入门教程了,十分简单是不是。当然benchmark还有一些高级的用法,本文就先不介绍了。
另外上面关于split函数测试的结论,你可以自行修改编译器的优化级别来看一下性能排名是否有变化。当然了C++17开始引入了string_view,对于split的实现可以更高效了。感兴趣的话可以阅读这篇文章:
[brpc小课堂:从StringPiece说开来]
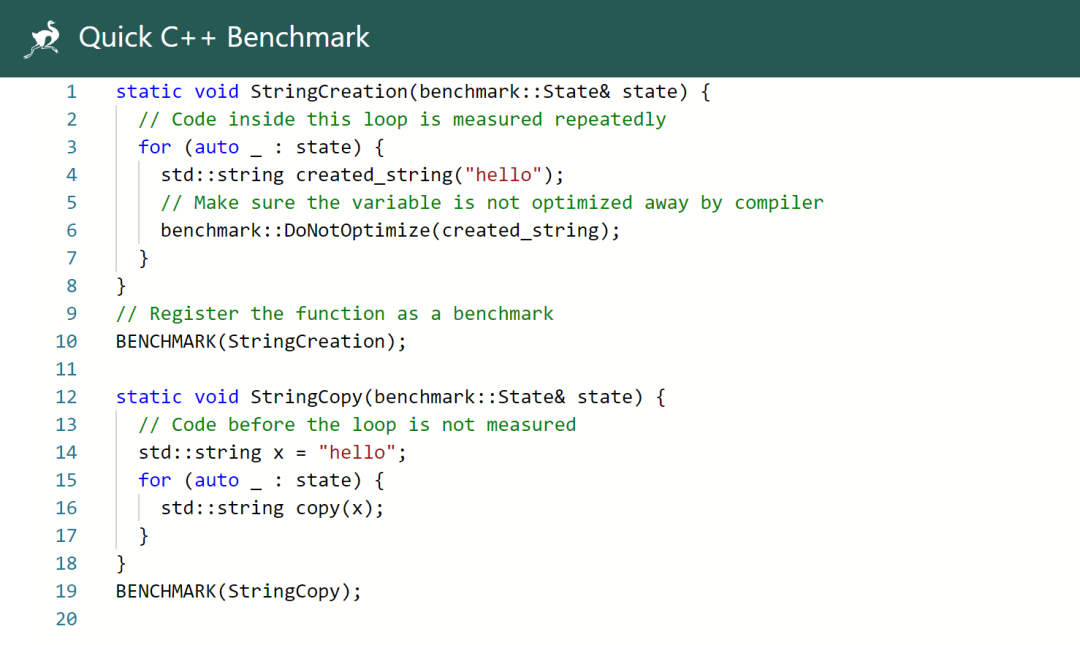
在线benchmark
前面讲到的测试流程,需要自己下载安装benchmark,然后写代码进行测试。有没有更方便的手段呢?有!
有一个在线benchmark的网站:
https://quick-bench.com/
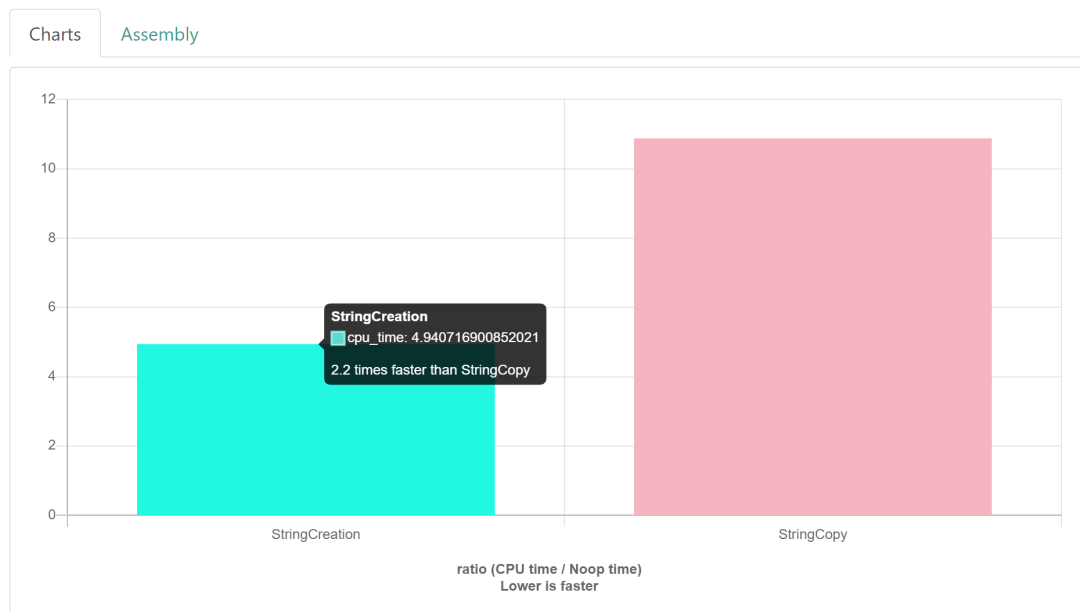
可以直接在网页上做benchmark,测试代码编写方法和前文一样。给大家截图看下这个网站: