高山仰之可极,谈半同步/半异步网络并发模型
0 . 仰之弥高
2015年,在腾讯暑期实习期间,leader给我布置的一个任务是整理分析网络模型。虽然也有正常工作要做,但这个任务贯穿了整个实习期。后来实习结束的总结PPT上,这部分内容占到了一半篇幅,我从C10K问题引入,讲了很多:从fork-exec的多进程到进程池;从多线程再到IO多路复用;从accept的惊群到pthread_cond_wait的惊群。
现在回想,这些总结还是偏初级,后来又看了很多资料,但感觉还是有很多东西抓不住,尽管如此却在我心里埋下一颗种子。以至于后来工作和学习中看到Server,我都会自我诘难:它是什么『网络模型』?
1 . 本立道生:基础知识导入
所谓『网络并发模型』,亦可称之为『网络并发的设计模式』。『半同步/半异步』模式是出镜率很高的一种模式,要想解释清楚它,我要先从基础讲起。熟悉的同学可以跳过本节。
1.1 单线程IO多路复用
首先带大家再回顾一个典型的单线程Polling API的使用过程。Polling API泛指select/poll/epoll/kqueue这种IO多路复用API。
一图胜千言:
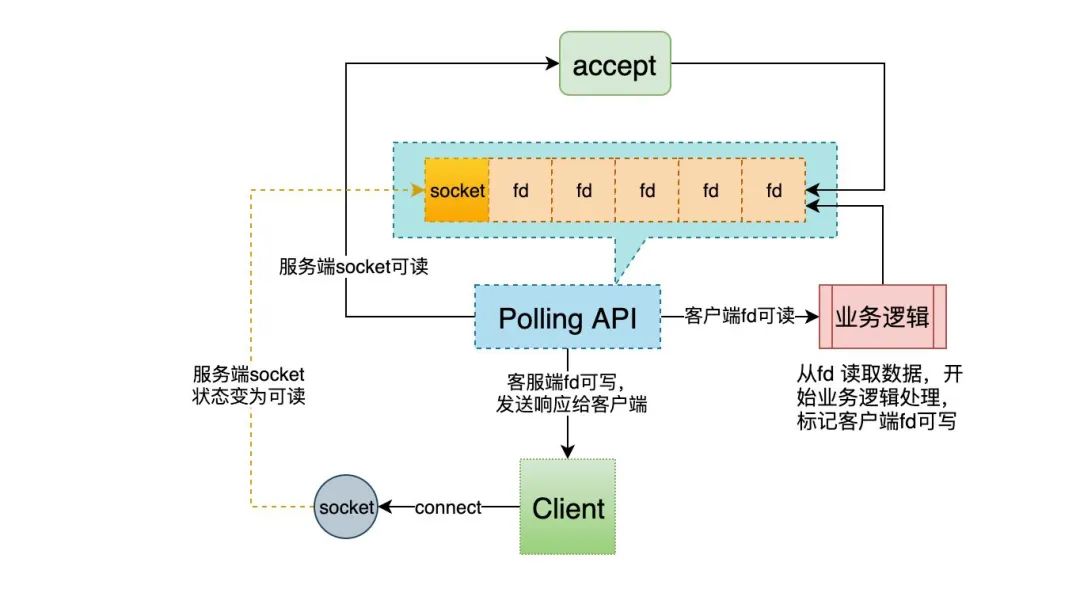
为了表达简洁清晰,用socket指代服务端套接字,fd表示连接之后的客户端套接字。
单线程Polling API的常规用法是:
让Polling API监控服务端socket的状态,然后开始死循循环,循环过程中主要有三种逻辑分支:
- 服务端socket的状态变为可读,即表示有客户端发起连接,此时就调用accept建立连接,得到一个客户端fd。将其加入到Polling API的监控集合,并标记其为可读。
- 客户端fd的状态变为可读,则调用read/recv从fd读取数据,然后执行业务逻辑,处理完,再将其加入到Polling API的监控集合,并标记其为可写。
- 客户端fd的状态变为可写,则调用write/send将数据发送给客户端。
1.2 平民级的多线程IO
最平民的多线程(or多进程)网络IO的模式,比较简单,这里就不画图了。就是主线程创建多个线程(pthread或者std::thread),然后每个线程内部开启死循环,循环体内进行accept。当无客户端连接的时候accept是阻塞的,当有连接到时候,则会被激活,accept开始返回。这种模式在上古时代,存在accept的『惊群』问题(Thundering herd Problem),即当有某个客户端连接的时候,多个阻塞的线程会被唤醒。当然这个问题在Linux内核2.6版本就已经解决。
2 . 言归正传:半同步/半异步
『半同步/半异步』模式(Half-Sync/Half-Async,以下简称HSHA),所谓『半同步/半异步』主要分三层:
异步IO层+队列层+同步处理层
当然也使用了多线程,一般是一个IO线程和多个工作线程。IO线程也可以是主线程,负责异步地从客户端fd获取客户端的请求数据,而工作线程则是并发的对该数据进行处理。工作线程不关心客户端fd,不关心通信。而IO线程不关心处理过程。
那么从IO线程到工作线程如何交换数据呢?那就是:队列。果然又应了那句老话『在软件工程中,没有一个问题是引入中间层解决不了』。
通过队列来作为数据交换的桥梁。因此可以看出,在HSHA模式中,有我们熟悉的『生产者、消费者』模型。当然由于涉及到多线程的同时操作队列,所以加锁是必不可以少的。
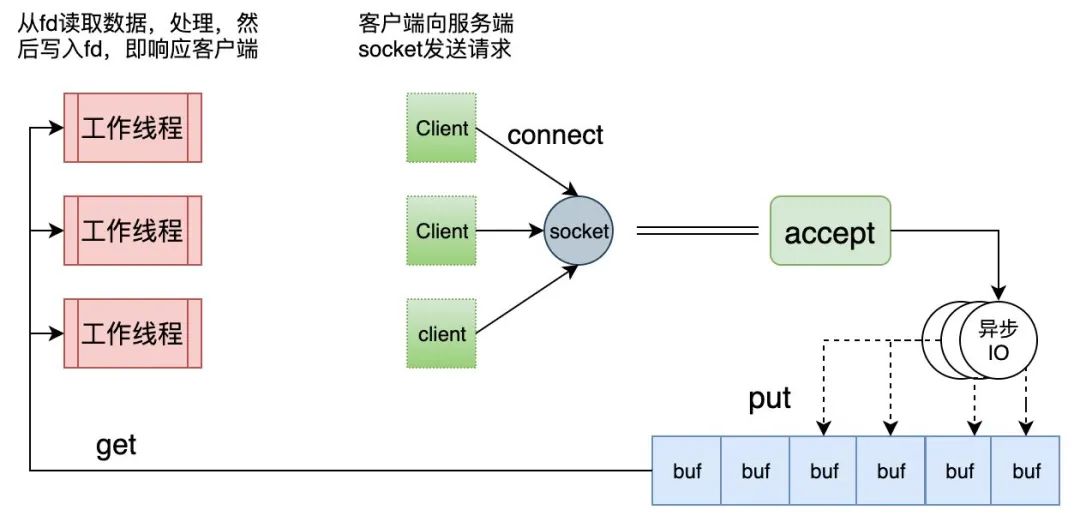
2.1 异步IO与同步处理
所谓异步:在接收客户端连接,获取请求数据,以及向队列中写入数据的时候是异步的。在写入完成可能会执行预设的回调函数,进行预处理和其他通知操作。也便是Proactor模式(与之相对的是Reactor,下文有述)。
关于异步IO,严重依赖内核的支持,比如Windows的IOCP就是公认的不错的异步IO实现,而Linux的AIO系列API虽然模拟了异步操作的接口,但是内部还是用多线程来模拟,实则为伪异步,十分鸡肋。另外请注意epoll不是异步IO!,epoll虽然可以一次返回多个fd的就绪状态,但若要获取数据,单线程的话还是同步一个fd一个fd的read的。
所谓同步:一个客户端连接的一次请求,其具体处理过程(业务逻辑)是同步的。虽然在消费队列的时候是多线程,但并不会多个线程并行处理一次请求。
综上,也就是说当一个客户端发送请求的时候,整个服务端的逻辑一分为二。第一部分,接收请求数据是异步的;第二部分,在收完数据之后的处理逻辑是同步的。所谓半同步,半异步因此得名。
2.2 返回数据是怎么发送的?
读完上一节,你明白了HSHA的名称由来,但是你发现没,漏讲了一部分。那就是『数据是如何发送回去的』。甚至我那个潦草的图里面都没有画。不止你有此一问,我其实也疑惑。关于HSHA,很多资料都有介绍如何用异步IO接收客户端请求数据,但却没有谈到应该如何发送响应数据给客户端。即便是HSHA的名称出处《POSA》这本书也没深究这部分。当然我们学习要活学活用,懂得灵活变通,而不能生搬硬套。关于如何发送,其实本身不是难点,我们也不需要拘泥于一定之规。
它的实现方式可以有很多,比如在工作线程中,处理完成之后,直接在工作线程向客户端发送数据。或者再弄一个写入队列,将返回数据和客户端信息(比如fd)放入该队列(在工作线程中侵入了IO逻辑,违背解耦初衷)。然后有一组专门负责发送的线程来取元素和发送(这种方式会增加额外的锁)。总之也不需要过分追求,什么标准、什么定义。
2.3 队列思考
队列中元素为封装了请求数据和其他元数据的结构体,可以称之为任务对象。HSHA模式不一定是多线程实现的,也可以是多进程。那么此时队列可能是一个共享内存,通过信号量同步来完成队列的操作。如果是多线程实现的。那么队列可以是一个普通的数组,多线程API若使用pthread,则同步即可使用pthread_mutext_t。当然也可以使用C++11的std::thread。
关于工作线程消费队列数据的方式,和一般的『队列』模型相同,即可分为『推』和『拉』两种模型。通常HSHA为推模型,即若队列尚无数据,则工作线程阻塞休眠,等待数据产生。而当IO线程写入了数据之后,则会唤醒休眠的工作线程来处理。很明显在pthread的语义下,这必然是一个条件变量(pthread_cond_t)。需要注意的是条件变量的惊群问题,即可能同时唤醒多个工作线程。前文虽然提到accept的惊群问题早被内核解决,但是条件变量的惊群问题仍在。这里需要注意的是虽然 pthread_cond_wait 本身便能阻塞线程,但一般还是要用while而非if来做阻塞判断,一方面便是为了避免惊群,另一个方面是某些情况下,阻塞住的线程可能被虚假唤醒(即没有pthread_cond_signal就解除了阻塞)。
用伪码来描述一下:
while (1) {
if (pthread_mutex_lock(&mtx) != 0) { // 加锁
... // 异常逻辑
}
while (!queue.empty()) {
if (pthread_cond_wait(&cond, &mtx) != 0) {
... // 异常逻辑
}
}
auto data = queue.pop();
if (pthread_mutex_unlock(&mtx) != 0) { // 解锁
... // 异常逻辑
}
process(data); // 处理流程,业务逻辑
}保险起见,上面的empty和pop函数内部一般也最好加锁保护。
再谈一下拉模型。即不需要条件变量,工作线程内做死循环,去不停的轮训队列数据。两种模型各有利弊,主要要看实际业务场景和业务规模,抛开业务谈架构,常常是狭隘的。如果是IO密集型的,比如并发度特别高,以至于几乎总能取到数据,那么就不需要推模型。
另外关于队列的数据结构,多进程需要使用到共享内存,相对麻烦,实际用多线程就OK了。前文提到多线程环境下用普通数组即可,尽管数组是定长的,当超过预设大小的时候,表示已经超过了处理能力则直接报错给客户端,即为一种『熔断』策略。我们当然也可以使用vector,但是切记,除非你真的了解容器,否则不要滥用。vector不是线程安全的,因此加锁也是必要的。另外一个隐患是,vector是可变长的,很多人自以为便自己为得起便利,除非系统内存不足,捕获一下bad_alloc,否则就以为万事大吉。殊不知vector在进行realloc,即重新分配内存的时候,之前的返回给你的迭代器会失效!
请记住C++不是银弹,STL更不是!
3 . 变体:半同步半反应堆
HSHA模式十分依赖异步IO,然而实现真异步通常是比较困难,即便Linux有AIO系列API,但其实十分鸡肋,内部用pthread模拟,在这方面不如Windows的IOCP。而当时IO多路复用技术的发展,带给了人们新的思路,用IO多路复用代替异步IO,对HSHA进行改造。这就是『半同步/半反应堆』模型(Half-Sync/Half-Reactor,以下简称HSHR)。
我又画了一个潦草的图:
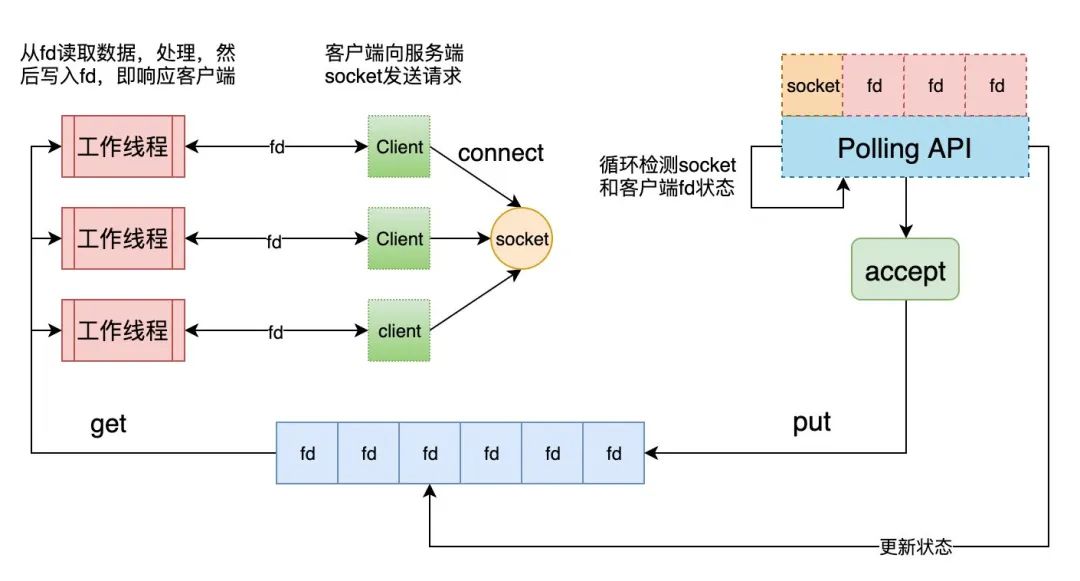
当然队列中存储的元素并不是简单的int来表示fd,而是一个结构体,里面除了包含fd以外还会包含一些其他信息,比如状态之类的。如果队列是数组,则需要有状态标记,fd是否就绪,是否已被消费等等。工作线程每次取的时候不是简单的竞争队首元素,而是也要判断一下状态。当然如果是链表形式的队列,也可以通过增删节点,来表示fd是否就绪,这样工作线程每次就只需要竞争队首了,只不过在每个连接频繁发送数据的时候,会频繁的增删相同的fd节点,这样的链表操作效率未必比数组高效。
3.2epoll一定比select效率高吗?
曾几何时,有位面试官问我“epoll一定比select效率高吗?”。我说“恩”。然后他一脸鄙夷,和我再三确认。面试结束后。我翻遍谷歌,想找出一些 what time select is better than epoll的例子来。但是很遗憾,没有发现。百度搜索国内的资料,发现国人倒是写过一些。比如说在监视的fd个数不多的时候,select可能比epoll更高效。
貌似很多人对select的理解存在误区,认为只有监视的fd个数足够多的时候,由于select的线性扫描fd集合操作效率才比较低,所以就想当然的认为当监视的fd个数不是很多的时候,它的效率可能比摆弄红黑树和链表的epoll要更高。其实不是,这个扫描效率和fd集合的大小无关,而是和最大的fd的数值有关。比如你只监视一个fd,这个fd是1000,那么它也会从0到1000都扫描一遍。当然这也不排除fd比较少的时候,有更大的概率它的数值一般也比较小,但是我不想玩文字游戏,如果硬要说fd集合小的时候,epoll效率未必最优的话,那也是和poll比,而不是select。
poll没有select那种依赖fd数值大小的弊端,虽然他也是线性扫描的,但是fd集合有多少fd,他就扫描多少。绝不会多。所以在fd集合比较小的时候,poll确实会有由于epoll的可能。但是这种场景使用epoll也完全能胜任。当然poll也并不总是由于select的。因为这两货还有一个操作就是每次select/poll的时候会将监视的fd集合从用户态拷贝到内核态。select用bitmask描述fd,而poll使用了复杂的结构体,所以当fd多的时候,每次poll需要拷贝的字节数会更多。所以poll和select的比较也是不能一概而论的。
当然我也没说select在“某些”情况下肯定就不会高于epoll哦(括弧笑)。
虽然总体来说select不如epoll,但select本身的效率也没你想象中那么低。如果你在老系统上看到select,也运行的好好的,那真的只是Old-Fashion,不存在什么很科学的解释,说这个系统为什么没采用epoll。Anyway,除非你不是Linux系统,否则为什么对epoll说不呢?
好了。本文基本就到这里了,再留个课后题:本文提到的模式严重依赖队列,那么可以取消掉这个队列吗?答案是当然可以,只是那就不是HSHA了,而是Leader/Follower或者其他了。
虽然本文废话很多,也可能论述有出入。但是如果你能耐心读完,相信你还是会有所收获的。很多模糊的,抓不住的概念,可以抓住了。很多自己本来就知道的东西,其实是一套定义或方法论的。所有技术问题都怕耐心,网络编程亦如是。耐心坚持下去,你终会发现:
高山仰之可极,深渊度之可测