Kafka-On-K8S 设计方案
@
-
背景
-
关键点分析
-
镜像构建
-
实例管理
-
数据持久化
-
网络方案
-
V1版本输出形态
-
Zookeeper-On-K8S资源示例
-
Kafka-On-K8S资源示例
1背景
本次V1版本的目标旨在跑通一套基本的kafka上云方案,仅包含kafka和zookeeper两个组件。后续再根据实际场景与需求进一步调整、丰富及优化。
过程中调研了confluent以及strimizi的kafka上云方案,两者都使用到了Operator(Kubernetes中的用户自定义资源CRD)的方式对应用进行抽象及管理,经组内讨论,V1版本只使用k8s的原生资源进行实现,这个版本不通过operator的方式进行管理。
使用CRD的优势:
Kubernetes中内置了很多原生的资源类型,这些资源类型实际上做的事情是期望状态管理,k8s自动将当前对象的实际状态不断向用户定义的预期状态趋同。这里简单的说,用户对于预期状态描述的能力以及自动化的状态管理能力受限于Kubernetes中内置资源类型的设定,但它们满足不了一些复杂的或定制化的场景需求,这种情况下Kubernetes为用户提供了自己开发定义CRD的方式来实现自己的需求。 但这样需要自行编写代码实现controller,增加方案复杂度。
2关键点分析
v1版本方案的设计需要考虑这些问题
镜像构建
- 基础镜像版本: centos7.9.2009
- jdk版本:jdk-8u281-linux-x64 ## 正式打包会使用JRE以使镜像更加精简
- zookeeper版本:apache-zookeeper-3.5.9-bin.tar.gz
- kafka版本:kafka_2.13-2.4.1.tar
- 其他:nc、net-tools、kubectl 等
1. 构建带jdk的基础镜像,支持java程序运行
#base-Dockerfile
#base-Dockerfile
FROM centos:centos7.9.2009
MAINTAINER xxxxxx xxxxxx@xxxxxx.com
ADD jdk-8u281-linux-x64.rpm /opt
RUN set -x \
&& yum -y install /opt/jdk-8u281-linux-x64.rpm \
&& yum -y install vi nc wget net-tools \
&& yum clean all \
&& rm -rf /opt/jdk-8u281-linux-x64.rpm
docker build -f base-Dockerfile -t centos-jdk:7.9-1.8 .
2.使用jdk镜像构建zookeeper镜像
#zookeeper-Dockerfile
FROM centos-jdk:7.9-1.8
ADD apache-zookeeper-3.5.9-bin.tar.gz /opt
ADD kubectl /usr/local/bin/
docker build -f zookeeper-Dockerfile -t zk-centos:3.5.9-7.9 .
3.使用jdk镜像构建kafka镜像
#kafka-Dockefile
FROM centos-jdk:7.9-1.8
ADD kafka_2.13-2.4.1.tar /opt
ADD kubectl /usr/local/bin/
docker build -f kafka-Dockerfile -t kafka-centos:2.4.1-7.9 .
实例管理
进程管理
我们需要管理多个kafka和zookeeper的实例进程,由于不提倡一个容器内管理多个进程,因此每个kafka的broker或zookeeper的实例独自占用一个container。
为什么不提倡一个容器内管理多个进程?
一般来讲,容器不具备管理多个进程的能力,是典型的单进程模型。 因为容器的主进程(PID=1)就是启动命令对应的应用本身,其他的进程都是这个主进程的子进程。 而大部分应用作为主进程时都不具备像systemd那样拥有管理任意进程的能力。 如果另辟蹊径采用“docker in docker”的方式,会带来较大安全隐患。
kubernetes中的最小可调度单元为Pod而不是Container,pod本质是一个容器组, 因此这里每个kafka或zk的实例都会对应到一个单独的pod。
为什么kubernetes需要Pod作为“一等公民”?
- 参考了操作系统“进程组”的概念。
- 考虑到某些应用必须部署在同一台机器上进行本地通信,容器组作为一个整体避免了这些容器被调度到不同的节点。
- pod中的所有容器共享的是同一个NetworkNamespace,并且可以声明共享同一个Volume,这样一来用“SideCar”的模式可以通过辅助容器来完成一些独立于主容器之外的工作。
生产环境的集群一定是高可用的部署方式,因此单独Pod是不能满足需求的,需要对多个Pod进行编排。K8S中内置了对Pod进行编排的工作负载资源——StatefulSet, Deployment, DaemonSet, CronJob, Job。
其中sts主要用于有状态服务的管理,因此这里会选择sts来管理kafka和zk。
状态管理
zk和kafka主要涉及到两种状态的管理:网络标识和存储。
zk和kafka中各个节点通信需要固定唯一的网络标识,每次创建的Pod,其IP地址都是重新生成的,不能保证不变。 而在sts中管理的pod,虽然IP会变,但是pod的名字每次重建都是固定的:<sts name>-<index>,当用户提前配置好了能够将Pod名字作为dns解析的Service资源时,我们就可以用<pod name>.<svc name>.<namespace>来作为Pod的唯一网络标识,无论ip怎么变化,节点之间都能通过dns记录来找到正确的ip地址。
zk和kafka会将一些有状态数据持久化到存储中,这就要求不论Pod重建多少次,都访问的是同一份存储数据。k8s中本来就抽象出了持久化存储PersistentVolume,不论Pod重建多少次,其所使用的PV是不会自动回收的,因此只要能够固定Pod和PV的关系就可以解决这个问题。
sts里提供了专有的volumeClaimTemplates字段,在这个字段中可以对PVC做出描述,sts创建时会优先查找是否存在同名的pvc,只有不存在才会重新创建。而PVC的名字由Pod的名字构成,有几个Pod就会有几个PVC,因此每次Pod重建,PVC的名字都不会变,同时pvc与pv又是一对一绑定的关系。这样就保证了无论Pod重建多少次,它所使用的PV存储都是同一份。
配置管理
k8s抽象出了专门管理配置的资源类型——ConfigMap。可以将ConfigMap以文件的形式挂载到容器中,这样做的一个好处是,修改配置文件可以在容器外进行而不用进入每个容器,如果用户修改了对应的configmap,那么容器中对应的文件会被自动修改。
对于一些必要的环境变量,可以直接在sts里容器相关的配置字段中定义。
启动,停止,升级
配置文件中的某些配置是无法在声明式的YAML里提前定义的,比如:
zookeeper——zoo.cfg
server.1=zksts-0.zksvc.default.svc.cluster.local:2888:3888
server.2=zksts-1.zksvc.default.svc.cluster.local:2888:3888
server.3=zksts-2.zksvc.default.svc.cluster.local:2888:3888
zookeeper——myid
3
kafka——server.propertise
broker.id=$KAFKA_BROKER_ID"
listeners=PLAINTEXT://$HOSTNAME.$DOMAIN:9092
advertised.listeners=PLAINTEXT://$NODEIP:$((31090+${KAFKA_BROKER_ID}))因此我们会将上面这类的配置在启动之前自动生成或者使用initContainer进行初始化,这个启动脚本也会直接放在对应的ConfigMap中,zk和kafka的启动命令便是直接运行各自的脚本。
手动删除sts中的pod,pod会被自动重启,因此停止服务的方式是将sts下线,如果下线前需要做定制化的回收工作,可以在lifecycle.preStop字段中定义Shell,这个shell会阻塞容器的停止直到执行完成。
当需要升级版本时,修改sts中的镜像地址或版本,直接更新sts即可,sts中提供两种更新策略:RollingUpdate和OnDelete。前一种是one-by-one的逐个更新Pod,后一种不会自动更新,全靠用户手动删除Pod来触发更新,多用于灰度发布。
健康检查
k8s提供了存活探针和就绪探针的健康检查能力,这两个字段并不是sts独有。
存活探针支持通过shell或接口判断容器的存活状态,异常的话会自动重启容器。
就绪探针会判断容器启动命令执行后是否到达了可以对外提供服务的阶段,只有到了就绪标准,这个Pod才会对外提供服务,这里对外提供服务的依赖是Service。
弹性伸缩
sts通过spec.replicas来定义Pod实例的个数,直接修改这个字段k8s会自动对pod个数进行调整。sts每次的删除都是按照index由大到小,每次新增都是由小到大。
对于存储,pv有两种制备方式,一种是集群管理员或运维提前创建好足够多的pv,使用方声明了pvc后自动去匹配符合要求的pv,这种情况下,需要pv充足的情况下才能够扩容成功。另一种方式是管理员或运维人员提前定义好StorageClass资源,当使用方在声明pvc的时候指定了sc,那么之后如果在集群中找不到符合要求的pv,k8s就会自动创建出一个pv,直接与这个pvc所绑定。这种情况下,扩容时总是会有pod需要的新pv。另一方面,sts缩容后并不会自动删除之前pod使用的pvc和pv。
对于扩缩容后Pod实例的变化,对外提供服务的Service资源中会自动更新后端代理的Pod。
数据持久化
kubernetes提供了PersistentVolume,PersistentVolumeClaim,StorageClass三种资源将存储抽象了出来实现数据持久化。而StatefulSet又提供了存储状态的管理能力。但依然还存在一个问题。
由于Pod在实际环境中,常常会产生漂移,即重启后的pod可能从一台主机跑到另一台主机上重建,这大多数情况下取决于k8s的调度控制。这种情况下,如果想要Pod在重建后仍然能使用之前的pv,就需要从下面两个方案中选择一种:
- 存储与计算分离。
- 强制Pod与PV总是在同一节点。
如果要实现第一种存储与计算分离,我们就需要引入远端的分布式存储,比如Ceph RBD。
Ceph支持动态供应PV的方式,同时官方也给出了Ceph-CSI插件,这样一来,只需要提前在集群中安装Ceph-CSI的插件(这些插件主要作用一是为了监听存储资源的变更,找到需要使用ceph的资源;二是实现了和ceph交互的逻辑,例如如何从ceph申请一块指定的volume)。接着定义一个Ceph的StorageClass资源,然后就可以直接使用pvc来创建自己需要的ceph存储。
这时候如果pod进行了漂移,那么对应的cech块存储会自动从旧节点unmount,unattach,再attach到新的节点,mount到该节点指定的目录。我们提供的方案就是动态供应的ceph rbd。但是ceph rbd也有自己的一些问题,例如性能,例如不支持同时attach到多个节点等。
经组内讨论,由于ceph rbd的一些特性还在研究中,因此V1版本先不采用这个存储与计算分离的方案,我们使用local pv来实现第二种方案。
如果实现了Pod与PV总是在同一节点这个效果,那么我们完全可以直接使用本地的存储。而官方正好提供了节点亲和度这个字段在PV上。

local pv有一个限制,只支持静态供应,但使用local pv时候提前创建一个storage class是有必要的,因此WaitForFirstConsumer属性在sc中定义后,可以延迟pv的绑定。这样一来,在pod被创建后,对应的pv才并和pvc进行绑定,对于local pv来说,不但保证了pod与pv一定是同一节点,而且还能够使k8s兼顾到pod自己的调度优先级。
对于存储的扩容,直接修改pvc的大小即可,修改后pv也会自动变更大小。
网络方案
k8s网络背景概述
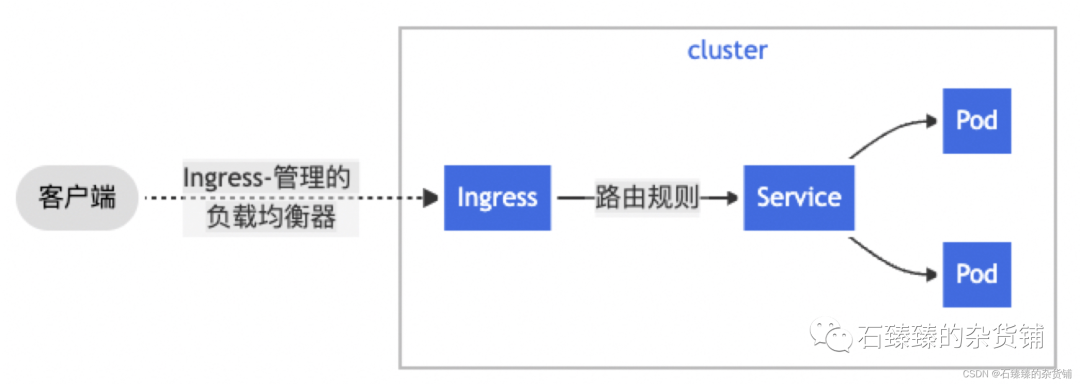
如上图,k8s网络资源主要包含service和ingress, service可以理解成四层负载,主要使用场景是在k8s集群内部提供负载服务, ingress对应七层负载,提供url匹配,ssl卸载等高级功能,主要使用场景是对集群外部暴露k8s中部署的服务
k8s部署时,一般为service和pods分别配置两个独立网段, 默认,这两个网段k8s集群外部都是不能访问到的。
k8s网络方案
按网络模型来说,分为underlay和overlay两种 我们现在underlay模型是基于macvlan开源方案, overlay模型当前是基于flannel开源方案,后面还会继续探寻其他优秀方案
macvlan
这种方案直接将pods的网段暴露给了k8s集群外部,网关和路由交给交换机管理,
默认k8s service不能提供服务,需要引入外部的负载均衡方案,
比如我们部署的环境就是这种,引入了系统部自研的DLB四层负载,
转发性能高,和传统网络拓扑融合,利于传统应用快速上容器,
但是灵活性差,ip地址依赖物理环境,不能随意分配
flannel
vxlan类型的overlay网络,对底层物理网络无要求,只要工作节点之间三层连通就可以, k8s pods和service网络都不能提供外部访问,只在集群内可见,
转发性能一般, 不依赖物理网络,灵活性高
kafka网络需求
客户端和kafka的通信,需要明确访问到指定的broker,也就是某个确认的pods,
这个在k8s的underlay网络场景不用特别考虑,因为pods的ip直接就可以供外部访问, 唯一需要做的就是保障确定pods的ip重启时不要发生变更即可。
具体来说, pod1(broker1)永远对应到ip1,在升级或者重建时也不要变更, 这个限制是因为我们没有全局DNS方案, 具备全局dns服务后,可以使用域名替换ip访问,ip不再有要求
这里,我们主要需要讨论overlay的网络场景,在集群外部访问kafka的情况, 由于pods网络不能对外访问,为此,我们需要解决一个关键问题:
- kafka broker对应的pods需要提供外部可访问的地址
k8s对外提供服务有三种方式:1) nodePort类型service 2) loadbalancer类型service 3) ingress 我们可以基于这几种对外暴露pods的服务,为每一个pods(kafka broker)提供一个外部可访问的地址, 因为2和3中都需要引入外部服务, 这里我们默认使用nodePort的方式提供对外访问,也就是将物理机ip的某个端口映射给pods的服务端口,对于单独的broker,需要配置单独的nodeport service来代理,每个sts管理的pod,在创建后都会自动打上一个独有的标签,value是pod name,这样一来,service通过labels进行pod选择时,就可以只选择出指定的单个pod。
V1版本输出形态
Helm是一个K8S的包管理工具,可以多一组资源yaml进行下发和管理。简单来说可以在发布时动态修改charts包中资源的参数,一键发布及管理一组yaml资源。
我们将kafka-on-k8s的方案打成helm charts的包,将这个包放在kubeAssemble的应用商店中当作App提供给用户,用户可以在界面自定义必要信息后一键部署kafka到k8s中。
3Zookeeper-On-K8S资源示例
以下是zookeeper在k8s中的yaml资源示例,自动化所用的helm charts详见内部GitLab的Kafka-On-K8S项目。
local-storage.yaml, 定义local pv的供应参数,由于local pv无法动态供应,这里只是为了volumeBindingMode参数生效。
kind: StorageClass
apiVersion: storage.k8s.io/v1
metadata:
name: local-storage
provisioner: kubernetes.io/no-provisioner
volumeBindingMode: WaitForFirstConsumer
zksts.yaml,zk的工作负载
apiVersion: apps/v1
kind: StatefulSet
metadata:
name: zksts
namespace: default
spec:
selector:
matchLabels:
app: zksts
serviceName: "zksvc"
replicas: 3
updateStrategy:
type: RollingUpdate
podManagementPolicy: Parallel
template:
metadata:
labels:
app: zksts
annotations:
spec:
terminationGracePeriodSeconds: 10
initContainers:
- name: init-config
image: zookeeper:3.5.9
command: ['/bin/bash', '/etc/zk/config/init.sh']
env:
- name: POD_NAME
valueFrom:
fieldRef:
fieldPath: metadata.name
- name: POD_NAMESPACE
valueFrom:
fieldRef:
fieldPath: metadata.namespace
- name: REPLICAS
value: "3"
volumeMounts:
- name: configmap
mountPath: /etc/zk/config
- name: data
mountPath: /data/zookeeper/data
dnsPolicy: None
dnsConfig:
nameservers:
- 10.100.2.84
options:
- name: ndots
value: "5"
containers:
- name: zookeeper
image: zk-centos:3.5.9-7.9
env:
- name: POD_NAME
valueFrom:
fieldRef:
fieldPath: metadata.name
- name: KAFKA_LOG4J_OPTS
value: -Dlog4j.configuration=file:/etc/zk/config/log4j.properties
#- name: ZOO_CONF_DIR
# value: /etc/zk/config
#- name: ZOO_DATA_DIR
# value: /data/zk
command:
#- tail
#- -f
#- /dev/null
- /opt/apache-zookeeper-3.5.9-bin/bin/zkServer.sh
- --config
- /etc/zk/config
- start-foreground
#- ./bin/zkServer.sh
#- --config
#- /etc/zk/config/zoo.cfg
#- start
#lifecycle:
# preStop:
# exec:
# command: ["sh", "-ce", "kill -s TERM 1; while $(kill -0 1 2>/dev/null); do sleep 1; done"]
ports:
- containerPort: 2181
name: client
- containerPort: 2888
name: peer
- containerPort: 3888
name: leader-election
resources:
requests:
cpu: 100m
memory: 100Mi
limits:
memory: 120Mi
#readinessProbe:
# exec:
# command:
# - /bin/sh
# - -c
# - '[ "imok" = "$(echo ruok | nc -w 1 -q 1 127.0.0.1 2181)" ]'
#timeoutSeconds: 2
#periodSeconds: 30
volumeMounts:
- name: configmap
mountPath: /etc/zk/config
- name: data
mountPath: /data/zk
volumes:
- name: configmap
configMap:
name: zkconfig
volumeClaimTemplates:
- metadata:
name: data
spec:
accessModes: [ "ReadWriteOnce" ]
storageClassName: "local-storage"
resources:
requests:
storage: 10Gizkconfig.yaml, zk的配置文件及启动脚本
kind: ConfigMap
metadata:
name: zkconfig
namespace: default
apiVersion: v1
data:
configuration.xsl: |
<?xml version="1.0"?>
<xsl:stylesheet xmlns:xsl="http://www.w3.org/1999/XSL/Transform" version="1.0">
<xsl:output method="html"/>
<xsl:template match="configuration">
<html>
<body>
<table border="1">
<tr>
<td>name</td>
<td>value</td>
<td>description</td>
</tr>
<xsl:for-each select="property">
<tr>
<td><a name="{name}"><xsl:value-of select="name"/></a></td>
<td><xsl:value-of select="value"/></td>
<td><xsl:value-of select="description"/></td>
</tr>
</xsl:for-each>
</table>
</body>
</html>
</xsl:template>
</xsl:stylesheet>
init.sh: |-
#!/bin/bash
set -e
set -x
[ ! -d /data/zookeeper/data ] && mkdir -p -m 770 /data/zookeeper/data
echo $((${HOSTNAME##*-} + 1)) | tee /data/zookeeper/data/myid
log4j.properties: |-
zookeeper.root.logger=INFO, CONSOLE
zookeeper.console.threshold=INFO
zookeeper.log.dir=.
zookeeper.log.file=zookeeper.log
zookeeper.log.threshold=INFO
zookeeper.log.maxfilesize=256MB
zookeeper.log.maxbackupindex=20
zookeeper.tracelog.dir=${zookeeper.log.dir}
zookeeper.tracelog.file=zookeeper_trace.log
log4j.rootLogger=${zookeeper.root.logger}
log4j.appender.CONSOLE=org.apache.log4j.ConsoleAppender
log4j.appender.CONSOLE.Threshold=${zookeeper.console.threshold}
log4j.appender.CONSOLE.layout=org.apache.log4j.PatternLayout
log4j.appender.CONSOLE.layout.ConversionPattern=%d{ISO8601} [myid:%X{myid}] - %-5p [%t:%C{1}@%L] - %m%n
log4j.appender.ROLLINGFILE=org.apache.log4j.RollingFileAppender
log4j.appender.ROLLINGFILE.Threshold=${zookeeper.log.threshold}
log4j.appender.ROLLINGFILE.File=${zookeeper.log.dir}/${zookeeper.log.file}
log4j.appender.ROLLINGFILE.MaxFileSize=${zookeeper.log.maxfilesize}
log4j.appender.ROLLINGFILE.MaxBackupIndex=${zookeeper.log.maxbackupindex}
log4j.appender.ROLLINGFILE.layout=org.apache.log4j.PatternLayout
log4j.appender.ROLLINGFILE.layout.ConversionPattern=%d{ISO8601} [myid:%X{myid}] - %-5p [%t:%C{1}@%L] - %m%n
log4j.appender.TRACEFILE=org.apache.log4j.FileAppender
log4j.appender.TRACEFILE.Threshold=TRACE
log4j.appender.TRACEFILE.File=${zookeeper.tracelog.dir}/${zookeeper.tracelog.file}
log4j.appender.TRACEFILE.layout=org.apache.log4j.PatternLayout
log4j.appender.TRACEFILE.layout.ConversionPattern=%d{ISO8601} [myid:%X{myid}] - %-5p [%t:%C{1}@%L][%x] - %m%n
zoo.cfg: |
tickTime=2000
initLimit=10
syncLimit=5
dataDir=/data/zk
clientPort=2181
run: |
#!/bin/bash
set -a
mkdir -p /conf
rm -rf /conf/*
cp /etc/zk/config/* /conf/
HOST=$(hostname)
DOMAIN=`hostname -d`
if [[ ${DOMAIN: -1} == '.' ]]
then
DOMAIN=$(echo "${DOMAIN}cluster.local")
fi
if [[ $HOST =~ (.*)-([0-9]+)$ ]]; then
NAME=${BASH_REMATCH[1]}
else
echo "Failed to extract ordinal from hostname $HOST"
exit 1
fi
# 这里可以自行echo一些配置进去
for (( i=1; i<=$REPLICAS; i++ ))
do
echo "server.$i=$NAME-$((i-1)).$DOMAIN:2888:3888" >> /conf/zoo.cfg
done
/opt/apache-zookeeper-3.5.9-bin/bin/zkServer.sh --config /conf start-foreground
zksvc.yaml, headless service,用于zk pod的dns解析
apiVersion: v1
kind: Service
metadata:
name: zksvc
spec:
ports:
- port: 2888
name: peer
- port: 3888
name: leader-election
clusterIP: None
selector:
app: zksts
zkpv.yaml,local pv定义,这里有多少pod,就要提前定义多少pv
apiVersion: v1
kind: PersistentVolume
metadata:
name: zk-data-2
spec:
capacity:
storage: 10Gi
volumeMode: Filesystem
accessModes:
- ReadWriteOnce
persistentVolumeReclaimPolicy: Delete
storageClassName: local-storage
local:
path: /data/zookeeper/2
nodeAffinity:
required:
nodeSelectorTerms:
- matchExpressions:
- key: kubernetes.io/hostname
operator: In
values:
- 1.1.1.1
4Kafka-On-K8S资源示例
以下是zookeeper在k8s中的yaml资源示例,自动化所用的helm charts详见GitLab的Kafka-On-K8S项目。
local-storage.yaml,与zk共用同一个。
kafkapv.yaml, 与zk基本一致。
kafkasts.yaml, kafka的工作负载
apiVersion: apps/v1
kind: StatefulSet
metadata:
name: kafkasts
spec:
selector:
matchLabels:
app: kafkasts
serviceName: "kafkadns"
replicas: 3
updateStrategy:
type: RollingUpdate
podManagementPolicy: Parallel
template:
metadata:
labels:
app: kafkasts
spec:
terminationGracePeriodSeconds: 30
containers:
- name: kafka-broker
image: kafka-centos:2.4.1-7.9
env:
- name: POD_NAME
valueFrom:
fieldRef:
fieldPath: metadata.name
- name: POD_NAMESPACE
valueFrom:
fieldRef:
fieldPath: metadata.namespace
- name: KAFKA_LOG4J_OPTS
value: -Dlog4j.configuration=file:/etc/kafka/config/log4j.properties
- name: JMX_PORT
value: "9999"
- name: NODEIP
valueFrom:
fieldRef:
apiVersion: v1
fieldPath: status.hostIP
- name: PODIP
valueFrom:
fieldRef:
fieldPath: status.podIP
ports:
- name: inside
containerPort: 9092
- name: jmx
containerPort: 9999
command:
#- tailf
#- /dev/null
- /bin/bash
- /etc/kafka/config/run
#lifecycle:
# preStop:
# exec:
# command: ["sh", "-ce", "kill -s TERM 1; while $(kill -0 1 2>/dev/null); do sleep 1; done"]
resources:
requests:
cpu: 100m
memory: 100Mi
limits:
cpu: 600m
memory: 600Mi
readinessProbe:
tcpSocket:
port: 9092
timeoutSeconds: 1
volumeMounts:
- name: configmap
mountPath: /etc/kafka/config
- name: data
mountPath: /data/kafka
volumes:
- name: configmap
configMap:
name: kafkaconfig
volumeClaimTemplates:
- metadata:
name: data
spec:
accessModes: [ "ReadWriteOnce" ]
storageClassName: "local-storage"
resources:
requests:
storage: 5Gikafkadns.yaml, headless service,用于对kafka pod的dns解析
apiVersion: v1
kind: Service
metadata:
name: kafkadns
spec:
ports:
- port: 9092
name: inside
clusterIP: None
selector:
app: kafkasts
kafkaconfig.yaml, kafka的配置文件和启动脚本
kind: ConfigMap
metadata:
name: kafkaconfig
apiVersion: v1
data:
run: |-
#!/bin/bash
set -a
set -e
set -x
mkdir -p /conf
rm -rf /conf/*
cp /etc/kafka/config/* /conf/
HOST=$(hostname)
DOMAIN=`hostname -d`
if [[ ${DOMAIN: -1} == '.' ]]
then
DOMAIN=$(echo "${DOMAIN}cluster.local")
fi
KAFKA_BROKER_ID=${HOSTNAME##*-}
if [[ $HOST =~ (.*)-([0-9]+)$ ]]; then
NAME=${BASH_REMATCH[1]}
else
echo "Failed to extract ordinal from hostname $HOST"
exit 1
fi
echo "broker.id=$KAFKA_BROKER_ID" >> /conf/server.properties
echo "listeners=PLAINTEXT://$HOSTNAME.$DOMAIN:9092,EXTERNAL://0.0.0.0:$((31090+${KAFKA_BROKER_ID}))" >> /conf/server.properties
echo "advertised.listeners=PLAINTEXT://$HOSTNAME.$DOMAIN:9092,EXTERNAL://$NODEIP:$((31090+${KAFKA_BROKER_ID}))" >> /conf/server.properties
/opt/kafka_2.13-2.4.1/bin/kafka-server-start.sh /conf/server.properties
server.properties: |
delete.topic.enable=true
auto.create.topics.enable=false
auto.leader.rebalance.enable=false
num.network.threads=3
num.io.threads=8
socket.send.buffer.bytes=102400
socket.receive.buffer.bytes=102400
socket.request.max.bytes=104857600
log.dirs=/data/kafka-logs
num.partitions=1
num.recovery.threads.per.data.dir=1
offsets.topic.replication.factor=1
transaction.state.log.replication.factor=1
transaction.state.log.min.isr=1
log.retention.hours=168
log.segment.bytes=1073741824
log.retention.check.interval.ms=300000
zookeeper.connect=zkclisvc.default.svc.cluster.local:2181/kafka1
zookeeper.connection.timeout.ms=6000
group.initial.rebalance.delay.ms=0
log4j.properties: |-
log4j.rootLogger=INFO, stdout, kafkaAppender
log4j.appender.stdout=org.apache.log4j.ConsoleAppender
log4j.appender.stdout.layout=org.apache.log4j.PatternLayout
log4j.appender.stdout.layout.ConversionPattern=[%d] %p %m (%c)%n
log4j.appender.kafkaAppender=org.apache.log4j.DailyRollingFileAppender
log4j.appender.kafkaAppender.DatePattern='.'yyyy-MM-dd-HH
log4j.appender.kafkaAppender.File=${kafka.logs.dir}/server.log
log4j.appender.kafkaAppender.layout=org.apache.log4j.PatternLayout
log4j.appender.kafkaAppender.layout.ConversionPattern=[%d] %p %m (%c)%n
log4j.appender.stateChangeAppender=org.apache.log4j.DailyRollingFileAppender
log4j.appender.stateChangeAppender.DatePattern='.'yyyy-MM-dd-HH
log4j.appender.stateChangeAppender.File=${kafka.logs.dir}/state-change.log
log4j.appender.stateChangeAppender.layout=org.apache.log4j.PatternLayout
log4j.appender.stateChangeAppender.layout.ConversionPattern=[%d] %p %m (%c)%n
log4j.appender.requestAppender=org.apache.log4j.DailyRollingFileAppender
log4j.appender.requestAppender.DatePattern='.'yyyy-MM-dd-HH
log4j.appender.requestAppender.File=${kafka.logs.dir}/kafka-request.log
log4j.appender.requestAppender.layout=org.apache.log4j.PatternLayout
log4j.appender.requestAppender.layout.ConversionPattern=[%d] %p %m (%c)%n
log4j.appender.cleanerAppender=org.apache.log4j.DailyRollingFileAppender
log4j.appender.cleanerAppender.DatePattern='.'yyyy-MM-dd-HH
log4j.appender.cleanerAppender.File=${kafka.logs.dir}/log-cleaner.log
log4j.appender.cleanerAppender.layout=org.apache.log4j.PatternLayout
log4j.appender.cleanerAppender.layout.ConversionPattern=[%d] %p %m (%c)%n
log4j.appender.controllerAppender=org.apache.log4j.DailyRollingFileAppender
log4j.appender.controllerAppender.DatePattern='.'yyyy-MM-dd-HH
log4j.appender.controllerAppender.File=${kafka.logs.dir}/controller.log
log4j.appender.controllerAppender.layout=org.apache.log4j.PatternLayout
log4j.appender.controllerAppender.layout.ConversionPattern=[%d] %p %m (%c)%n
log4j.appender.authorizerAppender=org.apache.log4j.DailyRollingFileAppender
log4j.appender.authorizerAppender.DatePattern='.'yyyy-MM-dd-HH
log4j.appender.authorizerAppender.File=${kafka.logs.dir}/kafka-authorizer.log
log4j.appender.authorizerAppender.layout=org.apache.log4j.PatternLayout
log4j.appender.authorizerAppender.layout.ConversionPattern=[%d] %p %m (%c)%n
log4j.logger.org.apache.zookeeper=INFO
log4j.logger.kafka=INFO
log4j.logger.org.apache.kafka=INFO
log4j.logger.kafka.request.logger=WARN, requestAppender
log4j.additivity.kafka.request.logger=false
log4j.logger.kafka.network.RequestChannel$=WARN, requestAppender
log4j.additivity.kafka.network.RequestChannel$=false
log4j.logger.kafka.controller=TRACE, controllerAppender
log4j.additivity.kafka.controller=false
log4j.logger.kafka.log.LogCleaner=INFO, cleanerAppender
log4j.additivity.kafka.log.LogCleaner=false
log4j.logger.state.change.logger=TRACE, stateChangeAppender
log4j.additivity.state.change.logger=false
log4j.logger.kafka.authorizer.logger=INFO, authorizerAppender
log4j.additivity.kafka.authorizer.logger=false
kafka-brokers-svc.yaml,kafka broker对外提供服务的service, kafka的每一个broker都需要客户端能够访问,因此这里不能给所有的pod使用同一个service进行代理,需要每个broker对应一个nodeport service, 可以参考下面这个例子
apiVersion: v1
kind: Service
metadata:
name: kafka-external-svc-0
spec:
ports:
protocol: TCP
port: 19092
targetPort: 31092
nodePort: 31092
type: NodePort
selector:
app: kafkasts
statefulset.kubernetes.io/pod-name: kafkasts-0