低代码渲染那些事

低代码渲染是什么?
在了解低代码渲染之前,我们先来了解一下低代码渲染是什么? 首先,我们来考虑一下,低代码是什么?
比如下图阿里内部的某低代码平台,阿里对外的低代码产品有宜搭。他们都是通过可视化,即拖拽、配置,再加上很少的代码来设计出页面。
我们可以看到它的源码是一份 json 文件,这份 json 文件相当于是一份新的语言,浏览器是没有办法进行识别的,所以我们需要低代码渲染引擎将 json 渲染到浏览器中。
低代码如何渲染?
正如烹饪一样,为了做成功一份美食,我们需要菜谱和食材,然后通过不同的处理方式,比如煎、炒、炸等烹饪方式做出来一道菜。
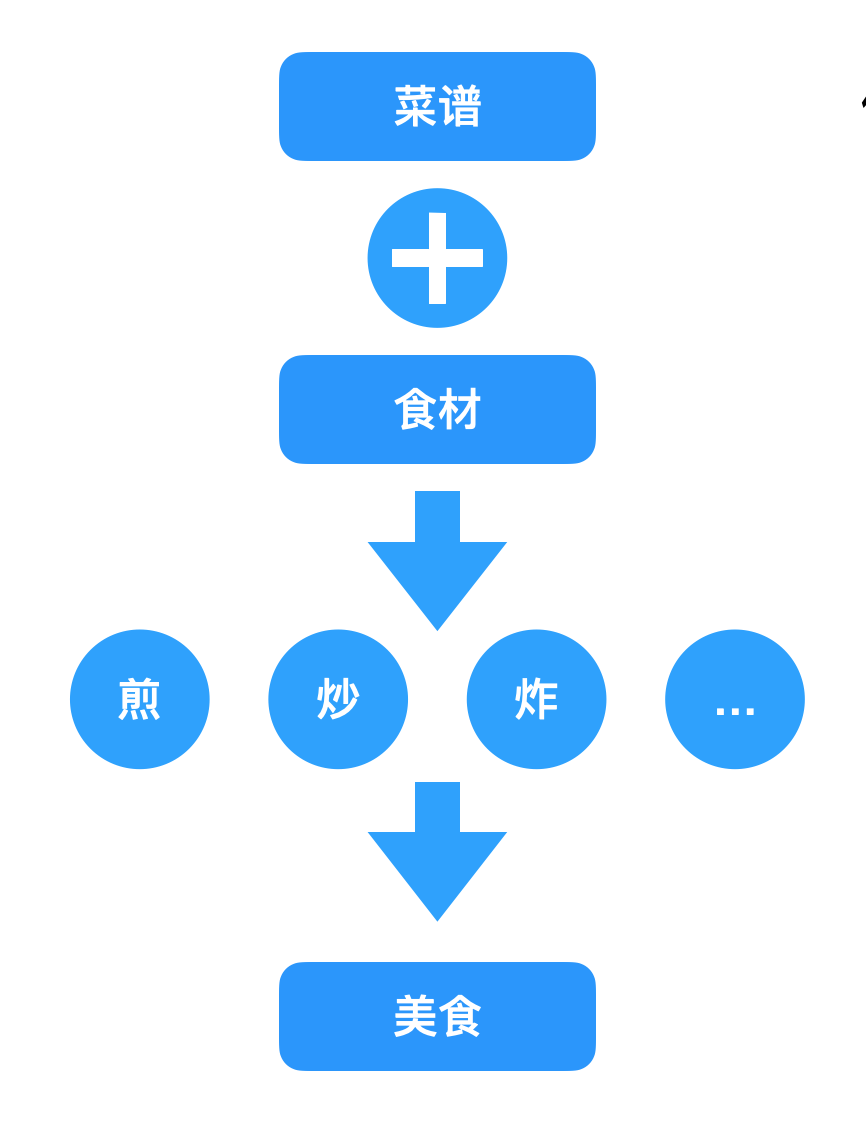
我们的低代码渲染也是有类似的公式:
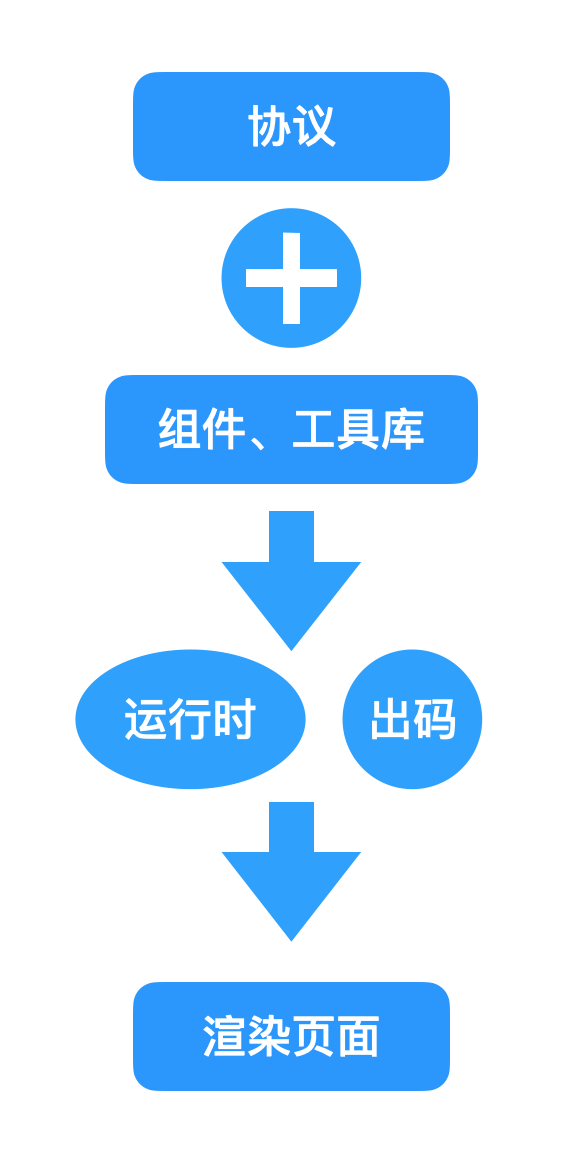
协议
其中菜谱我们可以认为这是一份标准,它保证了同样一道菜在不同地方 80% 以上的口味都是一致的。如果缺少了这份标准,很有可能在不同的地方吃到的宫保鸡丁味道、食材等都完全不一样。
而低代码相关的协议就是低代码渲染的标准,如果低代码渲染都按照这一份标准来做,可以让不同部门、团队、公司低代码解析都是一致的。这样可以方便物料、工具集等生态产物进行无障碍流通。
协议也可以理解为是 React/Vue 等 ProCode 代码和低代码 json 源码如何互相解析的说明
我们的协议有两份:
- 《低代码引擎搭建协议规范》
- 《低代码引擎资产包协议规范》
这里我们对渲染所需的几个关键的协议字段做一下介绍。
协议原文:https://lowcode-engine.cn/lowcode
《低代码引擎搭建协议规范》
componentsMap
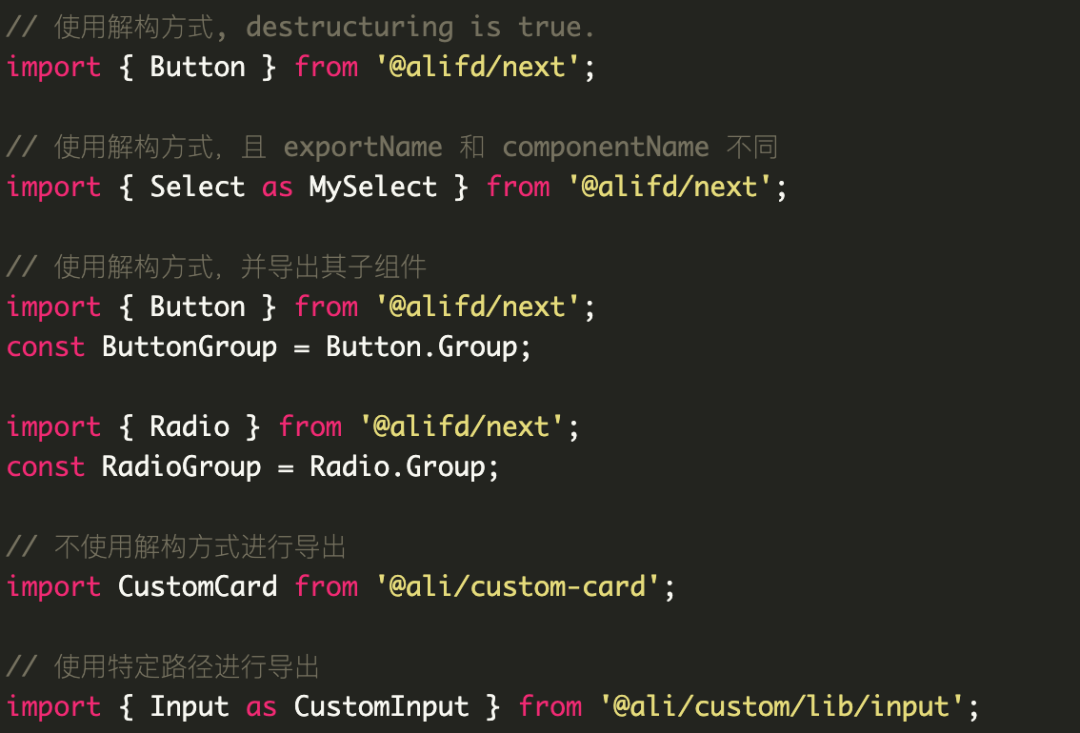
它描述的是页面用到的组件的信息,例如从 ProCode 转化为我们的 json 协议内容如图:
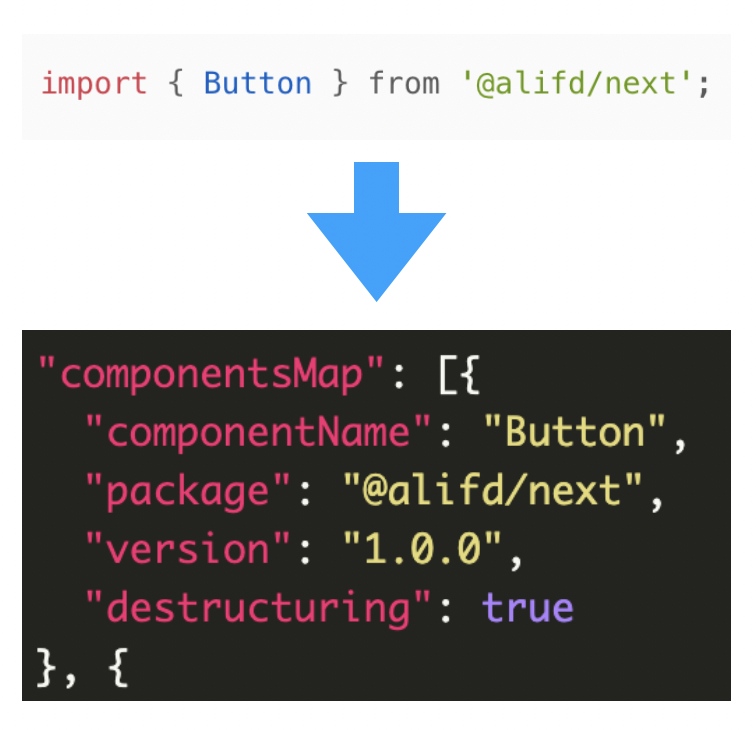
destructuring 为 true 表示我们用解构的方式来获取组件。当然我们还有其他的描述字段来保证能支持各种组件的导出方式。
utils
它描述的是页面使用到的工具类扩展信息,比如我们页面中想使用 lodash.clone 方法,那么就需要在协议中这样描述:

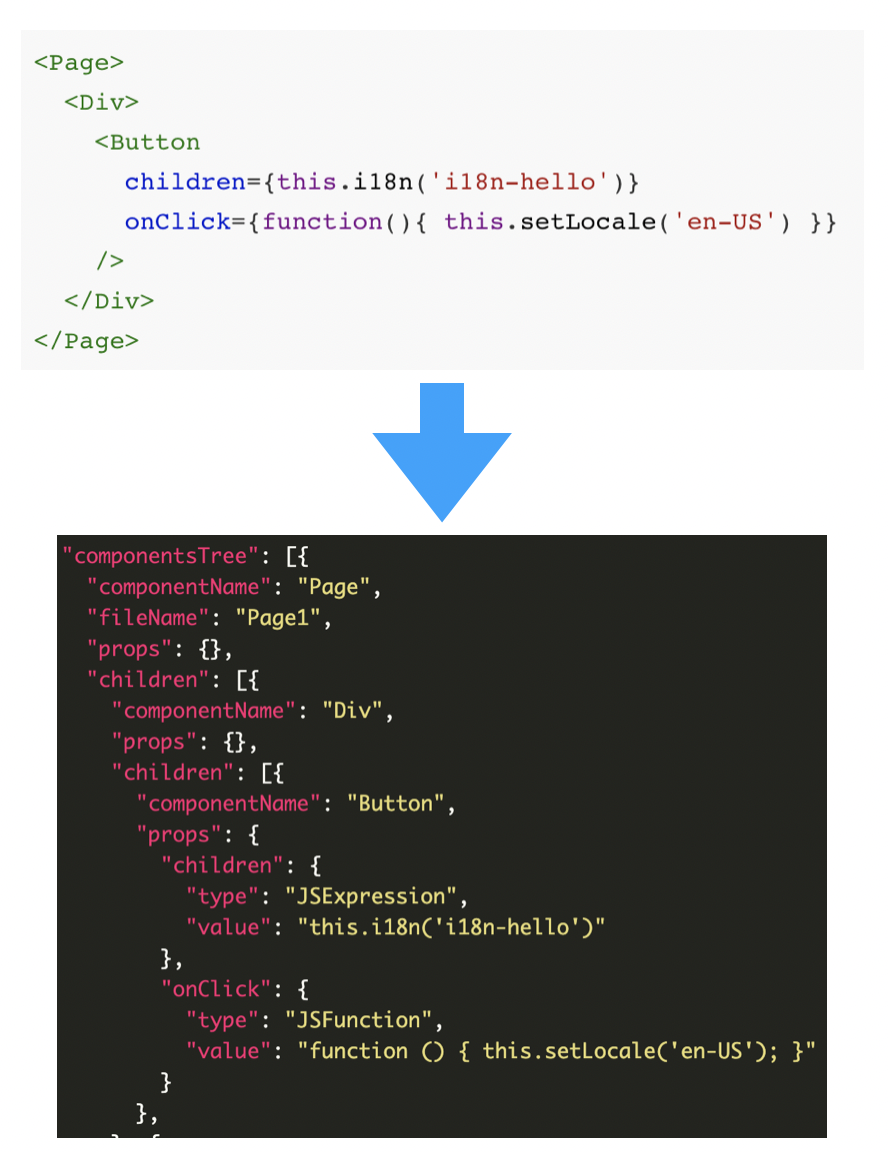
componentsTree
componentsTree 描述的是页面的组件树,主要描述的内容相当于我们写的 JSX:
《低代码引擎资产包协议规范》
搭建协议中虽然描述了组件的来源,但是我们在浏览器运行时中无法使用 npm 引入,所以我们还需要资产包协议,来帮助我们获取组件、工具集等渲染所需材料。
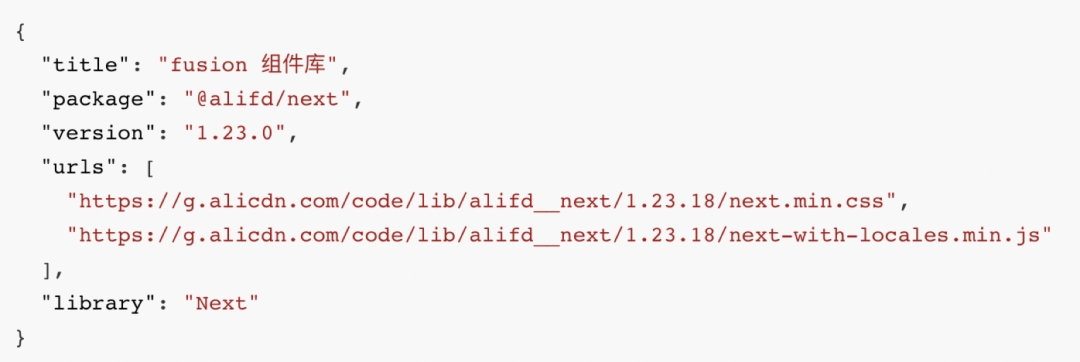
packages
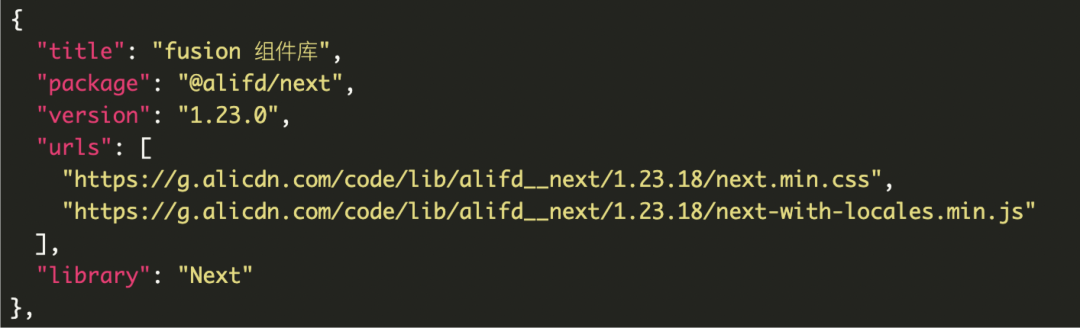
上图是 packages 的一个示例,它描述了一个组件的 urls。当我们渲染的时候,需要在浏览器中加载上述的 urls。
加载之后,我们可以通过 window.Next.Button 获取到 Button 组件,如下图所示。

大家可以在 https://lowcode-engine.cn/demo 中尝试看看我们加载了多少组件。
材料
schema
我们在设计器中进行可视化拖拽、配置实际上就是产生我们的 schema。这份 schema 就是遵循《低代码引擎搭建协议规范》的产物,每一个页面对应一个 schema。
页面资产包
根据资产包协议规范,我们需要提供一份页面/应用的资产包信息。
在阿里内部的低代码产品中的某低代码平台里面,有一个依赖管理页面,在这里我们可以新增组件,在新增组件之后进行打包构建。
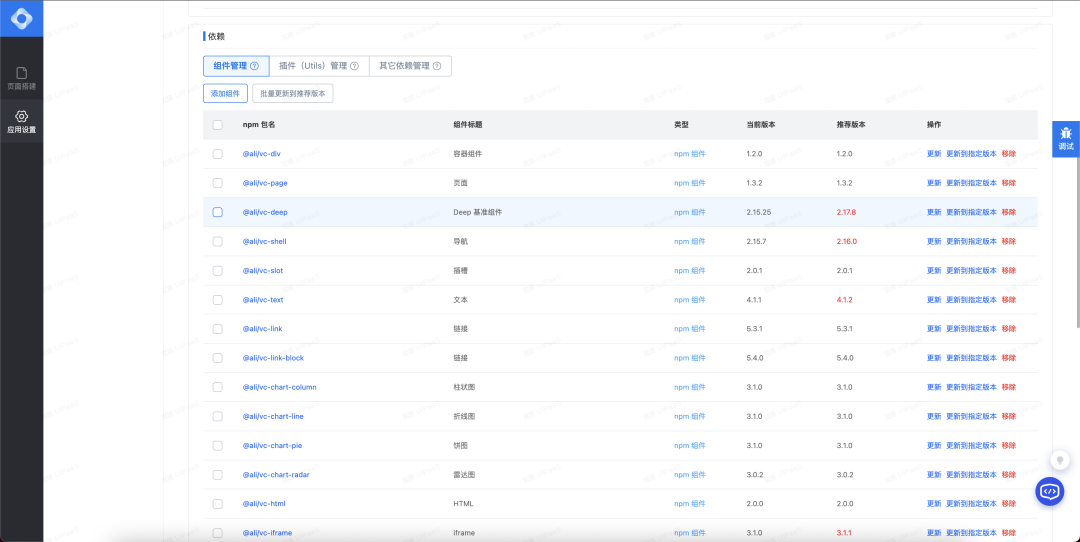
我们可以看到依赖配置信息中实际上是没有配置 urls 的,只是配置 package、version 等信息。
当我们点击打包构建时,我们会通过 package、version 等信息,将其打包成 UMD 资源,作为资产包中的 urls。

而这份 urls 会根据 package、version 进行存储并缓存,所以当我们新发布了一份 npm 包,并且进行打包构建的时候,打包构建的时间会比较长,而在第二个项目里面再添加一次,就很快了,这就是因为有了缓存,大大减少了打包构建时间。
组件和工具扩展
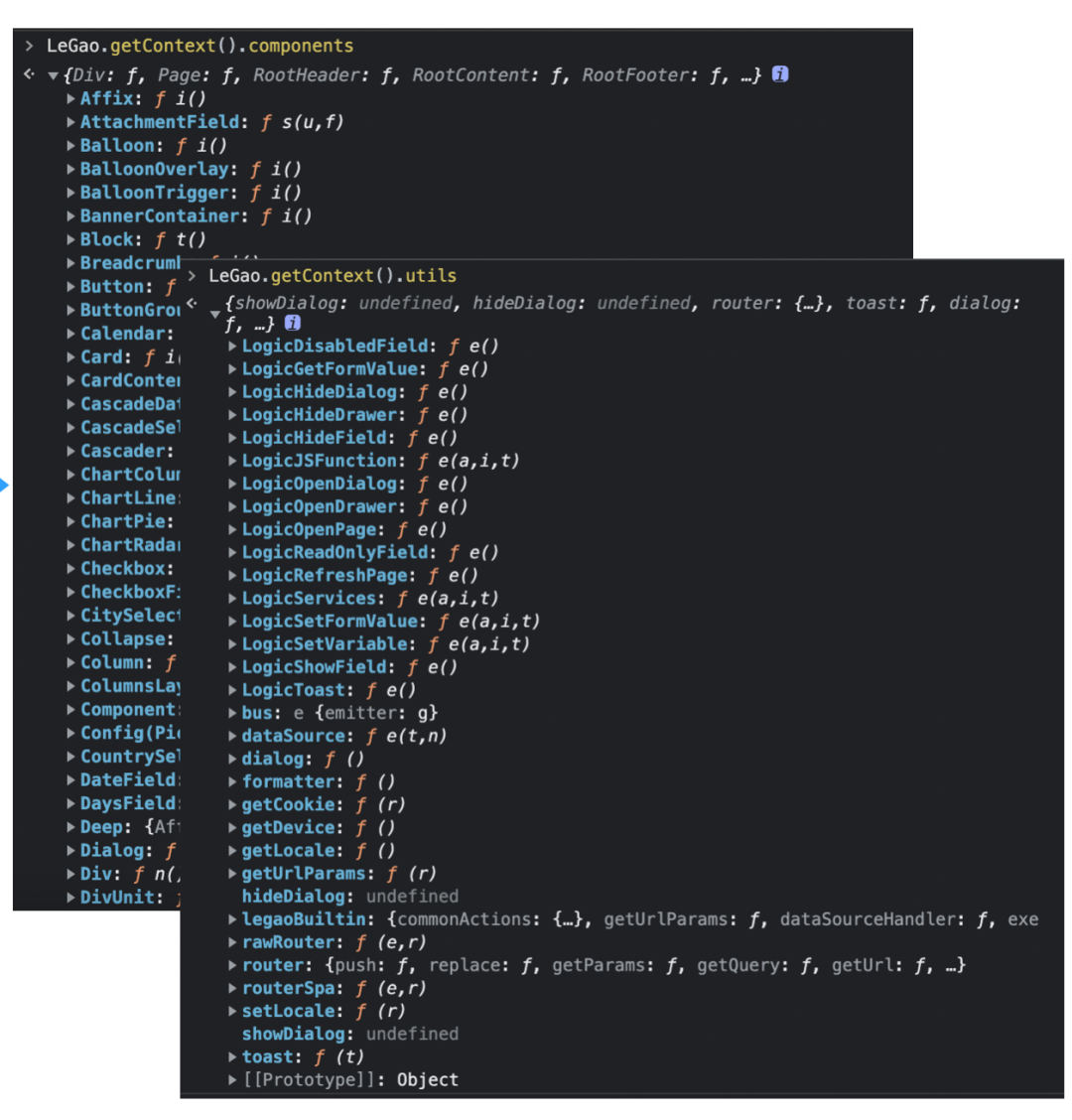
我们通过搭建协议中 componentsMap 的描述信息,可以知道 Button 组件是在 @alifd/next 中。

而通过资产包协议的 package 信息,我们就可以知道如何获取到 @alifd/next 内容,也就知道 Button 组件如何获取了。
通过这种方式,我们就可以获取到页面的 components 和 utils。
其他
我们还需要根据我们使用的技术栈,在 html 中提前加载 react/rax 相关依赖的资源。

如果是图表组件我们也需要加载 highcharts 资源。

当然还有很多更多的资源,可以根据情况进行引入。
渲染方式
渲染方式主要有两个大类:
- 出码渲染
- 运行时渲染
其中在阿里内部大多数低代码平台中,我们主要使用的都是运行时渲染,包括宜搭低代码产品,只有少部分对性能要求较高的产品才会使用出码渲染的方式。
出码渲染
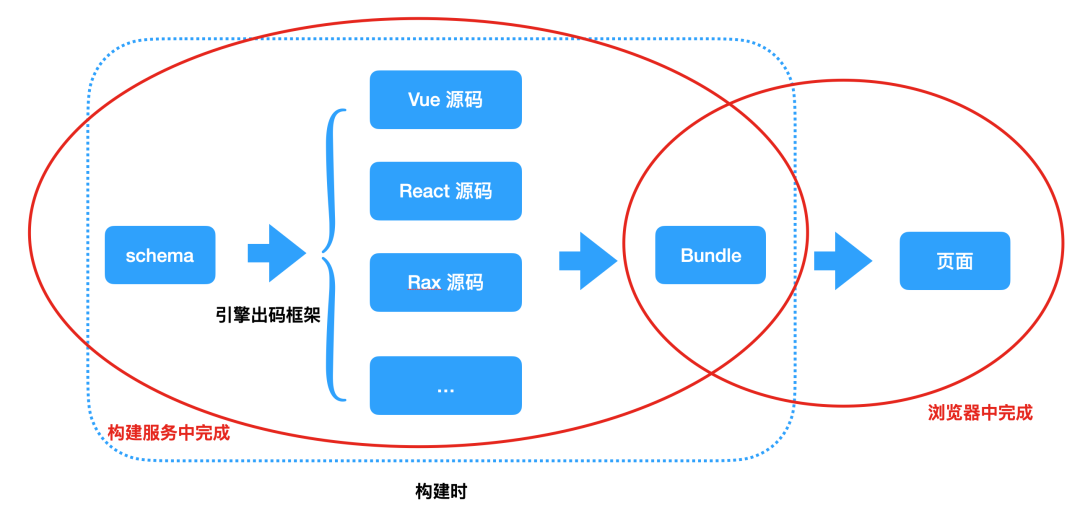
出码渲染是将 schema 转化为 Vue 源码、React 源码或者其他语言的源码。当然就像 React 工程需要进行打包构建才能在浏览器中渲染一样,我们会将 React/其他源码进行打包,打包成一份 Bundle 文件,之后就可以在浏览器中进行消费,渲染出页面了。
以上的过程大多数都是在构建服务中进行的,而 Bundle 渲染为页面是在浏览器中完成的,这一部分本身都是依赖市面上成熟的前端框架,比如 React、Vue 等,所以这时候在浏览器的运行时已经不存在低代码渲染了。
下面是某个页面的 schema 转化为 React ProCode 的示例:

这里对出码渲染就不做过多的介绍了,有兴趣的小伙伴可以去看看低代码引擎中的出码模块。
运行时渲染
运行时渲染和出码渲染的主要区别在于,页面 schema 渲染成页面都是在浏览器中完成的,不存在预编译的过程。
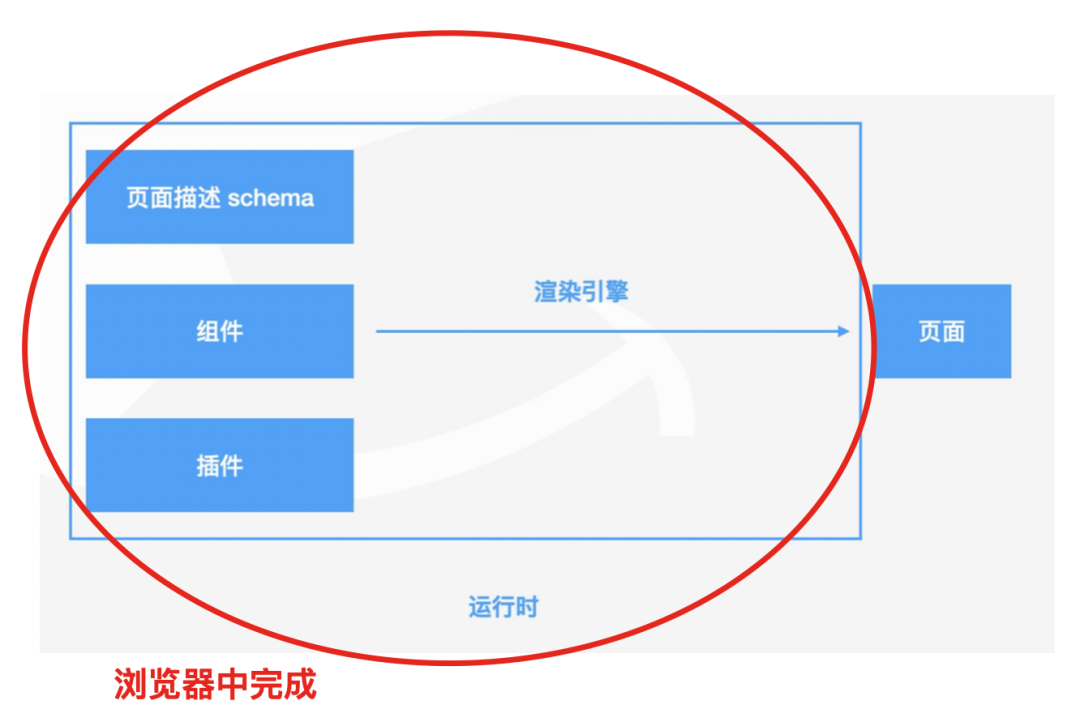
运行时渲染详解
这里我们就运行时渲染进行详细的介绍。
渲染能力概览
渲染能力就是我们根据协议的内容,在运行时渲染引擎上支持的能力。
比如我们要渲染的一个页面,可以把它解析成一个树状结构,而其中的最底层的节点就是我们最小粒度的组件。
对于这个组件,我们需要支持的能力主要是: 1) 获取源码组件 2) 解析组件的 props 3) 获取组件的 children 4) 保留并传入上下文,包括循环上下文,插槽上下文等; 5) 节点更新,当参数变化时需要更新对应的节点 6) 节点循环处理 7) 获取节点实例并进行存储 ...... 而比组件更大的一个纬度来说,也就是页面的渲染,而他们的能力需要: 1) 页面生命周期的生成和执行; 2) 页面内组件树描述生成,并递归处理单个组件; 3) 页面上下文生成,比如数据源 State、低代码组件的 Props 等。 4) 页面 API 支持; ......
组件渲染
获取源码组件
通过 Node 的 componentName 和之前获取到的 components 就可以获取到 React/Rax 的源码组件。上面的渲染所需材料获取的模块已经介绍过了。
解析 props
为了实现所有的搭建场景,我们的 props 有几种解析方式:
1.参数是确定的值
配置的值是确定的,比如确定的 text 文本。
{
"componentName": "Text",
"id": "node_ocl45bcwsy1",
"props": {
"content": "文本",
},
}2.参数是需要计算的表达式
配置的值根据数据源进行变化的,比如说 text 文件需要根据 state.text 进行计算的场景。
这里会用 type:JSExpression 来描述需要计算的表达式。
{
"componentName": "Text",
"props": {
"content": {
"type": "JSExpression",
"value": "state.text"
}
}
}3.参数是函数
参数是作为函数传到组件中,比如说 Button 组件配置的 onClick 事件、onChange 事件等。
这里会用 type:JSFunction 来描述函数。
{
"componentName": "Text",
"props": {
"onClick": {
"type": "JSFunction",
"value": "this.onClick",
},
"onChange": {
"type": "JSFunction",
"value": "function() { this.setState({ text: 'new Text' }) }",
}
}
}4.参数是 React/其他框架的节点
协议中还描述了某一种属性作为 ReactNode 渲染的情况,这时候组件渲染的内容不是 children,而是这个组件的某一个参数。
其中 type 为 JSSlot 就是描述这种情况的参数格式。
{
"componentName": "Card",
"props": {
"title": {
"type": "JSSlot",
"value": [{
"componentName": "Icon",
"props": {}
},{
"componentName": "Text",
"props": {}
}]
},
}
}上面代码中的 Card 中的 this.props.title 在 React 渲染引擎下就会解析成 ReactNode。
获取组件的 children
通过递归处理即可获取其 children,下图是其伪代码。

处理节点更新机制
当数据源变化的时候,我们需要对页面进行更新,主要有两种更新方式,全量更新和增量更新。
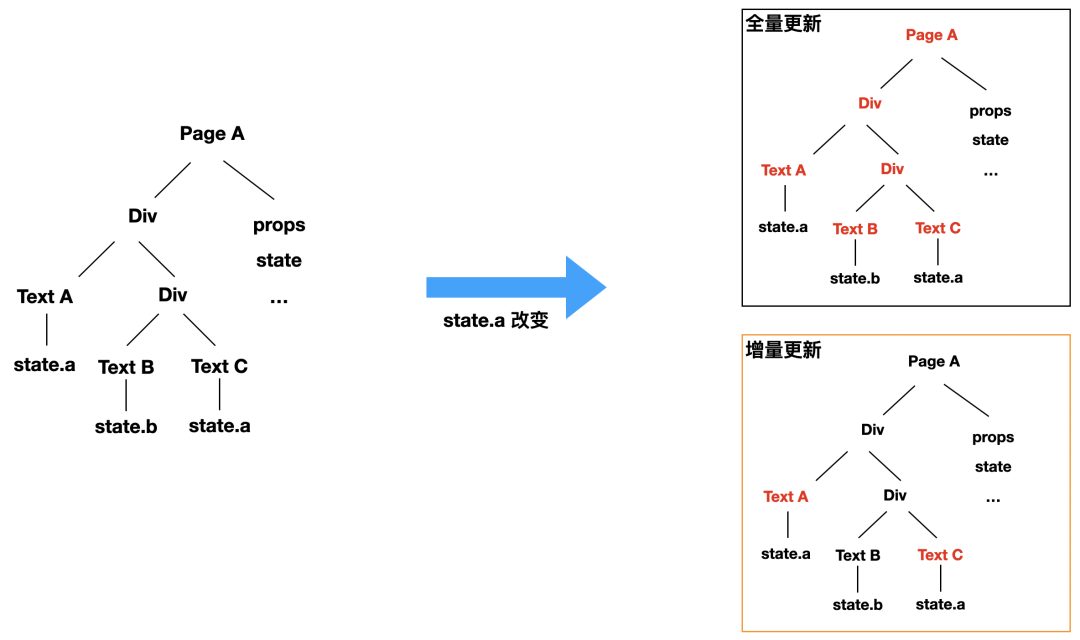
1、全量更新
全量更新就是只要数据源发生变化,我们就从页面的顶层节点,也就是 Page 开始从头开始再次进行计算、递归子元素并对 props 进行计算。也就是每一个节点都会重新计算和渲染。
这样的好处的是处理比较简单,而坏处就是由于多了不必要的计算和渲染,在性能上较差,特别是如果节点比较多就会出现明显的卡顿。
2、增量更新
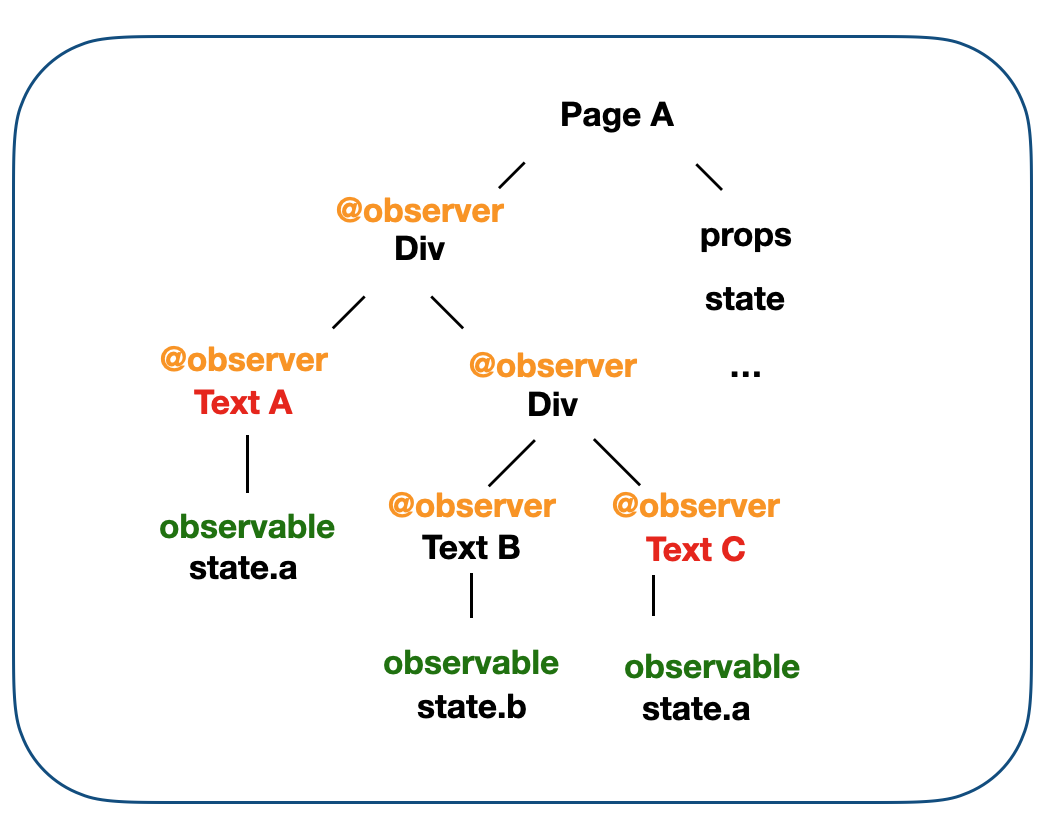
增量更新是找到用到这个数据源的组件才进行更新,也就是上图中的 TextA 和 TextC。
我们实现的方式就是利用了 mobx,如下图所示我们将 state 和 props 进行 observable。并对每一个组件都进行 observer 观测,当组件用到的 state 或者 props 产生变化的时候,mobx 会控制其进行更新。
处理节点循环
由于在循环的场景中,循环的组件和其子组件需要通过 this.item 和 this.index 来获取循环的索引和循环的值。
所以我们在节点循环的时候,我们需要计算循环的值,并将循环的值,作为当前节点和节点的 children 的 scope 来解析。
处理节点实例
当我们配置了组件的 ref,我们就可以通过 this.$(ref) 来获取组件实例。
在 React 中,我们主要是直接利用组件的 ref 参数,来获取到组件的实例,并将其存储到渲染引擎的上下文中。
页面渲染
执行页面生命周期
在搭建协议中,定义的生命周期方法主要是 React16 的标准生命周期方法,对于 React 的渲染引擎来说,只需要在合适的时机调用相关生命周期方法即可。 而对于其他语言的渲染引擎,我们就需要根据情况,在其类似的生命周期中调用 schema 中的生命周期方法。比如 Rax 技术栈的渲染引擎,由于没有类似的生命周期,所以使用 hooks 来替代对应的生命周期;当然对于使用者来说是感知不到差别的。
递归解析组件树
下面是其递归组件树示例的一个伪代码。
fuction renderNode(node) {
if (!node) {
return null;
}
const React源码组件 = components[node.componentName];
const props = compute(node.props);
const children = node.children.map(d => renderNode(d));
return React.render(React源码组件, props, children);
}
renderNode(schema)而在递归之后,我们就可以按照组件的渲染逻辑,对单个组件进行渲染了。
递归处理组件,按照前文提到的组件渲染相关的逻辑对每一个组件进行处理。就可以按照组件树的层级关系将其绘制到浏览器上。
页面上下文生成
上下文、状态和数据管理和层级以及包裹的组件是有关系的,其中页面下的组件,使用的是页面的上下文、数据和状态。在页面包裹的区块下的组件,优先使用区块下的上下文、状态和数据,如果区块中不存在,这时会去页面上下文、状态和数据中寻找。
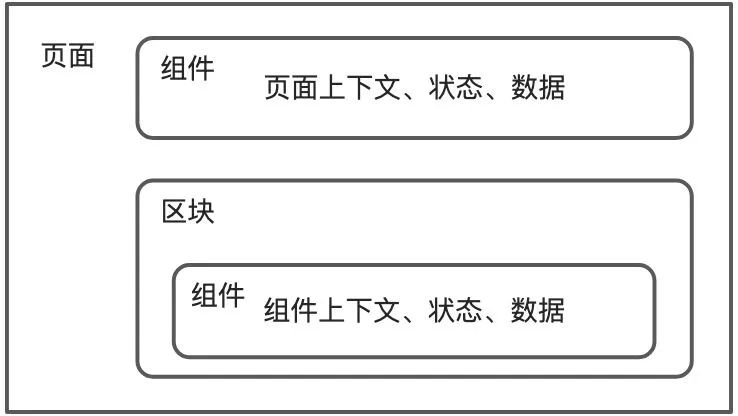
上下文、状态和数据管理使用的是 proto 来实现的。当进入区块时,会新建区块数据和区块上下文,并使用 proto 来继承页面上下文和页面数据,这样就可以在区块中优先使用区块的数据和上下文,当区块中没有的时候,会向页面数据和上下文中查找。整体逻辑类似下面的伪代码:
// 页面上下文
var content = {
a: '1',
b: '2',
};
// 页面数据
var state = {
a: 'a',
b: 'b',
};
function Block1() {
// 区块上下文
var blockContent = {
a: '3'
};
blockContent.__proto__ = content;
// 区块数据
var blockState = {
a: 'c'
};
blockState.__proto__ = state;
// 区块内组件使用
console.log('区块内组件 a', content.a, state.a);
console.log('区块内组件 b', content.b, state.b)
}
// 页面内组件使用
console.log('页面内组件 a', content.a, state.a);
console.log('页面内组件 b', content.b, state.b)
Block1();输出结果如下:

实现上述的几个逻辑,就可以完成一个最简单的运行时低代码渲染引擎了。
运行时渲染体系现状及规划
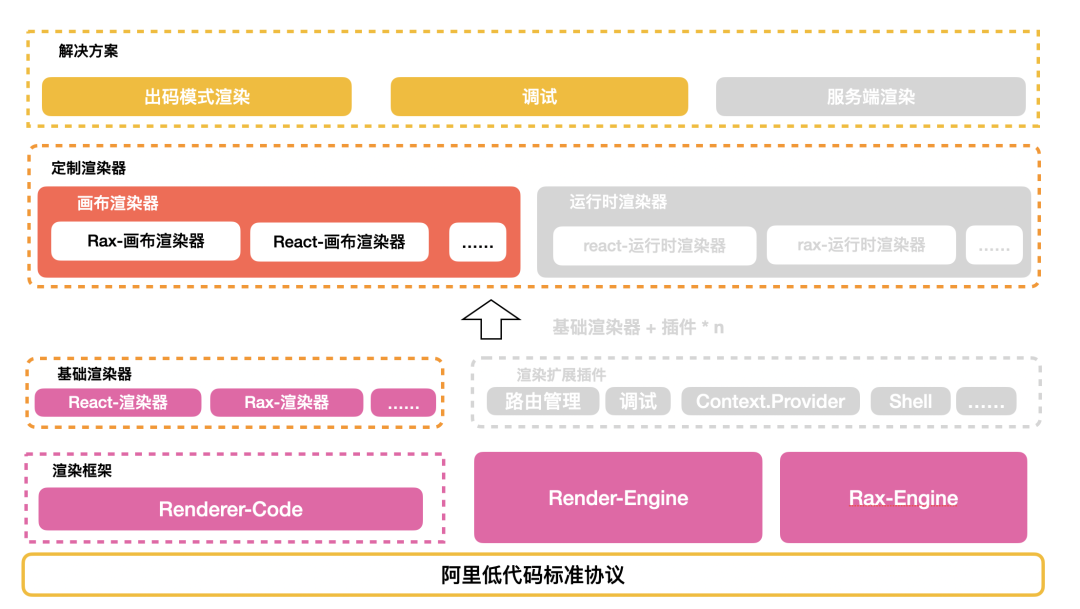
目前我这边维护的运行时渲染框架主要有三套:
- lowcode-react-renderer 和 lowcode-rax-renderer :是低代码引擎(lowcode-engine)提供的低代码运行时渲染能力,其底层使用的是 renderer-core。
- Render-Engine:是集团内部的基于 React 运行时的低代码渲染引擎,支持应用级别的渲染,包括导航、登陆等应用级别的渲染能力。
- Rax-Engine:也是应用级别的渲染能力,运行时框架依赖的是 Rax。
痛点-维护成本高

解决方案
而三套独立的运行时渲染框架导致我们的维护成本是大于 3 的。基于这个原因,在后续的迭代中我们会将通用能力下层,而他们之间的差异能力通过插件化来适配。

痛点-调试困难
这个痛点是来自低代码平台的使用者。

大多数看到这个问题的就是应用的开发人员,但是就算是开发人员,当遇到这个报错了也还是比较懵逼的,无从下手。这导致低代码平台的答疑成本一直比较高,而低代码使用者在使用低代码平台的时候体验也会很差。
另外当遇到这个报错时,只有使用浏览器调试才能解决问题,这就导致了低代码研发人员必须要有一部分的前端研发能力,导致低代码产品的使用人群无法进一步扩大。
解决方案
通过研发低代码渲染调试能力,来帮助低代码平台的使用着解决相关问题。相关解决方案即将在掘金大会上进行线上直播分享,主题是《基于 LowCodeEngine 调试能力建设与实践》
未来规划
最后我们的运行时渲染体系架构最终会实现成这样。
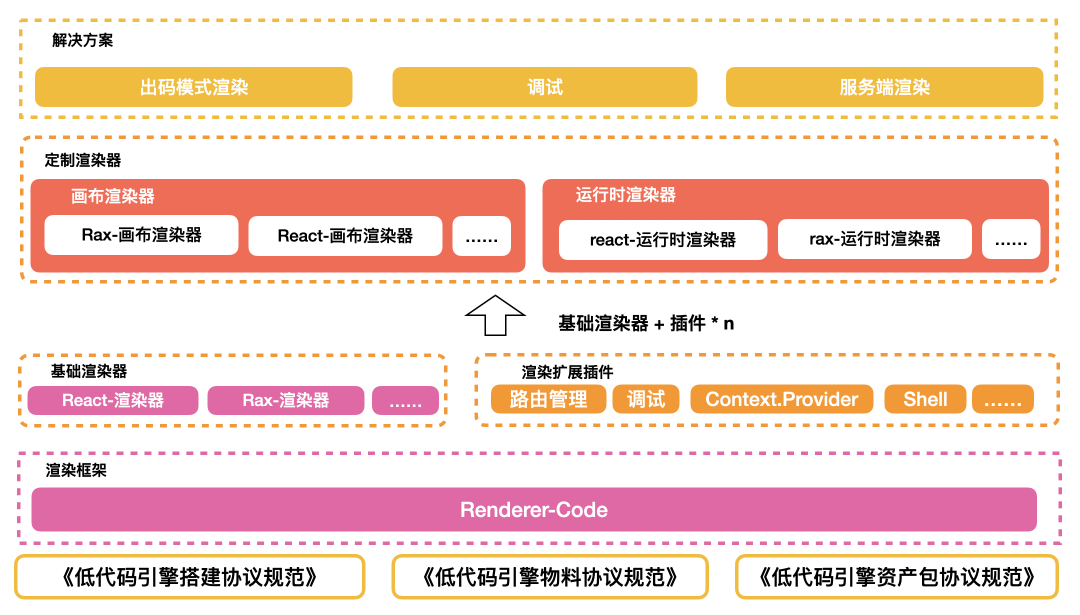
在低代码引擎标准协议的基础上,将运行时的通用逻辑进行下沉到 Renderer-Core 中,并基于它实现 React 渲染器和 Rax 渲染器。其他差异性的运行时渲染能力比如画布渲染、应用渲染等通过扩展插件来实现。
而在解决方案上会将一部分完善低代码调试能力、也会提供服务端渲染能力解决运行时渲染能力的性能瓶颈。