【连载】1.1 监控系统概述
这套连载课程,纵观整个行业的解决方案,做出横评对比,然后以夜莺监控系统为蓝本,介绍一个监控系统的方方面面。学习完本课程,会对监控系统有个非常全面的认知。适合人群:DevOps工程师、SRE、研发工程师。作者有10余年DevOps研发经验,8年监控系统开发经验,所以本课程不止讲解操作,还会讲解很多原理,欢迎持续关注。
监控概述
监控系统到底是解决什么问题的?大家通常所谓的监控系统,其实只是可观测性三大支柱之一,何为可观测性三大支柱?作为支柱之一的指标监控系统,具体有哪些特点?本章重点来回答这些问题。
需求来源
最初始的需求,其实只有一句话,就是系统出问题了我们能及时感知。当然,随着时代的发展,我们对监控系统提出了更多的诉求,比如:
- 通过监控了解到趋势,知道系统在未来的某个时刻可能出问题
- 通过监控了解系统的水位情况,可以在资源不足的时候及时扩容
- 通过监控来把脉系统,感知到哪里需要优化,比如一些中间件的参数的调优
- 通过监控来洞察业务,知道业务发展的情况,业务异常了也能及时感知
监控系统的重要性越来越高,不但可以解决上面这些诉求,还能沉淀知识,沉淀在监控系统中的稳定性相关的知识,可能要比很多工程师的大脑更为丰富。当然,这得益于对监控体系的持续运营,特别是一些资深工程师的持续运营成果。
可观测性三大支柱
我们通常所谓的监控系统,其实只是指标监控,体现在图表上的一条折线图,比如某个机器的CPU利用率,或者某个数据库实例的流量,或者网站的在线人数,都体现为随着时间变化的一条线,比如:
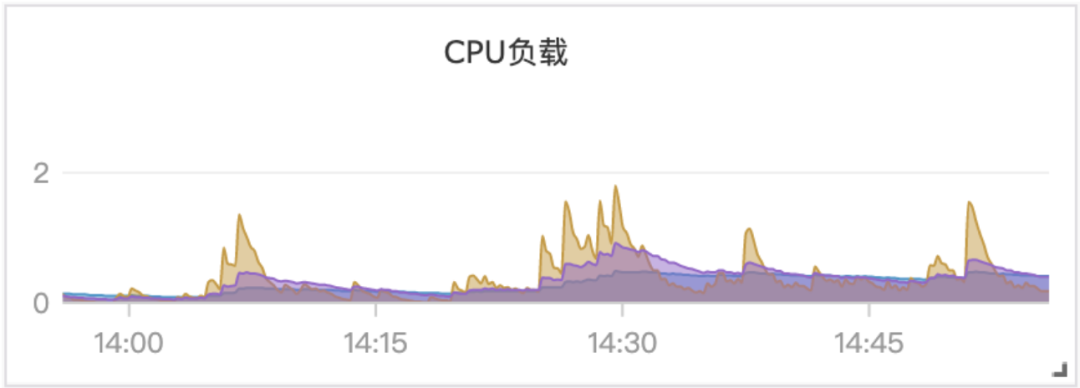
除了指标监控,另一个重要的可观测性支柱,是日志。从日志中也可以得到很多信息,对于了解软件的运行情况、业务的运营情况,都很关键。比如操作系统的日志、接入层的日志、服务日志,都是重要的数据源,从操作系统的日志中,可以得知很多系统级的事件发生了,从接入层的日志中,可以得知有哪些域名、IP、URL 收到了访问,是否成功以及延迟情况等,从服务日志中可以查询到 Exception 的信息,调用堆栈等,对于排查问题,非常关键。
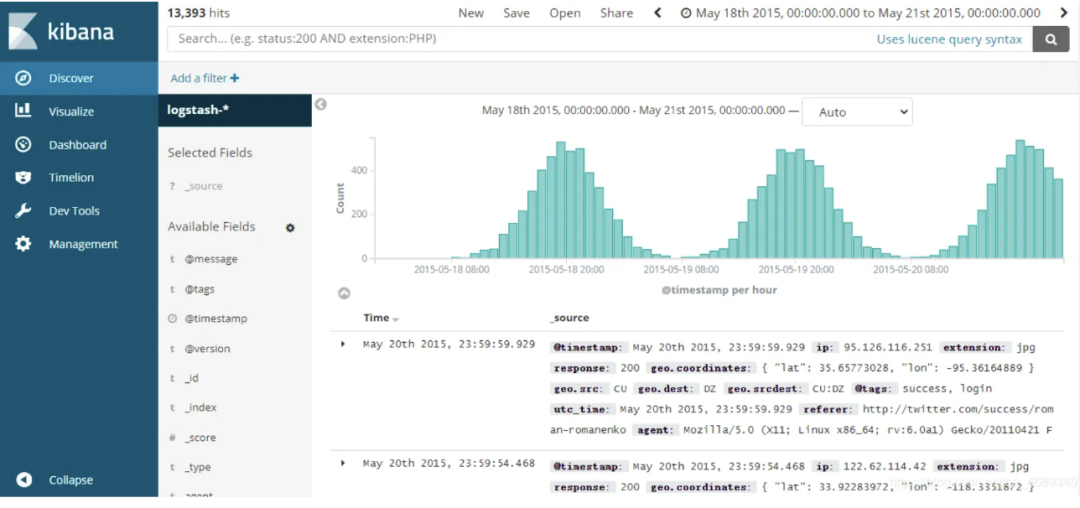
处理日志这个场景,也有很多专门的系统,开源产品首推ELK,商业产品比如 Splunk、Datadog 等,下面是ELK中查询日志的一张截图:
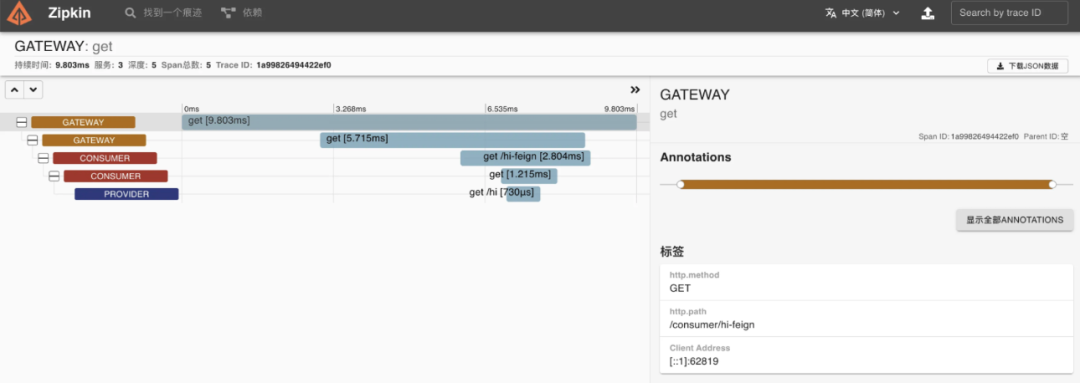
链路追踪的思路是,以请求串联上下游模块,为每个请求生成一个随机字符串作为请求ID,服务之间调用的时候把这个ID逐层往下传递,各层分别花费了多久时间,是否正常处理,都可以收集起来附到这个请求ID上,后面追查问题时,拿着请求ID就可以把串联的所有信息提取出来。链路追踪这个领域也有很多产品,比如 Skywalking、Jaeger、Zipkin 等,都是个中翘楚。下面是Zipkin的一张截图:
指标监控产品特点
我们重点探讨的是指标监控,不讨论日志和链路追踪,要了解指标监控,首先要了解何为指标,说白了,指标就是衡量目标的数值。比如 Linux 操作系统,我们可以从多个方面去衡量它的负载情况,比如 CPU 的使用率方面有 cpu_usage_system(CPU内核态时间占比)、cpu_usage_user(CPU用户态时间占比)、cpu_usage_idle(CPU空闲时间占比) 等指标,内存方面则有 mem_available_percent(内存可用率)、mem_used(内存使用量)等指标,磁盘方面则有 disk_used_percent(磁盘使用率)、diskio_write_bytes(磁盘写入量)等指标。
一般,会在OS内安装一个客户端软件,作为一个常驻进程运行,按照一个固定的频率来采集(比如15秒),采集到数据之后,发给服务端存储和分析展示。
故而,指标监控的几个特点:
- 一般只处理数值数据,不处理字符串(个别监控系统也可以处理字符串,大部分都不处理)
- 指标数据是时序数据,每隔一个固定的间隔就采集一次,把采集到的数据上报,永不停歇
- 指标数据是采样数据,比如15秒采集一次,只能拿到采集的那一时刻的数据,如果把采集频率调小,可以获取更丰富的更精确的数据,但是代价会更大,需要更多存储,更多算力来处理,实际生产环境,30秒或者60秒就够了,如果对精度要求高,15秒就够了,再小的频率,意义不大,因为监控数据的核心是感知异常和感知趋势,如果出现异常,一般异常会持续一段时间,偶尔的异常通常也不需要关注,所以采样数据通常也可以感知到异常,而对于趋势,如果查看的时间越大,采集频率可以越大,如果看1小时的数据,15秒一个点是可以的,如果看1年的数据,每小时一个点的频率也完全够用,太多的数据点,可能会把浏览器打爆
- 因为是处理的时序数据,每个值都带有一个时间戳,这种数据很有规律,行业内出现了专注于这类数据处理的数据库,称为时序数据库,比如InfluxDB、VictoriaMetrics、M3DB等,监控系统依赖一个时序数据库,也就变成了一个典型的架构特点
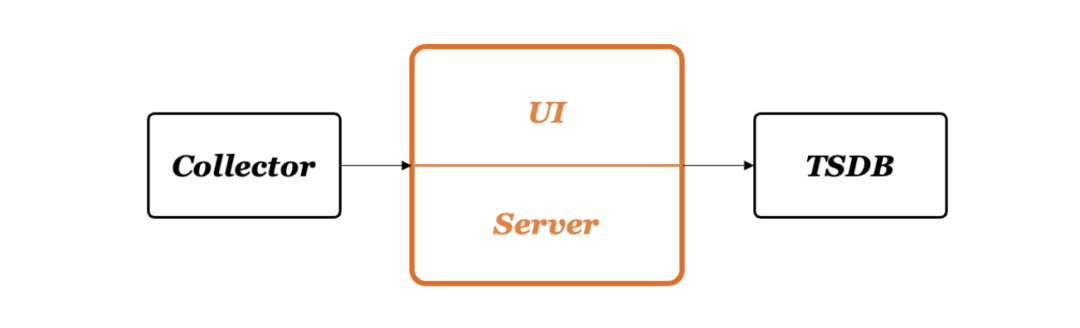
架构上来说,指标监控系统除了依赖一个时序库,还必然需要一个采集器去采集各种指标数据,其次就是告警引擎和可视化展示,典型的系统架构如下:
本章就介绍到这里,后面的内容会在下面的号里持续更新,欢迎大家持续关注。