公有云网关接入高性能探测器方案
以下内容来自腾讯接入架构师gengmin
在腾讯公有云业务中,需要用到探测器,场景如下:
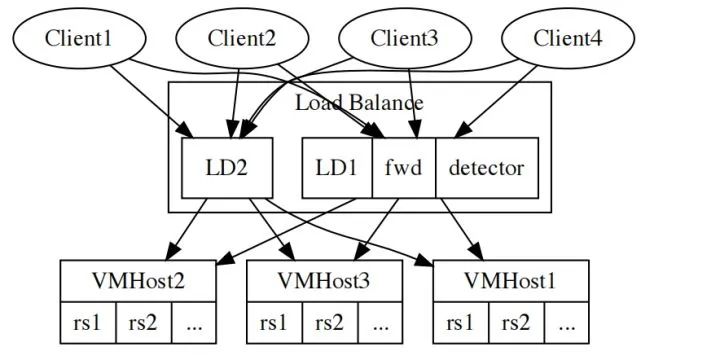
vmhost上的子机real server,LB集群由多个实例LD组成,每台LD内部进程fwd负责调度real server,转发client发出的请求。调度之前,需要确认real server是可调度的,这就是探测器的工作内容。
随着单集群后端的rs数量增加,达到百万级,千万级,探测器所负担的探测任务也会随之增加,但是LD作为一个整体,探测器能分到的资源是有限的,cpu和网卡是最主要的两项资源。
cpu建立大量的连接,这些连接需要在短时间内完成探测,比如LD实例上,绝大多数cpu资源都给fwd用于转发业务,cpu资源是受限的。网卡大量的连接会占用网卡的资源,进而影响本地业务的流量,由于内核协议栈工作在软中断上下文,放任报文进入危及系统稳定 > 本地业务的影响是双向的,本地业务的配置也会影响探测流量,比如iptables,一旦出问题需要都能把握。
本文描述了解决上述问题的完整方案:
kernel-bypass的协议栈 这种大量并发连接的问题,用kernel协议栈是行不通的,对应到服务端是C10M问题,客户端也需要用类似的kernel-bypass的方式来处理报文,配合用户态协议栈。
报文队列 为了适应不同的环境,报文处理被抽象成一个队列,通过recv收包,xmit发包,框架层处理掉2层细节,recv/xmit处理3层报文。
- 框架层封装多种不同的
kernel-bypass机制: - - 基于
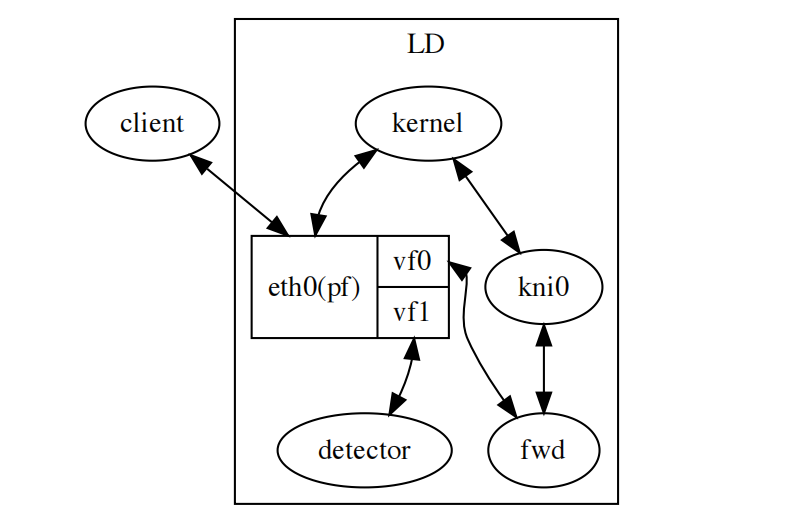
SRIOV技术的 dpdk switch representation - 这种技术将一个物理网卡虚拟出多个
function,dpdk能够工作在vf之上,接管网卡处理报文,充分利用网卡的硬件加速能力。
- - 基于
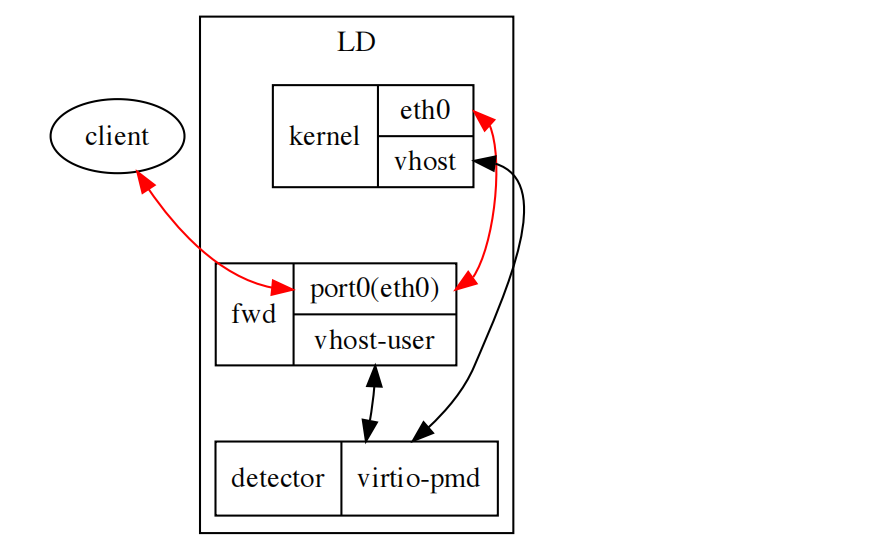
virtio的 virtio-pmd - 当不支持
SRIOV的环境下也需要探测,此时使用vhost-user/vhost+virtio-pmd的virtio-networking方案,相比硬件方案性能会差一些,但是逻辑完全一致。
- - 基于raw socket的evloop
- 在资源受限的低配环境,也可以
kernel-bypass,此时使用raw socket收发报文。这种情况主要的考量是避免影响本地业务,占用系统资源,以及受系统配置影响等等。
- 其他 kernel-bypass技术
netmap,af_xdp等等
- 用户态协议栈
用户态协议栈不稳定是人所共知的事实,考虑我们的场景,与其谈论选择哪个用户态协议栈,不如使用一个简化的自研协议栈。
- 协议栈简化
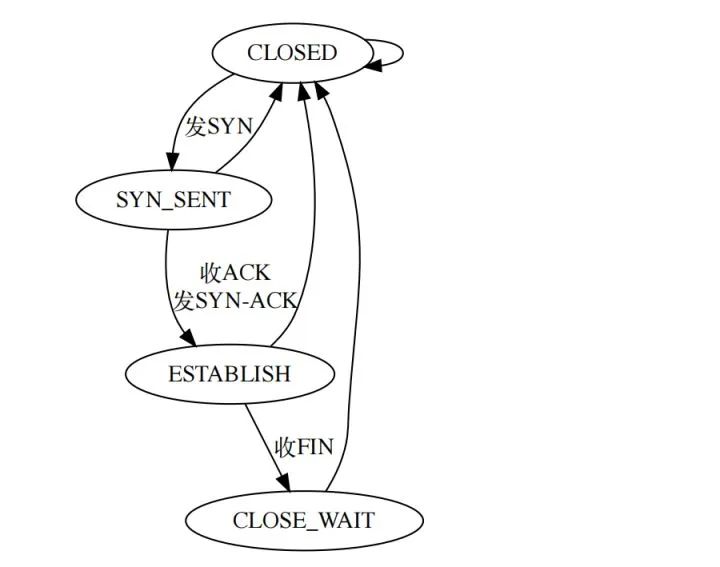
探测应用是一个客户端,那服务端和会话相关的逻辑都是不需要的,只需要实现最基本的状态机,1000行左右,又快又简单又稳定。
TCP状态机,仅保留CLOSE,SYN_SENT,ESTABLISH,CLOSE_WAIT这四个状态:
- 收发包API调整
平常使用的socket API沿袭了文件读取思路,在性能上有所欠缺,必须先复制出来再处理:

对epoll而言,系统调用读取数据无法避免,uring虽然可以一定程度避免数据复制的动作,但是从数据准备好到应用实际使用数据存在一个时间窗口,这段窗口期,cache可能已经刷出,特别是大量数据的时候 为了获得最大的性能,这里使用基于回调的做法,当数据准备好之后,做好预取直接处理数据:

socket只会在一个core上工作,业务只做策略。
- 高性能IPC
当我们考虑RS规模,探测器会频繁向外传递探测结果,外部也会频繁对探测器执行调整,为了支持对探测器实施有效的控制,执行数据交换,需要一套高性能的IPC作为支撑。
- 封装层
考虑到我们使用的kernel-bypass技术,需要拆分逻辑线程,以便允许支持一快一慢和<span style="font-size: 14px;">两个慢速这两种不同模式。
这里的快速逻辑指的是busyloop这种无系统调用的做法,慢速逻辑则是和内核通过系统调用交互的做法,相对而言,系统调用很慢,达到了us级。
因为我们要执行IPC,所以一定有一个慢速逻辑,但是快速逻辑,则需要具体环境,比如引入了基于dpdk的技术才会用到,这两者之间的差异,通过引入一个ring消除:
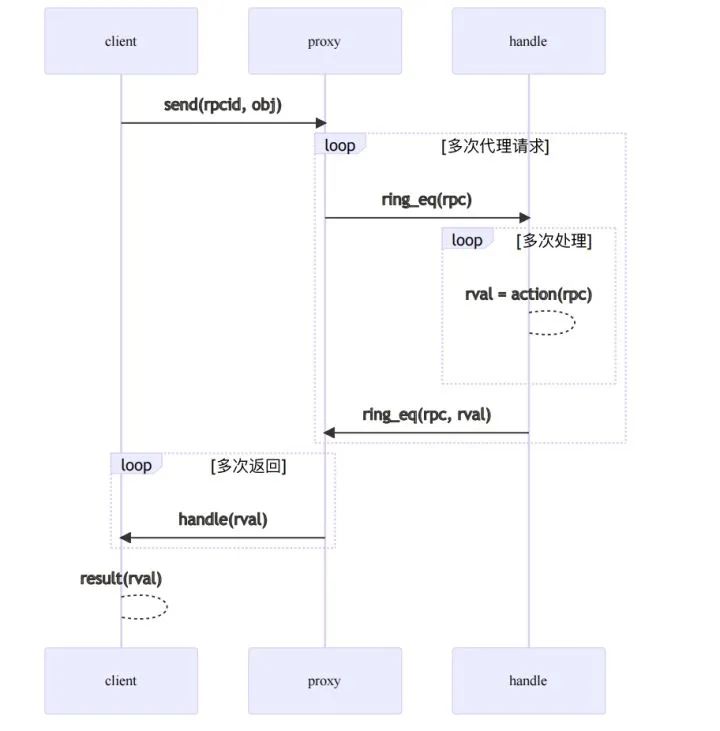
proxy表示慢速线程,作为一个syscall proxy,基于libuv框架执行异步并发循环,开销随着任务量伸缩 handle表示业务线程,当引入dpdk之后,就是一个独立的内核可调度线程,否则就和慢速线程分时复用相同线程
两个逻辑通过ring进行交互,handle具体使用的哪种kernel-bypass技术不会影响整体逻辑。
- 无锁化
慢速逻辑之所以叫proxy,另外一层意思是它只处理系统调用上下文,所有业务对象都传递给handle,所有实际工作都在handle内分时完成,这样就能确保无锁顺序执行。
这里的无锁化的意义是去同步,避免proxy和handle发生阻塞,从而跑满IPC带宽。
- 向量批处理
client到proxy这一段主要的优化是内存管理和减少系统调用次数。
正常进行对象传递时,需要先传递对象size,然后接收方分配缓存,核查缓存已经接收完毕,然后提交到应用,具体像下面这样:

size,预分配内存,聚合处理:

IPC借助libuv框架,允许多个client并发执行请求,每个请求可以包含多个对象,在handle内顺序处理,因为慢速逻辑proxy会比handle慢得多,handle在处理完报文之后,还有空闲cpu用来处理proxy的请求。
如果当前handle特别忙的时候,整个系统达到瓶颈,proxy被阻塞,进而阻塞client 如果当前handle空闲,proxy达到瓶颈,client被阻塞
大多数情况,瓶颈会在proxy,假定一次syscall花费1us,则proxy上限为100wcps。
当IPC模式为N次请求N次返回,正反都占用syscall,上限为50wcps。
当IPC模式为N次请求0次返回,或者1次请求N次返回,只有单向占用syscall,上限为100wcps。
进一步提高cps的措施就是上面说的向量化批处理,提高批处理的上限,最终瓶颈会到handle。
- 平台层组件
如前所述,我们有一个快速逻辑来处理报文和IPC请求,IPC请求可以阻塞,然而报文不行,报文处理慢就会丢包,除了优化协议栈的处理方式,还需要一些高性能的轮子,支撑整个系统高效运转。
- O(1)时间轮
探测器每个探测请求都由一个定时器驱动,协议栈内部也有超时需要定时器,定时器分时复用,探测过程中协议栈使用,探测完毕探测器使用。
管理大量定时器的成熟方案是时间轮,像下面这样:
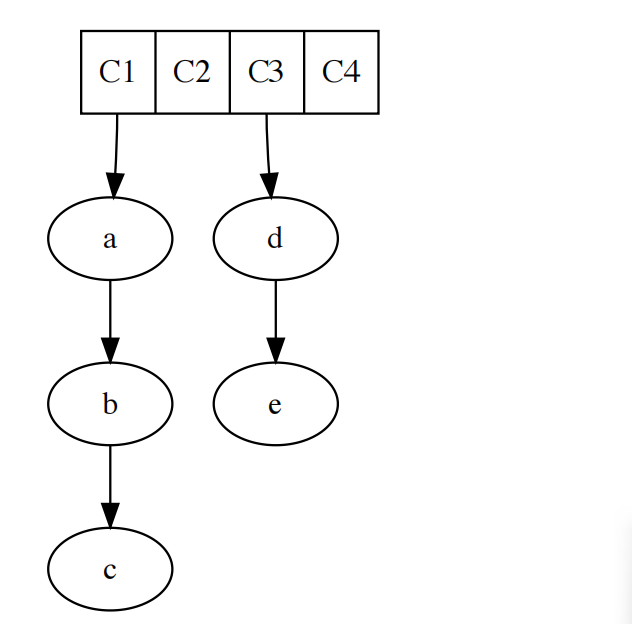
正常的时间轮不是所有操作复杂度都是O(1),原因是触发顺序。
假设时间片为1秒,那超时时间分别为0.4,0.1,0.5的定时器应该按0.1,0.4,0.5的顺序超时,这样就会引入一个至少是O(logn)的排序动作,并成为瓶颈。
去掉这个排序,时间轮就可以稳定O(1),代价是精度下降,并且无法保证超时按顺序触发。
- 内存池
内存池是避免触发系统调用,page fault,cache miss,避免运行时失败,保证系统稳定可靠并且高性能的重要一环。
内存池有很多现有的实现,像jemalloc,tcmalloc这种分配器提供的内存池,只是提供了分配钩子,内部的复杂逻辑是不可控的。这里需要完全可控的内存管理,尤其需要避免某些 库升级之后特性发生变化这种问题。内存池采用外部元数据,每个内存池用一段连续内存管理,如下所示:

free list指向alloc map的一个链表,分配和释放都是O(1),因为链表是LIFO,每次都会分配上次回收的内存,避免cache刷出。
整个mempool可以指定放在普通内存或者>hugepage之上。
任意分配出来的内存都会根据实际地址满足对齐要求
> 根据实际地址对齐很重要,编译器为了提高吞吐会应用向量指令集,要求对齐到16B甚至64B边界,否则会造成进程崩溃,malloc对齐到8B就会有这类问题
- 多级缓存hash
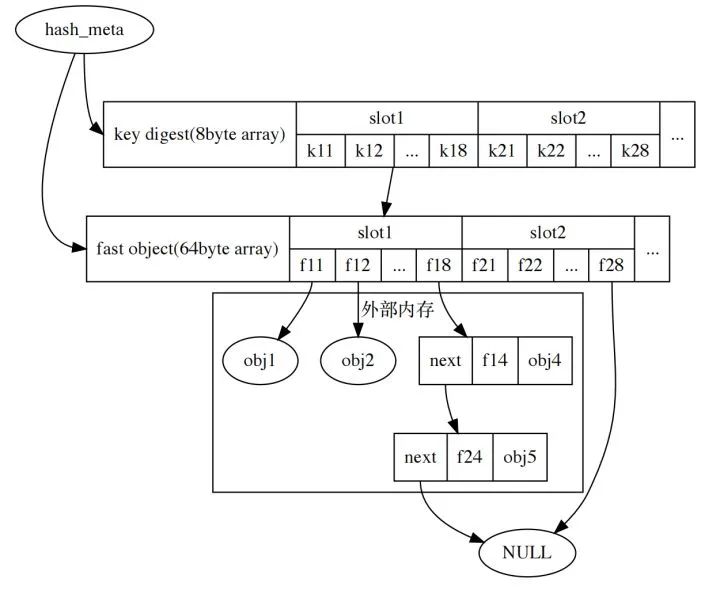
hash是一个关键组件,每个报文都需要匹配一次hash五元组,需要针对cache miss问题做专门的优化。考虑多级缓存方案优化,使用拉链法,对象存储形式作出调整:
- 1级缓存
8byte的key摘要可以显著提升比较性能,把key集中存放,挑选适当的摘要算法可以显著减少遍历开销 > 集中存放的key会因为CPU一次访问一整个cache line而提高缓存命中率。
- 2级缓存
使用64byte固定长度的cache,这个cache刚好是一个cpu cacheline,能容纳key,并且还能放一些频繁使用的数据,把存储对象分为快数据部分和慢数据部分,通过快数据索引慢数据,这样就满足了通用性的要求。
> cacheline典型长度是64byte,也有使用128byte的cpu,CPU硬件预取策略会尝试读取后续的cache line
- 拉链长度估计
假设完全随机的情况下,假定数据分布符合正态分布,按正态分布3σ原则,0.9973以内即认为在合理区间,以此为参考,使用jhash进行散列,实测8作为一个拉链长度的上限的合理值,超过8使用链表,性能降级,8以内使用数组,遍历长度为8的数组性能损失完全可以接受。
按上述要求调整后的布局如下图所示:
- 匹配过程
1. 计算hash摘要,对hash摘要素数取模,得到key digest的slot号,根据slot分别预取key(8\*8byte)和fast object(8\*64byte)
2. 遍历key digest的slot,与fast object中的key做比对,比对成功返回快数据
> 和其他hash相比,比如hlist,必须先访问指针再访问数据,而这里直接访问预取之后的数据,可以减少cache miss
3. 不幸比对到第8个key,则性能降级,线性遍历查找
- 插入过程
1. 如果key digest有空位,则直接插入快表
2. 如果没有空位,则插入第8个位置的慢表
- 删除过程
1. 快表直接把key置0,不从慢表中移动数据进快表
> C语言里面会有指针直接指向对象,移动数据会引发低概率问题
2. 慢表直接删除
对我们要解决的问题来说,五元组和定时器信息放到快数据,其余放到慢数据即可大幅降低hash引入的性能损耗。
参考 -
The Secret To 10 Million Concurrent Connections
An Introduction to the io_uring Asynchronous I/O Framework
Switch Representation within DPDK Applications
NIC Switches
PMD for virtio
Virtio-networking and DPDK