手撕 Golang 高性能内存缓存库 bigcache!
1 . 前言
你好哇! 之前写了三篇 [#Golang 并发编程] 的文章了,这次来换换口味,开个 手撕源码 的新坑!一起来扒一扒 Go 语言高性能 local cache 库 bigcache,看看能不能把开源大佬们的骚操作带到项目里去装一装(?)
2 . 为什么要学习开源项目
个人认为学习开源项目的收益:
- 跟进社区,不做井底之蛙 看到一个开源项目,可以思考下:大佬们最近都在解决哪些问题?他们用到了哪些开源工具?我能拿到项目里用吗?这玩意有 bug 吗?要不要提个 issue 或者提个 PR 呢?
- 面向原理编程 我们在实际项目中会用上很多开源库/框架,你是否好奇过它们的实现机制呢?理解用到的库的实现机制,能帮我们避开很多坑,堪称降维打击
- 学习优秀的设计 优秀的开源项目经过了成千上万开发者的 review,质量一般会比公司赶进度赶出来的质量高得多得多,从中学习优秀的设计,再在实际项目中多用用,同事会感叹:

3 . bigcache 简介
3.1 本地缓存与分布式缓存
缓存是系统提升并发能力、降低时延的利器,根据存储介质和使用场景,我们一般又会使用本地缓存与分布式缓存两种手段。本地缓存一般是在进程内的,最简单的,用 go 的 sync.Map 就能实现一个简单的并发安全的本地缓存了。常见的,将一些静态的、配置类的数据放置在本地缓存中,能有效降低到下游存储的压力。分布式缓存一般会用 redis 或 memcached 等分布式内存数据库来实现,能做到分布式、无状态。这次先研究下 bigcache 后续有机会再挖一挖这里。
3.2 bigcache 诞生背景
bigcache 的开发者是 allegro,是波兰的一个电商网站,参考资料中给出了他们的技术博客的原文,文中详细描述了他们问题的背景以及思考,值得研究。他们的需求主要是:
- 用 HTTP 协议处理 GET POST 请求,body 不大
- 10k rps(requests per second) 5k 读 5k 写
- 缓存至少 10 分钟
- 低延时:平均 5ms ,P99 < 10ms,P999 < 400ms 总结一下,他们需要一个快速、支持过期淘汰、支持 RESTful api 的字典服务
开发团队经过了一番对比,选择了 go 语言(高并发度、带内存管理安全性比 C/C++ 好),抛弃了分布式缓存组件(redis/memcached/couchbase),主要理由是多一跳网络开销。这里我表示怀疑,P999 400ms 的时延其实不至于担心到 redis 网络那点时间,分布式环境下 local cache 不同机器间的数据不一致带来的 cache miss 可能更蛋疼。 最终开发团队选择了实现一个支持以下特性的内存缓存库:
- 百万级缓存项时响应速度也很快
- 并发安全
- 支持设置过期时间
4 . 关键设计
4.1 并发与 sharding
设计上如何做到并发安全呢?最简单的思路就是给 map 上一把 sync.RWMutex 即读写锁。然而当缓存项过多时,并发请求会造成锁冲突,因此需要降低锁粒度。bigcache 采用了分布式系统里常用的 sharding 思路,即将一个大 map 拆分成 N 个小 map,我们称为一个 shard(分片)
如 bigcache.go 的声明,我们初始化得到的 BigCache,核心实际上是一个 []*cacheShard,缓存的写入、淘汰等核心逻辑都在 cacheShard 中了
type BigCache struct {
shards []*cacheShard
lifeWindow uint64
clock clock
hash Hasher
config Config
shardMask uint64
close chan struct{}
}那么在写入一个 key value 缓存时,是如何做分片的呢?
func (c *BigCache) Set(key string, entry []byte) error {
hashedKey := c.hash.Sum64(key)
shard := c.getShard(hashedKey)
return shard.set(key, hashedKey, entry)
}这里会首先进行一次 hash 操作,将 string key hash 到一个 uint64 类型的 key。再根据这个数字 key 去做 sharding
func (c *BigCache) getShard(hashedKey uint64) (shard *cacheShard) {
return c.shards[hashedKey&c.shardMask]
}这里把取余的操作用位运算来实现了,这也解释了为什么在使用 bigcache 的时候需要使用 2 的幂来初始化 shard num 了
cache := &BigCache{
shards: make([]*cacheShard, config.Shards),
lifeWindow: uint64(config.LifeWindow.Seconds()),
clock: clock,
hash: config.Hasher,
config: config,
// config.Shards 必须是 2 的幂
// 减一后得到一个二进制结果全为 1 的 mask
shardMask: uint64(config.Shards - 1),
close: make(chan struct{}),
}例如使用 1024 作为 shard num 时,mask 值为 1024 - 1 即二进制的 '111111111',使用 num & mask 时,即可获得 num % mask 的效果
需要注意,这里的 hash 可能是会冲突的,虽然概率极小,当出现 hash 冲突时,bigcache 将直接返回结果不存在:
func (s *cacheShard) get(key string, hashedKey uint64) ([]byte, error) {
s.lock.RLock()
wrappedEntry, err := s.getWrappedEntry(hashedKey)
if err != nil {
s.lock.RUnlock()
return nil, err
}
// 这里会将二进制 buffer 按顺序解开
// 在打包时将 key 打包的作用就体现出来了
// 如果这次操作的 key 和打包时的 key 不相同
// 则说明发生了冲突,不会错误地返回另一个 key 的缓存结果
if entryKey := readKeyFromEntry(wrappedEntry); key != entryKey {
s.lock.RUnlock()
s.collision()
if s.isVerbose {
s.logger.Printf("Collision detected. Both %q and %q have the same hash %x", key, entryKey, hashedKey)
}
return nil, ErrEntryNotFound
}
entry := readEntry(wrappedEntry)
s.lock.RUnlock()
s.hit(hashedKey)
return entry, nil
}4.2 cacheShard 与 bytes queue 设计
bigcache 对每个 shard 使用了一个类似 ringbuffer 的 BytesQueue 结构,定义如下:
type cacheShard struct {
// hashed key => bytes queue index
hashmap map[uint64]uint32
entries queue.BytesQueue
lock sync.RWMutex
entryBuffer []byte
onRemove onRemoveCallback
isVerbose bool
statsEnabled bool
logger Logger
clock clock
lifeWindow uint64
hashmapStats map[uint64]uint32
stats Stats
}下图很好地解释了 cacheShard 的底层结构~
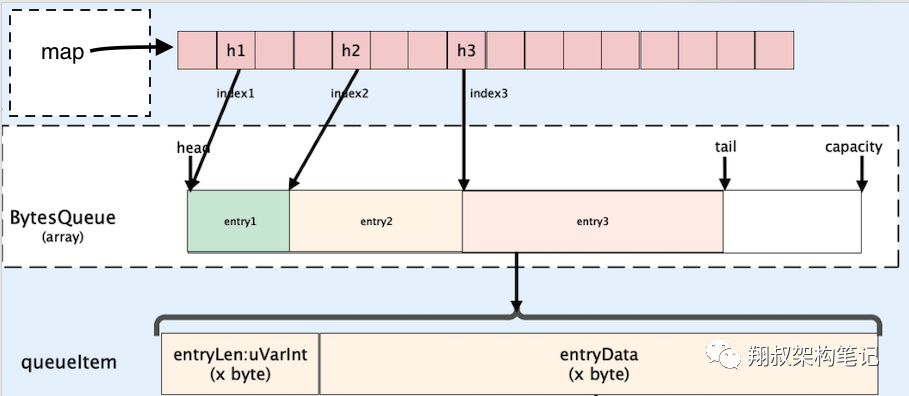
在处理完 sharding 后,bigcache 会将整个 value 与 key、hashedKey 等信息序列化后存进一个 byte array,这里的设计是不是有点类似网络协议里的 header 呢?
// 将整个 entry 打包到当前 shard 的
// byte array 中
w := wrapEntry(currentTimestamp, hashedKey, key, entry, &s.entryBuffer)
func wrapEntry(timestamp uint64, hash uint64, key string, entry []byte, buffer *[]byte) []byte {
keyLength := len(key)
blobLength := len(entry) + headersSizeInBytes + keyLength
if blobLength > len(*buffer) {
*buffer = make([]byte, blobLength)
}
blob := *buffer
// 小端字节序
binary.LittleEndian.PutUint64(blob, timestamp)
binary.LittleEndian.PutUint64(blob[timestampSizeInBytes:], hash)
binary.LittleEndian.PutUint16(blob[timestampSizeInBytes+hashSizeInBytes:], uint16(keyLength))
copy(blob[headersSizeInBytes:], key)
copy(blob[headersSizeInBytes+keyLength:], entry)
return blob[:blobLength]
}这里存原始的 string key,我理解单纯是为了处理 hash 冲突用的。
每一个 cacheShard 底层的缓存数据都会存储在 bytes queue 中,即一个 FIFO 的 bytes 队列,新进入的 entry 都会 push 到末尾,如果空间不足,则会产生内存分配的过程,初始的 queue 的大小,是可以在配置中指定的:
func initNewShard(config Config, callback onRemoveCallback, clock clock) *cacheShard {
// 1. 初始化指定好大小可以减少内存分配的次数
bytesQueueInitialCapacity := config.initialShardSize() * config.MaxEntrySize
maximumShardSizeInBytes := config.maximumShardSizeInBytes()
if maximumShardSizeInBytes > 0 && bytesQueueInitialCapacity > maximumShardSizeInBytes {
bytesQueueInitialCapacity = maximumShardSizeInBytes
}
return &cacheShard{
hashmap: make(map[uint64]uint32, config.initialShardSize()),
hashmapStats: make(map[uint64]uint32, config.initialShardSize()),
// 2. 初始化 bytes queue,这里用到了上面读取的配置
entries: *queue.NewBytesQueue(bytesQueueInitialCapacity, maximumShardSizeInBytes, config.Verbose),
entryBuffer: make([]byte, config.MaxEntrySize+headersSizeInBytes),
onRemove: callback,
isVerbose: config.Verbose,
logger: newLogger(config.Logger),
clock: clock,
lifeWindow: uint64(config.LifeWindow.Seconds()),
statsEnabled: config.StatsEnabled,
}
}注意到这点,在初始化时使用正确的配置,就能减少重新分配内存的次数了。
4.3 GC 优化
bigcache 本质上就是一个大的哈希表,在 go 里,由于 GC STW(Stop the World) 的存在大的哈希表是非常要命的,看看 bigcache 开发团队的博客的测试数据:
With an empty cache, this endpoint had maximum responsiveness latency of 10ms for 10k rps. When the cache was filled, it had more than a second latency for 99th percentile. Metrics indicated that there were over 40 mln objects in the heap and GC mark and scan phase took over four seconds.
缓存塞满后,堆上有 4 千万个对象,GC 的扫描过程就超过了 4 秒钟,这就不能忍了。
主要的优化思路有:
- offheap(堆外内存),GC 只会扫描堆上的对象,那就把对象都搞到栈上去,但是这样这个缓存库就高度依赖 offheap 的 malloc 和 free 操作了
- 参考 freecache 的思路,用
ringbuffer存 entry,绕过了 map 里存指针,简单瞄了一下代码,后面有空再研究一下(继续挖坑 - 利用 Go 1.5+ 的特性:
当 map 中的 key 和 value 都是基础类型时,GC 就不会扫到 map 里的 key 和 value
最终他们采用了 map[uint64]uint32 作为 cacheShard 中的关键存储。key 是 sharding 时得到的 uint64 hashed key,value 则只存 offset ,整体使用 FIFO 的 bytes queue,也符合按照时序淘汰的需求,非常精巧。
经过优化,bigcache 在 2000w 条记录下 GC 的表现
go version go version go1.13 linux/arm64
go run caches_gc_overhead_comparison.go Number of entries: 20000000 GC pause for bigcache: 22.382827ms GC pause for freecache: 41.264651ms GC pause for map: 72.236853ms
效果挺明显,但是对于低延时的服务来说,22ms 的 GC 时间还是很致命的,对象数还是尽量能控制住比较好。
5 . 小结
认真学完 bigcache 的代码,我们至少有以下几点收获:
- 可以通过 sharding 来降低资源竞争
- 可以用位运算来取余数做 sharding (需要是 2 的整数幂 - 1)
- 避免
map中出现指针、使用 go 基础类型可以显著降低 GC 压力、提升性能 - bigcache 底层存储是 bytes queue,初始化时设置合理的配置项可以减少 queue 扩容的次数,提升性能