Dubbo的线程池监控--实战
Dubbo 是一款优秀的微服务框架,它以其高性能、简单易用、易扩展等特点,广泛应用于互联网、金融保险、科技公司、制造业、零售物流等多个领域。如今,Dubbo 框架已经成了互联网开发中比较常用的技术框架。
在Dubbo框架中,当客户端调用服务端的时候,请求抵达了服务端之后,会有专门的线程池去接收参数并且处理。所以如果要实现Dubbo的线程池监控,就需要先了解下Dubbo底层对于业务线程池的实现原理。
Dubbo底层对于线程池的查看
这里我所使用的框架是 Dubbo 2.7.8 版本,它在底层对于线程池的管理是通过一个叫做ExecutorRepository 的类处理的,这个类负责创建并管理 Dubbo 中的线程池,通过该扩展接口,我们可以获取到Dubbo在实际运行中的业务线程池对象。具体的处理逻辑部分如下所示:
package org.idea.dubbo.monitor.core.collect;
import org.apache.dubbo.common.extension.ExtensionLoader;
import org.apache.dubbo.common.threadpool.manager.DefaultExecutorRepository;
import org.apache.dubbo.common.threadpool.manager.ExecutorRepository;
import java.lang.reflect.Field;
import java.util.concurrent.ConcurrentMap;
import java.util.concurrent.ExecutorService;
import java.util.concurrent.ThreadPoolExecutor;
/**
* @Author idea
* @Date created in 7:04 下午 2022/6/29
*/
public class DubboThreadPoolCollector {
/**
* 获取Dubbo的线程池
* @return
*/
public static ThreadPoolExecutor getDubboThreadPoolInfo(){
//dubbo线程池数量监控
try {
ExtensionLoader<ExecutorRepository> executorRepositoryExtensionLoader = ExtensionLoader.getExtensionLoader(ExecutorRepository.class);
DefaultExecutorRepository defaultExecutorRepository = (DefaultExecutorRepository) executorRepositoryExtensionLoader.getDefaultExtension();
Field dataField = defaultExecutorRepository.getClass().getDeclaredField("data");
dataField.setAccessible(true);
ConcurrentMap<String, ConcurrentMap<Integer, ExecutorService>> data = (ConcurrentMap<String, ConcurrentMap<Integer, ExecutorService>>) dataField.get(defaultExecutorRepository);
ConcurrentMap<Integer, ExecutorService> executorServiceConcurrentMap = data.get("java.util.concurrent.ExecutorService");
//获取到默认的线程池模型
ThreadPoolExecutor threadPoolExecutor = (ThreadPoolExecutor) executorServiceConcurrentMap.get(9090);
return threadPoolExecutor;
} catch (Exception e) {
e.printStackTrace();
}
return null;
}
}
好了,现在我们知道如何在代码中实时查看Dubbo线程池的信息了,那么接下来要做的就是如何采集这些线程池的数据,并且进行上报,最后将上报存储的数据通过统计图的方式展示出来。下边我们按照采集,上报,展示三个环节来展示数据。
采集数据
在采集数据这块,有两种思路去采集,分别如下:
- 后台开启一个定时任务,然后每秒都查询一下线程池的参数信息。
- 每次有请求抵达provider的时候,就查看一些线程池的参数信息。
采用两种不同的模式采集出来的数据,可能会有些差异,下边是两种方式的比对:
| 统计方式 | 实现难度 | 可能存在的问题 |
|---|---|---|
| 定时任务采集数据 | 简单 | 定时任务执行间隙中的数据无法采集,导致数据失真。 |
| 请求抵达时采集数据 | 稍为复杂一些 | 在每次请求的时候都需要采集数据,会对性能有一定损耗。 |
通过对实际的业务场景分析,其实第二种方式对应用的性能损耗极微,甚至可以忽略,所以使用这种方式去采集数据的话会比较合适。
下边让我们一起来看看这种方式采集数据的话,该如何实现。
首先我们需要自己定义一个filter过滤器:
package org.idea.dubbo.monitor.core.filter;
import org.apache.dubbo.common.constants.CommonConstants;
import org.apache.dubbo.common.extension.Activate;
import org.apache.dubbo.rpc.*;
import org.idea.dubbo.monitor.core.DubboMonitorHandler;
import java.util.concurrent.ThreadPoolExecutor;
import static org.idea.dubbo.monitor.core.config.CommonCache.DUBBO_INFO_STORE_CENTER;
/**
* @Author idea
* @Date created in 2:33 下午 2022/7/1
*/
@Activate(group = CommonConstants.PROVIDER)
public class DubboRecordFilter implements Filter {
@Override
public Result invoke(Invoker<?> invoker, Invocation invocation) throws RpcException {
ThreadPoolExecutor threadPoolExecutor = DubboMonitorHandler.getDubboThreadPoolInfo();
//请求的时候趣统计线程池,当请求量太小的时候,这块的数据可能不准确,但是如果请求量大的话,就接近准确了
DUBBO_INFO_STORE_CENTER.reportInfo(9090,threadPoolExecutor.getActiveCount(),threadPoolExecutor.getQueue().size());
return invoker.invoke(invocation);
}
}
并且在dubbo的spi配置文件中指定好它们
dubboRecordFilter=org.idea.dubbo.monitor.core.filter.DubboRecordFilter
当provider加入了这个过滤器以后,若有请求抵达服务端,则会通过这个filter触发采集操作。
package org.idea.dubbo.monitor.core.collect;
import org.idea.dubbo.monitor.core.bo.DubboInfoStoreBO;
import java.util.Map;
import java.util.concurrent.ConcurrentHashMap;
/**
* Dubbo数据存储中心
*
* @Author idea
* @Date created in 11:15 上午 2022/7/1
*/
public class DubboInfoStoreCenter {
private static Map<Integer, DubboInfoStoreBO> dubboInfoStoreBOMap = new ConcurrentHashMap<>();
public void reportInfo(Integer port, Integer corePoolSize, Integer queueLength) {
synchronized (this) {
DubboInfoStoreBO dubboInfoStoreBO = dubboInfoStoreBOMap.get(port);
if (dubboInfoStoreBO != null) {
boolean hasChange = false;
int currentMaxPoolSize = dubboInfoStoreBO.getMaxCorePoolSize();
int currentMaxQueueLength = dubboInfoStoreBO.getMaxCorePoolSize();
if (corePoolSize > currentMaxPoolSize) {
dubboInfoStoreBO.setMaxCorePoolSize(corePoolSize);
hasChange = true;
}
if (queueLength > currentMaxQueueLength) {
dubboInfoStoreBO.setMaxQueueLength(queueLength);
hasChange = true;
}
if (hasChange) {
dubboInfoStoreBOMap.put(port, dubboInfoStoreBO);
}
} else {
dubboInfoStoreBO = new DubboInfoStoreBO();
dubboInfoStoreBO.setMaxQueueLength(queueLength);
dubboInfoStoreBO.setMaxCorePoolSize(corePoolSize);
dubboInfoStoreBOMap.put(port, dubboInfoStoreBO);
}
}
}
public DubboInfoStoreBO getInfo(Integer port){
return dubboInfoStoreBOMap.get(port);
}
public void cleanInfo(Integer port) {
dubboInfoStoreBOMap.remove(port);
}
}
注意这个采集类只会采集一段时间的数据,然后定期会清空重置。之所以这么做,是希望用这个map统计指定时间内的最大线程数和最大队列数,接着当这些峰值数据被上报到存储中心后就进行清空。
关于DubboInfoStoreCenter对象的定义,我将它放置在了一个叫做CommonCache的类里面,具体如下:
package org.idea.dubbo.monitor.core.config;
import org.idea.dubbo.monitor.core.store.DubboInfoStoreCenter;
/**
* @Author idea
* @Date created in 12:15 下午 2022/7/1
*/
public class CommonCache {
public static DubboInfoStoreCenter DUBBO_INFO_STORE_CENTER = new DubboInfoStoreCenter();
}
因为这里使用了static关键字去修饰DubboInfoStoreCenter,所以在上边的过滤器中,我们才可以直接通过静态类引用去调用它的采集接口。
好了,现在整体来看,我们已经实现了在过滤器中去实时采集线程池的数据,并且将它暂存在了一个Map表中,这个map的数据主要是记录了某段时间内的线程池峰值,供采集器角色去使用。
那么接下来,我们就来看看上报器模块主要做了哪些操作。
上报数据
上报数据前,最重要的就是选择合适的存储组件了。首先上报的数据本身体量并不大,我们可以将采集时间短设置为15秒,那么设计一个上报任务,每隔15秒采集一次dubbo线程池的数据。那么一天的时间就需上报5760次,假设一次上报存储一条记录的话,那么一天下来所需要存储的数据也并不是特别多。
并且存储下来的服务数据实际上也并不需要保留太长的时间,一般存储个一周时间也就足够了,所以最终我选用了Redis进行这方面的存储。
我们实际每次关注的数据字段主要有三个,关于它们的定义我整理成了下边这个对象:
package org.idea.dubbo.monitor.core.bo;
/**
* @Author idea
* @Date created in 7:17 下午 2022/6/29
*/
public class ThreadInfoBO {
private Integer activePoolSize;
private Integer queueLength;
private long saveTime;
public Integer getActivePoolSize() {
return activePoolSize;
}
public void setActivePoolSize(Integer activePoolSize) {
this.activePoolSize = activePoolSize;
}
public Integer getQueueLength() {
return queueLength;
}
public void setQueueLength(Integer queueLength) {
this.queueLength = queueLength;
}
public long getSaveTime() {
return saveTime;
}
public void setSaveTime(long saveTime) {
this.saveTime = saveTime;
}
@Override
public String toString() {
return "ThreadInfoBO{" +
", queueLength=" + queueLength +
", saveTime=" + saveTime +
'}';
}
}
接着会开启一个线程任务,每间隔15秒就会执行一轮上报数据的动作:
package org.idea.dubbo.monitor.core.report;
import com.alibaba.fastjson.JSON;
import org.idea.dubbo.monitor.core.bo.DubboInfoStoreBO;
import org.idea.dubbo.monitor.core.bo.ThreadInfoBO;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.boot.CommandLineRunner;
import java.util.concurrent.ExecutorService;
import java.util.concurrent.Executors;
import static org.idea.dubbo.monitor.core.config.CommonCache.DUBBO_INFO_STORE_CENTER;
/**
* @Author idea
* @Date created in 12:13 下午 2022/7/1
*/
public class DubboInfoReportHandler implements CommandLineRunner {
@Autowired
private IReportTemplate reportTemplate;
private static final Logger LOGGER = LoggerFactory.getLogger(DubboInfoReportHandler.class);
public static ExecutorService executorService = Executors.newFixedThreadPool(1);
public static int DUBBO_PORT = 9090;
@Override
public void run(String... args) throws Exception {
executorService.submit(new Runnable() {
@Override
public void run() {
while (true) {
try {
Thread.sleep(10000);
DubboInfoStoreBO dubboInfoStoreBO = DUBBO_INFO_STORE_CENTER.getInfo(DUBBO_PORT);
ThreadInfoBO threadInfoBO = new ThreadInfoBO();
threadInfoBO.setSaveTime(System.currentTimeMillis());
if(dubboInfoStoreBO!=null){
threadInfoBO.setQueueLength(dubboInfoStoreBO.getMaxQueueLength());
threadInfoBO.setActivePoolSize(dubboInfoStoreBO.getMaxCorePoolSize());
} else {
//这种情况可能是对应的时间段内没有流量请求到provider上
threadInfoBO.setQueueLength(0);
threadInfoBO.setActivePoolSize(0);
}
//这里是上报器上报数据到redis中
reportTemplate.reportData(JSON.toJSONString(threadInfoBO));
//上报之后,这里会重置map中的数据
DUBBO_INFO_STORE_CENTER.cleanInfo(DUBBO_PORT);
LOGGER.info(" =========== Dubbo线程池数据上报 =========== ");
} catch (Exception e) {
e.printStackTrace();
}
}
}
});
}
}
这类要注意下,Dubbo应用的线程池上报任务应当等整个SpringBoot应用启动成功之后再去触发,否则可能会有些许数据不准确性。所以在定义Bean初始化线程的时候,我选择了CommandLineRunner接口。
细心查看代码的你可能会看到这么一个类
org.idea.dubbo.monitor.core.report.IReportTemplate
这个类定义了数据上报器的基本动作,下边是它的具体代码:
package org.idea.dubbo.monitor.core.report;
/**
* 上报模版
*
* @Author idea
* @Date created in 7:10 下午 2022/6/29
*/
public interface IReportTemplate {
/**
* 上报数据
*
* @return
*/
boolean reportData(String json);
}
实现类部分如下所示:
package org.idea.dubbo.monitor.core.report.impl;
import org.idea.dubbo.monitor.core.report.IReportTemplate;
import org.idea.qiyu.cache.redis.service.IRedisService;
import org.springframework.stereotype.Component;
import javax.annotation.Resource;
import java.time.LocalDate;
import java.util.concurrent.TimeUnit;
/**
* @Author idea
* @Date created in 7:12 下午 2022/6/29
*/
@Component
public class RedisTemplateImpl implements IReportTemplate {
@Resource
private IRedisService redisService;
private static String queueKey = "dubbo:threadpool:info:";
@Override
public boolean reportData(String json) {
redisService.lpush(queueKey + LocalDate.now().toString(), json);
redisService.expire(queueKey + LocalDate.now().toString(),7, TimeUnit.DAYS);
return true;
}
}
这里面我采用的是list的结构去存储这些数据指标,设定了一个过期时间为一周,最终存储到redis之后的格式如下所示:
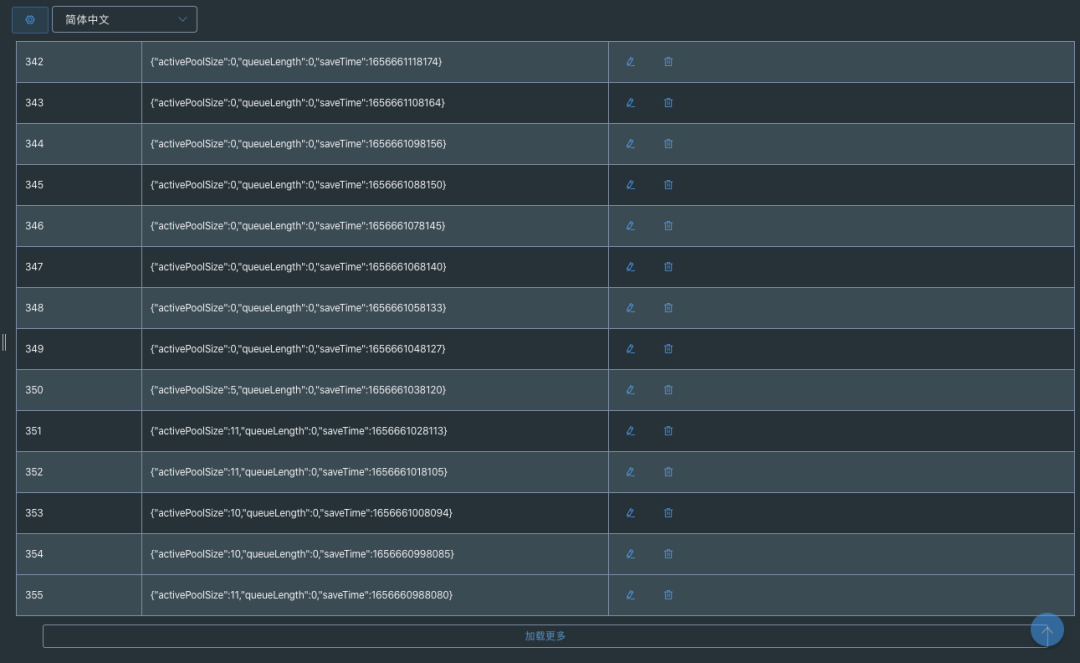
> 数据展示
好了,现在我们已经完成了对线程池的监控,最后只需要设计一个管理台,从缓存中提取上报的数据并且进行页面的展示即可。
实现的逻辑比较简单,只需要定义好统计图所需要的数据结构,然后在controller返回即可,例如下图所示:
最终展现出来的效果如下图:
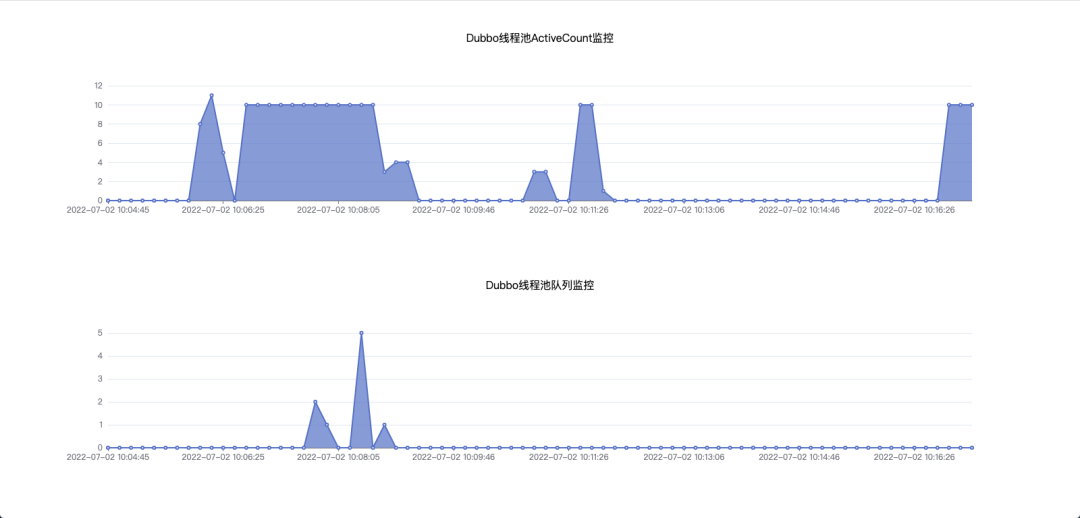
随着请求dubbo接口的量发生变化,统计图可以展示出dubbo线程池的数据变动情况。如果希望统计图以实时的方式展示数据的话,其实只需要在js中写一个定时调用的函数即可。
这里我是使用的是echart插件做的图表渲染,我选用的是最简单的统计图类型,大家也可以根据自己的具体所需在echart的官网上选择合适的模型进行渲染,下边这是echart的官网地址:
https://echarts.apache.org/examples/zh/index.html