京东零售营销选品平台架构设计
背景
随着互联网业的发展和用户购物习惯的转变,电商在零售市场中的占比逐年增加,市场的扩大也带来了各个电商平台中商品的数量在近十年里快速上涨,以京东零售为例,现在全站的商品规模已经达到数十亿级。
如此大的商品量,在带来了更丰富的商品的同时,也给日常电商的运营工作增加了更大的难度。其中很核心的难点之一就是,如何从这些海量的商品中找出优质的、符合运营诉求的商品。
基于这样的痛点,各大零售平台都在近几年推出了各自的选品工具或者平台,本人所在团队有幸参与到了京东零售营销端的选品平台从零到一的规划、设计、落地,并在2022年618大促活动中覆盖了50%的促销活动楼层商品的选品职责。
本文将分享从2021年Q3到2022年618这一年时间里平台开发过程中团队所积累的一些相关的技术经验,希望对业内同学有所帮助。
选品核心能力拆解
从上一节的背景中,我们可以看出一个选品系统最核心的功能是能帮助运营从较大规模的数据中选出目标数据,这是我们进行系统设计最核心的关键点。所以这里设计的关键问题就可以转化为如何能实现从较大规模的数据中选出目标数据。关键问题清晰之后,我们其实可以看出,这是一个数据检索服务。当我们把问题转化成实现一个数据检索服务的时候,很多设计思路就清晰了起来。
检索服务对于每个人来说都不是一个陌生的功能,我们在日常工作设计甚至生活中都经常接触这样的功能,比如日常工作中筛选excel表格中的数据,或者我们日常在百度、谷歌上使用的搜索功能,其实都是数据的检索服务。基于此,我们把各种检索服务进行横向对比分析,可以得到我们认为如果要设计一个选品系统最重要的三大核心要素:数据、筛选和排序。
为了让大家更容易理解这三个核心要素,我们基于三要素把日常经常接触的工具进行横向比较,如下表:
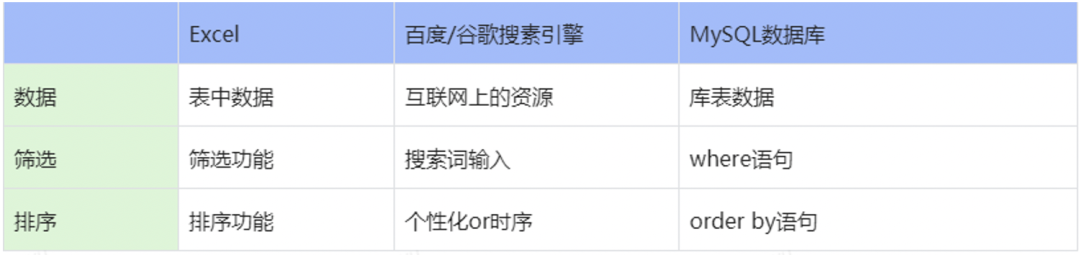
京东零售选品业务情况
乔布斯曾经在一次发布会上回答了一位工程师质疑他是否懂技术的问题,他回答大意是:我们应该为了一个好产品去找到适合它的技术,而不是为了推广技术而去设计一个产品。同样的,为了更合理的设计好我们的选品平台,我们也需要在前期深入的去了解业务的具体使用场景和相关的技术情况。
经过我们对业务的调研,大体总结出几个核心的业务使用情况:
1. 不同的选品业务会使用不同的数据,数据范围从百万到亿级不等,使用到的指标也不一样。
2. 京东零售业务比较复杂,平台需要支持的业务会比较多。
3. 数据选品需要实时得到结果,结果包括数据的列表和数据的一些分布。
针对上述的业务使用信息,我们可以得到系统需要满足:
1. 支持较大数据量的实时查询。
2. 选品数据多样性高,需要针对不同业务进行灵活调整。
3. 需要同时支持OLTP和OLAP查询。
选品领域模型设计
针对上一节的业务使用诉求,我们首先设计了一套选品平台的领域模型,主要包含输入和输出两大部分,输入域包含我们选品的核心三要素:数据、筛选和排序;输出域偏向业务功能的使用诉求,主要包含视图能力和数据输出能力。模型设计如下图:

选品系统架构
确定了选品平台的领域能力模型后,我们继续进行系统架构的设计拆解,由于我们平台的定位是服务整个京东零售营销的选品场景,业务场景较多且区别较大,于是在系统设计上如何通过一套底层能力支撑多变的前台使用是我们在设计平台架构的时候重点需要思考的问题。下面介绍一下团队针对选品从前端到服务端各个环节的系统架构。
01 前端
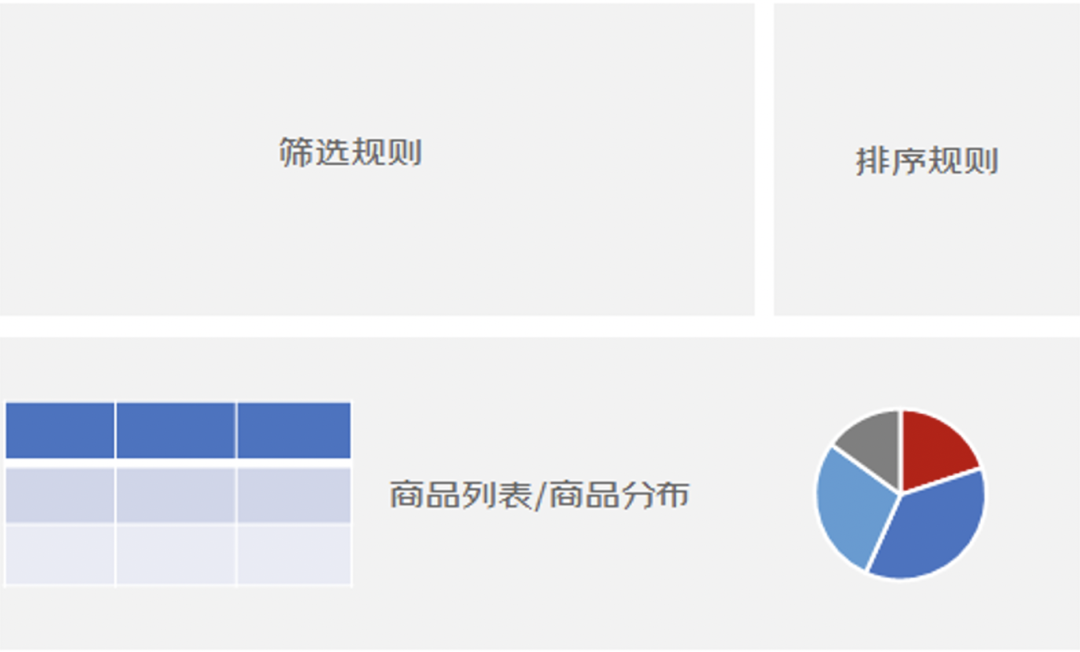
前端是最直接面向用户的一层服务,这里需要先考虑到合适的用户体验,经过一段时间的打磨,最终我们选品操作工作台的交互功能设计了三大核心工作区域:筛选规则配置区、排序配置规则区和展示区(商品列表和商品分布),如下图:
在技术实现方面,为了保证我们整个前端工作区域的适配性和多样性,我们把工作台各个区域的渲染都通过配置化的方式实现,整个配置化组件底层协议基于Json schema,渲染基于京东零售的水滴组件(已开源,水滴表单组件 https://github.com/JDFED/drip-form,水滴表格组件 https://github.com/JDFED/drip-table)。
这一套设计保证了我们可以通过配置快速搭建各个基于同一底层的不同的前端选品样式,具备优秀的灵活性和可适配性。架构图如下:

02 服务端
服务端方面,首先是应用层设计,这里最重要的是联动配置化的前端协议来实现后台的服务。考虑到选品本质是上把前端用户交互翻译成数据Query的过程,所以这里对于服务端的应用层最核心的就是两部分功能:协议字典、Query解析引擎。其中协议字典主要作用在于和前段的配置协议进行映射翻译,翻译成一些逻辑语言,比如大于、小于、等于等。Query解析引擎作用是把逻辑性语言通过动态Query的方式生成Query语句。如下图:

在应用层之外,选品服务端的数据层也是非常重要的部分,在存储介质方面,考虑到选品用户需要检索商品以及查看商品分布,技术选型上我们首选ClickHouse。ClickHouse在OLAP查询方面以及数据写入、数据查询性能方面都有很好的表现。
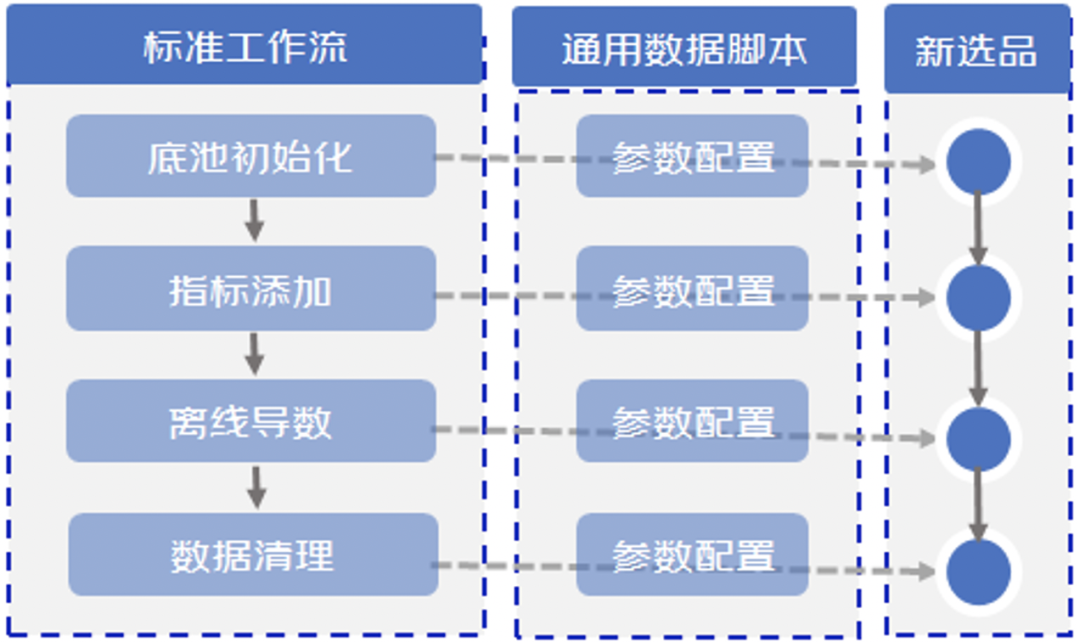
另外,选品数据处理涉及大数据海量数据的前置处理,这里我们主要使用离线大数据计算的方式进行处理(HIVE SQL或者Spark)。在离线数据处理方面,我们主要进行了标准化设计,沉淀了一套通用的数据脚本,把所有数据处理过程都抽象成一套标准的数据处理流程(1. 底池初始化,2. 指标添加,3. 离线导数,4. 数据清理),这样可以保证各个环节可以用通用的数据处理脚本,不同业务处理数据只需要传入不同的配置参数即可。如下图:
最后,在应用层和数据层之外,我们也设计了质量监控体系,包括服务链路监控、定时巡检、降级限流、异常数据处理等,来保证整个选品系统的健壮性和内部流程的可观测性。
最后是整个的架构图,如下:
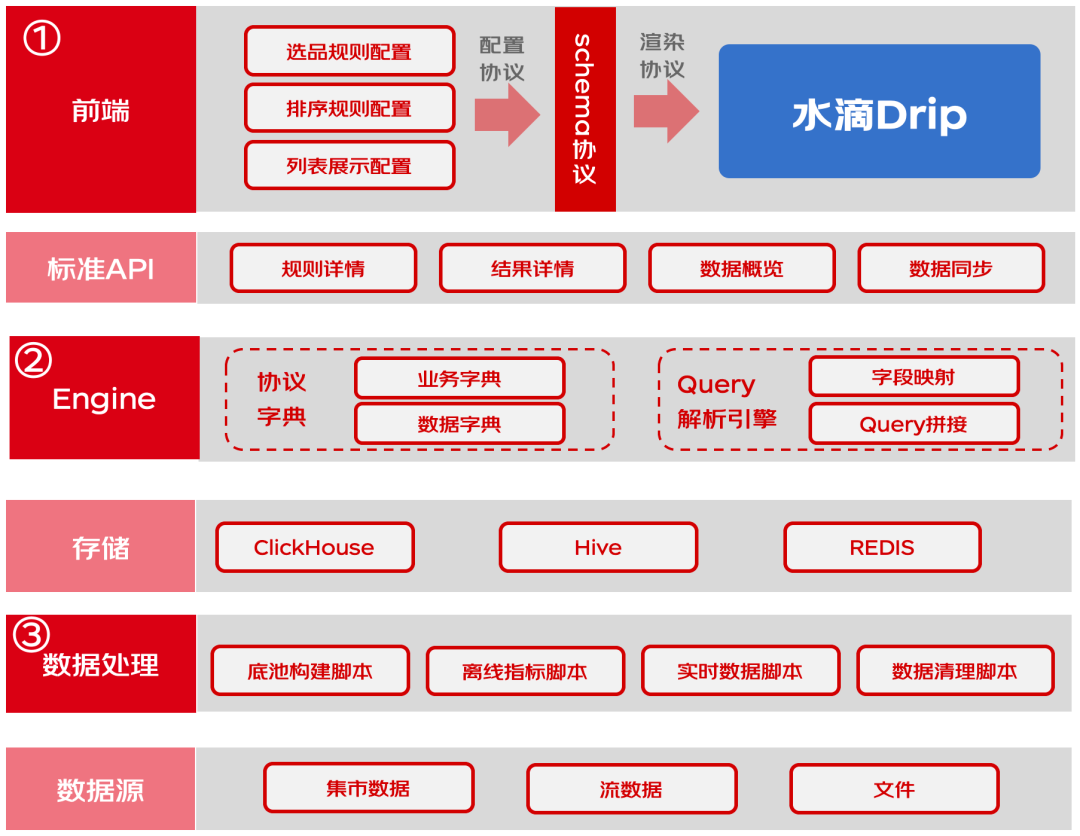
通过这一套系统架构,我们实现了选品平台的统一底层、灵活配置化的前端,一键部署多端适配的系统特性。
选品数据索引架构
除了上一章节介绍的平台工程架构以外,数据也是选品平台极其核心的部分,这里数据包含数据的生产传输和数据的检索查询。考虑到数据的量级(亿级),传统的单点数据库支持不太适用,我们选择的方向是分布式数据库或者数据引擎,考虑到这里对于查询有明确的聚合查询场景(查看分布等OLAP性质查询),我们综合下来选择了现在社区比较活跃并且成熟度也较高的ClickHouse所谓数据索引引擎。
在索引结构设计上,我们也可以从查询由近到远的视角拆解来看。
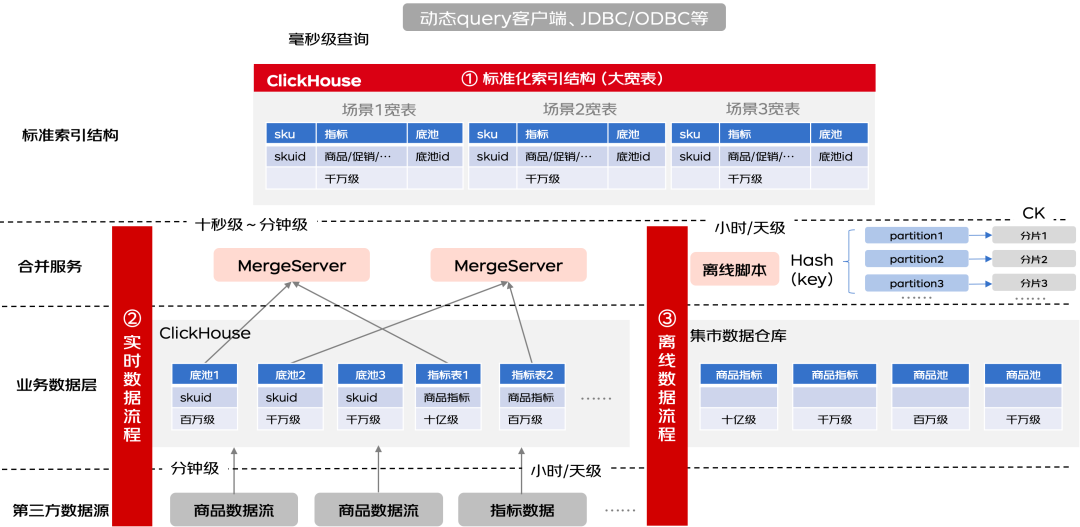
首先第一部分是离查询最近的索引,这里索引最核心的指标是提供尽量快的查询性能,考虑到一个选品查询的过程本质上是条件查询的过程,所以这里我们设计上针对不同的选品垂直业务场景,把商品主键和业务指标合并成一个宽表的形式,这样查询可以直接命中单表结构,不需要额外的实时关联数据操作(比如多表join),在性能上是最优的。结构如下:

这里的结构是比较简单明了的,但是我们也要认识到底层的数据结构其实是很多样的,所以如何能保证把多样性的底层数据可以标准化的处理成我们需要的结构是整个数据处理流程中最重要的设计点。针对这块设计,按照数据的实时性要求,我们可以拆分成两大类数据处理流程:离线数据(实时性要求不高,可以容忍小时级或者天级数据延迟)和实时数据(实时性要求高,基本需要准实时)处理流程。
首先看离线数据处理流程,这里的设计思路比较明确,只需要通过离线数据处理脚本把多样的底层数据处理成需要的格式。这里最大的挑战在于当数据量很大的时候如何可以较快的导入到索引库里,这里主要通过一些脚本的优化,比如通过自定义Hash函数把数据进行分区,再各个分区数据直连索引库分片的方式进行数据写入。
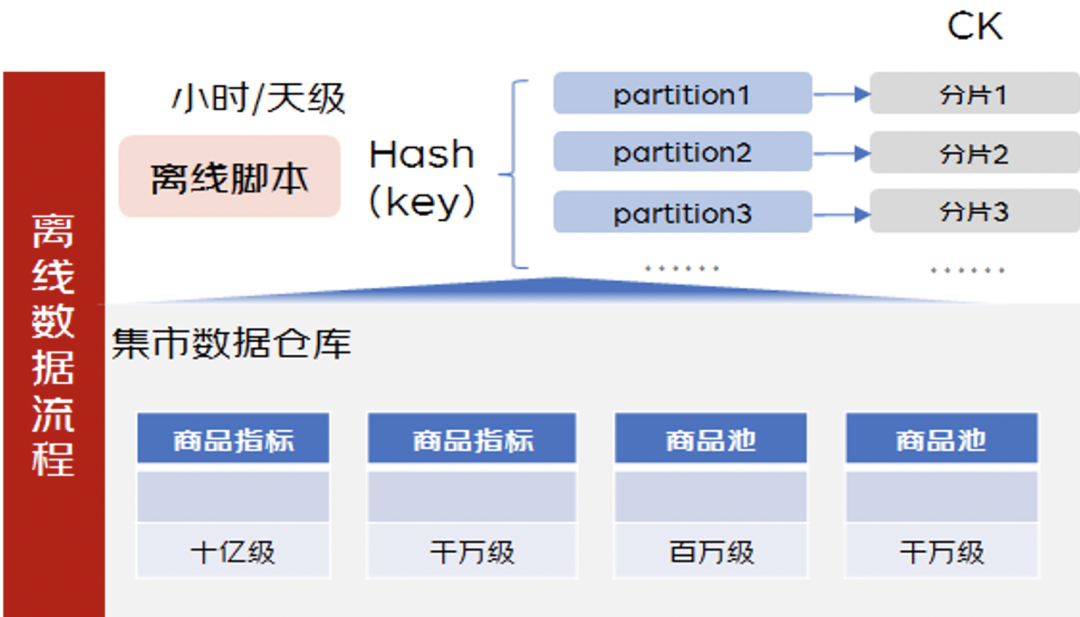
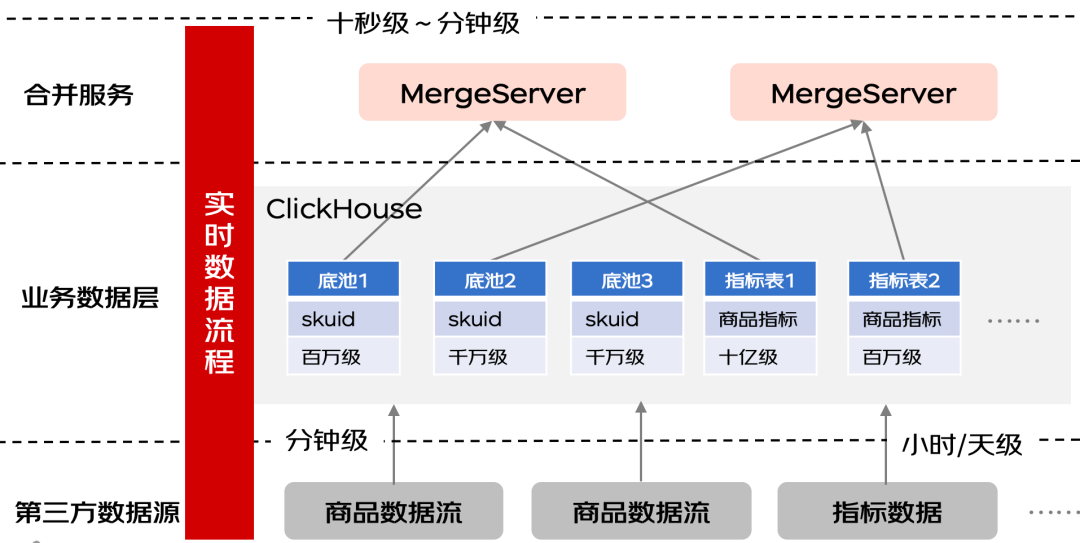
接着看实时数据处理流程,对于分布式大数据量,实时数据处理流程的复杂度是高于离线数据处理流程的。实时数据处理的难点主要在于大量数据如何按照我们的标准格式快速接入到查询索引里。为了达成这个系统设计目标,我们参考了业内很多的分布式数据库设计思路,把实时数据处理流程分成两阶段,写入阶段和合并数据阶段。
其中写入阶段目标是把数据能够较快的落库,考虑最核心的是性能,所以我们采用的方案主要是按照原数据流格式直接不做复杂逻辑处理就进行直接入库,整个数据的格式比较灵活。合并数据阶段目标是把数据处理成目标格式,所以这里的服务处理可以做一定的定制处理,来把多样格式的数据处理成统一的目标格式。
通过这样一套底层索引的架构设计,我们通过宽表的查询索引表结构保证了选品实时查询的效率,通过实时和离线双路流程保证了数据的同步传输效率。下图为整体架构图:
结语
京东零售选品平台初版上线于2021年Q3,整个平台的架构设计,包含了系统工程和数据处理两大方面的研发知识体系,对于团队和我个人是一个挑战和机遇。通过这次平台的落地过程,团队完成了很多成绩也踩过很多坑,相对于完成的成绩,我们更感谢这些出现过的问题和踩过的坑,因为团队正是从这一个一个的困难问题中得到了历练,不管从技术深度还是广度上都提升了很多。
最后,提业内的一句名言:“软件开发没有银弹”,我们分享的平台架构设计是基于京东零售营销体系的业务使用场景的,这也是我为什么在前三章节用比较多的篇幅来介绍业务,这套架构是否适用于其他场景需要各位读者自行分析体会,当然我们设计中肯定依然有很多不足,我们团队内部也在持续的迭代优化系统,这里也欢迎各位读者可以留言来提供宝贵的意见。