聊聊分布式锁
为什么我们需要一把分布式锁?
- 为了效率(efficiency),协调各个客户端避免做重复的工作。即使锁偶尔失效了,只是可能把某些操作多做一遍而已,不会产生其它的不良后果。比如重复发送了一封同样的 email(当然这取决于业务应用的容忍度)。
- 为了正确性(correctness)。在任何情况下都不允许锁失效的情况发生,因为一旦发生,就可能意味着数据不一致(inconsistency),数据丢失,文件损坏,订单重复,超卖或者其它严重的问题。
分布式锁的三个属性
- 互斥(Mutual Exclusion),这是锁最基本的功能,同一时刻只能有一个客户端持有锁;
- 避免死锁(Dead lock free),如果某个客户端获得锁之后花了太长时间处理,或者客户端发生了故障,锁无法释放会导致整个处理流程无法进行下去,所以要避免死锁。最常见的是通过设置一个 TTL(Time To Live,存活时间) 来避免死锁。
- 容错(Fault tolerance),为避免单点故障,锁服务需要具有一定容错性。大体有两种容错方式,一种是锁服务本身是一个集群,能够自动故障切换(ZooKeeper、etcd);另一种是客户端向多个独立的锁服务发起请求,其中某个锁服务故障时仍然可以从其他锁服务读取到锁信息(Redlock),代价是一个客户端要获取多把锁,并且要求每台机器的时钟都是一样的,否则 TTL 会不一致,可能有的机器会提前释放锁,有的机器会太晚释放锁,导致出现问题。
常见的分布式锁实现方案
- Redis
- MySQL
- ZooKeeper
基于 Redis 的分布式锁
错误的加锁:非原子操作
使用 Redis 的分布式锁,我们首先想到的是 setnx 命令,SET if Not Exists:
SETNX lockKey value EXPIRE lockKey 30
使用 jedis 的客户端代码如下:
if (jedis.setnx(lockKey, val) == 1) {
jedis.expire(lockKey, timeout);
}虽然这两个命令和前面算法描述中的一个 SET 命令执行效果相同,但却不是原子的。如果客户端在执行完 SETNX 后崩溃了,那么就没有机会执行 EXPIRE 了,导致它一直持有这个锁。
加锁和设置超时两个操作是分开的,并非原子操作。假设加锁成功,但是设置锁超时失败,那么该 lockKey 永不失效。
问题 1:为什么这个锁必须要设置一个过期时间?
当一个客户端获取锁成功之后,假如它崩溃了,或者它忘记释放锁,或者由于发生了网络分割(network partition)导致它再也无法和 Redis 节点通信了,那么它就会一直持有这个锁,而其它客户端永远无法获得锁了
问题 2:这个锁的有效时间设置多长比较合适?
前面这个算法中出现的锁的有效时间(lock validity time),设置成多少合适呢?如果设置太短的话,锁就有可能在客户端完成对于共享资源的访问之前过期,从而失去保护;如果设置太长的话,一旦某个持有锁的客户端释放锁失败,那么就会导致所有其它客户端都无法获取锁,从而长时间内无法正常工作。看来真是个两难的问题。
正确的加锁姿势
Redis 客户端为了获取锁,向 Redis 节点发送如下命令:
SET lockKey requestId NX PX 30000
- lockKey 是加锁的锁名;
- requestId 是由客户端生成的一个随机字符串,它要保证在足够长的一段时间内在所有客户端的所有获取锁的请求中都是唯一的;(下面会分析它的作用)
- NX 表示只有当 lockKey 对应的 key 值不存在的时候才能 SET 成功。这保证了只有第一个请求的客户端才能获得锁,而其它客户端在锁被释放之前都无法获得锁;
- PX 30000 设置过期时间,表示这个锁有一个 30 秒的自动过期时间。当然,这里 30 秒只是一个例子,客户端可以选择合适的过期时间。
在 Java 中使用 jedis 包的调用方法是:
String result = jedis.set(lockKey, requestId, "NX", "PX", expireTime)
问题:为什么要设置一个随机字符串 requestId?如果没有会出现什么问题?
下面释放锁的时候给出答案。
依赖 Redis 超时自动释放锁的问题
如果按照如下方式加锁:
String result = jedis.set(lockKey, requestId, "NX", "PX", expireTime);
if ("OK".equals(result)) {
return true;
}
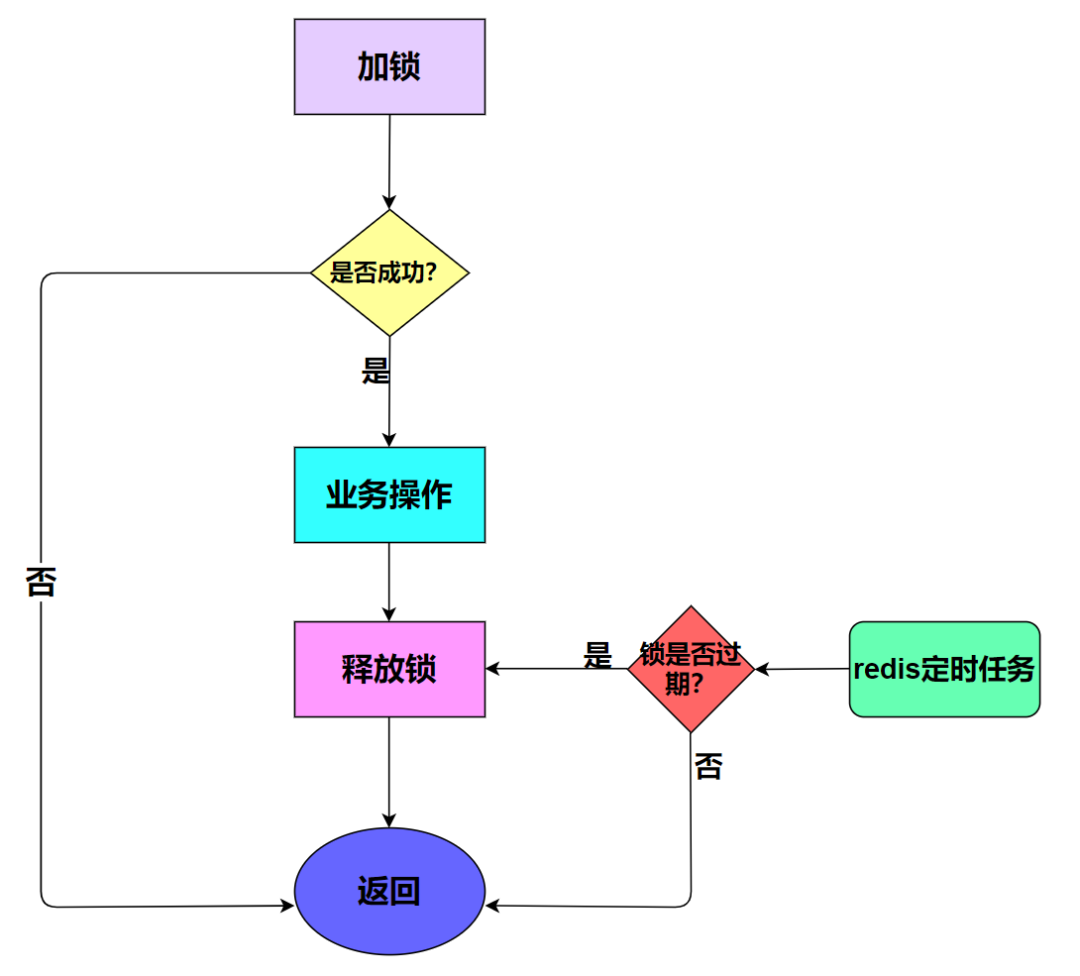
return false;加锁之后,每次都会到 expireTime 之后才会释放锁,哪怕业务使用完这把锁了。所以更合理的做法是:
- 加锁;
- 业务操作;
- 主动释放锁;
- 如果主动释放锁失败了,则达到超时时间,Redis 自动释放锁。
try{
String result = jedis.set(lockKey, requestId, "NX", "PX", expireTime);
if ("OK".equals(result)) {
return true;
}
return false;
} finally {
unlock(lockKey);
}
释放了别人的锁
上面那个 unlock(lockKey)代码释放锁有什么问题?可能会出现释放别人的锁的问题。
有的同学可能会反驳:线程 A 获取了锁之后,它要是没有释放锁,这个时候别的线程假如线程 B、C……根本不可能获取到锁,何来释放别人锁之说?

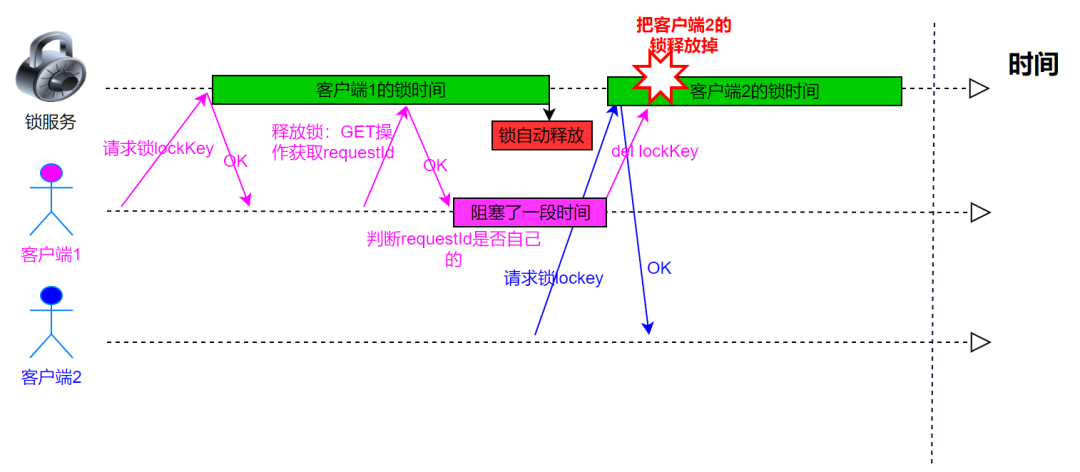
- 客户端 1 获取锁成功。
- 客户端 1 在某个操作上阻塞了很长时间。
- 过期时间到了,锁自动释放了。
- 客户端 2 获取到了对应同一个资源的锁。
- 客户端 1 从阻塞中恢复过来,释放掉了客户端 2 持有的锁。
- 另外线程客户端 3 此时可以成功请求到锁
如何解决这个问题:自己只能释放自己加的锁,不允许释放别人加的锁!
前面使用 set 命令加锁的时候,除了使用 lockKey 锁标识之外,还使用了一个 requestId,这个 requestId 的作用是什么呢?
requestId 是在释放锁的时候用的!!!
伪代码如下:
try{
String result = jedis.set(lockKey, requestId, "NX", "PX", expireTime);
if ("OK".equals(result)) {
return true;
}
return false;
} finally {
unlock(lockKey);
}
所以在释放锁的时候,先要获取到该锁的值(就是每个加锁线程自己设置的 requestId),然后判断跟之前自己设置的值是否相同,如果相同才允许删除锁,返回成功,如果不同,直接返回失败。
问题:为什么要设置一个随机字符串 requestId?如果没有会出现什么问题?
设置一个随机字符串 requestId 是必要的,它保证了一个客户端释放的锁必须是自己持有的那个锁。假如获取锁时 SET 的不是一个随机字符串,而是一个固定值,那么可能导致释放别人的锁。所以要保证 requestId 全局唯一。
释放锁的问题:非原子操作
if (jedis.get(lockKey).equals(requestId)) {
jedis.del(lockKey);
return true;
}
return false;显然,jedis.get(lockKey).equals(requestId) 这行代码包含了【获取该锁的值】,【判断是否是自己加的锁】,【删除锁】这三个操作,万一这三个操作中间的某个时刻出现阻塞
- 客户端 1 获取锁成功;
- 客户端 1 进行业务操作;
- 客户端 1 为了释放锁,先执行’GET’操作获取随机字符串的值。
- 客户端 1 判断随机字符串的值,与预期的值相等。
- 客户端 1 由于某个原因阻塞住了很长时间。
- 过期时间到了,锁自动释放了。
- 客户端 2 获取到了对应同一个资源的锁。
- 客户端 1 从阻塞中恢复过来,执行 DEL 操纵,释放掉了客户端 2 持有的锁。
实际上,如果不是客户端 1 阻塞住了,而是出现了大的网络延迟,也有可能导致类似的执行序列发生。
问题的根源:锁的判断在客户端,但是锁的删除却在服务端!
正确的释放锁姿势
正确的释放锁姿势——锁的判断和删除都在服务端(Redis),使用 lua 脚本保证原子性:
if redis.call("get",KEYS[1]) == ARGV[1] then
return redis.call("del",KEYS[1])
else
return 0
end这段 Lua 脚本在执行的时候要把前面的 requestId 作为 ARGV[1]的值传进去,把 lockKey 作为 KEYS[1]的值传进去。
释放锁的操作为什么要使用 lua 脚本?
释放锁其实包含三步操作:‘GET’、判断和‘DEL’,用 Lua 脚本来实现能保证这三步的原子性。
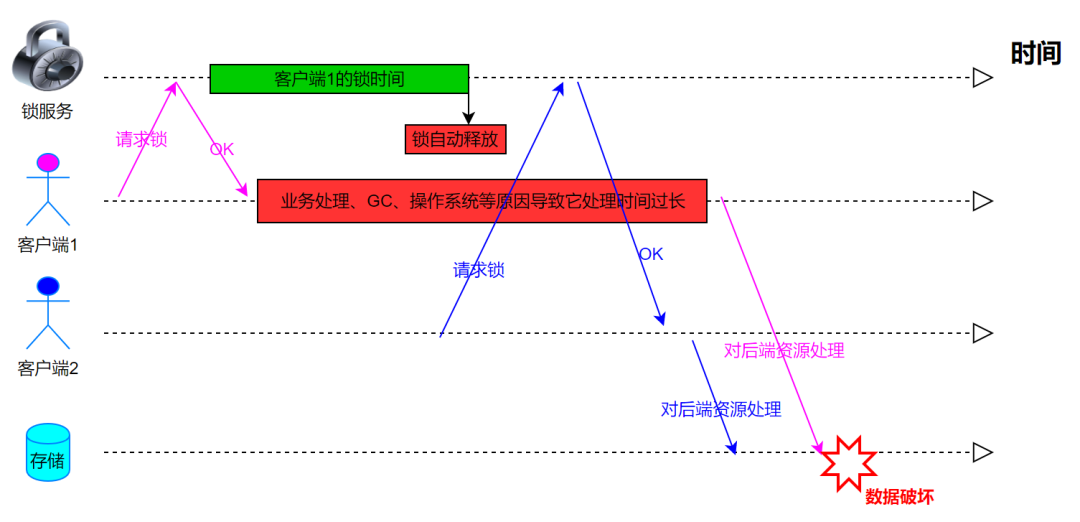
锁超时问题
如果客户端 1 请求锁成功了,但是由于业务处理、GC、操作系统等原因导致它处理时间过长,超过了锁的时间,这时候 Redis 会自动释放锁,这种情况可能导致问题:
Timer timer = new Timer();
timer.schedule(new TimerTask() {
@Override
public void run(Timeout timeout) throws Exception {
//自动续期逻辑
}
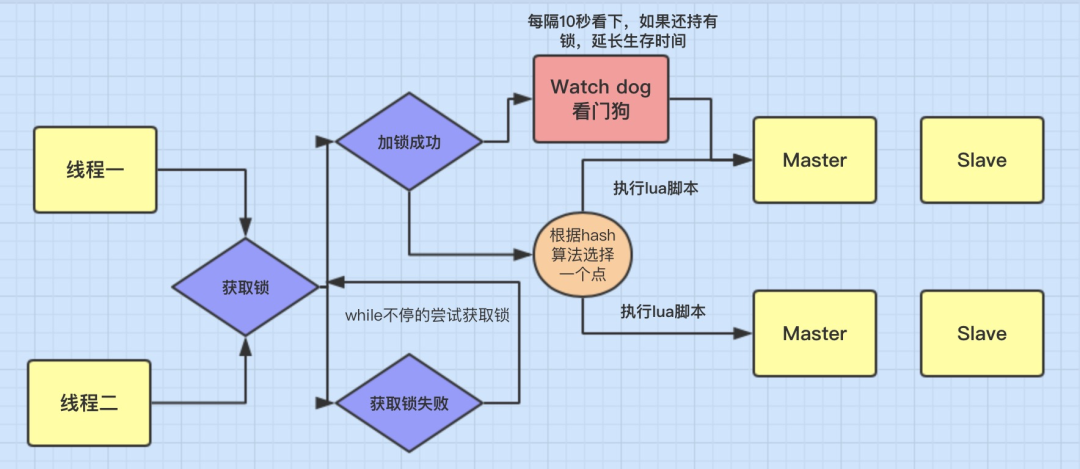
}, 10000, TimeUnit.MILLISECONDS);这个机制在 Redisson 框架中已经实现,而且还有一个比较霸气的名字 watchdog(看门狗):加锁时没有指定加锁时间时会启用 watchdog 机制,默认加锁 30 秒,每 10 秒钟检查一次,如果存在就重新设置 过期时间为 30 秒(即 30 秒之后它就不再续期了)
- lockWatchdogTimeout(监控锁的看门狗超时,单位:毫秒)
- 默认值:30000
- 监控锁的看门狗超时时间单位为毫秒。该参数只适用于分布式锁的加锁请求中未明确使用 leaseTimeout 参数的情况。如果该看门狗未使用 lockWatchdogTimeout 去重新调整一个分布式锁的 lockWatchdogTimeout 超时,那么这个锁将变为失效状态。这个参数可以用来避免由 Redisson 客户端节点宕机或其他原因造成死锁的情况。
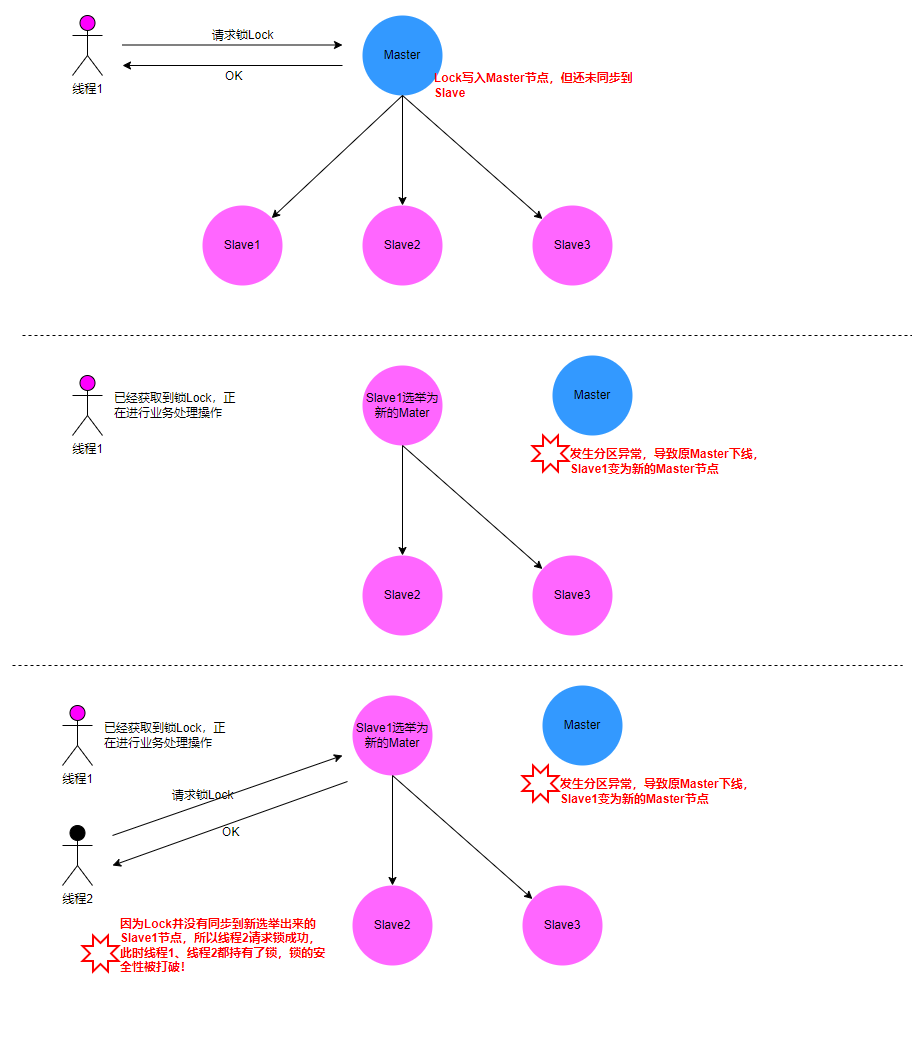
Redis 主从架构数据同步复制问题
我们通常使用「Redis Cluster」或者「哨兵模式」这两种方式实现 Redis 的高可用,而这两种方式都是基于「主从架构数据同步复制」实现的,而 Redis 默认的主从复制是异步的。
前面铺垫的 Redis 锁在单点实例中是没有问题的,因为并没有涉及 Redis 的高可用部署架构细节。但是如果多实例的情况下会出现什么问题呢?比如:主从、或者使用了哨兵模式、或者 Redis cluster。Redis 的主从架构如下所示:

丢失数据场景:当网络发生脑裂(split-brain)或者 partitioned cluster 集群分裂为多数派与少数派,如果数据继续写入少数派的 Master,则当 Cluster 感知,并停止少数派 Master,或者重新选主时,则面临丢失刚才已写入少数派的数据
主从发生重新选导致分布式锁出现问题的场景:
WAIT 命令能够为 Redis 实现强一致吗?
WAIT numreplicas timeout
- numreplicas:指定副本(slave)的数量。
- timeout:超时时间,时间单位为毫秒;当设置为 0 时,表示无限等待,即用不超时。
WAIT 命令作用:WAIT 命令阻塞当前客户端,直到所有先前的写入命令成功传输,并且由至少指定数量的副本(slave)确认。在主从、sentinel 和 Redis 群集故障转移中, WAIT 能够增强(仅仅是增强,但不是保证)数据的安全性。
官方文档:https://redis.io/commands/wait

Redlock 算法
针对上面的问题,Redis 之父 antirez 设计了 Redlock 算法,Redlock 的算法描述就放在 Redis 的官网上:
- https://redis.io/topics/distlock
在 Redlock 之前,很多人对于分布式锁的实现都是基于单个 Redis 节点的。而 Redlock 是基于多个 Redis 节点(都是 Master)的一种实现。前面基于单 Redis 节点的算法是 Redlock 的基础。
加锁
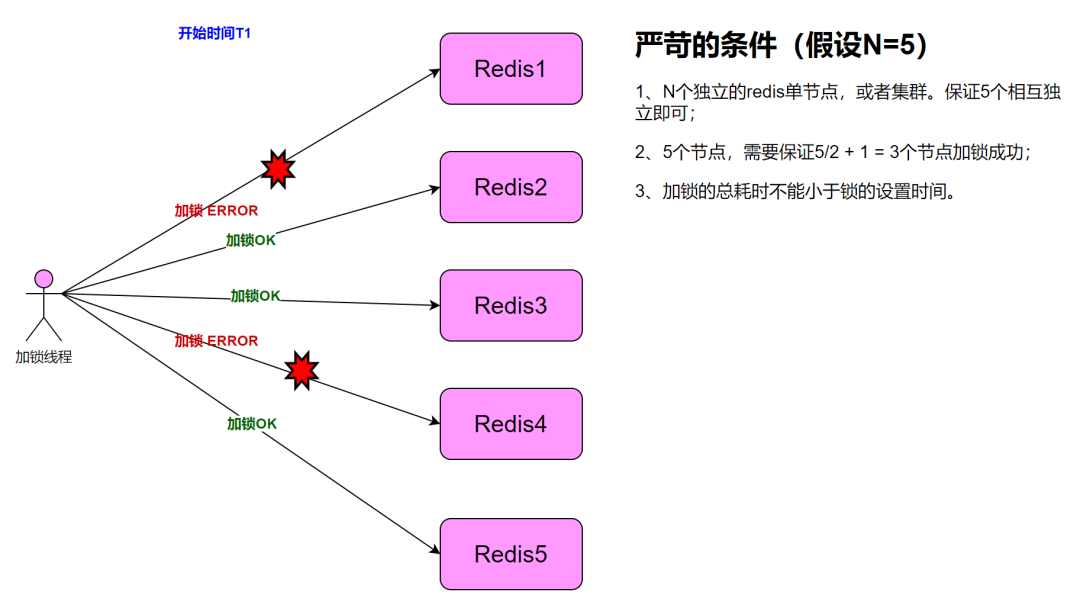
Redlock 算法基于 N 个完全独立的 Redis 节点,客户端依次执行下面各个步骤,来完成获取锁的操作:
- 获取当前时间 T1(毫秒数)。
- 使用相同的 key、value 按顺序依次向 N 个 Redis 节点执行获取锁的操作。这个获取操作跟前面基于单 Redis 节点的获取锁的过程相同,包含随机字符串 my_random_value,也包含过期时间(比如 PX 30000,即锁的有效时间)。为了保证在某个 Redis 节点不可用的时候算法能够继续运行,这个获取锁的操作还有一个超时时间(time out),它要远小于锁的有效时间(几十毫秒量级)。客户端在向某个 Redis 节点获取锁失败以后,应该立即尝试下一个 Redis 节点。
- 获取当前时间 T2 减去步骤 1 中的 T1,计算获取锁消耗了多长时间(T3= T2-T1),计算方法是用当前时间减去第 1 步记录的时间。如果客户端从大多数 Redis 节点(大于等于 N/2+1)成功获取到了锁,并且获取锁总共消耗的时间没有超过锁的有效时间(lock validity time),那么这时客户端才认为最终获取锁成功;否则,认为最终获取锁失败。
- 如果最终获取锁成功了,那么这个锁的有效时间应该重新计算,它等于最初的锁的有效时间减去第 3 步计算出来的获取锁消耗的时间。
- 如果最终获取锁失败了(可能由于获取到锁的 Redis 节点个数少于 N/2+1,或者整个获取锁的过程消耗的时间超过了锁的最初有效时间),那么客户端应该立即向所有 Redis 节点发起释放锁的操作(即前面介绍的 Redis Lua 脚本)。
注意!!!redLock 会直接连接多个 Redis 主节点,不是通过集群机制连接的。
RedLock 的写与主从集群无关,直接操作的是所有主节点,所以才能避开主从故障切换时锁丢失的问题。
失败重试(脑裂问题)
高并发场景下,当多个加锁线程并发抢锁时,可能导致脑裂,最终造成任何一个线程都无法抢到锁的情况。
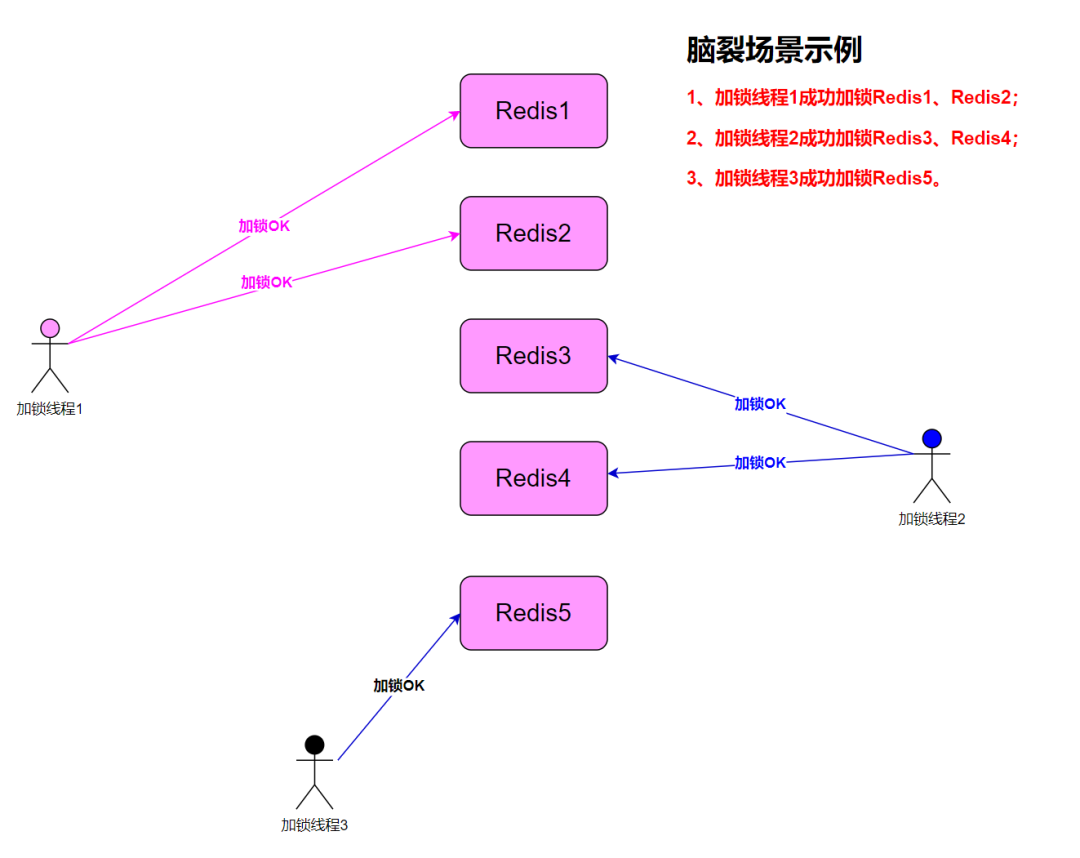
值得强调的是,如果获取大部分锁失败,加锁线程应该尽可能快的释放(部分)已经获得了的锁。所以为了让锁能够再次被获得就没有必要等待 key 过期(然而如果发生了网络分区导致客户端无法再与 Redis 实例交互,那么就必须等待 key 过期才能重新抢到锁)。
释放锁
Redlock 算法释放锁的过程比较简单:客户端向所有 Redis 节点发起释放锁的操作,不管这些节点当时在获取锁的时候成功与否。
问题 1:为什么要在多个实例上加锁?
本质上为了容错,部分实例异常宕机,剩余实例只要超过 N/2+1 依旧可用。多个实例节点,实际上构建了一个分布式锁系统。分布式系统中,总会有异常节点,所以需要考虑异常节点达到多少个,也不会影响整个系统的正确性。(可以参考一下拜占庭将军问题的分析)
问题 2:为什么步骤 3 加锁成功之后,还要计算加锁的累计耗时?
因为加锁操作的针对的是分布式中的多个节点,所以耗时肯定是比单个实例耗时更久,至少需要 N/2+1 个网络来回,还要考虑网络延迟、丢包、超时等情况发生,网络请求次数越多,异常的概率越大。所以即使 N/2+1 个节点加锁成功,但如果加锁的累计耗时已经超过了锁的过期时间,那么此时的锁已经没有意义了。
问题 3:为什么释放锁,要操作所有节点,对所有节点都释放锁?
因为当对某一个 Redis 节点加锁时,可能因为网络原因导致加锁“失败”。注意这个“失败”,指的是 Redis 节点实际已经加锁成功了,但是返回的结果因为网络延迟并没有传到加锁的线程,被加锁线程丢弃了,加锁线程误以为没有成功,于是加锁线程去尝试下一个节点了。
所以释放锁的时候,不管以前有没有加锁成功,都要释放所有节点的锁,以保证清除节点上述图中发生的情况导致残留的锁。
崩溃恢复(AOF 持久化)对 Redlock 算法影响
假设 Rodlock 算法中的 Redis 发生了崩溃-恢复,那么锁的安全性将无法保证。假设加锁线程在 5 个实例中对其中 3 个加锁成功,获得了这把分布式锁,这个时候 3 个实例中有一个实例被重启了。重启后的实例将丢失其中的锁信息,这个时候另一个加锁线程可以对这个实例加锁成功,此时两个线程同时持有分布式锁。锁的安全性被破坏。
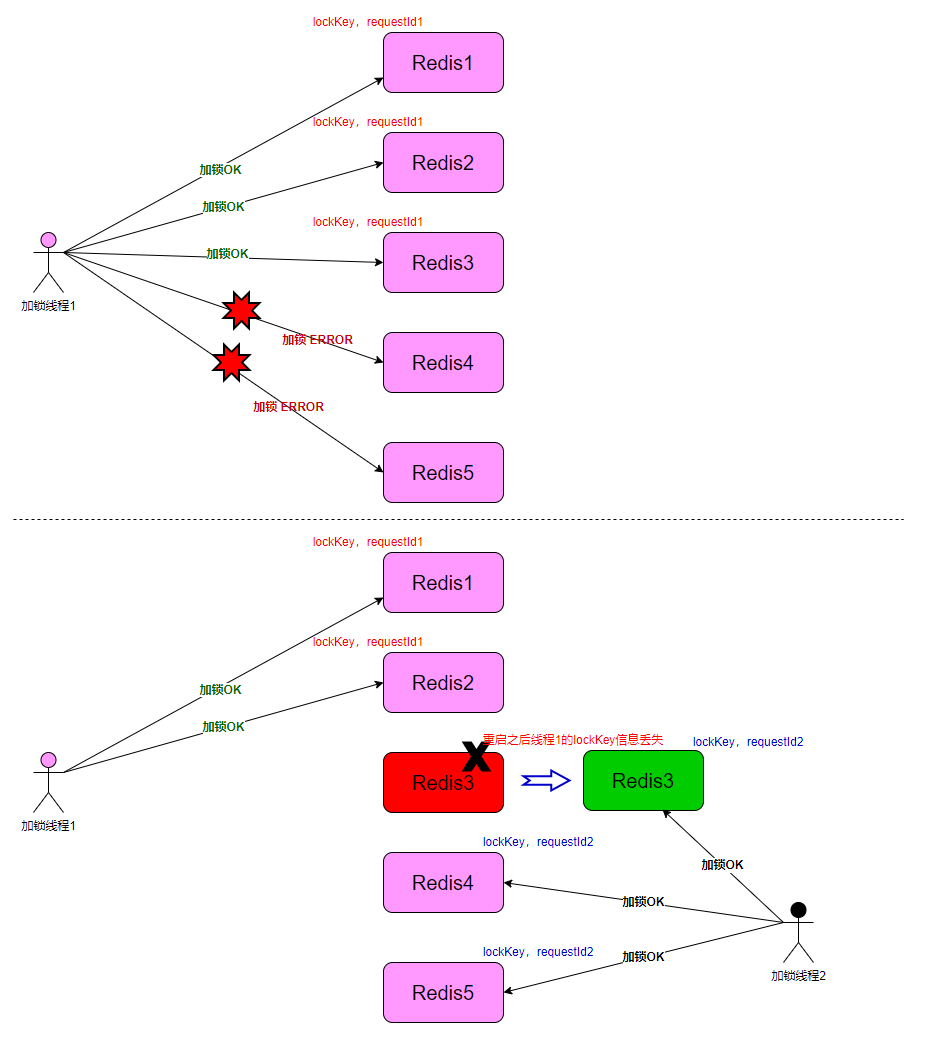
fsync=always,但此时 Redis 的性能将大大打折扣。
为了保证这一点,我们只需要让一个崩溃时间、不可用时间(实例崩溃后存在的锁的所有 key 所需的时间)比最大 TTL 还要长的实例变成非法和自动释放的。
如果不配置 Redis 持久化,那么只能使用延迟重启保证锁的安全性。
结论:为了保证 Redlock 算法的安全性,有如下两种手段
- 持久化配置中设置
fsync=always,性能大大降低 - 恰当的运维,把崩溃节点进行延迟重启,超过崩溃前所有锁的 TTL 时间之后才加入 Redlock 节点组
Redis 分布式锁官方文档翻译

Redlock 算法存在的问题
Redlock 论战:Martin Kleppmann vs. Antirez
- Martin Kleppmann 是剑桥大学的分布式系统专家,《数据密集型应用系统设计》一书的作者。
- Antirez 是 redis 的作者,redlock 算法的作者。
Redis 之父 Antirez 实现 Redlock 算法之后。有一天,Martin Kleppmann 写了一篇 blog,分析了 Redlock 在安全性上存在的一些问题。然后 Redis 的作者立即写了一篇 blog 来反驳 Martin 的分析。但 Martin 表示仍然坚持原来的观点。随后,这个问题在 Twitter 和 Hacker News 上引发了激烈的讨论,很多分布式系统的专家都参与其中。



- https://redis.io/topics/distlock
- https://martin.kleppmann.com/2016/02/08/how-to-do-distributed-locking.html
- http://antirez.com/news/101
Martin Kleppmann 在 2016-02-08 这一天发表了一篇 blog,名字叫“How to do distributed locking”,地址如下:
- https://martin.kleppmann.com/2016/02/08/how-to-do-distributed-locking.html
Martin 在这篇文章中谈及了分布式系统的很多基础性的问题(特别是分布式计算的异步模型),对分布式系统的从业者来说非常值得一读。这篇文章大体可以分为两大部分:
- 前半部分,与 Redlock 无关。Martin 指出,即使我们拥有一个完美实现的分布式锁(带自动过期功能),在没有共享资源参与进来提供某种 fencing 机制的前提下,我们仍然不可能获得足够的安全性。
- 后半部分,是对 Redlock 本身的批评。Martin 指出,由于 Redlock 本质上是建立在一个同步模型之上,对系统的记时假设(timing assumption)有很强的要求,因此本身的安全性是不够的。
客户端长期阻塞导致锁过期
首先我们讨论一下前半部分的关键点。Martin 给出了下面这样一份时序图:
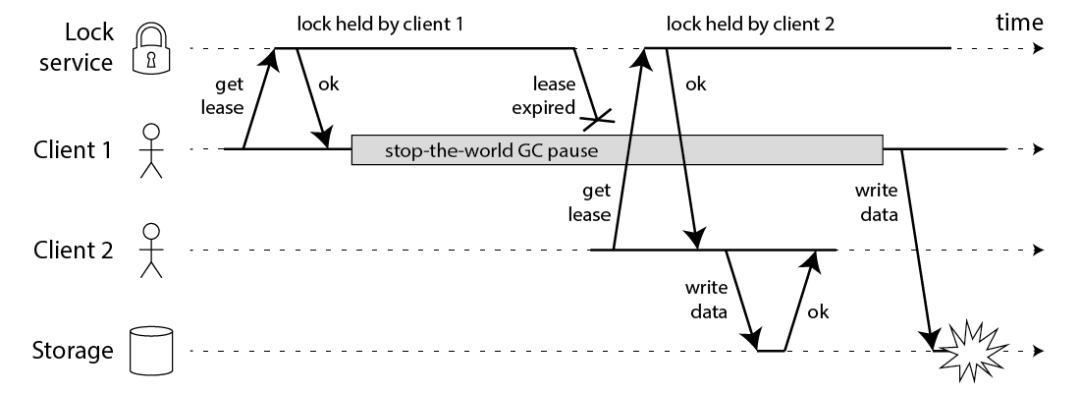
初看上去,有人可能会说,既然客户端 1 从 GC pause 中恢复过来以后不知道自己持有的锁已经过期了,那么它可以在访问共享资源之前先判断一下锁是否过期。但仔细想想,这丝毫也没有帮助。因为 GC pause 可能发生在任意时刻,也许恰好在判断完之后。
也有人会说,如果客户端使用没有 GC 的语言来实现,是不是就没有这个问题呢?Martin 指出,系统环境太复杂,仍然有很多原因导致进程的 pause,比如虚存造成的缺页故障(page fault),再比如 CPU 资源的竞争。即使不考虑进程 pause 的情况,网络延迟也仍然会造成类似的结果。
总结起来就是说,即使锁服务本身是没有问题的,而仅仅是客户端有长时间的 pause 或网络延迟,仍然会造成两个客户端同时访问共享资源的冲突情况发生。而这种情况其实就是我们在前面已经提出来的“客户端长期阻塞导致锁过期”的那个疑问。
解决方案——fencing token
那怎么解决这个问题呢?Martin 给出了一种方法,称为 fencing token。fencing token 是一个单调递增的数字,当客户端成功获取锁的时候它随同锁一起返回给客户端。而客户端访问共享资源的时候带着这个 fencing token,这样提供共享资源的服务就能根据它进行检查,拒绝掉延迟到来的访问请求(避免了冲突)。如下图:
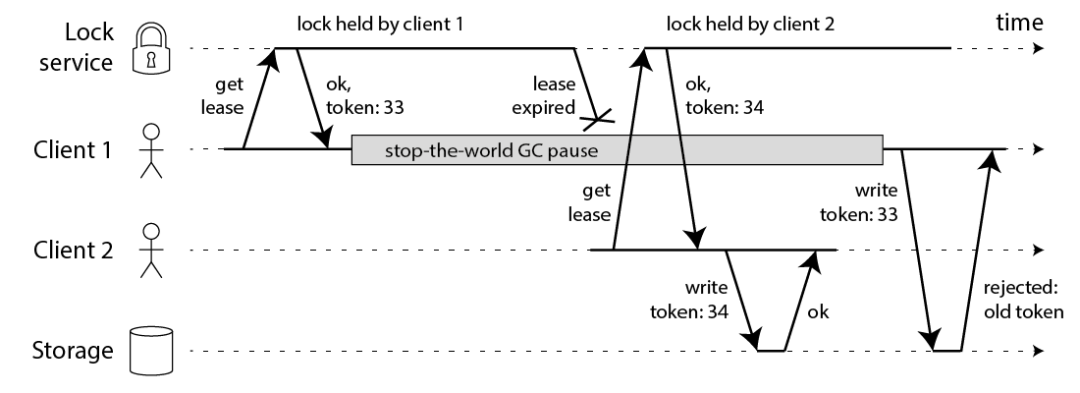
(问题:考虑网络延迟导致 33 号 token 比 34 号先到的情景)
时间跳跃
Martin 在文中构造了一些事件序列,能够让 Redlock 失效(两个客户端同时持有锁)。为了说明 Redlock 对系统记时(timing)的过分依赖,他首先给出了下面的一个例子(还是假设有 5 个 Redis 节点 A, B, C, D, E):
- 客户端 1 从 Redis 节点 A, B, C 成功获取了锁(多数节点)。由于网络问题,与 D 和 E 通信失败。
- 节点 C 上的时钟发生了向前跳跃,导致它上面维护的锁快速过期。
- 客户端 2 从 Redis 节点 C, D, E 成功获取了同一个资源的锁(多数节点)。
- 客户端 1 和客户端 2 现在都认为自己持有了锁。
上面这种情况之所以有可能发生,本质上是因为Redlock 的安全性(safety property)对系统的时钟有比较强的依赖,一旦系统的时钟变得不准确,算法的安全性也就保证不了了。Martin 在这里其实是要指出分布式算法研究中的一些基础性问题,或者说一些常识问题,即好的分布式算法应该基于异步模型(asynchronous model),算法的安全性不应该依赖于任何记时假设(timing assumption)。在异步模型中:进程可能 pause 任意长的时间,消息可能在网络中延迟任意长的时间,甚至丢失,系统时钟也可能以任意方式出错。一个好的分布式算法,这些因素不应该影响它的安全性(safety property),只可能影响到它的活性(liveness property),也就是说,即使在非常极端的情况下(比如系统时钟严重错误),算法顶多是不能在有限的时间内给出结果而已,而不应该给出错误的结果。这样的算法在现实中是存在的,像比较著名的Paxos,或 Raft。但显然按这个标准的话,Redlock 的安全性级别是达不到的。
在 Martin 的这篇文章中,还有一个很有见地的观点,就是对锁的用途的区分。他把锁的用途分为两种:
- 为了效率(efficiency),协调各个客户端避免做重复的工作。即使锁偶尔失效了,只是可能把某些操作多做一遍而已,不会产生其它的不良后果。比如重复发送了一封同样的 email。
- 为了正确性(correctness)。在任何情况下都不允许锁失效的情况发生,因为一旦发生,就可能意味着数据不一致(inconsistency),数据丢失,文件损坏,或者其它严重的问题。
最后,Martin 得出了如下的结论:
- 如果是为了效率(efficiency)而使用分布式锁,允许锁的偶尔失效,那么使用单 Redis 节点的锁方案就足够了,简单而且效率高。Redlock 则是个过重的实现(heavyweight)。
- 如果是为了正确性(correctness)在很严肃的场合使用分布式锁,那么不要使用 Redlock。它不是建立在异步模型上的一个足够强的算法,它对于系统模型的假设中包含很多危险的成分(对于 timing)。而且,它没有一个机制能够提供 fencing token。那应该使用什么技术呢?Martin 认为,应该考虑类似 Zookeeper 的方案,或者支持事务的数据库。
Martin 对 Redlock 算法的形容是:
neither fish nor fowl (不伦不类)
【其它疑问】
- Martin 提出的 fencing token 的方案,需要对提供共享资源的服务进行修改,这在现实中可行吗?
- 根据 Martin 的说法,看起来,如果资源服务器实现了 fencing token,它在分布式锁失效的情况下也仍然能保持资源的互斥访问。这是不是意味着分布式锁根本没有存在的意义了?
- 资源服务器需要检查 fencing token 的大小,如果提供资源访问的服务也是包含多个节点的(分布式的),那么这里怎么检查才能保证 fencing token 在多个节点上是递增的呢?
- Martin 对于 fencing token 的举例中,两个 fencing token 到达资源服务器的顺序颠倒了(小的 fencing token 后到了),这时资源服务器检查出了这一问题。如果客户端 1 和客户端 2 都发生了 GC pause,两个 fencing token 都延迟了,它们几乎同时到达了资源服务器,但保持了顺序,那么资源服务器是不是就检查不出问题了?这时对于资源的访问是不是就发生冲突了?
问题一:节点重启
N 个 Redis 节点中如果有节点发生崩溃重启,会对锁的安全性有影响的。具体的影响程度跟 Redis 对数据的持久化程度有关。参考上面的“崩溃恢复(AOF 持久化)对 Redlock 算法影响”分析。
【备注】在默认情况下,Redis 的 AOF 持久化方式是每秒写一次磁盘(即执行 fsync),因此最坏情况下可能丢失 1 秒的数据。为了尽可能不丢数据,Redis 允许设置成每次修改数据都进行 fsync,但这会降低性能。当然,即使执行了 fsync 也仍然有可能丢失数据(这取决于系统而不是 Redis 的实现)。所以,上面分析的由于节点重启引发的锁失效问题,总是有可能出现的。
如何解决这个问题?
Redis 之父 antirez 提出了延迟重启(delayed restarts)的概念。也就是说,一个节点崩溃后,先不立即重启它,而是等待一段时间再重启,这段时间应该大于锁的有效时间(lock validity time)。这样的话,这个节点在重启前所参与的锁都会过期,它在重启后就不会对现有的锁造成影响。

问题二:时钟变迁
Redlock 的安全性(safety property)对系统的时钟有比较强的依赖,一旦系统的时钟变得不准确,算法的安全性也就保证不了了。
结论:Redis 的过期时间是依赖系统时钟的,如果时钟漂移过大时会影响到过期时间的计算。
为什么系统时钟会存在漂移呢?先简单说下系统时间,linux 提供了两个系统时间:clock realtime 和 clock monotonic
- clock realtime 也就是 xtime/wall time,这个时间是可以被用户改变的,被 NTP 改变。Redis 的判断超时使用的 gettimeofday 函数取的就是这个时间,Redis 的过期计算用的也是这个时间。参考https://blog.habets.se/2010/09/gettimeofday-should-never-be-used-to-measure-time.html
- clock monotonic,直译过来是单调时间,不会被用户改变,但是会被 NTP 改变。
最理想的情况是:所有系统的时钟都时时刻刻和 NTP 服务器保持同步,但这显然是不可能的。
clock realtime 可以被人为修改,在实现分布式锁时,不应该使用 clock realtime。不过很可惜,Redis 使用的就是这个时间,Redis 5.0 使用的还是 clock realtime。Antirez 说过后面会改成 clock monotonic 的。也就是说,人为修改 Redis 服务器的时间,就能让 Redis 出问题了。
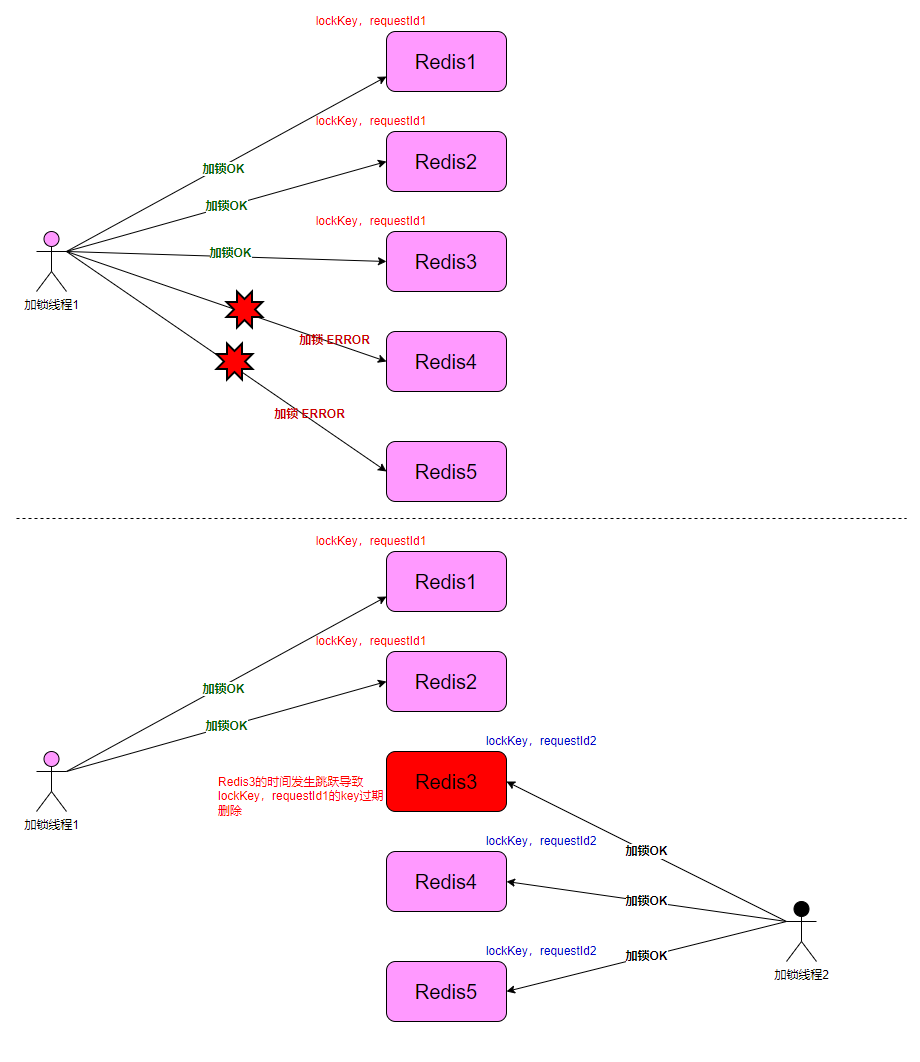
- 加锁线程 1 从节点 Redis1, Redis2, Redis3 成功获取了锁(多数节点)。由于网络问题,与 Redis4、Redis5 通信失败。
- 节点 Redis3 上的时钟发生了向前跳跃,导致它上面维护的锁快速过期。
- Redis5 成功获取了同一个资源的锁(多数节点)。
- 加锁线程 1 和加锁线程 2 现在都认为自己持有了锁。
什么情况下会发生时钟变迁?
- 人为修改了时钟
- 从 NTP 服务收到了一个大的时钟更新事件导致时钟漂移
- 闰秒(是指为保持协调世界时接近于世界时时刻,由国际计量局统一规定在年底或年中或者季末对协调世界时增加或减少 1 秒的调整,此时一分钟为 59 秒或者 61 秒,闰秒曾使许多大型系统崩溃)
- ……
如何解决这个问题?
- Redis 之父 antirez 在 Redlock 论战中的解释:实际系统中是可以避免大的时钟跳跃的。当然,这取决于基础设施和运维方式。(实际上这种理想情况是很难达到的,不同的 redis 节点,毫秒级别的时间误差几乎是必然存在的。)
- Fencing token 机制:类似 raft 算法、zab 协议中的全局递增数字,对这个 token 的校验需要后端资源进行校验,如此一来,相当于后端资源具备了互斥机制,这种情况下为什么还要一把分布式锁呢?而且涉及到后端资源的改造。
总结
- RedLock 算法数建立在了 Time 是可信的模型上的一种分布式锁,所以时间被破坏的情况下它无法实现锁的绝对安全;
- RedLock 算法实现比较复杂,并且性能比较差;
- RedLock 需要恰当的运维保障它的正确性,故障-崩溃之后需要一套延迟重启的机制
RedLock 的核心价值,在于多数派思想。相比于基于单点 Redis 的锁服务,RedLock 解决了锁数据写入时多份的问题,从而可以克服单点故障下的数据一致性问题。在继承自基于单点的 Redis 锁服务缺陷(解锁不具备原子性;锁服务、调用方、资源方缺乏确认机制)的基础上,其核心的问题为:缺乏锁数据丢失的识别和感知机制。
RedLock 中的每台 Redis,充当的仍旧只是存储锁数据的功能,每台 Redis 之间各自独立,单台 Redis 缺乏全局的信息,自然也不知道自己的锁数据是否是完整的。在单台 Redis 数据的不完整的前提下,没有分布式共识机制,使得在各种分布式环境的典型场景下(结点故障、网络丢包、网络乱序),没有完整数据但参与决策,从而破坏数据一致性。
基于 MySQL 的分布式锁(ShedLock)
使用 ShedLock 需要在 MySQL 数据库创建一张加锁用的表:
CREATE TABLE shedlock
(
name VARCHAR(64),
lock_until TIMESTAMP(3) NULL,
locked_at TIMESTAMP(3) NULL,
locked_by VARCHAR(255),
PRIMARY KEY (name)
)加锁
- 通过插入同一个 name(primary key),或者更新同一个 name 来抢,对应的 intsert、update 的 SQL 为:
INSERT INTO shedlock
(name, lock_until, locked_at, locked_by)
VALUES
(锁名字, 当前时间+最多锁多久, 当前时间, 主机名)UPDATE shedlock
SET lock_until = 当前时间+最多锁多久,
locked_at = 当前时间,
locked_by = 主机名 WHERE name = 锁名字 AND lock_until <= 当前时间释放锁:
- 通过设置 lock_until 来实现释放,再次抢锁的时候需要通过 lock_util 来判断锁失效了没。对应的 SQL 为:
UPDATE shedlock
SET lock_until = lockTime WHERE name = 锁名字问题分析
- 单点问题;
- 主从同步问题。假如使用全同步模式,分布式锁将会有性能上的问题。
基于 ZooKeeper 的分布式锁
ZooKeeper 的节点类型
ZooKeeper 的数据存储结构就像一棵树,这棵树由节点组成,这种节点叫做 Znode。Znode 分为四种类型:
1 . 持久节点 (PERSISTENT)
默认的节点类型。创建节点的客户端与 ZooKeeper 断开连接后,该节点依旧存在 。
2 . 持久节点顺序节点(PERSISTENT_SEQUENTIAL)
所谓顺序节点,就是在创建节点时,ZooKeeper 根据创建的顺序给该节点名称进行编号:
3 . 临时节点(EPHEMERAL)
和持久节点相反,当创建节点的客户端与 ZooKeeper 断开连接后,临时节点会被删除:
4 . 临时顺序节点(EPHEMERAL_SEQUENTIAL)【使用该类型节点实现分布式锁】
顾名思义,临时顺序节点结合和临时节点和顺序节点的特点:在创建节点时,ZooKeeper 根据创建的时间顺序给该节点名称进行编号;当创建节点的客户端与 ZooKeeper 断开连接后,临时节点会被删除。
ZooKeeper 的 watch 机制
ZooKeeper 集群和客户端通过长连接维护一个 session,当客户端试图创建/lock 节点的时候,发现它已经存在了,这时候创建失败,但客户端不一定就此返回获取锁失败。客户端可以进入一种等待状态,等待当/lock 节点被删除的时候,ZooKeeper 通过 watch 机制通知它,这样它就可以继续完成创建操作(获取锁)。这可以让分布式锁在客户端用起来就像一个本地的锁一样:加锁失败就阻塞住,直到获取到锁为止。这样的特性 Redis 的 Redlock 就无法实现。
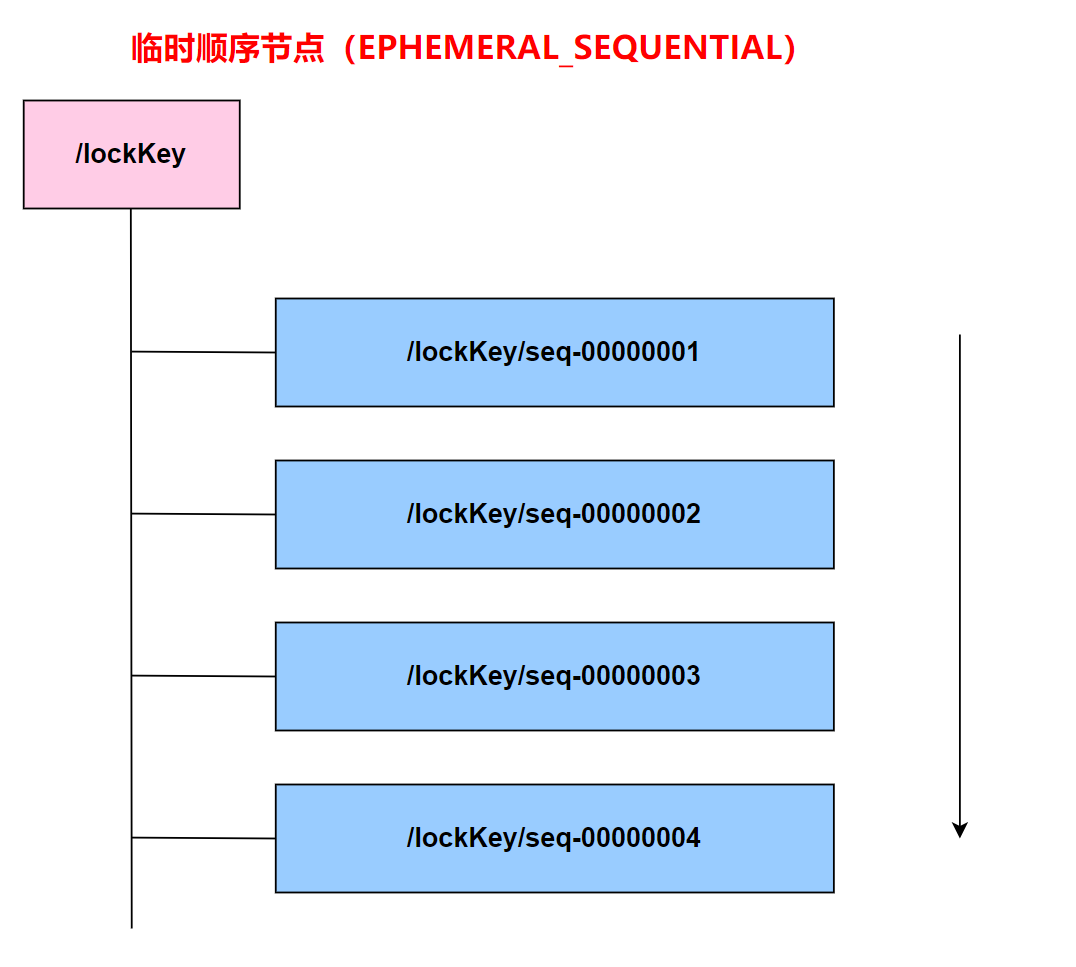
加锁&释放锁
- 客户端尝试创建一个 znode 节点,比如/lock。那么第一个客户端就创建成功了,相当于拿到了锁;而其它的客户端会创建失败(znode 已存在),获取锁失败。
- 持有锁的客户端访问共享资源完成后,将 znode 删掉,这样其它客户端接下来就能来获取锁了。(客户端删除锁)
- znode 应该被创建成 EPHEMERAL_SEQUENTIAL 的。这是 znode 的一个特性,它保证如果创建 znode 的那个客户端崩溃了,那么相应的 znode 会被自动删除。这保证了锁一定会被释放(ZooKeeper 服务器自己删除锁)。另外保证了公平性,后面创建的节点会加在节点链最后的位置,等待锁的客户端会按照先来先得的顺序获取到锁。
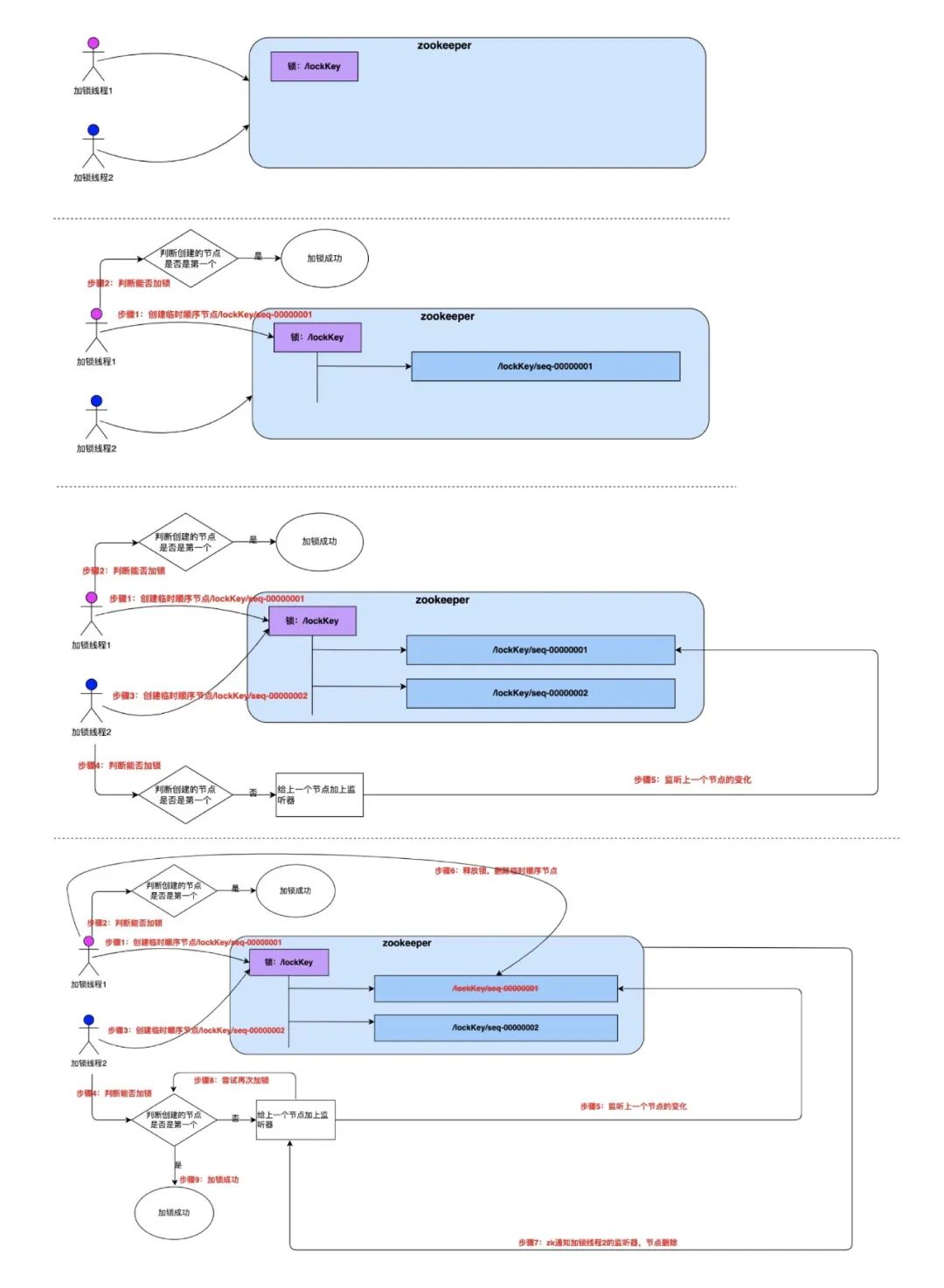
时钟变迁问题
ZooKeeper 不依赖全局时间,它使用 zab 协议实现分布式共识算法,不存在该问题。
超时导致锁失效问题
ZooKeeper 不依赖有效时间,它依靠心跳维持锁的占用状态,不存在该问题。
看起来这个锁相当完美,没有 Redlock 过期时间的问题,而且能在需要的时候让锁自动释放。但仔细考察的话,并不尽然。客户端可以删除锁,Z**ooKeeper 服务器也可以删除锁,**会引发什么问题。
ZooKeeper 是怎么检测出某个客户端已经崩溃了呢?
实际上,每个客户端都与 ZooKeeper 的某台服务器维护着一个 Session,这个 Session 依赖定期的心跳(heartbeat)来维持。如果 ZooKeeper 长时间收不到客户端的心跳(这个时间称为 Sesion 的过期时间),那么它就认为 Session 过期了,通过这个 Session 所创建的所有的 ephemeral 类型的 znode 节点都会被自动删除。
基于 ZooKeeper 的分布式锁存在的问题:
- 客户端 1 创建了 znode 节点/lock,获得了锁。
- 客户端 1 进入了长时间的 GC pause。(或者网络出现问题、或者 zk 服务检测心跳线程出现问题等等)
- 客户端 1 连接到 ZooKeeper 的 Session 过期了。znode 节点/lock 被自动删除。
- 客户端 2 创建了 znode 节点/lock,从而获得了锁。
- 客户端 1 从 GC pause 中恢复过来,它仍然认为自己持有锁。
这个场景下,客户端 1 和客户端 2 在一段窗口时间内同时获取到锁。
结论:使用 ZooKeeper 的临时节点实现的分布式锁,它的锁安全期是在客户端取得锁之后到 zk 服务器会话超时的阈值(跨机房部署很容易出现)的时间之间。它无法设置占用分布式锁的时间,何时 zk 服务器会删除锁是不可预知的,所以这种方式它比较适合一些客户端获取到锁之后能够快速处理完毕的场景。
另一种方案
另外一种使用 zk 作分布式锁的实现方式:不使用临时节点,而是使用持久节点加锁,把 zk 集群当做一个 MySQL、或者一个单机版的 Redis,加锁的时候存储锁的到期时间,这种方案把锁的删除、判断过期这两个职责交给客户端处理。(当做一个可以容错的 MySQL,性能问题!)
ZooKeeper 分布式锁的优点和缺点
总结一下 ZooKeeper 分布式锁:
优点:
- ZooKeeper 分布式锁基于分布式一致性算法实现,能有效的解决分布式问题,不受时钟变迁影响,不可重入问题,使用起来也较为简单;
- 当锁持有方发生异常的时候,它和 ZooKeeper 之间的 session 无法维护。ZooKeeper 会在 Session 租约到期后,自动删除该 Client 持有的锁,以避免锁长时间无法释放而导致死锁。
缺点:
ZooKeeper 实现的分布式锁,性能并不太高。为啥呢?
因为每次在创建锁和释放锁的过程中,都要动态创建、销毁瞬时节点来实现锁功能。大家知道,ZK 中创建和删除节点只能通过 Leader 服务器来执行,然后 Leader 服务器还需要将数据同步不到所有的 Follower 机器上,这样频繁的网络通信,性能的短板是非常突出的。
总之,在高性能,高并发的场景下,不建议使用 ZooKeeper 的分布式锁。而由于 ZooKeeper 的高可用特性,所以在并发量不是太高的场景,推荐使用 ZooKeeper 的分布式锁。
小结一下,基于 ZooKeeper 的锁和基于 Redis 的锁相比在实现特性上有两个不同:
- 在正常情况下,客户端可以持有锁任意长的时间,这可以确保它做完所有需要的资源访问操作之后再释放锁。这避免了基于 Redis 的锁对于有效时间(lock validity time)到底设置多长的两难问题。实际上,基于 ZooKeeper 的锁是依靠 Session(心跳)来维持锁的持有状态的,而 Redis 不支持 Sesion。
- 基于 ZooKeeper 的锁支持在获取锁失败之后等待锁重新释放的事件。这让客户端对锁的使用更加灵活。
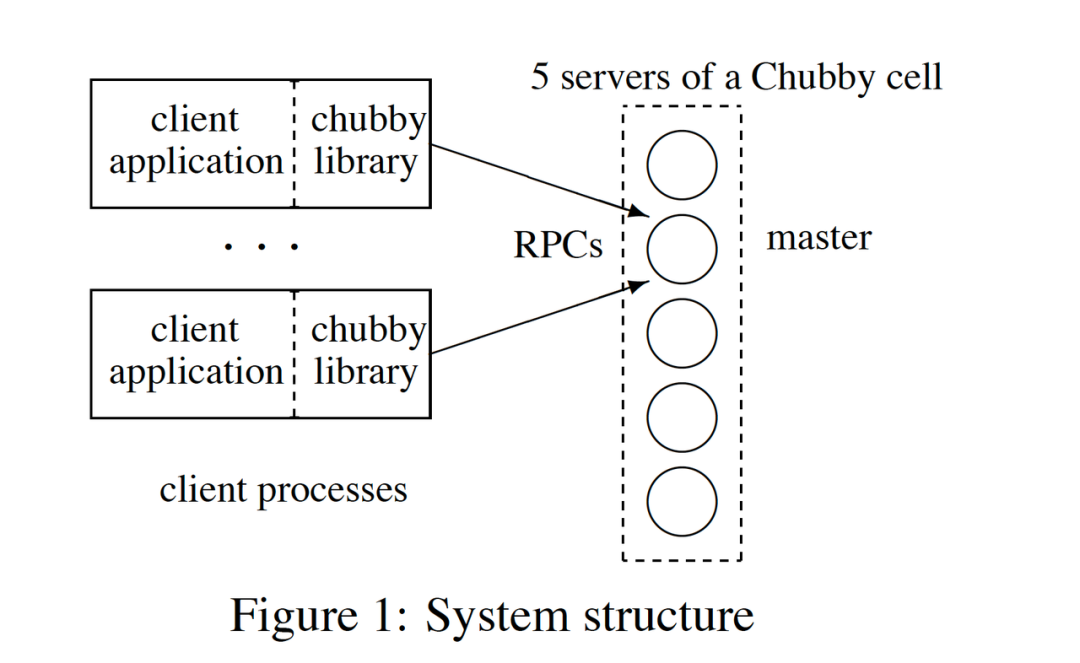
Chubby
提到分布式锁,就不能不提 Google 的 Chubby。
Chubby 是 Google 内部使用的分布式锁服务,有点类似于 ZooKeeper,但也存在很多差异。Chubby 对外公开的资料,主要是一篇论文,叫做“The Chubby lock service for loosely-coupled distributed systems”,下载地址如下:
- https://research.google.com/archive/chubby.html
另外,YouTube 上有一个的讲 Chubby 的 talk,也很不错,播放地址:
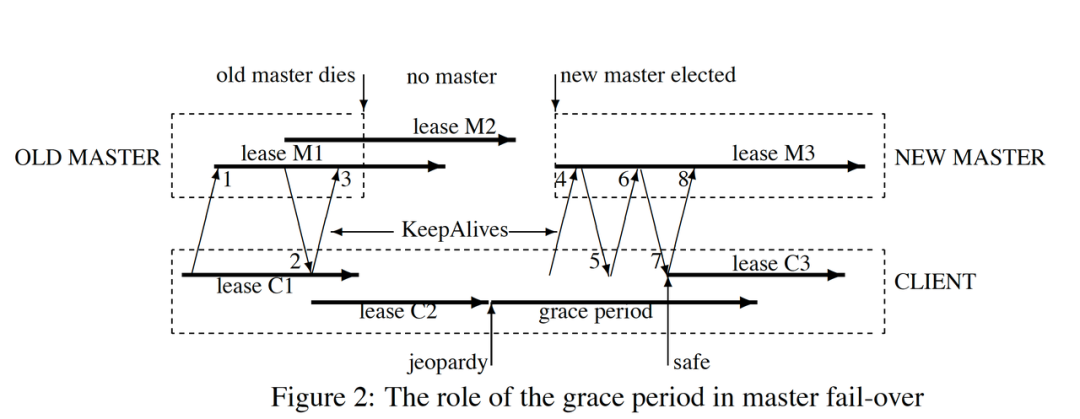
- https://www.youtube.com/watch?v=PqItueBaiRg&feature=youtu.be&t=487 Chubby 自然也考虑到了延迟造成的锁失效的问题。论文里有一段描述如下:
a process holding a lock L may issue a request R, but then fail. Another process may ac- quire L and perform some action before R arrives at its destination. If R later arrives, it may be acted on without the protection of L, and potentially on inconsistent data.
(译文:一个进程持有锁 L,发起了请求 R,但是请求失败了。另一个进程获得了锁 L 并在请求 R 到达目的方之前执行了一些动作。如果后来请求 R 到达了,它就有可能在没有锁 L 保护的情况下进行操作,带来数据不一致的潜在风险。)
这跟前面 Martin 的分析大同小异。
- 锁的名字。
- 锁的获取模式(排他锁还是共享锁)。
- lock generation number(一个 64bit 的单调递增数字)。作用相当于 fencing token 或 epoch number。
sequencer:客户端拿到 sequencer 之后,在操作资源的时候把它传给资源服务器。然后,资源服务器负责对 sequencer 的有效性进行检查。检查可以有两种方式:
- 调用 Chubby 提供的 API,CheckSequencer(),将整个 sequencer 传进去进行检查。这个检查是为了保证客户端持有的锁在进行资源访问的时候仍然有效。
- 将客户端传来的 sequencer 与资源服务器当前观察到的最新的 sequencer 进行对比检查。可以理解为与 Martin 描述的对于 fencing token 的检查类似。
锁延期机制:当然,如果由于兼容的原因,资源服务本身不容易修改,那么 Chubby 还提供了一种机制:
- lock-delay。Chubby 允许客户端为持有的锁指定一个 lock-delay 的时间值(默认是 1 分钟)。当 Chubby 发现客户端被动失去联系的时候,并不会立即释放锁,而是会在 lock-delay 指定的时间内阻止其它客户端获得这个锁。这是为了在把锁分配给新的客户端之前,让之前持有锁的客户端有充分的时间把请求队列排空(draining the queue),尽量防止出现延迟到达的未处理请求。
可见,为了应对锁失效问题,Chubby 提供的两种处理方式:CheckSequencer()检查与上次最新的 sequencer 对比、lock-delay,它们对于安全性的保证是从强到弱的。而且,这些处理方式本身都没有保证提供绝对的正确性(correctness)。但是,Chubby 确实提供了单调递增的 lock generation number,这就允许资源服务器在需要的时候,利用它提供更强的安全性保障。
总结起来,Chubby 引入了资源方和锁服务的验证,来避免了锁服务本身孤立地做预防死锁机制而导致的破坏锁安全性的风险。同时依靠 Session 来维持锁的持有状态,在正常情况下,客户端可以持有锁任意长的时间,这可以确保它做完所有需要的资源访问操作之后再释放锁。这避免了基于 Redis 的锁对于有效时间(lock validity time)到底设置多长的两难问题。
总结
- 基于 ZooKeeper 的分布式锁,适用于高可靠(高可用)而并发量不是太大的场景;
- 基于 Redis 的分布式锁,适用于并发量很大、性能要求很高的、而可靠性问题可以通过其他方案去弥补的场景。
- 基于 MySQL 的分布式锁一般均有单点问题,高并发场景下对数据库的压力比较大;
需要考虑的问题:我们的业务对极端情况的容忍度,为了一把绝对安全的分布式锁导致过度设计,引入的复杂性和得到的收益是否值得。