深入浅出富文本编辑器
编辑器介绍
常见的富文本编辑器现实方式可以分成两大类,分别是用 textarea 和 contenteditable 来实现。
textarea
结构简单使用方便,一些文本格式和复杂的样式难以实现,推荐仅在对编辑要求不高的场景使用。
contenteditable
将元素的 contenteditable 属性设为 true时,该元素则成为了编辑器的主体。配合 document.execCommand 能够实现绝大多数功能,主流编辑器是基于 contenteditable 来设计的。
但是单纯依赖 contenteditable 直接产出 html 会带来一些问题,例如相同的输入在不同浏览器下的输出可能不一致,相同的输出在不同浏览器中展示存在差异,并且这些问题在移动端会被放大,同时 html 使用具有局限性,不方便在跨平台间使用。
因此更好的方案是制定一套数据结构 + 文档模型,所有的输入都经过编辑器生成约定的产物,这样在不同的平台均可解析并且保证得到预期的效果。
还有一类是以 Google docs 为主的编辑器,不使用
contenteditable,而是基于 canvas 渲染[1],通过监听用户输入,模拟编辑器的运行,此类编辑器实现成本极高且复杂。
本文以 quill[2] 为例,介绍如何实现一个支持跨平台渲染,且可以插入自定义模块的富文本编辑器。
基本概念
delta[3]
用于描述富文本内容或内容变换的数据结构,纯 json 格式,能够转化成 js 对象后方便操作,基本格式如下,由一组 op 组成。
op 是个 js 对象,可理解为对当前内容的一次变更,它主要有以下几个属性。
insert: 插入,后面 【3.2 数据结构】有介绍可能的值和对应的含义
retain: 值为 number 类型,保留相应长度的内容
delete: 值为 number 类型,删除相应长度的内容
上面三个属性必有且仅有一个出现在 op 对象中
attributes: 可选,值为对象,可描述格式化信息
如何理解内容或内容变换,举个,下面这段数据表示了内容 “Grass the Green”,
{
ops: [
{ insert: 'Grass', attributes: { bold: true } },
{ insert: ' the ' },
{ insert: 'Green', attributes: { color: '#00ff00' } }
]
}经过下面一次 delta 内容变换后新内容为 “Grass the blue”。
{
ops: [
// 接下来 5 个字符取消加粗并加上斜体格式
{ retain: 5, attributes: { bold: null, italic: true } },
// 维持 5 个字符不变
{ retain: 5 },
// 插入
{ insert: "Blue", attributes: { color: '#0000ff' },
// 删除后面 5 个字符
{ delete: 5 }
]
}Delta 本质上是一系列操作记录,在渲染时可以看作记录了从空白到目标文档的一个过程,而 HTML 是一个树形结构,所以 Delta 的线性结构相比 HTML 在业务使用上有天生优势。
parchment[4]
一种文档模型,由 blots 组成,用来描述数据,可以拓展自定义的数据。
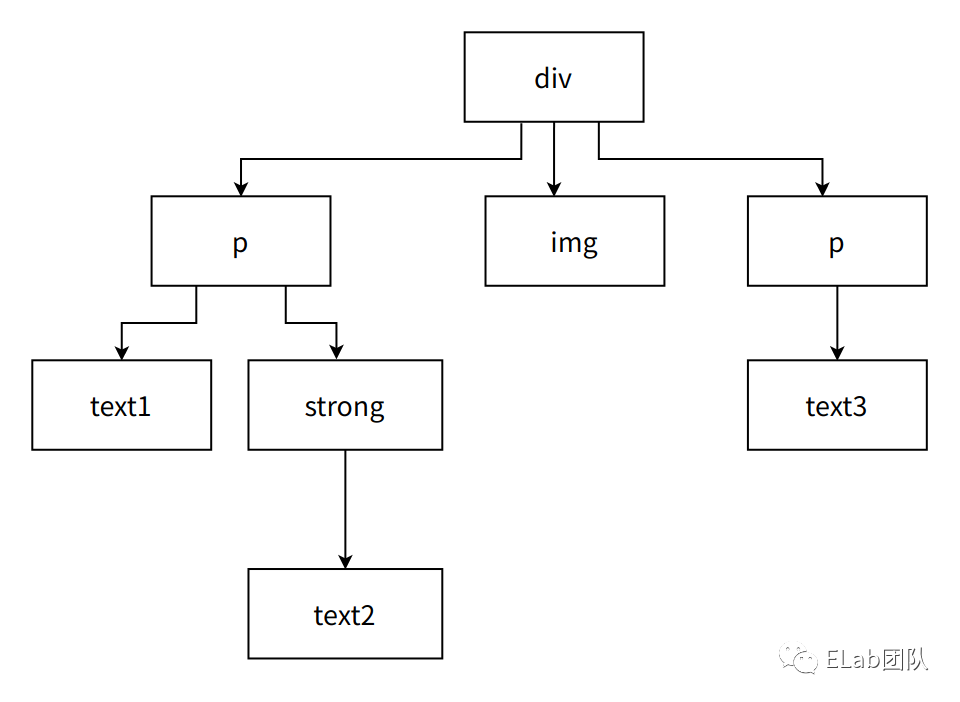
<p>
一段文字加视频的富文本内容。
<img src="xxx" alt="">
</p>
<p>
<strong>加粗文本结尾。</strong>
</p>parchment 与 blot 关系类似于 DOM 与 element node,上面一段 html 内容使用 dom tree 和 parchment tree 描述分别如下图所示。
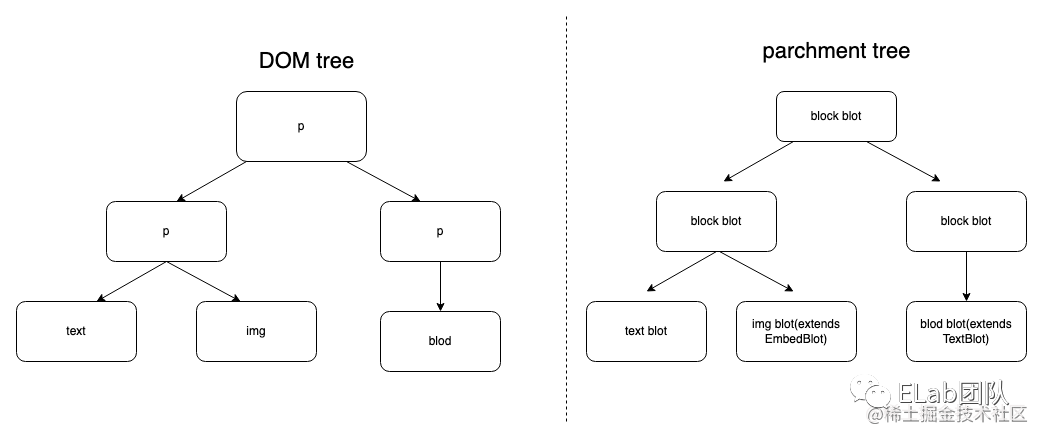
parchment 提供了几种基础 blot,同时支持开发中根据需求拓展定义自己的 blot,后面会演示如何开发一个自定义的 blot。
{
// 基础节点
ShadowBlot,
// 容器节点 => 基础节点
ContainerBlot,
// 格式化节点 => 容器节点
FormatBlot,
// 叶子节点
LeafBlot,
// 编辑器根节点 => 容器节点
ScrollBlot,
// 块级节点 => 格式化节点
BlockBlot,
// 内联节点 => 格式化节点
InlineBlot,
// 文本节点 => 叶子节点
TextBlot,
// 嵌入式节点 => 叶子节点
EmbedBlot,
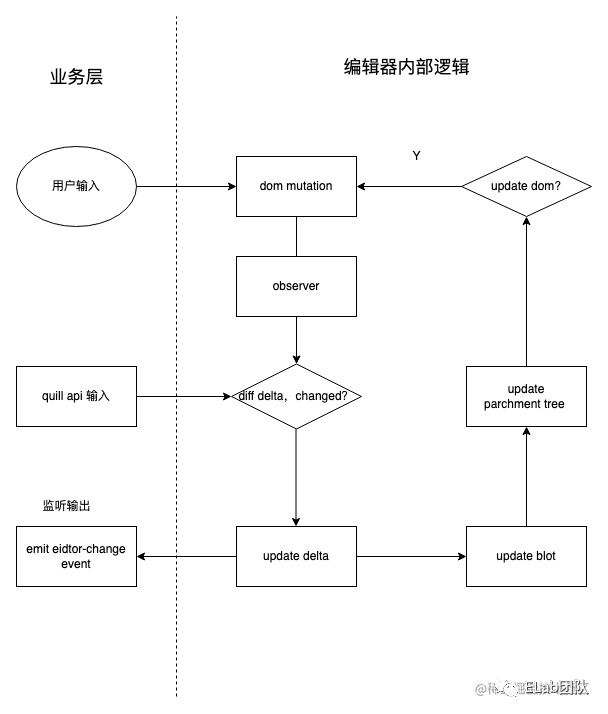
}最后用一张图了解下 quill 内部的工作流程,其中开发者需要关注的业务层逻辑十分简洁,可以通过手动输入和 api 方式变更编辑器内容,同时 editor-change 事件会输出当次操作和最新内容对应的 delta 数据。
实际应用
数据流
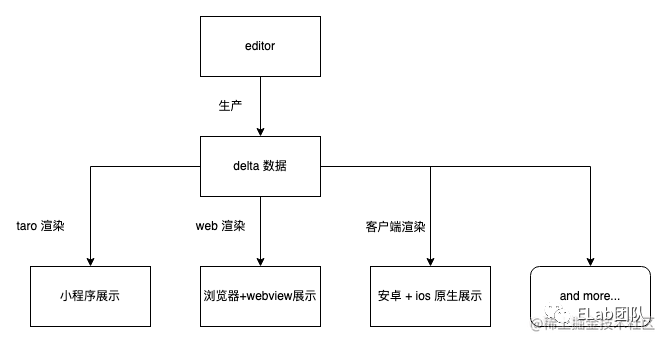
在业务中,基本数据流应该如下图所示,由编辑器生成 delta 数据,之后由相应平台的解析器渲染成对应的内容。
数据结构
良好的内容数据结构设计,在后续维护和跨平台渲染时起到关键作用,我们可以将富文本内容中依赖的媒体(图片、视频、自定义的格式)数据放到外层来,通过 id 关联,这样日后拓展和渲染时会比较方便。
interface ItemContent {
// 富文本数据,存储着 delta-string
text?: string;
// 视频
videoList?: Video[];
// 图片
imageList?: Image[];
// 自定义的模块,如投票、广告卡片、问卷卡片等等
customList?: Custom[];
}其中编辑器输出的是标准 delta 数据, 结构如下所示,
// 纯文本, \n 代表换行
{
insert: string;
},
// 特殊类型的文本
{
insert: '超链接文本',
attributes: {
// 文字颜色
color: string,
// 加粗
bold: boolean,
// 超链接地址
link: string;
...,
}
},
// 有序无序列表
{
insert: '\n',
attributes: {
list: 'ordered' | 'bullet'
}
},
{
insert: {
uploading: {
// 资源类型
type: 'image' | 'video' | 'vote' | 'and more...'
// 资源 id
uid: string
},
},
},
// 图片
{
insert: { image: '${image_uri}' }
},
// 视频
{
insert: {
videoPoster: {
/** 视频封面地址 */ url: string;
/** 视频 id */ videoId: string;
}
}
},
// 投票
{
insert: {
vote: {
voteId: string
}
}
},
// 缩进,作用域内所有文本向右缩进 indent 个单位;
// 作用域:从当前为起始位置向前回溯,遇到以下任意一种情况结束
// 1、纯文本 \n
// 2、attributes的属性含有indent并且indent值小于等于当前值
{
insert: '\n',
attributes: {
indent: 1-8,
}
},图片 / 视频混排
图片上传需要支持展示上传中的状态,并且不应该阻塞用户的编辑,所以需要先使用一个占位元素,待上传完成后将占位替换成真实图片或视频。
自定义 blot
自定义 blot 的好处是能够将整个的功能(例如图表功能)封装到一个 blot 中,这样业务开发时可直接使用,而不用管每个功能是怎么实现的。下面以图片视频上传态占位 blot 为例,演示如何自定义一个 blot。
import Quill from 'quill';
enum MediaType {
Image = 'image',
Video = 'video',
}
interface UploadingType {
type: MediaType;
// 唯一的 id,当图片或视频上传完成后,需要找到对应的 uid 进行替换
uid: string;
}
export const BlockEmbed = Quill.import('blots/block/embed');
class Uploading extends BlockEmbed {
static _value: Record<string, UploadingType> = {};
static create(value: UploadingType) {
const ELEMENT_SIZE = 60;
// blot 对应的 dom 节点
const node = super.create();
this._value[value.uid] = value;
node.contentEditable = false;
node.style.width = `${ELEMENT_SIZE}px`;
node.style.height = `${ELEMENT_SIZE}px`;
node.style.backgroundImage = `url(占位图地址)`;
node.style.backgroundSize = 'cover';
node.style.margin = '0 auto';
// 用来区分对应资源
node.setAttribute('data-uid', value.uid);
return node;
}
static value(v) {
return this._value[v.dataset?.uid];
}
}
Uploading.blotName = 'uploading';
Uploading.tagName = 'div';
export default Uploading;将自定义 blot 注册到编辑器实例中,使用 quill 的 insertEmbed 来调用这个blot 即可。
// editor.tsx
Quill.register(VideoPosterBlot);
quill.insertEmbed(1, 'uploading', {
type: 'image',
uid: 'xxx',
});
处理粘贴操作
复制粘贴可以大幅提升编辑器效率,但是我们需要对剪切板中的视频和图片进行特殊处理,将剪切板中的内容转化成自定义的格式,并自动上传其中图片和视频。
基本原理
监听用户的粘贴操作,读取 paste event[5] 返回的 clipboardData[6] 数据,二次加工后再插入编辑器中。
target.addEventListener('paste', (event) => {
const clipboardData = (event.clipboardData || window.clipboardData)
const text = clipboardData.getData(
'text',
);
const html = clipboardData.getData(
'text/html',
);
/**
* 业务逻辑
*/
event.preventDefault();
});clipboardData.items 是 DataTransferItem 的数组集合,它包含了本次粘贴操作的数据内容。
DataTransferItem 有两个属性分别是 kind和 type,其中 kind 值通常是 string 类型,如果是文件类型的数据那么值为 file;type 值是 MIME 类型,常见的是 text/plain 和 text/html。
处理图片
剪切板中的图片来源分为两大类,一是直接从文件系统中复制,这种情况我们
从文件系统中复制
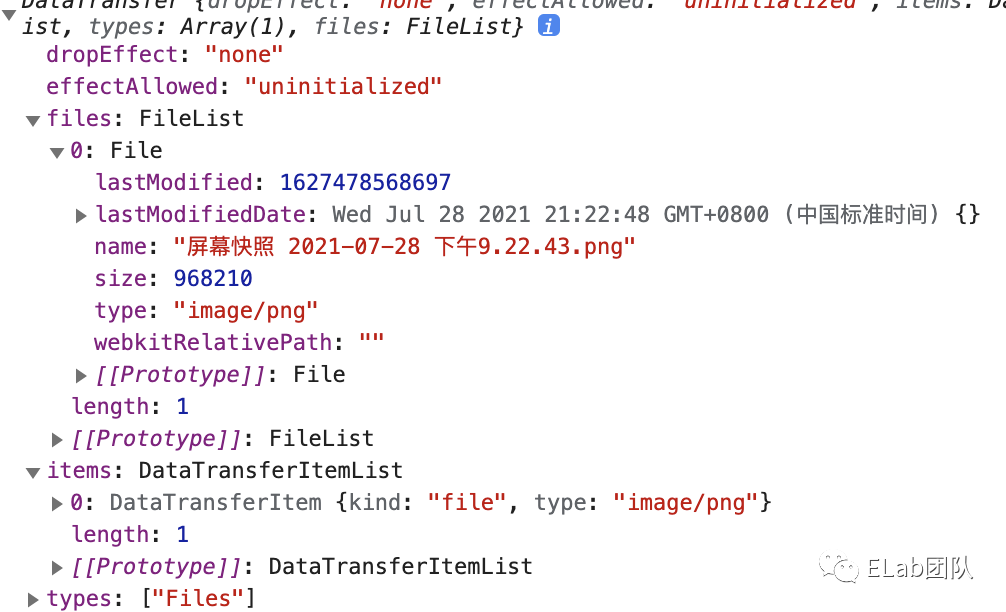
从网页复制


从上面右图不难看出,从网页中复制过来的内容中包含 text/html 富文本类型,由于图片可能是临时地址,直接使用三方图片地址不可靠,需要把 html 中图片地址提取出来,下载后再上传至我们自己的服务器中,图片上传模块还能继续复用上文的图片混排。
convert({ html, text }, formats = {}) {
if (!html) {
return new Delta().insert(text || '');
}
// 返回 HTMLDocument 对象
const doc = new DOMParser().parseFromString(html, 'text/html');
const container = doc.body;
// key - node
// value - matcher: (node, delta, scroll) => newDelta
const nodeMatches = new WeakMap();
// 返回两个匹配器,分别处理 ELEMENT_NODE 和 TEXT_NODE ,将 dom 转化成 Delta
const [elementMatchers, textMatchers] = this.prepareMatching(
container,
nodeMatches,
);
return traverse(
this.quill.scroll,
container,
elementMatchers,
textMatchers,
nodeMatches,
);
}
function traverse(scroll, node, elementMatchers, textMatchers, nodeMatches) {
// 节点为叶子节点即文本
if (node.nodeType === node.TEXT_NODE) {
return textMatchers.reduce((delta, matcher) => {
return matcher(node, delta, scroll);
}, new Delta());
}
if (node.nodeType === node.ELEMENT_NODE) {
return Array.from(node.childNodes || []).reduce((delta, childNode) => {
let childrenDelta = traverse(
scroll,
childNode,
elementMatchers,
textMatchers,
nodeMatches,
);
if (childNode.nodeType === node.ELEMENT_NODE) {
childrenDelta = elementMatchers.reduce((reducedDelta, matcher) => {
return matcher(childNode, reducedDelta, scroll);
}, childrenDelta);
childrenDelta = (nodeMatches.get(childNode) || []).reduce(
(reducedDelta, matcher) => {
return matcher(childNode, reducedDelta, scroll);
},
childrenDelta,
);
}
return delta.concat(childrenDelta);
}, new Delta());
}
return new Delta();
}上面例子中的数据可以转化成以下 delta 数据,视频的处理方法与图片类似,这里不再赘述。
{
ops: [
{
insert: '说起艾冬梅这个名字,现在的年轻人可能不是很熟悉,但是她曾经却是家喻户晓的人物,'
},
{
insert: '艾冬梅是我国著名的马拉松运动员' , attribute: {
bold: true
},
},
{
insert: '。她出生于1981年,是个来自东北的姑娘,和很多普通的八零后一样,她来自一个平凡的家庭,从小生活十分幸福,家境虽然不富裕,但艾冬梅依然是父母的掌上明珠。'
},
{
insert: {
image: {
url: 'xxx'
}
}
},
{
insert: '但是艾冬梅和其他人不同的是她从小就展现出了惊人的长跑天赋' , attribute: {
bold: true
},
},
{
insert: ' , 1993年当时艾冬梅还在念小学,她在一次跑步比赛中获得了一个十分优秀的成绩,在脚趾头受伤的情况下打破了当地的3000米项目记录,远远超过了参赛的所有人。这让很多人都十分震惊,于是艾冬梅顺利地被齐齐哈尔体校选中。'
}
]
}解析数据
在 web 场景下可以使用 quill-delta-to-html[7] 这个库来做解析,如果是小程序,对于媒体元素(如:小程序中图片必须要指定宽高[8])支持相对不太友好,需要自己解析,下面简单介绍下如何渲染 delta 数据。
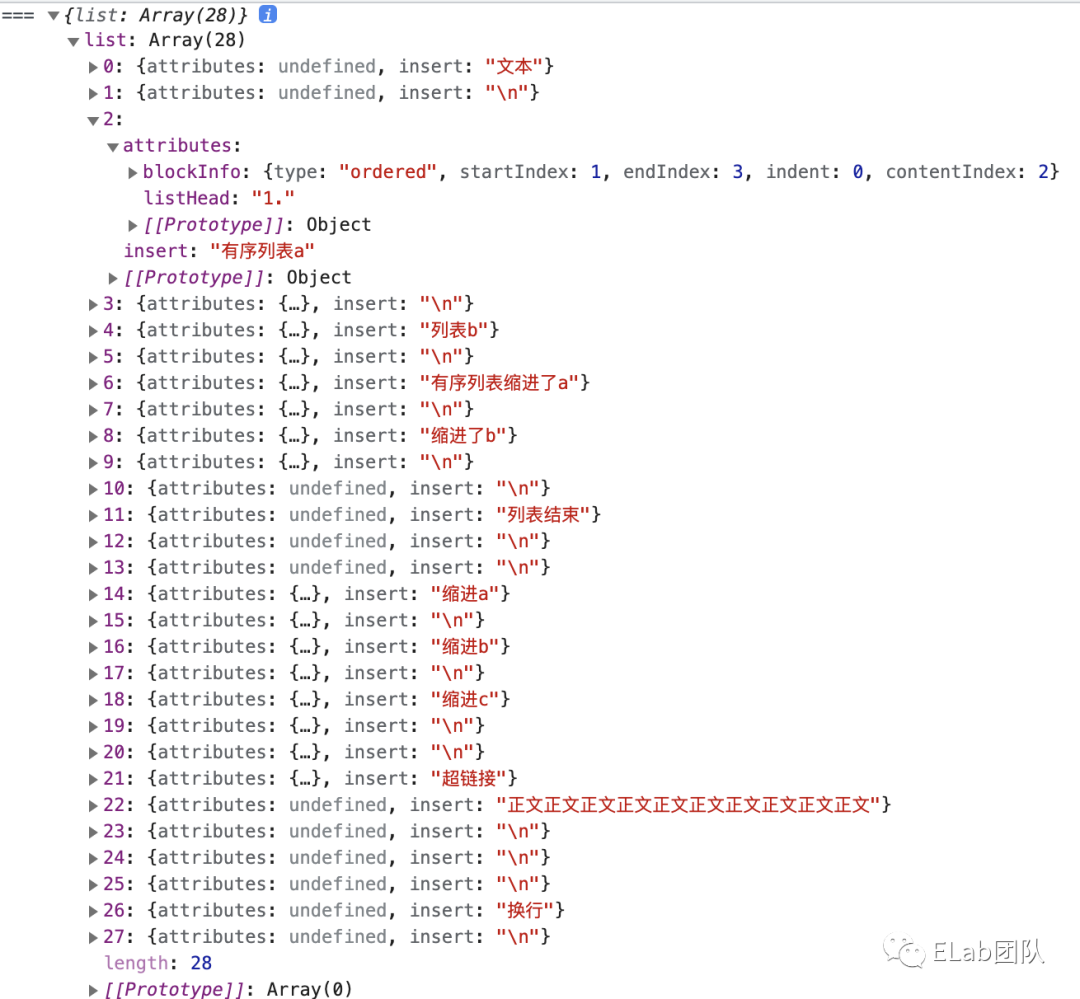
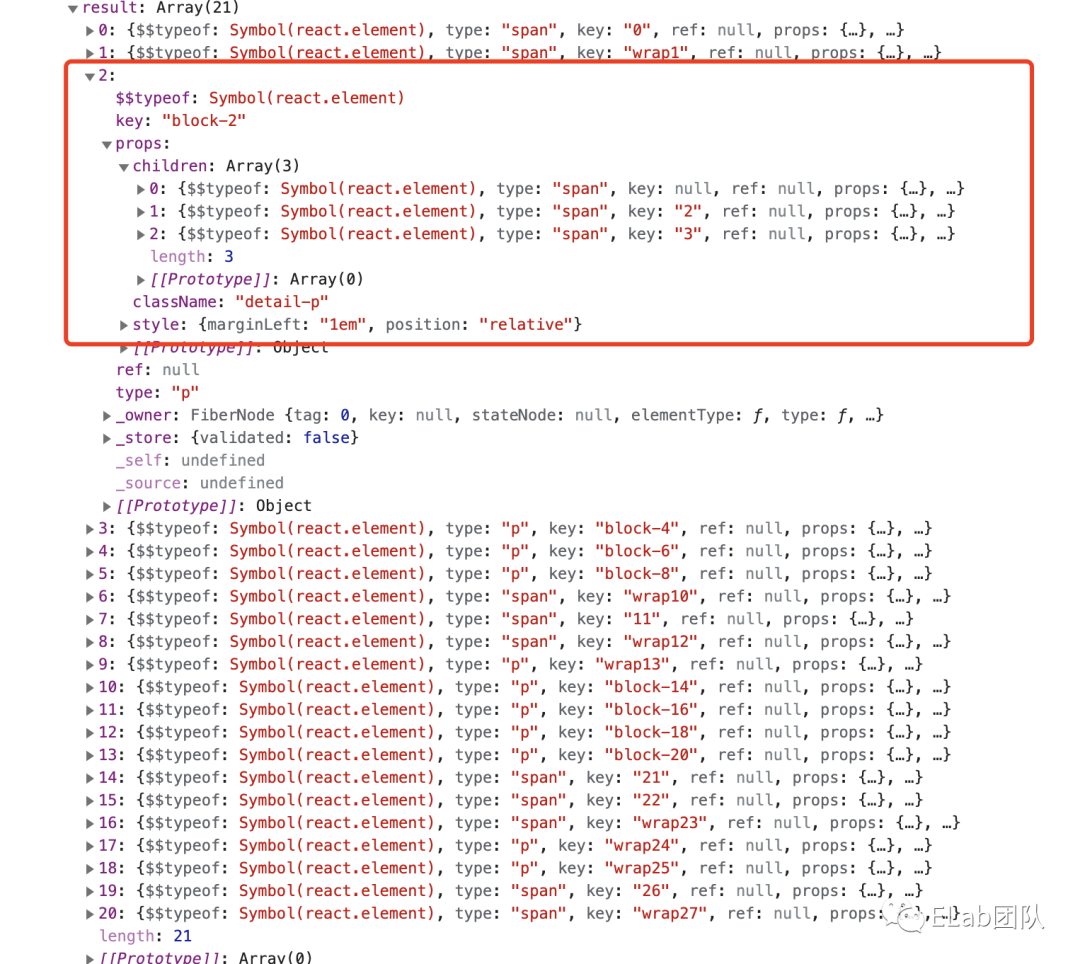
由于 delta 是一个线性结构,转化成 dom 时,需要构建一棵树,将块级元素的子元素关联到它的 children 中。

- 纯文本反规范化,将 abc\ndef\ng 格式转化成 [abc, \n, def, \n, g]
- 将块级元素的元信息,写入第一个 op 中
块级元素的元信息包括:缩进,有序列表序号,【当前元素所在块级元素】在原数据中的起始与终止索引,【当前元素所在块级元素】在 dom 列表中的索引
小结
至此,我们已经了解开发编辑器的基本流程和需要重点关注的一些事项。如果业务中需要拓展一些功能卡片,如飞书文档的各种应用,可通过拓展 blot + 编写对应的组件来实现。此外还能够通过编写相应平台的解析器在非 web 场景的展示,轻松实现内容跨平台渲染。