如何实现 1 小时内完成千万级数据运算
本文详细描述如何实现:目前手上可用的资源仅剩一个 16 核剩余 4-8G 内存的机器,单点完成在 1 个小时内千万级别 feed 流数据 flush 操作(主要包括:读数据,计算综合得分,淘汰低分数据,并更新最新得分,回写缓存和数据库)。
背景
目前工作负责的一款产品增加了综合得分序的 Feed 流排序方式:需要每天把(将近 1000W 数据量)的 feed 流信息进行算分计算更新后回写到数据层。手上的批跑物理机器是 16 核(因为混部,无法独享 CPU),同时剩下可用内存仅 4-8G。显而易见的是:我们可以申请机器,多机部署,分片计算或者通过现有的大数据平台 Hadoop 进行运算都看似可以解决问题。但是由于更新 feed 流的操作需要依赖下游服务(这里暂且叫 A,后续文中提到下游服务均可称 A 服务),而下游的服务 A-Server 本身是个 DB 强绑定的关系,也就说明了下游的服务瓶颈在于 DB 的 QPS,这也导致了即便我本身的服务多机部署,分片处理,下游服务的短板导致不可行。而针对方案二通过大数据平台完成的话,也就是需要推荐大数据的部门协助处理,显然这个是需要排期处理,而时间上也是不可预估。
既然如此,那就借用,朱光潜老先生的一篇文章《朝抵抗力最大的路径走》。我本人相信通过合理的资源调度以及更低的成本可以克服眼前的困难,实现最终的需求效果。当然优化过程中并不是一帆风顺,当然经过两周左右的优化迭代,也终于实现了。
业务主要流程流程
整个 flush 的业务流程大致如下:
- 读取 DB 获取目前所有的 feed 类别(约 2-3w 的数据);
- 通过类别读取 Cache 每一个类别下的 feed 流元素的索引(约 1000-10w 的数据);
- 通过每一个信息的索引查询 feed 流所对应的基础数据信息(需要查约 3-4 张表);
- 计算每一个 feed 元数据的得分信息(1000w 的数据量),过程中需要淘汰一部分,调用服务 A-Server 删除当前的索引;
- 根据权重计算每一个 feed 的元素的信息,调用下游服务 A-Server,update 索引分值。
主要业务流程图具体如下:
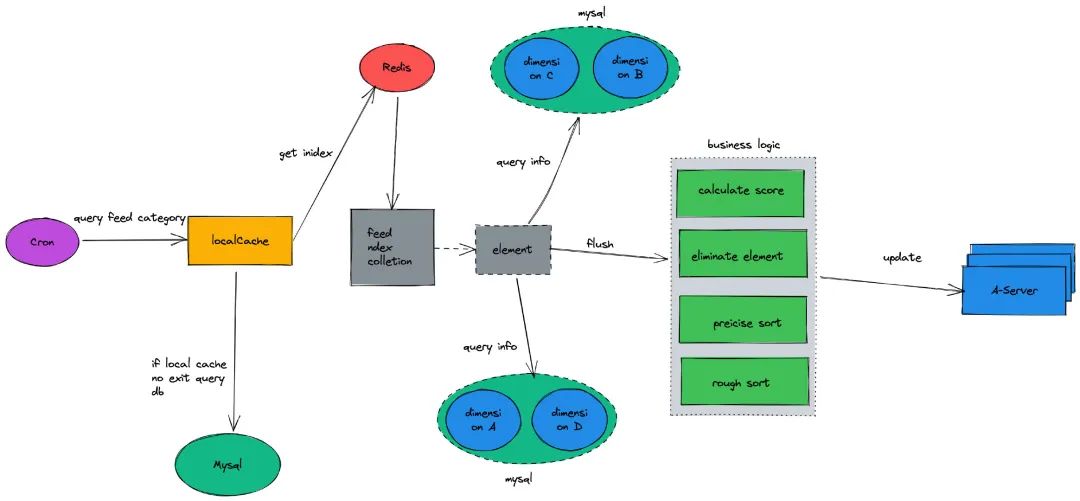
- 查询 DB 或者本地缓存获取索引 feed 流中的现有全集类别;
- foreach 类别集合 Collection,查询目前所以的类别下的 feed 数据流集合并存储到 Map 中,其中 key 是类别,value 是类别对应的数组集合(key:category,value:colletion);
- foreach 上述获取的 Map 并发起 goruntine 查询每一条信息流元素对应的基本信息,并通过粗排来淘汰需要淘汰的元素(考虑到下游的并发和 DB 的负载问题,每查询一批,sleep 一段时间),把最终符合要求的元素存储到 map 等待后续更新得分,并刷入缓存和 DB;
- foreach 上述粗排后的 Map,最终并发起 goruntine 调用下游 A-server,更新 feed 流的索引得分。
方案图如下:

将近 1000W 的数据虽然在处理过程中,在使用后的集合或者 Map 都会及时清空:
Map=nil []string=nil // 清空已使用的内容
runtime.GC() // 发出GC的请求,希望发起GC但是问题还是出现了:
内存跑满(由于机器总内存 18G,所以基本是内存直接跑满了)

compress@v1.12.2/zstd/blockdec.go:215 +0x149
created by github.com/klauspost/compress/zstd.newBlockDec
/root/go/pkg/mod/github.com/klauspost/compress@v1.12.2/zstd/blockdec.go:118 +0x166
goroutine 61 [chan receive, 438 minutes]:
github.com/klauspost/compress/zstd.(*blockDec).startDecoder(0xc006c1d6c0)
/root/go/pkg/mod/github.com/klauspost/compress@v1.12.2/zstd/blockdec.go:215 +0x149
created by github.com/klauspost/compress/zstd.newBlockDec
/root/go/pkg/mod/github.com/klauspost/compress@v1.12.2/zstd/blockdec.go:118 +0x166
goroutine 62 [chan receive, 438 minutes]:
github.com/klauspost/compress/zstd.(*blockDec).startDecoder(0xc006c1d790)
/root/go/pkg/mod/github.com/klauspost/compress@v1.12.2/zstd/blockdec.go:215 +0x149
created by github.com/klauspost/compress/zstd.newBlockDec
/root/go/pkg/mod/github.com/klauspost/compress@v1.12.2/zstd/blockdec.go:118 +0x166
goroutine 63 [chan receive, 438 minutes]:
github.com/klauspost/compress/zstd.(*blockDec).startDecoder(0xc006c1d860)
/root/go/pkg/mod/github.com/klauspost/compress@v1.12.2/zstd/blockdec.go:215 +0x149
created by github.com/klauspost/compress/zstd.newBlockDec
/root/go/pkg/mod/github.com/klauspost/compress@v1.12.2/zstd/blockdec.go:118 +0x166
因为堆栈给的信息不多,但是从机器上看基本是 goruntine 开启的太多,并发量太大,同时大量的数据同时加载到内存,导致了机器的内存和 Cpu 的负载过高。
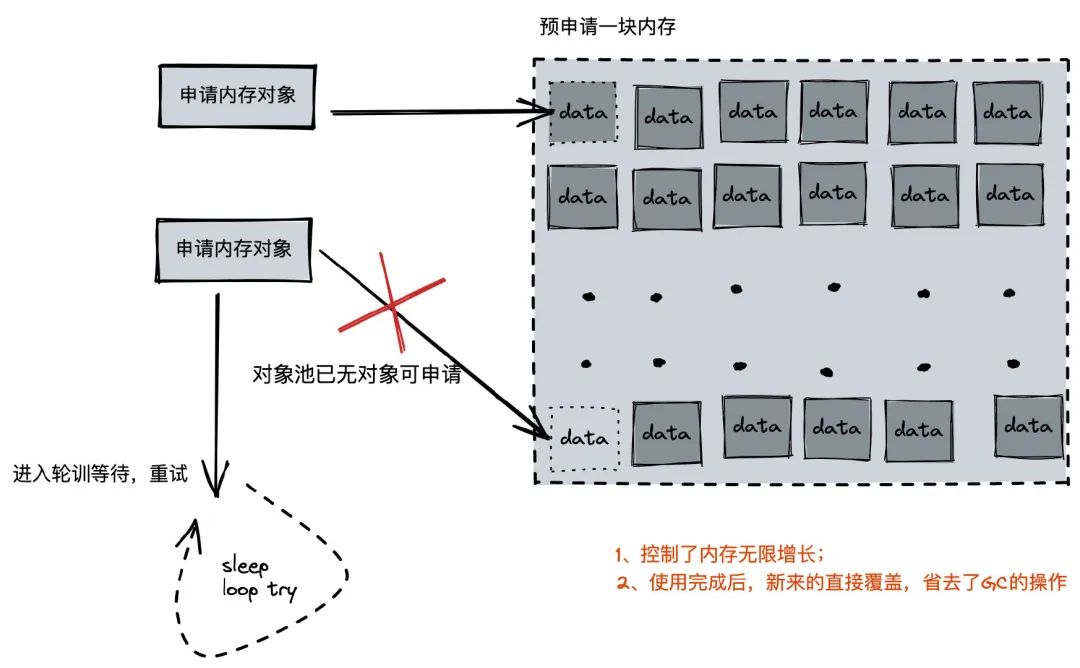
针对上述的问题,设计出了第二套方案:
- 自己实现一套协程池
- 预分配一个内存块,维持一个对象池
对象池具体改进点如下:
协程池
实现比较简单,这里就直接上代码:
// 协程池对象
type PoolBuilder struct {
workerNum int // Worker 线程数量
DelJobChan *chan string // 缓冲队列
}
// 创建一个协程池
func (pool *PoolBuilder) listenAdd(num int) {
for i := 0; i < num; i++ {
go func(i int) { //
addWorker(pool.AddJobChan)
}(i)
}
}
// 任务写入队列
func (pool *PoolBuilder) InsertAddChannel(id string, score int64) {
log.Infof("send value to add channel,%s", id)
pool.AddJobChan.In <- &AddChannel{
id: id,
score: score,
}
}
优化后的方案缺陷
内存和 Cpu 的负载相对降下来了,但是由于下游服务 A-Server 是对 DB 的强依赖的类型,所以突然的高并发,DB 的瓶颈成了 A-Server 的服务瓶颈。如果并发量降下来,但是 6 个小时内完成 1000w 的数据读库,业务计算,算法排序以及删除和更新每一条数据的得分,显然不够。
陷入僵局
全量的数据计算,并发高,下游服务,下游存储资源扛不;相对并发不高的情况,数据计算不完。与组内小伙伴商量,可以采用大数据平台计算不失一种好的办法。看似最优解,但是大数据平台接入,以及推动大数据平台的开发也是需要走排期等流程。
参考开源,集思广益
经过了两周的专研和思考,我最终从:hadoop 的 mapreduce 分而治的思想、vert.x 的全异步链路(本人超级喜欢的一个框架,使用后,根本不想写同步代码了)以及 Linux 的内核调度机制的三种优秀的设计中借鉴了一些思路,最终完成了 2 小时 40 分钟跑千万级别的数据优化。
1、Hadoop 的 mapreduce 分而治的思想
把任务拆分成若干分,然后分配给一个 woker 让每个 worker 处理手中的任务,并把处理后的子任务汇集到一个 woker-A。woker-A 负责把所以的子任务结果,汇总处理,并返回。
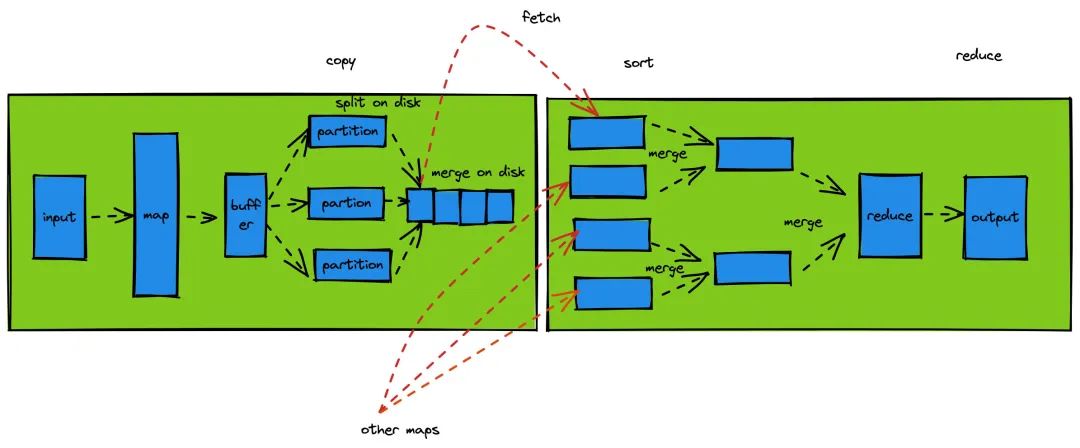
启发
我可以把每一个类别分配给一个协程处理,而每一个协程只负责每一个类别下的所以数据,这样协程的数量也就是类别的数据,这样进一步节省了协程数量,但是由于 merge 的结果在最终一步,这样的话内存就需要存储处理后全量数据,这一点与目前的内存有限不符合,所以这里借鉴了把任务分发的思想。
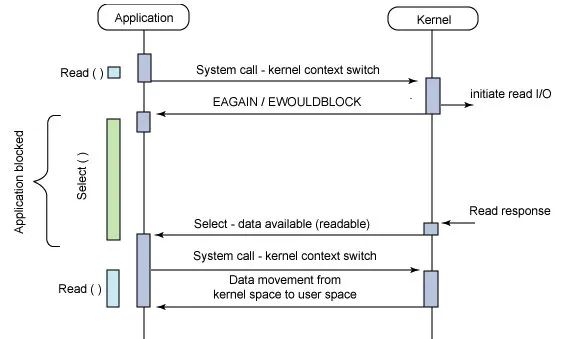
2、Linux 的内核调度机制(非 epoll)
在 Linux 的中内核调度中,我们知道非 epoll 的模式中,无论是 poll 和 select 的时候,都会有一个 select 来负责后续的任务调用和分配,用官方的描述就是:select 轮训设置或检查存放 fd 标志位的数据结构进行下一步处理。如果满足状态,就会扭转到下一个步,唤起相应的进程函数调用。
启发
这里可以参考 select 这个负责任的角色,当然改进的地方是我可以增加多个协程来并发查询所以类别,并进行分发类别处理,这样话,下游的协程池就可以尽可能的在完成一次调度后,马上进行下一次调度(因为分配任务的协程多了),而不会进入调度空闲的状态。
这里就直接使用网上的一张图:
3、vert.x 全异步链路
我将这个 vert.x 标红了,可以看到这里 vert.x 给我的启发是最关键也是最大的。上述问题,我反复思考,我发现,其实我如果突然的高并发,必然导致了下游的服务负载过高从而导致 DB 和下游服务扛不住。如果我能平滑的并发,而不是从某个时间点起,并发操作,也许就能解决这个问题。
并发代码我们写的多,但也许我们大家写的只是并发而不是真正的异步,因为我们在开始或者函数汇总的结果初我们都会使用阻塞,当然我也是有短时间没有写全异步的代码了,所以思想固化了,具体案例如下分析:
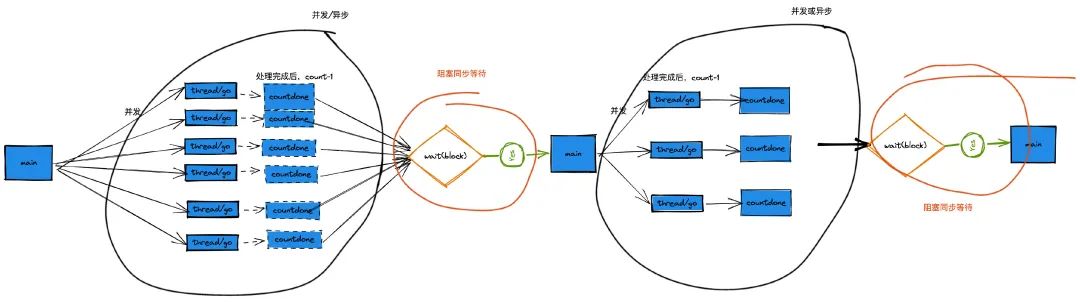
而在 vert.x 中是将上下游的数据通信都是用了 callback 的方式处理,而正是这样,这个框架的做到了全链路的异步逻辑。这里我们看看这个框架的核心思想:
Vertx 完成采用另一个机制,用一个线程来接受请求(也可以是几个,注意是几个,不是几百个),而把这个真正要执行的任务委托给另外一个线程来执行,从而不会堵塞当前线程。
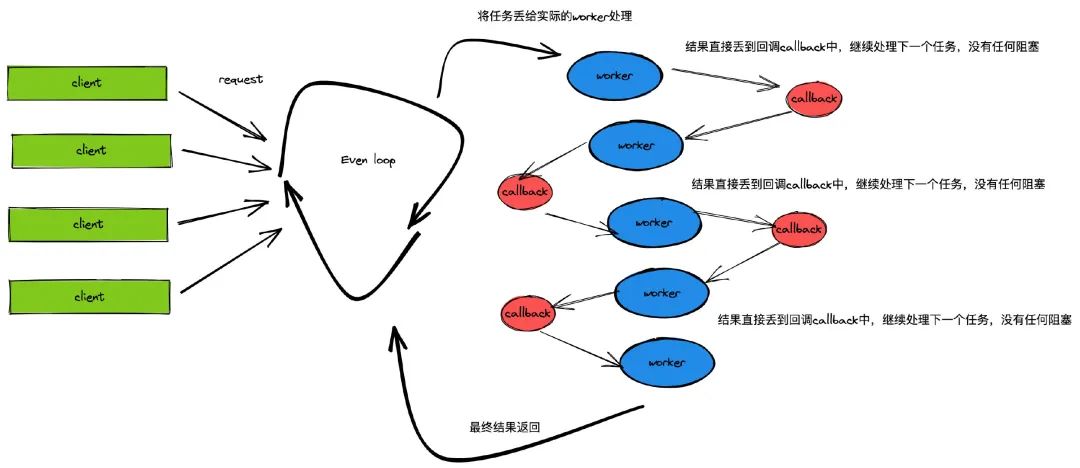
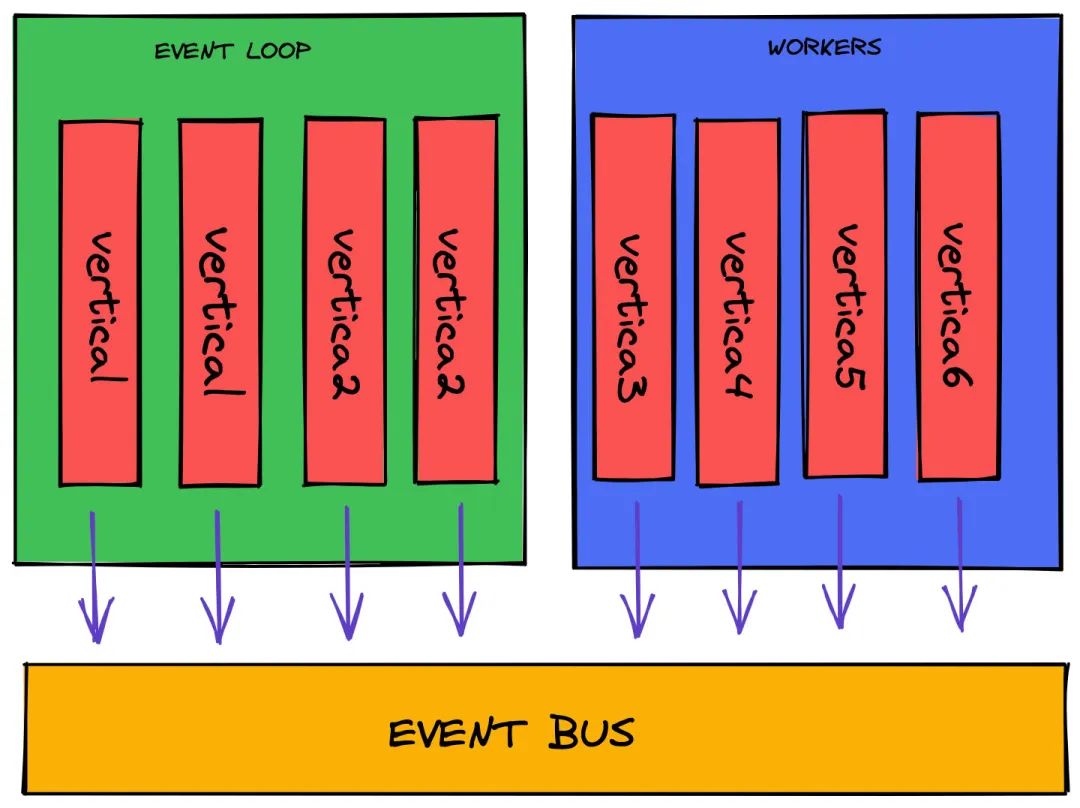
1.非阻塞处理请求,异步执行阻塞程序,保证了请求处理的高效性;
2.使用 Event Bus 事件总线来进行通讯,可以轻松编写出分布式、松耦合、高扩展性的程序。
这里可以展示一下 Vert.x 的异步代码:
public class Server extends AbstractVerticle {
public void start() {
vertx.createHttpServer().requestHandler(req -> {
req.response()
.putHeader("content-type", "text/plain")
.end("Hello from Vert.x!");
}).listen(8080);
}
}对异步代码有兴趣的小伙伴一定要看看:https://vertx.io/
优化改造开始
借鉴了上述优秀的思想,我对自己的服务做了以下改进:
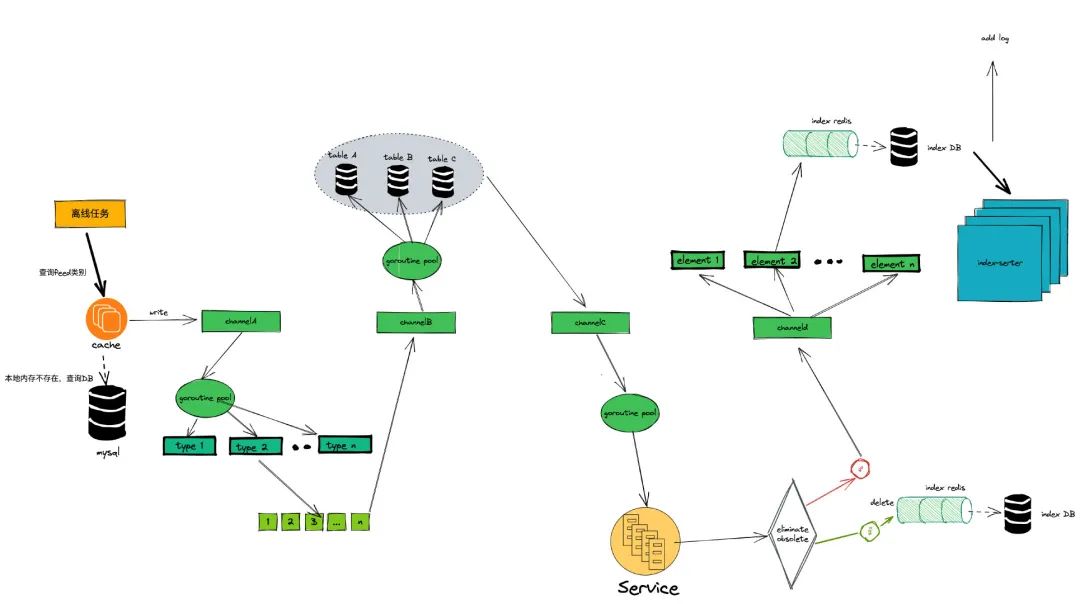
1、我构造了 4 个协程池,分别是查询类别 category、查询 DB 基本信息、根据算法计算综合得分、和数据更新回写;
2、从主协程开始,不做任何阻塞,查询类别的协程协程池,每查询一个类别,结果直接丢到 channelA(不阻塞然后继续擦下类别);
3、查询 DB 的协程,监听 channelA,当发现有数据的时候,查询 DB 信息,并将结果丢到 channelB(同上不做任何阻塞,继续查询下一条数据的结果集合);
4、帖子得分协程池读取 channelB 的数据,然后根据算法计算处理帖子的得分,并将结果集合丢到 channelC(同样不做任何阻塞,继续计算下一次的得分数据);
5、而数据回写的协程负责调用下游服务 A-Server,处理后完,打 log,标记处理的偏移量(由于没有阻塞,需要跟着最终所以数据是否处理完成)。
业务架构设计如下:
优化效果
1、协程数 6w->100!,这里协程数从 6w 降到了 100 个协程就 Cover 住了整个项目;
2、内存使用情况,从基本跑满到仅仅使用 1-2G 的正常内存。


总结:没想到自己的坚持看到了效果,自选股的业务中也因此可以接入综合得分序列的 feed 流,我相信这个是一个好的开始,在这个基础上,我们可以根据个人画像做更多的智能推荐,期间大伙的建议更多是借用大数据平台计算,而实际的推进和排期让我更愿意用自己的方式以最低的成本最优的结构去优化完成,当然这次很幸运,自己的努力实现了。