【转】 飞哥带你理解 iptables 原理!
现在 iptables 这个工具的应用似乎是越来越广了。不仅仅是在传统的防火墙、NAT 等功能出现,在今天流行的的 Docker、Kubernets、Istio 项目中也经常能见着对它的身影。正因为如此,所以深入理解 iptables 工作原理是非常有价值的事情。
Linux 内核网络栈是一个纯内核态的东西,和用户层功能是天然隔离。但为了迎合各种各样用户层不同的需求,内核开放了一些口子出来供用户干预。使得用户层可以通过一些配置,改变内核的工作方式,从而实现特殊的需求。
Linux 在内核网络组件中很多关键位置布置了 netfilter 过滤器。Iptables 就是基于 netfilter 来实现的。所以本文中 iptables 和 netfilter 这两个名词有时候就混着用了。
也在网上看过很多关于 netfilter 技术文章,但是我觉得都写的不够清晰。所以咱们撸起袖子,自己写一篇。Netfilter 的实现可以简单地归纳为四表五链。我们来详细看看四表、五链究竟是啥意思。
一、Iptables 中的五链
Linux 下的 netfilter 在内核协议栈的各个重要关卡埋下了五个钩子。每一个钩子都对应是一系列规则,以链表的形式存在,所以俗称五链。当网络包在协议栈中流转到这些关卡的时候,就会依次执行在这些钩子上注册的各种规则,进而实现对网络包的各种处理。
要想把五链理解好,飞哥认为最关键是要把内核接收、发送、转发三个过程分开来看。
1.1 接收过程
Linux 在网络包接收在 IP 层的入口函数是 ip_rcv。网络在这里包碰到的第一个 HOOK 就是 PREROUTING。当该钩子上的规则都处理完后,会进行路由选择。如果发现是本设备的网络包,进入 ip_local_deliver 中,在这里又会遇到 INPUT 钩子。
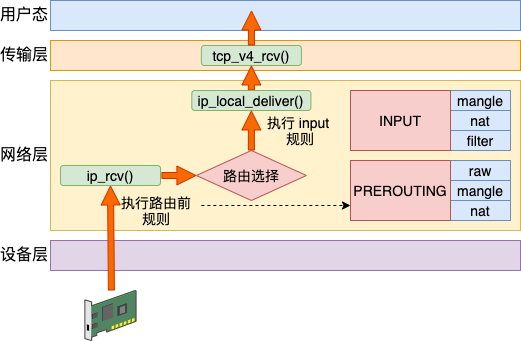
我们来看下详细的代码,先看 ip_rcv。
//file: net/ipv4/ip_input.c
int ip_rcv(struct sk_buff *skb, ......){
......
return NF_HOOK(NFPROTO_IPV4, NF_INET_PRE_ROUTING, skb, dev, NULL,
ip_rcv_finish);
}NF_HOOK 这个函数会执行到 iptables 中 pre_routing 里的各种表注册的各种规则。当处理完后,进入 ip_rcv_finish。在这里函数里将进行路由选择。这也就是 PREROUTING 这一链名字得来的原因,因为是在路由前执行的。
//file: net/ipv4/ip_input.c
static int ip_rcv_finish(struct sk_buff *skb){
...
if (!skb_dst(skb)) {
int err = ip_route_input_noref(skb, iph->daddr, iph->saddr,
iph->tos, skb->dev);
...
}
...
return dst_input(skb);
}如果发现是本地设备上的接收,会进入 ip_local_deliver 函数。接着是又会执行到 LOCAL_IN 钩子,这也就是我们说的 INPUT 链。
//file: net/ipv4/ip_input.c
int ip_local_deliver(struct sk_buff *skb){
......
return NF_HOOK(NFPROTO_IPV4, NF_INET_LOCAL_IN, skb, skb->dev, NULL,
ip_local_deliver_finish);
}简单总结接收数据的处理流程是:PREROUTING链 -> 路由判断(是本机)-> INPUT链 -> ...
1.2 发送过程
Linux 在网络包发送的过程中,首先是发送的路由选择,然后碰到的第一个 HOOK 就是 OUTPUT,然后接着进入 POSTROUTING 链。
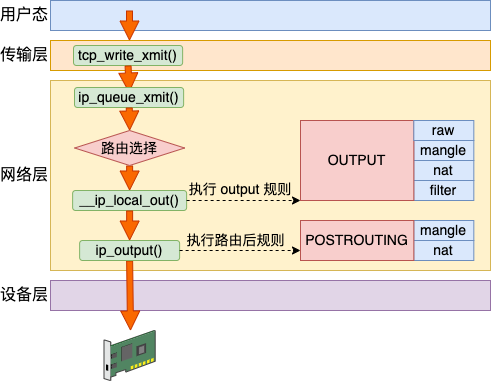
来大致过一下源码,网络层发送的入口函数是 ip_queue_xmit。
//file: net/ipv4/ip_output.c
int ip_queue_xmit(struct sk_buff *skb, struct flowi *fl)
{
// 路由选择过程
// 选择完后记录路由信息到 skb 上
rt = (struct rtable *)__sk_dst_check(sk, 0);
if (rt == NULL) {
// 没有缓存则查找路由项
rt = ip_route_output_ports(...);
sk_setup_caps(sk, &rt->dst);
}
skb_dst_set_noref(skb, &rt->dst);
...
//发送
ip_local_out(skb);
}在这里先进行了发送时的路由选择,然后进入发送时的 IP 层函数 __ip_local_out。
//file: net/ipv4/ip_output.c
int __ip_local_out(struct sk_buff *skb)
{
struct iphdr *iph = ip_hdr(skb);
iph->tot_len = htons(skb->len);
ip_send_check(iph);
return nf_hook(NFPROTO_IPV4, NF_INET_LOCAL_OUT, skb, NULL,
skb_dst(skb)->dev, dst_output);
}上面的 NF_HOOK 将发送数据包送入到 NF_INET_LOCAL_OUT (OUTPUT) 链。执行完后,进入 dst_output。
//file: include/net/dst.h
static inline int dst_output(struct sk_buff *skb)
{
return skb_dst(skb)->output(skb);
}在这里获取到之前的选路,并调用选到的 output 发送。将进入 ip_output。
//file: net/ipv4/ip_output.c
int ip_output(struct sk_buff *skb)
{
...
//再次交给 netfilter,完毕后回调 ip_finish_output
return NF_HOOK_COND(NFPROTO_IPV4, NF_INET_POST_ROUTING, skb, NULL, dev,
ip_finish_output,
!(IPCB(skb)->flags & IPSKB_REROUTED));
}总结下发送数据包流程是:路由选择 -> OUTPUT链 -> POSTROUTING链 -> ...
1.3 转发过程
其实除了接收和发送过程以外,Linux 内核还可以像路由器一样来工作。它将接收到网络包(不属于自己的),然后根据路由表选到合适的网卡设备将其转发出去。
这个过程中,先是经历接收数据的前半段。在 ip_rcv 中经过 PREROUTING 链,然后路由后发现不是本设备的包,那就进入 ip_forward 函数进行转发,在这里又会遇到 FORWARD 链。最后还会进入 ip_output 进行真正的发送,遇到 POSTROUTING 链。
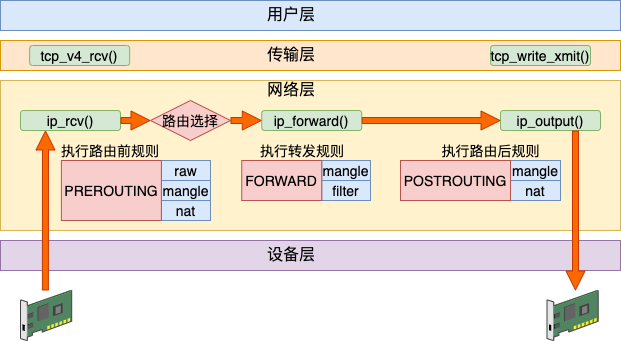
我们来过一下源码,先是进入 IP 层入口 ip_rcv,在这里遇到 PREROUTING 链。
//file: net/ipv4/ip_input.c
int ip_rcv(struct sk_buff *skb, ......){
......
return NF_HOOK(NFPROTO_IPV4, NF_INET_PRE_ROUTING, skb, dev, NULL,
ip_rcv_finish);
}PREROUTING 链条上的规则都处理完后,进入 ip_rcv_finish,在这里路由选择,然后进入 dst_input。
//file: include/net/dst.h
static inline int dst_input(struct sk_buff *skb)
{
return skb_dst(skb)->input(skb);
}转发过程的这几步和接收过程一模一样的。不过内核路径就要从上面的 input 方法调用开始分道扬镳了。非本设备的不会进入 ip_local_deliver,而是会进入到 ip_forward。
//file: net/ipv4/ip_forward.c
int ip_forward(struct sk_buff *skb)
{
......
return NF_HOOK(NFPROTO_IPV4, NF_INET_FORWARD, skb, skb->dev,
rt->dst.dev, ip_forward_finish);
}在 ip_forward_finish 里会送到 IP 层的发送函数 ip_output。
//file: net/ipv4/ip_output.c
int ip_output(struct sk_buff *skb)
{
...
//再次交给 netfilter,完毕后回调 ip_finish_output
return NF_HOOK_COND(NFPROTO_IPV4, NF_INET_POST_ROUTING, skb, NULL, dev,
ip_finish_output,
!(IPCB(skb)->flags & IPSKB_REROUTED));
}在 ip_output 里会遇到 POSTROUTING 链。再后面的流程就和发送过程的下半段一样了。
总结下转发数据过程:PREROUTING链 -> 路由判断(不是本设备,找到下一跳) -> FORWARD链 -> POSTROUTING链 -> ...
1.4 iptables 汇总
理解了接收、发送和转发三个过程以后,让我们把上面三个流程汇总起来。
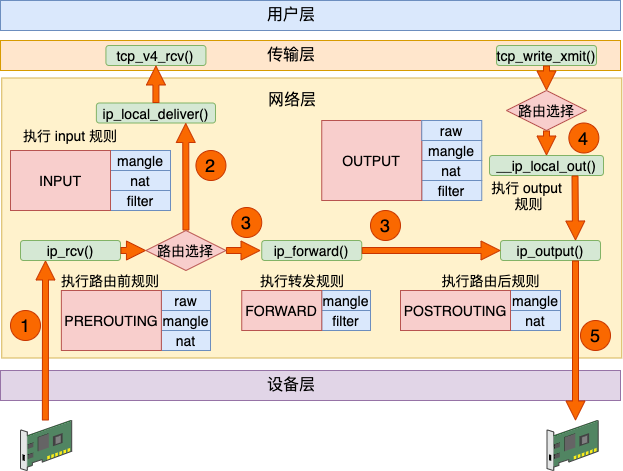
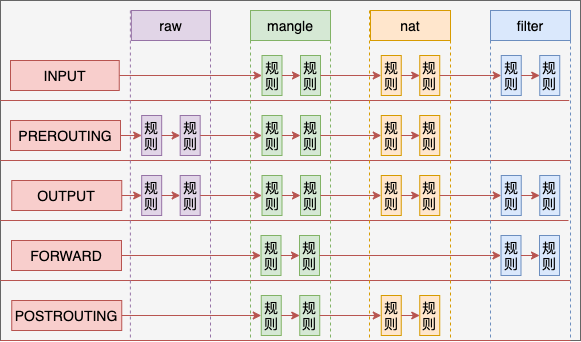
数据接收过程走的是 1 和 2,发送过程走的是 4 、5,转发过程是 1、3、5。有了这张图,我们能更清楚地理解 iptables 和内核的关系。
二、Iptables 的四表
在上一节中,我们介绍了 iptables 中的五个链。在每一个链上都可能是由许多个规则组成的。在 NF_HOOK 执行到这个链的时候,就会把规则按照优先级挨个过一遍。如果有符合条件的规则,则执行规则对应的动作。

而这些规则根据用途的不同,又可以raw、mangle、nat 和 filter。
- raw 表的作用是将命中规则的包,跳过其它表的处理,它的优先级最高。
- mangle 表的作用是根据规则修改数据包的一些标志位,比如 TTL
- nat 表的作用是实现网络地址转换
- filter 表的作用是过滤某些包,这是防火墙工作的基础
例如在 PREROUTING 链中的规则中,分别可以执行 raw、mangle 和 nat 三种功能。

我们再来聊聊,为什么不是全部四个表呢。这是由于功能的不同,不是所有功能都会完全使用到五个链。 Raw 表目的是跳过其它表,所以只需要在接收和发送两大过程的最开头处把关,所以只需要用到 PREROUTING 和 OUTPUT 两个钩子。
Mangle 表有可能会在任意位置都有可能会修改网络包,所以它是用到了全部的钩子位置。
NAT 分为 SNAT(Source NAT)和 DNAT(Destination NAT)两种,可能会工作在 PREROUTING、INPUT、OUTPUT、POSTROUTING 四个位置。
Filter 只在 INPUT、OUTPUT 和 FORWARD 这三步中工作就够了。
从整体上看,四链五表的关系如下图。
这里再多说一点,每个命名空间都是有自己独立的 iptables 规则的。我们拿 NAT 来举例,内核在遍历 NAT 规则的时候,是从 net(命名空间变量)的 ipv4.nat_table 上取下来的。NF_HOOK 最终会执行到 nf_nat_rule_find 函数。
//file: net/ipv4/netfilter/iptable_nat.c
static unsigned int nf_nat_rule_find(...)
{
struct net *net = nf_ct_net(ct);
unsigned int ret;
//重要!!!!!! nat_table 是在 namespace 中存储着的
ret = ipt_do_table(skb, hooknum, in, out, net->ipv4.nat_table);
if (ret == NF_ACCEPT) {
if (!nf_nat_initialized(ct, HOOK2MANIP(hooknum)))
ret = alloc_null_binding(ct, hooknum);
}
return ret;
}Docker 容器就是基于命名空间来工作的,所以每个 Docker 容器中都可以配置自己独立的 iptables 规则。
三、Iptables 使用举例
看完前面两小节,大家已经理解了四表五链是如何实现的了。那我们接下来通过几个实际的功能来看下实践中是如何使用 iptables 的。
3.1 nat
假如说我们有一台 Linux,它的 eth0 的 IP 是10.162.0.100,通过这个 IP 可以访问另外其它服务器。现在我们在这台机器上创建了个 Docker 虚拟网络环境 net1 出来,它的网卡 veth1 的 IP 是 192.168.0.2。
如果想让 192.168.0.2 能访问外部网络,则需要宿主网络命名空间下的设备工作帮其进行网络包转发。由于这是个私有的地址,只有这台 Linux 认识,所以它是无法访问外部的服务器的。这个时候如果想要让 net1 正常访问 10.162.0.101,就必须在转发时执行 SNAT - 源地址替换。
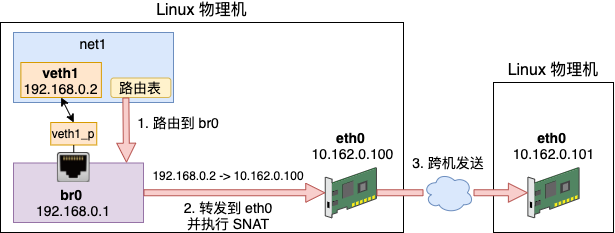
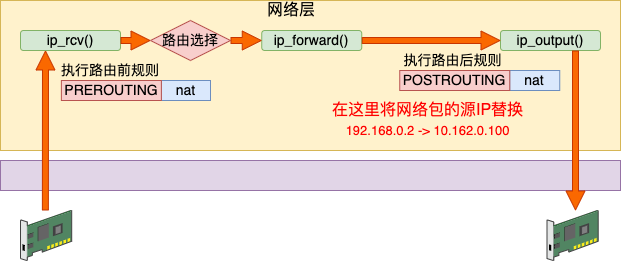
SNAT 工作在路由之后,网络包发送之前,也就是 POSTROUTING 链。我们在宿主机的命名空间里增加如下这条 iptables 规则。这条规则判断如果源是 192.168.0 网段,且目的不是 br0 的,统统执行源 IP 替换判断。
# iptables -t nat -A POSTROUTING -s 192.168.0.0/24 ! -o br0 -j MASQUERADE有了这条规则,我们来看下整个发包过程。
当数据包发出来的时候,先从 veth 发送到 br0。由于 br0 在宿主机的命名空间中,这样会执行到 POSTROUTING 链。在这个链有我们刚配置的 snat 规则。根据这条规则,内核将网络包中 192.168.0.2(外界不认识) 替换成母机的 IP 10.162.0.100(外界都认识)。同时还要跟踪记录链接状态。
3.2 DNAT 目的地址替换
接着上面小节里的例子,假设我们想在 192.168.0.2 上提供 80 端口的服务。同样,外面的服务器是无法访问这个地址的。这个时候要用到 DNAT 目的地址替换。需要在数据包进来的时候,将其目的地址替换成 192.168.0.2:80 才行。
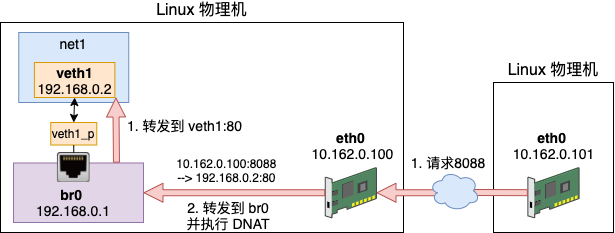
DNAT 工作在内核接收到网络包的第一个链中,也就是 PREROUTING。我们增加一条 DNAT 规则,具体的配置如下。
# iptables -t nat -A PREROUTING ! -i br0 -p tcp -m tcp --dport 8088 -j DNAT --to-destination 192.168.0.2:80
当有外界来的网络包到达 eth0 的时候。由于 eth0 在母机的命名空间中,所以会执行到 PREROUTING 链。
该规则判断如果端口是 8088 的 TCP 请求,则将目的地址替换为 192.168.0.2:80。再通过 br0(192.168.0.1)转发数据包,数据包将到达真正提供服务的 192.168.0.2:80 上。

同样在 DNAT 中也会有链接跟踪记录,所以 192.168.0.2 给 10.162.0.101 的返回包中的源地址会被替换成 10.162.0.100:8088。之后 10.162.0.101 收到包,它一直都以为自己是真的和 10.162.0.100:8088 通信。这样 net1 环境中的 veth1 也可以提供服务给外网使用了。事实上,单机的 Docker 就是通过这两小节介绍的 SNAT 和 DNAT 配置来进行网络通信的。
3.3 filter
Filter 表主要实现网络包的过滤。假如我们发现了一个恶意 IP 疯狂请求我们的服务器,对服务造成了影响。那么我们就可以用 filter 把它禁掉。其工作原理就是在接收包的 INPUT 链位置处进行判断,发现是恶意请求就尽早干掉不处理。避免进入到更上层继续浪费 CPU 开销。
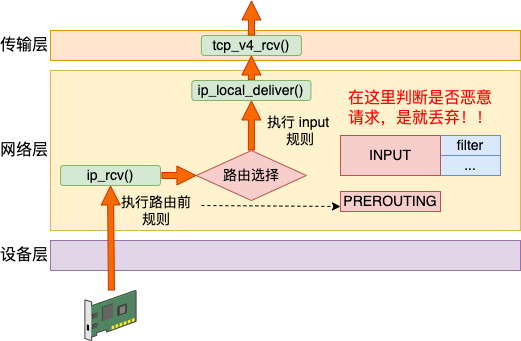
具体的配置方法细节如下:
# iptables -I INPUT -s 1.2.3.4 -j DROP //封禁
# iptables -D INPUT -s 1.2.3.4 -j DROP //解封当然也可以封禁某个 IP 段。
# iptables -I INPUT -s 121.0.0.0/8 -j DROP //封禁
# iptables -I INPUT -s 121.0.0.0/8 -j DROP //解封再比如说假设你不想让别人任意 ssh 登录你的服务器,只允许你的 IP 访问。那就只放开你自己的 IP,其它的都禁用掉就好了。
# iptables -t filter -I INPUT -s 1.2.3.4 -p tcp --dport 22 -j ACCEPT
# iptables -t filter -I INPUT -p tcp --dport 22 -j DROP 3.4 raw
Raw 表中的规则可以绕开其它表的处理。在 nat 表中,为了保证双向的流量都能正常完成地址替换,会跟踪并且记录链接状态。每一条连接都会有对应的记录生成。使用以下两个命令可以查看。
# conntrack -L
# cat /proc/net/ip_conntrack但在高流量的情况下,可能会有连接跟踪记录满的问题发生。我就遇到过一次在测试单机百万并发连接的时候,发生因连接数超过了 nf_conntrack_max 而导致新连接无法建立的问题。
# ip_conntrack: table full, dropping packet
但其实如果不使用 NAT 功能的话,链接跟踪功能是可以关闭的,例如。
# iptables -t raw -A PREROUTING -d 1.2.3.4 -p tcp --dport 80 -j NOTRACK
# iptables -A FORWARD -m state --state UNTRACKED -j ACCEPT3.5 mangle
路由器在转发网络包的时候,ttl 值会减 1 ,该值为 0 时,最后一个路由就会停止再转发这个数据包。如若不想让本次路由影响 ttl,便可以在 mangel 表中加个 1,把它给补回来。
# ptables -t mangle -A PREROUTING -i eth0 -j TTL --ttl-inc 1
所有从 eth0 接口进来的数据包的 ttl 值加 1,以抵消路由转发默认减的 1。
总结
Iptables 是一个非常常用,也非常重要的工具。Linux 上的防火墙、nat 等基础功能都是基于它实现的。还有现如今流行的的 Docker、Kubernets、Istio 项目中也经常能见着对它的身影。正因为如此,所以深入理解 iptables 工作原理是非常有价值的事情。
今天我们先是在第一节里从内核接收、发送、转发三个不同的过程理解了五链的位置。
接着又根据描述了 iptables 从功能上看的另外一个维度,表。每个表都是在多个钩子位置处注册自己的规则。当处理包的时候触发规则,并执行。从整体上看,四链五表的关系如下图。
最后我们又分别在 raw、mangle、nat、filter 几个表上举了简单的应用例子。希望通过今天的学习,你能将 iptables 彻底融会贯通。相信这一定会对你的工作有很大的帮助的!