代码优化的三重境界
写在前面:
俗话说:“九层之台,起于累土”。除了上层建筑,我们也必然得考虑程序底层结构的性能。对性能问题,我采取的是分层击破的策略,今天我将带着大家,分析影响高性能程序的底层基石 —— 代码实施。
我曾分享过一篇也是Go程序性能分析与优化的内容,讲解的上层系统与程序设计。本质上,属于不同的知识体系。当然如果有需要的朋友,我仍然建议你得空时作为拓展阅读可以看看 ,将帮助你从更上层的角度看待性能问题 ,从而完整地看下可以如何描述这棵性能分析的大树。
代码实际开发阶段,考验的是每一个Go开发者,对于 如何 书写更高效代码的理解。即便是在系统设计和程序架构都已经确定的情况下,实际的开发阶段也不是像搬砖一样毫无新意,其仍然充满创造力。
以下,Enjoy~
▶︎ 代码优化要权衡利弊
开始介绍代码实施的优化之前,我觉得有必要强调的是,最快的代码是从未运行过的代码。 你几乎总是能让程序变得更快,优化通常是一种收益递减的游戏。
实际上,大部分的架构与代码,都是逐渐迭代的过程。很多代码现在看起来很糟糕,但当时也许是成本最低的一种实现方式。不得不说,漫无目的的优化,会无端消耗精力,我们开发者需要直面遇到的最严重的性能瓶颈问题,并尽可能想办法解决。
我相信,二八定律仍然适用于代码优化中,20%的代码消耗了程序80%的时间。如果你将只占用 5% 运行时间的代码速度提高一倍,那么总程序的速度只会提高 2.5%。但是,将占用程序80%时间的代码,仅加速 10% 就将为程序带来8%的提速,成本与收益是显而易见的。

图 - 二八法则
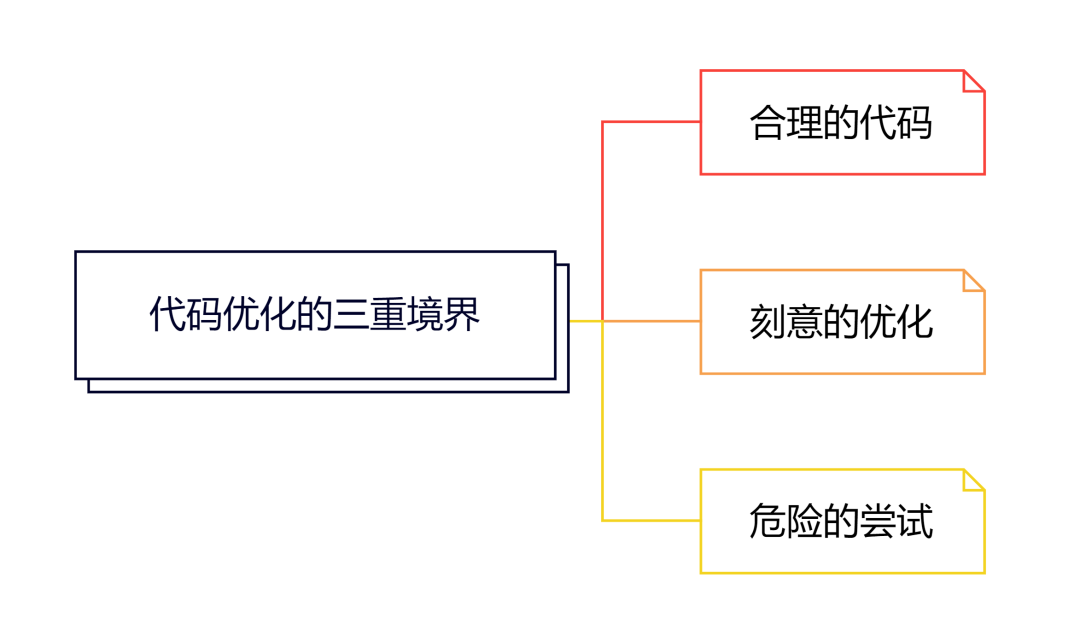
代码实施阶段的优化,可以分为下图的3个层面。其贯穿于代码设计阶段、代码开发阶段、到后期为满足特定的目标,对性能进行的合理甚至是极致的优化。
01 ⎪ 第一重境界 | 合理的代码
▶︎ 合理的代码,在高级开发者的指尖自然流淌
优秀的开发者,能够在头脑中想象出不同程序运行的过程和结果。只有在我们掌握了这样的技能之后,才能学会如何可靠地构建起能够表现出所需行为和结果的程序。
举一个例子,下图是用递归实现的斐波拉契数列,以及其执行的示意图。递归形式,是程序中比较复杂的一种过程了。高级开发者在书写这样的程序时,实际上脑海中就已经有了程序每一步如何运行的完整图像,看到程序过程的脉络。时间和空间复杂度尽收眼底。

Go语言拥有强大的标准库和保姆级别的运行时,这意味着对Go程序执行过程的把握,同样离不开对于代码表象背后底层原理的深入理解,才能够将看到的毛细血管延伸得更细致一些。
▶︎ 制度约束,保证程序在正常的轨道运行
合理的代码看起来是如此自然,然而对开发者的个人素质要求却极高。由于开发者对语言和程序设计理解上的差异,常常开发出来的代码风格迥异。因此,我们需要一些制度和规范,来帮助我们写出更符合规范的代码。
这些规范涉及程序开发的方方面面,从目录结构规范、测试规范、版本规范、目录结构规范、代码评审规范、开发规范等等。这部分,你还可以参考一下UBER开源的Go语言开发中的约定规范,链接我放这里,方便你查看:https://github.com/uber-go/guide/blob/master/style.md。
只需要遵守一些简单的规则,就能够更多地减少之后性能上的困扰。
这里举一个《Efficient Go》中的例子吧,下面的程序从功能上来看是没有问题的,往切片中添加元素。

但是这种写法却忽略了一个事实,即切片在自动扩容过程中, Go运行时会创建新的内存空间,并执行拷贝(参见《Go语言底层原理剖析》)。
这种操作显然不是没有成本的。当在循环操作中执行这样的代码,性能损失将会被放大,减慢程序的运行。性能损失的对比可参考:https://github.com/uber-go/guide/blob/master/style.md#prefer-specifying-container-capacity。

上述程序可以改写如下,在初始化时指定切片容量:

除了切片的动态扩容,哈希表的动态扩容也有类似的情况。这都是新手比较容易犯错的地方。这启发我们,即便是一开始不太理解底层的实现逻辑,也需要遵守一些基本的规则和常见的性能陷阱规避,从小事情上开始优化代码习惯。
▶︎ 程序优化 = 算法优化 + 数据结构优化
书写合理代码的第二方面,涉及到具体功能的算法和数据结构的设计与改造。有人说“程序=算法+数据结构”,可见其二者的重要性。在接触到很多业务屎山代码之后,我们总是感叹,有时候真的稍微写得合理一点,就可以避免掉后期理解成本与重构成本的大大增加。
对于算法,通常对于关键算法的调整,能带来数倍性能的提升。例如将冒泡排序(o(n^2)),替换为快速排序(o(n*logn)),将线性查找(o(n)) 替换为二分查找(o(log n)),甚至到哈希表的方式(o(1)),都是常见算法导致的性能提升。
对于数据结构,指的是添加或更改正在处理的数据的表示。这种表示很大程度上决定了数据的处理方式,进而决定了时间与空间复杂度。举一个简单的例子,如果在链表中,能够在头部节点添加一个表明链表长度的字段,则不必遍历链表来得到链表的总长度。

有时候,我们需要做一些以空间换时间的tradeoff。缓存就是一种提高性能,减少数据库访问和防止全局结构锁的机制。缓存这种空间换时间的策略,在高并发程序中应用广泛,例如不管是CPU多级缓存,还是Go运行时调度器,Go内存分配管理,甚至到标准库中sync.pool的设计,都体现了利用局部缓存提高整体并发速度的设计。
开发中通常在内存,或者借助redis等数据库缓存数据,减轻对原有数据访问的压力。当然,这中间如何提高缓存的命中率,如何设计缓存失效策略考验的,这取决于开发者基于实际场景对算法和业务的理解程度。
在设计算法与数据结构时,要考虑的另一个重要因素,是关于实现的复杂度。例如Go1.13前内存分配使用了Treap平衡树,Treap 是一种引入了随机数的二叉树搜索树,其实很简单,并且引入的随机数以及必要时的旋转,保证了比较好的平衡特性。又如redis中选择跳表,都是因为实现复杂度考虑,而没有选择实现更加复杂的红黑树。

▶︎ 效率提升能对比与量化
当完成重要过程的优化之后,鼓励大家对于功能进行benckmark性能测试,并通过benchstat 工具,对比两次benckmark的差别,做到心中有数。

02 ⎪ 第二重境界 | 刻意的优化
可以对程序刻意优化的点很多,例如:
放入接口中的数据会进行内存逃逸,需不需要优化?
字节数组与string互转的性能损失需不需要优化?
无用的内存需不需要复用?
这里我不考虑这种细节,一方面其依赖于开发者的水平和细腻程度,另一方面这些微小的性能损失很少成为瓶颈,至少在项目开发的初期是这样。
因此这里我想要讨论的刻意优化,指的是在项目开发和迭代过程中,为了达成需求目标而刻意对于性能瓶颈的优化。只关注最核心要解决的问题。总的来说,基于两者在通信层面的对比,我们因此能总结出它们本质上的差异:SOA基于配置,微服务则基于约定。
▶︎ 优化前提,是定位瓶颈问题
能够发现程序哪里有问题,想办法解决,比写出正确的程序,对开发者的要求其实要更高一些。因为在排查问题时遇到的不确定性更多,需要掌握的能力也更多。接下来,我将介绍排查程序性能瓶颈的常见手段。
很显然,如果能从上帝视角查看到 这段时间内程序运行的完整图像,就像是把胃镜深入胃里,一览无余定位到问题。运行中的程序就像是一个黑盒,我们能在多大程度上还原、收集、统计、分析程序的运行轨迹,就能够多大程度上更容易查看到程序的病症。
接下来要介绍的pprof与trace工具,就是借助操作系统与Go运行时,收集与统计一段时间内程序运行过程中产生的各种指标、聚合统计并可视化。对这些可视化图像的正确理解与分析,有助于帮助你在实际遇到性能问题时有的放矢,把握程序的运行脉络。
对于CPU资源来讲,要排查延迟和评估耗时最多的瓶颈在哪一个地方,除了查看代码、单元测试、在代码中打印耗时等手段,实践中通常使用pprof工具查看CPU耗时。示例如下:

pprof CPU 分析器,使用定时发送SIGPROF 信号中断代码执行。
当调用 pprof.StartCPUProfile 函数时,SIGPROF 信号处理程序,将被注册为默认每 10 毫秒间隔调用一次(100 Hz)。在 Unix 上,它使用 setitimer(2) 系统调用,来设置信号计时器。
当内核态返回到用户态调用注册好的sighandler 函数,sighandler 函数识别到信号为_SIGPROF 时,执行sigprof 函数记录该CPU样本,并以此机会获取当前代码的栈帧数据。

这些堆栈信息,最终合并为profile文件。并最终被pprof分析程序处理。

另一种常见性能分析的形式,是查看火焰图,仍然可以借助pprof。火焰图是软件分析中用于特征和性能分析的利器,因其形状和颜色像火焰而得名。火焰图可以快速准确地识别出最频繁使用的代码路径,从而得知程序的瓶颈所在。

以CPU 火焰图为例说明如下:
• 最上方的root 框代表整个程序的开始,其他的框都代表一个函数。
• 火焰图每一层中的函数都是平级的,下层函数是其对应的上层函数的子函数。
• 函数调用栈越长,火焰就越高。
• 框越长、颜色越深,代表当前函数占用CPU 时间越久。
• 可以单击任何框,查看该函数更详细的信息。
知道pprof 和火焰图中数字背后的意义,是非常重要的。现实中常常有很多人对这一指标,有比较深的误解,主要在于详细讲解如何观察pprof的文章很少。pprof通过统计学中采样的方式,得到了调用频率最多的函数。一个函数可能本身耗时不多,但是有大量的循环导致了总的函数耗时上涨。
同样地,一个函数可能耗时多,也不一定能够被捕获住。比如正常情况下,我们无法捕获到处理GC的函数。
通过pprof,找到我们关心的耗时最多,即cpu耗时最多的耗时,很多时候这样的函数,就是我们想要解决的瓶颈。不过,我们仍然需要清醒地认识到,在pprof图像中并不能够涵盖所有信息,例如一个长时间在等待状态下的协程,其本身是不消耗CPU的,也就不可能出现在pprof中,但是其可能会导致耗时变慢。
就是说,耗时变高可能并不来自于CPU繁忙,甚至恰恰相反,可能完全没有进入CPU处理。
对于这种情况,可以进行进一步的分析,在这里借助更强悍的trace工具,去观察程序的运行状态。在之前借助trace分析过程序的并行情况,这种强大的分析,借助于Go运行时在关键时刻进行的埋点。例如当进行协程切换时,记录下来一个事件,即可知道某一时刻线程对应的M从协程A切换到了协程B。
trace中的Goroutine analysis,是一个非常有用的工具,可以用来分析某一个协程的具体情况。

如下示例中,在抓取trace样本的一段时间内,一段协程可能执行了n次。而下图展示的就是对于这些协程按照时间进行由大到小的排序。从这里我们能看到某一个耗时最多的协程其主要的耗时是在哪一个地方。是耗时在了CPU、网络I/O、GC、调度器延迟、锁、还是系统调用上。这是一种非常强悍的观察方式,甚至是在实践中解决p99问题的法宝。

当我们知道了具体是哪一个部分,例如锁导致的瓶颈,GC导致的瓶颈,这时还需要定位到具体是哪一行函数,点击上图中的某一个协程ID号,即会跳转到该协程的调度页面,找到加锁的位置或触发GC的那一次内存操作。
有时候问题是棘手的,特别是当这些问题来自于Go源码的bug时,这里需要观察代码并结合dlv等更高级的调试手段,找到问题的根因。
▶︎ 瓶颈问题需对症下药工具暴露出来的瓶颈,通常就是我们要优化的目标,有时这种瓶颈是不明显的,还需要开发者做一些假设并验证自己的猜想。除了将不合理的数据结构与算法变得更加合理。这里要强调,有一些结构在之前是合理的,但是当结构或并发越来越大,就不太合理了。
例如程序中使用json进行结构序列化,由于标准库比较通用并使用大量反射,导致在并发量上来之后可能变为瓶颈,这时可以考虑将其替换为更快的第三方库。甚至替换序列化的方式为protobuf等更快的序列化方式。
还有一些优化涉及到对Go语言编译时与运行时的调整。例如之前介绍过的将环境变量GOMAXPROC调整为更合适的大小,本质上就是在修改运行时可并行的线程数量。
另外当并发量上来之后,GC确实可能成为系统的瓶颈所在。原因是GC有一段STW的时长,并且在并行标记期间占用了25%的CPU时间。而且在并发标记阶段出现的频繁内存分配,可能会导致辅助标记,进而导致程序无法有效处理用户协程,出现严重的响应超时问题。

图 - 垃圾回收(来自《Go底层原理剖析》)
一般GC问题需要修改代码,减少频繁的内存分配,或是借助sync.pool等内存池复用内存。另外运行时也暴露了一些有限的api能够干预垃圾回收的运行:
• 运行时环境变量GOGC调整GC的内存触发水位,GOGC=off甚至能够关闭GC的执行;
• Runtime.GC()手动强制执行GC;
• GODEBUG=gctrace=1 追踪GC的表现。
还有一些刻意的优化与Go版本有关,例如GO1.14以前死循环没有办法被抢占,导致程序被卡死的现象在实践中经常出现。那么在使用这种版本时,就不得不做一些特殊的判断和处理。
03 ⎪ 第三重境界 | 危险的优化
代码实施阶段,由于迫不得已的原因,需要进行一些特别的处理。例如由于很多机器学习库是用C或者C++完成的,因此需要使用CGO的技术。我曾经深度写过CGO相关的项目,苦不堪言。没有编辑器的提示,繁琐的语法,难以调试,内存不受到Go运行时的管理等问题,在迫不得已下,不要使用CGO。

图 - cgo代码
Go语言语法本身屏蔽了指针的操作,而且确实有些场景为了提高性能等高级操作会使用到unsafe库。然而,想要正确地使用unsafe,是很难的。
首先Go语言中的unsafe库本身,不是向后兼容的,这意味着在之后当前版本中正确的代码在之后的版本中可能是不正确的。
另外,对指针进行运算的uintptr,其本质上是一个整数,Go内置的垃圾回收无法管理。当操作指针时,由于Go运行时栈的自动扩容,可能导致之前指针指向的内容无效。这些危险的操作,需要开发者正确的权衡,并知道其正确的使用规则。对unsafe包的用法,可以参考:https://go101.org/article/unsafe.html。
有时候一些底层操作,为了获得更高的性能和语言,未暴露的功能甚至涉及到需要书写汇编代码。
04 ⎪ 总结
一座房子是由每一块砖砌成的,代码实施在码好每一块砖的同时,也极具创造力,考验开发者深刻的功力。代码实施阶段,分为了三层境界:合理的优化,刻意的优化,危险的优化。其贯穿于设计、开发与问题排查、调优。

全文思维导图
当优秀的代码能从指尖自然流淌时,我们才是一个合格的开发者,而当我们可以精细化的调优,驾驭整个程序时,我们的技术功夫已经臻于化境。
好,这次我们就交流到这里,非常感谢你耐心的阅读,我们在后面的分享再见。同时期待后续的某几个时段里,我与你能够有更多思想上的交流、碰撞。如果愿意分享,这一讲也欢迎转发给你的朋友,和他一起讨论。
参考资料:
[1] uber Go语言规范:https://github.com/uber-go/guide/blob/master/style.md
[2] Go底层原理:《Go底层原理剖析》
[3] 关于unsafe与cgo危险的优化:《Learning Go》Chapter 14. Here There Be Dragons: Reflect, Unsafe, and Cgo