面试官:哥们Go语言的读写锁了解多少?
前言
在上一文中:[面试官:哥们Go语言互斥锁了解到什么程度了?] 我们一起学习了Go语言中互斥锁是如何实现的,本文我们就来一起学习Go语言中读写锁是如何设计的,互斥锁可以保证多线程在访问同一片内存时不会出现竞争来保证并发安全,因为互斥锁锁定代码临界区,所以当并发量较高的场景下会加剧锁竞争,执行效率就会越来越差;因此就引申出更细粒度的锁:读写锁,适用于读多写少的情景,接下来我们就详细看看读写锁。
Golang版本:1.18
读写锁简介
互斥锁我们都知道会锁定代码临界区,当有一个goroutine获取了互斥锁后,任何goroutine都不可以获取互斥锁,只能等待这个goroutine将互斥锁释放,无论读写操作都会加上一把大锁,在读多写少场景效率会很低,所以大佬们就设计出了读写锁,读写锁顾名思义是一把锁分为两部分:读锁和写锁,读锁允许多个线程同时获得,因为读操作本身是线程安全的,而写锁则是互斥锁,不允许多个线程同时获得写锁,并且写操作和读操作也是互斥的,总结来说:读读不互斥,读写互斥,写写互斥;
为什么要有读锁
有些朋友可能会有疑惑,为什么要有读锁,读操作又不会修改数据,多线程同时读取相同的资源就是安全的,为什么还要加一个读锁呢?
举个例子说明,在Golang中变量的赋值不是并发安全的,比如对一个int型变量执行count++操作,在并发下执行就会出现预期之外的结果,因为count++操作分为三部分:读取count的值、将count的值加1,然后再将结果赋值给count,这不是一个原子性操作,未加锁时在多个线程同时对该变量执行count++操作会造成数据不一致,通过加上写锁可以解决这个问题,但是在读取的时候我们不加读锁会怎么样呢?写个例子来看一下,只加写锁,不加读锁:
package main
import "sync"
const maxValue = 3
type test struct {
rw sync.RWMutex
index int
}
func (t *test) Get() int {
return t.index
}
func (t *test)Set() {
t.rw.Lock()
t.index++
if t.index >= maxValue{
t.index =0
}
t.rw.Unlock()
}
func main() {
t := test{}
sw := sync.WaitGroup{}
for i:=0; i < 100000; i++{
sw.Add(2)
go func() {
t.Set()
sw.Done()
}()
go func() {
val := t.Get()
if val >= maxValue{
print("get value error| value=", val, "\n")
}
sw.Done()
}()
}
sw.Wait()
}运行结果:
get value error| value=3
get value error| value=3
get value error| value=3
get value error| value=3
get value error| value=3
.....每次运行结果都是不固定的,因为我们没有加读锁,如果允许同时读和写,读取到的数据有可能就是中间状态,所以我们可以总结出来读锁是很有必要的,读锁可以防止读到写中间的值。
读写锁的插队策略
多个读操作同时进行时也是线程安全的,一个线程获取读锁后,另外一个线程同样可以获取读锁,因为读锁是共享的,如果一直都有线程加读锁,后面再有线程加写锁就会一直获取不到锁造成阻塞,这时就需要一些策略来保证锁的公平性,避免出现锁饥饿,那么Go语言中读写锁采用的是什么插队策略来避免饥饿问题呢?
这里我们用一个例子来说明一下Go语言的插队策略:
假设现在有5个goroutine分别是G1、G2、G3、G4、G5,现在G1、G2获取读锁成功,还没释放读锁,G3要执行写操作,获取写锁失败就会阻塞等待,当前阻塞写锁的读锁goroutine数量为2:
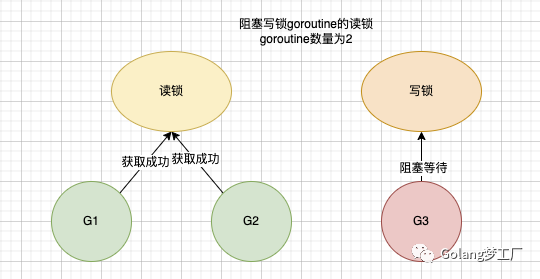
G4进来想要获取读锁,这时她就会判断如果当前有写锁的goroutine正在阻塞等待,为了避免写锁饥饿,那这个G4也会进入阻塞等待,后续G5进来想要获取写锁,因为G3在占用互斥锁,所以G5会进入自旋/休眠 阻塞等待;
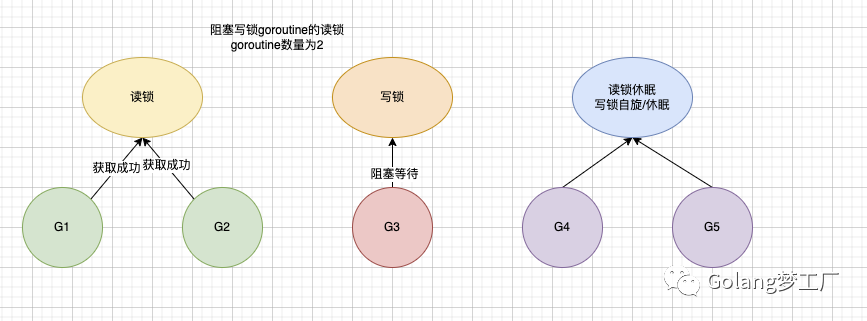
G1、G2释放了读锁,当释放读锁是判断如果阻塞写锁goroutine的读锁goroutine数量为0了并且有写锁等待就会唤醒正在阻塞等待的写锁G3,G3得到了唤醒:
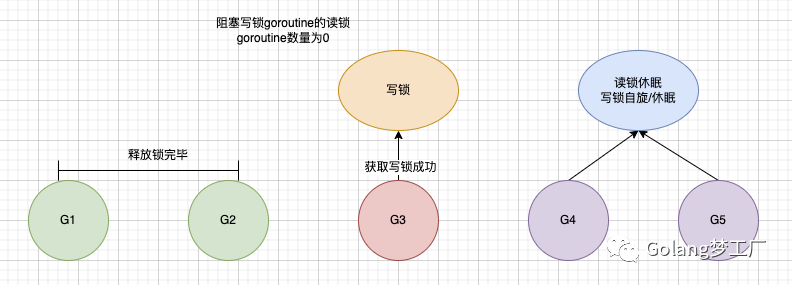
G3处理完写操作后会释放写锁,这一步会同时唤醒等待的读锁/写锁的goroutine,至于G4、G5谁能先获取锁就看谁比较快了,就像抢媳妇一样,先下手的先得呀。
读写锁的实现
接下来我们就深入源码分析一下,先看一下RWMutex结构都有啥:
type RWMutex struct {
w Mutex // held if there are pending writers
writerSem uint32 // semaphore for writers to wait for completing readers
readerSem uint32 // semaphore for readers to wait for completing writers
readerCount int32 // number of pending readers
readerWait int32 // number of departing readers
}w:复用互斥锁提供的能力;writerSem:写操作goroutine阻塞等待信号量,当阻塞写操作的读操作goroutine释放读锁时,通过该信号量通知阻塞的写操作的goroutine;readerSem:读操作goroutine阻塞等待信号量,当写操作goroutine释放写锁时,通过该信号量通知阻塞的读操作的goroutine;redaerCount:当前正在执行的读操作goroutine数量;readerWait:当写操作被阻塞时等待的读操作goroutine个数;
读锁
读锁的对应方法如下:
func (rw *RWMutex) RLock() {
// 原子操作readerCount 只要值不是负数就表示获取读锁成功
if atomic.AddInt32(&rw.readerCount, 1) < 0 {
// 有一个正在等待的写锁,为了避免饥饿后面进来的读锁进行阻塞等待
runtime_SemacquireMutex(&rw.readerSem, false, 0)
}
}精简了竞态检测的方法,读锁方法就只有两行代码了,逻辑如下:
使用原子操作更新readerCount,将readercount值加1,只要原子操作后值不为负数就表示加读锁成功,如果值为负数表示已经有写锁获取互斥锁成功,写锁goroutine正在等待或运行,所以为了避免饥饿后面进来的读锁要进行阻塞等待,调用runtime_SemacquireMutex阻塞等待。
非阻塞加读锁
Go语言在1.18中引入了非阻塞加读锁的方法:
func (rw *RWMutex) TryRLock() bool {
for {
// 读取readerCount值能知道当前是否有写锁在阻塞等待,如果值为负数,那么后面的读锁就会被阻塞住
c := atomic.LoadInt32(&rw.readerCount)
if c < 0 {
if race.Enabled {
race.Enable()
}
return false
}
// 尝试获取读锁,for循环不断尝试
if atomic.CompareAndSwapInt32(&rw.readerCount, c, c+1) {
if race.Enabled {
race.Enable()
race.Acquire(unsafe.Pointer(&rw.readerSem))
}
return true
}
}
}因为读锁是共享的,在没有写锁阻塞等待时多个线程可以同时获取,所以原子性操作可能会失败,这里采用for循环来增加尝试次数,很是巧妙。
释放读锁
释放读锁代码主要分为两部分,第一部分:
func (rw *RWMutex) RUnlock() {
// 将readerCount的值减1,如果值等于等于0直接退出即可;否则进入rUnlockSlow处理
if r := atomic.AddInt32(&rw.readerCount, -1); r < 0 {
// Outlined slow-path to allow the fast-path to be inlined
rw.rUnlockSlow(r)
}
}我们都知道readerCount的值代表当前正在执行的读操作goroutine数量,执行递减操作后的值大于等于0表示当前没有异常场景或写锁阻塞等待,所以直接退出即可,否则需要处理这两个逻辑:
rUnlockSlow逻辑如下:
func (rw *RWMutex) rUnlockSlow(r int32) {
// r+1等于0表示没有加读锁就释放读锁,异常场景要抛出异常
// r+1 == -rwmutexMaxReaders 也表示没有加读锁就是释放读锁
// 因为写锁加锁成功后会将readerCout的值减去rwmutexMaxReaders
if r+1 == 0 || r+1 == -rwmutexMaxReaders {
race.Enable()
throw("sync: RUnlock of unlocked RWMutex")
}
// 如果有写锁正在等待读锁时会更新readerWait的值,所以一步递减rw.readerWait值
// 如果readerWait在原子操作后的值等于0了说明当前阻塞写锁的读锁都已经释放了,需要唤醒等待的写锁
if atomic.AddInt32(&rw.readerWait, -1) == 0 {
// The last reader unblocks the writer.
runtime_Semrelease(&rw.writerSem, false, 1)
}
}解读一下这段代码:
r+1等于0说明当前goroutine没有加读锁就进行释放读锁操作,属于非法操作r+1 == -rwmutexMaxReaders说明写锁加锁成功了会将readerCount的减去rwmutexMaxReaders变成负数,如果此前没有加读锁,那么直接释放读锁就会造成这个等式成立,也属于没有加读锁就进行释放读锁操作,属于非法操作;readerWait代表写操作被阻塞时读操作的goroutine数量,如果有写锁正在等待时就会更新readerWait的值,读锁释放锁时需要readerWait进行递减,如果递减后等于0说明当前阻塞写锁的读锁都已经释放了,需要唤醒等待的写锁。(看下文写锁的代码就呼应上了)
写锁
写锁对应的方法如下:
const rwmutexMaxReaders = 1 << 30
func (rw *RWMutex) Lock() {
// First, resolve competition with other writers.
// 写锁也就是互斥锁,复用互斥锁的能力来解决与其他写锁的竞争
// 如果写锁已经被获取了,其他goroutine在获取写锁时会进入自旋或者休眠
rw.w.Lock()
// 将readerCount设置为负值,告诉读锁现在有一个正在等待运行的写锁(获取互斥锁成功)
r := atomic.AddInt32(&rw.readerCount, -rwmutexMaxReaders) + rwmutexMaxReaders
// 获取互斥锁成功并不代表goroutine获取写锁成功,我们默认最大有2^30的读操作数目,减去这个最大数目
// 后仍然不为0则表示前面还有读锁,需要等待读锁释放并更新写操作被阻塞时等待的读操作goroutine个数;
if r != 0 && atomic.AddInt32(&rw.readerWait, r) != 0 {
runtime_SemacquireMutex(&rw.writerSem, false, 0)
}
}代码量不是很大,但是理解起来还有一点复杂,我尝试用文字来解析一下,主要分为两部分:
- 获取互斥锁,写锁也就是互斥锁,这里我们复用互斥锁
mutex的加锁能力,当互斥锁加锁成功后,其他写锁goroutine再次尝试获取锁时就会进入自旋休眠等待; - 判断获取写锁是否成功,这里有一个变量
rwmutexMaxReaders = 1 << 30表示最大支持2^30个并发读,互斥锁加锁成功后,假设2^30个读操作都已经释放了读锁,通过原子操作将readerCount设置为负数在加上2^30,如果此时r仍然不为0说面还有读操作正在进行,则写锁需要等待,同时通过原子操作更新readerWait字段,也就是更新写操作被阻塞时等待的读操作goroutine个数;readerWait在上文的读锁释放锁时会进行判断,进行递减,当前readerWait递减到0时就会唤醒写锁。
非阻塞加写锁
Go语言在1.18中引入了非阻塞加锁的方法:
func (rw *RWMutex) TryLock() bool {
// 先判断获取互斥锁是否成功,没有成功则直接返回false
if !rw.w.TryLock() {
if race.Enabled {
race.Enable()
}
return false
}
// 互斥锁获取成功了,接下来就判断是否是否有读锁正在阻塞该写锁,如果没有直接更新readerCount为
// 负数获取写锁成功;
if !atomic.CompareAndSwapInt32(&rw.readerCount, 0, -rwmutexMaxReaders) {
rw.w.Unlock()
if race.Enabled {
race.Enable()
}
return false
}
return true
}释放写锁
func (rw *RWMutex) Unlock() {
// Announce to readers there is no active writer.
// 将readerCount的恢复为正数,也就是解除对读锁的互斥
r := atomic.AddInt32(&rw.readerCount, rwmutexMaxReaders)
if r >= rwmutexMaxReaders {
race.Enable()
throw("sync: Unlock of unlocked RWMutex")
}
// 如果后面还有读操作的goroutine则需要唤醒他们
for i := 0; i < int(r); i++ {
runtime_Semrelease(&rw.readerSem, false, 0)
}
// 释放互斥锁,写操作的goroutine和读操作的goroutine同时竞争
rw.w.Unlock()
}释放写锁的逻辑比较简单,释放写锁会将会面的读操作和写操作的goroutine都唤醒,然后他们在进行竞争;
总结
因为我们上文已经分享了互斥锁的实现方式,再来看读写锁就轻松许多了,文末我们再来总结一下读写锁:
-
读写锁提供四种操作:读上锁,读解锁,写上锁,写解锁;加锁规则是读读共享,写写互斥,读写互斥,写读互斥;
-
读写锁中的读锁是一定要存在的,其目的是也是为了规避原子性问题,只有写锁没有读锁的情况下会导致我们读取到中间值;
-
Go语言的读写锁在设计上也避免了写锁饥饿的问题,通过字段
readerCount、readerWait进行控制,当写锁的goroutine被阻塞时,后面进来想要获取读锁的goroutine也都会被阻塞住,当写锁释放时,会将后面的读操作goroutine、写操作的goroutine都唤醒,剩下的交给他们竞争吧; -
读锁获取锁流程:
-
锁空闲时,读锁可以立马被获取
-
如果当前有写锁正在阻塞,那么想要获取读锁的
goroutine就会被休眠 -
释放读锁流程:
-
当前没有异常场景或写锁阻塞等待出现的话,则直接释放读锁成功
-
若没有加读锁就释放读锁则抛出异常;
-
写锁被读锁阻塞等待的场景下,会将
readerWait的值进行递减,readerWait表示阻塞写操作goroutine的读操作goroutine数量,当readerWait减到0时则可以唤醒被阻塞写操作的goroutine了; -
写锁获取锁流程
-
写锁复用了
mutex互斥锁的能力,首先尝试获取互斥锁,获取互斥锁失败就会进入自旋/休眠; -
获取互斥锁成功并不代表写锁加锁成功,此时如果还有占用读锁的
goroutine,那么就会阻塞住,否则就会加写锁成功 -
释放写锁流程
-
释放写锁会将负值的
readerCount变成正值,解除对读锁的互斥 -
唤醒当前阻塞住的所有读锁
-
释放互斥锁
读写锁的代码量不多,因为其复用了互斥锁的设计,针对读写锁的功能多做了一些工作,理解起来比互斥锁要容易很多,你学会了吗?宝贝~。
好啦,本文到这里就结束了, 我们下期见。