一日一技:如何正确为历史遗留代码补充单元测试?

我们知道,在软件工程中,单元测试是保证软件质量的重要手段之一。一个优秀的代码,单元测试的代码量,经常会超过被测试的代码本身。一个理想化的开发团队,可能有三分之二的时间是在写测试,剩下的三分之一时间才是写业务代码。
如果你的项目是从一开始就写单元测试,那么你写起来应该轻松又愉快,因为单元测试会促使你的代码自身变成可测试的代码。
但如果你接手了一个大项目,里面已经有几十万行代码了,那么给这些代码补单元测试会让你知道什么叫做痛不欲生。你会发现有一些函数,它让你不知道怎么写测试代码。但你又不能随便修改代码的结构,谁知道会引起什么连锁反应?
我们来看一个例子:

business_code里面,check_data_dup分别返回True或者False的时候,下面代码的逻辑。也就是说,我只关心第18-27行的逻辑。这个时候不关心MySQL和Redis。但是每次测试都要从他们里面读取数据,这样就会导致测试代码依赖外部环境。如果MySQL或者Redis挂了,那么测试代码就会运行失败。
而且,就算Redis和MySQL没有故障,你怎么知道你的data_id和pk,在数据库中对应的是什么数据?为了分别走到特定的分支,你还需要去检测数据库中特定数据的id。万一是测试环境,别人修改了里面的数据,你的测试也可能会挂掉。
如果直接使用Pytest来写测试案例,代码是这样的:
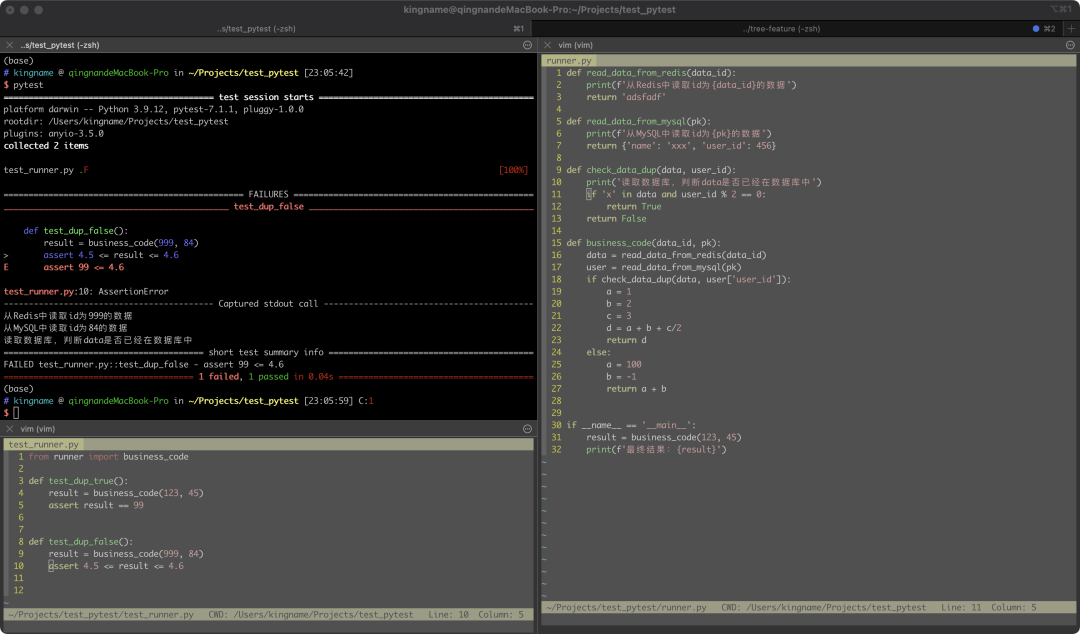
check_data_dup走到返回True逻辑的情况。
难道为了让单元测试进行下去,我还要去数据库构造一条特定的数据?这只是单元测试,又不是集成测试。
为了解决这个问题,我们就可以使用mock模块。这是Python自带的一个模块,可以动态替换函数。
它的写法非常简单:
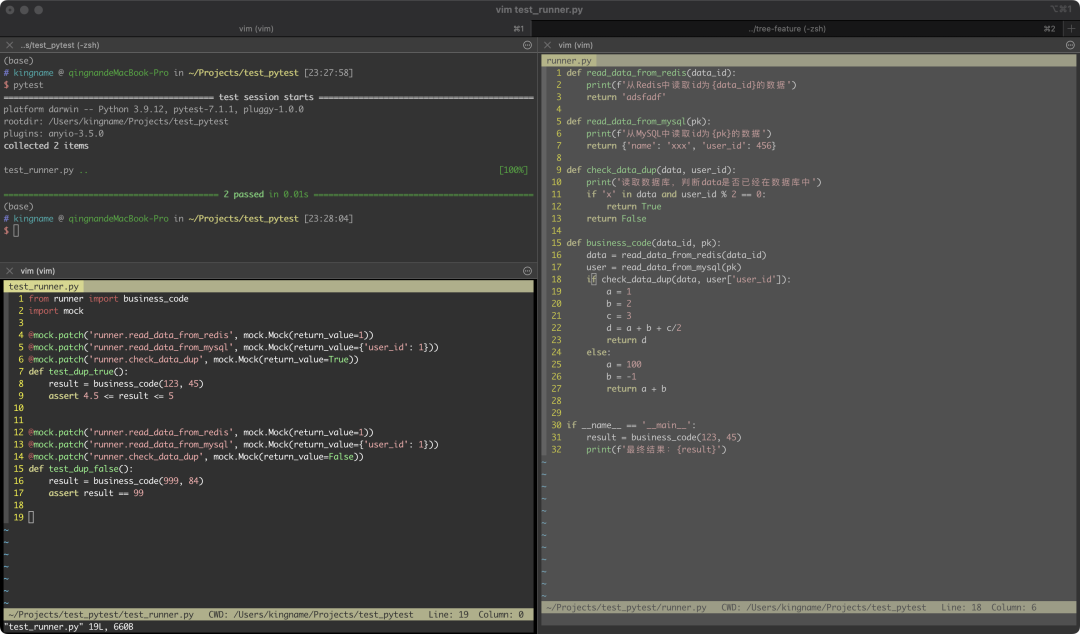
@mock.patch装饰器,装饰测试函数就可以了。这个装饰器接收两个参数,第一个参数是被模拟的函数的路径,以点分割;第二个参数是你想让它返回的值。
从上图可以看到,test_runner.py运行以后,原本在read_data_from_redis和read_data_from_mysql中打印的两段文字都没有打印,说明这两个函数已经被动态替换了,他们内部的代码不会运行。只会直接返回我们预设的这个返回值。这样一来就跟数据库解耦了。
注意,在上图中,由于我们已经mock了check_data_dup,因此read_data_from_redis和read_data_from_mysql两个函数随便返回什么值都可以。如果你想顺带也测试一下check_data_dup,那么可以不mock它,如下图所示。
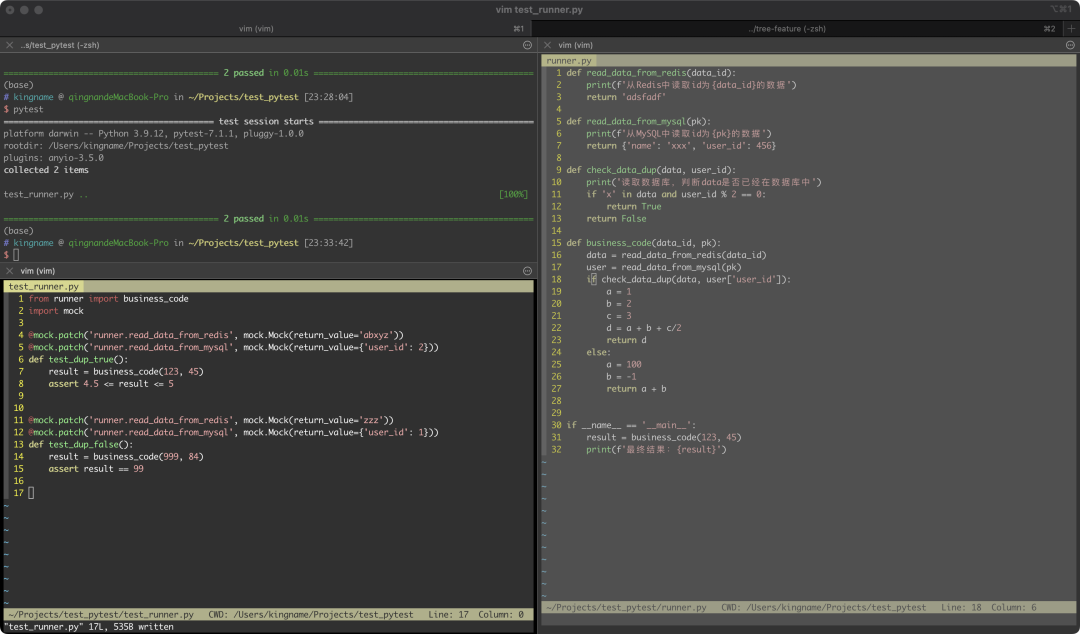
check_data_dup函数的逻辑中,如果data参数含有字符x,并且user_id是偶数,就返回True,否则返回False。我们通过mock两个读数据的函数,分别设置不同的返回值,就能满足让check_data_dup返回不同值的条件。
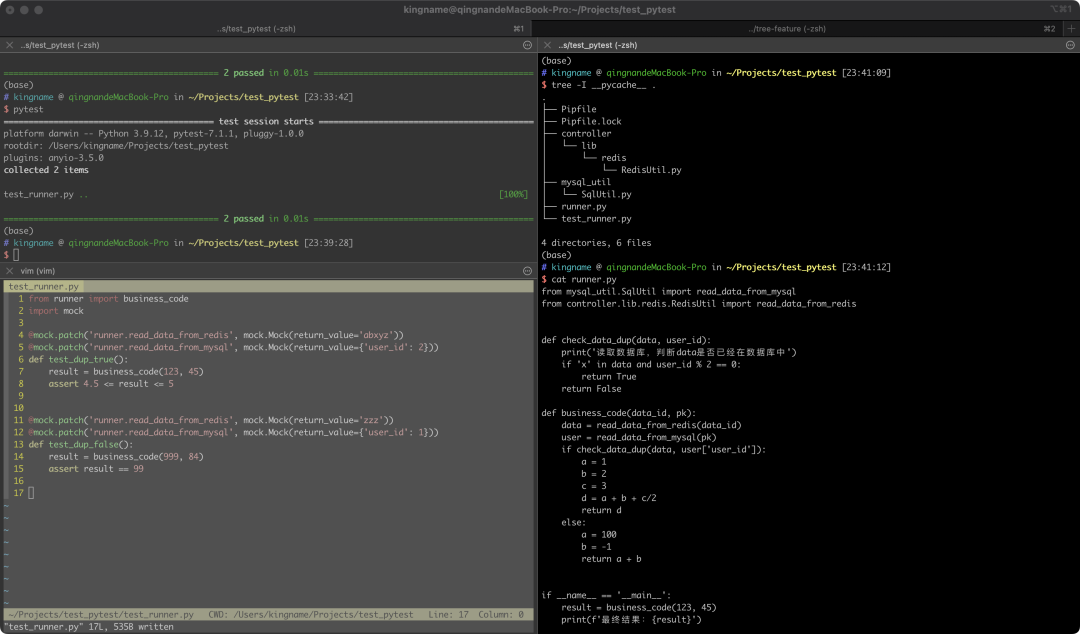
mock.path有一个小坑,一定要注意。我们来看看下面这个文件结构:
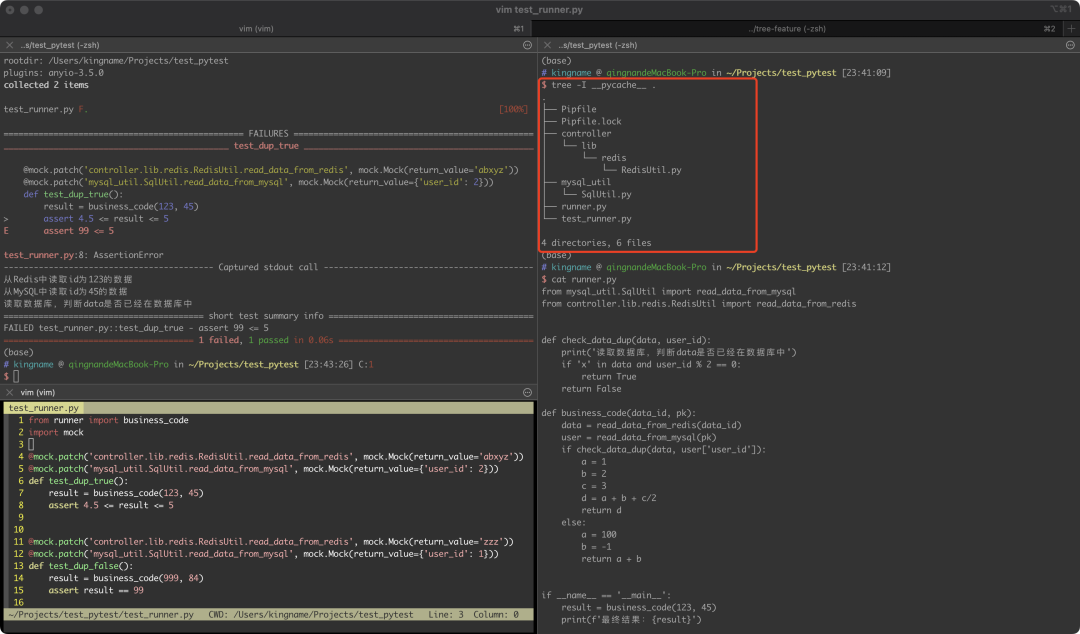
read_data_from_redis和read_data_from_mysql两个函数分布在了不同的文件里面。在runner.py中导入并使用了他们。test_runner.py中,我们使用@mock.patch对这两个函数定义的路径打补丁进行替换。可是替换了以后,运行Pytest,会发现这两个函数竟然正常运行了。也就是说我们的替换失败了。
之所以会出现这种情况,是因为我们要打补丁的并不是这两个函数定义的地方,而是使用的地方。我们在runner.py中,分别使用如下两个语句:
from mysql_util.SqlUtil import read_data_from_mysql
from controller.lib.redis.RedisUtil import read_data_from_redis导入了这两个函数,我们也是在runner.py中使用他们的。因此,@mock.patch的第一个参数,依然应该是runner.read_data_from_redis和runner.read_data_from_mysql。
正确的做法如下图所示:
mock.patch还有更多高级用法,例如替换类,替换实例方法等等。可以在unittest.mock中找到他。从Python 3.3开始,官方自带了unittest.mock,它跟直接import mock的效果是一样的。