图文详解 Java 泛型,写得太好了!
泛型—— 一种可以接收数据类型的数据类型,本文将通俗讲解Java泛型的优点、方法及相关细节。
一、泛型的引入
我们都知道,继承是面向对象的三大特性之一,比如在我们向集合中添加元素的过程中add()方法里填入的是Object类,而Object又是所有类的父类,这就产生了一个问题——添加的类型无法做到统一 由此就可能产生在遍历集合取出元素时类型不统一而报错问题。
例如:我向一个ArrayList集合中添加Person类的对象,但是不小心手贱添加了一个Boy类的对象,这就会导致如下结果
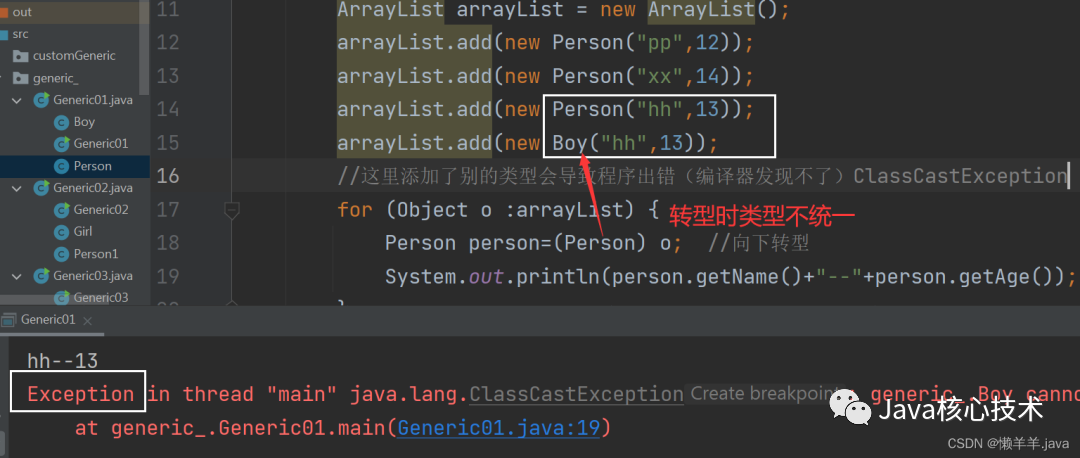
二、使用泛型的好处
1.提升了程序的健壮性和规范性
针对上述问题,当我们采用泛型就会显得非常简单,只需要在编译类型后利用泛型指定一个特定类型,编译器就会自动检测出不符合规范的类并抛出错误提示
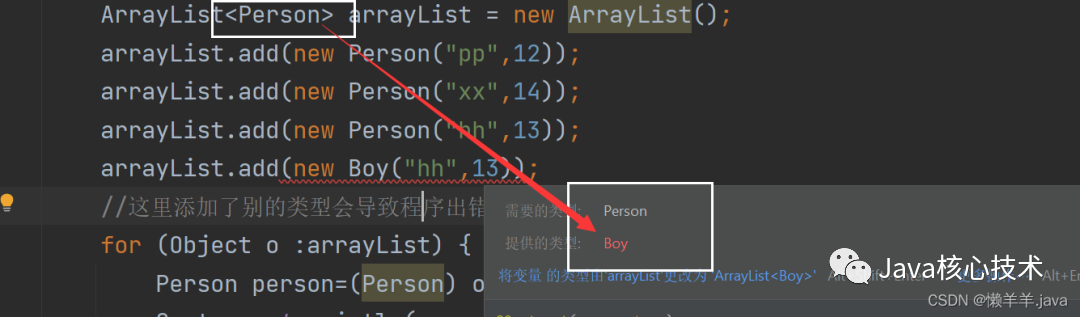
3.减少了类型转换的次数,提高效率
- 当不使用泛型时:
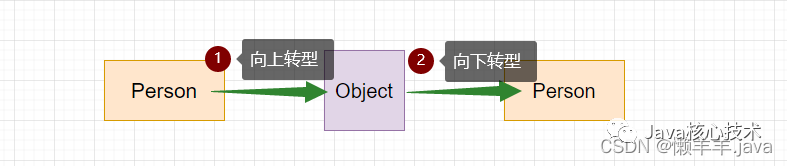
- 当使用泛型时:
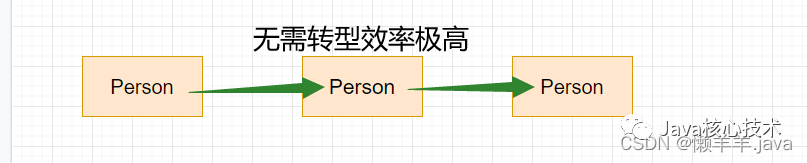
4 .在类声明时通过一个标识可以表示属性类型、方法的返回值类型、参数类型
class Person<E> {
E s; //可以是属性类型
public Person(E s) { //可以是参数类型
this.s = s;
}
public E f() { //可以是返回类型
return s;
}
public void show() {
System.out.println(s.getClass()); //显示S的运行类型
}
}可以这样理解:上述的class Person< E >中的“E”相当于这里的E是一个躯壳 占位用的 以后定义的时候程序员可以自己去自定义。
[就像这样]
public static void main(String[] args) {
Person<String> person1 = new Person<String>("xxxx");// E->String
person.show();
Person<Integer> person2 = new Person<Integer>(123); // E->Integer
person.show();
}
运行结果:
class java.lang.String
class java.lang.Integer[三、泛型常见用法]
[1.定义泛型接口]
[曾经写接口的时候都没有定义泛型,它默认的就是Object类,其实这样写是不规范的!]
[如果说接口的存在是一种规范,那泛型接口就是规范中的规范]
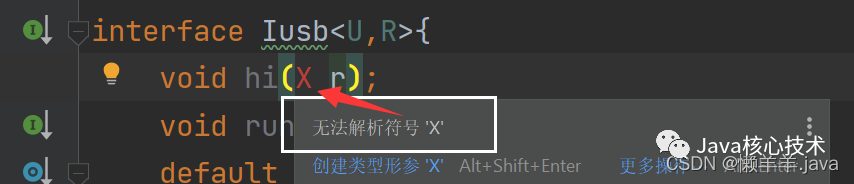
interface Im<U,R>{
void hi(R r);
void hello(R r1,R r2,U u1,U u2);
default R method(U u){
return null;
}
}[在上述的泛型接口中已经规定传入其中的必须是U,R类的对象,那么当我们传入其他类的对象时就会报错,如图:]
2.定义泛型集合
[1.使用泛型方式给HashSet中放入三个学生对象,并输出对象信息]
HashSet<Student> students = new HashSet<Student>();
students.add(new Student("懒羊羊",21));
students.add(new Student("喜羊羊",41));
students.add(new Student("美羊羊",13));
for (Student student :students) {
System.out.println(student);
}[上述的 泛型中Student的是我事先定义好的一个类,把它放到其中作为泛型来约束传入的对象,以及在遍历时减少转型的次数提高效率]
[2.使用泛型方式给HashMap中放入三个学生对象,并输出对象信息]
HashMap<String, Student> hm = new HashMap<String, Student>();
// K-> String V->Student与下面的对应
hm.put("001",new Student("喜羊羊",21));
hm.put("002",new Student("懒羊羊",32));
hm.put("003",new Student("美羊羊",43));
Set<Map.Entry<String,Student>> ek=hm.entrySet();
Iterator<Map.Entry<String, Student>> iterator = ek.iterator();//取出迭代器
while (iterator.hasNext()) {
Map.Entry<String, Student> next = iterator.next();
System.out.println(next.getKey()+" - "+next.getValue());
}[HashMap是一个双列集合,以[K-V]的方式存储对象,因此在使用泛型时要向其中传入两个类型]
我们都知道使用迭代器遍历HashMap时要先通过
entrySet()取出键值对,然后通过转型得到对应的类来得到对象信息。而在使用泛型定义[K-V]就规定了取出的键值对的类型,所以就省去了转型这一步骤,同样也使程序变得简单,高效。
四、泛型使用细节
1.<>中类型规范

2.继承性体现
在给泛型指定具体类型后,可以传入该类型或者其子类类型
P<A> ap = new P<A>(new A());
P<A> ap1 = new P<A>(new B()); //A的子类
class A {}
class B extends A{}3.简写形式
P<A> ap = new P(new A());
五、自定义泛型
1.自定义方法使用类声明的泛型
在形参列表中传入的数据类型与泛型不一致时会报错,体现规范性
public static void main(String[] args) {
U<String, Double, Integer> u = new U<>();
u.hi("hello", 1.0); //X->String Y->Double
}
class U<X, Y, Z> {
public void hi(X x, Y y) {} //使用类声明的泛型
}2.自定义泛型方法
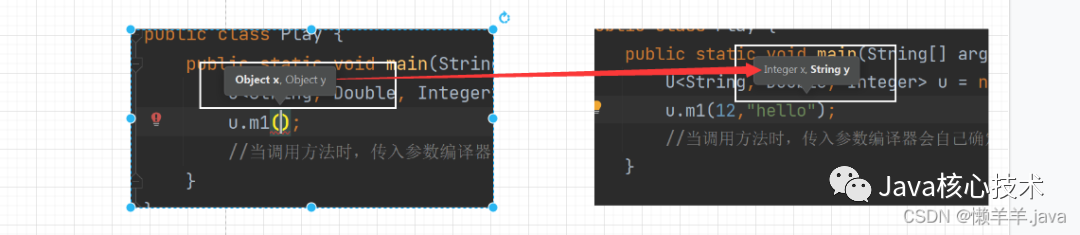
public static void main(String[] args) {
U<String, Double, Integer> u = new U<>();
u.m1("xx",22);
//当调用方法时,传入参数编译器会自己确定类型 会自动装箱
}
class U<X, Y, Z> {
public <X,Y> void m1(X x,Y y){} //自定义泛型方法
}这里的自动装箱很有意思,他是在三个类型中自动匹配当前输入的数据类型,也不用考虑顺序问题,如图所示
3.注意事项
①泛型数组不能初始化,因为数组在 new 不能确定A 的类型,就无法在内存开空间
错误写法: A[] a=new A[];
②静态方法不能使用类定义的泛型
