初识rust

这是网上关于Rust的一个笑话,每次搜索rust相关资料时,总能看到说rust上手难,反人类,编程一小时,编译一整天。但是它已经连续四年获「最受喜爱的编程语言」,不仅有很多硬件开发,服务端开发都用这个语言,前端很多框架比如swc,deno底层也有用rust改写。
本文通过rust与众不同的设计来讲解它是如何卷过其他语言。本文中所有代码可直接复制到 https://play.rust-lang.org/ 来看下rust代码执行的效果。
rust与众不同的设计
以垃圾回收机制为例
各种编程语言内存管理的方式不同,但通常有以下两种方式:
- 开发者自己分配和销毁: 比如 C、C++ 等,这种方式相当于把所有权力开放给开发者,管理不当容易内存泄漏。
- 编程语言提供自动垃圾回收机制: 比如 JavaScript、Java、Python 等,这种方式会产生运行时开销。
Rust 另辟蹊径采用所有权、生命周期机制在编译期自动插入内存释放逻辑来实现内存管理,简单说就是当某个变量走出作用范围时,内存就会立即自动交还给操作系统,不需要开发者自己进行空间申请/释放等操作 。由于没有了垃圾回收产生的运行时开销,Rust 整体表现的速度惊人且内存利用率极高。

在讲解所有权、生命周期机制之前,我们先了解下string。
string介绍
string分为两种情况,字符串字面值和动态可变的字符串。
字符串字面值:标量,手写的字符串值,不可变,在编译时就知道内容,类型是&str,在栈中存储。
动态可变的字符串:复杂类型,类型是string,由4部分组成(栈中存储指向存放字符串内容的内存指针,长度和容量。堆中存放字符串内容)。
PS:长度len是存放字符串内容所需的字节数(实际存了多少)。容量capacity是指string从操作系统中总共获得内存的字节数(最大能存多少)。
// 创建string类型的值
// 双冒号(::)运算符允许我们调用置于String命名空间下面的特定from函数,而不需要使用类似于string_from这样的名字
fn main() {
let mut s = String::from("hello");
s.push_str(", world"); // 或者 s += ", world";
println!("{}", s)
// 错误 使用js的字符串拼接方法,报错原因是cannot add `&str` to `&str`
// let mut s = "hello";
// s = s + ", world";
// println!("{}", s)
}所有权
所有权有以下三条规则:
- Rust 中的每个值都有一个变量,称为其所有者。
- 一次只能有一个所有者。
- 当所有者不在程序运行范围时,该值将被删除。
Rust 中的每个值都有一个变量,称为其所有者。这句话我们可以理解成变量名称就是所有者。
当所有者不在程序运行范围时,该值将被删除。也可以类比为js的块级作用域,超出作用域会报undefined。
一次只能有一个所有者这句话有些似懂非懂,我们通过几种变量与数据的交互方式来深入理解下这句话。
移动
下面的例子在js中只是一个简单的赋值过程,能够顺利执行,但是在rust中报错。
fn main() {
// string类型
let s1 = String::from("hello");
let s2 = s1;
println!("{}", s1); // 报错,s1不存在
println!("{}", s2);
}诶,这是为什么呢?我们看下这个图解。
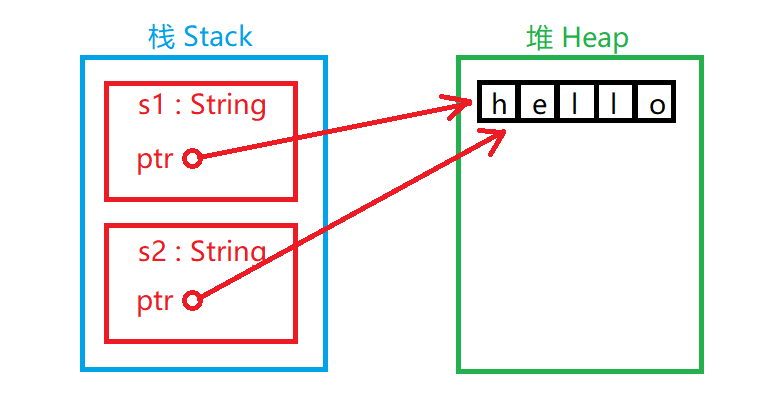
为了防止释放两次内存的问题,rust将s1的数据移动到s2,s1失效,这样的行为叫做移动。
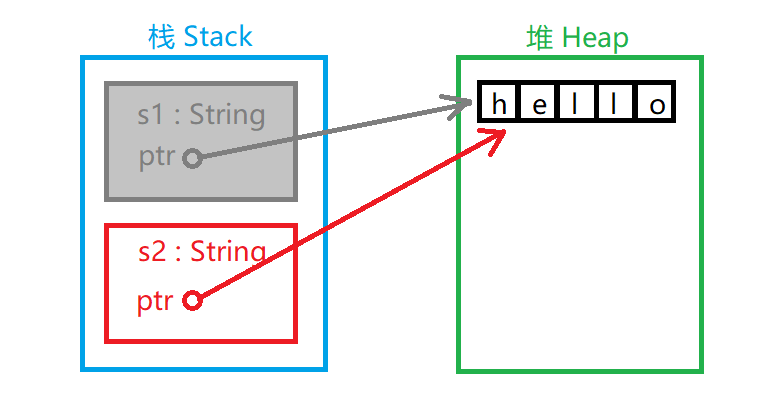
克隆
js中有 浅拷贝(shallow copy)和 深拷贝(deep copy)的概念,我们可以将上面的拷贝指针、长度和容量而不拷贝数据行为理解为浅拷贝。上述的例子如果想s1也生效的话,需要对数据进行一个深拷贝的操作,也就是除了栈上的三个数据,还有堆中的内容,这就是克隆,rust里有clone这个通用方法。
fn main() {
let s1 = String::from("hello");
let s2 = s1.clone();
println!("{}, {}", s1, s2);
}拷贝
只是存储在栈中的数据,比如整数类型,浮点类型,布尔类型,字符类型。这些是rust直接进行拷贝,不需要移动操作。
fn main() {
let x = 5;
let y = x;
println!("x = {}, y = {}", x, y);
}所有权与函数
向函数传递值可能会移动或者复制,就像赋值语句一样。同样的,函数返回值也有所有权。
fn main() {
let s = String::from("hello"); // s 进入作用域
takes_ownership(s); // s 的值移动到函数里 ...
// println!("{}", s); // 报错 ... 所以到这里不再有效
let x = 5; // x 进入作用域
let y = makes_copy(x); // x 应该移动函数里,
// 但 i32 是 Copy 的,
println!("x is {}", x); // 所以在后面可继续使用 x
// gives_ownership 将返回值转移给 y
} // 这里, x 先移出了作用域,然后是 s。但 s 的值已被移走,
fn takes_ownership(some_string: String) { // some_string 进入作用域
println!("{}", some_string);
} // 这里,some_string 移出作用域并调用 `drop` 方法。
// 占用的内存被释放
fn makes_copy(some_integer: i32) -> i32{ // some_integer 进入作用域
println!("{}", some_integer);
some_integer
} // 这里,some_integer 移出作用域。没有特殊之处
可以看到将引用类型的值传进函数后不能在使用,rust会报值已被移动找不到,但我们不想传递给函数之后就没了,我们希望在后续能继续使用这个参数,于是就出现了引用。
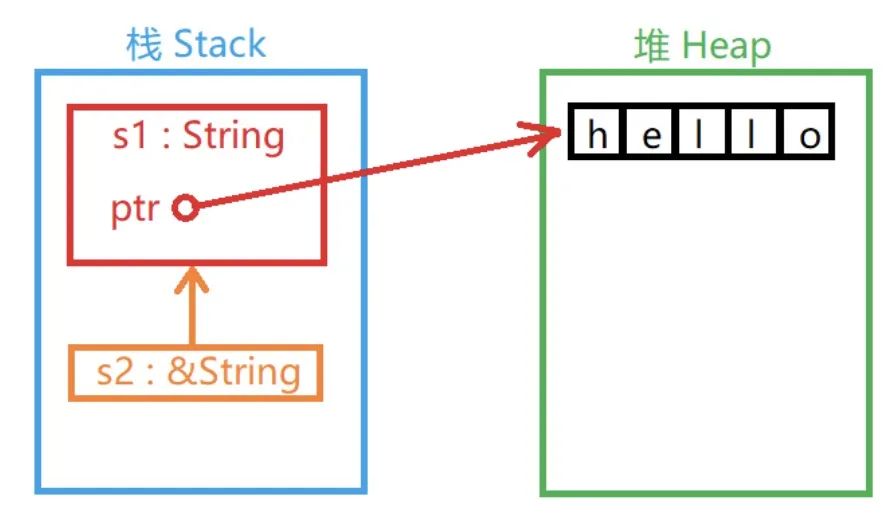
引用与租借
"引用"是变量的间接访问方式。运算符**&**。
fn main() {
let s1 = String::from("hello");
let len = calculate_length(&s1);
println!("The length of '{}' is {}.", s1, len);
}
fn calculate_length(s: &String) -> usize {
s.len()
}
引用不会获得值的所有权,只能租借(Borrow)值的所有权。它本身也是一个类型并具有一个值,这个值记录的是别的值所在的位置。
fn main() {
// 错误 s2 租借的 s1 已经将所有权移动到 s3,所以 s2 将无法继续租借使用 s1 的所有权。如果需要使用 s2 使用该值,必须重新租借
let s1 = String::from("hello");
let s2 = &s1;
let s3 = s1;
println!("{}", s2);
// 正确
let s1 = String::from("hello");
let mut s2 = &s1;
let s3 = s1;
s2 = &s3; // 重新从 s3 租借所有权
println!("{}", s2);
}引用又被分为可变引用和不可变引用。可变引用需要加上mut标识符。
// 不可变引用
fn main() {
let x = 10;
let r = &x;
}// 可变引用
fn main() {
let mut s = String::from("hello");
change(&mut s);
}
fn change(some_string: &mut String) {
some_string.push_str(", world");
}同一时刻,只能拥有要么一个可变引用,这是为了防止并发修改数据冲突,另外还有一个读写冲突,就是不可变引用和可变引用之间的限制。
// 并发修改数据冲突
fn main() {
let mut s = String::from("hello");
let s2 = &mut s;
let s3 = &mut s;
println!("{}", s2); // 报错 cannot borrow `s` as mutable more than once at a time
}// 读写冲突
fn main() {
let mut s = String::from("hello");
let s2 = &mut s;
s2.push_str(", world");
// 报错 cannot borrow `s` as immutable because it is also borrowed as mutable
// println!("{}", s);
// println!("{}", s2);
// 单独输出s或者s2,或者先输出可变引用不会报错
println!("{}", s2);
println!("{}", s);
}引用必须总是有效的 **(无效就是悬垂指针了)**。
悬垂引用
当指针指向某个值后,这个值被释放掉了,而指针仍然存在,引用无效,这就是悬垂引用也叫做悬垂指针。
下面是两种最常见导致悬垂指针现象的例子。
下面这个例子中,rust会报错说x的值生命周期没有那么长。
1 . 函数内大括号导致的作用域范围不一样
fn main() {
let r;
{
let x = 5;
r = &x;
}
println!("r: {}", r);
}
|
| r = &x;
| ^^ borrowed value does not live long enough2 . 函数返回一个内部创建的引用值
fn main() {
let reference_to_nothing = dangle(); // 报错,悬垂指针
}
fn dangle() -> &String {// dangle 返回一个字符串的引用
let s = String::from("hello");// s 是一个新字符串
&s // 返回字符串 s 的引用
}// 这里 s 离开作用域并被丢弃。其内存被释放。这就引出了rust的生命周期。
生命周期
生命周期,简而言之就是有效作用域。他与所有权机制同等重要的资源管理机制。主要作用是防止垂悬指针。
基础规则
在 Rust 中,每个引用都有自己的生命周期。从数据定义到一对大括号的结束,就是一个生命周期范围。一般情况下,我们无需手动的声明生命周期,因为Rust 编译器有一个 借用检查器(borrow checker),它通过比较作用域来判断借用是否合法有效。
上面例子中,打印r的语句跟r的赋值语句之间有一个大括号,也就是在执行r = &x; 后,x 的生命周期就结束了。x 的生命周期小于 r 的生命周期,这时 r 指向了一个被回收的数据的地址,变成了一个悬垂指针,所以就出错了。
我们看一个判断字符串长度的函数。
fn main() {
let string1 = String::from("long string is long");
let string2 = String::from("xyz");
let result = longest(string1, string2);
println! ("The longest string is {}", result);
}
fn longest(x: String, y: String) -> String {
if x.len() > y.len() {
x
} else {
y
}
}这里参数和返回值都是String类型,可以编译通过,输出The longest string is long string is long,我们让函数参数变成引用类型,返回值是整数类型再看看。
fn main() {
let string1 = String::from("abcd");
let string2 = "efghijklmnopqrstuvwxyz";
let result = longest(string1.as_str(), string2);
println!("The longest string is {}", result);
}
fn longest(x: &str, y: &str) -> usize {
if x.len() > y.len() {
x.len()
} else {
y.len()
}
}也可以编译通过,输出The longest string is 22。
我们把上面的函数再改下,参数和返回值都是引用类型,编译器就会报错。
fn main() {
let string1 = String::from("long string is long");
let string2 = String::from("xyz");
// 将字符串对象转换为字符串字面量,写成longest(&string1, &string2)也是可以的
let result = longest(string1.as_str(), string2.as_str());
println! ("The longest string is {}", result);
}
fn longest(x: &str, y: &str) -> &str {
if x.len() > y.len() {
x
} else {
y
}
}
这个报错的原因是,不添加标注的话,对Rust编译器来说,其实相当于
fn longest<'a,'b> (x: &'a str , y: &'b str) -> &str{//
两个引用参数各自拥有一个生命周期,Rust无法推断 x 和 y 的生命周期谁更长,以及 x 和 y 的生命周期与返回值的生命周期的关联。为了修复这个错误,我们要显式声明入参的生命周期。报错提示里写明了怎么进行修改,我们直接把第7行复制粘贴过去就得到了正确的写法。
生命周期注解语法
当引用的生命周期可能以不同的方式相互关联的时候(当函数的参数和返回值都是引用类型时),需要手动标注生命周期,避免悬垂指针。这就是生命周期注解。
生命周期注解是描述引用生命周期的办法。它不会改变引用的生命周期。
生命周期注解用单引号开头,跟着一个小写字母单词(不限a),位于 & 之后,并有一个空格来将引用类型与生命周期注解分隔开。
&i32 // 引用
&'a i32 // 带有显式生命周期的引用
&'a mut i32 // 带有显式生命周期的可变引用
longest 函数中,我们将函数生命周期参数,函数参数以及函数返回值都加上了生命周期'a,注意 longest 函数并不需要知道 x 和 y 以及返回值具体会存在多久,只需要知道有某个可以被 'a 替代的作用域将会满足最小作用域(引用参数作用域相重叠的那一部分)。
简单说就是,引用参数的最小作用域要大于等于函数引用返回值的作用域,任何不满足这个约束条件的值都将被借用检查器拒绝。我们将上面的例子中string2的生命周期改变下,依旧能返回正确的值。
fn main() {
let string1 = String::from("long string is long");
{
let string2 = String::from("xyz");
// 将字符串对象转换为字符串字面量,写成longest(&string1, &string2)也是可以的
let result = longest(string1.as_str(), string2.as_str());
println! ("The longest string is {}", result);
}
}在这个例子中,string1 直到外部作用域结束都是有效的,string2 则在内部作用域中是有效的,而 result 则引用了一些直到内部作用域结束都是有效的值。借用检查器认可这些代码;它能够编译和运行,并打印出 The longest string is long string is long。
我们在改下这个例子,将函数返回值的生命周期缩小。
fn main() {
let string1 = String::from("long string is long");
let string2 = String::from("xyz");
{
let result = longest(string1.as_str(), string2.as_str());
println! ("The longest string is {}", result);
}
}
fn longest<'a> (x: &'a str , y: &'a str) -> &'a str{
if x.len() > y.len() {
x
} else {
y
}
}也是可以正确输出的,接下来,我们再改下例子,将 result 变量的声明移动出内部作用域,但是将 result 和 string2 变量的赋值语句一同留在内部作用域中。接着,使用了变量 result 的 println! 也被移动到内部作用域之外。
fn main() {
let string1 = String::from("long string is long");
let result;
{
let string2 = String::from("xyz");
result = longest(string1.as_str(), string2.as_str());
}
println! ("The longest string is {}", result);
}
fn longest<'a> (x: &'a str , y: &'a str) -> &'a str{
if x.len() > y.len() {
x
} else {
y
}
}编辑器会报错,是因为rust要保证 println! 中的 result 是有效的,也就是longest函数的参数和返回值都是相同的生命周期参数 'a。但string2 的生命周期只在内部的作用域,需要直到外部作用域结束都是有效的代码才能正确运行。
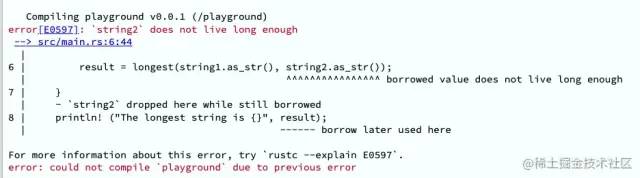
深入理解生命周期
指定生命周期参数的正确方式是依赖函数实现的具体功能。
还是上面的判断字符串函数为例,如果这个函数的返回值总是返回第一个参数,则y这个引用参数就不需要指定生命周期,代码也是可以编译通过的。
fn main() {
let string1 = String::from("abcd");
let string2 = "efghijklmnopqrstuvwxyz";
let result = longest(string1.as_str(), string2);
println!("The longest string is {}", result);
}
fn longest<'a>(x: &'a str, y: &str) -> &'a str {
x
}
有些函数,参数和返回值也都是引用,但不需要生命周期注解也能编译成功,比如数组或字符串的循环。
fn first_word(s: &str) -> &str {
let bytes = s.as_bytes();
for (i, &item) in bytes.iter().enumerate() {
if item == b' ' {
return &s[0..i];
}
}
&s[..]
}这个函数在早期的时候是必须添加生命周期的,但Rust 团队发现在特定情况下 Rust 程序员们总是重复地编写一模一样的生命周期注解。这些场景是可预测的并且遵循几个明确的模式。接着 Rust 团队就把这些模式编码进了 Rust 编译器中,如此借用检查器在这些情况下就能推断出生命周期而不再强制程序员显式的增加注解。被编码进 Rust 引用分析的模式被称为 生命周期省略规则(lifetime elision rules)。
函数或方法的参数的生命周期被称为 输入生命周期(input lifetimes),而返回值的生命周期被称为 输出生命周期(output lifetimes)。
编译器采用三条规则来判断引用何时不需要明确的注解。第一条规则适用于输入生命周期,后两条规则适用于输出生命周期。如果编译器检查完这三条规则后仍然存在没有计算出生命周期的引用,编译器将会停止并生成错误。这些规则适用于 fn 定义,以及 impl 块。
第一条规则是每一个是引用的参数都有它自己的生命周期参数。换句话说就是,有一个引用参数的函数有一个生命周期参数:fn foo<'a>(x: &'a i32),有两个引用参数的函数有两个不同的生命周期参数,fn foo<'a, 'b>(x: &'a i32, y: &'b i32),依此类推。
第二条规则是如果只有一个输入生命周期参数,那么它被赋予所有输出生命周期参数:fn foo<'a>(x: &'a i32) -> &'a i32。
第三条规则是如果方法有多个输入生命周期参数并且其中一个参数是 &self 或 &mut self,说明是个对象的方法(impl块)。那么所有输出生命周期参数被赋予 self 的生命周期。第三条规则使得方法更容易读写,因为只需更少的符号。
我们可以根据这三条生命周期规则来判断当前的函数是否需要加上显式的生命周期注解。
结尾
我们通过代码可以看到rust最重要的两个特点,高性能和可靠性。
- 高性能 - Rust 特有的垃圾回收机制,使它能够保证在运行时的高性能。
- 可靠性 - Rust 丰富的类型系统和所有权模型从源头上杜绝了数据共享冲突,保证了内存安全和线程安全。
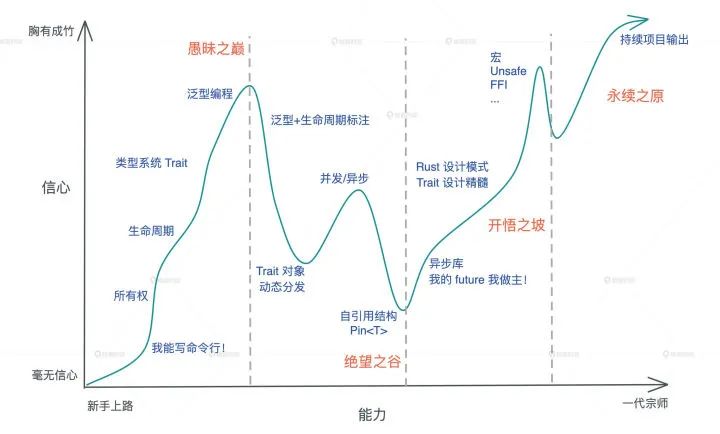
Rust不仅可以在嵌入式设备上运行,还能轻松和其他语言集成。比如web开发。rust支持把代码编译成 WebAssembly在浏览器上运行,目前也有相关的框架将这两部分集成可供前端开发者直接开箱部署,例如:yew。最后附上「rust学习路径图」,想学习rust的小伙伴可以参考下来计划学习之路。
参考资料
Rust 程序设计语言 - Rust 程序设计语言 简体中文版