告别 IPVS,拥抱 Cilium/XDP? [译]
Seznam.cz 是一家捷克技术公司,开发定制搜索引擎、广告平台、在线地图、内容管理系统,以及私有云服务、定制硬件和数据中心。
1 . 架构
Seznam 的基础设施早期采用 F5 硬件负载平衡器,但几年前我们切换到了软件负载均衡器。到目前为止,我们一直在使用 多层[1] 架构:
- 第一层 ECMP 路由[2]
- 第二层 IPVS[3] 作为 L4 负载均衡器(L4LB)[4]
- 第三层 Envoy 代理[5] 作为 L7 负载均衡器[6]。
不幸的是,随着流量的增加,并且由于 COVID,我们开始出现硬件供应短缺,我们迫切需要寻找更优的方案来更有效地使用硬件。
我们一直在密切关注 Cilium 并注意到 Cilium 1.10 版本中的独立 L4LB XDP[7] 和 Cilium 关于 maglev 的说明[8]。XDP 钩子(hook)以有效利用 CPU 而著称,具有极高的性能。这对我们的团队来说非常有趣,因为我们的流量峰值高达 20M 活动连接,这大大增加了 IPVS 节点的 CPU 使用率。
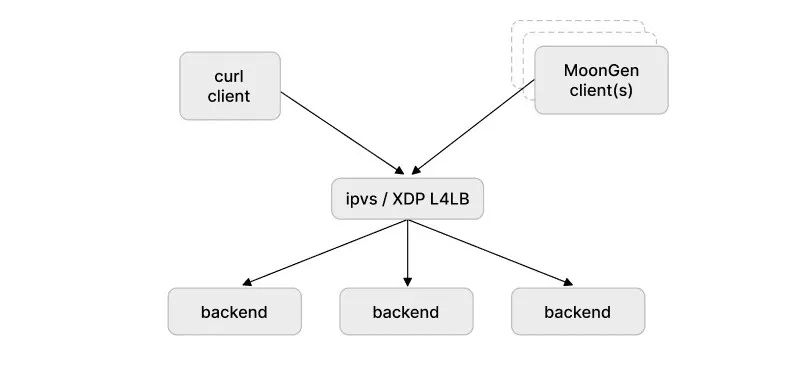
我们的负载均衡器设置将外部流量接入到 Kubernetes 和 OpenStack 集群,IPVS 用于经典的 “负载均衡器” 场景。简单架构看起来如下所示:

我们在 IPVS 节点上使用了 25GbE NIC,因此在 XDP 驱动程序层运行 L4LB 没有问题,因为大多数现代 NIC 都支持它。
# ethtool -i eth0
driver: i40e
version: 2.8.20-k
firmware-version: 6.02 0x80003621 1.1747.0
expansion-rom-version:
bus-info: 0000:c1:00.0
supports-statistics: yes
supports-test: yes
supports-eeprom-access: yes
supports-register-dump: yes
supports-priv-flags: yes
# lspci | grep Ether
c1:00.0 Ethernet controller: Intel Corporation Ethernet Controller XXV710 for 25GbE SFP28 (rev 02)2 . 启动独立 L4LB
Cilium 本身使用 Docker 镜像发布,我们尝试直接在 IPVS 节点本身上运行。为了在 Cilium 容器重新启动/升级时正常工作,我们使用 systemd 服务来挂载 bpf 文件系统:
# cat /etc/systemd/system/sys-fs-bpf.mount
[Unit]
Description=BPF mounts
DefaultDependencies=no
Before=local-fs.target umount.target
After=swap.target
[Mount]
What=bpffs
Where=/sys/fs/bpf
Type=bpf
[Install]
WantedBy=multi-user.target
然后我们仅以负载均衡器模式启动 Cilium:
systemctl start sys-fs-bpf.mount; docker run \
--cap-add NET_ADMIN \
--cap-add SYS_MODULE \
--cap-add CAP_SYS_ADMIN \
--network host \
--privileged \
-v /sys/fs/bpf:/sys/fs/bpf \
-v /lib/modules \
--name l4lb \
<our_private_docker_repo>/cilium cilium-agent \
--bpf-lb-algorithm=maglev \
--bpf-lb-mode=dsr \
--bpf-lb-acceleration=native \
--bpf-lb-dsr-dispatch=ipip \
--devices=eth0 \
--datapath-mode=lb-only \
--enable-l7-proxy=false \
--tunnel=disabled \
--install-iptables-rules=false \
--enable-bandwidth-manager=false \
--enable-local-redirect-policy=false \
--enable-hubble=false \
--enable-l7-proxy=false \
--preallocate-bpf-maps=false \
--disable-envoy-version-check=true \
-auto-direct-node-routes=false \
--enable-ipv4=true \
--enable-ipv6=true我们提供大约 3k 个服务并使用 30+ 个 L7 节点,因此我们很快就达到了 lbmap 的默认值。因此,我们添加了 --bpf-lb-map-max 512000 选项进行调整。
3 . 设置服务
Cilium 提供了 API 来设置 lbmaps,这里我们使用以下命令来配置服务:
cilium service update --id $idx --frontend "$svc" \
--backends "$backends" --k8s-node-port其中:
frontend代表每个 VIP 服务backends代表 L7 节点
完整设置样例如下所示:
$ cilium service update --id 1 \
--frontend "10.248.11.13:7047" \
--backends "10.246.3.34:7047, \
10.246.39.33 :7047, \
10.246.39.34:7047" \
--k8s-node-port对于 BGP 公告,我们使用 BIRD[9], 所以这部分相当简单:
# systemctl start bird
# systemctl start bird64 . 负载对比
测试工具和场景设置如下:
- SynFlood[10]
- MoonGen[11]
- 1 个 CPU 用于产生流量
- 64B 数据包
我们决定在一个运行 MoonGen 的单一客户产生的合成测试/负载下比较 IPVS 和 L4LB,MoonGen 有 1 个 CPU 和 64B 的小数据包,带有 TCP SYN 选项设置。
在这个过程中,我们对 MoonGen 生成器发出的数据包(tcp 段)进行了配置,以随机化源 IP 地址和 TCP 源端口,从而使流量分布在所有接收 rx 队列中,因为我们的网卡被配置为使用 4 元组(src IP, dst IP, src TCP port, dst TCP port)散列:
# ethtool -n eth0 rx-flow-hash tcp4
TCP over IPV4 flows use these fields for computing Hash flow key:
IP SA
IP DA
L4 bytes 0 & 1 [TCP/UDP src port]
L4 bytes 2 & 3 [TCP/UDP dst port]在测试运行期间,我们使用另一个客户端运行一个简单的 GET 请求(在 while 循环中使用 curl)来查看服务器请求处理情况。
测试设置如下图所示:
4.1 结果
在这两种场景(场景 #1 IPVS 和场景 #2 L4LB)中,MoonGen 客户端被配置为生成 1Mpps(每秒百万数据包)和 3Mpps。下面的每个输出屏幕截图均取自于对应的被测服务器 IPVS/L4LB 或 curl 客户端。
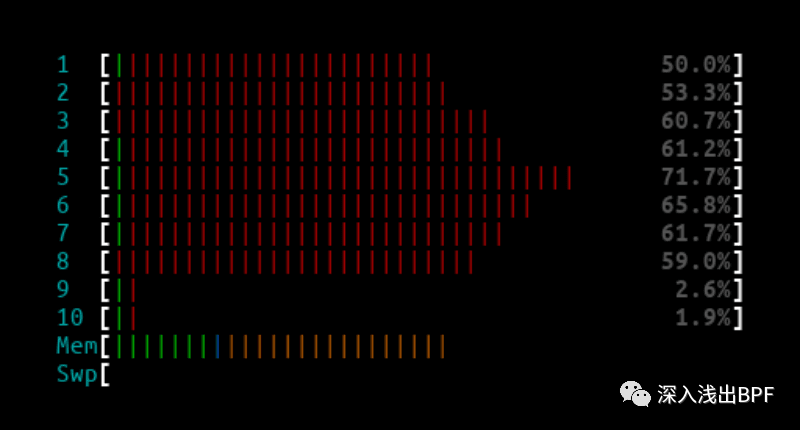
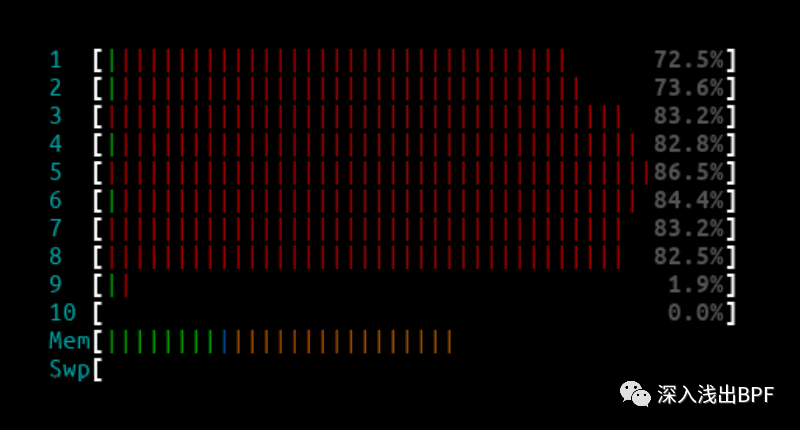
L4LB XDP 模式下,1Mpps 和 3Mpps 都可轻松处理,对性能没有任何影响。从 10Mpps 开始,我们仅看到在 14.8 Mpps 流量时受到影响,但这可能是由于 NIC 而不是 L4LB 的限制。
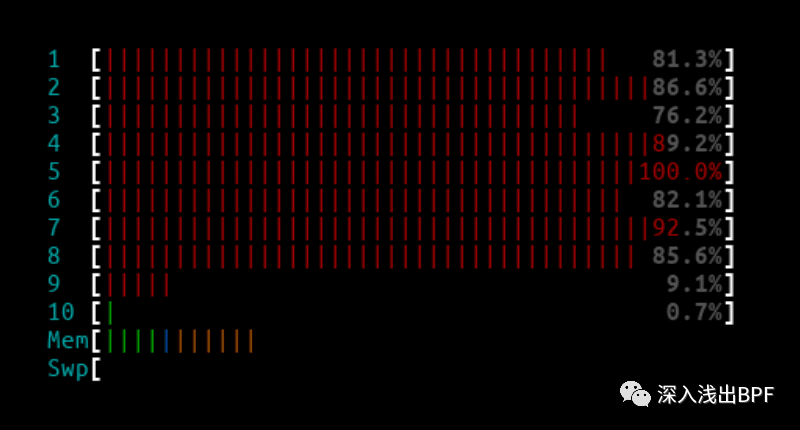
4.1.1 1Mpps - IPVS
IPVS htop 输出 :
Curl client 输出 :
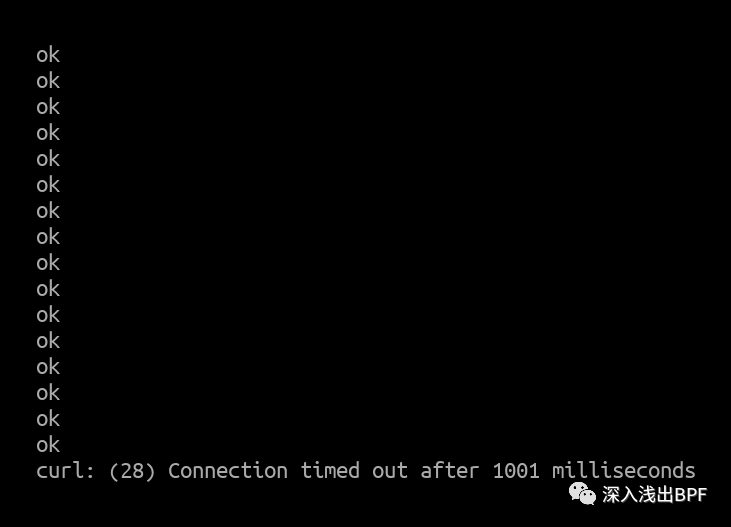
CPU 并没有完全被占用,但已接近极限,并且不时丢包。
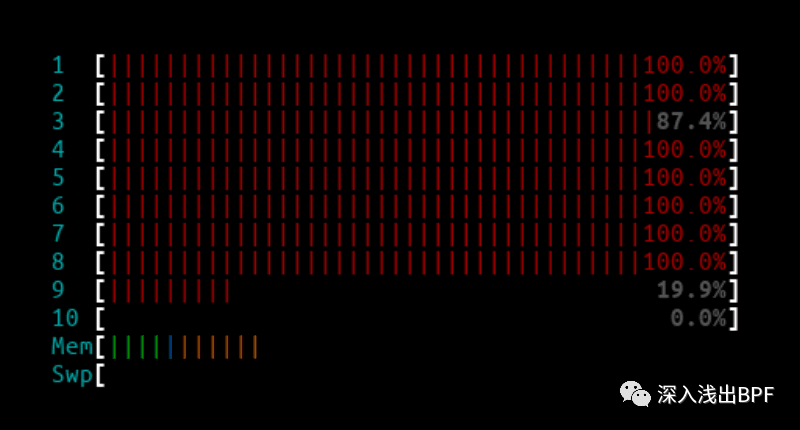
4.1.2 3Mpps - IPVS
IPVS htop 输出 :
Curl client 输出 :
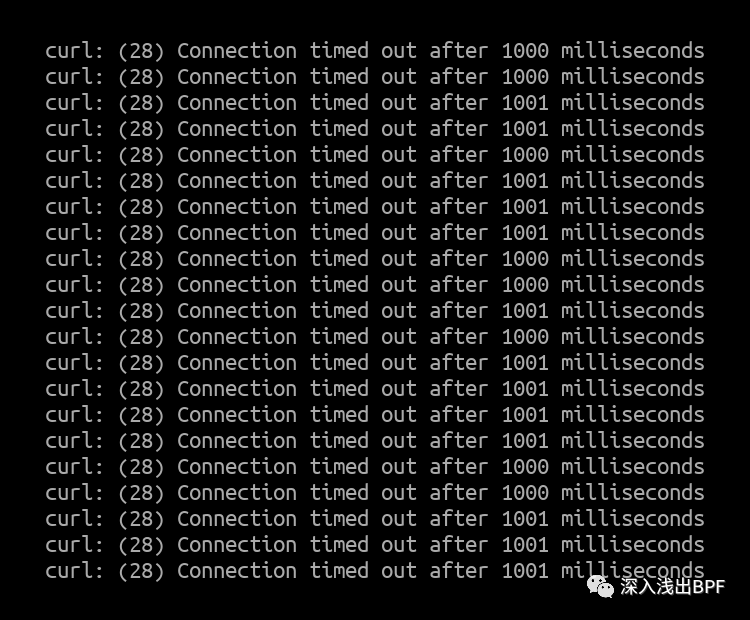
由于处理中断的所有 CPU 内核都已用尽,所有来自第二个客户端的数据包几乎都被 IPVS 节点丢弃。
4.1.3 10Mpps - L4LB XDP
L4LB htop 输出 :
Curl client 输出 :

4.1.4 14.8Mpps - L4LB XDP
L4LB htop 输出 :
Curl client 输出 :
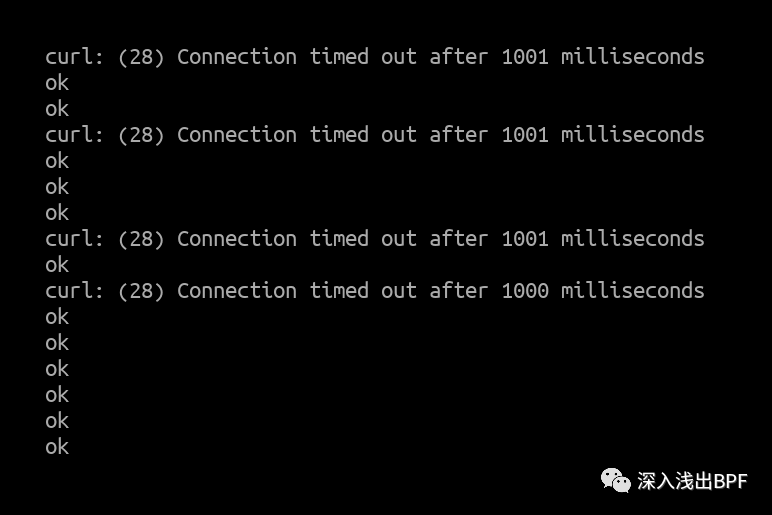
在流量达到 14.8Mpps 时,偶尔出现数据包丢弃情况,但这是由于达到了网卡限制,这完全符合预期。
5 . 生产环境流量验证
当我们将 L4LB XDP 部署到一个之前运行 IPVS 生产节点时,最大的惊喜出现了。由于我们可以完全访问节点并且能够在任何时间点启动/停止 BIRD,我们能够干净地在 L4LB XDP 节点和 IPVS 节点之间切换流量。
大约上午 11:00,我们停止了 IPVS 节点上的 BIRD,以便 L4LB XDP 节点处理所有流量,大约上午 11:14,我们切换到运行 IPVS 的 2 个节点。
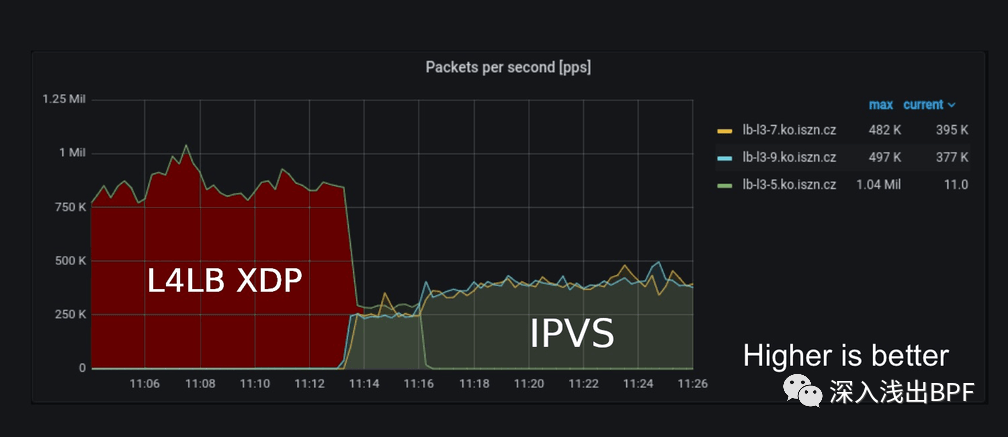
上面的输出显示:
在 ~11:04 - 11:13 期间,生产流量从 750kpps 上升到 1Mpps,这是由使用 L4LB XDP 的单个主机 lb-l3-5.ko.iszn.cz 处理的。
在 ~11:16,我们切换到运行 IPVS 的 2 台主机 lb-l3-7.ko.iszn.cz 和 lb-l3-9.ko.iszn.cz(这段时间的总流量也在 1Mpps)。
当我们查看 CPU 使用率时,效果非常显著。有一次,我们不确定是否在某个地方存在错误,因为当 L4LB XDP 处理流量时 CPU 负载非常低。但仔细观察后,与 IPVS 处理流量时的 2x18 CPU 相比,它确实只消耗了单个 CPU 的一半。
当切换到 L4LB XDP 时,我们节省了 36 个 CPU。
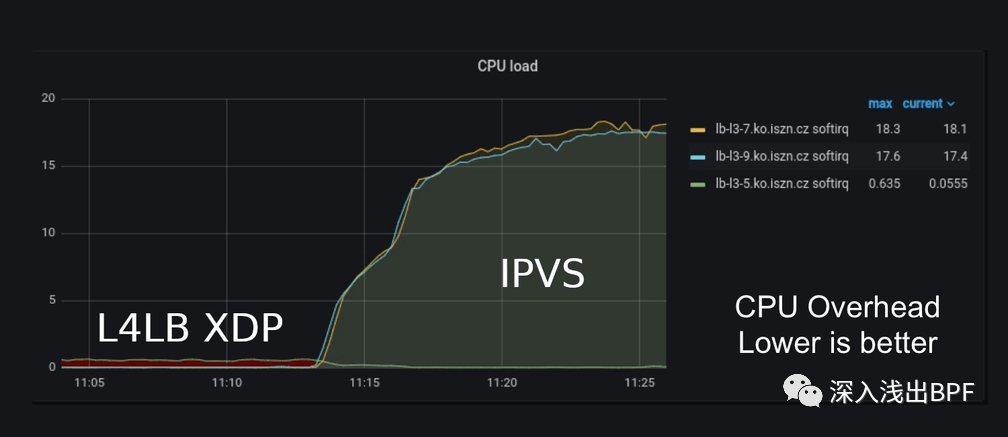
注:图片取自我们的生产 Grafana 面板中的 CPU 负载(越低越好)
6 . 总结
截图不言自明,但对我们来说关键是,L4LB XDP 在驱动层的大部分 HTTP 流量节省了处理生产流量所需的大量 CPU - 我们 90% 的流量是 HTTP 请求。
在我们完全切换到 L4LB XDP 之前,Cilium 中唯一缺少功能是加权后端功能,该功能我们正在开发中:maglev:支持通过新的 cmdline 参数在服务规范中设置后端的权重[12]。该功能开发完成后,那么就没有什么能阻止我们告别 IPVS。
借此,我们要感谢 Cilium 社区构建了如此出色的项目并给予了支持!
- 原文地址:https://cilium.io/blog/2022/04/12/cilium-standalone-L4LB-XDP/
- 原文作者:Ondrej Blazek@ Seznam.cz
参考资料
[1]多层: https://vincent.bernat.ch/en/blog/2018-multi-tier-loadbalancer
[2]ECMP 路由: https://vincent.bernat.ch/en/blog/2018-multi-tier-loadbalancer#first-tier-ecmp-routing
[3]IPVS: http://www.linuxvirtualserver.org/software/ipvs.html
[4]L4 负载均衡器(L4LB): https://vincent.bernat.ch/en/blog/2018-multi-tier-loadbalancer#second-tier-l4-load-balancing
[5]Envoy 代理 : https://www.envoyproxy.io/
[6]L7 负载均衡器: https://vincent.bernat.ch/en/blog/2018-multi-tier-loadbalancer#last-tier-l7
[7]独立 L4LB XDP: https://cilium.io/blog/2021/05/20/cilium-110#standalonelb
[8]Cilium 关于 maglev 的说明: https://cilium.io/blog/2020/11/10/cilium-19#maglev
[9]我们使用 BIRD: https://docs.cilium.io/en/stable/gettingstarted/bird/
[10]SynFlood: https://www.cloudflare.com/learning/ddos/syn-flood-ddos-attack/
[11]MoonGen: https://github.com/emmericp/MoonGen
[12]maglev:支持通过新的 cmdline 参数在服务规范中设置后端的权重: https://github.com/cilium/cilium/pull/18306