Redis常用集群以及性能压测实战 | 得物技术
背景
众所周知,Redis是一款性能强悍的中间件。那么它的性能到底多强,大家也是只拿到的是官方给到的数据,那么真实情况是否真的是这样? 带着这个疑问,挑选了Redis单机与集群做压测,得到性能数据,并分析两者性能的关系是否是线性的。
准备工作
简单介绍下业界的Redis集群:
一、Codis
Codis 是 Wandoujia Infrastructure Team 开发的一个分布式 Redis 服务, 用户可以看成是一个无限内存的 Redis 服务, 有动态扩/缩容的能力. 对偏存储型的业务更实用, 如果你需要 SUBPUB 之类的指令, Codis 是不支持的. 时刻记住 Codis 是一个分布式存储的项目. 对于海量的 Key, value不太大( <= 1M ), 随着业务扩展缓存也要随之扩展的业务场景有特效.
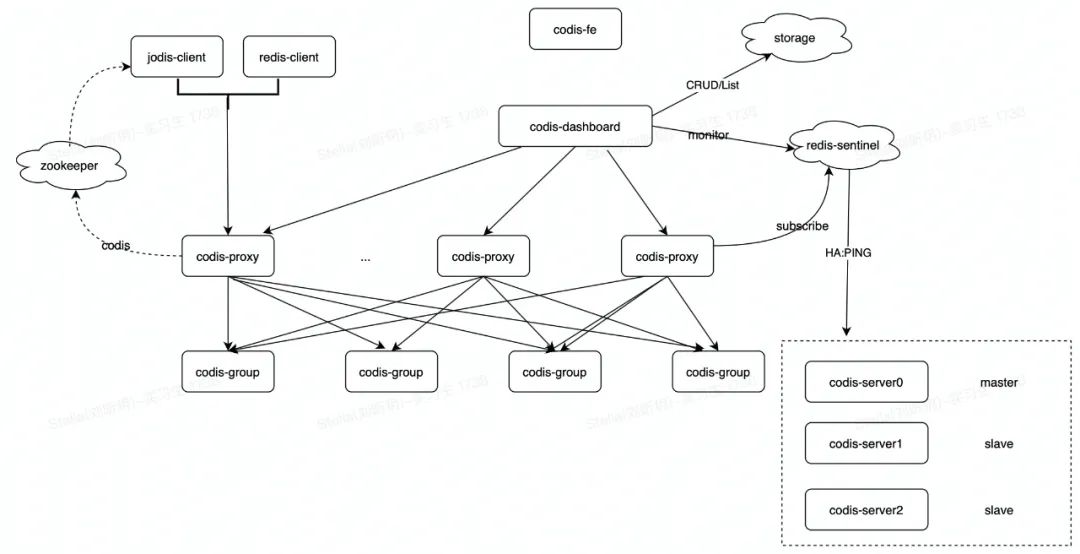
Redis获得动态扩容/缩容的能力,增减Redis实例对client完全透明、不需要重启服务,不需要业务方担心 Redis 内存爆掉的问题. 也不用担心申请太大, 造成浪费. 业务方也不需要自己维护 Redis。Codis支持水平扩容/缩容,扩容可以直接界面的 "Auto Rebalance" 按钮,缩容只需要将要下线的实例拥有的slot迁移到其它实例,然后在界面上删除下线的group即可。
Codis 采用 Pre-sharding 的技术来实现数据的分片, 默认分成 1024 个 slots (0-1023), 对于每个Key来说, 通过以下公式确定所属的 Slot Id : SlotId = crc32(key) % 1024。每一个 slot 都会有一个且必须有一个特定的 server group id 来表示这个 slot 的数据由哪个 server group 来提供。数据的迁移也是以slot为单位的。
二、Twemproxy
Twemproxy是一种代理分片机制,由Twitter开源。Twemproxy作为代理,可接受来自多个程序的访问,按照路由规则,转发给后台的各个Redis服务器,再原路返回。该方案很好的解决了单个Redis实例承载能力的问题。当然,Twemproxy本身也是单点,需要用Keepalived做高可用方案。通过Twemproxy可以使用多台服务器来水平扩张redis服务,可以有效的避免单点故障问题。虽然使用Twemproxy需要更多的硬件资源和Redis性能有一定的损失(Twitter测试约20%),但是能够提高整个系统的HA也是相当划算的。
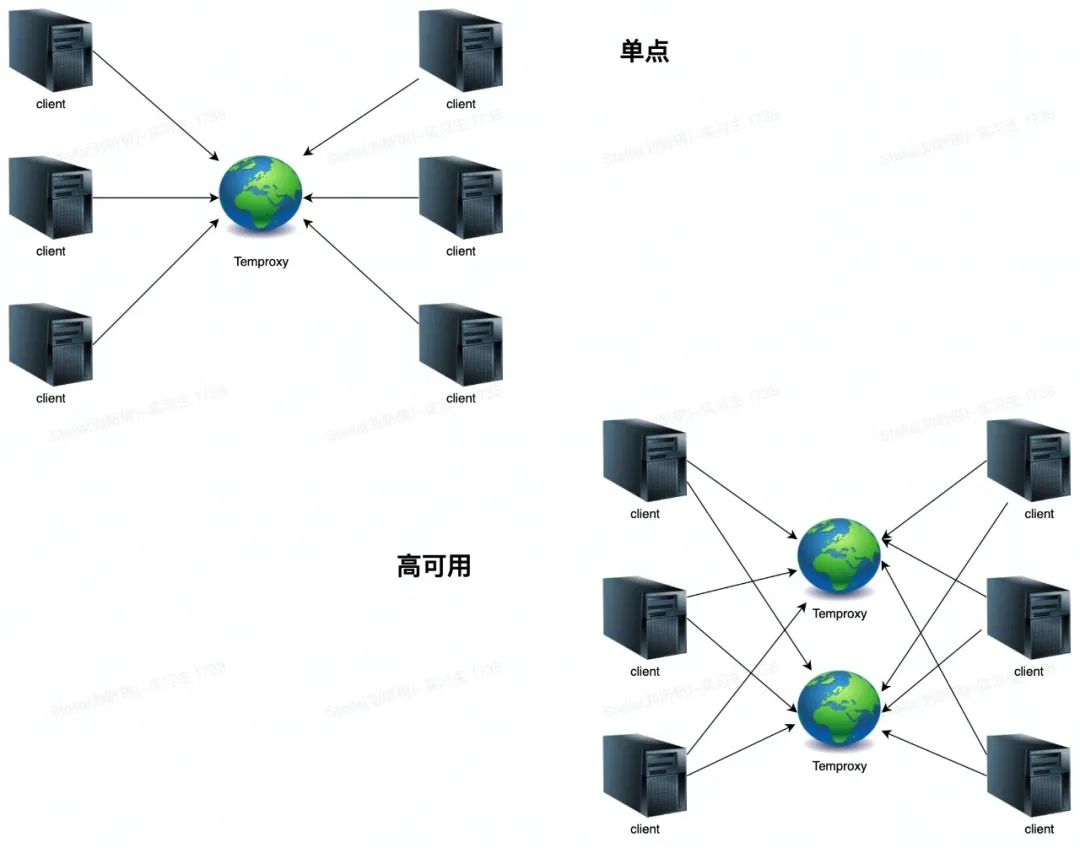
快速,轻巧。维护持久的服务器连接。保持后端缓存服务器的连接数低。启用请求和响应的流水线操作。支持代理多个服务器。同时支持多个服务器池。跨多个服务器自动分片数据。实现完整的memcached ascii和Redis协议。通过YAML文件轻松配置服务器池。支持多种散列模式,包括一致的散列和分布。可以配置为在发生故障时禁用节点。通过统计监控端口上显示的统计数据进行可观察性。适用于Linux,* BSD,OS X和SmartOS(Solaris)。
三、Redis Cluster
Redis 集群是一个提供在多个Redis间节点间共享数据的程序集。Redis集群并不支持处理多个Keys的命令,因为这需要在不同的节点间移动数据,从而达不到像Redis那样的性能,在高负载的情况下可能会导致不可预料的错误.Redis 集群通过分区来提供一定程度的可用性,在实际环境中当某个节点宕机或者不可达的情况下继续处理命令。
Redis 集群的优势:1.自动分割数据到不同的节点上。2.整个集群的部分节点失败或者不可达的情况下能够继续处理命令。
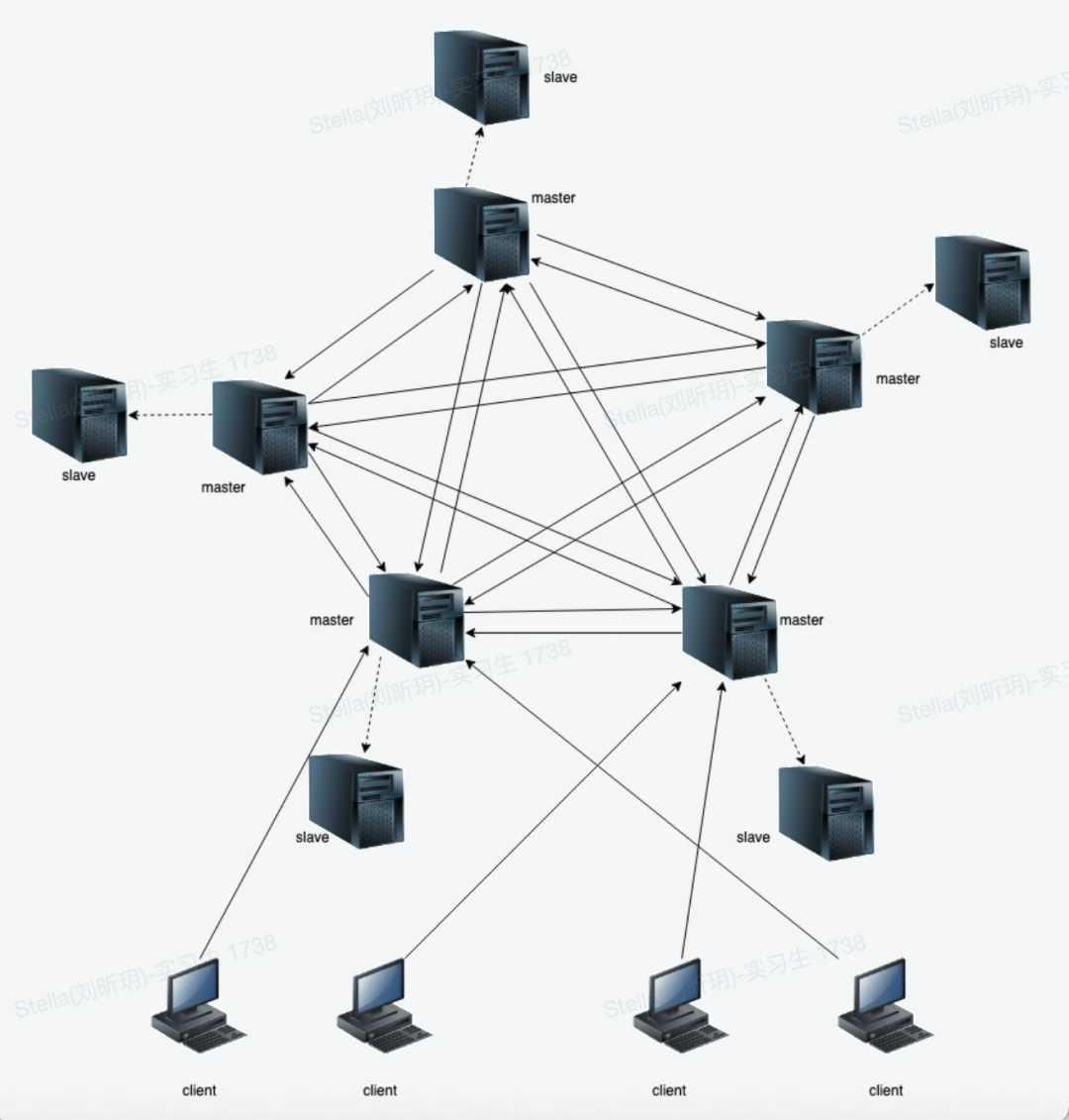
RedisCluster分片策略
Redis 集群没有并使用传统的一致性哈希来分配数据,而是采用另外一种叫做哈希槽 (hash slot)的方式来分配的。Redis cluster 默认分配了 16384 个slot,当我们set一个key 时,会用CRC16算法来取模得到所属的slot,然后将这个Key 分到哈希槽区间的节点上,具体算法就是:CRC16(key) % 16384。注意的是:必须要3个以后的主节点,否则在创建集群时会失败,我们在后续会实践到。所以,假设现在有3个节点已经组成了集群,分别是:A、B、C 三个节点,它们可以是一台机器上的三个端口,也可以是三台不同的服务器。那么,采用哈希槽 (hash slot)的方式来分配16384个slot 的话,它们三个节点分别承担的slot 区间是:节点A覆盖0-5460;节点B覆盖5461-10922;节点C覆盖10923-16383。
Redis Cluster 节点上下线流程
现有7001,7002,7003,7004,7005,7006六个Redis节点组成的集群,其中7001,7002,7003这三个节点是master节点,而他们的从节点分别是7001master对应7004slave,7002master对应7004slave,7003master对应7006slave根据Redis-Cluster官方建议slot数为16384,所以7001(0-5460),7002(5461-10922),7003(10923-16383)三个主节点对应的卡槽,现在来模拟一个主节点挂掉的情况,比如7002节点挂掉,按照Redis-cluster原理会选举7002的从节点7005为主节点,继续将7002节点重启,会发现7002会自动加入集群并且是7005的从节点集群添加节点,分为添加主节点,从节点,先添加主节点7007,加入了集群之后发现,并没有卡槽分配到7007上,需要手动对集群进行重新分片迁移数据,并且手动计算由于目前是4个主节点所以需要分配4096个卡槽给7007,并且要求填写从哪些节点上分配卡槽给新的主节点,如果输入all,集群中左右的主节点都会抽取一部分卡槽,凑够了4096个,移动到7007上;如果添加从节点,如果没有给定那个主节点--master-id的话,Redis-trib将会将新增的从节点随机到从节点较少的主节点上。
集群节点的移除,与添加一样,分为移除主节点,和从节点,移除主节点如果有数据,需要将卡槽先移到别的主节点上,该主节点上的从节点会分配到卡槽移动的目标主节点上;移除从节点比较方便,直接移除。
RedisCluster的slot为什么是16384个
根据CRC16算法(当然这个算法是什么我没有研究)最多可以分配65535(2^16-1)个slot,65535=65K,用bitmap压缩后就是8K,由于集群之间的节点会有心跳 ,会把8K的数据包都带着,有点浪费流量,所以还是建议用16384个slot然后用bitmap压缩后是2K,一般来看Redis的集群节点不会超过1000个。
下面进入我们的重点压测啦
既然准备压测Redis,肯定要准备压测机器,Redis服务器,这里还走了不少弯路,大致情况如下:
redis单点压测
1.三台Jmeter压5-10台Java服务器,压测后面一台单点的Redis
刚开始压测的时候想着模拟常规用户调用场景于是写了一个简单的Java服务,并且集群式部署,它们连接到一台Redis服务器,见下图:
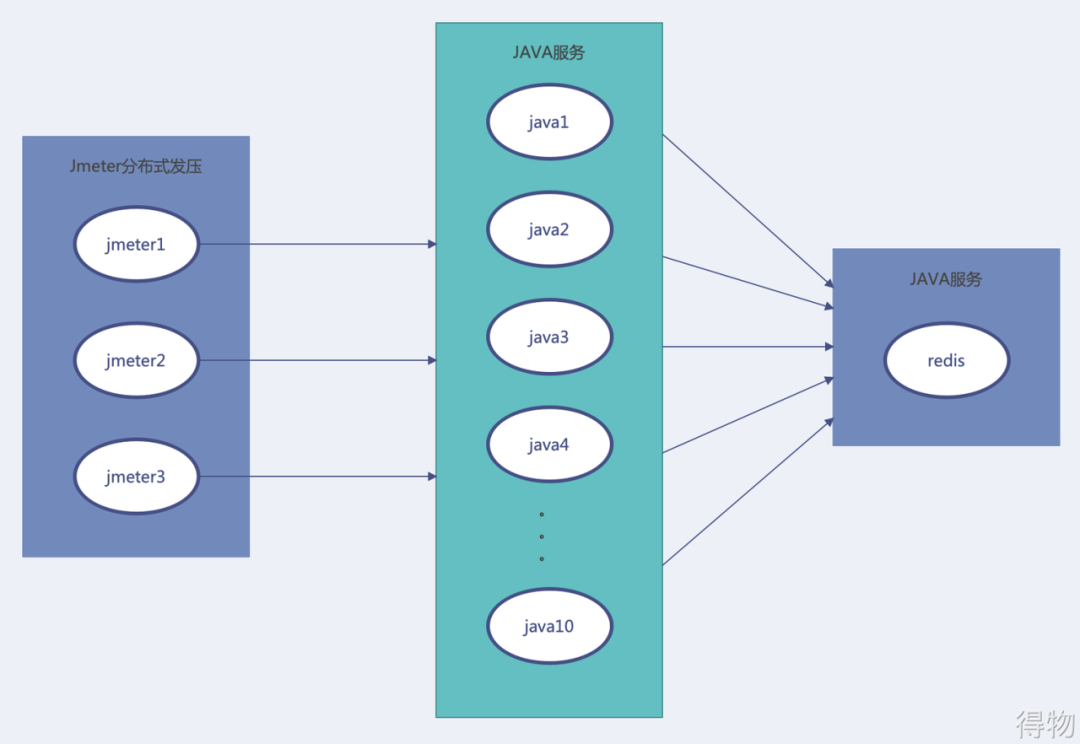
当然压之前也查看了Redis官网,以及用Redis-bechmark试过Redis极限性能到10万的GPS左右,但是用这样的方式压测根本压不到瓶颈,哪怕把Java服务器与Redis的连接数调大。不停地加Java服务机器,却怎么压不出Redis的极限,此时可以感受到Redis性能的强悍。虽然有官方数据,但是经过这么多机器的压测仍然达不到它的瓶颈,大概知道是压测方式出问题了。
单Java服务器压单台Redis
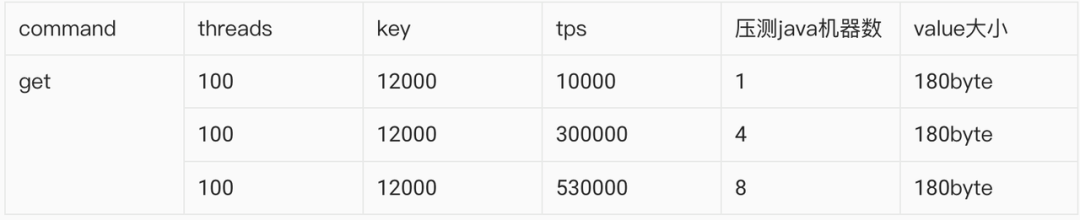
换另一个方案,Java服务器,写接口多线程压测Redis,性能爆炸,压测数据如下:
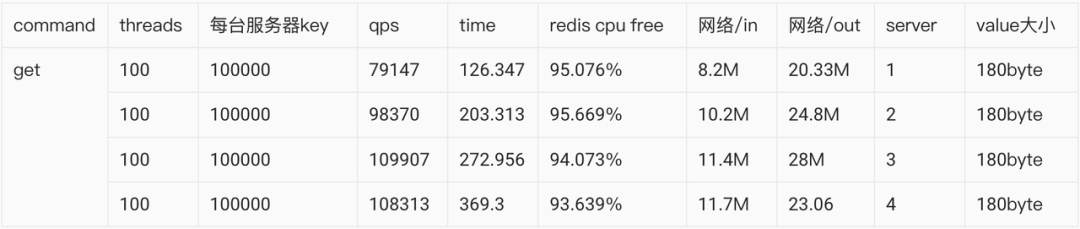
这个数据巅峰数值达到了11万,比传言的还要高。
Redis-cluster压测
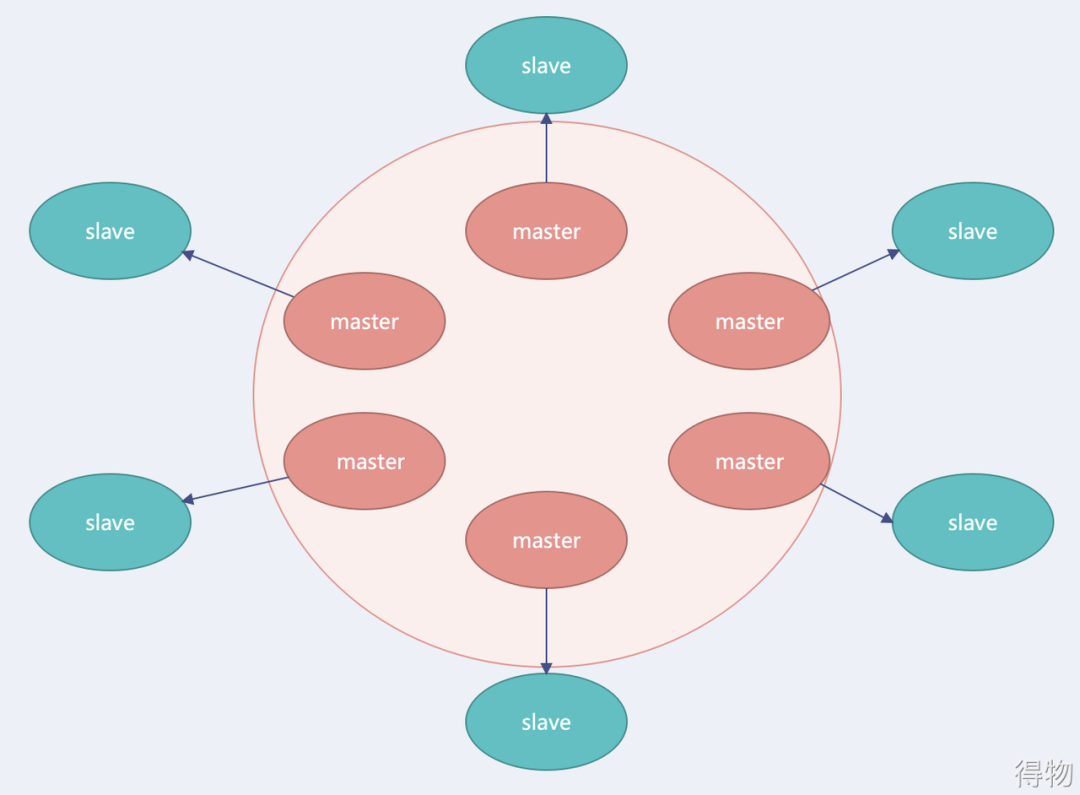
压完单点Redis服务之后,信心暴增,在求了运维之后,又加了了一些机器,利用6台Linux服务器搭建6主6从的Redis-cluster集群,如下图所示:
于是立马代码,着手压测,压测结果却不尽人意,下面请看数据:
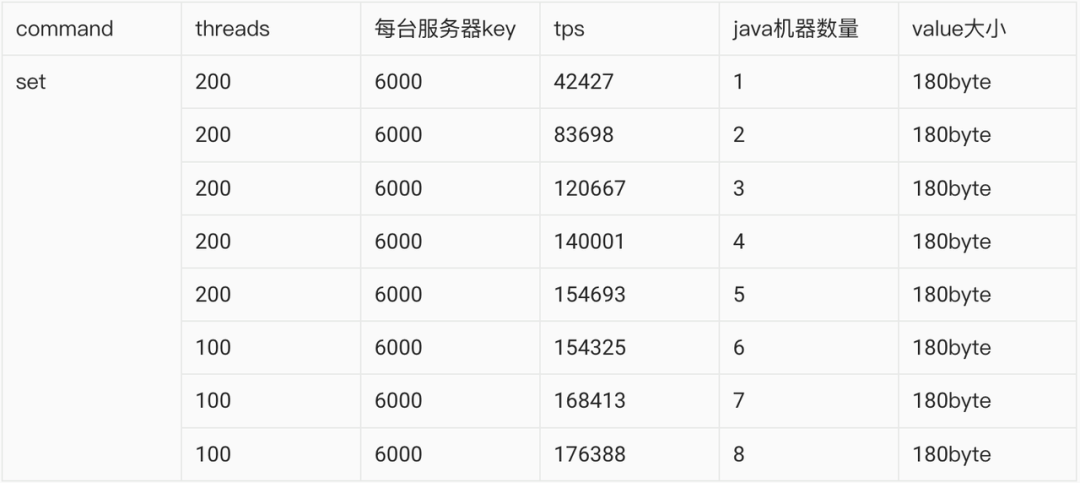
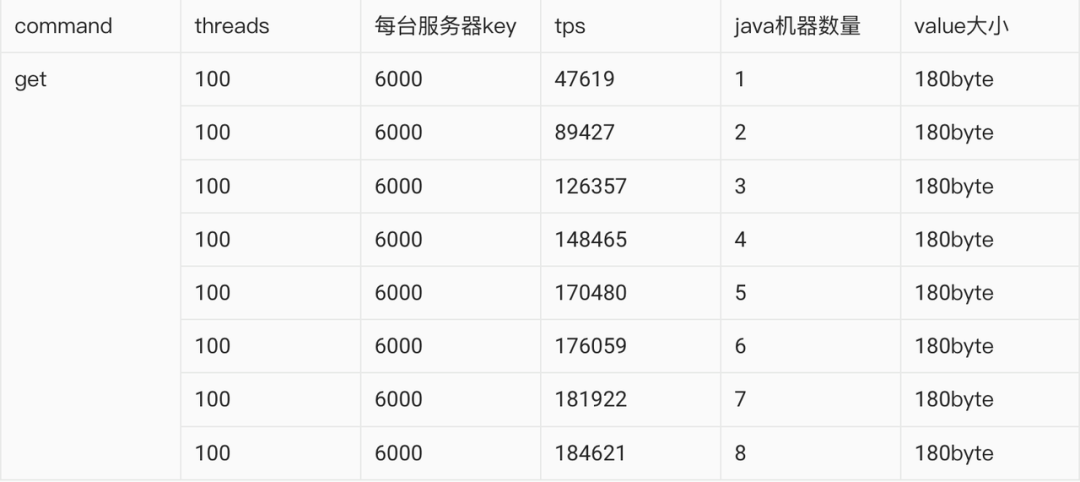
分析了下上面的压测数据,Redis机器添加了6倍,性能突破1倍都没有,肯定是哪里出了问题,于是继续分析代码,原来使用JedisPoll的时候,每次使用完一个链接,又得丢给池子,性能可能损耗在这里,于是立马改代码,将线程不用再丢弃,每个压测线程使用一个Redis的链接,得到的数据非常爆炸。
JedisPool设置了100个链接,且用100个线程同时请求。
又设置了1000个连接,

由此发现连接数越多也不是最好的,反而会导致性能下降,这个就是我们平时所谓的性能调优。
总结
1.Redis的单机性能达到10万GPS,集群的性能损失也不是很多,6节点的集群我们压到了50多万,只要合理使用Redis,Redis的性能远远够用。
2.Java服务器与Redis的连接数设置不是越多越好,一定是存在一个性能最好的中间值,这个需要不停的压测与调优才能得到。
3.最后,纸上得来终觉浅,绝知此事要躬行。这次压测收益良多,学会计算自己系统的压力阈值才能在未来的开发路上越走越宽。