图解浏览器渲染原理及流程
大家好, 今天来分享一下浏览器的渲染原理及流程。
前言
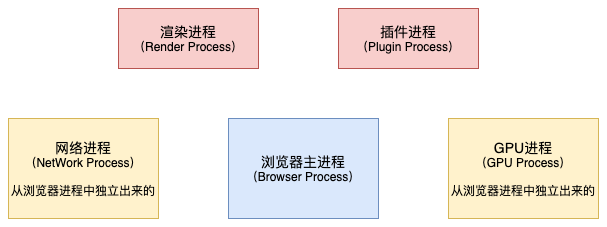
先来看看 Chrome 浏览器的多进程架构:


- DOM树构建:渲染引擎使用HTML解析器(调用XML解析器)解析HTML文档,将各个HTML元素逐个转化成DOM节点,从而生成DOM树;
- CSSOM树构建:CSS解析器解析CSS,并将其转化为CSS对象,将这些CSS对象组装起来,构建CSSOM树;
- 渲染树构建:DOM 树和 CSSOM 树都构建完成以后,浏览器会根据这两棵树构建出一棵渲染树;
- 页面布局:渲染树构建完毕之后,元素的位置关系以及需要应用的样式就确定了,这时浏览器会计算出所有元素的大小和绝对位置;
- 页面绘制:页面布局完成之后,浏览器会将根据处理出来的结果,把每一个页面图层转换为像素,并对所有的媒体文件进行解码。
对于这五个流程,每一阶段都有对应的产物:DOM树、CSSOM树、渲染树、盒模型、界面。
下图为渲染引擎工作流程中各个步骤所对应的模块:
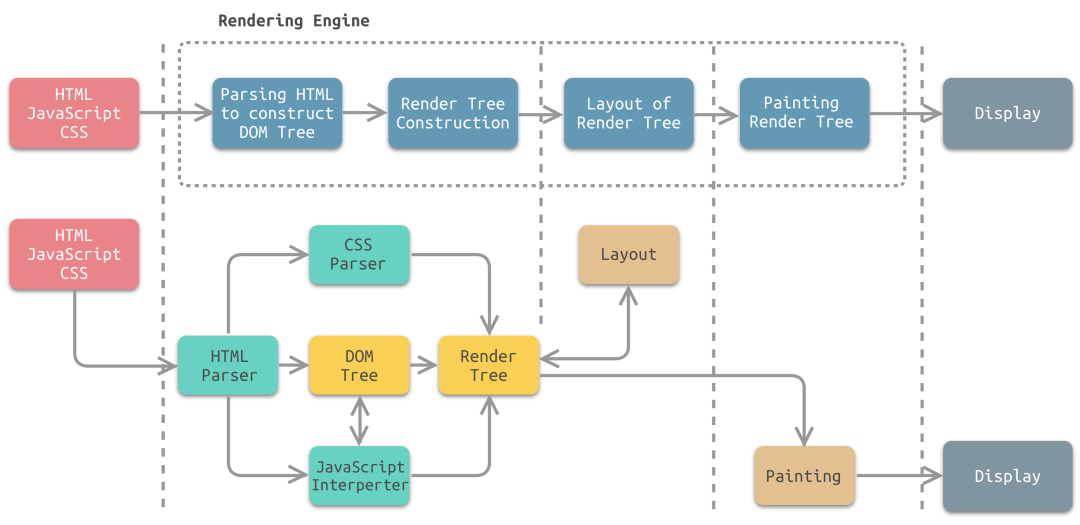
- HTML 解析器:解析HTML文档,主要作用是将HTML文档转换成DOM树;
- CSS 解析器:将DOM中的各个元素对象进行计算,获取样式信息,用于渲染树的构建;
- JavaScript 解释器:使用JavaScript可以修改网页的内容、CSS规则等。JavaScript解释器能够解释JavaScript代码,并通过DOM接口和CSSOM接口来修改网页内容、样式规则,从而改变渲染结果;
- 页面布局:DOM创建之后,渲染引擎将其中的元素对象与样式规则进行结合,可以得到渲染树。布局则是针对渲染树,计算其各个元素的大小、位置等布局信息。
- 页面绘制:使用图形库将布局计算后的渲染树绘制成可视化的图像结果。
DOM树构建
在说构建DOM树之前,我们需要知道,为什么要构建DOM树呢? 这是因为,浏览器无法直接理解和使用 HTML,所以需要将HTML转化为浏览器能够理解的结构——DOM树。
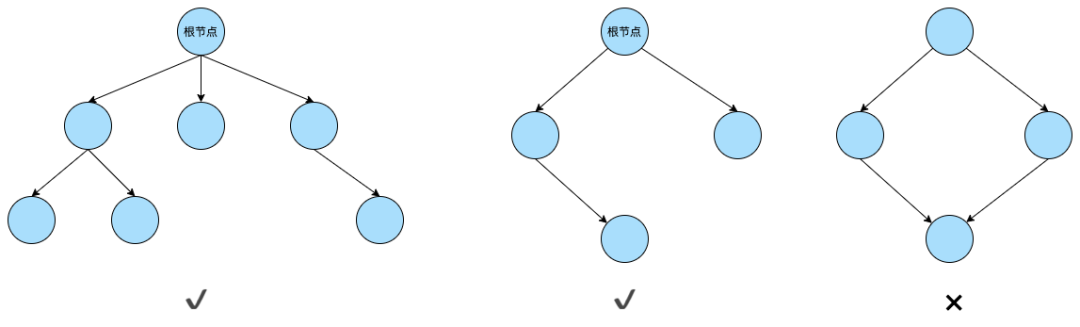
了解过数据结构的小伙伴对于树结构应该不陌生,树是由结点或顶点和边组成的且不存在着任何环的一种数据结构。一棵非空的树包括一个根结点,还有多个附加结点,所有结点构成一个多级分层结构。下面通过一张图来看看什么是树结构:
在页面中,每个HTML标签都会被浏览器解析成文档对象。HTML本质上就是一个嵌套结构,在解析时会把每个文档对象用一个树形结构组织起来,所有的文档对象都会挂在document上,这种组织方式就是HTML最基础的结构——文档对象模型(DOM),这棵树的每个文档对象就叫做DOM节点。
在渲染引擎中,DOM 有三个层面的作用:
- 从页面的视角来看,DOM 是生成页面的基础数据结构;
- 从 JavaScript 脚本视角来看,DOM 提供给 JavaScript 脚本操作的接口,通过这套接口,JavaScript 可以对 DOM 结构进行访问,从而改变文档的结构、样式和内容;
- 从安全视角来看,DOM 是一道安全防护线,一些不安全的内容在 DOM 解析阶段会被拒之门外。
在渲染引擎内部,HTML 解析器负责将 HTML 字节流转换为 DOM 结构,其转化过程如下:

1. 字符流 → 词(token)
HTML结构会首先通过分词器将字节流拆分为词(token)。Token分为Tag Token 和文本 Token。下面来看一个HTML代码是如何被拆分的:
<body>
<div>
<p>hello world</p>
</div>
</body>对于这段代码,可以拆成词:

<body>、<div>、就是 StartTag ,`</body>`、`</div>`、就是 EndTag,分别对应图中的蓝色和红色块,文本 Token 对应绿色块。
这里会通过状态机将字符拆分成token,所谓的状态机就是将每个词的特征逐个拆分成独立的状态,然后再将所有词的特征字符合并起来,形成一个连通的图结构。那为什么要使用状态机呢?因为每读取一个字符,都要做一次决策,这些决策都和当前的状态有关。
实际上,状态机的作用就是用来做词法分析的,将字符流分解为词(token)。
2. 词(token)→ DOM树
接下来就需要将 Token 解析为 DOM 节点,并将 DOM 节点添加到 DOM 树中。这个过程是通过栈结构来实现的,这个栈主要用来计算节点之间的父子关系,上面步骤中生成的token会按顺序压入栈中,该过程的规则如下:
- 如果分词器解析出来是StartTag Token,HTML 解析器会为该 Token 创建一个 DOM 节点,然后将该节点加入到 DOM 树中,它的父节点就是栈中相邻的那个元素生成的节点;
- 如果分词器解析出来是 文本 Token,那么会生成一个文本节点,然后将该节点加入到 DOM 树中,文本 Token 是不需要压入到栈中,它的父节点就是当前栈顶 Token 所对应的 DOM 节点;
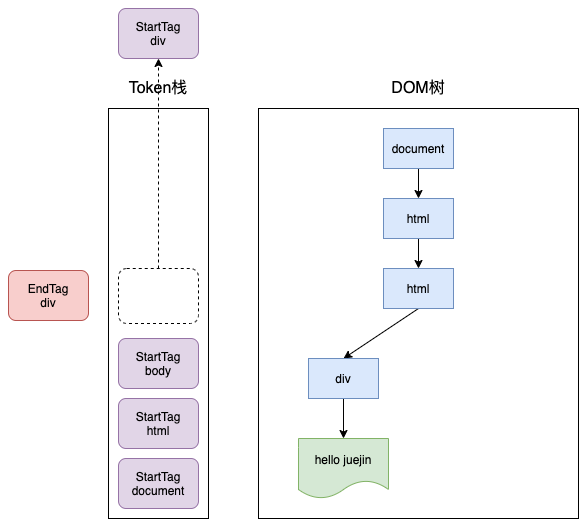
- 如果分词器解析出来的是EndTag Token,比如是 EndTag div,HTML 解析器会查看 Token 栈顶的元素是否是 StarTag div,如果是,就将 StartTag div从栈中弹出,表示该 div 元素解析完成。
通过分词器产生的新 Token 就这样不停地入栈和出栈,整个解析过程就这样一直持续下去,直到分词器将所有字节流分词完成。
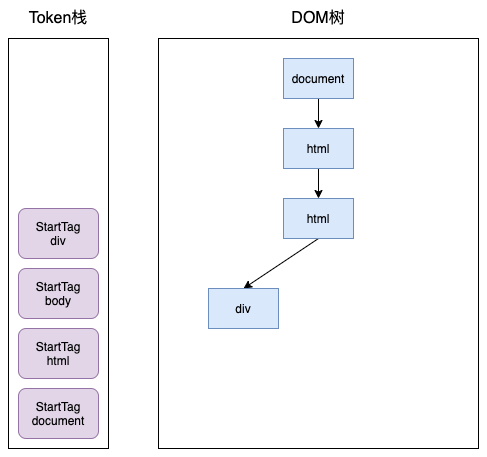
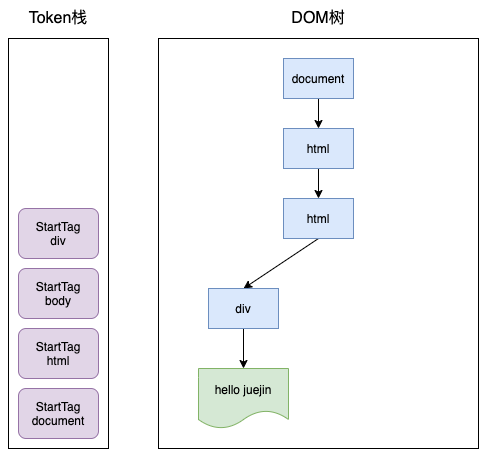
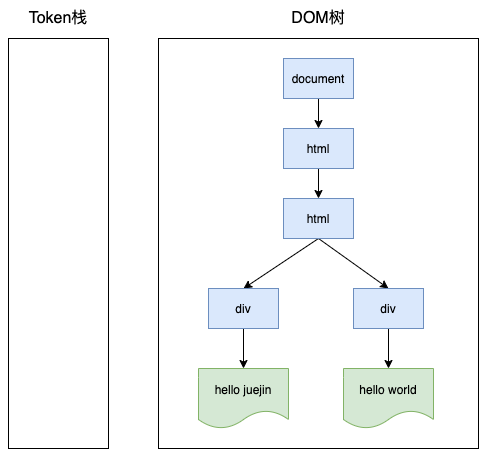
下面来看看这的Token栈是如何工作的,有如下HTML结构:
<html>
<body>
<div>hello juejin</div>
<p>hello world</p>
</body>
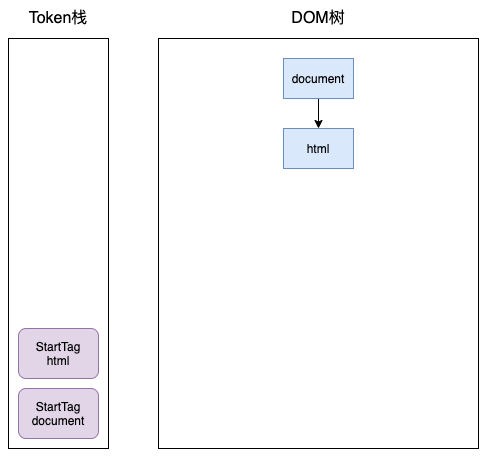
</html>开始时,HTML解析器会创建一个根为 document 的空的 DOM 结构,同时将 StartTag document 的Token压入栈中,然后再将解析出来的第一个 StartTag html 压入栈中,并创建一个 html 的DOM节点,添加到 document 上,这时 Token 栈和 DOM树 如下:
CSSOM树构建
上面已经基本了解了DOM的构建过程,但是这个DOM结构只包含节点,并不包含任何的样式信息。下面就来看看,浏览器是如何把CSS样式应用到DOM节点上的。
同样,浏览器也是无法直接理解CSS代码的,需要将其浏览器可以理解的CSSOM树。实际上。浏览器在构建 DOM 树的同时,如果样式也加载完成了,那么 CSSOM 树也会同步构建。CSSOM 树和 DOM 树类似,它主要有两个作用:
- 提供给 JavaScript 操作样式的能力;
- 为渲染树的合成提供基础的样式信息。
不过,CSSOM 树和 DOM 树是独立的两个数据结构,它们并没有一一对应关系。DOM 树描述的是 HTML 标签的层级关系,CSSOM 树描述的是选择器之间的层级关系。可以在浏览器的控制台,通过document.styleSheets命令来查看CSSOM树:

- 通过 link 引用的外部 CSS 样式文件;
<style>标签内的CSS样式;- 元素的style属性内嵌的CSS。
在将CSS转化为树形对象之前,还需要将样式表中的属性值进行标准化处理,比如,当遇到以下CSS样式:
body { font-size: 2em }
p {color:blue;}
div {font-weight: bold}
div p {color:green;}
div {color:red; }可以看到上面CSS中有很多属性值,比如2em、blue、red、bold等,这些数值并不能被浏览器直接理解。所以,需要将所有值转化为浏览器渲染引擎容易理解的、标准化的计算值,这个过程就是属性值标准化。经过标准化的过程,上面的代码会变成这样:
body { font-size: 32px }
p {color: rgb(0, 0, 255);}
div {font-weight: 700}
div p {color: (0, 128, 0);}
div {color: (255, 0, 0); }可以看到,2em被解析成了32px,blue被解析成了rgb(255, 0, 0),bold被解析成700。现在样式的属性已被标准化了,接下来就需要计算 DOM 树中每个节点的样式属性了,这就涉及到 CSS 的继承规则和层叠规则。
(1)样式继承
在 CSS 中存在样式的继承机制,CSS 继承就是每个 DOM 节点都包含有父节点的样式。比如在 HTML 上设置“font-size:20px;”,那么页面里基本所有的标签都可以继承到这个属性了。
在CSS中,有继承性的属性主要有以下几种:
1 . 字体系列属性
- font-family:字体系列
- font-weight:字体的粗细
- font-size:字体的大小
- font-style:字体的风格
2 . 文本系列属性
- text-indent:文本缩进
- text-align:文本水平对齐
- line-height:行高
- word-spacing:单词之间的间距
- letter-spacing:中文或者字母之间的间距
- text-transform:控制文本大小写(就是uppercase、lowercase、capitalize这三个)
- color:文本颜色
3 . 元素可见性
- visibility:控制元素显示隐藏
4 . 列表布局属性
- list-style:列表风格,包括list-style-type、list-style-image等
5 . 光标属性
- cursor:光标显示为何种形态
(2)样式层叠
样式计算过程中的第二个规则是样式层叠。层叠是 CSS 的一个基本特征,它是一个定义了 如何合并来自多个源的属性值的算法。它在 CSS 处于核心地位,CSS 的全称“层叠样式表”正是强调了这一点。这里不再多说。
总之,样式计算阶段的目的是为了计算出 DOM 节点中每个元素的具体样式,在计算过程 中需要遵守 CSS 的继承和层叠两个规则。这个阶段最终输出的内容是每个 DOM 节点的样 式,并被保存在 ComputedStyle 的结构内。
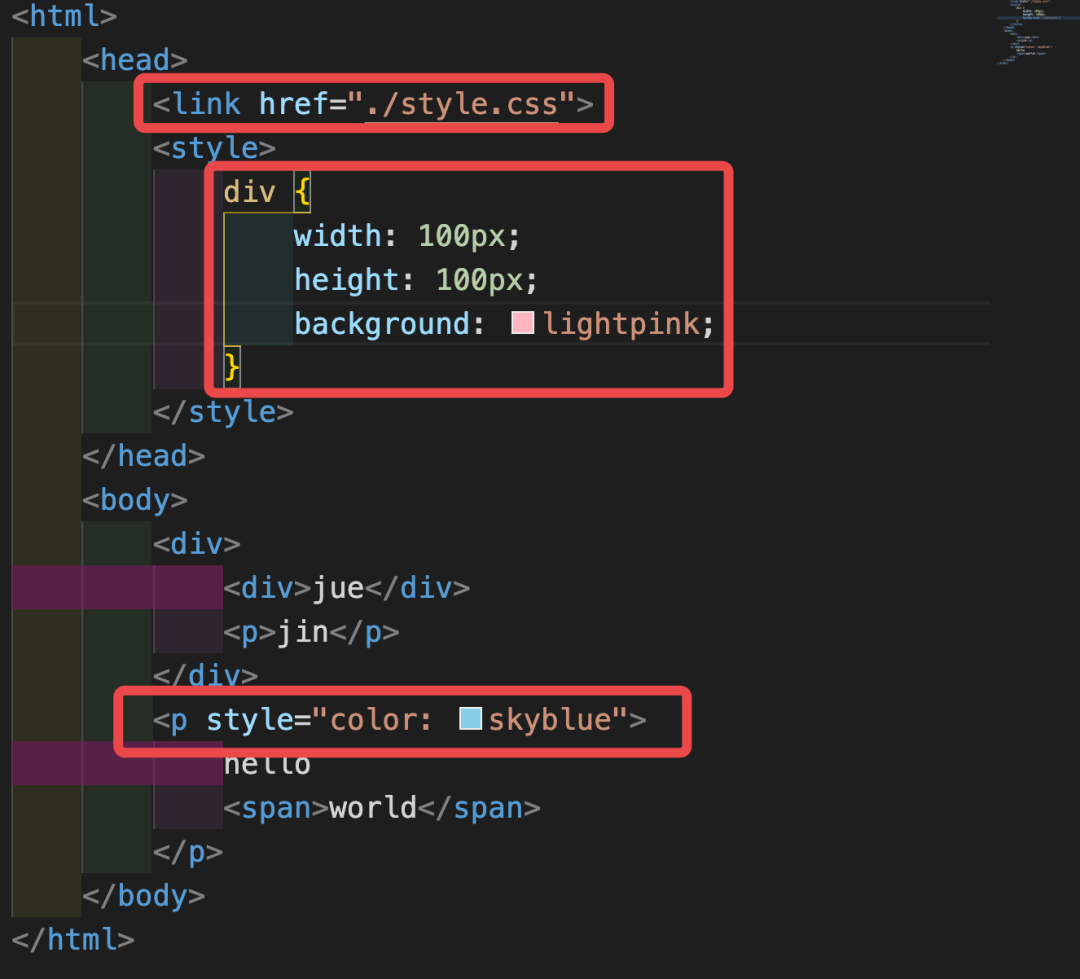
对于以下代码:
<html>
<head>
<link href="./style.css">
<style>
.juejin {
width: 100px;
height: 50px;
background: red;
}
.content {
font-size: 25px;
line-height: 25px;
margin: 10px;
}
</style>
</head>
<body>
<div class="juejin">
<div>CUGGZ</div>
</div>
<p style="color: blue" class="content">
<span>hello world</span>
<p style="display: none;">浏览器</p>
</p>
</body>
</html>最终生成的CSSOM树大致如下:
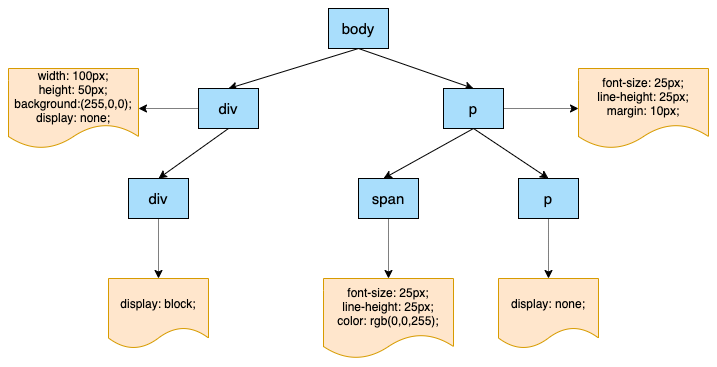
渲染树构建
在 DOM 树和 CSSOM 树都渲染完成之后,就会进入渲染树的构建阶段。渲染树就是 DOM 树和 CSSOM 树的结合,会得到一个可以知道每个节点会应用什么样式的数据结构。这个结合的过程就是遍历整个 DOM 树,然后在 CSSOM 树里查询到匹配的样式。
在不同浏览器里,构建渲染树的过程不太一样:
- 在 Chrome 里会在每个节点上使用 attach() 方法,把 CSSOM 树的节点挂在 DOM 树上作为渲染树。
- 在 Firefox 里会单独构造一个新的结构, 用来连接 DOM 树和 CSSOM 树的映射关系。
那为什么要构建渲染树呢?在上面的示例中可以看到,DOM树可能包含一些不可见的元素,比如head标签,使用display:none;属性的元素等。所以在显示页面之前,还要额外地构建一棵只包含可见元素的渲染树。
下面来看看构建渲染树的过程:
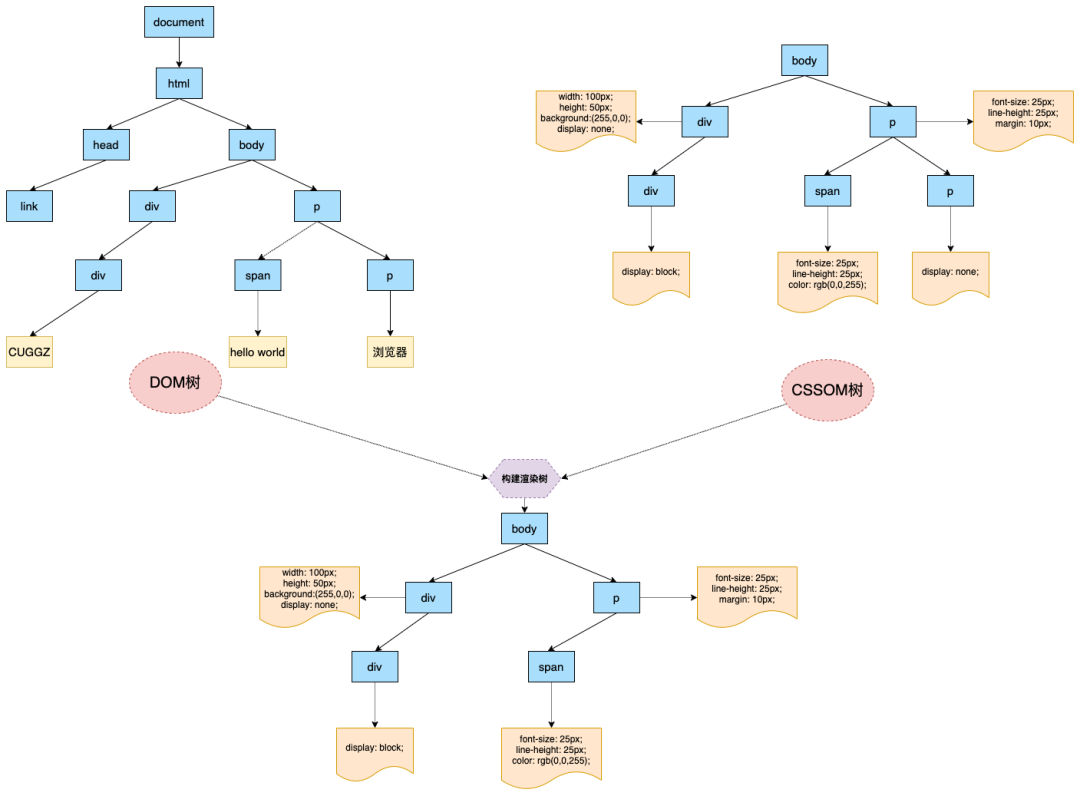
dispaly:none,所以这个元素也没有被包含进渲染树中。如果给元素设置了visibility: hidden属性,那这个元素会出现在渲染树中,因为具有这个样式的元素是需要占位的,只不过不需要显示出来。
这里在查找的过程中,出于效率的考虑,会从 CSSOM 树的叶子节点开始查找,对应在 CSS 选择器上也就是从选择器的最右侧向左查找。所以,不建议使用标签选择器和通配符选择器来定义元素样式。
除此之外,同一个 DOM 节点可能会匹配到多个 CSSOM 节点,而最终的效果由哪个 CSS 规则来确定,就是样式优先级的问题了。当一个 DOM 元素受到多条样式控制时,样式的优先级顺序如下:内联样式 > ID选择器 > 类选择器 > 标签选择器 > 通用选择器 > 继承样式 > 浏览器默认样式
CSS常见选择器的优先级如下:
| 选择器 | 格式 | 优先级权重 |
|---|---|---|
| id选择器 | #id | 100 |
| 类选择器 | .classname | 10 |
| 属性选择器 | a[ref=“eee”] | 10 |
| 伪类选择器 | li:last-child | 10 |
| 标签选择器 | div | 1 |
| 伪元素选择器 | li:after | 1 |
| 相邻兄弟选择器 | h1+p | |
| 子选择器 | ul>li | |
| 后代选择器 | li a | |
| 通配符选择器 | * | . |
对于选择器的优先级:
- 标签选择器、伪元素选择器:1;
- 类选择器、伪类选择器、属性选择器:10;
- id 选择器:100;
- 内联样式:1000;
注意:
- !important声明的样式的优先级最高;
- 如果优先级相同,则最后出现的样式生效;
- 继承得到的样式的优先级最低;
页面布局
经过上面的步骤,就生成了一棵渲染树,这棵树就是展示页面的关键。到现在为止,已经有了需要渲染的所有节点之间的结构关系及其样式信息。下面就需要进行页面的布局。
通过计算渲染树上每个节点的样式,就能得出来每个元素所占空间的大小和位置。当有了所有元素的大小和位置后,就可以在浏览器的页面区域里去绘制元素的边框了。这个过程就是布局。这个过程中,浏览器对渲染树进行遍历,将元素间嵌套关系以盒模型的形式写入文档流:
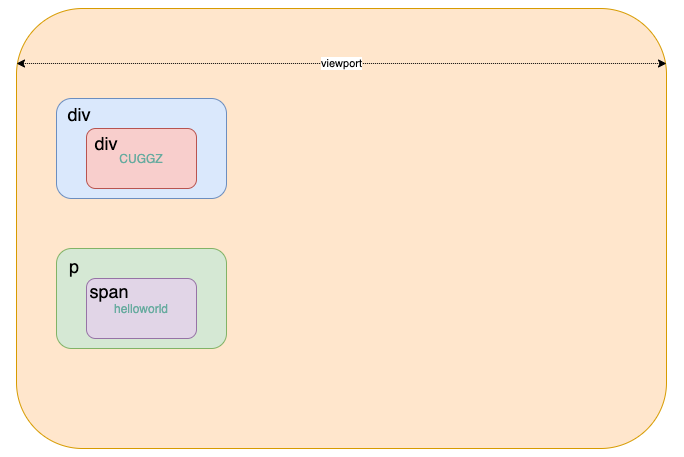
页面绘制
1. 构建图层
经过布局,每个元素的位置和大小就有了,那下面是不是就该开始绘制页面了?答案是否定的,因为页面上可能有很多复杂的场景,比如3D变化、页面滚动、使用z-index进行z轴的排序等。所以,为了实现这些效果,渲染引擎还需要为特定的节点生成专用的图层,并生成一棵对应的图层树。
那什么是图层呢?我们可以在Chrome浏览器的开发者工具中,选择Layers标签(如果没有,可以在更多工具中查找),就可以看到页面的分层情况,以掘金首页为例,其分层情况如下:
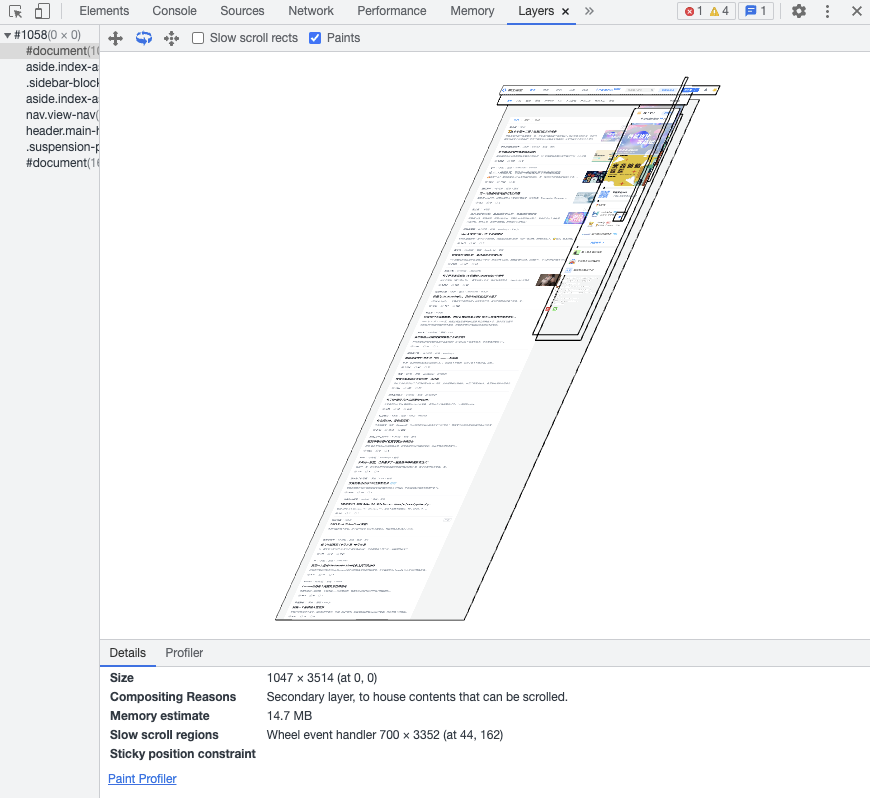
通常情况下,并不是渲染树上的每个节点都包含一个图层,如果一个节点没有对应的图层,那这个节点就会属于其父节点的图层。那什么样的节点才能让浏览器引擎为其创建一个新的图层呢?需要满足以下其中一个条件:
(1)拥有层叠上下文属性的元素
我们看到的页面通常是二维的平面,而层叠上下文能够让页面具有三维的概念。这些 HTML 元素按照自身属性的优先级分布在垂直于这个二维平面的 z 轴上。下面是盒模型的层叠规则:
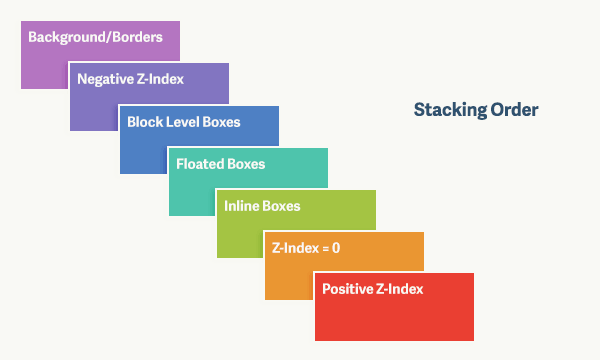
- 背景和边框:建立当前层叠上下文元素的背景和边框。
- 负的z-index:当前层叠上下文中,z-index属性值为负的元素。
- 块级盒:文档流内非行内级非定位后代元素。
- 浮动盒:非定位浮动元素。
- 行内盒:文档流内行内级非定位后代元素。
- z-index:0:层叠级数为0的定位元素。
- 正z-index:z-index属性值为正的定位元素。
注意: 当定位元素z-index:auto,生成盒在当前层叠上下文中的层级为 0,不会建立新的层叠上下文,除非是根元素。
(2)需要裁剪的元素
什么是裁剪呢?假如有一个固定宽高的div盒子,而里面的文字较多超过了盒子的高度,这时就会产生裁剪,浏览器渲染引擎会把裁剪文字内容的一部分用于显示在 div 区域。当出现裁剪时,浏览器的渲染引擎就会为文字部分单独创建一个图层,如果出现滚动条,那么滚动条也会被提升为单独的图层。
2. 绘制图层
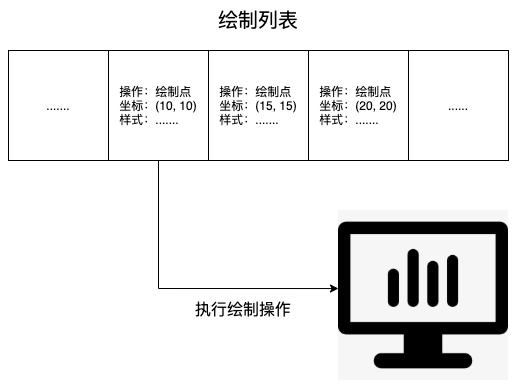
在完成图层树的构建之后,渲染引擎会对图层树中的每个图层进行绘制,下面就来看看渲染引擎是怎么实现图层绘制的。
渲染引擎在绘制图层时,会把一个图层的绘制分成很多绘制指令,然后把这些指令按照顺序组成一个待绘制的列表:
在Chrome浏览器的开发者工具中,通过Layer标签可以看到图层的绘制列表和绘制过程:
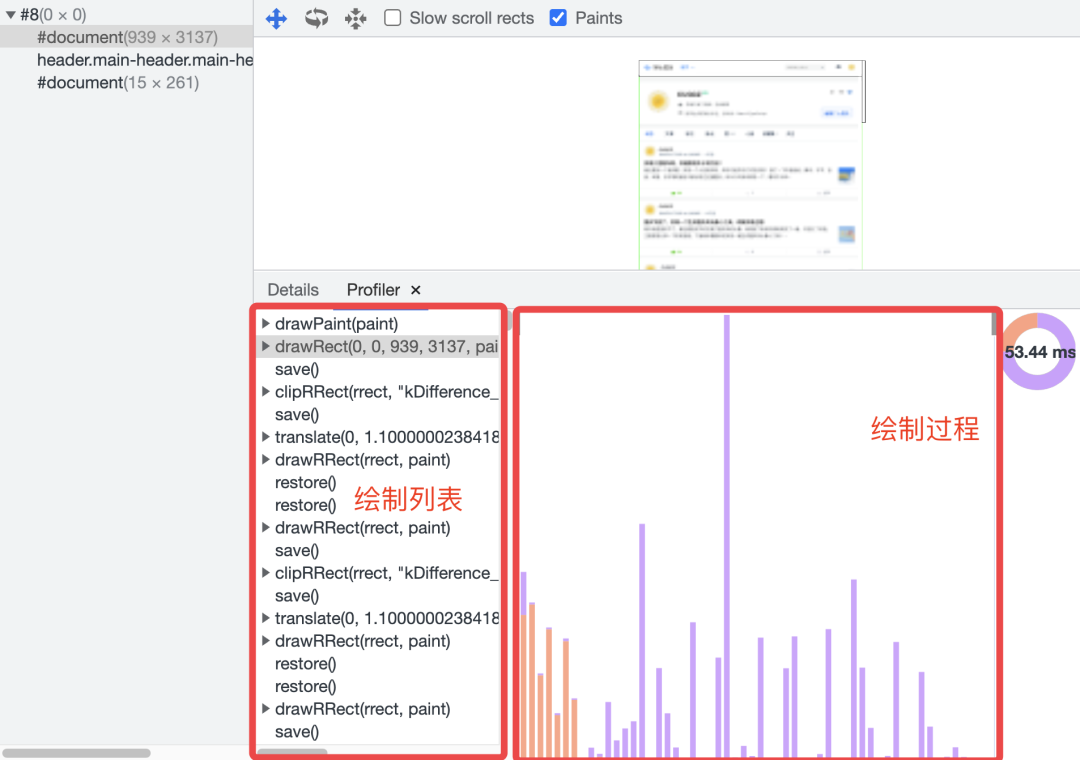
注意:合成操作是在合成线程上完成的,所以,在执行合成操作时并不会影响到主线程的执行。
很多情况下,图层可能很大,比如一篇长文章,需要滚动很久才能到底,但是用户只能看到视口的内容,所以没必要把整个图层都绘制出来。因此,合成线程会将图层划分为图块,这些图块的大小通常是 256x256 或者 512x512。合成线程会优先将视口附近的图块生成位图。实际生成位图的操作是在光栅化阶段来执行的,所谓的光栅化就是按照绘制列表中的指令生成图片。
当所有的图块都被光栅化之后,合成线程就会生成一个绘制图块的命令,浏览器相关进程收到这个指令之后,就会将其页面内容绘制在内存中,最后将内存显示在屏幕上,这样就完成了页面的绘制。
至此,整个渲染流程就完成了,其过程总结如下:
- 将HTML内容构建成DOM树;
- 将CSS内容构建成CSSOM树;
- 将DOM 树和 CSSOM 树合成渲染树;
- 根据渲染树进行页面元素的布局;
- 对渲染树进行分层操作,并生成分层树;
- 为每个图层生成绘制列表,并提交到合成线程;
- 合成线程将图层分成不同的图块,并通过栅格化将图块转化为位图;
- 合成线程给浏览器进程发送绘制图块指令;
- 浏览器进程会生成页面,并显示在屏幕上。
扩展
1. 重排和重绘
说完浏览器引擎的渲染流程,再来看两个重要的概念:重排(Reflow)和重绘(Repaint)。
我们知道,渲染树是动态构建的,所以,DOM节点和CSS节点的改动都可能会造成渲染树的重新构建。渲染树的改动就会造成页面的重排或者重绘。下面就来看看这两个概念,以及它们触发的条件和减少触发的操作。
(1)重排
当我们的操作引发了 DOM 树中几何尺寸的变化(改变元素的大小、位置、布局方式等),这时渲染树里有改动的节点和它影响的节点都要重新计算。这个过程就叫做重排,也称为回流。在改动发生时,要重新经历页面渲染的整个流程,所以开销是很大的。
以下操作都会导致页面重排:
- 页面首次渲染;
- 浏览器窗口大小发生变化;
- 元素的内容发生变化;
- 元素的尺寸或者位置发生变化;
- 元素的字体大小发生变化;
- 激活CSS伪类;
- 查询某些属性或者调用某些方法;
- 添加或者删除可见的DOM元素。
在触发重排时,由于浏览器渲染页面是基于流式布局的,所以当触发回流时,会导致周围的DOM元素重新排列,它的影响范围有两种:
- 全局范围:从根节点开始,对整个渲染树进行重新布局;
- 局部范围:对渲染树的某部分或者一个渲染对象进行重新布局。
(2)重绘
当对 DOM 的修改导致了样式的变化、但未影响其几何属性(比如修改颜色、背景色)时,浏览器不需重新计算元素的几何属性、直接为该元素绘制新的样式(会跳过重排环节),这个过程叫做重绘。简单来说,重绘是由对元素绘制属性的修改引发的。
当我们修改元素绘制属性时,页面布局阶段不会执行,因为并没有引起几何位置的变换,所以就直接进入了绘制阶段,然后执行之后的一系列子阶段。相较于重排操作,重绘省去了布局和分层阶段,所以执行效率会比重排操作要高一些。
下面这些属性会导致回流:
- color、background 相关属性:background-color、background-image 等;
- outline 相关属性:outline-color、outline-width 、text-decoration;
- border-radius、visibility、box-shadow。
注意:当触发重排时,一定会触发重绘,但是重绘不一定会引发重排。
相对来说,重排操作的消耗会比较大,所以在操作中尽量少的造成页面的重排。为了减少重排,可以通过以下方式进行优化:
- 在条件允许的情况下尽量使用 CSS3 动画,它可以调用 GPU 执行渲染。
- 操作DOM时,尽量在低层级的DOM节点进行操作
- 不要使用
table布局, 一个小的改动可能会使整个table进行重新布局 - 使用CSS的表达式
- 不要频繁操作元素的样式,对于静态页面,可以修改类名,而不是样式。
- 使用 absolute 或者 fixed,使元素脱离文档流,这样他们发生变化就不会影响其他元素
- 避免频繁操作DOM,可以创建一个文档片段
documentFragment,在它上面应用所有DOM操作,最后再把它添加到文档中 - 将元素先设置
display: none,操作结束后再把它显示出来。因为在display属性为none的元素上进行的DOM操作不会引发回流和重绘。 - 将DOM的多个读操作(或者写操作)放在一起,而不是读写操作穿插着写。这得益于浏览器的渲染队列机制。
浏览器针对页面的回流与重绘,进行了自身的优化——渲染队列, 浏览器会将所有的回流、重绘的操作放在一个队列中,当队列中的操作到了一定的数量或者到了一定的时间间隔,浏览器就会对队列进行批处理。这样就会让多次的回流、重绘变成一次回流重绘。
2. JavaScript 对 DOM 的影响
当解析器解析HTML时,如果遇到了script标签,判断这是脚本,就会暂停 DOM 的解析,因为接下来的 JavaScript 脚本可能会修改当前已经生成的 DOM 结构。
来看一段代码:
<html>
<body>
<div>hello juejin</div>
<script>
document.getElementsByTagName('div')[0].innerText = 'juejin yyds'
</script>
<p>hello world</p>
</body>
</html>这里,当解析完div标签后,就会解析script标签,这时的DOM结构如下:

上面我们说的JavaScript脚本是通过script标签直接嵌入到HTML中的。当在页面中引入JavaScript脚本时,情况就会变得复杂。比如:
<html>
<body>
<div>hello juejin</div>
<script type="text/javascript" src='./index.js'></script>
<p>hello world</p>
</body>
</html>其实这里的执行流程和上面时一样的,当遇到script标签时,HTML解析器都会暂停解析并去执行脚本文件。不过这里执行 JavaScript 脚本时,需要先下载脚本。脚本的下载过程会阻塞 DOM 的解析,而通常下载又是非常耗时的,会受到网络环境、JavaScript 脚本文件大小等因素的影响。
经过上面的分析可知,JavaScript 线程会阻塞 DOM 的解析,我们可以通过CDN、压缩脚本等方式来加速 JavaScript 脚本的加载。如果脚本文件中没有操作DOM的相关代码,就可以将JavaScript脚本设置为异步加载,可以给script标签添加 async 或 defer 属性来实现脚本的异步加载。两者的使用方式如下:
<script async type="text/javascript" src='./index.js'></script>
<script defer type="text/javascript" src='./index.js'></script>下图可以直观的看出异步加载和直接加载的区别:
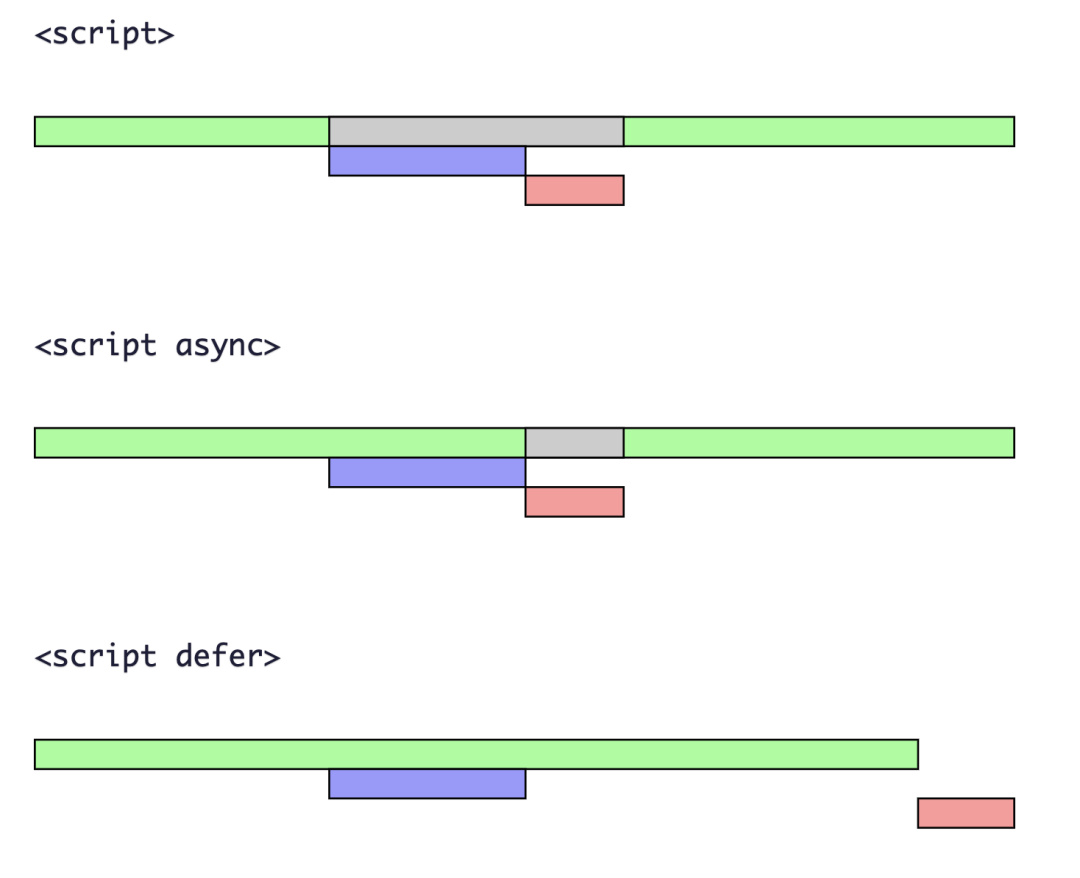
当初始HTML文档已完全加载和解析时,将触发DOMContentLoaded事件,而不需要等待样式表,图像和子框架页面加载。该事件可以用来检测HTML页面是否完全加载完毕。
defer 和 async属性都是去异步加载外部的JS脚本文件,它们都不会阻塞页面的解析,其区别如下:
- 执行顺序: 多个带async属性的标签,不能保证加载的顺序;多个带defer属性的标签,按照加载顺序执行;
- 脚本是否并行执行: async属性,表示后续文档的加载和执行与js脚本的加载和执行是并行进行的,即异步执行;defer属性,加载后续文档的过程和js脚本的加载(此时仅加载不执行)是并行进行的(异步),JavaScript 脚本需要等到文档所有元素解析完成之后才执行,DOMContentLoaded事件触发执行之前。
再来看另外一种情况:
<html>
<head>
<style src='./style.css'></style>
</head>
<body>
<div>hello juejin</div>
<script>
const ele = document.getElementsByTagName('div')[0];
ele.innerText = 'juejin yyds'; // 操作DOM
ele.style.color = 'skyblue'; // 操作CSSOM
</script>
<p>hello world</p>
</body>
</html>上面的代码中,第9行是操作DOM的,而第10行是操作CSSOM的,所以在执行 JavaScript 脚本之前,还需要先解析 JavaScript 语句之上所有的 CSS 样式。所以如果代码里引用了外部的 CSS 文件,那么在执行 JavaScript 之前,还需要 等待外部的 CSS 文件下载完成,并解析生成 CSSOM 对象之后,才能执行 JavaScript 脚本。而 JavaScript 引擎在解析 JavaScript 之前,是不知道 JavaScript 是否操纵了 CSSOM 的,所以渲染引擎在遇到 JavaScript 脚本时,不管该脚本是否操纵了 CSSOM,都会执行 CSS 文件下载,解析操作,再执行 JavaScript 脚本。
所以,JavaScript 会阻塞 DOM 生成,而样式文件又会阻塞 JavaScript 的执行,我们在开发时需要格外注意这一点。
最后再来看一种情况,示例代码如下:
<html>
<head>
<style src='./style.css'></style>
</head>
<body>
<div>hello juejin</div>
<script type="text/javascript" src='./index.js'></script>
<p>hello world</p>
</body>
</html>这段HTML代码中包含了CSS外部引用和JavaScript外部文件,在接收到 HTML 数据之后的预解析过程中,HTML 预解析器识别出来了有 CSS 文件和 JavaScript 文件需要下载,就会同时发起两个文件的下载请求。