Docker 是怎么实现的?前端怎么用 Docker 做部署?
代码开发完之后,要经过构建,把产物部署到服务器上跑起来,这样才能被用户访问到。
不同的代码需要不同的环境,比如 JS 代码的构建需要 node 环境,Java 代码 需要 JVM 环境,一般我们会把它们隔离开来单独部署。
现在一台物理主机的性能是很高的,完全可以同时跑很多个服务,而我们又有环境隔离的需求,所以会用虚拟化技术把一台物理主机变为多台虚拟主机来用。
现在主流的虚拟化技术就是 docker 了,它是基于容器的虚拟化技术。
它可以在一台机器上跑多个容器,每个容器都有独立的操作系统环境,比如文件系统、网络端口等。
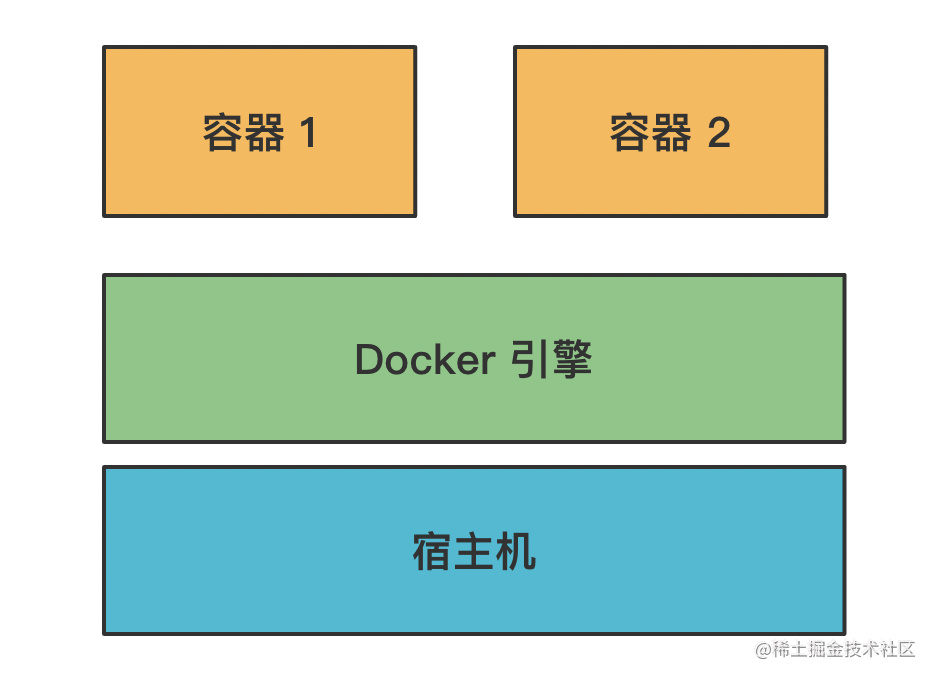

这就依赖操作系统的机制了:
linix 提供了一种叫 namespace 的机制,可以给进程、用户、网络等分配一个命名空间,这个命名空间下的资源都是独立命名的。
比如 PID namespace,也就是进程的命名空间,它会使命名空间内的这个进程 id 变为 1,而 linux 的初始进程的 id 就是 1,所以这个命名空间内它就是所有进程的父进程了。
而 IPC namespace 能限制只有这个 namespace 内的进程可以相互通信,不能和 namespace 外的进程通信。
Mount namespace 会创建一个新的文件系统,namespace 内的文件访问都是在这个文件系统之上。
类似这样的 namespace 一共有 6 种:
- PID namespace:进程 id 的命名空间
- IPC namespace:进程通信的命名空间
- Mount namespace:文件系统挂载的命名空间
- Network namespace:网络的命名空间
- User namespace:用户和用户组的命名空间
- UTS namespace:主机名和域名的命名空间
通过这 6 种命名空间,Docker 就实现了资源的隔离。
但是只有命名空间的隔离还不够,这样还是有问题的,比如如果一个容器占用了太多的资源,那就会导致别的容器受影响。
怎么能限制容器的资源访问呢?
这就需要 linux 操作系统的另一种机制:Control Group。
创建一个 Control Group 可以给它指定参数,比如 cpu 用多少、内存用多少、磁盘用多少,然后加到这个组里的进程就会受到这个限制。
这样,创建容器的时候先创建一个 Control Group,指定资源的限制,然后把容器进程加到这个 Control Group 里,就不会有容器占用过多资源的问题了。
那这样就完美了么?
其实还有一个问题:每个容器都是独立的文件系统,相互独立,而这些文件系统之间可能很大部分都是一样的,同样的内容占据了很大的磁盘空间,会导致浪费。
那怎么解决这个问题呢?
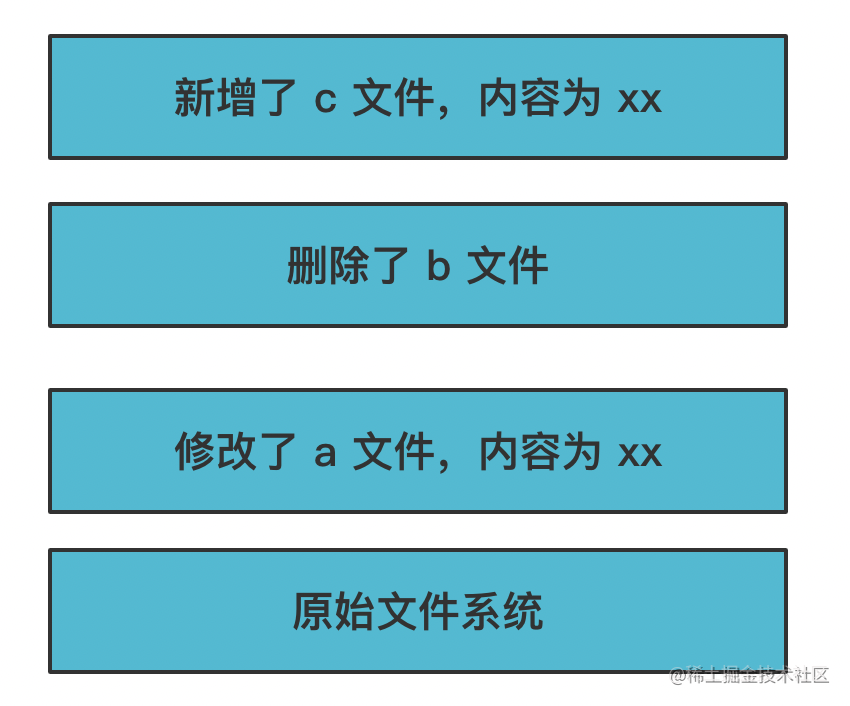
Docker 设计了一种分层机制:
每一层都是不可修改的,也叫做镜像。那要修改怎么办呢?
会创建一个新的层,在这一层做修改
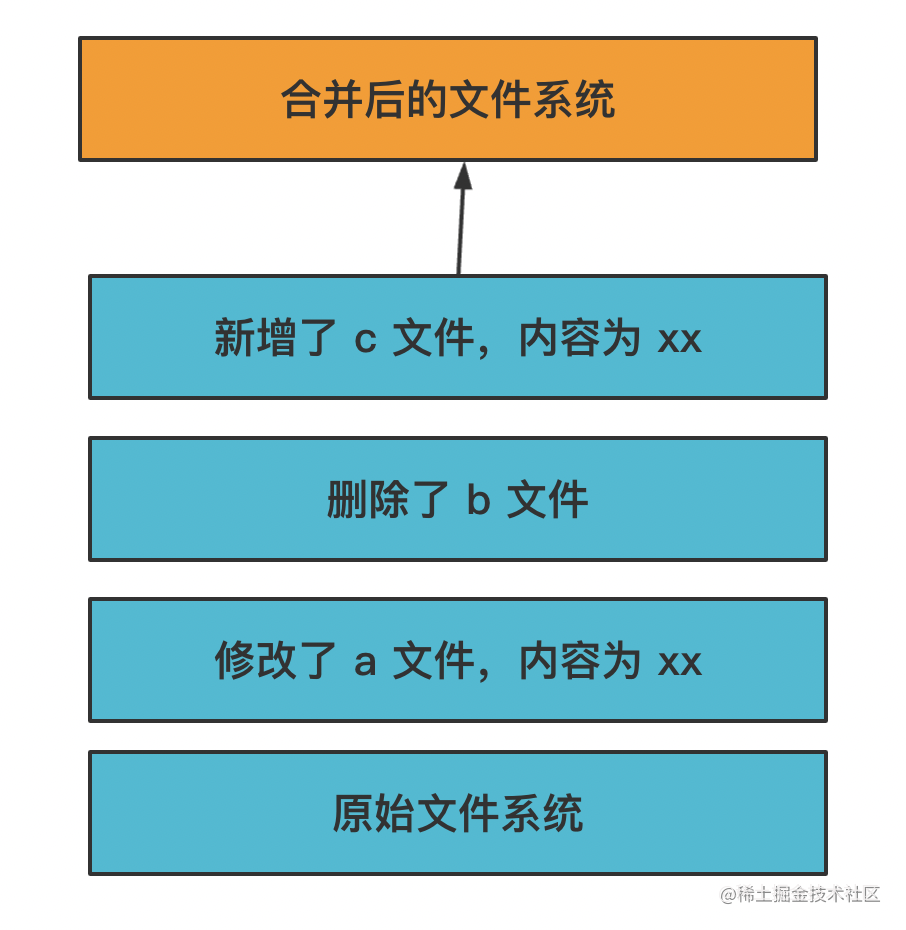
Docker 通过这种分层的镜像存储,写时复制的机制,极大的减少了文件系统的磁盘占用。
而且这种镜像是可以复用的,上传到镜像仓库,别人拉下来也可以直接用。
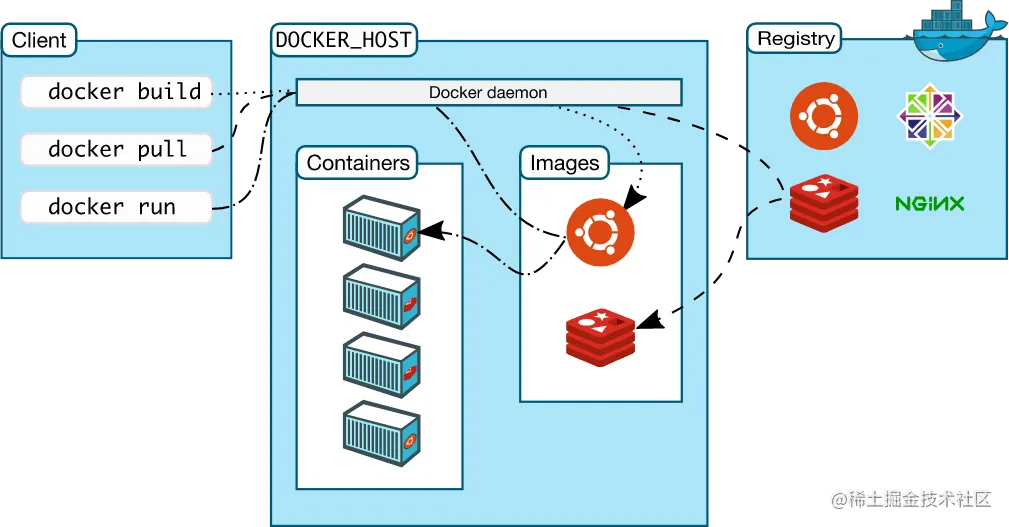
比如下面这张 Docker 架构图:
回顾一下 Docker 实现原理的三大基础技术:
- Namespace:实现各种资源的隔离
- Control Group:实现容器进程的资源访问限制
- UnionFS:实现容器文件系统的分层存储,写时复制,镜像合并
都是缺一不可的。
上图中还有个 docker build 是干啥的呢?
一般我们生成镜像都是通过 dockerfile 来描述的。
比如这样:
FROM node:10
WORKDIR /app
COPY . /app
EXPOSE 8080
RUN npm install http-server -g
RUN npm install && npm run build
CMD http-server ./distDokcer 是分层存储的,修改的时候会创建一个新的层,所以这里的每一行都会创建一个新的层。
这些指令的含义如下:
- FROM:基于一个基础镜像来修改
- WORKDIR:指定当前工作目录
- COPY:把容器外的内容复制到容器内
- EXPOSE:声明当前容器要访问的网络端口,比如这里起服务会用到 8080
- RUN:在容器内执行命令
- CMD:容器启动的时候执行的命令
上面这个 dockerfile 的作用不难看出来,就是在 node 环境下,把项目复制过去,执行依赖安装和构建。
我们通过 docker build 就可以根据这个 dockerfile 来生成镜像。
然后执行 docker run 把这个镜像跑起来,这时候就会执行 http-server ./dist 来启动服务。
这个就是一个 docker 跑 node 静态服务的例子。
但其实这个例子不是很好,从上面流程的描述我们可以看出来,构建的过程只是为了拿到产物,容器运行的时候就不再需要了。
那能不能把构建分到一个镜像里,然后把产物赋值到另一个镜像,这样单独跑产物呢?
确实可以,而且这也是推荐的用法。
那岂不是要 build 写一个 dockerfile,run 写一个 dockerfile 吗?
也不用,docker 支持多阶段构建,比如这样:
# build stage
FROM node:10 AS build_image
WORKDIR /app
COPY . /app
EXPOSE 8080
RUN npm install && npm run build
# production stage
FROM node:10
WORKDIR /app
COPY --from=build_image /app/dist ./dist
RUN npm i -g http-server
CMD http-server ./dist我们把两个镜像的生成过程写到了一个 dockerfile 里,这是 docker 支持的多阶段构建。
第一个 FROM 里我们写了 as build_image,这是把第一个镜像命名为 build_image。
后面第二个镜像 COPY 的时候就可以指定 --from=build_image 来从那个镜像复制内容了。
这样,最终只会留下第二个镜像,这个镜像里只有生产环境需要的依赖,体积更小。传输速度、运行速度也会更快。
构建镜像和运行镜像分离,这个算是一种最佳实践了。
一般我们都是在 jenkins 里跑,push 代码的时候,通过 web hooks 触发 jenkins 构建,最终产生运行时的镜像,上传到 registry。
部署的时候把这个镜像 docker pull 下来,然后 docker run 就完成了部署。
node 项目的 dockerfile 大概怎么写我们知道了,那前端项目呢?
大概是这样的:
# build stage
FROM node:14.15.0 as build-stage
WORKDIR /app
COPY package.json ./
RUN npm install
COPY . .
RUN npm run build
# production stage
FROM nginx:stable-perl as production-stage
COPY --from=build-stage /app/dist /usr/share/nginx/html
COPY --from=build-stage /app/default.conf /etc/nginx/conf.d/default.conf
EXPOSE 80
CMD ["nginx", "-g", "daemon off;"]也是 build 阶段通过一个镜像做构建,然后再制作一个镜像把产物复制过去,然后用 nginx 跑一个静态服务。
一般公司内部署前端项目都是这样的。
不过也不一定。
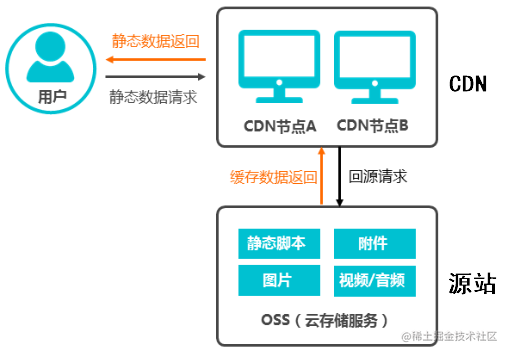
因为公司部署前端代码的服务是作为 CDN 的源站服务器的,CDN 会从这里取文件,然后在各地区的缓存服务器缓存下来。
而阿里云这种云服务厂商都提供了对象存储服务,可以直接把静态文件上传到 oss,根本不用自己部署:
总结
Docker 是一种虚拟化技术,通过容器的方式,它的实现原理依赖 linux 的 Namespace、Control Group、UnionFS 这三种机制。
Namespace 做资源隔离,Control Group 做容器的资源限制,UnionFS 做文件系统的镜像存储、写时复制、镜像合并。
一般我们是通过 dockerfile 描述镜像构建的过程,然后通过 docker build 构建出镜像,上传到 registry。
镜像通过 docker run 就可以跑起来,对外提供服务。
用 dockerfile 做部署的最佳实践是分阶段构建,build 阶段单独生成一个镜像,然后把产物复制到另一个镜像,把这个镜像上传 registry。
这样镜像是最小的,传输速度、运行速度都比较快。
前端、node 的代码都可以用 docker 部署,前端代码的静态服务还要作为 CDN 的源站服务器,不过我们也不一定要自己部署,很可能直接用阿里云的 OSS 对象存储服务了。
理解了 Docker 的实现原理,知道了怎么写 dockerfile 还有 dockerfile 的分阶段构建,就可以应付大多数前端部署需求了。