Go语言从0到1实现最简单的数据库!
导语 | 后台开发对于数据库操作是必不可少的事情,了解数据库原理对于平常的工作的内功积累还是很有帮助的,这里实现一个最简单的数据库加深自己对数据库的理解。
一、go实现数据库目的
-
了解数据是如何在内存和磁盘存储的
-
数据是怎么移动到磁盘
-
主键是如何保持唯一性
-
索引是如何形成
-
如何进行全表遍历
-
熟悉Go语言对内存以及文件操作
二、数据库选择SQLite
选择SQLite(https://www.sqlite.org/arch.html)原因是数据库完全开源,实现简单,并且有C语言最简单的实现版本,因此参考go语言实现一个数据库加深对于关系型数据库的理解。
三、SQLite主要架构
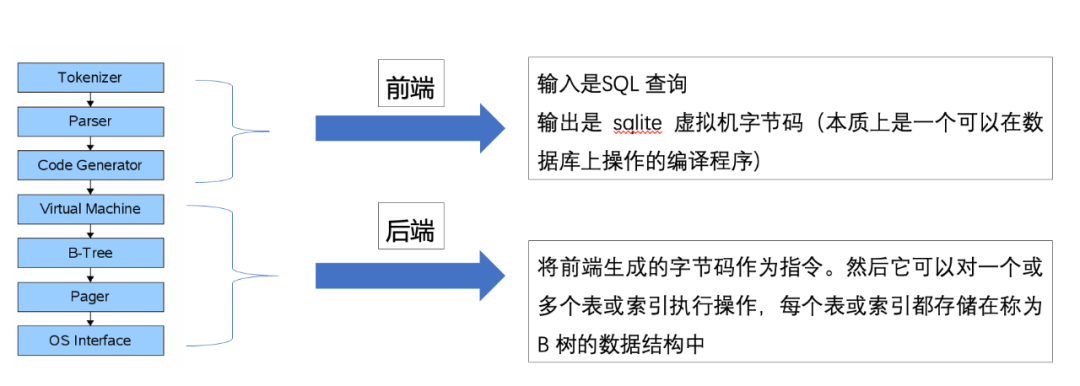
其中:前端的输入是一个SQL查询。输出是sqlite虚拟机字节码(本质上是一个可以在数据库上操作的编译程序) 后端:VM将前端生成的字节作为指令,然后对一个表或者多个表或索引进行操作,每一个表或者索引都存储在B树中,VM本质上时指令的分支选择语句。B树组成了每一个节点,每个节点的最大长度时一页。B树可以通过pager的命令,将数据保存到磁盘上。pager收到数据读写的命令,负责数据偏移与读写,它还将最近访问的页面缓存在内存中,并确定何时需要将这些页面写回磁盘。
雷普勒
启动sqlite,会有一个读写命令循环:
main函数将有一个无限循环来打印提示,获取一行输入,然后处理该行输入:
// run main 主函数,这样写方便单元测试
func run() {
table, err := dbOpen("./db.txt")
if err != nil {
panic(err)
}
for {
printPrompt()
// 语句解析
inputBuffer, err := readInput()
if err != nil {
fmt.Println("read err", err)
}
// 特殊操作
if len(inputBuffer) != 0 && inputBuffer[0] == '.' {
switch doMetaCommand(inputBuffer, table) {
case metaCommandSuccess:
continue
case metaCommandUnRecongnizedCommand:
fmt.Println("Unrecognized command", inputBuffer)
continue
}
}
// 普通操作 code Generator
statement := Statement{}
switch prepareStatement(inputBuffer, &statement) {
case prepareSuccess:
break;
case prepareUnrecognizedStatement:
fmt.Println("Unrecognized keyword at start of ", inputBuffer)
continue
default:
fmt.Println("invalid unput ", inputBuffer)
continue
}
res := executeStatement(&statement, table)
if res == ExecuteSuccess {
fmt.Println("Exected")
continue
}
if res == ExecuteTableFull {
fmt.Printf("Error: Table full.\n");
break
}
if res == EXECUTE_DUPLICATE_KEY {
fmt.Printf("Error: Duplicate key.\n");
break;
}
}
}处理特殊的元语句如下:
func doMetaCommand(input string, table *Table) metaCommandType {
if input == ".exit" {
dbClose(table)
os.Exit(0)
return metaCommandSuccess
}
if input == ".btree" {
fmt.Printf("Tree:\n");
print_leaf_node(getPage(table.pager, 0));
return metaCommandSuccess;
}
if input == ".constants" {
fmt.Printf("Constants:\n");
print_constants();
return metaCommandSuccess
}
return metaCommandUnRecongnizedCommand
}效果如下:
四、最简单的“SQL编译器”
和“VM”(虚拟机)
(一)prepareStatement为最简单的解析器“SQL编译器”
当前改解析器,最简单到还没有识别出SQL语句,只是写死识别两个单词的SQL语句:
func prepareStatement(input string, statement *Statement)PrepareType {
if len(input) >= 6 && input[0:6] == "insert" {
statement.statementType = statementInsert
inputs := strings.Split(input, " ")
if len(inputs) <=1 {
return prepareUnrecognizedStatement
}
id, err := strconv.ParseInt(inputs[1], 10, 64)
if err != nil {
return prepareUnrecognizedSynaErr
}
statement.rowToInsert.ID = int32(id)
statement.rowToInsert.UserName = inputs[2]
statement.rowToInsert.Email = inputs[3]
return prepareSuccess
}
if len(input) >= 6 && input[0:6] == "select" {
statement.statementType = statementSelect
return prepareSuccess
}
return prepareUnrecognizedStatement
}(二)最简单的“虚拟机”(VM)执行器
// executeStatement 实行sql语句 ,解析器解析程statement,将最终成为我们的虚拟机
func executeStatement(statement *Statement, table *Table) executeResult{
switch statement.statementType {
case statementInsert:
return executeInsert(statement, table)
case statementSelect:
return executeSelect(statement, table)
default:
fmt.Println("unknown statement")
}
return ExecuteSuccess
}(三)最简单的插入的数据结构
需要插入序列化的数据格式如下:
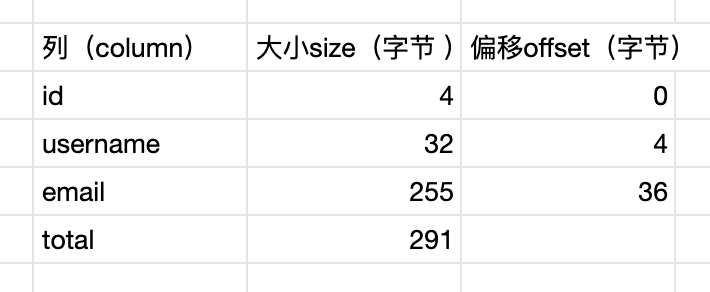
将一列进行序列化代码如下:
// 将row序列化到指针,为标准写入磁盘做准备
func serializeRow(row *Row, destionaton unsafe.Pointer) {
ids := Uint32ToBytes(row.ID)
q := (*[ROW_SIZE]byte)(destionaton)
copy(q[0:ID_SIZE], ids)
copy(q[ID_SIZE+1:ID_SIZE+USERNAME_SIZE], (row.UserName))
copy(q[ID_SIZE+USERNAME_SIZE+1: ROW_SIZE], (row.Email))
}(四)从文件去取出反序列化
// deserializeRow 将文件内容序列化成数据库元数据
func deserializeRow(source unsafe.Pointer, rowDestination *Row) {
ids := make([]byte, ID_SIZE, ID_SIZE)
sourceByte := (*[ROW_SIZE]byte)(source)
copy(ids[0:ID_SIZE], (*sourceByte)[0:ID_SIZE])
rowDestination.ID = BytesToInt32(ids)
userName := make([]byte, USERNAME_SIZE, USERNAME_SIZE)
copy(userName[0:], (*sourceByte)[ID_SIZE+1: ID_SIZE + USERNAME_SIZE])
realNameBytes := getUseFulByte(userName)
rowDestination.UserName = (string)(realNameBytes)
emailStoreByte := make([]byte, EMAIL_SIZE, EMAIL_SIZE)
copy(emailStoreByte[0:], (*sourceByte)[1+ ID_SIZE + USERNAME_SIZE: ROW_SIZE])
emailByte := getUseFulByte(emailStoreByte)
rowDestination.Email = (string)(emailByte)
}(五)呼叫器
主要功能写入到磁盘,数据结构:
// Pager 管理数据从磁盘到内存
type Pager struct {
osfile *os.File;
fileLength int64;
numPages uint32;
pages []unsafe.Pointer; // 存储数据
}整个数据库的数据表:
// Table 数据库表
type Table struct {
rootPageNum uint32;
pager *Pager;
}page写入磁盘,由下面可以看到时一页一页写入文件:
// pagerFlush 这一页写入文件系统
func pagerFlush(pager *Pager, pageNum , realNum uint32) error{
if pager.pages[pageNum] == nil {
return fmt.Errorf("pagerFlush null page")
}
offset, err := pager.osfile.Seek(int64(pageNum*PageSize), io.SeekStart)
if err != nil {
return fmt.Errorf("seek %v", err)
}
if offset == -1 {
return fmt.Errorf("offset %v", offset)
}
originByte := make([]byte, realNum)
q := (*[PageSize]byte)(pager.pages[pageNum])
copy(originByte[0:realNum], (*q)[0:realNum])
// 写入到byte指针里面
bytesWritten, err := pager.osfile.WriteAt(originByte, offset)
if err != nil {
return fmt.Errorf("write %v", err)
}
// 捞取byte数组到这一页中
fmt.Println("already wittern", bytesWritten)
return nil
}在关闭db的链接,写入磁盘:
func dbClose(table *Table) {
for i:= uint32(0); i < table.pager.numPages; i++ {
if table.pager.pages[i] == nil {
continue
}
pagerFlush(table.pager, i, PageSize);
}
defer table.pager.osfile.Close()
// go语言自带gc
}数据从磁盘到内存的获取:
func getPage(pager *Pager, pageNum uint32) unsafe.Pointer {
if pageNum > TABLE_MAX_PAGES {
fmt.Println("Tried to fetch page number out of bounds:", pageNum)
os.Exit(0)
}
if pager.pages[pageNum] == nil {
page := make([]byte, PageSize)
numPage := uint32(pager.fileLength/PageSize) // 第几页
if pager.fileLength%PageSize == 0 {
numPage += 1
}
if pageNum <= numPage {
curOffset := pageNum*PageSize
// 偏移到下次可以读读未知
curNum, err := pager.osfile.Seek(int64(curOffset), io.SeekStart)
if err != nil {
panic(err)
}
fmt.Println(curNum)
// 读到偏移这一页到下一页,必须是真的有多少字符
if _,err = pager.osfile.ReadAt(page, curNum);err != nil && err != io.EOF{
panic(err)
}
}
pager.pages[pageNum] = unsafe.Pointer(&page[0])
if pageNum >= pager.numPages {
pager.numPages = pageNum +1
}
}
return pager.pages[pageNum]
}上面可以看到,为了尽量减少磁盘IO,我们采用一页一页读取磁盘(disk)信息,并且以B+树点形似。
(六)B树
B树是对二叉查找树的改进:设计思想是,将相关数据尽量集中在一起,以便一次读取多个数据,减少硬盘操作次数。
(七)B+树:
非叶子节点不存储data,只存储key。如果每一个节点的大小固定(如4k,正如在sqlite中那样),那么可以进一步提高内部节点的度,降低树的深度。
(八)table和索引(索引)
根据sqlite介绍表的存储用的B+树,索引用的B树,我想大概是因为索引不需要存数据,只需要看存在不存在。这里的表比较小,索引暂时没有实现,下面有数据储存主键的查找。
树的节点查找
在表里面查找主键:
// 返回key的位置,如果key不存在,返回应该被插入的位置
func tableFind(table *Table, key uint32) *Cursor {
rootPageNum := table.rootPageNum
rootNode := getPage(table.pager, rootPageNum)
// 没有找到匹配到
if getNodeType(rootNode) == leafNode {
return leafNodeFind(table, rootPageNum, key)
} else {
fmt.Printf("Need to implement searching an internal node\n");
os.Exit(0);
}
return nil
}叶子节点查找:
func leafNodeFind(table *Table, pageNum uint32, key uint32) *Cursor {
node := getPage(table.pager, pageNum)
num_cells := *leaf_node_num_cells(node)
cur := &Cursor{
table: table,
page_num: pageNum,
}
// Binary search
var min_index uint32
var one_past_max_index = num_cells
for ;one_past_max_index != min_index; {
index := (min_index + one_past_max_index) /2
key_at_index := *leaf_node_key(node, index)
if key == key_at_index {
cur.cell_num = index
return cur
}
// 如果在小到一边,就将最大值变成当前索引
if key < key_at_index {
one_past_max_index = index
} else {
min_index = index+1 // 选择左侧
}
}
cur.cell_num = min_index
return cur
}并且为了B+树方便查找遍历,增加了游标抽象层次:
// Cursor 光标
type Cursor struct {
table *Table
pageNum uint32 // 第几页
cellNum uint32 // 多少个数据单元
endOfTable bool
}
func tableStart(table *Table) * Cursor{
rootNode := getPage(table.pager, table.rootPageNum)
numCells := *leaf_node_num_cells(rootNode)
return &Cursor{
table: table,
pageNum: table.rootPageNum,
cellNum: 0,
endOfTable: numCells ==0,
}
}
func cursorAdvance(cursor *Cursor) {
node := getPage(cursor.table.pager, cursor.pageNum)
cursor.cellNum += 1
if cursor.cellNum >=(*leaf_node_num_cells(node)) {
cursor.endOfTable = true
}
}五、总结
本文以Go语言从0到1实现最简单的数据库为例,选取SQlite数据库,实现了insert和select数据操作,并进一步介绍了page对磁盘的读写操作,B树如何进行数据存储操作等内容。只是当前实现的基于B+树的数据库仅仅支持一页内的读取,当一页内容达到上限4K之后便会报错,在后续开发中将进一步优化该功能,提升容量。
参考资料:
1.c语言0-1实现一个数据库