是什么让一段20行代码的性能提升了10倍

一、背景
1.1 业务背景
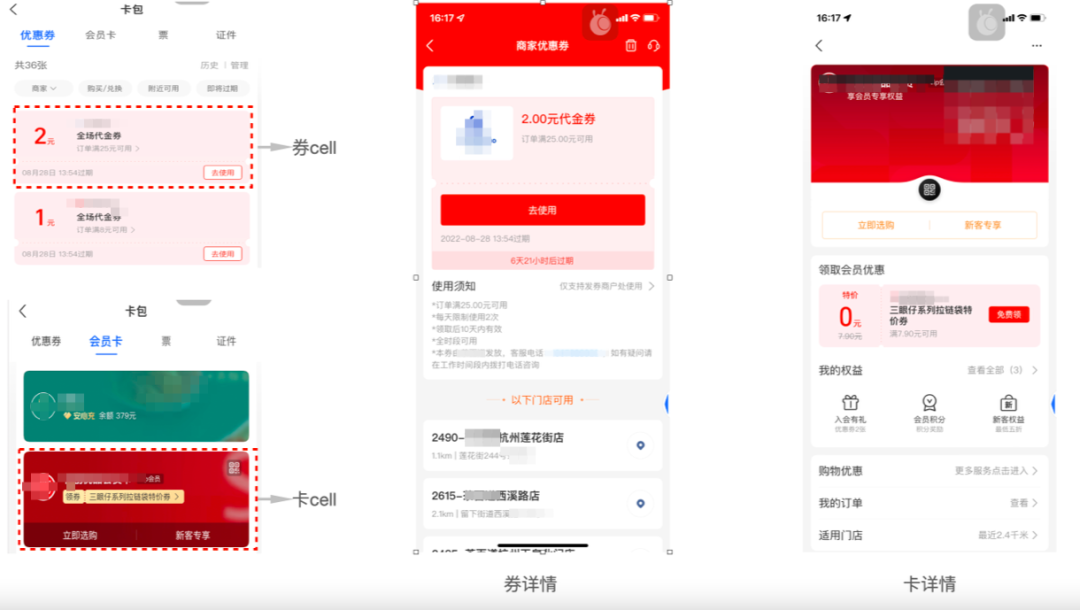
支付宝卡包存放着用户的会员卡和优惠券。无论是卡券cell,还是卡券详情,都是通过静态模板配置加上动态可变数据,最终呈现给终端用户的。
下面【图1】展现了卡券数据在C端用户的展现形式,【图2】表示了C端数据组装过程。
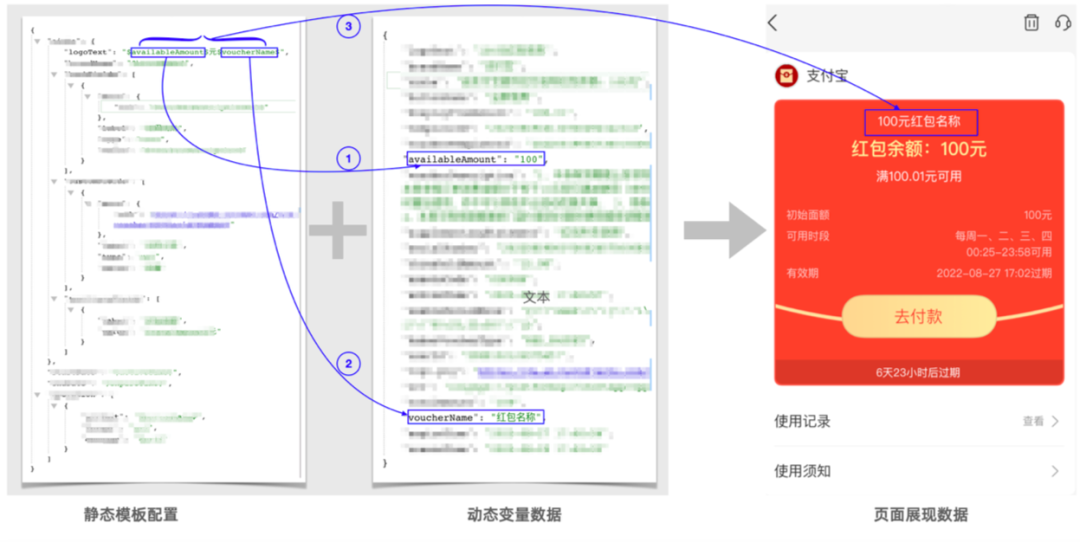
【图2】C端数据组装过程
以【图2】为例,模板中有availableAmount 和voucherName 两个变量,这两个变量在动态变量数据有对应的值。用动态的值替换掉模板里面对应的这两个变量,最后拼装成“100元红包名称”。当这个红包被使用了一次,消费了30元后,动态数据里面availableAmount 的值就会变成70。用户再次进入到红包详情页时,展现数据重新组装后就会变成“70元红包名称”。
1.2 问题发现
最近做项目过程中,把卡券组装渲染逻辑好好的梳理了一遍,其中仔细研读了【图3】这段模板变量替换逻辑。这是一段老代码,从卡包产品诞生之日起就存在,差不多有十年的时间了。其作用就是用动态数据替换掉模板里面的变量。这段代码逻辑咋一看,并没有什么问题,就是把模板里面两个$ 之间(包含)的变量,用动态数据进行替换。考虑到这是一段极为核心又高频的调用逻辑,于是看看有没有性能优化的空间。
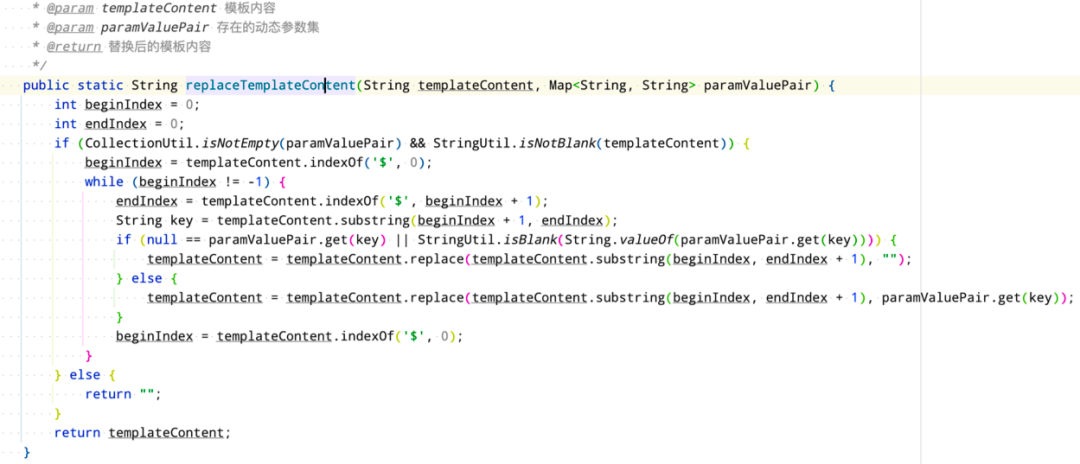
【图3】模板变量替换代码实现
把替换逻辑厘清了之后,第一感觉就是这段代码有性能提升的空间。主要有两点:
1、每次while 循环进行了两次indexOf 操作
2、每次while 循环都进行了substring 操作
于是,就有了下面两个疑问:
1、能够减少indexOf 和substring 操作吗?
2、真的每次都要进行模板变量查找吗?
二、性能优化
带着上面两个问题,逐步进行性能优化并测试。
整个优化过程一共迭代了5版,并最终取得了性能提升超过10倍的效果。下面分别来介绍下不同版本的实现和性能对比。
2.1 性能优化V1
这一版去掉了indexOf 和substring 操作,转而使用另一种替换方式。
之前的替换逻辑是从头到尾循环模板内容字符串,遇到$ 之间的变量就进行替换,过程中需要不断的进行indexOf 和substring 操作。新的实现方式是在进行变量替换之前,通过循环模板内容字符串,利用双指针把模板里面所有变量都提取出来,再对变量集合进行循环,依次替换掉模板内容里面的变量。
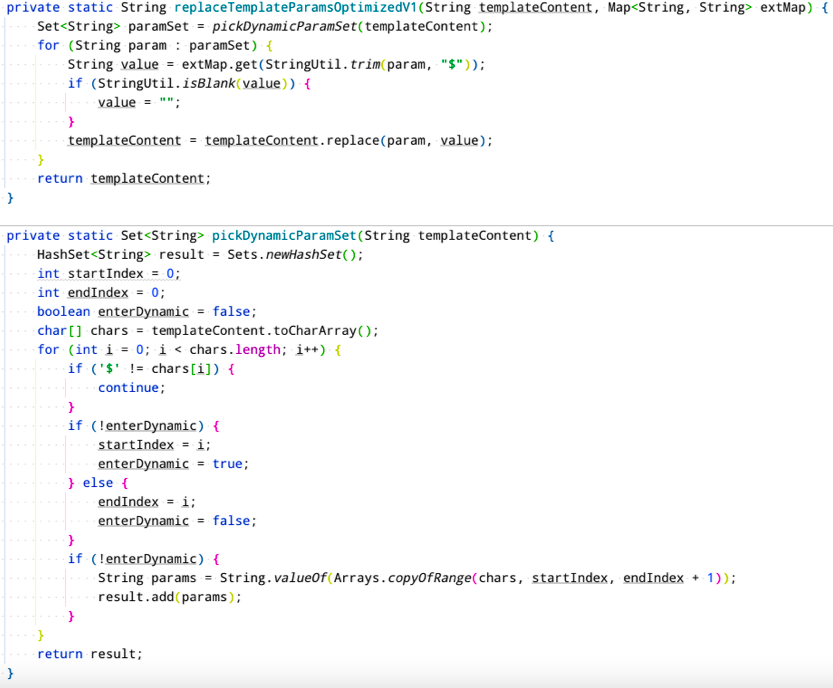
【图4】性能优化V1代码实现
2.2 性能优化V2
静态模板配置一般情况下不会发生变更。也就意味着,同一个模板对应的变量都是固定不变的。可以将模板id和模板变量集合进行一对一的缓存,减少每次替换之前的变量提取。
在决定使用缓存之前,要想好怎么实现缓存。有两点需要注意:
1、用本地缓存代替TBase,减少大流量场景下对TBase的压力
2、怎么控制本地缓存的有效数量,并在有限的内存占用情况下最大化缓存效率
可以借助Google Guava库的缓存类来实现缓存逻辑,示例代码见【图5】

【图5】缓存实现示例代码

【图6】性能优化V2代码实现
2.3 性能对比(1)
做完上面两步之后进行了性能测试,性能对比如【图7】所示。

【图7】V1、V2版性能对比
通过性能对比发现,V1版相对于原始版有性能提升,带缓存的V2版相对于不带缓存的V1版也有性能提升。但随着流量增大,性能优化效果逐步减弱。说明V1、V2版耗时优化的点,在整个模板变量替换耗时中占比并不高。也同时说明,整个模板变量替换逻辑当中,还存在其他更为耗时的点。
回过头来再仔细看一遍变量替换逻辑,突然间意识到遗漏了一个”大问题“。就是这个String.replace 方法,该方法有两个耗时点:
1、 每次replace 都会进行模板编译
2、replace 都是创建一个新的对象进行返回
并且每次replace 之后还要进行变量的重新赋值。
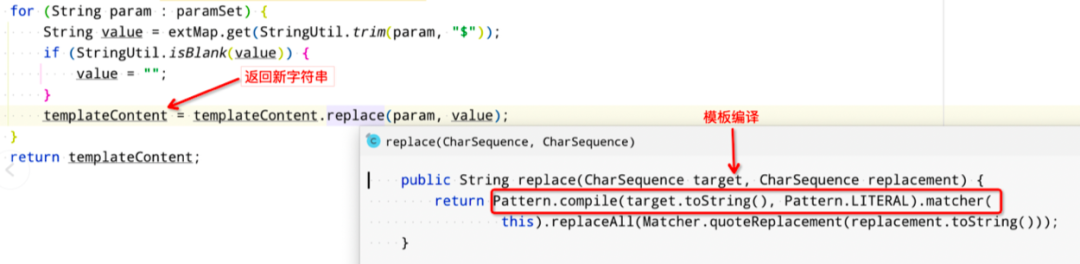
【图8】String.replace 代码实现
2.4 性能优化V3
在V2版基础上,去掉replace 方法,用StringBuilder 来实现。
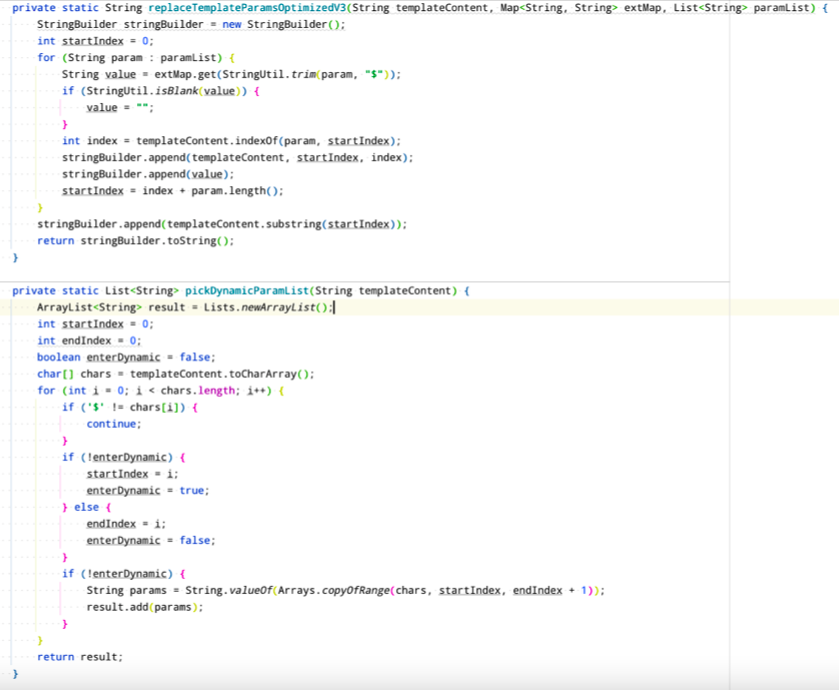
【图9】性能优化V3代码实现
StringBuilder 实现过程中有一点要注意。V2版本中,提取变量返回的是一个Set 集合。返回集合中出现变量的顺序和模板中变量顺序会不一致,模板中有多个相同变量的情况下,也只会替换第一个出现的变量。所以要将变量提取返回的结果换成有序可重复的List ,才能保证逻辑的正确性。
2.5 性能优化V4
V3版优化之后,性能提升明显,证明String.replace 方法才是整个模板变量替换逻辑中最为耗时的点。于是在原方法上只用StringBuilder 来替换String.replace ,得到V4版。

【图10】性能优化V4代码实现
2.6 性能对比(2)

【图11】V1、V2、V3、V4版性能对比
通过【图11】可以明显的发现,在进行StringBuilder 实现后,性能提升超过10倍,效果十分明显。
V4版耗时实际上比V3版带缓存的还要少,说明V3版先提取变量再进行StringBuilder 组装的过程,相对来说还是会更耗时一点。但V4版的代码可读性是不如V3版的,可以把V3版和V4版相结合,剔除掉缓存依赖,产生一个代码可读性和性能最佳的V5版。
2.7 性能优化V5
先提取变量,去掉缓存依赖,用StringBuilder 替换掉String.replace ,增加代码可读性。
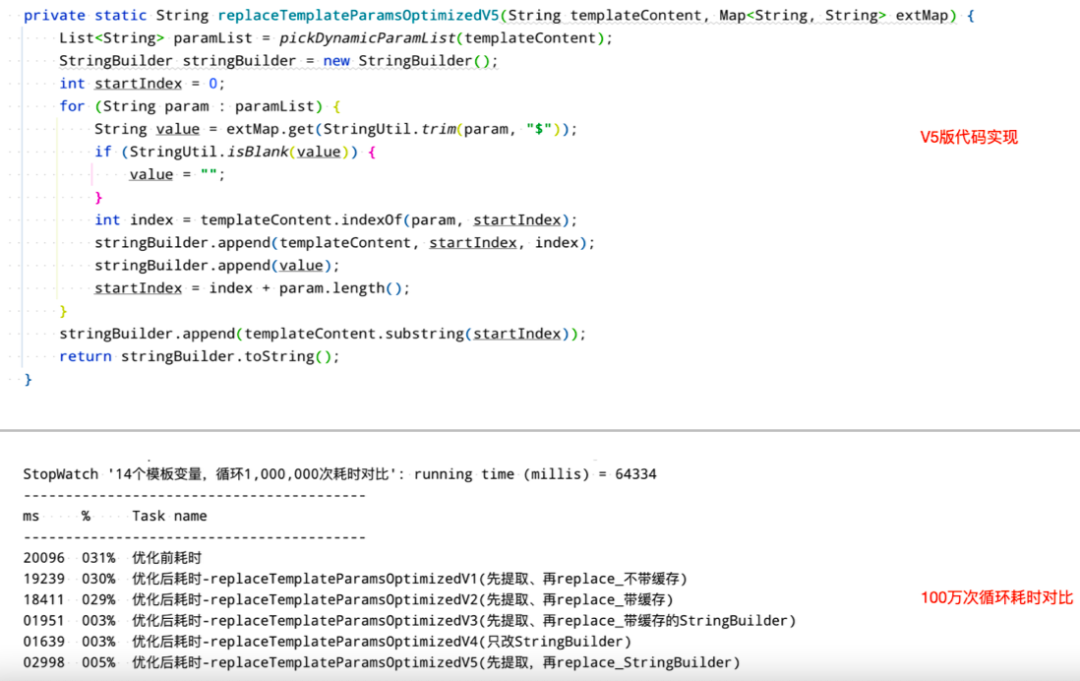
【图12】V5版代码实现&100万次循环耗时对比
三、总结
通过上面5个版本的性能优化,性能得到了超过10倍的提升。
性能由高到低的顺序是V4 > V3 > V5 > V2 > V1 > 未被优化的原始版。其中V3、V4、V5版的性能显著优于V1和V2版,证明这段模板替换逻辑最为耗时的点为String.replace ,V3 > V5和V2 > V1表明,引入缓存对性能提升还是有一定帮助的。在代码可读性方面,V4是不如V3和V5的。
整个优化总结下来主要有两点:
1、String.replace 方法涉及到模板编译和新字符串生成,比较吃资源
2、StringBuilder 代替String.replace ,除了能够缩短调用耗时,在空间上也能够减少资源占用。因为StringBuilder.append 相对于String.replace 来说,能够减少中间大量String 对象的创建和销毁,能够减少GC的压力,从而降低CPU的负载。
性能优化显而易见的好处是能够节约机器资源。如果一个有2000台服务器的应用,整体性能提升了10%,理论上来说,就相当于节省了200台的机器。除了节省机器资源外,性能好的应用相对于性能差的应用,在应对流量突增时更不容易达到机器的性能瓶颈,在同样流量场景下进行机器扩容时,也只需要更少的机器,从而能够更快的完成扩容、应急操作。所以,性能好的应用相对于性能差的应用在稳定性方面也更胜一筹。
最后再回到本次文章的主题:是什么让一段20行代码的性能提升了10倍?
我的回答是:StringBuilder yyds!