分页 + 模糊查询竟然有坑?
不知道你有没有使用过Mysql的like语句,进行模糊查询?
不知道你有没有将查询结果,进行分页处理?
模糊查询,加上分页处理,会有意想不到的坑,不信我们继续往下看。
我之前提供过一个品牌查询接口,给前端品牌选择控件使用的。
当时为了性能考虑,怕前端控件因为一次性加载太多的品牌,而导致页面卡死。
因此,对品牌查询接口做了分页处理。
刚开始品牌表的数据比较少,没有出现什么问题。
后来,产品加需求了,在品牌下拉选择控件中,让用户可以输入自定义品牌。
在用户添加品牌前,需要先查一下,如果该品牌存在,则使用已有品牌。如果不存在,则新增品牌。(这里是精确匹配)
这个需求很简单,很容易实现了。
后来,产品又加需求了,需要按名称模糊查询品牌。
该功能上线后,使用了很长一段时间,也没啥问题。
突然,在不经意的某一天,这个功能却出问题了。
到底怎么回事呢?
1.案发现场
某一天下午,运营找到测试反馈一个问题说:明明品牌苏三,已经存在了,但用户输入关键字:苏三时,系统没有让用户直接选择已有品牌,而是添加了一个叫:苏三的自定义的品牌。
我过去一看,还真的有问题。
不一会儿,就定位到原因了,初步判断是分页的问题。
搜索关键字:苏三,竟然出现了好几页的数据,把我惊呆了,品牌表怎么多了这么多数据了。
我查了数据库,其实数据量并不是特别多,但有些品牌名称比较特殊,有些品牌名称是多个品牌名称拼接而成的,比如:苏三,李四 或者 苏三,李四,王五,这是一个品牌。
其实是品牌名称建的不规范导致的问题,但已经没法让运营修改品牌了,只能通过技术手段解决目前的问题。
查询第一页的数据sql:
select * from brand where name like '%苏三%'
order by edit_date desc limit 5;执行结果: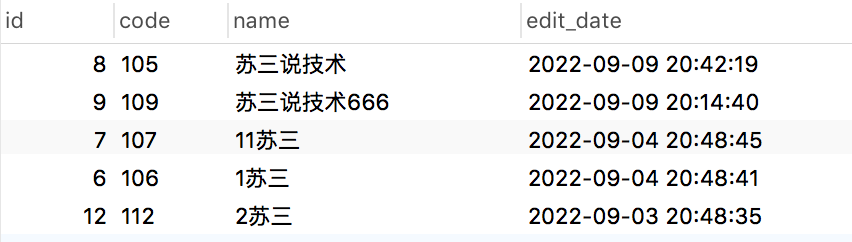
苏三这两个字的数据。
注意:为了好演示,这里给的每页大小是5,真实的场景并非如此。
查询第二页的数据sql:
select * from brand where name like '%苏三%'
order by edit_date desc limit 5,5;执行结果: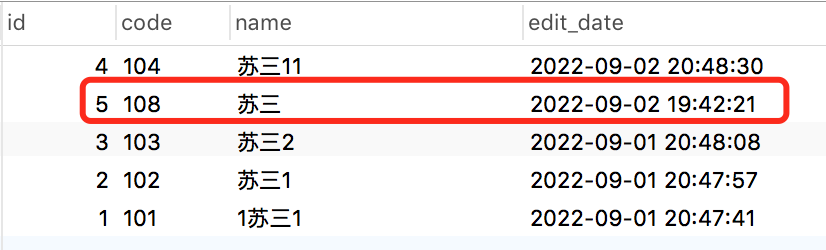
苏三这两个字的数据。
用户搜索关键字:苏三 时,前端页面在调用品牌查询接口,pageNo默认是1。由于能够匹配关键字的数据太多了,第一页返回不完,需要多页才能全部返回。
前端获取到第一页的数据后,跟关键字:苏三 做比较,发现没有等于苏三的品牌。
这样就会在下拉控件中,自动添加一个品牌:苏三,同时在右边增加自定义标签。
这样就出问题了,明明苏三这个品牌是有的,但用户还能自定义一个苏三,而不是直接选择。
2.思考123
苏三这个关键字,通过模糊查询可以查询出来,但由于品牌接口做了分页,全匹配的品牌:苏三,出现在第二页了,才导致问题的产生。
如果要解决这个问题,让它出现在第一页不就OK了?
这时候,就有下面几种解决方案。
2.1 方案1
分页查询品牌接口,pageSize是5。
我们为什么不把pageSize调大一点?比如改成:200、500等。
这样通过苏三关键字,进行模糊查询的时候,结果基本都在第一页。
这样就能非常快速的解决问题。
但有个缺点就是:如果这次调大了pageSize,但后面查询关键字的品牌又出现在第二页怎么办?
不可能一直改pageSize吧?
2.2 方案2
把分页查询接口的数据,拆分成两部分:
- 精确查询
- 模糊查询
在代码中做处理的时候,先根据关键字精确查询,即sql中使用name='苏三',这种方式查询一次数据。
如果没查出数据,则再直接用like '%苏三'进行模糊查询。
如果查出了一条数据,则把它放在返回结果集合中的第一位置。接下来,使用like '%苏三'进行模糊查询的时候,再加上条件 name <> '苏三'。将查出的结果,从第二个位置往后放。
这样可以拼接出你想要的集合。
但有个缺点,就是代码耦合性太大了。
2.3 方案3
之前,品牌苏三在第二页,最根本的原因是使用了edit_time字段进行逆序的。
也就是说,修改时间越大的越排在前面,而品牌苏三的修改时间很小,所以排在第二页了。
如果想品牌苏三,排在第一页,修改一下排序规则,不就搞定了?
可以改成按:id或者name字段排序。
用id字段排序,不太合适,虽说用了雪花算法,但跟修改时间类似,先插入的数据,会越小。
select * from brand where name like '%苏三%'
order by id desc limit 5;用它排序的结果,跟使用修改时间排序差不了太多。
3.如何排序?
我们在sql中直接对name字段,进行升序或者降序吗?
显然不是。
使用name字段降序:
select * from brand where name like '%苏三%'
order by char_length(name) asc limit 5;执行结果: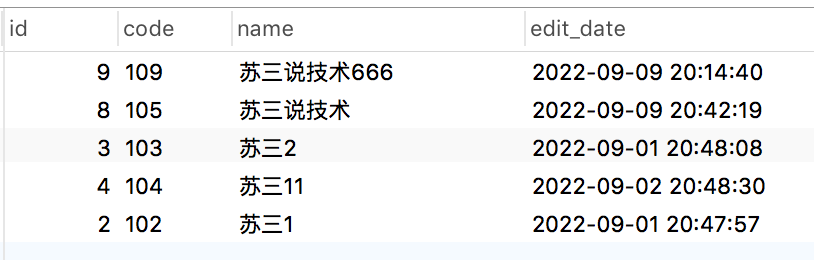
其实,使用name字段升序,也可能在第一页查不出我们所想要的数据。
到底该如何处理呢?
假如,我们有这样一种排序:
- 全匹配显示在最前面,比如:苏三。
- 数据左半部分匹配,右边按字母排序,比如:苏三1、苏三2、苏三说技术。
- 从中间开始匹配,比如:1苏三、2苏三。
- 第2步和第3步,还要根据字符长度排序,字符短的排在前面,比如:1苏三、1苏三1、苏三说技术。
如果我们能实现上面的这种排序方式,这个问题就能完美解决了。
说起来容易,做起来难。
难道要先全匹配:name='苏三',再有匹配:name like '苏三%',再左匹配:name like '%苏三',把查询三次的结果组装起来?
显然这种做法有点low。
要实现上面我们设想的排序方式,在es中更好处理一下,但在mysql中要怎么处理呢?
4.解决方案
其实,我们可以换一种思路,根据字符的长度排序。
mysql给我们提供了很多非常有用的函数,比如:char_length。
通过该函数就能获取字符长度。
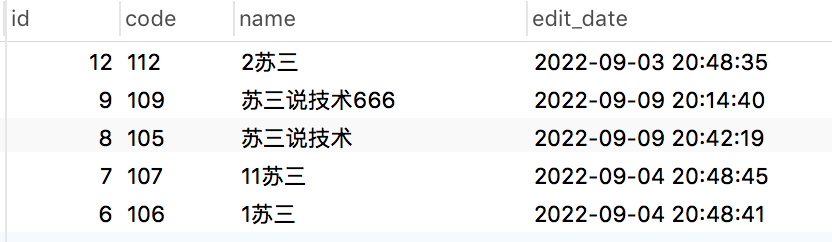
sql调整如下:
select * from brand where name like '%苏三%'
order by char_length(name) asc limit 5;name字段使用关键字模糊查询之后,再使用char_length函数,获取name字段的字符长度,然后按长度升序。
仅这一个骚操作,就搞定需求了: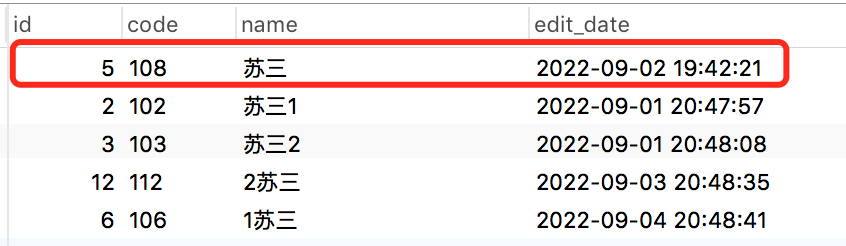
业务上的需求搞定了。
但追求完美的我们,好奇,想看看第二页是什么情况:
select * from brand where name like '%苏三%'
order by char_length(name) asc limit 5,5;执行结果:

这时该怎么办?
答:可以使用mysql中的locate函数,通过它可以匹配的关键字,在字符串中的位置。
使用locate函数改造之后sql如下:
select * from brand where name like '%苏三%'
order by char_length(name) asc, locate('苏三',name) asc limit 5,5;执行结果:
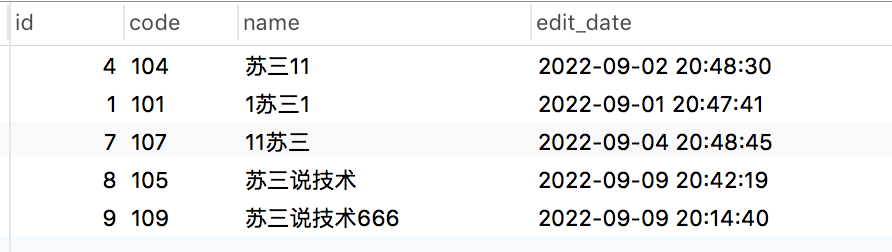
除此之外,还可以使用:instr和position函数,它们的功能跟locate函数类似,在这里我就不一一介绍了,感兴趣的小伙伴可以找我私聊。
5 . 总结
其实,模糊查询和分页,如果分开用,一般是没问题的。
但如果它们要一起使用,一定要考虑排序问题。
如果只是按照简单的时间或者id排序,有些特殊的业务场景,没办法满足,很容易出现bug。
当然解决上面问题,还有其他办法,比如:pageSize调大一点,或者把全匹配放到第一页。
但更优的方案,是通过mysql的函数来解决问题。
我们可以通过mysql提供的:char_length、locate、instr和position函数等,来实现很多复杂的排序功能。