多态实现-虚函数、函数指针以及变体
作为一名C++面试官,问的最多的问题就是说说多态的实现机制,无非想听到的答案就是虚函数以及虚函数表,也算是烂大街的问题了,稍微有点经验的候选人都会答上个一二三。今天,借助本文,我们聊聊实现多态的几个方式。
本文主要内容如下图所示:
背景
前段时间,群里某个读者突然抛出了一个问题,说是去面试的时候,面试官问了一个问题说说动态多态的实现方式,该读者详细的说了自己所知道的虚函数以及虚函数的实现机制,不过,貌似面试官不是很满意这个答案。

今天,借助本文,我们就聊聊动态多态的几种实现方式,当然,项目中不一定要用到,但总归还是要了解的。
概念
自我们接触C++开始,就提到了C++的三大特性封装、继承和多态。
多态(Polymorphisn)是面向对象程序设计(OOP)的一个重要特征。多态字面意思为多种状态。在面向对象语言中,一个接口,多种实现即为多态。
在C++中,多态体现在编译时和运行时两个方面。将编译时多态称之为静态多态,而将运行时多态称之为动态多态。
静态多态和动态多态的区别是在什么时候将函数实现和函数调用关联起来,是在编译时还是运行时。
传统上,静态多态分为函数重载和模板(也称为泛型编程)两种。而运行时多态则仅有虚函数一种。在本文中,我们将讲解另外两种多态-函数指针多态(静态多态)和variant多态(动态多态)两种。
虚函数
我敢保证,在大部分情况下,当听到运行时多态实现机制的时候,你第一印象肯定是虚函数(毕竟我们从接触多态开始,就是使用虚函数来实现)。本节从实现以及效率角度来对虚函数机制实现的多态进行分析。
实现
C++中的虚函数的作用主要是实现运行时多态。在基类中声明一个虚(virtual)函数,然后在派生类中对其进行重写。基类的引用或者指针指向一个派生类对象,当该基类变量调用该函数时候,会自动调用派生类的函数,这就是所谓的动态多态。
对C++了解的人都应该知道虚函数(Virtual Function)是通过一张虚函数表(Virtual Table)来实现的。简称为vtbl。在这个表中,主是要一个类的虚函数的地址表,这张表解决了继承、覆盖的问题,保证其容真实反应实际的函数。这样,在有虚函数的类的实例中这个表被分配在了这个实例的内存中,所以,当我们用父类的指针来操作一个子类的时候,这张虚函数表就显得由为重要了,它就像一个地图一样,指明了实际所应该调用的函数。
为了便于理解上面的内容,先来看一段代码:
class Base {
public:
virtual void Print(){
std::cout << "Base::Print" << std::endl;
}
virtual void fun() {
std::cout << "in Base::fun" << std::endl;
}
};
class Derived : public Base {
public:
void Print() {
std::cout << "in Derived::Print" << std::endl;
}
void fun() {
std::cout << "in Derived::fun" << std::endl;
}
};
int main() {
Base *b = new Derived;
b->Print();
return 0;
}不出意外的话,代码输出结果如下:
in Derived::Print
在前面的内容中有提到,C++是通过虚函数表来实现运行时多态的。通常所有声明为virtual的虚函数地址都被存放于该表中。编译器会为每个存在虚函数的类对象插入一个vtpr(virtul function pointer),该vptr指向存放了虚函数地址的虚函数表vtbl,这样对象在调用虚函数的时候,第一步会先根据vptr找到vbtl,然后根据该虚函数在vbtl中的索引来进行调用,这样就实现了运行时多态功能。
那么编译器又是如何实现的呢?我们以如下代码为例:
class Base {
public:
virtual void Print(){
std::cout << "Base::Print" << std::endl;
}
virtual void fun() {
std::cout << "in Base::fun" << std::endl;
}
};
Base b;
b.vptr = address of b.vtable;
b.vtable[0]= &Base::Print;
b.vtable[1]= &Base::fun;在上述代码中,有一个类Base,其中定义了两个虚函数fun1和fun2。因为有虚函数,所以编译器会创建一个虚函数表,表中的内容分别为虚函数的地址,vptr指向该虚函数表,示例图如下:
VFPTR VFTABLE FUNCTION
vptr -> Base::vtbl[0] -> Base::Print()
Base::vtbl[1] -> Base::fun()那么我们如何知道虚函数表中的内容呢?我们可以借助gdb来进行查看(gdb 提供了命令info vtbl object来查看虚函数表中的内容):
(gdb) set print object on
(gdb) info vtbl b
vtable for 'Base' @ 0x400a50 (subobject @ 0x7fffffffe120):
[0]: 0x4008fc <Base::Print()>
[1]: 0x400926 <Base::fun()>通过上述内容,我们可以看到,在虚函数表的第一项为Base::Print()的函数地址,在第二项为Base::fun()函数地址。这里说的项为虚函数表中的索引,这个索引是根据虚函数的声明顺序来确定的,假如又增加了一个虚函数virtual fun1(),那么其在虚函数表中的索引就是2。
如果我们想在代码中直接通过虚函数表调用虚函数,又该如何实现呢?大部分编译器的实现,都是将vptr放在对象的首位,所以我们可以通过这个特点来直接调用虚函数表中的函数,代码如下:
typedef void(*Fun)();
int main() {
Derived d;
long address = *(long*)&d;
Fun fun= (Fun)(*(long*)address);
fun();
fun = (Fun)(*(((long*)address)+1));
fun();
return 0;
}上述代码输出如下:
in Derived::Print()
in Derived::fun()好了,到了这里,使用虚函数表来实现运行时多态的实现机制基本已经讲完了,我们知道编译器是通过虚函数表来实现运行时多态操作的,那么对于普通的成员函数和虚成员函数,编译器的行为有什么区别呢?
name mangling
在进行下面内容之前,我们有必要讲讲name mangling。编译器会对函数进行name mangling,了解了这部分内容,便于理解后面编译器的相关行为。
在C++中,因为允许函数重载,所以编译器需要对函数进行name mangling,而对于C,因为不允许重载,所以不存在name mangling操作。
在此,说下编译器mangling后函数名的规则,仍然以成员函数Print()优化后的名称_ZN4Base5PrintEv为例(这个规则以笔者使用的gcc为例):
- 编码后的符号由_Z开头
- 如果有作用域符,则在_Z之后加上N
- 接着是命名空间名字长度、命名空间名字、类名字长度、类名、成员函数名称、函数名称
- 如果有作用域符,则以E结尾
- 最后加上函数形参符号,void是v,int是i,char是c,P代表指针,有几个形参就写几个符号
从上述规则我们可以看出,C++中的重载只跟函数名和函数参数有关。
如果想了解gcc对函数进行name mangling后的名称,可以进行如下操作:
gcc -c -std=c++11 test.cc && nm test.o | c++filt
...
0000000000000023 t _Z41__static_initialization_and_destruction_0ii
0000000000000000 W _ZN4Base3funEv
0000000000000000 W _ZN4Base5PrintEv
U _ZNSolsEPFRSoS_E
U _ZNSt8ios_base4InitC1Ev
U _ZNSt8ios_base4InitD1Ev
U _ZSt4cout
...不同的编译器采用不同的name mangling系统,还会有很多其他的问题导致不同编译生成的目标文件不能互相链接,因为name mangling只是C++ ABI中很少的一部分,例如异常处理(exception handling),虚表布局(virtual table layout),结构体和栈帧padding等都会导致不同编译器生成的目标文件不兼容。
C++标准没有为”name mangling”指定标准,引用g++问题列表上的一句话:
“compilers differ as to how objects are laid out, how multiple inheritance is implemented, how virtual function calls are handled, and so on, so if the name mangling were made the same, your programs would link against libraries provided from other compilers but then crash when run. For this reason, the ARM encourages compiler writers to make their name mangling different from that of other compilers for the same platform. Incompatible libraries are then detected at link time, rather than at run time”
上面的内容已经说明了为什么C++标准没有将name mangling标准。但是,在现在的很多编译器中,大多采用的是Itanium C++指定的mangling标准。
效率优化
编译器为了保证运行效率,从各个维度进行优化,将普通成员函数的效率优化成与普通函数一致,而对于虚函数的效率优化,则相较于普通成员函数,仅仅多了一次虚函数寻址。本节将从效率优化角度,来分析编译器是如何对普通成员函数和虚函数进行优化的。
普通成员函数
为了保证函数调用效率,对于普通的成员函数,编译器会将其转化成普通函数,如下:
class C {
public:
Print() {
// do sth
}
};
void Print() {
// do sth
}
Base b;
b.Print();
Print();在上述代码中,通过对象调用成员函数b.Print()以及普通的函数调用Print()效率是一样的。对于成员函数,编译器内部已经将成员函数实体转换为对应的非成员函数实体:
- 改写函数原型以安插一个额外的参数到成员函数中,通常这个额外的参数为对象的地址,如上述的成员函数Print最终会变成
Print(const Base *this) - 将成员函数重新写成一个外部函数,对函数名称进行
mangling处理,使它在程序中称为独一无二的词汇,比如Print()成员函数最终会变成_ZN4Base5PrintEv
结合上述两点,成员函数Print()最终会被编译器优化成一个普通函数_ZN4Base5PrintEv(const Base *this)。
Base b;
b.Print();上述代码最终由编译器优化为_ZN4Base5PrintEv(&b)。
虚函数
那么编译器对于虚函数又是如何做优化呢?
int main() {
Base *ptr = new Derived;
ptr->Print();
return 0;
}在上述代码中,有一个基类指针ptr指向派生类Derived对象,我们在进行ptr->Print()调用的时候,并不知道b所指对象的具体类型,但是有两点很清楚:
- 无论ptr对应哪种对象,我们总是可以通过ptr找到对应对象的vtbl
- 无论ptr对应哪种对象,Print()函数的地址总是在虚函数表的第1位
所以,编译器对上述调用将优化成如下:
(*ptr->vptr[offset])(ptr);
其中:
- ptr为对象地址
- vptr表示由编译器产生的指针,指向虚函数表。它被安插在每一个声明有(或者继承)一个或者多个虚函数的类对象中。事实上,其名称也会被
mangling,因为在一个复杂的派生类中,可能存在多个vptrs - offset为该函数在虚函数表中的索引,通常这个索引是按照类中虚函数的声明顺序来的
从上述我们可以看出,与普通的成员函数相比,编译器在调用虚函数的时候,多了一次通过虚函数表来获取函数地址的操作,其他的则与普通成员函数操作类似(包括将对象指针作为函数参数等操作)。
函数指针
就像常规指针指向一个数据的变量一样,函数指针是指向函数的变量。函数和数据都是存在于内存中,因此这些类型的指针实际上没有任何区别:它们都指向内存中某块地址。
class Base {
public:
Base() = default;
void Print() {
std::cout << "in Base::Print()" << std::endl;
}
void f() {
std::cout << "in Base::f()" << std::endl;
}
std::function<void()> fun;
};
class Derived : public Base {
public:
Derived() = default;
void Print() {
std::cout << "in Derived::Print()" << std::endl;
}
void f() {
std::cout << "in Derived::f()" << std::endl;
}
std::function<void()> fun;
};
int main() {
Base b;
Derived d;
b.fun = std::bind(&Derived::Print, d);
b.fun();
return 0;
}以函数指针来实现多态的方式还是比较简单的,其原理就是通过传入的函数指针回调来实现多态。
std::variant & std::visit
C++17中引入了std::variant和std::visit以实现多态。
std::variant
std::variant是C++17引入的变体类型,它最大的优势是提供了一种新的具有多态性的处理不同类型集合的方法。也就是说,它可以帮助我们处理不同类型的数据,并且不需要公共基类和指针。variant<X, Y, Z> 是可存放 X, Y, Z 这三种类型数据的变体类型。
我们可以将其理解为union的升级版,之所以称之为升级版,是因为union有如下缺点:
- 对象并不知道它们现在持有的值的类型
- 不能持有std::string等非平凡类型
- 不能被继承
既然称之为union的升级版,那么union的缺点其肯定不存在的,在此我们整理了下variant的特点:
- 可以获取当前类型
- 可以持有任何类型的值(不能是引用、C类型的数组指针、void等)
- 可以被继承
我们定义了一个如下类型变量v:
std::variant<int, std::string> v;
其中v是一个可存放 int, std::string这两种类型数据的variant对象,下面我们整理下std::variant<>提供的基本操作:
- v.index()返回变体类型v实际所存放数据的类型的下标。变体中第1种类型下标为0,第2种类型下标为1,以此类推
- std::holds_alternative(v)可查询变体类型v是否存放了T 类型的数据
- std::get(v)如果变体类型v存放的数据类型下标为I,那么返回所存放的数据,否则报错
- std::get_if(&v)如果变体类型v存放的数据类型下标为I,那么返回所存放数据的指针,否则返回空指针
- std::get(v)如果变体类型v存放的数据类型为T,那么返回所存放的数据,否则报错
- std::get_if(&v)如果变体类型v存放的数据类型为 T,那么返回所存放数据的指针,否则返回空指针
先看一段代码,以便于理解variant的使用:
#include <variant>
#include <string>
int main() {
std::variant<int, float> v, w;
v = 12; // (1)
int i = std::get<int>(v); // (2)
w = std::get<int>(v); // (3)
w = std::get<0>(v); // (4)
w = v; // (5)
// std::get<double>(v); // (6) ERROR
// std::get<3>(v); // (7) ERROR
try{
std::get<float>(w); // (8)
}
catch (std::bad_variant_access&) {}
return 0;
}在上述代码中:
- 定义了支持int和float的variant变量v和w
- 第一行(后面以(1)标记)将v赋值为12
- 第二行通过std::get来获取v的值(返回结果为12),并将其赋值给整数i
- 第三行通过std::get来获取v的值(返回结果为12),并将其赋值给w
- 第四行通过std::get来获取v的值(返回结果为12),并将其赋值给w
- 第五行将v赋值给w
- 第六行调用std::get(v)会报错,因为v不支持double类型
- 第七行std::get<3>(v)会报错,因为v只支持两个类型,即索引最大到1
- 第八行std::get(v)会出错,然后被try..cache捕获
如果使用get()方式来获取对应值的话,显得有点冗余,为了解决这个问题,C++17又引入了另外一个概念visit。
std::visit
std::visit的定义如下:
template <class Visitor, class... Variants>
constexpr visit( Visitor&& vis, Variants&&... vars );在上述定义中,vis是一个访问器,而vars则是传给访问器的参数列表。换句话说,std::visit能将所有变体类型参数所存放的数据作为参数传给函数。
std::visit访问器可以是函数对象、泛型lambda以及重载的lambda等。
使用函数对象作为访问器
使用函数对象作为访问器,我们需要将variant变量中支持的类型都在函数对象中进行实现,即对variant对象支持所有类型的operator()重载。假如一个variant对象中支持int和string两种对象,那么访问器的operator()重载就需要支持这俩种类型。
#include <iostream>
#include <string>
#include <variant>
struct Visitor {
void operator()(int n) const {
std::cout << "int: " << n << std::endl;
}
void operator()(const std::string &str) const {
std::cout << "string: " << str << std::endl;
}
};
int main() {
std::variant<int, std::string> v;
Visitor vst;
v = "with Visitor";
std::visit(vst, v);
return 0;
}输出如下:
with Visitor
需要注意的是,如果访问器访问一个在函数对象中不支持的类型operator()重载时候,会导致编译器错误。如果调用有歧义的话也会导致编译时错误。
使用泛型lambda作为访问器
最简单的使用访问器的方式是使用泛型lambda,它是一个可以处理任意类型的函数对象,如下代码所示:
int main() {
std::variant<int, std::string> v;
v = "with lambda";
std::visit([](const auto &val) {
std::cout << val << std::endl;}, v);
return 0;
}输出如下:
with lambda
使用重载的lambda作为访问器
通过使用函数对象和lambda的重载器(overloader) ,可以定义一系列lambda,其中最佳的匹配将会被用作访问器。与函数对象类似,需要增加variant所支持类型的operator()重载。代码如下:
template<typename...Func>
struct overload : Func... {
using Func::operator()...;
};
template<typename...Func> overload(Func...) -> overload<Func...>;
跟函数对象一样,我们需要对variant中所有的类型都实现对应的lambda函数,然后使用overload来访问variant。当前variant中所存储的类型overload不支持,则会编译失败。
具体使用方式如下:
int main() {
std::variant<int, std::string> v;
v = "with overload";
std::visit(overload{[](int n) {std::cout << n << std::endl;},
[](const std::string &s) {std::cout << s << std::endl;}
}, v);
return 0;
}代码输出如下:
with overload
实现
好了,到了这里,相信我们已经知道怎样使用variant和visit来实现多态了,话不多说,代码如下:
class Base {
public:
void Print() const {
std::cout << "in Base::Print" << std::endl;
}
};
class Derived : public Base {
public:
void Print() const {
std::cout << "in Derived::Print" << std::endl;
}
};如上代码所示,我们声明了一个基类Base 和一个派生类Derived,这俩类均有一个非virtual的成员函数Print()。在Print()函数为非virtual的情况下,将演示如何实现动态多态的功能。
接下来,就是本节最核心的部分,如下:
std::variant<Base, Derived> v;
因为需要实现多态,而多态是基于多种类型的,所以我们声明一个变量v,其类型可以是Base对象或者Derived对象。
然后使用函数对象(也可以使用lambda或者overload)来实现多态,本例中使用的是函数对象,代码如下:
struct CallPrint {
void operator()(const Base& b) { b.Print(); }
void operator()(const Derived& d) { d.Print(); }
};
int main() {
std::variant<Base, Derived> v = Derived();
std::visit(CallPrint{}, v);
v = Base();
std::visit(CallPrint{}, v);
return 0;
}输出如下:
in Derived::Print
in Base::Print性能对比
既然variant也可以实现运行时多态,那么我们就有必要将其与标准中的虚函数机制进行对比咯,本节从性能角度进行对比。
使用传统虚函数代码virtual.cc如下:
#include <sys/time.h>
#include <array>
#include <iostream>
#include <variant>
class Base {
public:
virtual void Print() const {
std::cout << "in Base::Print" << std::endl;
}
};
class Derived : public Base {
public:
void Print() const {
std::cout << "in Derived::Print" << std::endl;
}
};
int main() {
Base *b = new Derived;
for (int i = 0; i < 1000000; ++i) {
b->Print();
}
return 0;
}使用variant的代码variant.cc代码如下:
#include <sys/time.h>
#include <array>
#include <iostream>
#include <variant>
class Base {
public:
virtual void Print() const {
std::cout << "in Base::Print" << std::endl;
}
};
class Derived : public Base {
public:
void Print() const {
std::cout << "in Derived::Print" << std::endl;
}
};
int main() {
Base *b = new Derived;
for (int i = 0; i < 1000000; ++i) {
b->Print();
}
return 0;
}效果对比图如下:
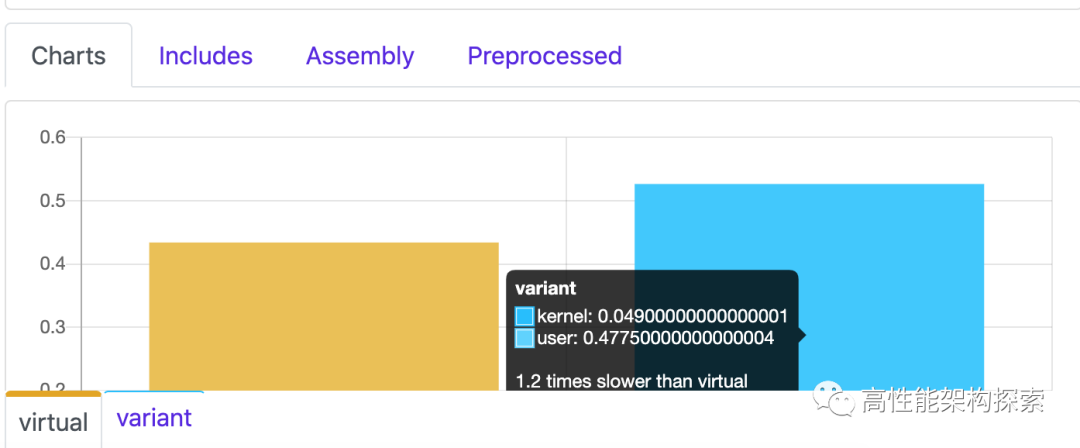
需要说明的是,本次测试结果仅针对上述代码。
在写本文的时候,查阅了相关资料,有些作者得出的结论是variant+visit性能优于传统的虚函数,而有些却是比传统的虚函数实现方式慢,所以具体采用哪种方式,需要依赖于具体的使用场景。
特点
在前面的内容中,我们讲了使用虚函数以及variant来实现多态的方案,既然二者都能实现多态,那么我们什么时候使用虚函数什么时候使用variant呢?这就需要从其优缺点来进行分析,使用者可以根据其特点进行选择,首先,总结下其优点:
- 值语义,无需动态分配
- 不需要基类,类之间可以不相关
- 相比于虚函数的重载(函数名、参数完全一致),variant只需要函数名一致即可,即不同的类里面可以函数名相同而参数不同,通过visit来进行对应的调用,从而实现多态
看完了前面的内容,其缺点也相对来说比较明显,如下:
- 需要在编译时预先了解所有类型
- 浪费内存,因为
std::variant大小是支持类型的最大大小。因此,如果一种类型是 10 字节,另一种是 100 字节,那么每个变体至少是 100 字节。因此,您可能会丢失 90 个字节 - 每个多态操作都需要实现一个对应的visit
结语
在本文中,我们研究了实现多态的三种方式,其中着重对虚函数机制和std::variant机制进行了分析。虚函数机制是语言标准支持的,而std::variant则是通过另外一种方式来实现多态。基于std::variant的多态是否比传统的虚函数机制性能更优?我也查了很多资料,也进行了测试,从二者性能测试结果来看各有胜负,换句话说没有明确的答案来说二者孰优孰劣,因为二者都有其优点和缺点。对于std::variant,其是值语义的,这就避免了虚函数机制所需要的堆上分配,进而提高系统性能。但是其预先需要了解所有可能的类型,在扩展方面不是很友好,而虚函数机制则没有此类问题。
好了,今天的文章就到这,我们下期见!
-- END --