详聊前端异常原理
导读
随着近年来前端监控体系建设日益完善,前端工程师对异常更加关注。业界关于 JS 异常介绍大多只谈了异常的捕获方法,对产生的原因和处理办法谈的较少。本文将详细的阐述异常原理,把笔者近 2 年在前端监控领域中与异常打交道的经验分享给大家。

异常定义
异常,Exception, 即预料之外的事件,在程序执行过程中发生,会打断正常的程序运行。

ECMA-262 白皮书 13 版中描述了 8 种异常
- SyntaxError:语法异常
- ReferenceError:引用异常
- RangeError:范围异常
- Error:异常基类
- InternalError:内部异常
- TypeError: 类型异常
- EvalError: Eval 方法异常
- URIError: URI 相关方法产生的异常
1. SyntaxError
在引擎执行代码之前,编译器需要对 js 进行编译,编辑阶段包括:词法分析,语法分析;如图:
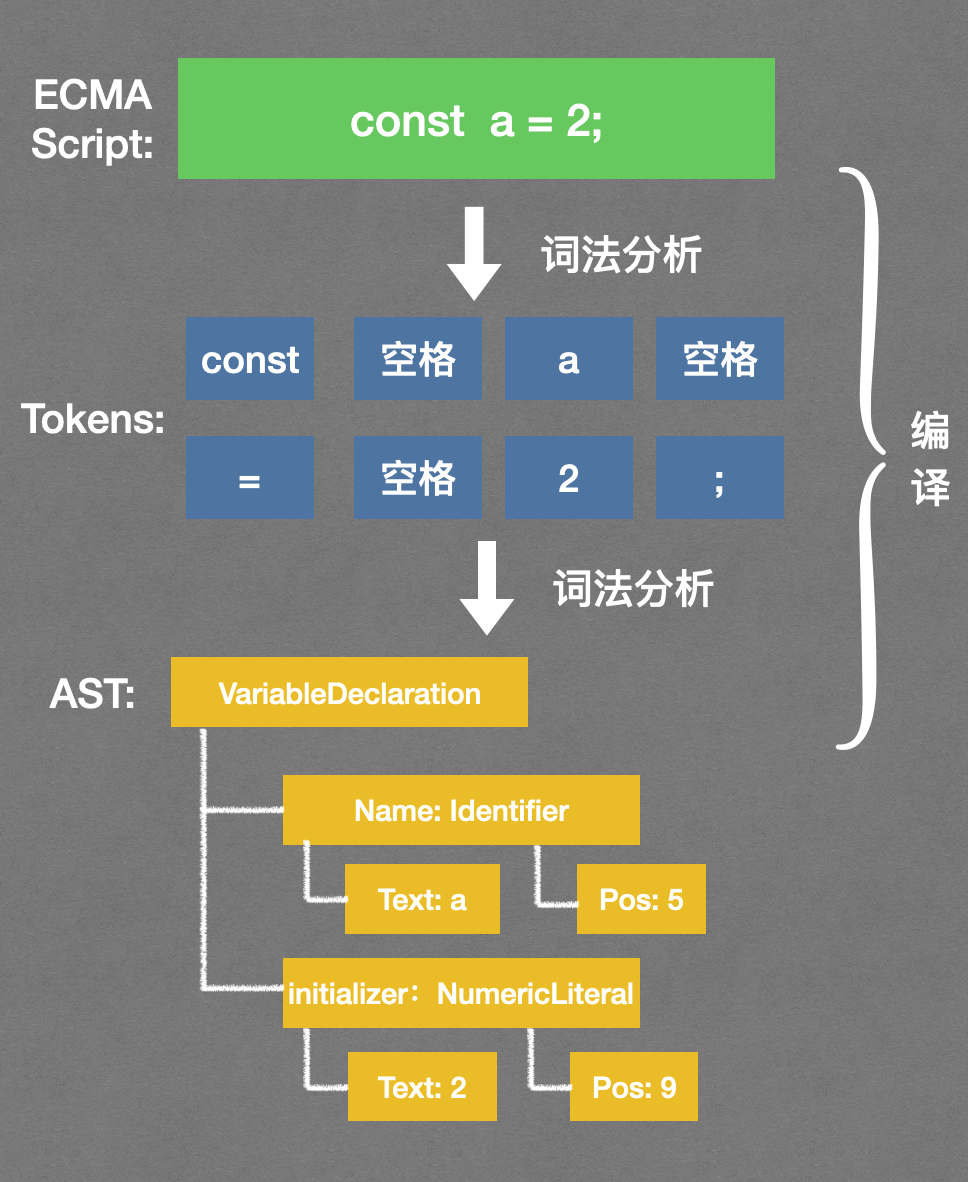
编译阶段发生的异常都是 SyntaxError,但 SyntaxError 不完全都发生于编译阶段;
const a = '3;
比如这行代码,缺少一个引号,就会发生: SyntaxError: Invalid or unexpected token.
其他常见的 SyntaxError:
- SyntaxError:Unexpected token u in JSON at position 0
- SyntaxError:Unexpected token '<'
- SyntaxError:Unexpected identifier
绝大部分 SyntaxError 都可以通过配置编辑器的校验工具,从而在开发阶段避免。
2. ReferenceError
引用异常,比较常见,类似于 Java 语言中最著名的空指针异常 (Null Pointer Exception,NPE).
- ReferenceError:$ is not defined
- ReferenceError:Can't find variable: $
上面举的 2 个引用异常例子其实是同一个异常,第一个是发生在 Android,第二个是在 iOS 下,异常对象的 message 有着兼容性的差别。
什么情况下会发生引用异常呢?
这里需要先提一下 LHS 查询和 RHS 查询。
比如 const a = 2; ,对于这一行代码,引擎会为变量 a 进行 LHS 查询。另外一个查找的类型叫作 RHS,即在赋值语句的 Left Hand Side 和 Right Hand Side。RHS 查询与简单地查找某个变量的值别无二致,而 LHS 查询则是试图找到变量的容器本身,即作用域。
LHS 和 RHS 的含义是 “赋值操作的左侧或右侧” 并不一定意味着就是 “=”。比如 console.log(a) 也会进行异常 RHS。我们再来看一个例子:
function foo(a) {
var b = a;
return a + b;
}
var c = foo(2);其中有 function foo;Var c;A = 2;Var b 这 4 次 LHS 和 4 次 RHS
为什么区分 LHS 和 RHS 是一件重要的事情?
因为在变量还没有声明的情况下,这两种查询的行为是不一样的。
如果 RHS 查询在所有嵌套的作用域中遍寻不到所需的变量,引擎就会抛出 ReferenceError。
如果 RHS 查询找到了一个变量,但是你尝试对这个变量的值进行不合理的操作,会抛出另外一种类型的异常,叫作 TypeError。
3. TypeError
TypeError 在对值进行不合理操作时会发生,比如试图对一个非函数类型的值进行函数调用,或者引用 null 或 undefined 类型的值中的属性,那么引擎会抛出这种类型的异常。比如:
TypeError:Cannot read property 'length' of undefined
这是个最常见的异常之一,在判断数组长度时可能发生。
可以做前置条件判空,比如:
if (obj) {
res = obj.name;
}也可以改写成逻辑与运算 && 的表达式写法
res = obj && obj.name;
但如果属性较多,这种方法就很难看了,可以使用可选链的写法,如下:
res = obj && obj.a && obj.a.b && obj.a.b.name
res = obj?.a?.b?.name;虽然条件判断、逻辑与判断、可选链判断都可以避免报错,但是还是有 2 个缺点:
- js 对于变量进行 Bool 强制转换的写法还是不够严谨,可能出现判断失误
- 这样写法在为空时本行代码不会报错,但是后续逻辑可能还会出问题;只是减少了异常,并没有办法解决这种情况。对于重要的逻辑代码建议使用 try/catch 来处理,必要时可以加上日志来分析。
4. RangeError
范围错误,比如:
new Array(-20)会导致RangeError: Invalid array length- 递归等消耗内存的程序会导致
RangeError: Maximum call stack size exceeded
递归可以使用循环 + 栈或尾递归的方式来优化
//普通递归
const sum = (n) => {
if (n <= 1) return n;
return n + sum(n-1)
}
//尾递归
const sum = (n, prevSum = 0) => {
if (n <= 1) return n + prevSum;
return sum(n-1, n + prevSum)
}尾递归和一般的递归不同在对内存的占用,普通递归创建 stack 累积而后计算收缩,尾递归只会占用恒量的内存。当编译器检测到一个函数调用是尾递归的时候,它就覆盖当前的活动记录而不是在栈中去创建一个新的。
5. Error 与自定义异常
Error 是所有错误的基类,其他错误类型继承该类型。所有错误类型都共享相同的属性。
Error.prototype.message错误消息。对于用户创建的 Error 对象,这是构造函数的第一个参数提供的字符串。Error.prototype.name错误名称。这是由构造函数决定的。Error.prototype.stack错误堆栈
通过继承 Error 也可以创建自定义的错误类型。创建自定义错误类型时,需要提供 name 属性和 message 属性.
class MyError extends Error {
constructor(message) {
super();
this.name = 'MyError'
this.message = message }
}大多流行框架会封装一些自定义异常,比如 Axios 和 React.
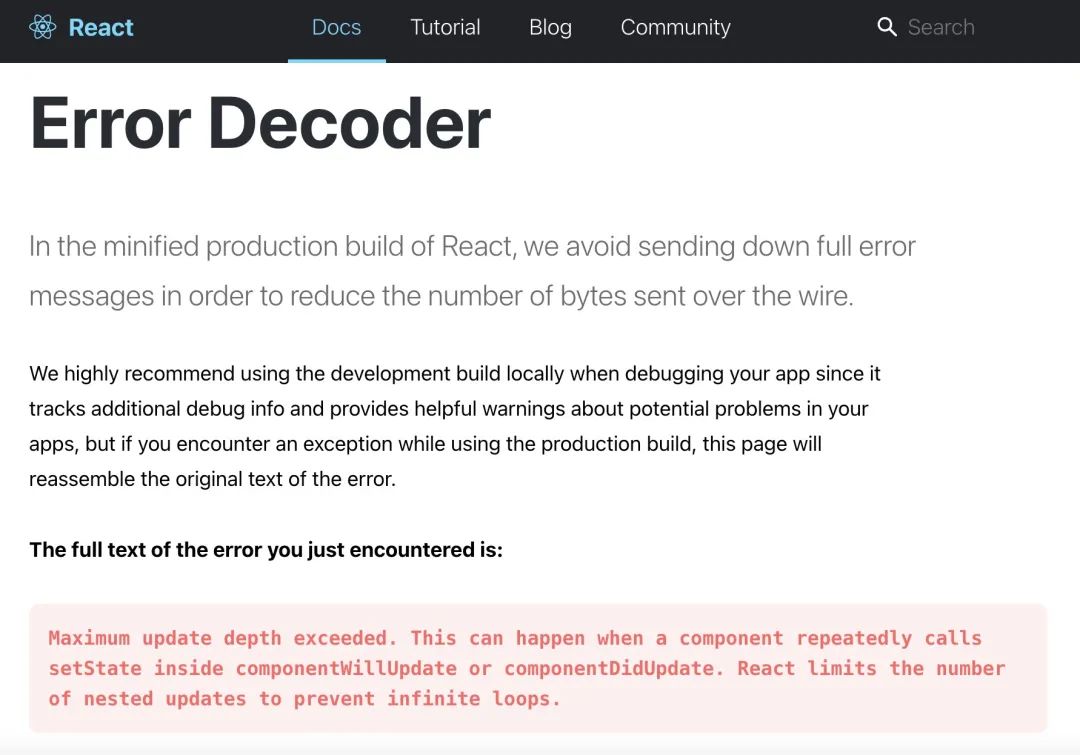
React 在 ErrorDecoder 模块中对自定义错误做了介绍。每个错误都有 ID,比如 ID:185 错误是:在 componentDidUpdate 函数中调用了 this.setState() 方法,导致 componentDidUpdate 陷入死循环。在报错后会输出带有异常介绍链接的日志.
https://reactjs.org/docs/error-decoder.html/?invariant = 异常 ID.
利用链接打开可视化链接,如下:
6. Error: Script Error.
它是 Error 类型中最常见的一种;由于没有具体异常堆栈和代码行列号,成为可最神秘的异常之一。
由于浏览器基于安全考虑效避免敏感信息无意中被第三方 (不受控制的) 脚本捕获到,浏览器只允许同域下的脚本捕获具体的错误信息。
但大部分的 JS 文件都存放在 CDN 上面,跟页面的域名不一致。做异常监控只能捕获 Error: Script Error. 无法捕获堆栈和准确的信息。2 步解决:
1、给 script 标签增加 crossorigin 属性,让浏览器允许页面请求资源。
<scrpit src="http://def.com/demo.js" crossorigin="anonymous"></script>
这样请求头 sec-fetch-mode 值就会变成 cors, 默认是 no-cors.
但有些浏览器还不兼容此方法,加上 crossorigin 后仍不能发出 sec-fetch-mode:cors 请求
2、给静态资源服务器增加响应头允许跨域标记。
Access-Control-Allow-Origin: *.58.com
大部分主流 CDN 默认添加了 Access-Control-Allow-Origin 属性。
整个过程可以参考以下流程图:
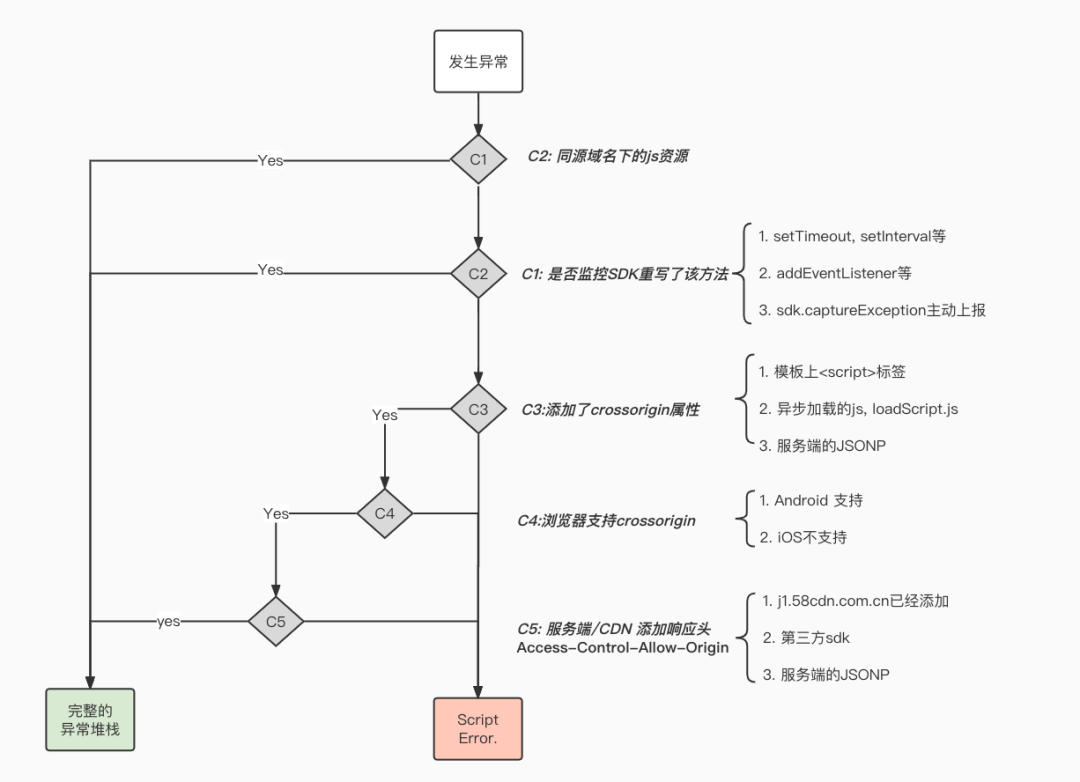
在加上跨域请求头、响应头后可能还有大量的 ScriptError,就要考虑以下几种情况
- 通过 append Script 标签异步加载 JS
- JSONP 请求
- 第三方 SDK
7. 其他异常
InternalError
这种异常极为少见,在 JS 引擎内部发生,示例场景通常为某些成分过大,例如:
- “too many switch cases”(过多 case 子句);
- “too many parentheses in regular expression”(正则表达式中括号过多);
- “array initializer too large”(数组初始化器过大);
EvalError
在 eval() 方法执行过程中抛出 EvalError 异常。
根据 Ecma2018 版以后,此异常不再会被抛出,但是 EvalError 对象仍然保持兼容性。
URIError
用来表示以一种错误的方式使用全局 URI 处理函数而产生的错误.
decodeURI, decodeURIComponent, encodeURI, encodeURIComponent 这四个方法会产生这种异常;
比如执行 decodeURI('%%') 的异常:Uncaught URIError: URI malformed
异常处理
ECMA-262 第 3 版新增了 try/catch 语句,作为在 JavaScript 中处理异常的一种方式。基本的语法如下所示,跟 Java 中的 try/catch 语句一样。
1. finally
finally 在 try-catch 语句中是可选的,finally 子句一经使用,其代码无论如何都会执行。
function a () {
try {
return '约会'
} catch (e) {
return '约会失败'
} finally {
return '睡觉';
}
}
console.log('函数结果:', a()) // '睡觉'上述代码的结果是 ' 睡觉 ',finally 会阻止 return 语句的终止.
2. throw
throw new Error('Boom');
什么时候应该手动抛出异常呢?
一个指导原则就是可预测程序在某种情况下不能正确进行下去,需要告诉调用者异常的详细信息,而不仅仅是异常内容本身。比如上文提到的 React 自定义异常;
一个健壮的函数,会对参数进行类型有效性判断;通常在实参不合理时,为了避免报错阻断程序运行,开发者会通过默认值,return 空等方式处理。
这种方式虽然没有报错,但是程序的结果未必符合预期,默认值设计不合理会造成语义化误解;另外,也可能无法避免后续的代码报错;
3. 断言
上文提到可预测,很容易联想到 Node 中的断言 assert,如果表达式不符合预期,就抛出一个错误。
assert 方法接受两个参数,当第一个参数对应的布尔值为 true 时,不会有任何提示,返回 undefined。当第一个参数对应的布尔值为 false 时,会抛出一个错误,该错误的提示信息就是第二个参数设定的字符串。
var assert = require('assert');
function add (a, b) {
return a + b;
}
var expected = add(1,1);
assert( expected === 2, '预期1加1等于2');通常在 TDD 开发模式中,会用于编写测试用例;
不过 ECMA 还没有类似的设计,感兴趣可以简单封装一个 assert 方法。浏览器环境中的 console 对象有类似的 assert 方法。
4. 异步中的异常
非同步的代码,在事件循环中执行的,就无法通过 try catch 到。
主要注意的是,Promise 的 catch 方法用于处理 rejected 状态,而非处理异常。Rejected 状态未处理的话会触发 Uncaught Rejection. 后者可以通过如下方式进行统一的监听。
window.onunhandledrejection = (event) => {
console.warn(`REJECTION: ${event.reason}`);
};tips: await 这种 Promise 的同步写法,通常会被开发者忽略 rejected 的处理,可以用 try catch 来捕获。
5. 异常监控
服务端通常会通过服务器的日志进行异常监控,比如观察单台服务器的日志输出,或 kibana 可视化查询。 前端异常监控与之最大的不同,就是需要把客户端发生的异常数据通过网络再收集起来。
可以使用下面几个方式来收集数据:
- window.onerror 捕获语法异常
- 可以重写 setTimeout、setInterval 等异步方法,用同步的写法包裹 try 来捕获异步函数中发生的错误
- window.addEventListener (‘unhandledrejection’,・・・); 捕获未处理的异步 reject
- window.addEventListener (‘error’, …) 捕获资源异常
- 重写 fetch, XMLHttpRequest 来捕获接口状态
总结
本文详细讲解了 ECMA 中 8 种异常的产生原理,涉及了 LHS&RHS、递归优化、ScriptError、finally、Promise 等知识点,希望在处理异常的工作中能给你带来帮助。
参考
- ecma-262: https://www.ecma-international.org/publications-and-standards/standards/ecma-262/
- ES6th 白皮书: https://262.ecma-international.org/6.0
- React Error Decoder: https://reactjs.org/docs/error-decoder.html/?invariant=1
- 《Js 高级程序设计 第四版》
- 《你不知道的 JS》