React官网这么快,得益于Gatsby这个库
当我们打开 React 官网时,会发现从浏览器上输入url 到页面首屏完全展示这一过程所花的时间极短,而且在页面中点击链接切换路由的操作非常顺滑,几乎页面可以达到“秒切”的效果,根本不会有卡顿等待的情况发生,于是带着“react官网到底是怎么做的”疑问开始了本次探索,发现其主要用了以下的优化手段
静态站点生成 SSG
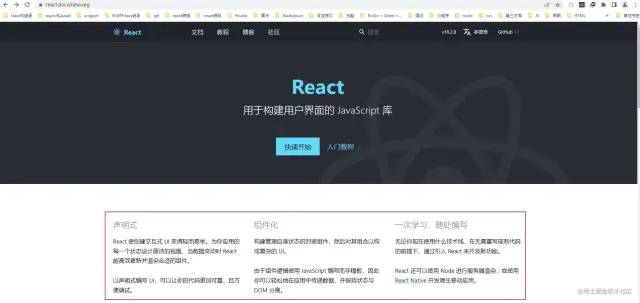
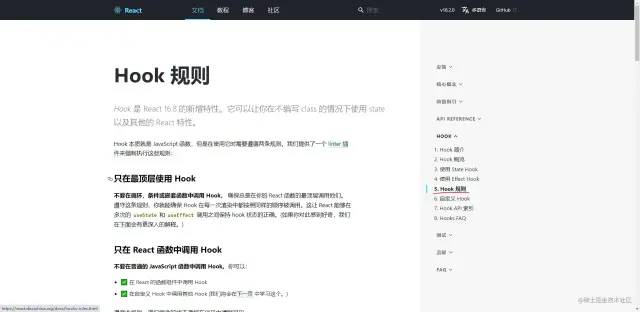
下面是react官方中文文档首页的截图,大家注意下方的红色区域,后面会作为推断的一个理由
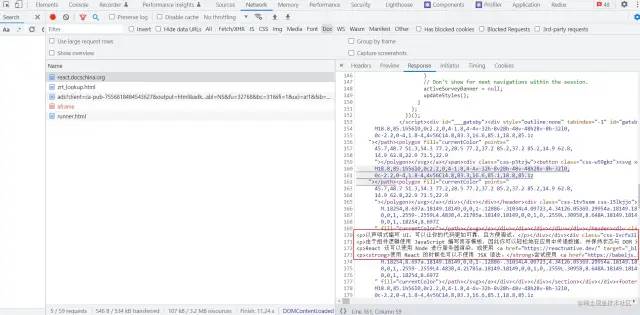
当我们打开控制台之后,点击network并选择 DOC文档请求,就会发现有一个请求路径为https://zh-hans.reactjs.org/ 的GET请求,响应结果为一个 html文档,里面刚好能找到对应上图中红色区域文字的文本,这也就佐证了这个html文档所对应的页面就是react官网首页,而这种渲染页面的方式只有两种,一种是服务端渲染 SSR,还有一种是静态站点生成 SSG
很多人总是分不清客户端渲染CSR、服务端渲染SSR还有静态站点生成SSG,下面我们简单介绍一下它们各自的特点,看完之后相信你就能清晰的感受到它们的区别所在了
页面的渲染流程
在开始之前,我们先来回顾一下页面最基本的渲染流程是怎么样的?
- 浏览器通过请求得到一个
HTML文本 - 渲染进程解析
HTML文本,构建DOM树 - 浏览器解析
HTML的同时,如果遇到内联样式或者样本样式,则下载并构建样式规则(stytle rules)。若遇到Javascript脚本,则会下载并执行脚本 DOM树和样式规则构建完成之后,渲染进程将两者合并成渲染树(render tree)- 渲染进程开始对渲染树进行布局,生成布局树(
layout tree) - 渲染进程对布局树进行绘制,生成绘制记录
- 渲染进程对布局树进行分层,分别栅格化每一层并得到合成帧
- 渲染进程将合成帧发送给
GPU进程将图像绘制到页面中
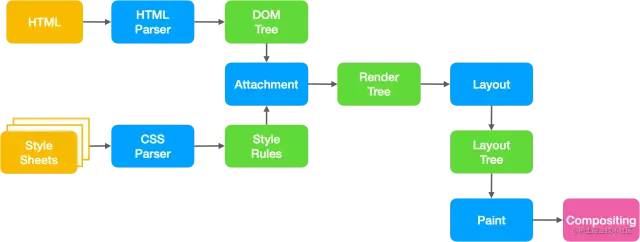
可以看到,页面的渲染其实就是浏览器将HTML文本转化为页面帧的过程,下面我们再来看看刚刚提到的技术:
客户端渲染 CSR
如今我们大部分 WEB 应用都是使用 JavaScript 框架(Vue、React、Angular)进行页面渲染的,页面中的大部分DOM元素都是通过Javascript插入的。也就是说,在执行 JavaScript 脚本之前,HTML 页面已经开始解析并且构建 DOM 树了,JavaScript 脚本只是动态的改变 DOM 树的结构,使得页面成为希望成为的样子,这种渲染方式叫动态渲染,也就是平时我们所称的客户端渲染 CSR(client side render)
下面代码为浏览器请求 react 编写的单页面应用网页时响应回的HTML文档,其实它只是一个空壳,里面并没有具体的文本内容,需要执行 JavaScript 脚本之后才会渲染我们真正想要的页面
<!doctype html>
<html lang="en">
<head>
<meta charset="utf-8" />
<link rel="icon" href="/favicon.ico" />
<meta name="viewport" content="width=device-width,initial-scale=1" />
<meta name="theme-color" content="#000000" />
<meta name="description" content="Web site created using create-react-app" />
<link rel="apple-touch-icon" href="/logo192.png" />
<link rel="manifest" href="/manifest.json" />
<title>Jira任务管理系统</title>
<script
type="text/javascript">!function (n) { if ("/" === n.search[1]) { var a = n.search.slice(1).split("&").map((function (n) { return n.replace(/~and~/g, "&") })).join("?"); window.history.replaceState(null, null, n.pathname.slice(0, -1) + a + n.hash) } }(window.location)</script>
<link href="/static/css/2.4ddacf8e.chunk.css" rel="stylesheet">
<link href="/static/css/main.cecc54dc.chunk.css" rel="stylesheet">
</head>
<body><noscript>You need to enable JavaScript to run this app.</noscript>
<div id="root"></div>
<script>!function (e) { function r(r) { for (var n, a, i = r[0], c = r[1], f = r[2], s = 0, p = []; s < i.length; s++)a = i[s], Object.prototype.hasOwnProperty.call(o, a) && o[a] && p.push(o[a][0]), o[a] = 0; for (n in c) Object.prototype.hasOwnProperty.call(c, n) && (e[n] = c[n]); for (l && l(r); p.length;)p.shift()(); return u.push.apply(u, f || []), t() } function t() { for (var e, r = 0; r < u.length; r++) { for (var t = u[r], n = !0, i = 1; i < t.length; i++) { var c = t[i]; 0 !== o[c] && (n = !1) } n && (u.splice(r--, 1), e = a(a.s = t[0])) } return e } var n = {}, o = { 1: 0 }, u = []; function a(r) { if (n[r]) return n[r].exports; var t = n[r] = { i: r, l: !1, exports: {} }; return e[r].call(t.exports, t, t.exports, a), t.l = !0, t.exports } a.e = function (e) { var r = [], t = o[e]; if (0 !== t) if (t) r.push(t[2]); else { var n = new Promise((function (r, n) { t = o[e] = [r, n] })); r.push(t[2] = n); var u, i = document.createElement("script"); i.charset = "utf-8", i.timeout = 120, a.nc && i.setAttribute("nonce", a.nc), i.src = function (e) { return a.p + "static/js/" + ({}[e] || e) + "." + { 3: "20af26c9", 4: "b947f395", 5: "ced9b269", 6: "5785ecf8" }[e] + ".chunk.js" }(e); var c = new Error; u = function (r) { i.onerror = i.onload = null, clearTimeout(f); var t = o[e]; if (0 !== t) { if (t) { var n = r && ("load" === r.type ? "missing" : r.type), u = r && r.target && r.target.src; c.message = "Loading chunk " + e + " failed.\n(" + n + ": " + u + ")", c.name = "ChunkLoadError", c.type = n, c.request = u, t[1](c) } o[e] = void 0 } }; var f = setTimeout((function () { u({ type: "timeout", target: i }) }), 12e4); i.onerror = i.onload = u, document.head.appendChild(i) } return Promise.all(r) }, a.m = e, a.c = n, a.d = function (e, r, t) { a.o(e, r) || Object.defineProperty(e, r, { enumerable: !0, get: t }) }, a.r = function (e) { "undefined" != typeof Symbol && Symbol.toStringTag && Object.defineProperty(e, Symbol.toStringTag, { value: "Module" }), Object.defineProperty(e, "__esModule", { value: !0 }) }, a.t = function (e, r) { if (1 & r && (e = a(e)), 8 & r) return e; if (4 & r && "object" == typeof e && e && e.__esModule) return e; var t = Object.create(null); if (a.r(t), Object.defineProperty(t, "default", { enumerable: !0, value: e }), 2 & r && "string" != typeof e) for (var n in e) a.d(t, n, function (r) { return e[r] }.bind(null, n)); return t }, a.n = function (e) { var r = e && e.__esModule ? function () { return e.default } : function () { return e }; return a.d(r, "a", r), r }, a.o = function (e, r) { return Object.prototype.hasOwnProperty.call(e, r) }, a.p = "/", a.oe = function (e) { throw console.error(e), e }; var i = this.webpackJsonpjira = this.webpackJsonpjira || [], c = i.push.bind(i); i.push = r, i = i.slice(); for (var f = 0; f < i.length; f++)r(i[f]); var l = c; t() }([])</script>
<script src="/static/js/2.2b45c055.chunk.js"></script>
<script src="/static/js/main.3224dcfd.chunk.js"></script>
</body>
</html>
复制代码服务端渲染 SSR
顾名思义,服务端渲染就是在浏览器请求页面 URL 的时候,服务端将我们需要的 HTML 文本组装好,并返回给浏览器,这个 HTML 文本被浏览器解析之后,不需要经过 JavaScript 脚本的下载过程,即可直接构建出我们所希望的 DOM 树并展示到页面中。这个服务端组装HTML的过程就叫做服务端渲染 SSR
下面是服务端渲染时返回的 HTML 文档,由于代码量实在是太多,所以只保留了具有象征意义的部分代码,但不难发现,服务端渲染返回的HTML文档中具有页面的核心文本
<!DOCTYPE html>
<html lang="zh-hans">
<head>
<link rel="preload" href="https://unpkg.com/docsearch.js@2.4.1/dist/cdn/docsearch.min.js" as="script" />
<meta name="generator" content="Gatsby 2.24.63" />
<style data-href="/styles.dc271aeba0722d3e3461.css">
/*! normalize.css v8.0.1 | MIT License | github.com/necolas/normalize.css */
html {
line-height: 1.15;
-webkit-text-size-adjust: 100%
}
/* ....many CSS style */
</style>
</head>
<body>
<script>
(function () {
/*
BE CAREFUL!
This code is not compiled by our transforms
so it needs to stay compatible with older browsers.
*/
var activeSurveyBanner = null;
var socialBanner = null;
var snoozeStartDate = null;
var today = new Date();
function addTimes(date, days) {
var time = new Date(date);
time.setDate(time.getDate() + days);
return time;
}
// ...many js code
})();
</script>
<div id="___gatsby">
<!-- ...many html dom -->
<div class="css-1vcfx3l">
<h3 class="css-1qu2cfp">一次学习,跨平台编写</h3>
<div>
<p>无论你现在使用什么技术栈,在无需重写现有代码的前提下,通过引入 React 来开发新功能。</p>
<p>React 还可以使用 Node 进行服务器渲染,或使用 <a href="https://reactnative.dev/" target="_blank"
rel="nofollow noopener noreferrer">React Native</a> 开发原生移动应用。</p>
</div>
</div>
<!-- ...many html dom -->
</div>
</body>
</html>
复制代码静态站点生成 SSG
这也就是React官网所用到的技术,与SSR的相同之处就是对应的服务端同样是将已经组合好的HTML文档直接返回给客户端,所以客户端依旧不需要下载Javascript文件就能渲染出整个页面,那不同之处又有哪些呢?
使用了SSG技术搭建出的网站,每个页面对应的HTML文档在项目build打包构建时就已经生成好了,用户请求的时候服务端不需要再发送其它请求和进行二次组装,直接将该HTML文档响应给客户端即可,客户端与服务端之间的通信也就变得更加简单
但读到这里很容易会发现它有几个致命的弱点:
HTML文档既然是在项目打包时就已经生成好了,那么所有用户看到的都只能是同一个页面,就像是一个静态网站一样,这也是这项技术的关键字眼——静态- 每次更改内容时都需要构建和部署应用程序,所以其具有很强的局限性,不适合制作内容经常会变换的网站
但每项技术的出现都有其对应的使用场景,我们不能因为某项技术的某个缺点就否定它,也不能因为某项技术的某个优点就滥用它! 该技术还是有部分应用场景的,如果您想要搭建一个充满静态内容的网站,比如个人博客、项目使用文档等Web应用程序,使用SSG再适合不过了,使用过后我相信你一定能感受到这项技术的强大之处!
问题解答
现在我们就可以回答为什么react官网要使用SSG这项技术去做了?
因为相对于客户端渲染,服务端渲染和静态网点生成在浏览器请求URL之后得到的是一个带有数据的HTML文本,并不是一个HTML空壳。浏览器只需要解析HTML,直接构建DOM树就可以了。而客户端渲染,需要先得到一个空的HTML页面,这个时候页面已经进入白屏,之后还需要经过加载并执行 JavaScript、请求后端服务器获取数据、JavaScript 渲染页面几个过程才可以看到最后的页面。特别是在复杂应用中,由于需要加载 JavaScript脚本,越是复杂的应用,需要加载的 JavaScript脚本就越多、越大,这会导致应用的首屏加载时间非常长,从而降低了体验感
至于SSR与SSG的选取,我们要从应用场景出发,到底是用户每次请求都在服务端重新组装一个HTML文档?还是在项目构建的时候就生成一个唯一的HTML文档呢?
React团队成员在开发官网的时候肯定早就想到了这个问题,既然是官网,那肯定没有权限之分,所有进入到该网站的人看到的内容应该是一样的才对,那每次请求都在服务端组装一个一模一样的HTML有什么意义呢?为什么不提前在服务端渲染好,然后发给每个人,这样N次渲染就变成了1次渲染,大大减少了客户端与服务端通信的时间,进而提升了用户体验
总结
无论是哪种渲染方式,一开始都是要请求一个 HTML 文本,但是区别就在于这个文本是否已经被服务端组装好了
- 客户端渲染还需要去下载和执行额外的
Javascript脚本之后才能得到我们想要的页面效果,所以速度会比服务端渲染慢很多 - 服务端渲染得到的
HTML文档就已经组合好了对应的文本,浏览器请求到之后直接解析渲染出来即可,不需要再去下载和执行额外的Javasript脚本,所以速度会比客户端渲染快很多 - 对于一些内容不经常变化的网站,我们甚至可以在服务端渲染的基础上予以改进,将每次请求服务端都渲染一次
HTML文档改成总共就只渲染一次,这就是静态站点生成技术
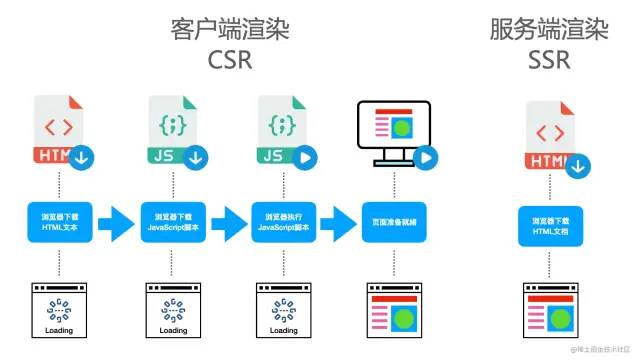
下图是客户端渲染和服务端渲染的流程图:
一些预加载/预处理资源的方式
研究完首屏渲染之后,我们再来研究一下路由跳转后内容的切换。经常看 react 文档的朋友可能早就发现了,其路由跳转无比丝滑,感觉就像是一个静态页面一样,完全没有发送网络请求的痕迹,比如我现在处在hook 简介这一个板块,当我点击 hook 规则 目录之后

发现页面瞬间秒切了过去,内容也瞬间展现在了出来,没有一丝卡顿,用户体验直接爆炸,这到底是怎么做到的呢?
下面我们就来一点一点分析它的每个优化手段
preload
在当前页面中,你可以指定可能或很快就需要的资源在其页面生命周期的早期——浏览器的主渲染机制介入前就进行预加载,这可以让对应的资源更早的得到加载并使用,也更不易阻塞页面的初步渲染,进而提升性能
关键字 preload 作为元素 <link> 的属性 rel的值,表示用户十分有可能需要在当前浏览中加载目标资源,所以浏览器必须预先获取和缓存对应资源 。下面我们来看一个示例:
<link as="script" rel="preload" href="/webpack-runtime-732352b70a6d0733ac95.js">
复制代码这样做的好处就是让在当前页面中可能被访问到的资源提前加载但并不阻塞页面的初步渲染,进而提升性能
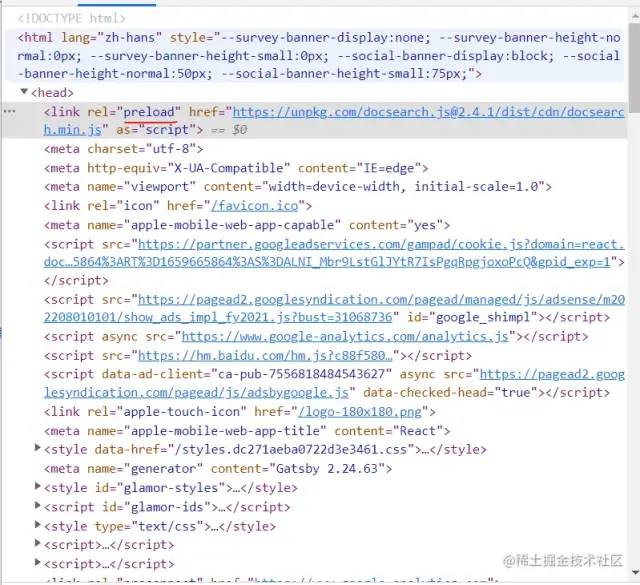
下面是 react文档中对 preload关键字的使用,告诉浏览器等等可能需要这个资源,希望能够尽早下载下来
可以预加载的资源有很多,现在浏览器支持的主要有:
- audio:音频文件,通常用于 audio 标签
- document: 旨在由 frame 或嵌入的 HTML 文档
- embed:要嵌入到 embed 元素中的资源
- fetch:要通过 fetch 或 XHR 请求访问的资源,例如 ArrayBuffer 或 JSON 文件
- font: 字体文件
- image:图像文件
- object:要嵌入到 object 元素中的资源
- script: JavaScript 文件
- style: CSS 样式表
- track: WebVTT 文件
- worker:一个 JavaScript 网络工作者或共享工作者
- video:视频文件,通常用于 video 标签
注意:使用
preload作为link标签rel属性的属性值的话一定要记得在标签上添加as属性,其属性值就是要预加载的内容类型
preconnect
元素属性的关键字preconnect是提示浏览器用户可能需要来自目标域名的资源,因此浏览器可以通过抢先启动与该域名的连接来改善用户体验 —— MDN
下面来看一个用法示例:
<link rel="preconnect" href="https://www.google-analytics.com">
复制代码下面是 react官方文档中的使用:
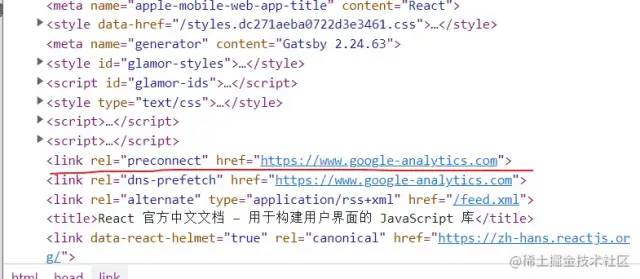
简单来说就是提前告诉浏览器,在后面的js代码中可能会去请求这个域名下对应的资源,你可以先去把网络连接建立好,到时候发送对应请求时也就更加快速
dns-prefetch
DNS-prefetch (DNS 预获取) 是尝试在请求资源之前解析域名。这可能是后面要加载的文件,也可能是用户尝试打开的链接目标 —— MDN
那我们为什么要进行域名预解析呢?这里面其实涉及了一些网络请求的东西,下面简单介绍一下:
当浏览器从(第三方)服务器请求资源时,必须先将该跨域域名解析为 IP 地址,然后浏览器才能发出请求。此过程称为 DNS 解析。DNS 缓存可以帮助减少此延迟,而 DNS 解析可以导致请求增加明显的延迟。对于打开了与许多第三方的连接的网站,此延迟可能会大大降低加载性能。预解析域名就是为了在真正发请求的时候减少延迟,从而在一定程度上提高性能
用法示例:
<link rel="dns-prefetch" href="https://www.google-analytics.com">
复制代码下面是 react官方文档中的使用:
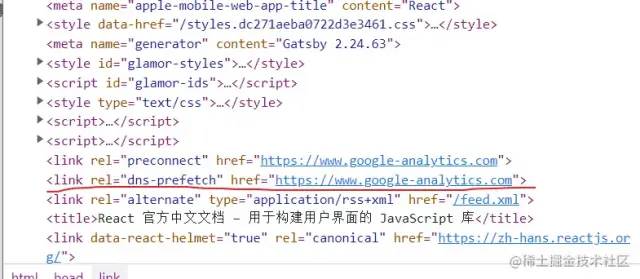
通俗点来说,dns-prefetch 的作用就是告诉浏览器在给第三方服务器发送请求之前去把指定域名的解析工作给做了,这个优化方法一般会和上面的preconnect一起使用,这些都是性能优化的一些手段,我们也可以在自己项目中合适的地方来使用
prefetch
关键字 prefetch 作为元素 的属性 rel 的值,是为了提示浏览器,用户未来的浏览有可能需要加载目标资源,所以浏览器会事先获取和缓存对应资源,优化用户体验 ——MDN
上面的解释已经很通俗易懂了,就是告诉浏览器用户未来可能需要这些资源,这样浏览器可以提前获取这些资源,等到用户真正需要使用这些资源的时候一般都已经加载好了,内容展示就会十分的流畅
用法示例:
<link rel="prefetch" href="/page-data/docs/getting-started.html/page-data.json" crossorigin="anonymous" as="fetch">
复制代码可以看到 react文档在项目中大量使用到了 prefetch来优化项目

那么我们在什么情况下使用 prefetch才比较合适呢?
像 react文档一样,当你的页面中具有可能跳转到其他页面的路由链接时,就可以使用prefetch 预请求对应页面的资源了
但如果一个页面中这样的路由链接很多呢?那岂不是要大量的发送网络请求,虽然现在流量很便宜,但你也不能那么玩啊!(doge)
React 当然考虑到了这个问题,因为在它的文档中包含有大量的路由链接,不可能全部都发一遍请求,这样反而不利于性能优化,那react是怎么做的呢?
通过监听 Link元素,当其出现到可见区域时动态插入带有prefetch属性值的link标签到HTML文档中,从而去预加载对应路由页面的一些资源,这样当用户点击路由链接跳转过去时由于资源已经请求好所以页面加载会特别快
举个例子,还没有点击下图中划红线的目录时,由于其子目录没有暴露到视图窗口中,所以页面中并没有对应的标签,而当点击了该目录后,其子目录就会展示在视图窗口中,react会自动将暴露出来的路由所对应的数据通过prefetch提前请求过来,这样当用户点击某个子目录的时候,由于已经有了对应的数据,直接获取内容进行展示即可。用这样的方法,我们感受到的速度能不快吗?
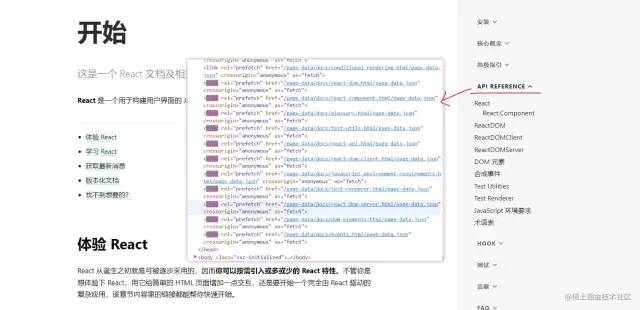
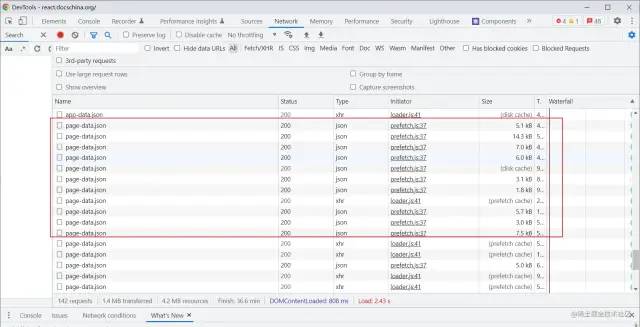
下面是我们在network查看到的结果
补充
react官网其实并不完全是由react这个框架进行开发的,能做上述所说的那么多性能优化其实得益于Gatsby这个库
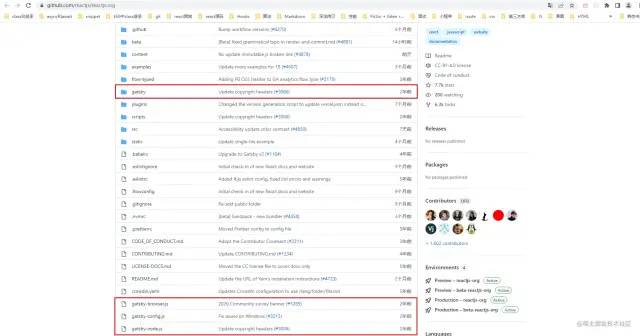
Gatsby 是一个性能很好,开发很自由的,基于 React 和 GraphQL 来构建网站的库。一般用于构建静态网站,比如博客、企业官网等,或者说静态内容相对比较多的网站
它在打包的时候就生成了所有页面对应的 HTML文件以及数据文件等,这样当你访问某个页面时,服务端可以直接返回HTML ,另外一方面当页面中有使用 Link 时,会提前加载这个页面所对应的数据,这样点击跳转后页面加载速度就会很快。所以上文中所说的优化手段,其实是 Gatsby帮助实现的,有兴趣的朋友可以去它的官网了解更多相关知识
- 至于这个监听
Link元素是怎么实现的呢?
具体实现是使用 Intersection Observer ,相关介绍见 IntersectionObserver API 使用教程 - 阮一峰的网络日志 ,有写到图片懒加载和无限滚动也可以使用这个 API去实现,只不过现在有个别浏览器还没有支持,所以在兼容性上存在一些阻拦,导致这个 Api现在还没有被普及
参考
本篇文章参考了以下几篇文章并结合上了自己的理解,下面文章个人觉得质量真的很高,大家也可以去看看。另外大家在文章中如果发现问题可以在评论区中指出,大家共同进步~