信息流场景下的AIGC实践
导读
以QQ浏览器的信息流场景为例,每个内容都展示有标题和封面图。这是用户在决定是否点击查看详细内容时的关键参考因素,对于用户来说,标题和封面图是否命中用户兴趣极大影响用户的消费行为。所以,吸引人的标题和封面图无论是对创作者、平台方还是广告商来说都非常重要。 今天的介绍会围绕下面两点展开:
- 个性化的标题生成
- 自动封面图合成
01 个性化的标题生成
个性化的标题生成,指使用用户内容以及个性化的信息生成针对不同用户或者不同应用场景的标题。
主要使用场景有以下三种:
- 推荐场景:在推荐系统中,不同用户或群体可能对相同内容有不同的兴趣。因此,在推荐场景下,个性化标题生成需要根据用户的兴趣和喜好为他们生成有针对性的标题。这可以提高用户的阅读兴趣,增加点击率,从而提升整个推荐系统的效果。
- 搜索场景:在搜索引擎中,基于用户的搜索查询(query)生成与其相关的标题是至关重要的。个性化标题生成应该能够捕捉到用户的搜索意图,并将其结合文章内容生成符合用户需求的标题。这样可以帮助用户快速找到满足他们需求的信息,提升搜索体验。
- 创作者平台:在创作者平台上,作者通常会有自己独特的写作风格。个性化标题生成需要模仿作者历史的标题创作风格,为他们生成风格一致的标题。这可以帮助作者保持个人品牌形象的连贯性,同时也能让读者更容易识别出作者的作品。
主要面临的问题难点:
- 场景表示:用户兴趣、搜索 query、作者风格等等显式或者隐式的信息如何表示?
- 交互设计:场景表示获取之后如何和文章或者标题交互生成个性化的标题?
1. 基于关键词的标题生成
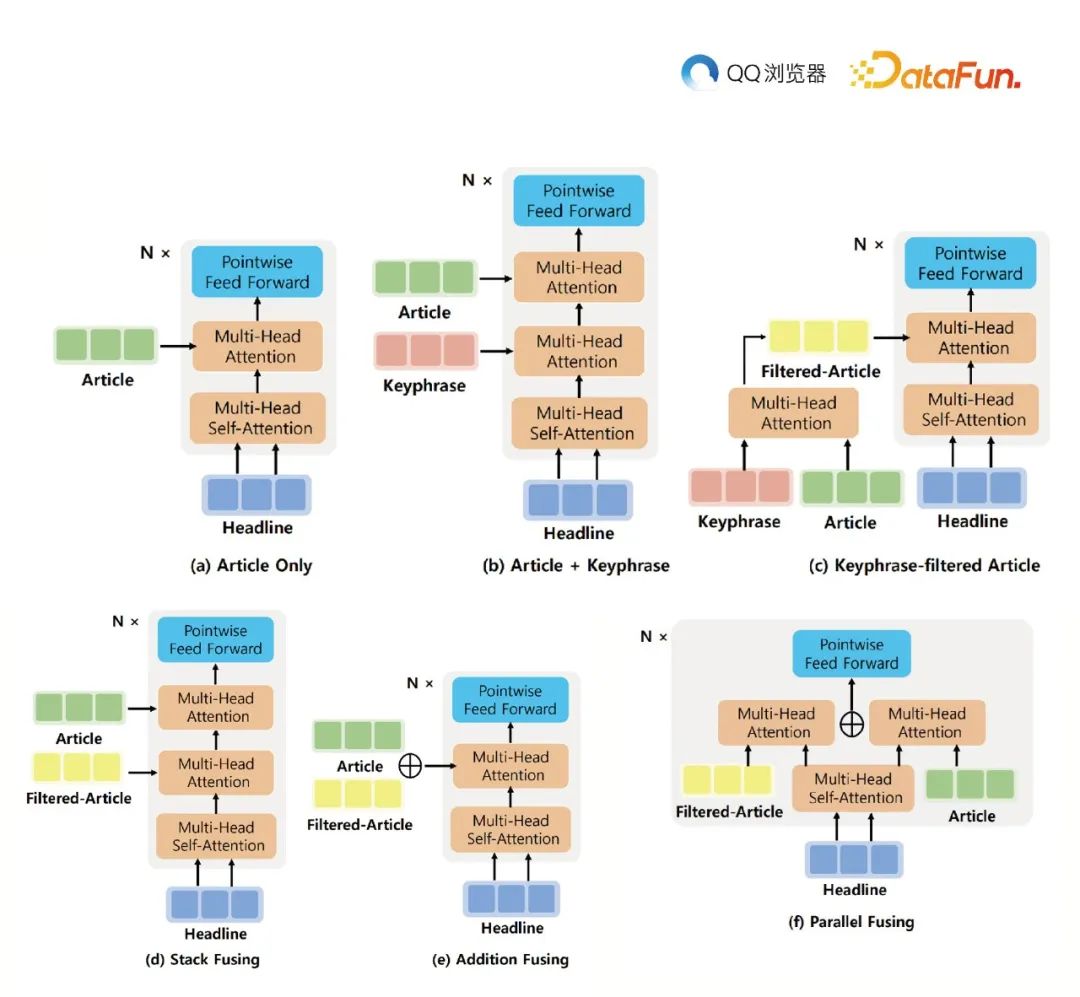
推荐和搜索场景存在大量的关键词,比如,推荐里的 tag,兴趣点和画像,搜索里的 query 等。模型使用了 Transformer 结构,包括 Encoder 和 Decoder 部分。
文章尝试了多种方法将关键词信息整合到模型中,以实现更好的效果。最简单的方法是通过在原有的 Multi-head Attention 层上添加一个新的关键词表示层。
另一种方法是先将文章表示与关键词表示进行交互,关键词表示作为 query,文章表示作为 key 和 value,再使用 Multi-head Attention 层生成过滤后的文章表示,最后在 Decoder 端进行处理。
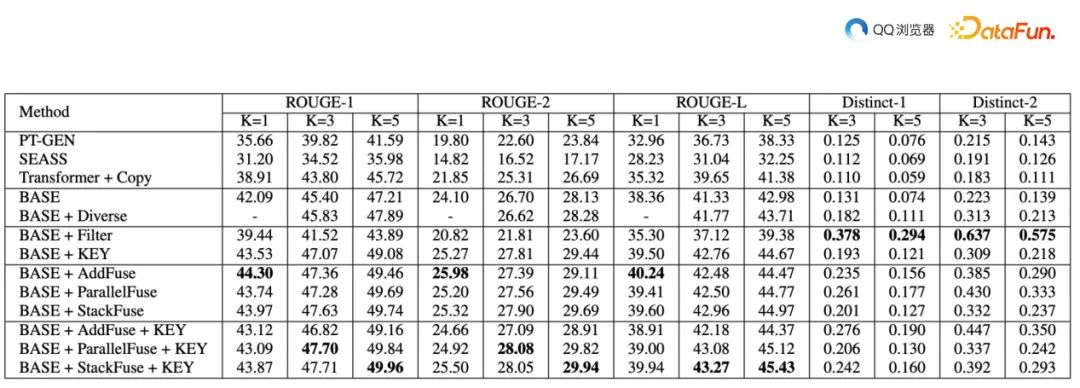
实验结果表明,在引入关键词过滤的文章表示后,模型性能得到了显著提升。通过这种方法,生成的标题更贴合用户兴趣,进而提高推荐和搜索的准确性。
2. 基于历史点击序列的个性化标题生成
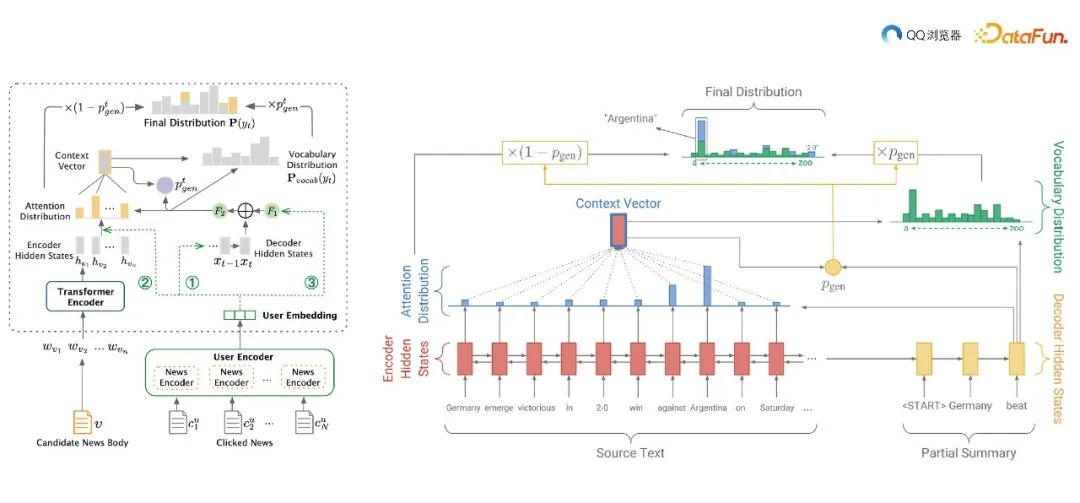
为了生成与用户点击风格更匹配的标题,我们提出了一种结合 transformer encoder 和 LSTM decoder 的方法,并将用户历史点击序列信息融入其中。以下是该方法的详细介绍:输入数据与用户表示:首先,对每个用户的历史点击序列进行处理。输入数据包括用户浏览过的文章标题或者其他相关特征。通过 user encoder 对这些历史点击序列进行编码,得到一个用户 embedding,代表用户的点击风格。
模型架构:整个模型以基于自注意力机制的 transformer encoder 作为 encoder 端,用于提取输入文章内容的语义和结构信息。而 decoder 端采用长短时记忆网络(LSTM),它具有较强的时序建模能力,可以有效地生成流畅、连贯的标题。
用户风格指导:在标题生成过程中,user embedding 可通过如下三种方式指导模型的输出:
- 初始化 LSTM hidden state:将 user embedding 作为 LSTM 的初始隐藏状态(hidden state)。这意味着在生成标题时,模型会从用户点击风格的角度开始思考。这样可以使得生成的标题更符合用户的兴趣和口味。
- 参与 attention distribution 计算:在解码过程中,LSTM需要根据输入文章内容和当前已生成的部分标题来预测下一个词。为了实现这个目标,引入 attention 机制可以帮助 LSTM 关注到更加重要的输入信息。通过将 user embedding 纳入 attention 分布的计算,可以让模型在生成标题时更关注与用户点击风格相关的内容。
- 参加门控网络计算:LSTM 中的门控网络起到调节信息流动的作用。在标题生成过程中,通过将 user embedding 与文章内容信息相结合,参与门控网络的计算,可以进一步优化信息筛选和更新过程。这有助于生成更符合用户风格的标题。
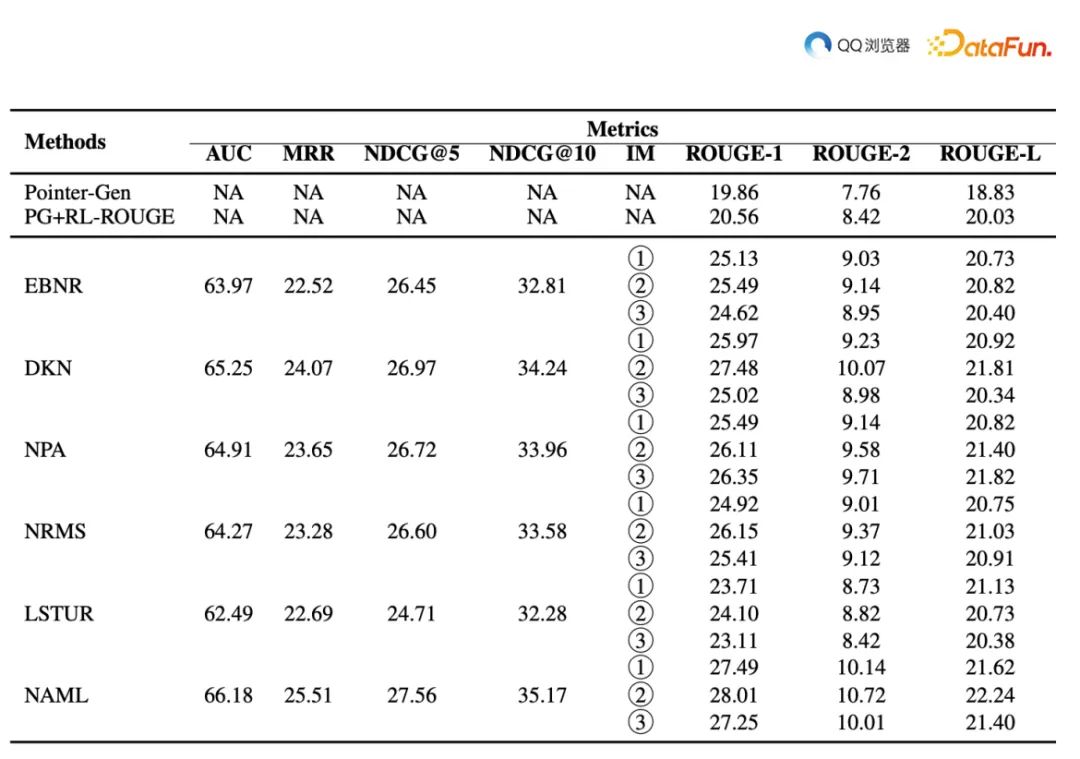
实验效果如下:
3. 基于作者风格的标题生成
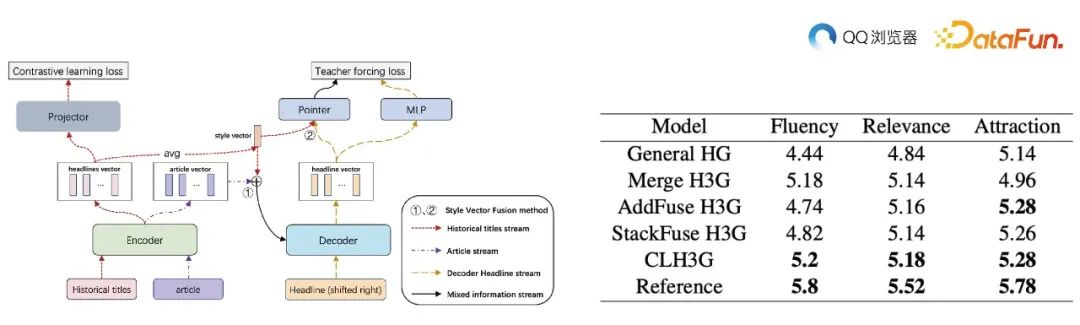
为了生成更具吸引力、相关性和流畅性的标题,我们采用了基于 transformer 模型的方法,并将作者的历史标题信息融入其中。
首先,为了构建训练数据集,我们对每天发文量特别多的搬运号和发文量特别少的创作者进行过滤。
接着,根据作者的历史标题,构造一个三元组(<文章,历史标题,想要的标题>)数据集。这些数据将作为输入来训练 transformer 模型。
在 transformer 模型中,encoder 主要负责提取输入文本的语义信息。然而,仅通过计算 n 个历史标题的 embedding 并对其进行平均,很难得到作者风格的表征。
为解决这个问题,我们引入了对比学习的方法。在 batch 内,同一作者的标题两两组成正例,不同作者的标题两两组成负例。这样进行训练,可以使模型的表征更倾向于捕捉作者风格,而非单纯的语义信息。
实验结果表明,引入作者风格的标题生成模型在 Rouge 和 BLEU 评估指标上有所提升。与原始模型相比,新模型生成的标题具有更高的流畅性、相关性和吸引力,同时能够保持与作者风格的一致性。这说明,通过利用作者历史标题信息,我们可以成功地生成更符合作者风格的标题,从而提高用户体验。
02 自动封面图合成
在当今信息爆炸的时代,封面图作为一种视觉传达方式,具备强烈的吸引力和可读性。它在各种场景中都发挥着至关重要的作用,如社交媒体、网站、杂志等。然而,要设计出一个既能够吸引观众注意力又不失实用性的封面图,并非易事。封面图的简单与复杂之间需要找到一个平衡点,以确保用户能够快速地理解其内容,并产生浓厚兴趣。过于简单的封面图可能导致用户无法获取足够的信息,从而忽略了其背后的价值。
而过于复杂的封面图可能让人觉得难以消化,使用户在面对海量信息中迅速丧失耐心。因此,在设计封面图时,应该遵循“简洁明了”的原则,通过适当的文字和图片组合来告诉用户这是一篇什么样的文章。为了增加封面图的吸引力和实用性,建议在封面图中嵌入标题、标签(Tag)等关键信息。这些关键信息能够让用户在第一时间获得文章的主题,从而激起他们的阅读兴趣。同时,这也有助于提高文章的专业性和可信度,让用户相信它是值得花时间去阅读的。
总之,封面图在信息传递和用户吸引方面具有重要意义。设计师应该根据目标受众和传播渠道来平衡封面图的简单与复杂程度,精心设计出既美观又实用的封面图。通过在封面图中嵌入关键信息,如标题、标签等,可以提升用户体验,进而扩大文章的传播范围和影响力。这里需要注意几点:- 封面图不能含有台标,水印,字幕等。
- 封面图关键信息不能遮挡人脸,重要目标等。
- 封面图上的关键信息需要从标题,标签,分类和关键词等抽取。
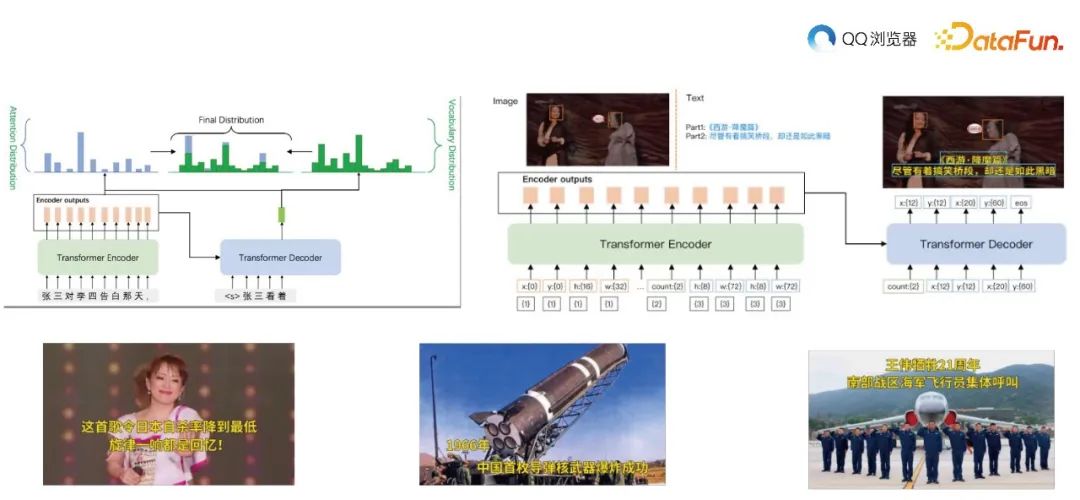
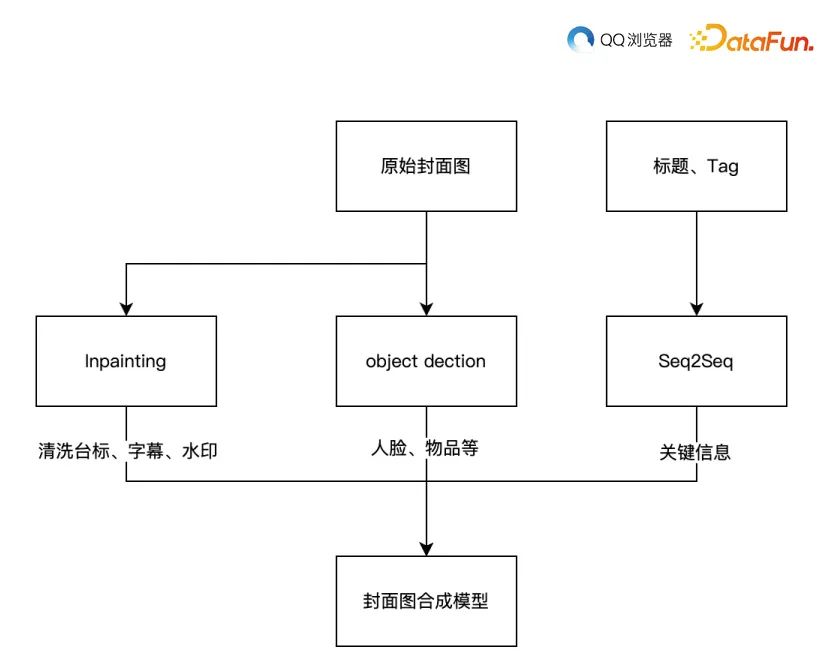
首先,通过图像修复技术去除水印、字幕等干扰元素,得到干净的封面图。然后,使用 Seq2Seq 模型提取标题和标签中的关键信息。接下来,进行目标检测以识别人脸、物品等关键部位,确保在生成的封面图上不被遮挡。最后,采用自动封面图合成参考 Layout Generation 方法,将文本信息融合到封面图中。其具体流程框图如下:
为了实现高质量的封面图生成,本文介绍了一种采用先进技术的方法,包括图像修复技术、Seq2Seq 模型、目标检测以及自动封面图合成参考 Layout Generation 方法。
以下是该方法的详细步骤:图像修复技术:图像修复技术旨在去除水印、字幕等干扰元素,从而得到干净的封面图。这一过程使用 Faster R-CNN,主要有以下几步:OCR 识别文本框的 proposals。
使用 ResNet50 对输入图片进行特征提取,得到 F1。通过特征映射,从F1中获取文本框的特征 F2。
基于 F2 进行分类,识别是否是文案、台标、字幕。基于 inpainting 进行内容抹除。通过这种方式,修复后的图像能够保留原始场景的视觉效果,同时消除不必要的元素。
使用 Seq2Seq 模型提取关键信息:Seq2Seq 模型是一种基于深度学习的端到端序列生成模型。
在此应用中,它被用于从标题和标签中提取关键信息。Seq2Seq 模型由两部分组成:编码器和解码器。编码器将输入文本转换为一个固定大小的向量表示,然后解码器从该表示生成输出序列。在这个过程中,模型可以学会识别并提取与封面图相关的关键信息。
具体做法如下:使用带 Pointer 的预训练 T5 模型作为底座模型。标注一批数据,使用视频的标题、分类和关键词作为输入,人工改写的信息作为结果。
预测的关键信息可能包含多个片段。目标检测:目标检测技术用于识别图像中的关键部位,如人脸、物品等。
这些部位可能在图像中具有显著的视觉特征,因此它们在生成封面图时需要特别关注。目标检测通常借助深度学习技术,如卷积神经网络(CNN)和区域卷积神经网络(R-CNN),来实现对关键部位的精确识别。
这样,在插入文本信息时,可以确保这些关键部位不被遮挡。目前目标检测模型可以识别人脸、猫、狗、汽车等65个类别。目标框位置使用左上和右下两个点的坐标表示。自动封面图合成参考 Layout Generation 方法:在前述准备工作完成后,接下来就是将文本信息融合到封面图中。为此,采用一种名为 Layout Generation 的方法来自动生成封面图布局。
该方法首先对输入图像进行分析,提取其视觉特征和结构信息。然后,根据这些信息确定最佳的文本插入位置和样式。
最后,将从标题和标签中提取到的关键信息插入到相应位置,生成最终的封面图。