一文带你搞懂 Docker 容器的核心基石 Cgroups

Cgroups 是 Linux 系统内核提供的一种机制,这种机制可以根据需求将一些列系统任务机器子任务整合或分离到按资源划分登记的不同组内,从而为系统资源管理提供一个的框架。简单地说,cgroups 可以限制、记录任务组所使用的物理组员(比如 CPU、Memory、IO等),为容器实现虚拟化提供了基本保证,是构建 Docker 等一些列虚拟化管理工具的基石。今天我们就来详细介绍一下 cgroups 相关的内容。
1. 为什么要了解 Cgroups
从2013年开源的 Docker 推出、2014年开源的 Kubernetes 出现,到现在的云原生技术与生态的全面普及与火热化,容器技术已经逐步成为主流的基础云原生技术之一。使用容器技术,可以很好地实现资源层面上的限制和隔离,这都依赖于 Linux 系统内核所提供的Cgroups和 Namespace技术。
Cgroups主要用来管理资源的分配、限制;Namespace主要用来封装抽象、限制、隔离资源,使命名空间内的进程拥有它们自己的全局资源。
Linux内核提供的 Cgroups 和 Namespace 技术,为容器实现虚拟化提供了基本保证,是构建 Docker 等一些列虚拟化管理工具的基石。下面我们就来详细介绍一下 Cgroups 相关的内容。
2. Cgroups简介
Cgroups 是 control groups 的缩写,是 Linux 内核提供的一种可以限制、记录、隔离进程组(process groups)所使用的物理资源(如 CPU、Memory、IO 等等)的机制。
Cgroups 和 Namespace 类似,也是将进程进行分组,但它的目的和 Namespace 不一 样,Namespace 是为了隔离进程组之间的资源,而 Cgroups 是为了对一组进程进行统一的资源监控和限制。
Cgroups 分 v1 和 v2 两个版本,v1 实现较早,功能比较多,但是由于它里面的功能都是零零散散的实现的,所以规划的不是很好,导致了一些使用和维护上的不便,v2 的出现 就是为了解决 v1 中这方面的问题,在最新的 4.5 内核中,Cgroups v2 声称已经可以用于生产环境了,但它所支持的功能还很有限,随着 v2 一起引入内核的还有 Cgroups、Namespace,v1 和 v2 可以混合使用,但是这样会更复杂,所以一般没人会这样用。
3. 什么是 Cgroups?
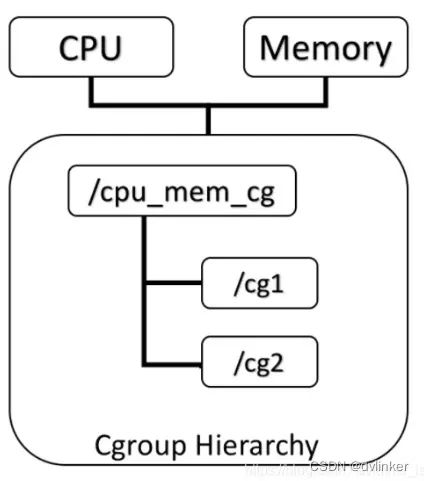
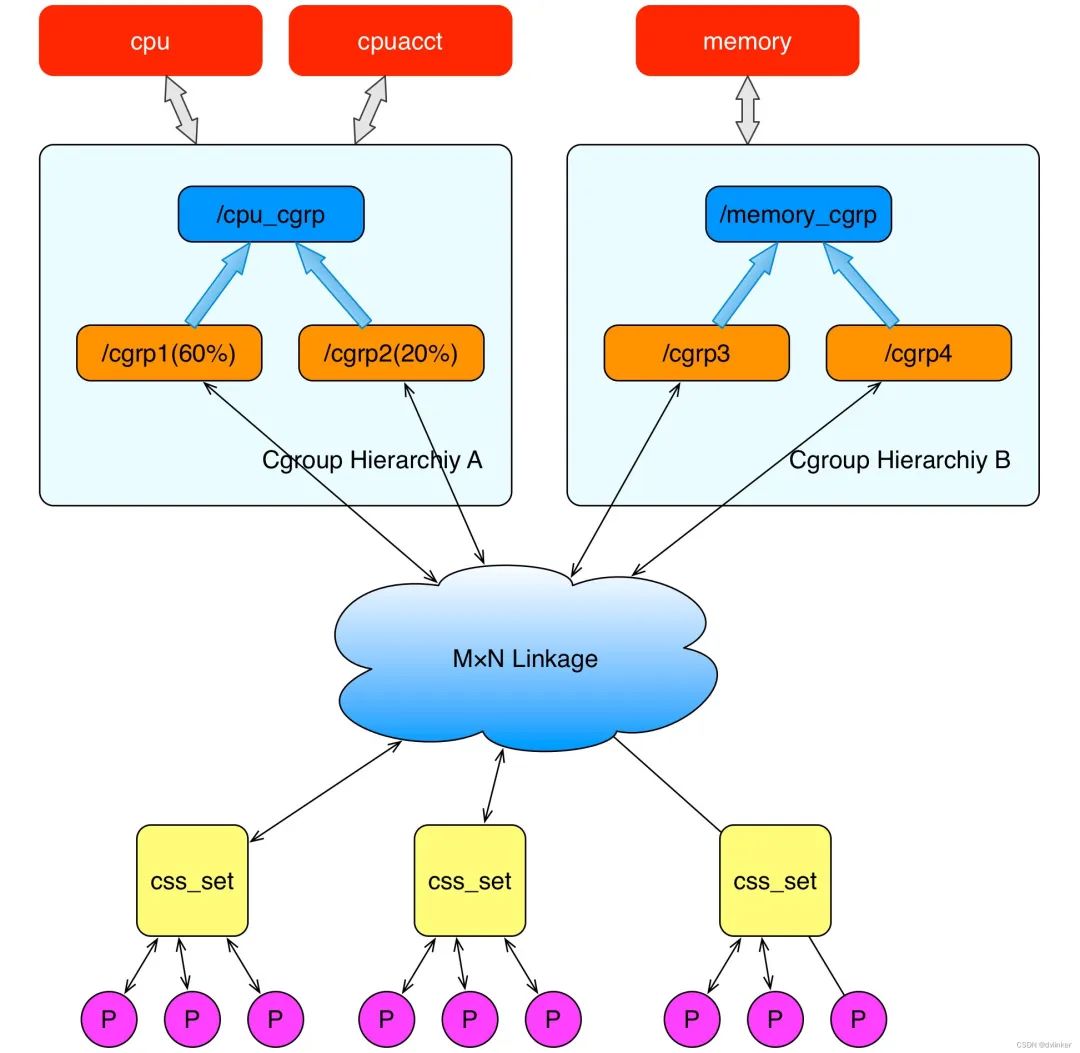
Cgroups 是 Linux 下的一种将进程按组进行管理的机制,在用户层看来,Cgroups 技术就是把系统中的所有进程组织成一颗一颗独立的树,每棵树都包含系统的所有进程,树的每个节点是一个进程组,而每颗树又和一个或者多个 subsystem 关联,树的作用是将进程分组,而 subsystem 的作用就是对这些组进行操作,Cgroups 的主体架构提如下:
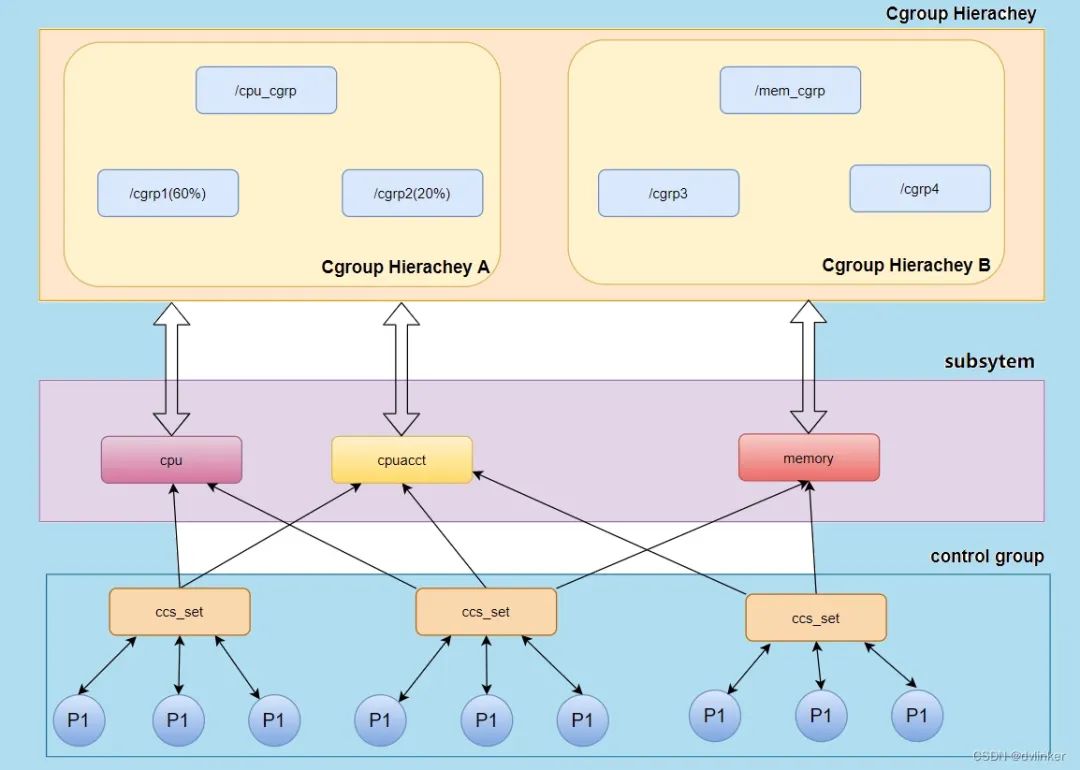
- subsystem: 一个 subsystem 就是一个内核模块,他被关联到一颗 cgroup 树之后, 就会在树的每个节点(进程组)上做具体的操作。subsystem 经常被称作 resource controller,因为它主要被用来调度或者限制每个进程组的资源,但是这个说法不完全准 确,因为有时我们将进程分组只是为了做一些监控,观察一下他们的状态,比如 perf_event subsystem。到目前为止,Linux 支持 12 种 subsystem,比如限制 CPU 的使 用时间,限制使用的内存,统计 CPU 的使用情况,冻结和恢复一组进程等,后续会对它们一一进行介绍。
- hierarchy: 一个 hierarchy 可以理解为一棵 cgroup 树,树的每个节点就是一个进程 组,每棵树都会与零到多个 subsystem 关联。在一颗树里面,会包含 Linux 系统中的所有 进程,但每个进程只能属于一个节点(进程组)。系统中可以有很多颗 cgroup 树,每棵树 都和不同的 subsystem 关联,一个进程可以属于多颗树,即一个进程可以属于多个进程 组,只是这些进程组和不同的 subsystem 关联。
目前 Linux 支持 12 种 subsystem,如果不考虑不与任何 subsystem 关联的情况(systemd 就属于这种情况),Linux 里面最多可以建 12 颗 cgroup 树,每棵树关联一个 subsystem,当然也可以只建一棵树,然后让这 棵树关联所有的 subsystem。当一颗 cgroup 树不和任何 subsystem 关联的时候,意味着这棵树只是将进程进行分组,至于要在分组的基础上做些什么,将由应用程序自己决定, systemd 就是一个这样的例子。
4. 为什么需要 Cgroups?
在 Linux 里,一直以来就有对进程进行分组的概念和需求,比如 session group, progress group 等,后来随着人们对这方面的需求越来越多,比如需要追踪一组进程的内存和 IO 使用情况等,于是出现了 cgroup,用来统一将进程进行分组,并在分组的基础上对进程进行监控和资源控制管理等。
举个例子,Linux 系统中安装了杀毒软件 ESET 或者 ClamAV,杀毒时占用系统资源过高,影响系统承载业务运行,怎么办?单个虚拟机进程或者 docker 进程使用过高的资源,怎么办?单个Java进行占用系统过多的内存的资源,怎么办?
cgroup 就是能够控制并解决上述问题的工具,cgroup 在 linux 内核实现、用于控制 linux 系统资源。
5. Cgroups 是如何实现的?
在 CentOS 7 系统中(包括 Red Hat Enterprise Linux 7),通过将 cgroup 层级系统与 systemd 单位树捆绑,可以把资源管理设置从进程级别移至应用程序级别。默认情况下 systemd 会自动创建 slice、scope 和 service 单位的层级(具体的意思稍后再解释),来为 cgroup 树提供统一结构。
可以通过 systemctl 命令创建自定义 slice 进一步修改此结构。如果我们将系统的资源看成一块馅饼,那么所有资源默认会被划分为 3 个 cgroup:System, User 和 Machine。每一个 cgroup 都是一个 slice,每个 slice 都可以有自己的子 slice,如下图所示:
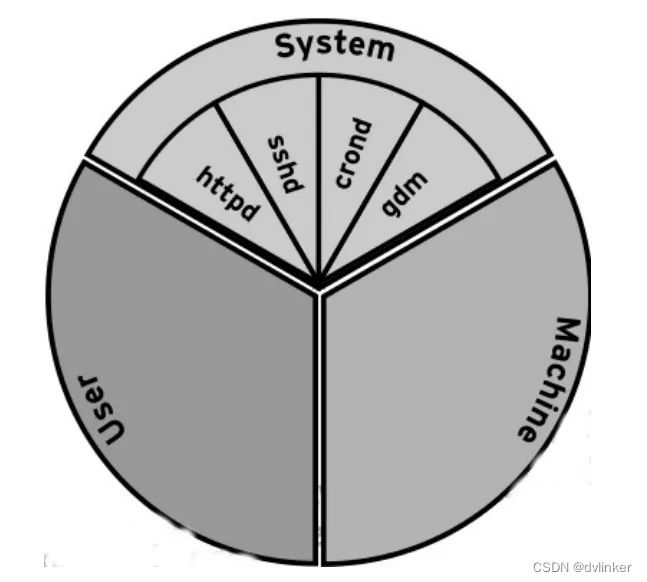
- 1)system.slice:所有系统 service 的默认位置。
- 2)user.slice:所有用户会话的默认位置。每个用户会话都会在该 slice 下面创建一个子 slice,如果同一个用户多次登录该系统,仍然会使用相同的子 slice。
- 3)machine.slice:所有虚拟机和 Linux 容器的默认位置 控制 CPU 资源使用的其中一种方法是 shares。shares 用来设置 CPU 的相对值(你可以理解为权 重),并且是针对所有的 CPU(内核),默认值是 1024。因此在上图中,httpd, sshd, crond 和 gdm 的 CPU shares 均为 1024,System, User 和 Machine 的 CPU shares 也是 1024。
假设该系统上运行了 4 个 service,登录了两个用户,还运行了一个虚拟机。同时假设 每个进程都要求使用尽可能多的 CPU 资源(每个进程都很繁忙),则:
- 1)system.slice 会获得 33.333% 的 CPU 使用时间,其中每个 service 都会从 system.slice 分配的 资源中获得 1/4 的 CPU 使用时间,即 8.25% 的 CPU 使用时间。
- 2)user.slice 会获得 33.333% 的 CPU 使用时间,其中每个登录的用户都会获得 16.5% 的 CPU 使 用时间。假设有两个用户:tom 和 jack,如果 tom 注销登录或者杀死该用户会话下的所有进程, jack 就能够使用 33.333% 的 CPU 使用时间。
- 3)machine.slice 会获得 33.333% 的 CPU 使用时间,如果虚拟机被关闭或处于 idle 状态,那么 system.slice 和 user.slice 就会从这 33.333% 的 CPU 资源里分别获得 50% 的 CPU 资源,然后 均分给它们的子 slice。
6. Cgroups 的作用
Cgroups 最初的目标是为资源管理提供的一个统一的框架,既整合现有的 cpuset 等子系统,也为未来开发新的子系统提供接口。现在的 cgroups 适用于多种应用场景,从单个进程的资源控制,到实现操作系统层次的虚拟化(OS Level Virtualization),框架图如下:
- 1)限制进程组可以使用的资源数量(Resource limiting )。比如:memory子系统可以为进程 组设定一个memory使用上限,一旦进程组使用的内存达到限额再申请内存,就会出发 OOM(out of memory)。
- 2)进程组的优先级控制(Prioritization )。比如:可以使用cpu子系统为某个进程组分配特定 cpu share。
- 3)记录进程组使用的资源数量(Accounting )。比如:可以使用cpuacct子系统记录某个进程 组使用的cpu时间。
- 4)进程组隔离(Isolation)。比如:使用ns子系统可以使不同的进程组使用不同的 namespace,以达到隔离的目的,不同的进程组有各自的进程、网络、文件系统挂载空间。
- 5)进程组控制(Control)。比如:使用freezer子系统可以将进程组挂起和恢复。
7. Cgroups 相关概念及相互关系
7.1 相关概念
1)任务(task):在 cgroups 中,任务就是系统的一个进程。
2)控制族群(control group):控制族群就是一组按照某种标准划分的进程。Cgroups 中的资源控制都是以控制族群为单位实现。一个进程可以加入到某个控制族群,也从一个进程组迁移到另 一个控制族群。一个进程组的进程可以使用 cgroups 以控制族群为单位分配的资源,同时受到 cgroups 以控制族群为单位设定的限制。
3)层级(hierarchy):控制族群可以组织成 hierarchical 的形式,既一颗控制族群树。控制族 群树上的子节点控制族群是父节点控制族群的孩子,继承父控制族群的特定的属性。
4)子系统(subsystem):一个子系统就是一个资源控制器,比如 cpu 子系统就是控制 cpu 时间分配的一个控制器。子系统必须附加(attach)到一个层级上才能起作用,一个子系统附加到某个 层级以后,这个层级上的所有控制族群都受到这个子系统的控制。
7.2 相互关系
- 1)每次在系统中创建新层级时,该系统中的所有任务都是那个层级的默认 cgroup(我们称之为 root cgroup ,此 cgroup 在创建层级时自动创建,后面在该层级中创建的 cgroup 都是此 cgroup 的后代)的初始成员。
- 2)一个子系统最多只能附加到一个层级。
- 3)一个层级可以附加多个子系统
- 4)一个任务可以是多个 cgroup 的成员,但是这些 cgroup 必须在不同的层级。
- 5)系统中的进程(任务)创建子进程(任务)时,该子任务自动成为其父进程所在 cgroup 的成员。然后可根据需要将该子任务移动到不同的 cgroup 中,但开始时它总是继承其父任务的 cgroup。
8. Cgroups 子系统介绍
可以看到,在 /sys/fs/cgroup 下面有很多 cpu、memory 这样的子目录,也就称为子系统 subsystem:
- 1)net_cls:将 cgroup 中进程产生的网络包分类,以便 Linux 的 tc(traffic controller) 可以根据分类区分出来自某个 cgroup 的包并做限流或监控。这个子系统使用等级识别符(classid)标记网络数据包,可允许 Linux 流量控制程序 (tc)识别从具体 cgroup 中生成的数据包。
- 2)net_prio:设置 cgroup 中进程产生的网络流量的优先级。
- 3)memory:控制 cgroup 中进程的内存占用。
- 4)cpuset:在多核机器上设置 cgroup 中进程可以使用的 cpu 和内存。这个子系统为 cgroup 中的任务分配独立 CPU(在多核系统)和内存节点。
- 5)freezer:挂起(suspend)和恢复(resume) cgroup 中的进程。这个子系统挂起或者恢复 cgroup 中的任务。
- 6)blkio:设置对块设备(如硬盘)输入输出的访问控制。这个子系统为块设备设定输入/输出限制,比如物理设备(磁盘,固态硬盘,USB 等等)。
- 7)cpu:设置 cgroup 中进程的 CPU 占用。这个子系统使用调度程序提供对 CPU 的 cgroup 任务访问。
- 8)cpuacct:统计 cgroup 中进程的 CPU 占用。这个子系统自动生成 cgroup 中任务所使用的 CPU 报告。
- 9)devices:控制 cgroup 中进程对设备的访问 16 这个子系统可允许或者拒绝 cgroup 中的任务访问设备。
8.1 如何查看当前系统支持哪些 subsystem?
可以通过查看 /proc/cgroups(since Linux 2.6.24)知道当前系统支持哪些 subsystem,下面 是一个例子:
#subsys_name hierarchy num_cgroups enabled
cpuset 11 1 1
cpu 3 64 1
cpuacct 3 64 1
blkio 8 64 1
memory 9 104 1
devices 5 64 1
freezer 10 4 1
net_cls 6 1 1
perf_event 7 1 1
net_prio 6 1 1
hugetlb 4 1 1
pids 2 68 1每一列的说明:
- 1)subsys_name:subsystem 的名字
- 2)hierarchy:subsystem 所关联到的 cgroup 树的 ID,如果多个 subsystem 关联到同一颗 cgroup 树,那么他们的这个字段将一样,比如这里的 cpu 和 cpuacct 就一样,表示他们绑定到了同一颗树。如果出现下面的情况,这个字段将为0:
- 当前 subsystem 没有和任何 cgroup 树绑定
- 当前 subsystem 已经和 cgroup v2 的树绑定
- 当前 subsystem 没有被内核开启
- 3)num_cgroups:subsystem 所关联的 cgroup 树中进程组的个数,也即树上节点的个数
- 4)enabled:1 表示开启,0 表示没有被开启(可以通过设置内核的启动参数
cgroup_disable来控制 subsystem 的开启)。
8.2 Cgroups 下的 CPU 子系统
cpu 子系统用于控制 cgroup 中所有进程可以使用的 cpu 时间片。cpu subsystem 主要涉及5接口:cpu.cfs_period_us、cpu.cfs_quota_us、cpu.shares、cpu.rt_period_us、cpu.rt_runtime_us.cpu。
- 1)cfs_period_us:cfs_period_us 表示一个 cpu 带宽,单位为微秒。系统总 CPU 带宽:
cpu核心数 * cfs_period_us cpu。 - 2)cfs_quota_us:cfs_quota_us 表示 Cgroup 可以使用的 cpu 的带宽,单位为微秒。cfs_quota_us 为-1,表示使用的 CPU 不受 cgroup 限制。cfs_quota_us 的最小值为1ms(1000),最大值为1s。结合 cfs_period_us,就可以限制进程使用的 cpu。例如配置 cfs_period_us=10000,而 cfs_quota_us=2000。那么该进程就可以可以用2个 cpu core。
- 3)cpu.shares:通过 cfs_period_us 和 cfs_quota_us 可以以绝对比例限制 cgroup 的 cpu 使用,即
cfs_quota_us/cfs_period_us等于进程可以利用的 cpu cores,不能超过这个数值。而 cpu.shares 以相对比例限制 cgroup 的 cpu。例如:在两个 cgroup 中都将 cpu.shares 设定为 1 的任务将有相同的 CPU 时间,但在 cgroup 中将 cpu.shares 设定为 2 的任务可使用的 CPU 时间 是在 cgroup 中将 cpu.shares 设定为 1 的任务可使用的 CPU 时间的两倍。 - 4)cpu.rt_runtime_us:以微秒(µs,这里以“us”代表)为单位指定在某个时间段中 cgroup 中的任务对 CPU 资源的最长连续访问时间。建立这个限制是为了防止一个 cgroup 中的任务独占 CPU 时间。如果 cgroup 中的任务应该可以每 5 秒中可有 4 秒时间访问 CPU 资源,请将 cpu.rt_runtime_us 设定为 4000000,并将 cpu.rt_period_us 设定为 5000000。
- 5)cpu.rt_period_us:以微秒(µs,这里以“us”代表)为单位指定在某个时间段中 cgroup 对 CPU 资源访问重新分配的频率。如果某个 cgroup 中的任务应该每 5 秒钟有 4 秒时间可访问 CPU 资源,则请将 cpu.rt_runtime_us 设定为 4000000,并将 cpu.rt_period_us 设定为 5000000。注意
sched_rt_runtime_us是实时任务的保证时间和最高占用时间,如果实时任务没有使用,可以分配给非实时任务,并且实时任务最终占用的时间不能超过这个数值,参考 Linux-85 关于sched_rt_runtime_us和sched_rt_period_us。对cpu.rt_period_us参数的限制是必须小于父目录中的同名参数值。对cpu.rt_runtime_us的限制是:
Sum_{i} runtime_{i} / global_period <= global_runtime / global_period即:
Sum_{i} runtime_{i} <= global_runtime 当前的实时进程调度算法可能导致部分实时进程被饿死,如下A和B是并列的,A的运行时时长正好覆盖了B的运行时间:
* group A: period=100000us, runtime=50000us
- this runs for 0.05s once every 0.1s
* group B: period= 50000us, runtime=25000us
- this runs for 0.025s twice every 0.1s (or once every 0.05 sec).Real-Time group scheduling 中提出正在开发 SCHED_EDF (Earliest Deadline First scheduling),优先调度最先结束的实时进程。
8.3 在 CentOS 中安装 Cgroups
#若系统未安装则进行安装,若已安装则进行更新。
yum install libcgroup
#查看运行状态,并启动服务
[root@localhost ~] service cgconfig status
Stopped
[root@localhost ~] service cgconfig start
Starting cgconfig service: [ OK ]
service cgconfig status 9 Running 1011
#查看是否安装cgroup
[root@localhost ~] grep cgroup /proc/filesystems8.4 查看 service 服务在哪个 cgroup 组
systemctl status [pid] | grep CGroup 23
cat /proc/[pid]/cgroup
cd /sys/fs/ && find * ‐name "*.procs" ‐exec grep [pid] {} /dev/null \; 2> /dev/null
#查看进程cgroup的最快方法是使用以下bash脚本按进程名:
#!/bin/bash
THISPID=`ps ‐eo pid,comm | grep $1 | awk '{print $1}'`
cat /proc/$THISPID/cgroup9. 如何使用 Cgroups
9.1 通过 systemctl 设置 cgroup
在使用命令 systemctl set-property 时,可以使用 tab 补全:
$ systemctl set‐property user‐1000.slice
AccuracySec= CPUAccounting= Environment= LimitCPU= LimitNICE= LimitSIGPEN DING= SendSIGKILL=
BlockIOAccounting= CPUQuota= Group= LimitDATA= LimitNOFILE= LimitSTACK= U ser=
BlockIODeviceWeight= CPUShares= KillMode= LimitFSIZE= LimitNPROC= MemoryA ccounting= WakeSystem=
BlockIOReadBandwidth= DefaultDependencies= KillSignal= LimitLOCKS= LimitR SS= MemoryLimit=
BlockIOWeight= DeviceAllow= LimitAS= LimitMEMLOCK= LimitRTPRIO= Nice=
BlockIOWriteBandwidth= DevicePolicy= LimitCORE= LimitMSGQUEUE= LimitRTTIM E= SendSIGHUP=这里有很多属性可以设置,但并不是所有的属性都是用来设置 cgroup 的,我们只需要关注 Block, CPU 和 Memory。
如果你想通过配置文件来设置 cgroup,service 可以直接在 /etc/systemd/system/xxx.service.d 目录下面创建相应的配置文件,slice 可以直接在 /run/systemd/system/xxx.slice.d 目录下面创建相应的配置文件。事实上通过 systemctl 命令行工具设置 cgroup 也会写到该目录下的配置文件中:
$ cat /run/systemd/system/user‐1000.slice.d/50‐CPUQuota.conf
[Slice]
CPUQuota=20%9.2 设置 CPU 资源的使用上限
如果想严格控制 CPU 资源,设置 CPU 资源的使用上限,即不管 CPU 是否繁忙,对 CPU 资源的使用都不能超过这个上限。可以通过以下两个参数来设置:
- 1)cpu.cfs_period_us = 统计 CPU 使用时间的周期,单位是微秒(us)
- 2)cpu.cfs_quota_us = 周期内允许占用的 CPU 时间(指单核的时间,多核则需要在设置时累加)
systemctl 可以通过 CPUQuota 参数来设置 CPU 资源的使用上限。例如,如果你想将用户 tom 的 CPU 资源使用上限设置为 20%,可以执行以下命令:
$ systemctl set‐property user‐1000.slice CPUQuota=20%9.3 通过配置文件设置 cgroup(/etc/cgconfig.conf)
cgroup 配置文件所在位置 /etc/cgconfig.conf,其默认配置文件内容
mount {
cpuset = / cgroup / cpuset ;
cpu = / cgroup / cpu ;
cpuacct = / cgroup / cpuacct ;
memory = / cgroup / memory ;
devices = / cgroup / devices ;
freezer = / cgroup / freezer ;
net_cls = / cgroup / net_cls ;
blkio = / cgroup / blkio ;
}相当于执行命令:
mkdir /cgroup/cpuset
mount ‐t cgroup ‐o cpuset red /cgroup/cpuset
……
mkdir /cgroup/blkio
[root@localhost ~] vi /etc/cgrules.conf
[root@localhost ~] echo 524288000 > /cgroup/memory/foo/memory.limit_in_b ytes 使用 cgroup 临时对进程进行调整,直接通过命令即可,如果要持久化对进程进行控制,即重启后依然有效,需要写进配置文件 /etc/cgconfig.conf 及 /etc/cgrules.conf。
10. 查看 Cgroup
10.1 通过 systemd 查看 cgroup
1)systemd-cgls 命令:通过 systemd-cgls 命令来查看,它会返回系统的整体 cgroup 层级,cgroup 树的最高层 由 slice 构成,如下所示:
$ systemd‐cgls ‐‐no‐page
├─1 /usr/lib/systemd/systemd ‐‐switched‐root ‐‐system ‐‐deserialize 22
├─user.slice
│ ├─user‐1000.slice
│ │ └─session‐11.scope
│ │ ├─9507 sshd: tom [priv]
│ │ ├─9509 sshd: tom@pts/3
│ │ └─9510 ‐bash
│ └─user‐0.slice
│ └─session‐1.scope
│ ├─ 6239 sshd: root@pts/0
│ ├─ 6241 ‐zsh
│ └─11537 systemd‐cgls ‐‐no‐page
└─system.slice 15 ├─rsyslog.service
│ └─5831 /usr/sbin/rsyslogd ‐n
├─sshd.service 18 │ └─5828 /usr/sbin/sshd ‐D
├─tuned.service
│ └─5827 /usr/bin/python2 ‐Es /usr/sbin/tuned ‐l ‐P 21 ├─crond.service
│ └─5546 /usr/sbin/crond ‐n可以看到系统 cgroup 层级的最高层由 user.slice 和 system.slice 组成。因为系统中没有 运行虚拟机和容器,所以没有 machine.slice,所以当 CPU 繁忙时,user.slice 和 system.slice 会各获得 50% 的 CPU 使用时间。
user.slice 下面有两个子 slice:user-1000.slice 和 user-0.slice,每个子 slice 都用 User ID (UID) 来命名,因此我们很容易识别出哪个 slice 属于哪个用户。例如从上面的输出信息中可以看出 user-1000.slice 属于用户 tom,user-0.slice 属于用户 root。
2)systemd-cgtop 命令:systemd-cgls 命令提供的只是 cgroup 层级的静态信息快照,要想查看 cgroup 层级的动 态信息,可以通过 systemd-cgtop 命令查看:
$ systemd‐cgtop
Path Tasks %CPU Memory Input/s Output/s
/ 161 1.2 161.0M ‐ ‐ 5 /system.slice ‐ 0.1 ‐ ‐ ‐
/system.slice/vmtoolsd.service 1 0.1 ‐ ‐ ‐
/system.slice/tuned.service 1 0.0 ‐ ‐ ‐
/system.slice/rsyslog.service 1 0.0 ‐ ‐ ‐
/system.slice/auditd.service 1 ‐ ‐ ‐ ‐
/system.slice/chronyd.service 1 ‐ ‐ ‐ ‐
/system.slice/crond.service 1 ‐ ‐ ‐ ‐
/system.slice/dbus.service 1 ‐ ‐ ‐ ‐
/system.slice/gssproxy.service 1 ‐ ‐ ‐ ‐
/system.slice/lvm2‐lvmetad.service 1 ‐ ‐ ‐ ‐
/system.slice/network.service 1 ‐ ‐ ‐ ‐
/system.slice/polkit.service 1 ‐ ‐ ‐ ‐
/system.slice/rpcbind.service 1 ‐ ‐ ‐ ‐
/system.slice/sshd.service 1 ‐ ‐ ‐ ‐
/system.slice/system‐getty.slice/getty@tty1.service 1 ‐ ‐ ‐ ‐
/system.slice/systemd‐journald.service 1 ‐ ‐ ‐ ‐
/system.slice/systemd‐logind.service 1 ‐ ‐ ‐ ‐
/system.slice/systemd‐udevd.service 1 ‐ ‐ ‐ ‐
/system.slice/vgauthd.service 1 ‐ ‐ ‐ ‐
/user.slice 3 ‐ ‐ ‐ ‐
/user.slice/user‐0.slice/session‐1.scope 3 ‐ ‐ ‐ ‐
/user.slice/user‐1000.slice 3 ‐ ‐ ‐ ‐
/user.slice/user‐1000.slice/session‐11.scope 3 ‐ ‐ ‐ ‐
/user.slice/user‐1001.slice/session‐8.scopescope systemd-cgtop 提供的统计数据和控制选项与 top 命令类似,但该命令只显示那些开启了 资源统计功能的 service 和 slice。
如果你想开启 sshd.service 的资源统计功能,可以进行如下操作:
$ systemctl set‐property sshd.service CPUAccounting=true MemoryAccounting=true
#该命令会在 /etc/systemd/system/sshd.service.d/ 目录下创建相应的配置文件:
$ ll /etc/systemd/system/sshd.service.d/
总用量 8
4 ‐rw‐r‐‐r‐‐ 1 root root 28 5月 31 02:24 50‐CPUAccounting.conf
4 ‐rw‐r‐‐r‐‐ 1 root root 31 5月 31 02:24 50‐MemoryAccounting.conf
$ cat /etc/systemd/system/sshd.service.d/50‐CPUAccounting.conf
[Service]
CPUAccounting=yes 1415
$ cat /etc/systemd/system/sshd.service.d/50‐MemoryAccounting.conf
[Service]
MemoryAccounting=yes 1819
#配置完成之后,再重启 sshd 服务:
$ systemctl daemon‐reload 21 $ systemctl restart sshd这时再重新运行 systemd‐cgtop 命令,就能看到 sshd 的资源使用统计了。
10.2 通过 proc 查看 cgroup
如何查看当前进程属于哪些 cgroup 可以通过查看 /proc/[pid]/cgroup(since Linux 2.6.24)知道指定进程属于哪些cgroup,如下:
$ cat /proc/777/cgroup
11:cpuset:/
10:freezer:/
9:memory:/system.slice/cron.service
8:blkio:/system.slice/cron.service
7:perf_event:/ 7 6:net_cls,net_prio:/
5:devices:/system.slice/cron.service
4:hugetlb:/
3:cpu,cpuacct:/system.slice/cron.service
2:pids:/system.slice/cron.service
1:name=systemd:/system.slice/cron.service每一行包含用冒号隔开的三列,他们的意思分别是:
cgroup树的ID :和cgroup树绑定的所有subsystem :进程在cgroup树中的路径
- 1)cgroup 树的 ID,和
/proc/cgroups文件中的 ID 一一对应。 - 2)和 cgroup 树绑定的所有 subsystem,多个 subsystem 之间用逗号隔开。这里
name=systemd表示没有和任何 subsystem 绑定,只是给他起了个名字叫 systemd。 - 3)进程在 cgroup 树中的路径,即进程所属的 cgroup,这个路径是相对于挂载点的相对路径。
10.3 通过 /sys 查看 cgroup
查看 cgroup 下 CPU 资源的使用上限:
$ cat /sys/fs/cgroup/cpu,cpuacct/user.slice/user‐1000.slice/cpu.cfs_perio d_us
100000
$ cat /sys/fs/cgroup/cpu,cpuacct/user.slice/user‐1000.slice/cpu.cfs_quota _us
20000 这表示用户 tom 在一个使用周期内(100 毫秒)可以使用 20 毫秒的 CPU 时间。不管 CPU 是否空闲,该用户使用的 CPU 资源都不会超过这个限制。
CPUQuota 的值可以超过 100%,例如:如果系统的 CPU 是多核,且 CPUQuota 的值为 200%,那么该 slice 就能够使用 2 核的 CPU 时间。
来源:https://blog.csdn.net/chenlycly/article/details/125956805