拆解Token:深入了解ChatGPT背后的构建单元
ChatGPT彻底点燃大家对大语言模型(LLM)的热情,越来越多的同学开始自己动手来实现自己的AI应用,而调用过OpenAI API的同学都知道,其API调用是按照Token来计费的,那么Token到底是什么?Token和单词/字有什么不同?Token是如何构建的?它在LLM中到底起到了什么作用?本文就来回答这些问题。

Token化就是教LLM认字
当人类看到一段文字会很自然地把它分解为一个个单词/字,这是我们理解分析文章和句子的基础。但对于LLM来说,它看到的不过是长长的一串二进制的01、01,对LLM来说,它不理解什么是段落、句子、单词,为了让LLM也像人类一样在理解语言的时候有一个基础,我们也需要教会LLM认字,这和我们小时候先学会认字,然后才能读书是一个道理。
而教LLM认字的过程是,我们首先把文章/句子切分成一个个小片段,并把这些小片段转换成LLM理解的向量形式,之后把这些向量输入给LLM让它学习,当LLM学习了足够多的数据后,它就学会了认字。
为什么Token和单词不是一一对应的
在上面的类比中,我们说要教LLM认字,但实际上LLM认的“字”/Token和我们的单词却并不是一一对应的,为什么会这样?
假设我们让单词和Token一一对应,那么常见的英语训练语料包含的单词在17万到100万之间,考虑到英语单词还有单复数、时态的变化,这会进一步让词汇表膨胀。过大的词汇表一方面会增加LLM的训练难度,另一方面,即使有了一个很大的词汇表,在实际应用中,还是会碰到一些在训练语料中没有出现的单词,此时LLM就不知道如何处理了,这就是所谓的OOV(Out Of Vocabulary)问题。
除了OOV问题外,即使我们的词汇表包含了一些生僻字,因为这些生僻词出现的频率往往很低,LLM也不能得到充分训练理解这些生僻字。
那么我们如何来解决这个问题呢?中国有句老话叫“认字认半边”,英语单词也有所谓的“词根”,所以解决办法就是找到一个大小适中的词汇表,里面有些是常见的单词,有些则是词根、常见的缩写、前后缀等,比如词汇表中可能有"look"这样的常见词,也会有"ed", "ing", "s"这样常见的时态、单复数后缀,而像"goodness"则有可能会被拆解为"good"和"ness"这两个词放进词汇表。这样当我们碰到OOV问题或者生僻字的时候,我们就可以把它拆解为词表中已有词汇的组合了,这其实就是“认字认半边”的思路。因为词汇表和单词不是一一对应的,所以我们就把词表的构成元素起名为Token。
有些善于思考的同学可能会说,顺着这个思路,那是不是英语的词表拆解成26个字母就可以了?中文也可以先用Unicode表示,然后用一个字节表示半个汉字,这样中文词表也就只有256个字了。
理论上上述思路是可行的,但是这种过细力度的拆解会丢改大量的语义信息,同时导致LLM的输入变得非常长,训练难度和成本指数级上升。
所以我们要做的就是在词表大小和保持语义之间保持一个平衡,既不能让词表过小丢失太多语义信息,也不能让词表过大增加过多训练和推理成本,在实践中,GPT-2和GPT-3的词表大约有5万个单词,而AI21 Lab的Jurassic模型其词表则有25.6万个单词,因为Jurassic的词表更大表达力更丰富,所以对同样的输入,Jurassic需要使用的Token比GPT-3要少28%。
因为Token是LLM理解语言的基本单元,Token中蕴含了大量的语义,所以能否把一个句子切分成合适的Token序列对LLM的训练和推理起着关键作用,在这个环节,我们主要要完成两个工作:
- 找到一个合适的词表
- 把句子切分成合适的Token序列
下面我们就来看看业界常用的分词方法是如何完成这两个工作的。
BPE (Byte-Pair Encoding)
我们以一个极简的输入"the cat the car the rat"为例子,BPE首先以组成这个输入的字符集[t, h, e, c, a, t, r, ]为基础Token,然后把输入拆分为如下序列:
[t, h, e, c, a, t, t, h, e, c, a, r, t, h, e, r, a, t]
然后看词表中哪两个Token一起出现的次数最多,就将其合并加入词表,可以看到't'和‘h'一共一起出现了3次,所以我们把'th'加入词表:
[th, t, h, e, c, a, t, t, h, e, c, a, r, t, h, e, r, a, t]
然后合并序列中的't'和'h'为'th':
[th, e, c, a, t, th, e, c, a, r, th, e, r, a, t]
重复上述循环,我们看到'th'和'e'一起出现了3次频率最高,所以词表变成:
[th, the, t, h, e, c, a, t, t, h, e, c, a, r, t, h, e, r, a, t]
而输入句子的拆分序列变成:
[the, c, a, t, the, c, a, r, the, r, a, t]
接着我们发现'c'和'a'一起出现了2次频率最高,所以词表变为:
[th, the, ca, t, h, e, c, a, t, t, h, e, c, a, r, t, h, e, r, a, t]
而输入句子的拆分序列变为:
[the, ca, t, the, ca, r, the, r, a, t]
上述过程可以一直循环,直到词表的大小增长到指定大小或者不再增长为止,此时我们就完成了第一个工作 -- 找到合适的词表。
现在,我们要进行第二项工作,把新的输入分解为词表中的Token序列,在上述训练过程中,我们一共进行了3次合并:
t, h -> th
th, e -> the
c, a -> ca
假设新的输入为"the ox",它首先被分解为[t, h, e, o, x],然后依次应用上述合并得到最后的结果:
[t, h, e, o, x] -> [th, e, o, x] -> [the, o, x]
对于中文,我们也可以用类似的方法来处理,比如“今天”的Unicode表示为[x62, x11, 4e, ca],然后对这样的序列,按照上面的过程不断合并就可以得到一个词表,对新的输入也是先将其拆解为Unicode序列,然后依次应用训练中发生的合并即可。
BPE最大的优点是其工作过程很简单,GPT-2,GPT-3就采用了BPE算法来分词,但它也有两个不足:
在扩充词表的过程中,BPE是选择贪心算法,把一起出现次数最高的两个Token合并,但这个选择并不一定总是最优选择,有可能两个Token不常出现,但只要它们一出现就总是一起出现,这种情况下,优先把这两个Token合并在语义上更能反映语言中各个Token的整体概率分布。
BPE的另一个潜在不足是,在处理新的输入时,BPE是按照训练时合并发生的顺序来处理输入的,但一个输入往往可以被拆分为不同的Token序列,按训练时的顺序来合并Token,其结果并不一定总是最优的Token序列。
WordPiece
上面讲了BPE虽然简单,但是有两个缺点,而WordPiece就针对缺点1进行了优化,WordPiece的整体工作过程和BPE很像,但是在选择哪两个Token进行合并时,它不是看哪两个Token一起出现的次数最多,而是看合并哪两个Token更符合语言的整体概率分布,Google的Bert模型就使用了这一算法。
那么WordPiece是如何找到最符合整体概率分布的那两个Token来合并的呢?其大致思路是,一个句子拆分成N个Token,这种拆分比较合理的可能性(也就是符合语言整体概率分布的似然值)就是这N个Token各自概率的乘积,那么只要看看合并哪两个Token后,Token序列的概率乘积最大,我们就可以找到最应该合并的Token了。
上述工作过程的数学公式如下,不感兴趣的同学可以跳过。
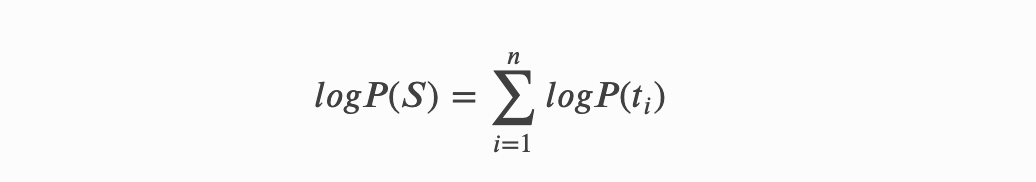
其中S表示一个句子,这个句子被拆分成了N个Token,ti就表示第i个Token,而*P*(ti)表示第i个Token的概率,数学上为了方便计算,通过取对数,把概率的连乘变成了连加,而找到最应该合并的Token的过程就是最大化上述公式取值的过程。
那么具体每个Token的概率又是怎么来的呢?这个比较简单,虽然不同的WordPiece实现有细节上的差别,但大致可以理解为通过对训练集进行频率统计即可得到单个Token的概率。
Unigram Language Model (ULM)
BPE算法中构建词表时,贪心算法不保证词表最优,为了解决这个问题,WordPiece是合并Token时做优化,不断找到最优的Token对然后合并加入词表,而ULM则反其道而行,它首先初始化一个比较大的词表,然后看把哪些词去掉,剩下的词表更符合语言的整体概率分布,这样不断迭代,直到词表缩小到预期的尺寸,下面讲讲其详细工作过程。
初始化词表
这个初始化的大词表一般是训练集上所有的单词、再加上常见的字符串构成。因为上面讲到的BPE算法很简单,在有些ULM的实现中,也可以直接用BPE来初始化一个大词表。
计算词表中每个Token的概率
这里一般使用EM算法,这个算法的思路是,先给每个Token随便估一个概率,然后拿训练集的数据来优化这个概率,不断迭代直到Token的概率变化收敛,EM算法找到的解不一定是全局最优的,但至少能找到一个局部最优解。
EM算法比较复杂,需要专门的文章来介绍,其核心在于求解如下似然函数的最大值:
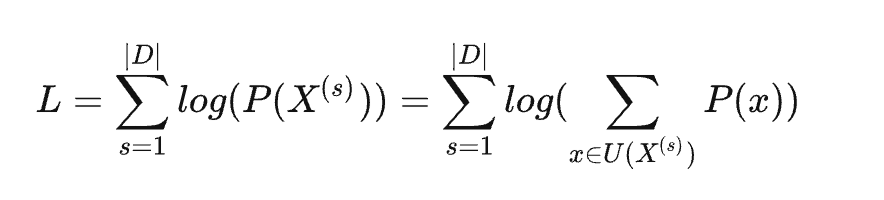
对于一个数据集D,它由多个句子s组成,其中每个句子有多种拆分序列的可能,上述公式就是对所有句子的所有拆分序列的概率求和。
下面是一个EM算法具体求解过程的例子,假设训练数据是 ["I", "like", "apples", "Apples", "are", "tasty", "I", "like", "bananas"]:
-
我们先把词表初始化为: {"I": 0.1, "like": 0.1, "apples": 0.1, "Apples": 0.1, "are": 0.1, "tasty": 0.1, "bananas": 0.1},刚开始所有的Token概率相同
-
统计各个Token在训练数据中出现的次数,并乘以其概率,在EM算法中这叫做计算期望值:
"I": 0.1 * 2 = 0.2
"like": 0.1 * 2 = 0.2
"apples": 0.1 * 1 = 0.1
"Apples": 0.1 * 1 = 0.1
"are": 0.1 * 1 = 0.1
"tasty": 0.1 * 1 = 0.1"bananas": 0.1 * 1 = 0.1
-
归一化期望值:0.2 + 0.2 + 0.1 + 0.1 + 0.1 + 0.1 + 0.1 = 0.9,计算出新的概率:
"I": 0.2 / 0.9 = 0.222
"like": 0.2 / 0.9 = 0.222
"apples": 0.1 / 0.9 = 0.111
"Apples": 0.1 / 0.9 = 0.111
"are": 0.1 / 0.9 = 0.111
"tasty": 0.1 / 0.9 = 0.111
"bananas": 0.1 / 0.9 = 0.111
不断循环上述迭代,直到概率变化收敛,我们就得到了各个Token的概率。
计算词表
当我们有了一个初始的大词表,并通过EM算法计算出了每个Token的概率后,对词表中的每个词,我们计算如果把这个词从词表中删除,词表符合整体语言概率分布的可能性会下降多少(通过上面EM算法的似然函数计算),如果删除一个词导致的变化较小,就说明词表中有没有这个词影响不大,我们选择最无关紧要的20%的词删除,词表更新后,我们用EM算法再次计算每个Token的概率,然后又一次删除20%无关紧要的词,不断迭代,直到词表缩小到预期的大小。
用词表和Token概率对新的输入分词
当我们最终得到了一个词表和相应Token的概率后,给定一个新的句子S,这个句子被拆分成了N个Token,ti表示第i个Token,而*P*(ti)表示第i个Token的概率,则这个句子符合整体语言概率分布的可能性(取对数方便计算)为:
对S的所有可能拆分,我们选择可能性最大的那个序列作为分词结果输出。
在实际应用中,Google推出的SentencePiece开源库集成了ULM算法,AI21 Lab的Jurassic模型就使用了SentencePiece。
对比BPE, WordPiece, ULM三者,BPE最简单,但不能保证其词表和分词结果是最优的(符合语言整体概率分布),WordPiece则优化了词表创建的过程,也比BPE稍微复杂一点,而ULM则最复杂,它同时优化了词表的创建和分词过程。