腾讯云原生场景下内存多级卸载落地实践
近期,第四届中国云计算基础架构开发者大会(China Cloud Computing Infrastructure Developer Conference – 简称 CID)在深圳举办。本届 CID 大会聚焦业界最前沿的云计算基础架构技术成果,围绕基础架构技术领域的技术交流,展示先进技术在行业中的典型实践。在主论坛上,作者以《云原生场景下内存多级卸载落地实践》为议题,分享内存多级卸载方案(内部称“Tencent OS悟净”)在公司业务落地过程中所遇到的实际问题、对应的解决方案,以及在容器平台上的落地数据。以下为分享重点。
产业背景
内存需求成本不断上升,提升内存利用率成为首要问题:
- 服务器在数据中心硬件采购成本中占比最高, 其中 CPU、GPU 和 DRAM 是主要成本项;
- 随着数据量和业务复杂度上升,内存需求陡增,而应用程序为了提高性能,大都采用内存密集性策略,长时间运行或者大量服务并存时会出现很大的内存压力,如内存颠簸、OOM 等。云计算对内存需求也在持续增长。
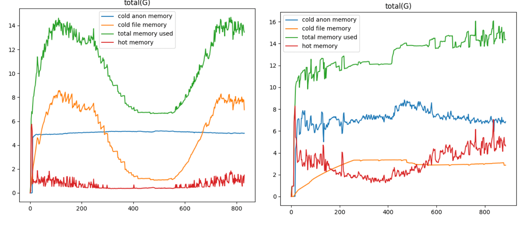
- 业务内存中不活跃冷内存占有很大比例,比例值根据业务不同会有波动,比如我们在集群中抓去的一些典型workload的冷热内存占比如下图。
在这样的背景下,内存多级卸载应运而生。如下图,用了内存多级卸载之后,每台workload可以节省出很多空闲资源。对于这些空闲资源,我们在腾讯云应用中主要有三种场景。
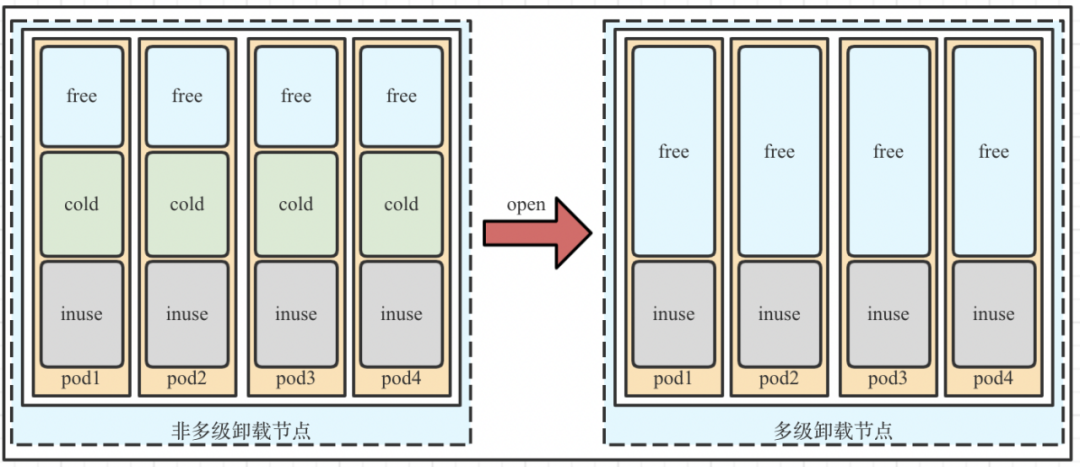
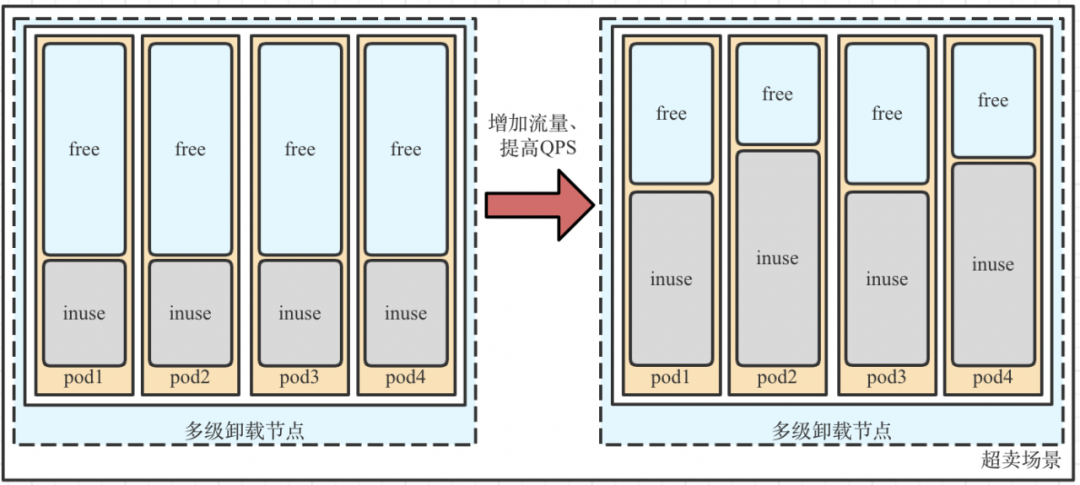
第一种,业务超卖场景:对workload开启多级卸载后,增加单pod(CVM)流量,提高TPS、QPS。
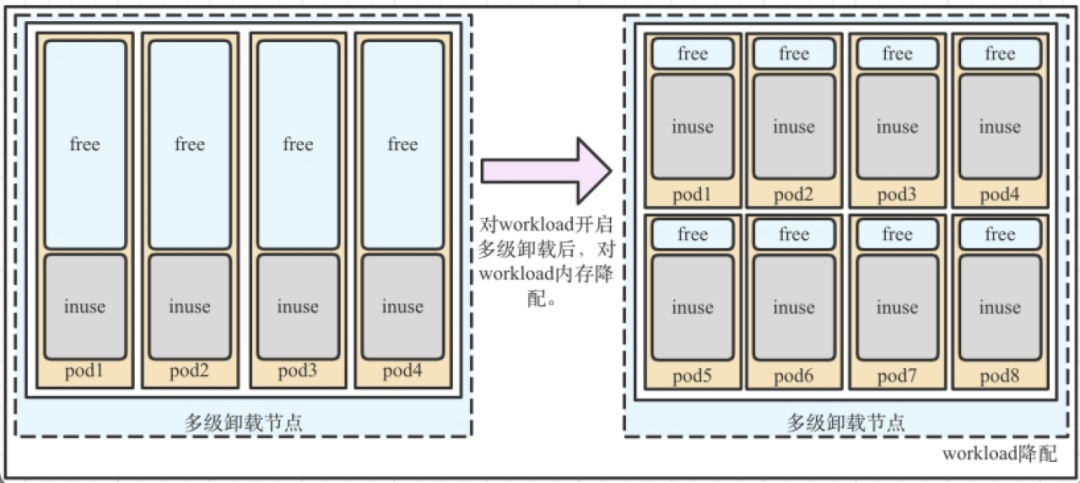
第二种,负载降配
● 降低业务成本:对workload开启内存多级卸载后,降低workload resources的memory request和limit,降低平台业务的上云成本。
● 提高集群装箱率:多数集群节点CPU/MEM是1:2,但是现网很多是大内存workload(1:4,1:8),影响集群装箱率,将大内存workload降配后(1:8 -> 1:4),可以提高集群装箱率。
第三种,混部弹性内存超卖
提高内存混部率:把非内存敏感型workload开启内存多级卸载,节省出多余的空闲内存资源,可以调度更多的离线(低优先级)pod上来,并且,在整机内存压力大又不能及时迁出的情况下,优先迁出、OOM调离线(低优先级)pod。

整体解决方案
首先多级卸载在云原生场景落地中遇到的一些实际问题:
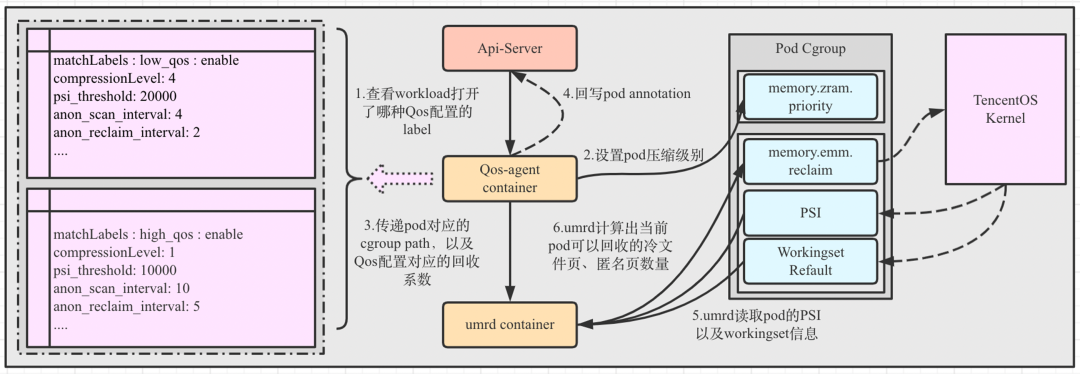
● 回收路径难以确定:内存多级卸载的回收名单是cgroup path list,但是在云原生容器平台中,pod cgroup path是一串哈希值,并且pod会在集群的node中间迁入迁出,实时调度,如何确定节点上哪些pod需要开启内存多级卸载,并且随着pod状态的改变,实时改变回收及更新名单?
● 回收参数难以确定:在容器平台中,需要开启内存多级卸载的workload对内存回收的敏感程度是不一样的,如何判断workload类型,然后使用对应回收参数?
● 主动回收也会导致一些问题:
(1) 误回收“冷”文件页:主动回收额外的文件页面,由于当前lru精度比较单调,导致误回收一些将会访问的页面,导致cache miss,造成读IOPS增加。
(2)过度压缩匿名页:在主备存储模型中,备份节点一直处于空闲状态,因为PSI一直表征空闲情况,内存多级卸载不断将其匿名页面压缩到zram,突然的主备切换,导致备节点突增大量请求,所有在zram的页面基本都需要解压,造成颠簸的延迟反应。
● zram的页面无法统计,这也是社区面临的问题:目前workload的resources.limits.memory是对cgroup的memory.usage_in_bytes做限制,但是压缩在zram的匿名页面无法被限制,会造成计数器泄露的问题,pod可能无限制得利用node上的zram资源,而k8s感知不到。
● 无法隔离非内存多级卸载pod的换出行为:当对node节点开启zram的时候,虽然不对非内存多级卸载pod做主动回收,但在非内存多级卸载pod容器内存紧缺的情况下、或者整机内存紧缺的情况下,依然有可能把非内存多级卸载pod的匿名页面压缩到zram中,改变客户原本的预期行为。
整体架构
针对以上问题,我们出了一个整体解决方案,分为5个模块及各自功能。
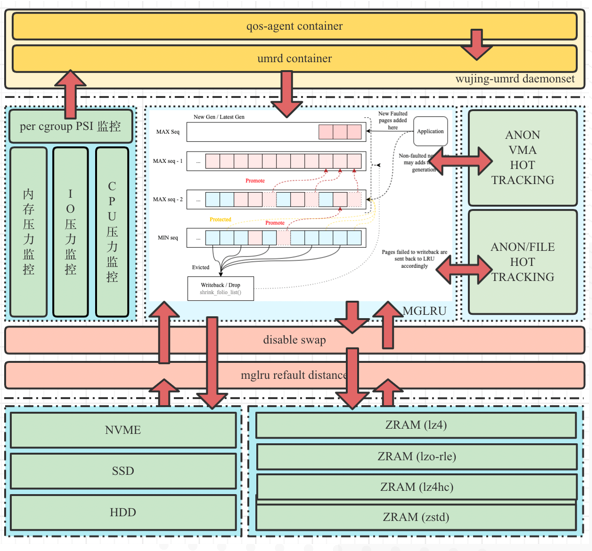
○ qos-agent container:在node上,找到哪些pod打开了多级卸载,并且把pod cgroup和回收参数发送到umrd ds。
○ umrd container:umrd根据qos-agent传递过来的回收列表进行主动回收,并且根据回收参数、PSI、refault、cpu util计算回收文件页、匿名页的数量。
● mglru增强模块:
○ 拆分接口:文件页面、匿名页面独立扫描、回收。
○ Workingset Evaluation:评估有效文件页回写数量。
○ new workingset refault feature:优化mglru workingset。
● swap隔离模块:system disable、cgroup disable,可以隔离来自节点内存紧缺和容器内存紧缺对非开启内存多级卸载的pod换出行为。
● zram增强模块:per-cgroup zram priority、per-cgroup zram counter(raw、limit、usage)每个cgroup可以独立设置zram压缩登极,对于per-cgroup也做到了每个cgroup都能独立计算出压缩前和压缩后的量,以及现在cgroup zram的用量。
● 现网集群中部署热度探测模块:可以做匿名段热度探测,pod中总内存的容器总匿名页、文件页面热度探测,计算各自占比,我们根据占比评估出workload哪个集群适合开启多级卸载。
子模块介绍
wujing-umrd ds
首次在集群中部署wujing-umrd ds,集群中每个node都会被调度上一个wujing-umrd pod,其中, wujing-umrd ds包含一个qos-agent container和umrd container。
● qos-agent container:当node上pod状态发生变化的时候,根据pod yaml打的QOS标签,对pod开启多级卸载,并且启用QOS标签对应的压缩等级和回收参数。
● umrd container:接受qos-agent container传递的回收路径和回收参数,并且根据PSI、refault负反馈决定当前回收的页面数量,将这些页面数量下给内核。
mglru增强
内核里面,我们更换了LRU算法。原本是两级mglru,我们backpod上游多级:
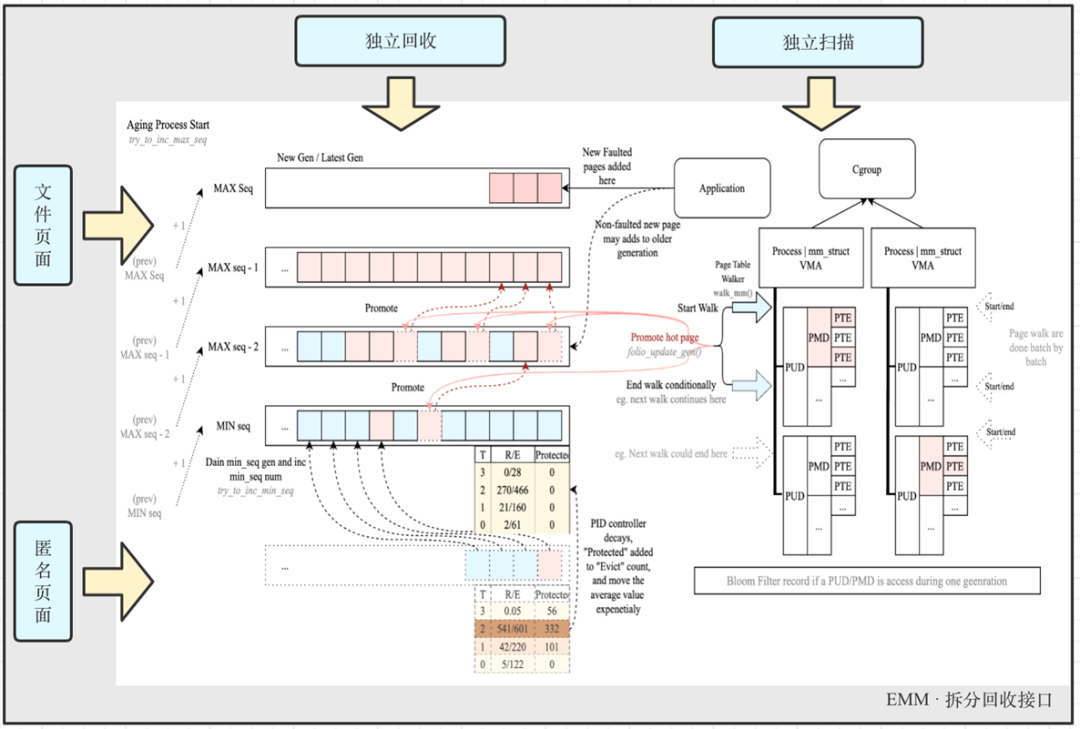
● mglru拆分接口:
○ 将mglru文件页、匿名页的扫描和回收过程隔离,并且给出同一的用户接口。
○ 使用方式,例如:
对于访问频繁的匿名页面,可以10s扫描一次,5s回收一次。
对于慢盘并且访问少的文件页,可以20s扫描一次,2s回收一次,实现有针对性的回收。
● Workingset Evaluation:
○ 可以获取一个 Cgroup 过去 1分钟/10分钟/30分钟 内平均 Refault 距离,以及预估有效文件页回写数量。
● workingset refault重构与优化:
○ 对 Linux 内核中传统 LRU 长期使用的 Workingset Refault Distance 算法进行了重新优化设计,并成功将其与 MGLRU 中的 Refault PID 算法结合。
○ 改进后的算法可以辅助不同场景下进行更加有效的页面平衡,并能更加有效地防止 Thrashing。新算法在一些应用场景中有着非常显著的性能提升(5% - 400%)。即使是在传统 LRU 场景下,新算法也有可见性能提升(1 - 5%)。部分改进已发至上游。
swap隔离
在集群原本没有开启swap,在使用多级卸载后,将会把集群的swap打开,对于非多级卸载pod,在整机、容器内存紧缺的情况下,会将匿名页面换出到swap设备,这是业务非预期行为,得支持swap的隔离。

● 容器内存紧缺:在容器内存紧缺的情况下,内核内存子系统会从当前memcg开始遍历memcg,并且回收其lruvec,如果当前memcg没有开启多级卸载,那么会导致业务的匿名页面换出到swap上。
接口与解决办法:
● 内核接口:vm.force_swappiness、memory.swappiness
● qos-agent:qos-agent对开启多级卸载的集群,设置vm.force_swappiness=1,强制在整机、容器内存紧缺的情况下,强制对swappiness==0的容器不回收匿名页面;并且,在node上pod状态发生变化的时候,对非多级卸载pod设置swappiness=0,多级卸载pod设置swappiness=60。
zram增强
ZRAM Enhance基于上游 Object Cgroup API 实现,每个 Cgroup 提供了:
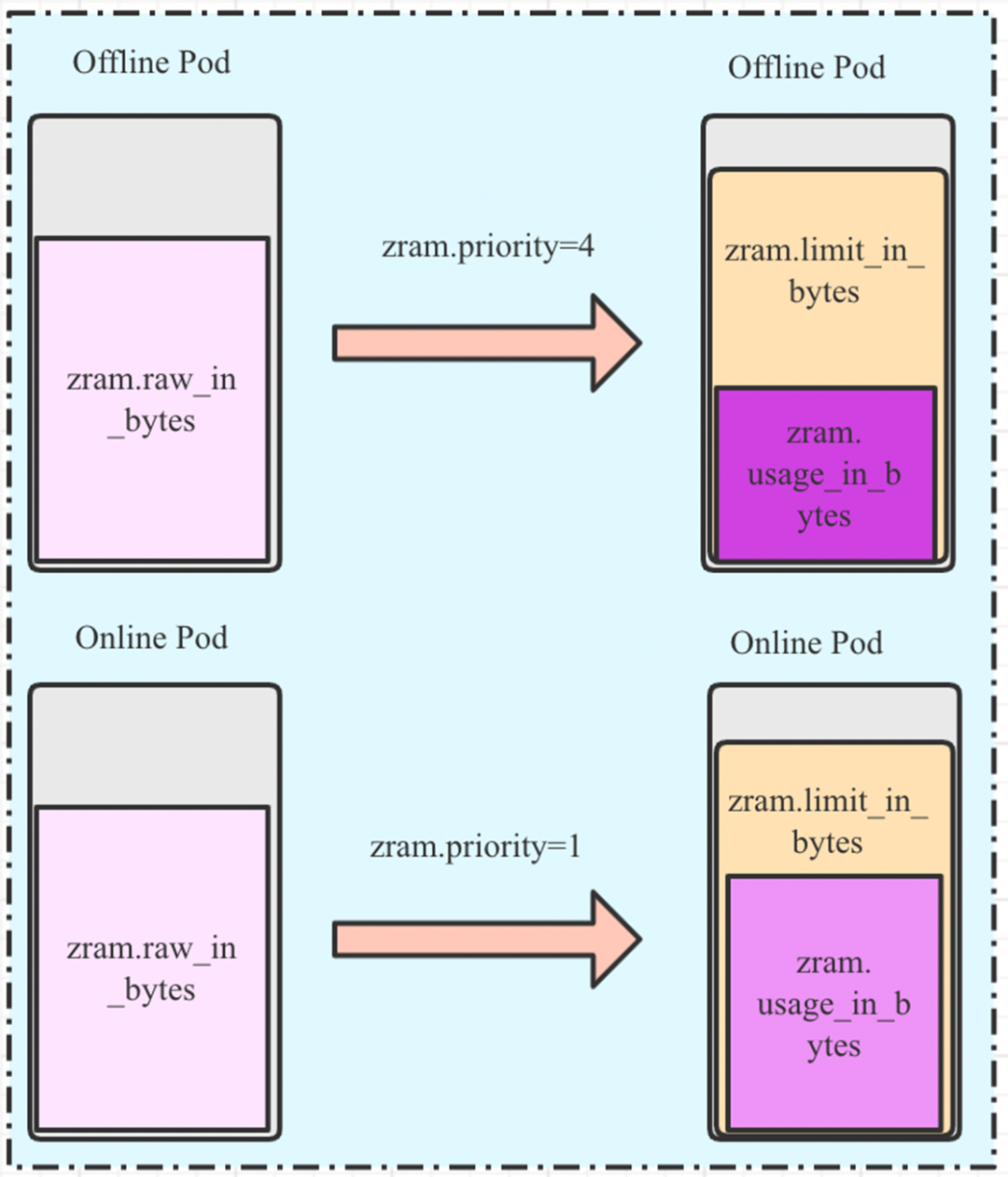
/memory.zram.priority:每个 Cgroup 可以选择压缩等级 1 - 4,默认分别对应算法 lz4,lzo-rle,lz4hc,zstd,压缩率由高到低,性能损失由小增大,进而对不同敏感程度的pod用不同的压缩等级。
● 独立统计 ZRAM 压缩数据:
/memory.zram.raw_in_bytes:以 Byte 为单位的换出到zram压缩前的数据大小
/memory.zram.usage_in_bytes:以 Byte 为单位的换出到zram压缩后的总数据大小
● 限制 ZRAM 压缩量
/memory.zram.limit_in_bytes:以Byte为单位,限制本memcg换出到zram的总数据大小,超出这个限制后,匿名页面将无法换出到zram设备。
同时,zram压缩后的数据大小会计算到memory.usage_in_bytes上,方便k8s感知和限制。
落地效果
目前内存多级卸载在公司在线容器平台、离线容器平台都已大量应用,覆盖业务含:键值存储、文件存储、聊天图片存储、聊天消息存储、AI平台、游戏AI训练、转码、数据库等。目前收益场景:超卖、降配、混部。
超卖场景
内存节省:提升单机的内存售卖率,降低内存存储的成本。相同数据量情况下,开启多级卸载,内存用量降低35%。
延迟情况:请求延时基本没有波动。
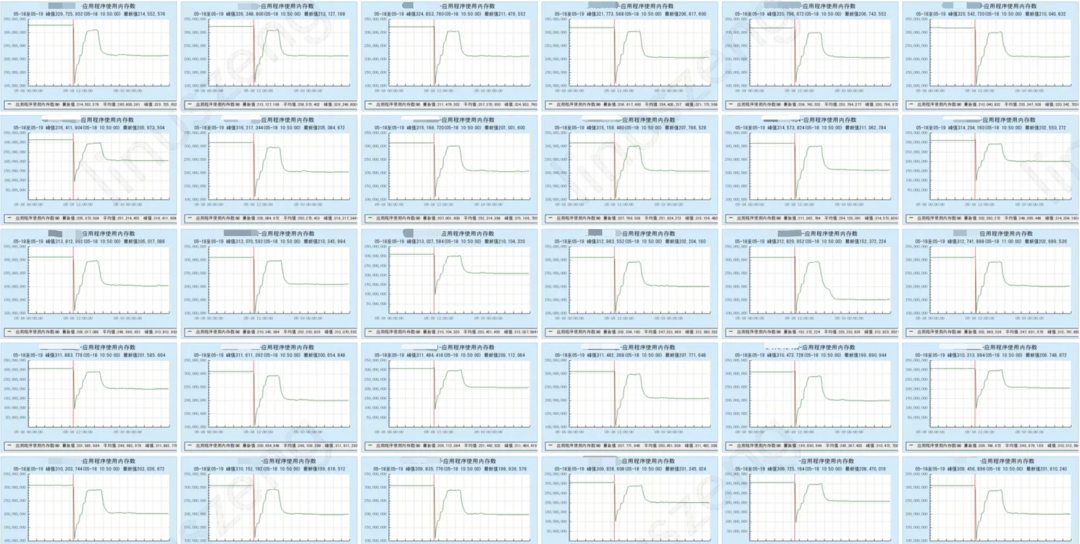

降配场景
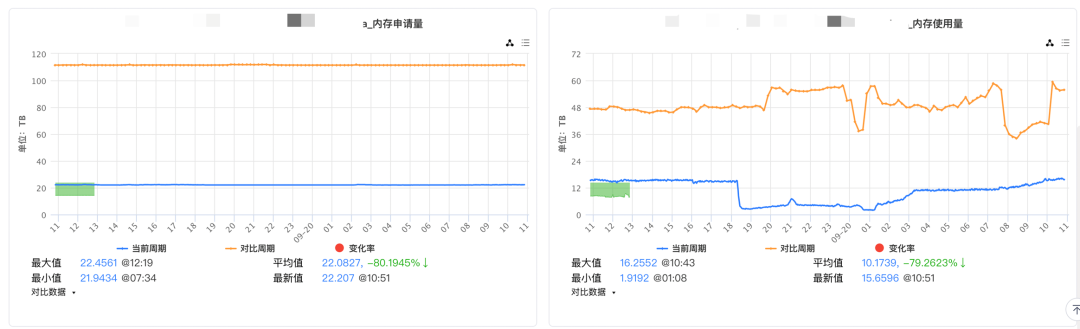
内存节省:对workload开启多级内存卸载,稳定降低内存用量后,降低workload的配置,节省业务上云成本。
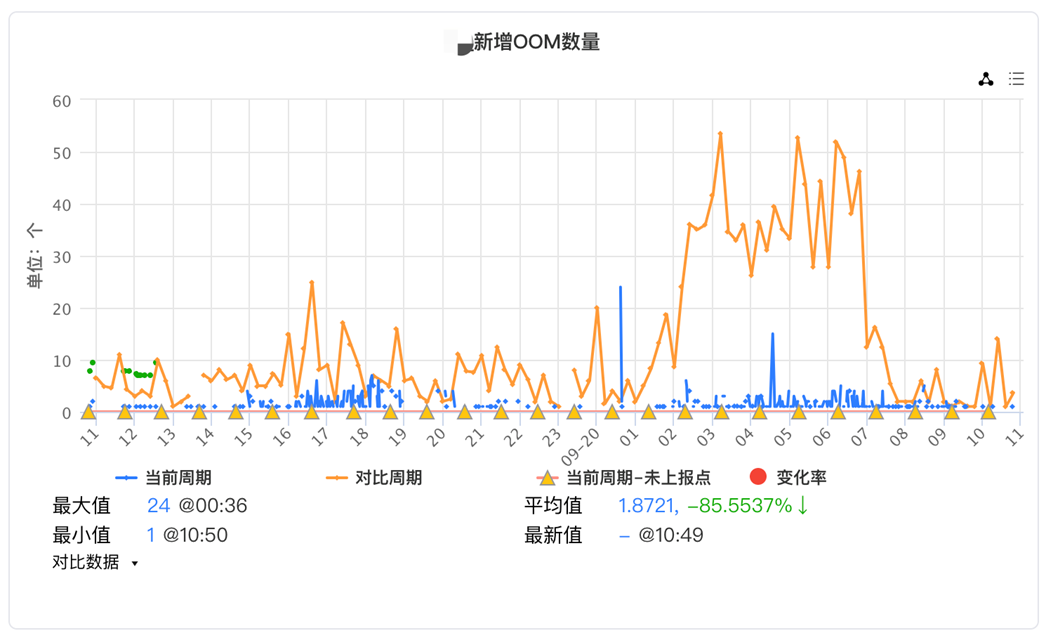
性能:降低业务workload 86%的OOM数量。
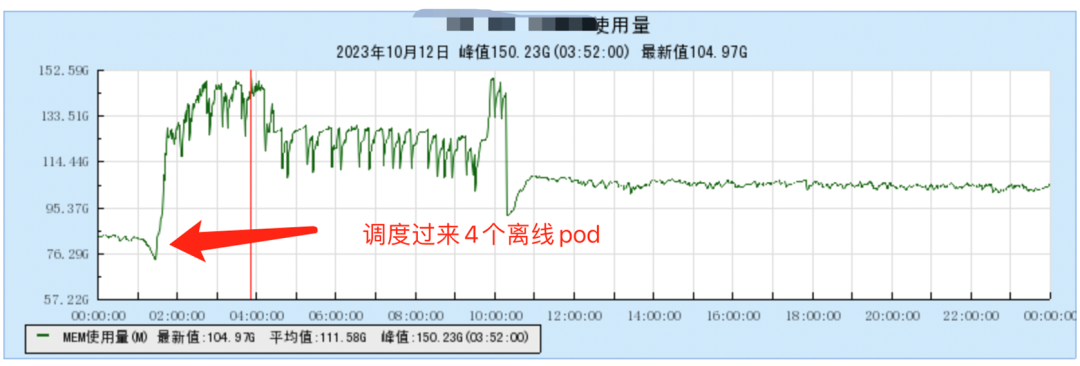
混部场景
内存节省:在混部集群中,节点内存接近打满,但CPU利用率还有空闲,此时内存资源成为混部瓶颈。对非内存敏感型workload开启多级卸载后,节省出额外的内存资源,调度更多的离线pod。
性能:无影响(出现影响优先kill离线pod)。


https://cloud.tencent.com/document/product/457/78197
上集成内存压缩能力,目前火热内测中,欢迎提交工单抢先体验: